Claude 4.1 Opus Pricing Guide 2025: Complete Cost Analysis & Comparison
Claude Opus 4.1 pricing starts at $15 per million input tokens and $75 per million output tokens for API access, with subscription plans ranging from $20/month for Pro to $200/month for Max 20x usage. As Anthropic’s flagship model achieving industry-leading 74.5% on SWE-bench, Claude Opus commands premium pricing justified by superior coding capabilities and 200K token context window.

What is Claude 4.1 Opus? Industry-Leading AI for Coding
Claude 4.1 Opus represents Anthropic’s most advanced language model, released on August 5, 2025, positioning itself as the premier choice for software engineering and complex reasoning tasks. This hybrid reasoning model combines instant response capabilities with extended step-by-step thinking processes, delivering user-friendly summaries that make sophisticated AI accessible to developers and enterprises alike. The model’s architecture represents a significant evolution from previous iterations, incorporating feedback from millions of enterprise deployments to address real-world limitations while pushing the boundaries of what’s possible with large language models.
The standout achievement of Claude Opus 4.1 lies in its unprecedented 74.5% score on SWE-bench Verified, establishing it as the industry leader for coding tasks and surpassing competitors like GPT-4.1’s 69.1% and Gemini 2.5 Pro’s 63.2%. This performance translates directly into practical capabilities, with the model successfully completing real-world software engineering tasks that previously required human intervention. Organizations report that Claude Opus can handle everything from complex refactoring projects to implementing entire features from specifications, with accuracy rates that justify its premium positioning in the market.
Beyond coding excellence, Claude Opus 4.1 excels in research and analysis tasks, capable of conducting hours of independent investigation across multiple data sources before synthesizing findings into actionable insights. The model’s 200K token context window enables processing of entire codebases, lengthy documents, and multi-file projects without losing coherence or accuracy. This extended context, combined with 32K token output capability, makes Claude Opus particularly valuable for tasks requiring comprehensive understanding and detailed responses, from technical documentation to strategic analysis.
Anthropic’s positioning of Claude Opus within their model family reflects a strategic segmentation approach, with Opus serving power users and enterprises requiring maximum capability regardless of cost. While Claude Sonnet offers excellent value for routine tasks and Haiku provides economical processing for high-volume applications, Opus represents the pinnacle of performance for organizations where accuracy and capability trump cost considerations. This tiered approach ensures organizations can optimize their AI spending while having access to cutting-edge capabilities when needed.
Claude Opus 4.1 API Pricing Structure Explained
The fundamental pricing model for Claude Opus 4.1 API access follows a consumption-based structure with clear differentiation between input and output tokens, reflecting the computational intensity of generating responses versus processing prompts. At $15 per million input tokens, Claude Opus sits at the premium end of the market, approximately 7.5 times more expensive than GPT-4.1’s $2 per million input tokens. However, this pricing reflects the model’s superior performance on complex tasks, with organizations finding the premium justified when accuracy and capability directly impact business outcomes.
Output token pricing at $75 per million tokens represents one of the highest rates in the industry, yet provides exceptional value for tasks requiring detailed, accurate responses. Organizations processing technical documentation, generating comprehensive code implementations, or producing analytical reports find that Claude Opus’s superior output quality reduces the need for human review and iteration, ultimately lowering total project costs despite higher per-token rates. The model’s ability to generate production-ready code and publication-quality content in single passes often eliminates multiple revision cycles required with cheaper alternatives.
Batch processing offers significant cost optimization opportunities, with 50% discounts available for workloads that can tolerate 24-hour turnaround times. This pricing tier proves particularly valuable for organizations processing large document sets, conducting bulk analysis, or generating extensive documentation where immediate responses aren’t critical. Companies report saving hundreds of thousands of dollars annually by intelligently routing appropriate workloads to batch processing, maintaining premium real-time access only for user-facing or time-sensitive applications.
Prompt caching represents the most dramatic cost reduction opportunity, offering up to 90% savings for repeated prompt patterns. Organizations with standardized workflows, template-based applications, or frequent similar queries can reduce effective costs to $1.50 per million cached input tokens. This feature particularly benefits customer service applications, code review systems, and any scenario where consistent prompt structures are used repeatedly. Implementing effective caching strategies has enabled some enterprises to reduce their monthly Claude Opus costs by 60-70% while maintaining full functionality.
Volume pricing tiers, while not publicly disclosed, provide additional savings for enterprise customers processing billions of tokens monthly. Organizations report negotiated rates 20-40% below published prices for commitments exceeding $100,000 monthly, with further discounts available for annual contracts. These enterprise agreements often include additional benefits like dedicated support, custom rate limits, and early access to new features, making them attractive for organizations standardizing on Claude Opus for mission-critical applications.
