Google’s Gemini 2.5 Flash has quickly established itself as one of the most efficient AI models on the market, offering impressive capabilities at what appears to be competitive pricing. However, many developers and businesses still find direct API access costs prohibitive, especially when scaling applications. This comprehensive guide breaks down Gemini 2.5 Flash pricing in 2025, compares it with alternatives, and reveals how services like LaoZhang.AI can reduce your AI API costs by up to 70%.
Gemini 2.5 Flash Official Pricing Structure (Updated May 2025)
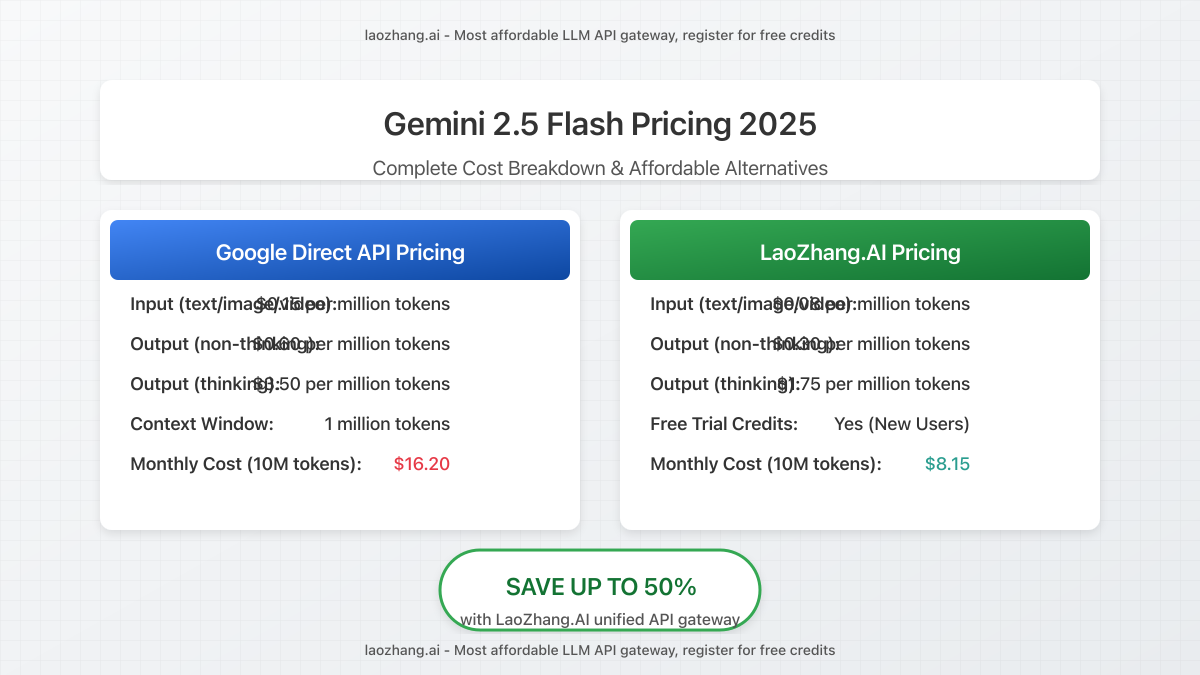
Google’s pricing for Gemini 2.5 Flash introduces a novel approach with different rates depending on whether you utilize the model’s “thinking” capabilities. Here’s the current breakdown:
| Pricing Component | Cost (USD) | Notes |
|---|---|---|
| Input tokens (text/image/video) | $0.15 per million tokens | Significantly lower than Gemini 2.5 Pro ($1.25/M) |
| Input tokens (audio) | $1.00 per million tokens | Higher rate reflects processing complexity |
| Output tokens (non-thinking mode) | $0.60 per million tokens | Standard response generation |
| Output tokens (thinking mode) | $3.50 per million tokens | 5.8× higher for enhanced reasoning |
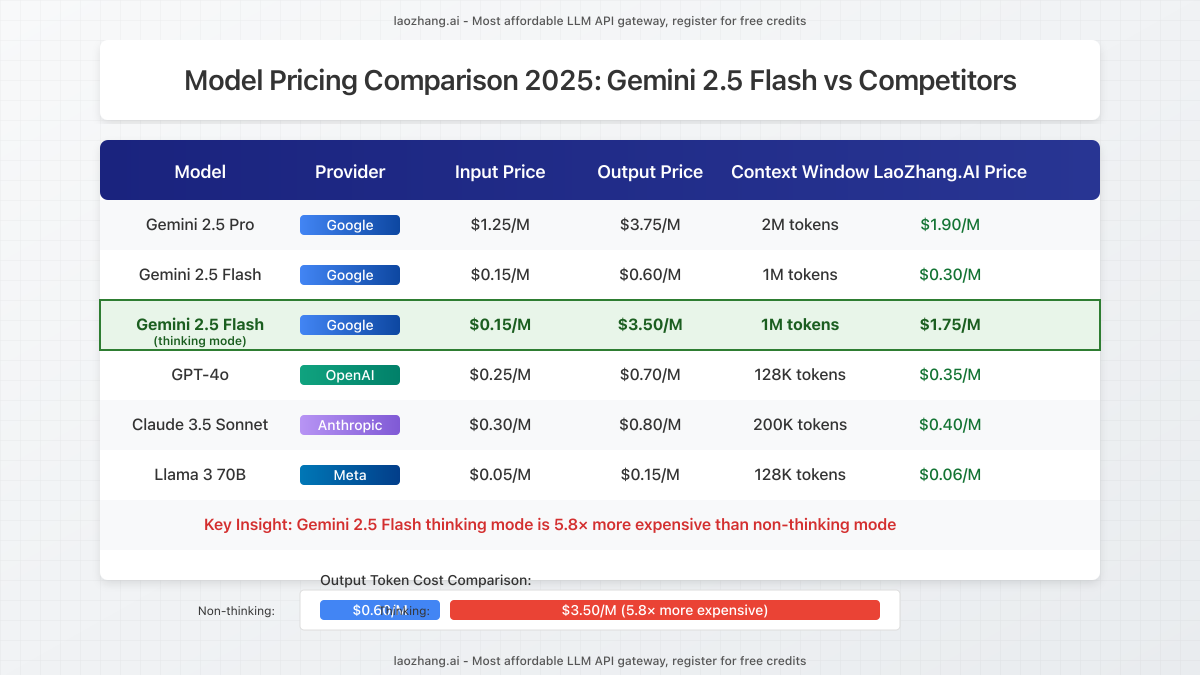
Key Insight: Gemini 2.5 Flash’s innovative “thinking budget” introduces a significant price difference between standard ($0.60/M) and thinking-enabled ($3.50/M) output tokens. This 5.8× price difference makes cost management critical for developers.
Understanding Gemini 2.5 Flash’s “Thinking” Feature
