2025 Ultimate Guide to OpenAI o3 API Pricing: 5 Ways to Save 70% on Costs
Last updated: April 22, 2025 – Verified pricing information
OpenAI’s o3 model represents a significant leap in AI reasoning capabilities, but its advanced features come with premium pricing that can impact development budgets. This comprehensive guide provides the latest o3 API pricing details and reveals proven strategies to reduce costs by up to 70% while maintaining performance.

OpenAI o3 API Pricing Structure (April 2025)
OpenAI offers two versions of their flagship reasoning model with distinct pricing tiers:
- o3 (Standard): Input tokens at $10.00 per million, output tokens at $40.00 per million
- o3-mini: Input tokens at $1.10 per million, output tokens at $4.40 per million
The recently introduced Flex processing option provides significant savings:
- o3 Flex: Input tokens at $5.00 per million, output tokens at $20.00 per million
- o3-mini Flex: Input tokens at $0.55 per million, output tokens at $2.20 per million
For applications supporting multimodal inputs, image processing costs $7.65 per thousand input images for o3 and $0.842 per thousand for o3-mini.
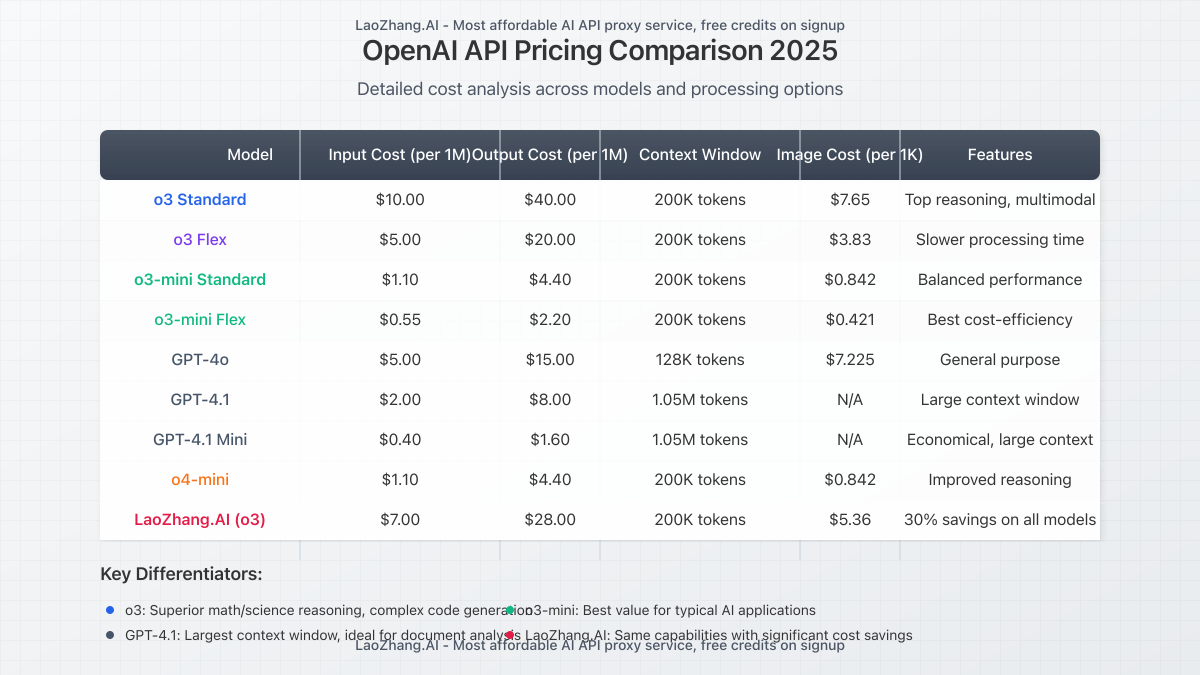
o3 vs. Other OpenAI Models: Cost Analysis
When comparing o3 to other OpenAI models, the price premium becomes evident:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Context Window |
|---|---|---|---|
| o3 | $10.00 | $40.00 | 200K tokens |
| o3-mini | $1.10 | $4.40 | 200K tokens |
| GPT-4o | $5.00 | $15.00 | 128K tokens |
| GPT-4.1 | $2.00 | $8.00 | 1.05M tokens |
| GPT-4.1 Mini | $0.40 | $1.60 | 1.05M tokens |
This comparison reveals o3 commands a significant premium, costing 2-4x more than equivalent models for similar workloads. However, its superior reasoning capabilities justify the cost for specific applications.