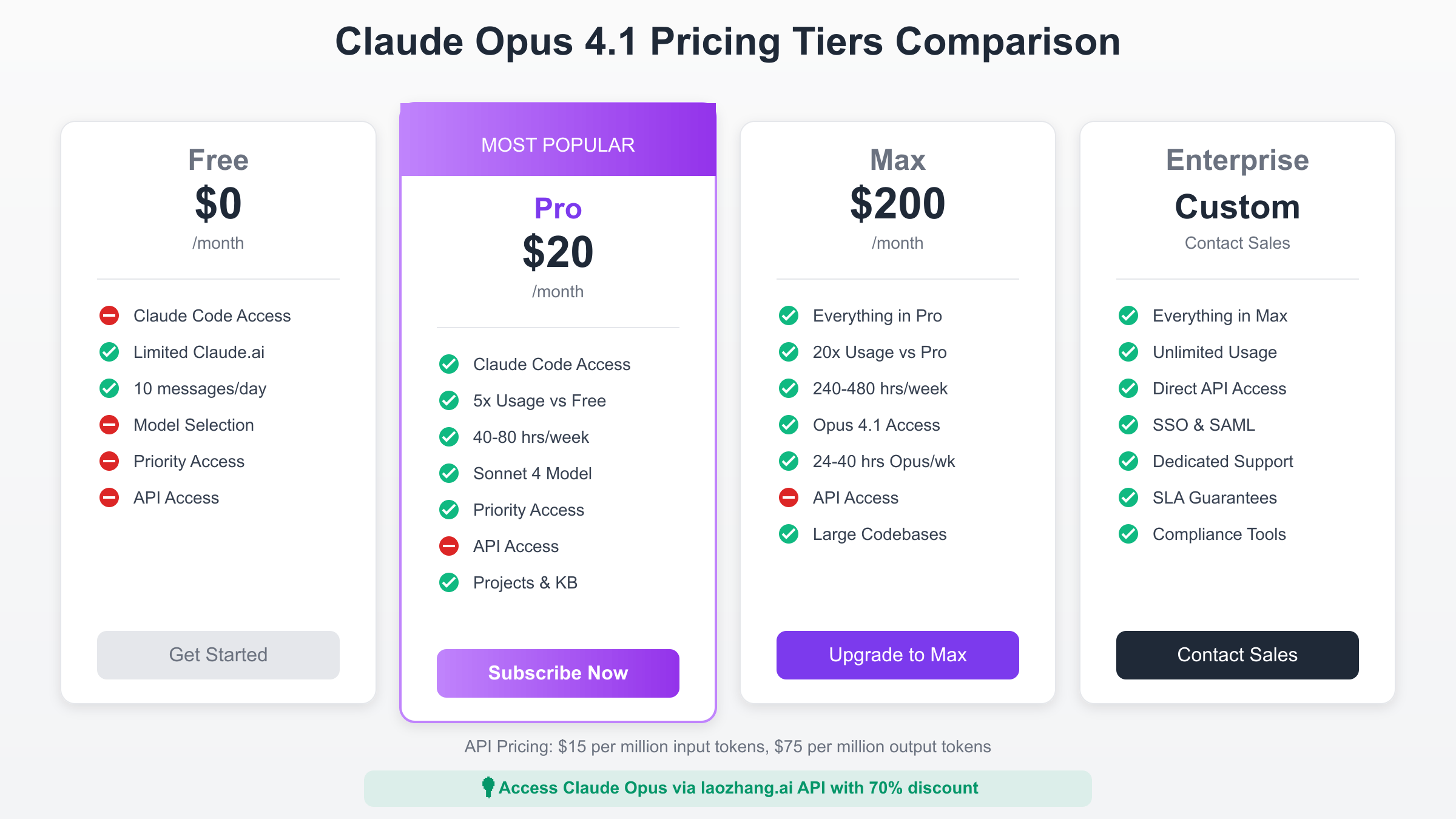
Subscription Plans: Pro, Max, and Enterprise Options
Claude Pro at $20 per month represents the entry point for individual developers and small teams seeking access to Claude’s advanced capabilities without API complexity. This subscription provides approximately 5x the usage of the free tier, translating to roughly 45 messages per 5-hour period when system load is normal. Pro subscribers gain access to Claude Sonnet 4 for general tasks, priority queueing during peak times, and advanced features like Projects and Knowledge Bases that significantly enhance productivity. While Pro plan doesn’t include Claude Opus 4.1 access, it serves as an excellent starting point for evaluating Claude’s capabilities before committing to higher tiers.