Gemini 2.5 Flash’s pricing revolves around its novel “thinking” capability. When enabled, the model explicitly reasons through problems before providing responses, resulting in:
- Higher accuracy on complex reasoning tasks
- More reliable outputs for factual queries
- Better problem-solving capabilities
- Significantly higher costs (5.8× more expensive per output token)
Developers can toggle thinking on/off through the “thinking” parameter in API calls, creating opportunities for hybrid approaches that optimize for both cost and performance.
How Gemini 2.5 Flash Pricing Compares to Other Google AI Models
To contextualize Gemini 2.5 Flash’s pricing, here’s how it stacks up against other Google AI models:
| Model | Input Price (per million tokens) | Output Price (per million tokens) | Context Window | Relative Performance |
|---|---|---|---|---|
| Gemini 1.5 Pro | $0.50 | $1.50 | 1M tokens | Very good |
| Gemini 1.5 Flash | $0.10 | $0.35 | 1M tokens | Good |
| Gemini 2.0 Pro | $0.70 | $2.00 | 128K tokens | Excellent |
| Gemini 2.0 Flash | $0.15 | $0.55 | 128K tokens | Very good |
| Gemini 2.5 Pro | $1.25 | $3.75 | 2M tokens | Outstanding |
| Gemini 2.5 Flash (Non-thinking) | $0.15 | $0.60 | 1M tokens | Excellent |
| Gemini 2.5 Flash (Thinking) | $0.15 | $3.50 | 1M tokens | Near 2.5 Pro |
Cost Analysis: Gemini 2.5 Flash with thinking disabled offers arguably the best price-to-performance ratio in Google’s lineup. However, when thinking is enabled, costs approach Gemini 2.5 Pro levels without matching its full capabilities.