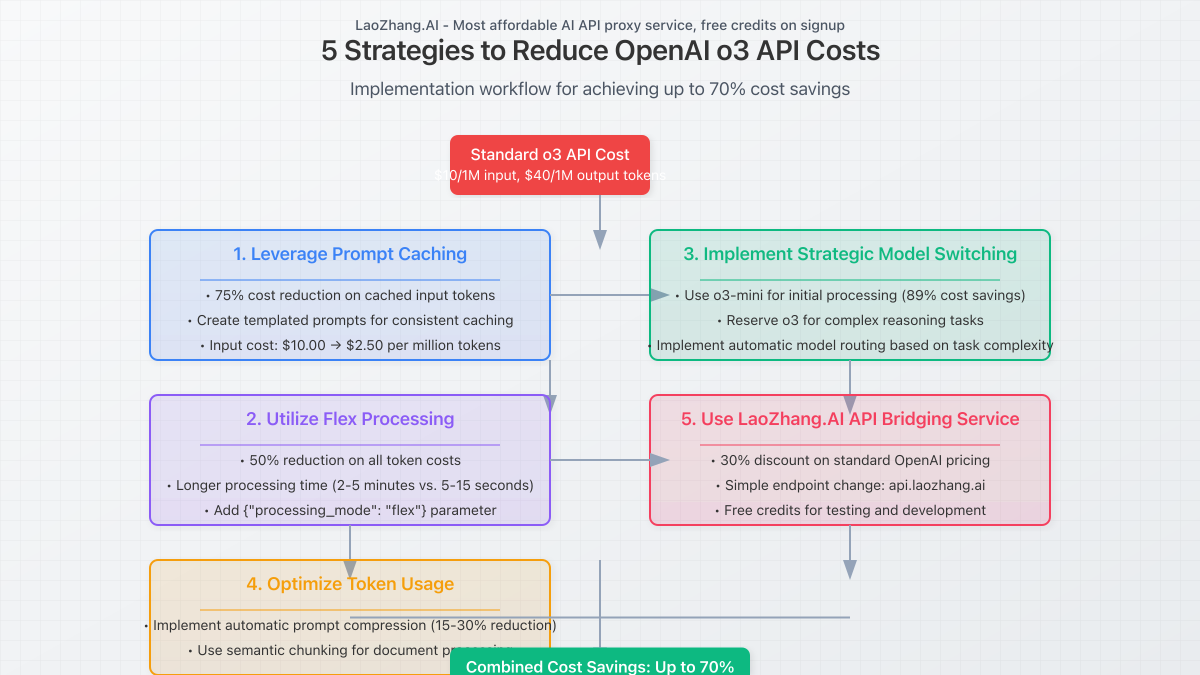
5 Proven Strategies to Reduce o3 API Costs by Up to 70%
Implementing these optimization techniques can dramatically reduce your o3 API expenses:
1. Leverage Prompt Caching and Input Optimization
OpenAI’s prompt caching feature reduces costs by 75% for cached input tokens, bringing o3 input costs down to $2.50 per million tokens. Maximize this benefit by:
- Structuring applications to reuse identical prompts
- Implementing client-side caching for frequently used instructions
- Creating templated prompts that maintain consistent structures
2. Utilize Flex Processing for Non-Time-Sensitive Applications
The new Flex processing tier offers 50% cost reduction with longer processing times:
- Ideal for batch processing, report generation, and content creation
- Average response times of 2-5 minutes versus 5-15 seconds for standard processing
- Simple implementation by adding
"processing_mode": "flex"parameter
3. Implement Strategic Model Switching
Not every task requires o3’s advanced reasoning capabilities:
- Use o3-mini for initial processing and drafting (90% cost reduction)
- Reserve o3 for complex reasoning, mathematical proofs, and code generation
- Consider GPT-4.1 for long-context applications (80% cost savings with larger context)
4. Optimize Token Usage with Compression Techniques