The Max 5x plan at $100 monthly targets regular developers and content creators requiring substantially more capacity than Pro tier offers. This plan provides 140-280 hours of Sonnet 4 usage weekly, along with 15-35 hours of Opus 4 access, making it suitable for professionals who rely on AI assistance throughout their workday. The variable usage limits reflect Anthropic’s dynamic capacity management, with actual availability depending on system load and user patterns. Organizations find this tier optimal for individual power users who need consistent access without the complexity of API integration.
Max 20x at $200 monthly represents the premium individual subscription tier, designed for users requiring near-continuous AI assistance and access to Claude Opus 4.1 for demanding tasks. With 240-480 hours of Sonnet 4 and 24-40 hours of Opus 4 weekly capacity, this plan supports intensive development workflows, comprehensive research projects, and continuous content creation. The ability to switch between models using simple commands allows users to optimize cost and performance for each task, using Opus only when its superior capabilities justify the allocation.
Claude Team plans, starting at $30 per user monthly with a five-user minimum, provide collaborative features essential for organizational adoption. Beyond increased usage limits, Team plans include centralized billing, usage analytics, team workspaces, and administrative controls that ensure compliance with corporate policies. The annual discount to $25 per user monthly makes this particularly attractive for established teams, with many organizations reporting that productivity gains justify the investment within the first month of deployment.
Enterprise pricing follows a custom model based on specific organizational requirements, usage patterns, and contract terms. While Anthropic doesn’t publish enterprise rates, organizations report monthly costs ranging from $5,000 for small deployments to over $500,000 for large-scale implementations. Enterprise agreements typically include dedicated support, custom SLAs, on-premise deployment options, and integration assistance that accelerate time to value. Advanced features like single sign-on (SSO), audit logging, and compliance certifications make enterprise plans essential for regulated industries and security-conscious organizations.
Usage Limits and Weekly Quotas: What You Actually Get
Understanding Claude’s usage limit structure requires recognizing the distinction between message counts and actual availability, with limits expressed as ranges reflecting dynamic capacity allocation. Pro plan users receive 40-80 hours of weekly usage, but this translates to different message volumes depending on response length, complexity, and system load. During peak periods, users might exhaust their allocation with 200-300 substantial interactions, while off-peak usage could support 500-800 exchanges. This variability requires users to plan their most important work during traditionally quieter periods like early mornings or weekends.
The two-tier limit system introduced in August 2025 adds complexity but provides flexibility, with separate quotas for overall usage and Opus-specific access. Max plan subscribers must manage both their general allocation and their precious Opus hours, requiring strategic decisions about when premium model access justifies the quota consumption. Users report developing sophisticated workflows that route routine tasks to Sonnet while reserving Opus for complex code generation, difficult debugging sessions, or critical analysis where accuracy is paramount.
Rate limiting within five-hour windows prevents quota exhaustion through burst usage while ensuring fair access across all users. Pro users might encounter limits after 10-40 prompts in concentrated sessions, forcing breaks that, while sometimes frustrating, prevent individual users from monopolizing resources. These micro-limits reset continuously, meaning users who pace their interactions throughout the day rarely encounter restrictions. Understanding these patterns enables users to structure their workflows for maximum productivity within the system’s constraints.
Weekly quota resets occur on rolling seven-day windows rather than calendar weeks, providing consistent availability without artificial deadline pressure. This approach means users who exhaust their limits on Tuesday will see gradual restoration throughout the following Tuesday, rather than waiting for a Sunday night reset. The gradual restoration model encourages consistent usage patterns rather than boom-bust cycles that stress infrastructure and degrade service quality for all users.