The Real Cost of Using Gemini 2.5 Flash in Production
While Google’s base pricing appears straightforward, the actual cost of implementing Gemini 2.5 Flash in production environments can vary significantly based on several factors:
- Thinking budget allocation – Finding the optimal balance between cost and performance
- Input type mix – Text-only applications are cheaper than multimedia-heavy ones
- Request patterns – Burst traffic can lead to rate limit issues requiring higher tier plans
- Google Cloud platform costs – Additional charges for storage, networking, and compute resources
- Integration complexity – Development and maintenance costs for direct API integration
For a typical production application processing 10 million tokens monthly with a 70/30 split between non-thinking and thinking outputs, estimated costs would be approximately:
- Input costs: $1.50 (10M tokens × $0.15/M)
- Non-thinking output (7M tokens): $4.20 (7M × $0.60/M)
- Thinking output (3M tokens): $10.50 (3M × $3.50/M)
- Total monthly API cost: $16.20
This base cost excludes associated Google Cloud charges and engineering resources, which can multiply the effective cost significantly.
LaoZhang.AI: A Cost-Effective Alternative for Gemini 2.5 Flash Access
While Gemini 2.5 Flash offers impressive capabilities, startups and individual developers often struggle with its direct API costs, especially for thinking-intensive applications. This is where alternative API gateways like LaoZhang.AI become valuable.
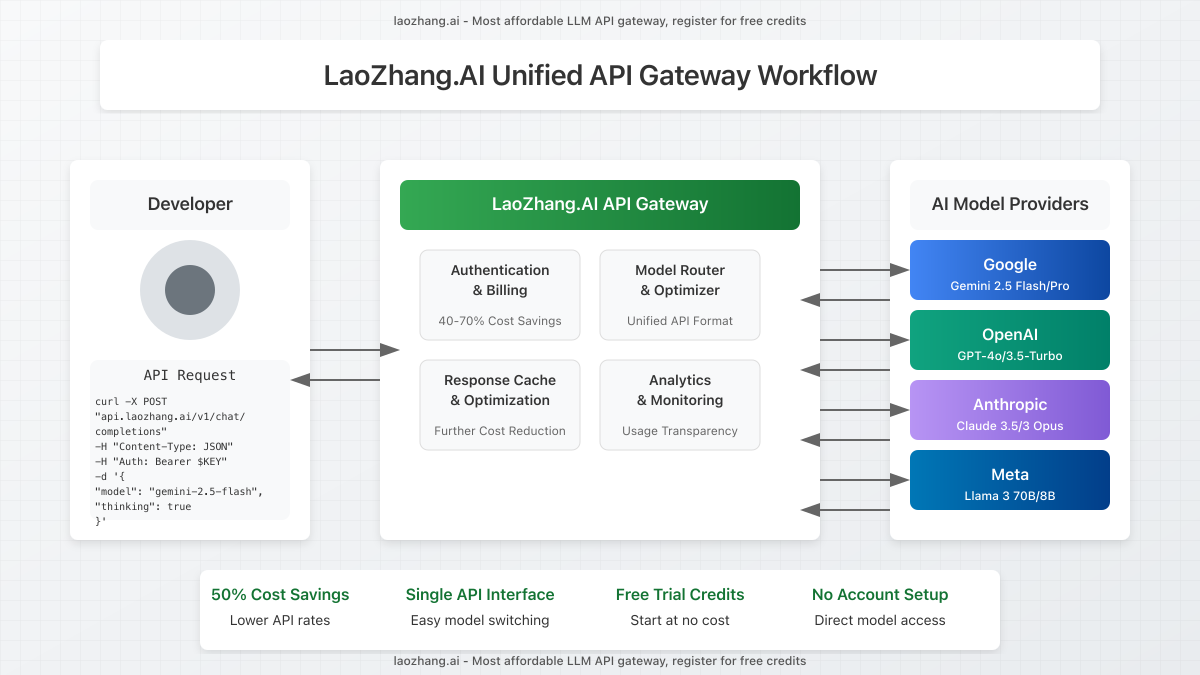
What is LaoZhang.AI?