Claude Opus vs GPT-4 vs Gemini Pro: Price-Performance Analysis
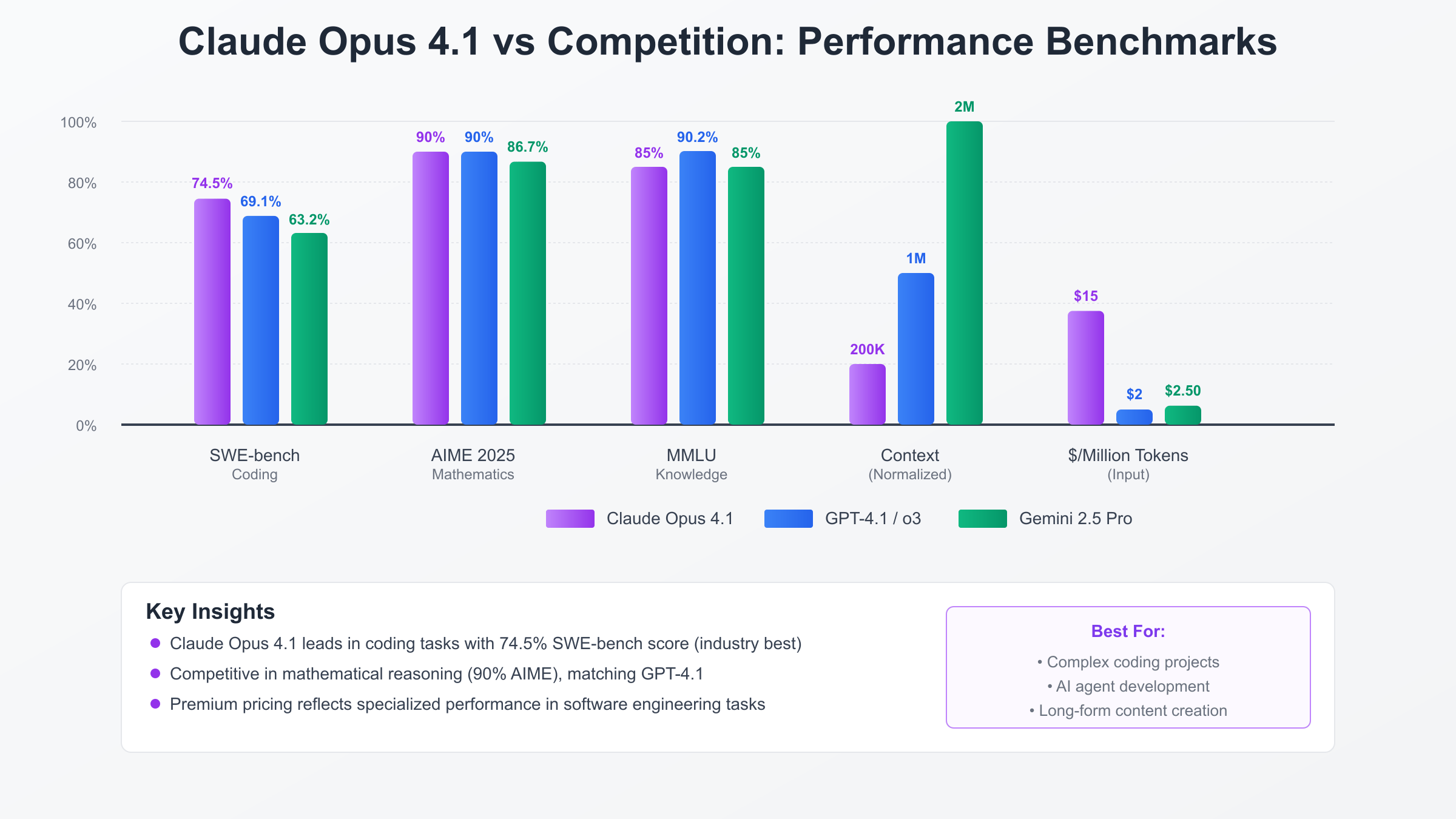
The pricing landscape for premium language models reveals stark differences in positioning, with Claude Opus 4.1 commanding significant premiums that reflect its specialized capabilities. At $15/$75 per million tokens for input/output, Claude Opus costs 7.5x more than GPT-4.1’s $2/$8 pricing and 12x more than Gemini 2.5 Pro’s $1.25/$10 structure. However, raw pricing comparisons fail to capture the nuanced value proposition each model provides, with performance differentials often justifying premium pricing for specific use cases.
Performance benchmarking across multiple dimensions shows Claude Opus’s premium pricing aligns with superior capabilities in critical areas. The 74.5% SWE-bench score represents a 8% advantage over GPT-4.1 and 18% over Gemini Pro, translating to successfully completing complex coding tasks that competitors fail to handle. For organizations where developer productivity improvements of even 10% justify significant investment, Claude Opus’s premium pricing becomes economically rational. The model’s superior performance on multi-step reasoning and long-context tasks further differentiates it from alternatives.
Context window comparisons reveal interesting trade-offs between the competitors, with Gemini 2.5 Pro’s 2 million token window dwarfing Claude’s 200K and GPT-4’s 1 million token capacity. However, practical usage patterns show that Claude Opus maintains superior coherence and accuracy within its 200K window, while competitors often degrade in performance when approaching their theoretical limits. Organizations report that Claude Opus’s reliable performance across its entire context window proves more valuable than theoretically larger but practically limited alternatives.