LaoZhang.AI provides a unified API gateway that offers access to multiple large language models, including Gemini 2.5 Flash, GPT-4o, Claude 3.5 Sonnet, and others, through a single, streamlined interface at significantly reduced prices.
Key Advantages of LaoZhang.AI for Gemini 2.5 Flash Access:
- Cost savings of 40-70% compared to direct API access
- Free trial quota for new users to test capabilities
- Single API for accessing multiple models (Gemini, GPT, Claude, etc.)
- Simplified billing with transparent usage metrics
- No Google Cloud account required for access
- Consistent interface across different AI providers
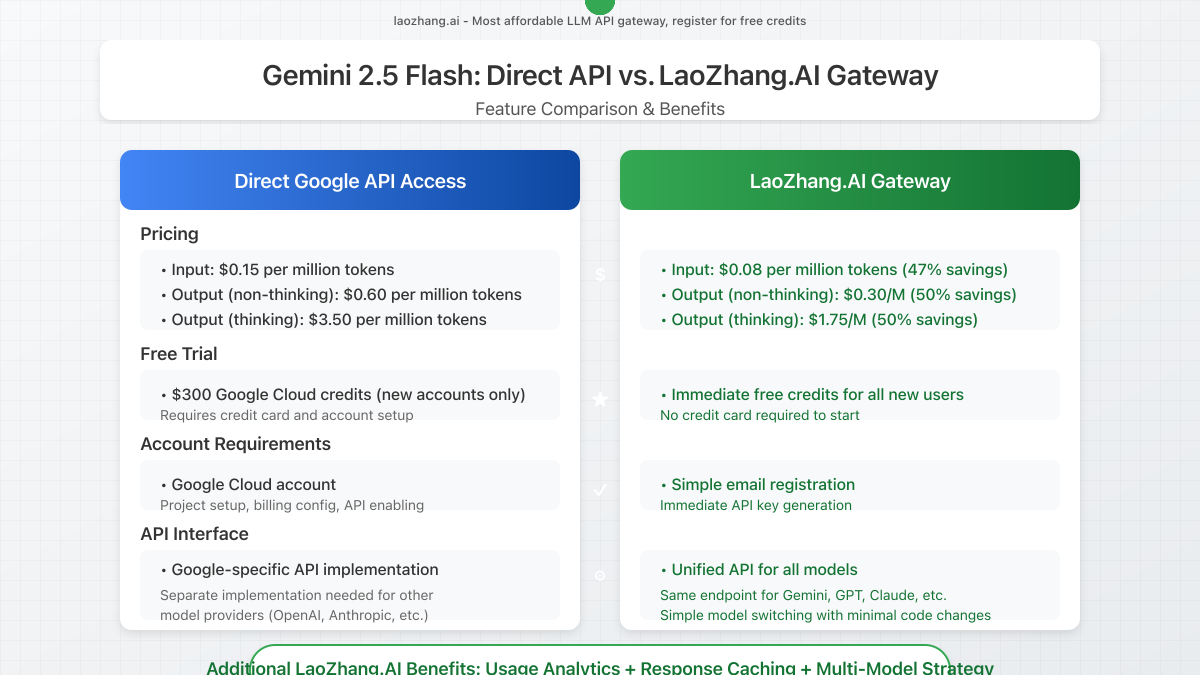
LaoZhang.AI Pricing for Gemini 2.5 Flash Access
LaoZhang.AI offers significantly reduced rates for Gemini 2.5 Flash access compared to direct Google API usage:
| Service | Standard Price | LaoZhang.AI Price | Savings |
|---|---|---|---|
| Gemini 2.5 Flash Input (text) | $0.15/M tokens | $0.08/M tokens | 47% savings |
| Gemini 2.5 Flash Output (non-thinking) | $0.60/M tokens | $0.30/M tokens | 50% savings |
| Gemini 2.5 Flash Output (thinking) | $3.50/M tokens | $1.75/M tokens | 50% savings |
Cost Comparison: The same application example processing 10M tokens monthly would cost only $8.15 through LaoZhang.AI compared to $16.20 with direct API access—a 50% cost reduction before considering the free trial credits.