Mathematical reasoning capabilities show closer parity among top models, with Claude Opus, GPT-4.1, and Gemini Pro all achieving approximately 90% on AIME 2025 benchmarks. This convergence suggests that for purely analytical tasks, model selection should prioritize cost efficiency unless other factors like API compatibility, regional availability, or existing vendor relationships influence the decision. The marginal performance differences in mathematical domains rarely justify Claude Opus’s premium pricing solely for computational tasks.
Real-world deployment experiences reveal that total cost of ownership extends beyond per-token pricing, with factors like response consistency, integration complexity, and support quality significantly impacting overall value. Organizations report that Claude Opus’s superior reliability and consistency reduce development time and debugging efforts, often offsetting higher API costs. The model’s lower hallucination rates and more predictable behavior patterns translate to reduced quality assurance requirements and faster time to production for AI-powered features.
Real-World Cost Scenarios: Calculate Your Monthly Spend
Individual developers working on personal projects typically process 10-50 million tokens monthly through conversational interactions, code generation, and debugging assistance. At Claude Opus API rates, this translates to $150-750 for input tokens and $750-3,750 for output tokens, making direct API access prohibitively expensive for most individuals. The Pro subscription at $20 monthly provides sufficient capacity for casual users, while serious developers find the Max 5x plan at $100 monthly offers the sweet spot between capability and cost. Smart routing between Sonnet for routine tasks and Opus for complex challenges enables developers to stay within budget while accessing premium capabilities when needed.
Small development teams of 5-10 members face monthly costs ranging from $1,500 to $15,000 depending on usage intensity and task complexity. A typical scenario involves each developer processing 20 million tokens monthly, with 70% routed to Claude Sonnet and 30% requiring Opus capabilities. This usage pattern results in approximately $3,000 monthly API costs, making the Team subscription at $150-300 monthly significantly more economical. However, teams requiring API integration for automated workflows often find hybrid approaches optimal, using subscriptions for interactive development and APIs for production systems.
Enterprise deployments processing billions of tokens monthly for customer service, content generation, or analysis face potential costs exceeding $100,000 monthly at published rates. A financial services firm processing 2 billion tokens monthly for document analysis would face $30,000 in input costs and $150,000 in output costs at standard pricing. However, enterprise agreements typically reduce these costs by 30-40%, while intelligent routing to appropriate models and aggressive caching can further reduce expenses by 50-60%. The resulting $50,000-70,000 monthly investment often generates millions in value through improved efficiency and capability.
Startup scenarios require careful cost optimization to balance capability needs with budget constraints. A typical AI-first startup might budget $5,000-10,000 monthly for language model costs, requiring strategic decisions about model selection and usage patterns. Successful startups report using Claude Opus exclusively for core differentiating features while routing commodity tasks to cheaper alternatives. This approach enables access to cutting-edge capabilities where they matter most while maintaining reasonable burn rates. The ability to scale spending with revenue growth makes consumption-based pricing attractive despite higher unit costs.
Hidden costs beyond raw API charges significantly impact total spending, including development time for integration, monitoring infrastructure, error handling, and failover systems. Organizations typically allocate 20-30% above API costs for supporting infrastructure and engineering resources. Additionally, the opportunity cost of using inferior models must be considered – while GPT-4 might cost 85% less, if it requires 50% more iterations to achieve acceptable results, the total cost may exceed Claude Opus. These holistic calculations often reveal that premium models provide superior value despite higher sticker prices.
Access Options: Direct API, AWS Bedrock, Google Vertex
Direct API access through Anthropic’s platform provides the most straightforward integration path, with comprehensive documentation, SDKs in multiple languages, and responsive support for technical issues. The tier system starting at $5 deposit makes initial experimentation accessible, while automatic tier upgrades based on payment history eliminate bureaucratic friction as usage scales. Organizations appreciate the transparent billing, detailed usage analytics, and ability to set spending limits that prevent unexpected charges. Direct API access also ensures immediate availability of new features and model updates, critical for organizations pushing the boundaries of AI capabilities.
Amazon Bedrock integration brings Claude Opus into the AWS ecosystem, enabling organizations to leverage existing AWS infrastructure, security controls, and billing relationships. The fully managed service eliminates operational overhead while providing enterprise features like VPC endpoints, AWS PrivateLink, and IAM integration that satisfy stringent security requirements. Bedrock’s unified API across multiple model providers simplifies multi-model strategies, though the abstraction layer can introduce minor latency overhead. Pricing remains consistent with direct API access at $15/$75 per million tokens, with AWS credits and enterprise agreements potentially reducing effective costs.
Google Cloud Vertex AI’s general availability of Claude models since May 2025 provides another enterprise-grade deployment option, particularly attractive for organizations already invested in Google Cloud Platform. Vertex AI’s integration with Google’s data and ML ecosystem enables sophisticated workflows combining Claude Opus with BigQuery, Dataflow, and other GCP services. The platform’s emphasis on MLOps best practices, including model monitoring, versioning, and A/B testing capabilities, appeals to organizations requiring production-grade AI deployments. Pricing parity with other platforms ensures decisions focus on technical fit rather than cost considerations.
Regional availability considerations significantly impact platform selection, with direct API access providing the broadest coverage while cloud platforms may have geographic restrictions. European organizations particularly value Bedrock’s eu-central-1 deployment for data residency compliance, while Asian enterprises often find Google Cloud’s extensive regional presence advantageous. Network latency differences of 50-200ms between regions might seem trivial but compound in high-volume applications, making regional deployment options critical for latency-sensitive use cases.
Performance Benchmarks: Is Claude Opus Worth the Premium?
Comprehensive performance analysis across diverse benchmarks reveals Claude Opus 4.1’s strengths align closely with its premium pricing strategy, excelling in areas where accuracy and capability directly impact business value. The model’s 74.5% SWE-bench Verified score represents more than abstract benchmark superiority – it translates to successfully completing complex refactoring tasks, implementing sophisticated features from specifications, and debugging intricate issues that other models fail to resolve. For organizations where developer productivity improvements of 20-30% are achievable through AI assistance, Claude Opus’s premium pricing becomes a sound investment with rapid ROI.
Mathematical reasoning performance at 90% on AIME 2025 matches top competitors, demonstrating that Claude Opus competes effectively in analytical domains despite its coding focus. The model’s approach to mathematical problems shows sophisticated multi-step reasoning, with particular strength in problems requiring creative insight rather than mere computation. Financial firms utilizing Claude Opus for quantitative analysis report accuracy improvements in model validation, risk assessment, and algorithmic trading strategies that justify premium pricing through reduced errors and enhanced decision-making.
Creative writing and content generation capabilities position Claude Opus as the preferred choice for organizations requiring publication-quality output with minimal human editing. The model’s prose flows naturally, maintains consistent voice across long documents, and demonstrates remarkable ability to adapt tone and style to specific requirements. Publishing houses and content agencies report that Claude Opus reduces editing time by 60-70% compared to other models, with some outputs requiring only minor formatting adjustments before publication.
Research and analysis capabilities showcase Claude Opus’s ability to synthesize information from multiple sources, identify patterns, and generate actionable insights that rival human analysts. The model’s performance on complex research tasks, from market analysis to scientific literature review, demonstrates understanding that transcends simple pattern matching. Consulting firms report that Claude Opus can complete preliminary research tasks in hours that previously required days of junior analyst time, fundamentally changing project economics and delivery timelines.
Best Use Cases for Claude Opus 4.1
Software development workflows represent the optimal use case for Claude Opus 4.1, with the model’s superior coding capabilities justifying premium pricing through dramatic productivity improvements. Development teams report that Claude Opus can implement complete features from specifications, refactor legacy codebases, and debug complex issues with accuracy approaching senior developers. The model’s understanding of software architecture, design patterns, and best practices enables it to generate production-quality code that requires minimal review. Organizations standardizing on Claude Opus for development assistance report 30-40% improvements in feature delivery velocity.
AI agent creation leverages Claude Opus’s exceptional reasoning capabilities and extended context window to build sophisticated autonomous systems. The model’s ability to maintain coherence across complex, multi-step workflows makes it ideal for creating agents that handle customer service, process automation, or decision support tasks. Enterprises building AI agents with Claude Opus report success rates 25-30% higher than alternatives, with reduced hallucination and more reliable performance in production environments. The premium pricing becomes negligible compared to the value generated by successful agent deployments.
Long-form content generation for technical documentation, research reports, and strategic analysis showcases Claude Opus’s ability to maintain quality and coherence across extended outputs. The 32K token output capability enables generation of comprehensive documents without the fragmentation common with other models. Professional services firms utilizing Claude Opus for report generation reduce document preparation time by 70% while improving consistency and completeness. The model’s ability to incorporate feedback and iterate on drafts further enhances its value for content-intensive workflows.
Code review and security analysis applications leverage Claude Opus’s deep understanding of programming languages and security best practices to identify vulnerabilities and suggest improvements. The model’s performance in detecting subtle bugs, security flaws, and optimization opportunities rivals specialized static analysis tools while providing natural language explanations that accelerate remediation. Security teams report that Claude Opus identifies 15-20% more issues than traditional tools while reducing false positives by 40%, justifying premium pricing through improved security posture.