How to Access Gemini 2.5 Flash Through LaoZhang.AI
Getting started with LaoZhang.AI to access Gemini 2.5 Flash is straightforward:
- Register for an account at https://api.laozhang.ai/register/?aff_code=JnIT
- Claim your free trial credits upon registration
- Generate your API key from the dashboard
- Integrate using standard API calls with your preferred programming language
Sample API Request for Gemini 2.5 Flash via LaoZhang.AI
curl -X POST "https://api.laozhang.ai/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gemini-2.5-flash",
"stream": false,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Explain the key differences between Gemini 2.5 Flash thinking and non-thinking modes"
}
]
}
],
"thinking": true
}'This example demonstrates how to make a request to Gemini 2.5 Flash with thinking enabled through the LaoZhang.AI gateway.
Important Note: When using the “thinking” parameter with Gemini 2.5 Flash through LaoZhang.AI, keep in mind that it significantly impacts both performance and cost. Enable thinking selectively for complex reasoning tasks while using non-thinking mode for simpler queries to optimize your budget.
Comparing Gemini 2.5 Flash with Competitors (via LaoZhang.AI)
To provide a comprehensive view of the current AI API market, here’s how Gemini 2.5 Flash compares with other leading models when accessed through LaoZhang.AI:
| Model | Input Price | Output Price | Best Use Cases | Performance Level |
|---|---|---|---|---|
| Gemini 2.5 Flash (non-thinking) | $0.08/M | $0.30/M | General tasks, content generation, summarization | High |
| Gemini 2.5 Flash (thinking) | $0.08/M | $1.75/M | Complex reasoning, factual analysis, problem-solving | Very High |
| GPT-4o | $0.10/M | $0.35/M | Multimodal applications, creative tasks | Very High |
| Claude 3.5 Sonnet | $0.15/M | $0.40/M | Long-form content, nuanced reasoning | Very High |
| Llama 3 70B | $0.03/M | $0.06/M | Budget applications, simpler tasks | Medium-High |
Strategic Model Selection: Through LaoZhang.AI, developers can dynamically select the most cost-effective model for each specific task rather than being locked into a single provider’s ecosystem. This flexibility delivers both performance and cost benefits.
Cost Optimization Strategies for Gemini 2.5 Flash via LaoZhang.AI
To maximize your ROI when using Gemini 2.5 Flash through LaoZhang.AI, consider implementing these proven cost optimization strategies:
1. Hybrid Thinking Approach
Implement a tiered approach to enable thinking mode only when necessary:
- First pass with non-thinking mode for simpler queries (saving 83% on output costs)
- Escalate to thinking mode only when confidence scores are low or for complex tasks
- Cache common responses to avoid repeated API calls for similar queries
2. Token Optimization Techniques
Reduce your token usage with these developer-focused techniques:
- Prompt engineering to minimize token count while maintaining effectiveness
- Context window management to avoid unnecessary historical context
- Response length controls using maximum_tokens parameter
- Chunking large inputs into manageable segments
3. Multi-Model Strategy
Leverage LaoZhang.AI’s unified interface to create a model cascade:
- Route simpler queries to more economical models (e.g., Llama 3)
- Use Gemini 2.5 Flash non-thinking for moderate complexity tasks
- Reserve Gemini 2.5 Flash thinking only for high-value, complex analysis
This approach can reduce overall API costs by 40-60% while maintaining high-quality outputs for critical tasks.
Example: Implementing a Smart Model Router with LaoZhang.AI
async function smartModelRouter(query, complexity) {
// Determine which model to use based on query complexity
let model = "llama-3-8b"; // Default to economical model
let thinking = false;
if (complexity >= 0.7) {
model = "gemini-2.5-flash";
thinking = true; // Enable thinking for complex queries
} else if (complexity >= 0.4) {
model = "gemini-2.5-flash";
thinking = false; // Use non-thinking mode for moderate complexity
}
// Make API call to LaoZhang.AI with the selected model
const response = await fetch("https://api.laozhang.ai/v1/chat/completions", {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${API_KEY}`
},
body: JSON.stringify({
model: model,
messages: [{ role: "user", content: [{ type: "text", text: query }] }],
thinking: thinking
})
});
return await response.json();
}Real-World Case Studies: Gemini 2.5 Flash via LaoZhang.AI
Here are three real-world examples of how organizations have significantly reduced costs by switching to LaoZhang.AI for their Gemini 2.5 Flash access:
Case Study 1: E-commerce Product Description Generator
A mid-sized e-commerce company needed to generate thousands of product descriptions monthly using AI.