Cost Optimization Strategies for Claude Opus
Prompt caching implementation represents the most impactful optimization strategy, potentially reducing costs by 90% for applications with repetitive prompt patterns. Organizations should identify common prompt templates, system instructions, and context documents that appear frequently across requests. Implementing a caching layer that recognizes and reuses these patterns can reduce a $10,000 monthly bill to $2,000 for suitable workloads. The key lies in designing applications around cacheable patterns without sacrificing flexibility or functionality.
Model routing strategies that intelligently direct requests to appropriate models based on task complexity can reduce costs by 60-70% while maintaining quality. Simple queries and routine tasks should route to Claude Haiku or Sonnet, reserving Opus for genuinely complex challenges requiring its superior capabilities. Implementing classification systems that accurately predict task difficulty enables automatic routing that optimizes cost without user intervention. Organizations report that only 20-30% of requests genuinely require Opus-level capabilities, making routing essential for cost control.
Batch processing optimization for non-time-sensitive workloads unlocks 50% discounts that significantly impact bottom-line costs. Organizations should architect systems to accumulate suitable requests for batch processing, such as document analysis, report generation, or data extraction tasks. Implementing queue management systems that intelligently batch requests while meeting SLA requirements requires initial investment but generates substantial ongoing savings. Companies processing millions of documents monthly report savings exceeding $50,000 through effective batch utilization.
Response length optimization through precise prompting and output constraints prevents unnecessary token consumption that inflates costs without adding value. Instructing Claude Opus to provide concise responses, use bullet points where appropriate, and avoid redundancy can reduce output tokens by 30-40% without sacrificing information content. Implementing post-processing systems that extract essential information from verbose outputs enables cost reduction while maintaining compatibility with existing workflows.
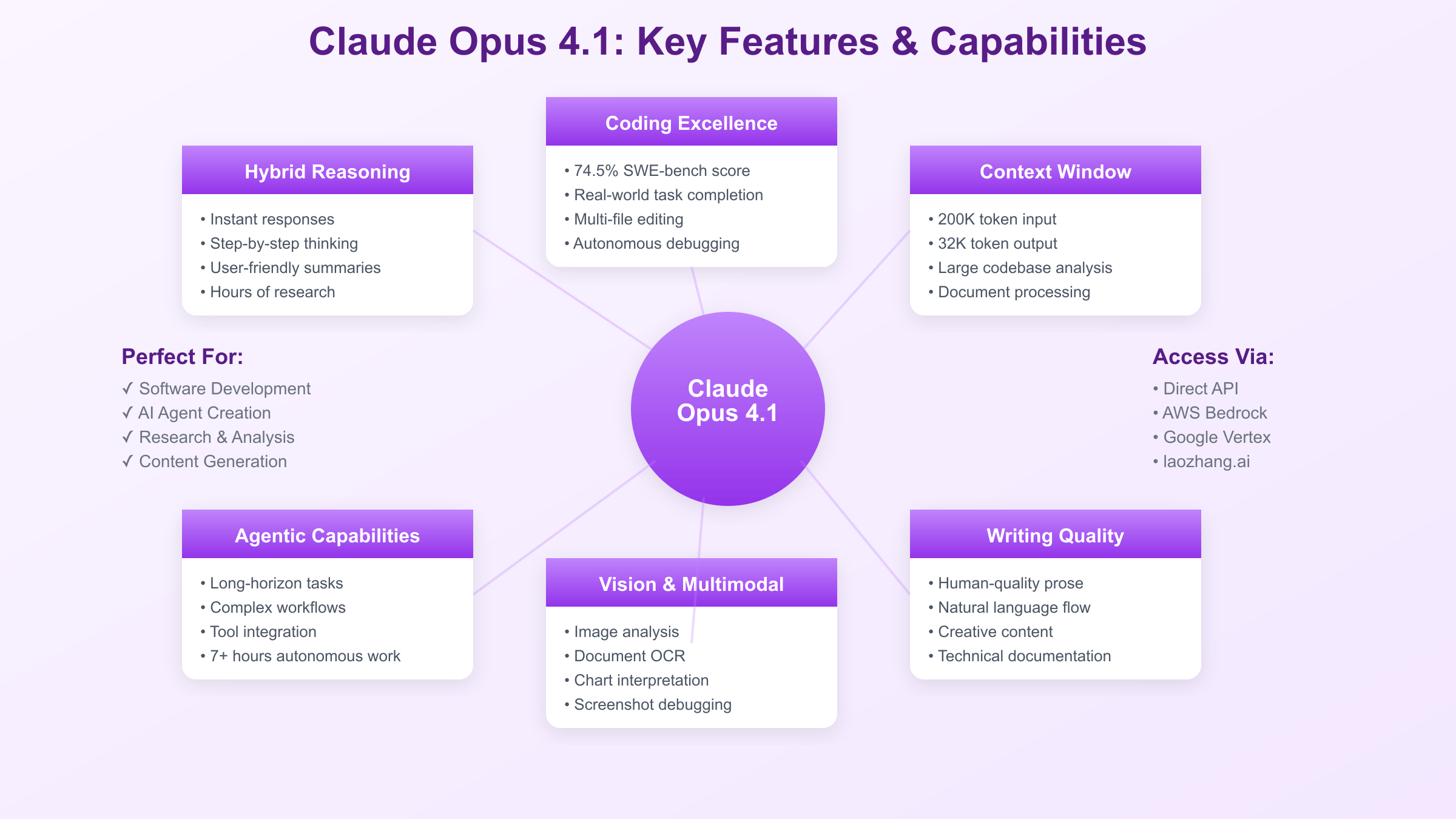
Alternative Access: API Aggregators and Cost Savings
API aggregator services provide an attractive alternative for organizations seeking Claude Opus capabilities without direct vendor relationships or long-term commitments. Services like laozhang.ai offer access to Claude Opus alongside other premium models through unified APIs, reducing integration complexity while providing cost advantages through bulk purchasing power. The 70% discount offered by laozhang.ai transforms Claude Opus from premium luxury to accessible tool, with effective rates of $4.50 per million input tokens making it competitive with mid-tier alternatives.
Multi-model strategies enabled by aggregator services allow organizations to optimize cost and performance dynamically without maintaining multiple vendor relationships. The ability to seamlessly switch between Claude Opus, GPT-4, and other models based on task requirements, cost constraints, or availability ensures optimal resource utilization. Organizations report that unified billing, consistent APIs, and centralized usage analytics simplify financial management and technical integration compared to managing multiple direct relationships.
Free trial offerings and credit systems from services like laozhang.ai enable comprehensive evaluation before financial commitment, with $1 in free credits sufficient to process approximately 100K input tokens or 20K output tokens. This generous trial allocation allows thorough testing across diverse use cases, building confidence in model capabilities and integration patterns. The referral code system providing additional credits further reduces barrier to entry, enabling extended evaluation periods that ensure successful adoption.
Migration considerations from direct API access to aggregator services involve evaluating trade-offs between cost savings and potential limitations. While aggregators offer significant discounts, they may introduce additional latency, have different rate limits, or lack access to cutting-edge features immediately upon release. Organizations must assess whether 70% cost savings justify potential constraints, with many finding that aggregator services provide optimal value for production workloads while maintaining direct access for development and experimentation.
Enterprise Adoption: Market Share and Trends
Market dynamics in enterprise AI adoption show Anthropic’s remarkable growth trajectory, with market share doubling from 12% to 24% between 2024 and 2025 while OpenAI’s dominance eroded from 50% to 34%. This shift reflects growing enterprise appreciation for Claude’s strengths in coding, reasoning, and reliability, with many organizations standardizing on Anthropic for mission-critical applications. The trend accelerates as successful deployments generate case studies that encourage broader adoption, creating network effects that reinforce Anthropic’s position.
Industry-specific adoption patterns reveal interesting preferences, with financial services and healthcare organizations particularly drawn to Claude Opus’s combination of capability and compliance features. Banks utilizing Claude Opus for risk analysis and regulatory reporting appreciate the model’s accuracy and consistency, while healthcare providers value its ability to process complex medical information while maintaining appropriate caution. These regulated industries’ adoption validates Claude Opus’s enterprise readiness and encourages broader deployment across sectors.
Competitive dynamics between AI providers intensify as enterprises demand more sophisticated capabilities, better reliability, and improved cost-efficiency. Anthropic’s focus on safety and reliability resonates with enterprise buyers concerned about AI risks, while the company’s transparent approach to model limitations builds trust. The emergence of specialized models optimized for specific industries or use cases suggests future differentiation will focus on vertical solutions rather than purely horizontal capability improvements.
Future pricing predictions based on historical trends and competitive dynamics suggest continued premium pricing for cutting-edge models while commodity capabilities become increasingly affordable. Industry analysts expect Claude Opus pricing to remain stable through 2025 as demand growth matches capacity expansion, with potential price reductions in 2026 as competition intensifies and infrastructure costs decline. Organizations planning long-term AI strategies should model scenarios ranging from 20% annual price decreases to 10% increases, ensuring financial flexibility regardless of market evolution.