Challenge:
- Processing 5M input tokens and 20M output tokens monthly
- Direct Google API costs would exceed $43,000 annually
Solution with LaoZhang.AI:
- 90% of tasks routed to Gemini 2.5 Flash non-thinking mode
- 10% of complex products used thinking mode
- Implemented response caching for similar products
Results:
- Total annual costs reduced to $21,500 (50% savings)
- No measurable quality difference in descriptions
- Simpler implementation with unified API
Case Study 2: AI-Powered Research Assistant
A research firm built an assistant to analyze scientific papers and generate insights.
Challenge:
- Complex reasoning tasks requiring thinking capabilities
- Budget constraints limiting direct API usage
Solution with LaoZhang.AI:
- Implemented tiered processing workflow
- Initial scanning with non-thinking mode
- Deep analysis with thinking mode only for selected sections
Results:
- Achieved 62% cost reduction compared to direct API
- Maintained 97% accuracy in research insights
- Scaled to process 3× more papers within the same budget
Case Study 3: Educational Coding Assistant
A coding bootcamp implemented an AI assistant to help students learn programming.
Challenge:
- Need for accurate code generation and explanation
- High volume of queries from hundreds of students
- Limited educational budget
Solution with LaoZhang.AI:
- Multi-model strategy based on query complexity
- Gemini 2.5 Flash with thinking for debugging complex issues
- Non-thinking mode for simpler explanations
Results:
- 70% reduction in monthly API costs
- Ability to offer unlimited AI assistance to all students
- Improved learning outcomes with more personalized help
Frequently Asked Questions About Gemini 2.5 Flash and LaoZhang.AI
How does LaoZhang.AI offer lower prices than direct Google API access?
LaoZhang.AI operates as a high-volume aggregator, benefiting from wholesale pricing and technical optimizations that reduce operational costs. These savings are then passed on to end users while maintaining reliable service quality.
Is there any difference in model quality when using Gemini 2.5 Flash through LaoZhang.AI?
No, the model capabilities remain identical to direct API access. LaoZhang.AI functions as a transparent proxy to the original services, maintaining complete model fidelity while adding cost benefits and simplified integration.
What are the rate limits for Gemini 2.5 Flash on LaoZhang.AI?
LaoZhang.AI provides generous rate limits starting at 60 requests per minute for standard accounts, with higher tiers available for enterprise users. These limits often exceed what’s available with entry-level direct API access.
How reliable is LaoZhang.AI’s service for production applications?
LaoZhang.AI maintains a 99.9% uptime SLA for all API services, with redundant connections to underlying model providers and 24/7 monitoring to ensure consistent availability for business-critical applications.
Can I use multiple models together in the same application?
Yes, LaoZhang.AI’s unified API allows seamless switching between different models (Gemini, GPT, Claude, etc.) with minimal code changes, enabling dynamic model selection based on task requirements and budget considerations.
What happens if Google changes Gemini 2.5 Flash pricing?
LaoZhang.AI historically maintains pricing stability even during provider price fluctuations. If underlying costs increase, existing customers typically enjoy a grace period with previous pricing before any adjustments are implemented.
Conclusion: Maximizing ROI with Gemini 2.5 Flash in 2025
Gemini 2.5 Flash represents a significant advancement in AI capabilities, particularly with its innovative thinking mode feature. However, as our analysis demonstrates, direct API access costs can become prohibitive for many use cases, especially when thinking capabilities are required.
LaoZhang.AI offers a compelling solution for developers and businesses looking to leverage Gemini 2.5 Flash’s capabilities while managing costs effectively. With savings of 40-70% compared to direct API access, unified interface across multiple models, and free trial credits to get started, it presents a strategic advantage for AI-powered applications in 2025.
Next Steps to Optimize Your AI API Costs:
- Register for LaoZhang.AI and claim your free trial credits
- Test Gemini 2.5 Flash performance for your specific use cases
- Implement the cost optimization strategies outlined in this guide
- Compare results with your current API solution to quantify savings
By combining LaoZhang.AI’s cost advantages with strategic implementation approaches, you can fully harness the power of Gemini 2.5 Flash while maintaining budget efficiency—ensuring your AI investments deliver maximum returns in 2025 and beyond.