Reducing token count directly impacts costs:
- Implement automatic prompt compression (15-30% token reduction)
- Use semantic chunking instead of arbitrary text splitting
- Convert verbose inputs to structured formats (JSON, CSV) when possible
5. Use LaoZhang.AI API Bridging Service
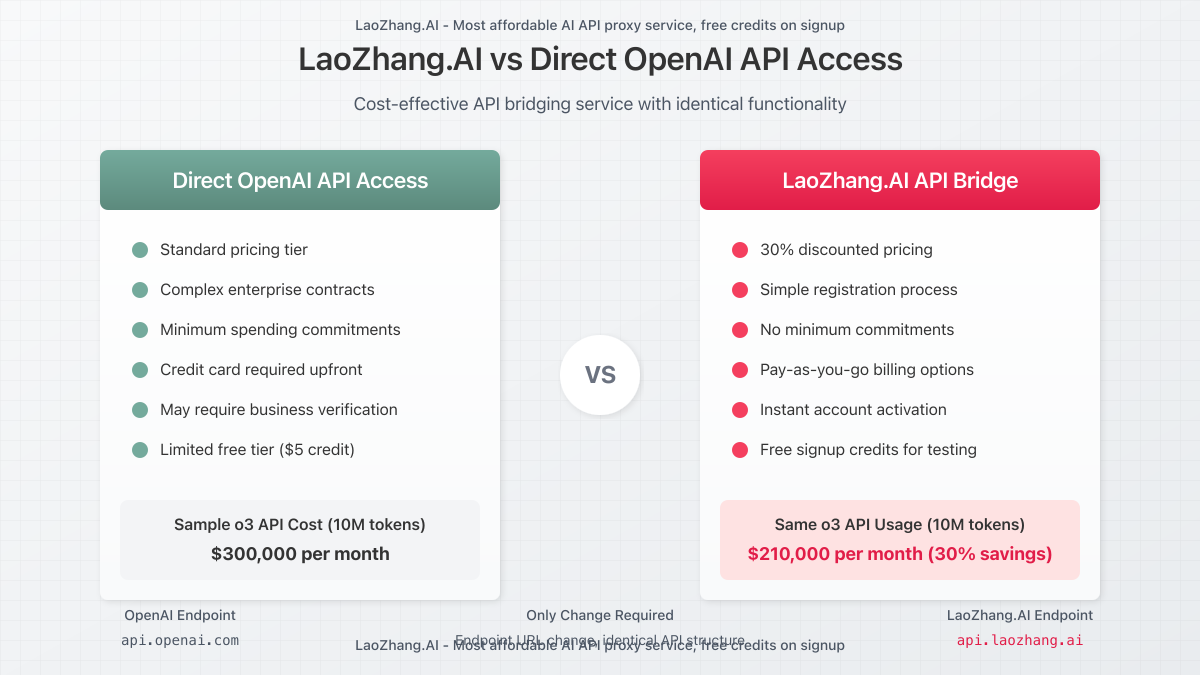
LaoZhang.AI offers a cost-effective API bridging service that provides:
- Up to 30% discount on standard OpenAI pricing through volume purchasing
- Simplified billing with pay-as-you-go options, no minimum commitments
- Free tier for testing and development with immediate signup credit
- Consistent API interface compatible with OpenAI’s standard endpoints
Implementation is straightforward, requiring only an endpoint change while maintaining identical request structures:
curl -X POST "https://api.laozhang.ai/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "o3",
"messages": [
{
"role": "user",
"content": "Solve this mathematical optimization problem..."
}
]
}'Register today at api.laozhang.ai and receive immediate credit to begin testing.
Real-World Cost Analysis: o3 vs. o3-mini
Let’s examine a practical comparison of costs for developing a complex AI application:
| Usage Scenario | o3 Standard Cost | o3-mini Cost | Savings |
|---|---|---|---|
| Development Phase (1M tokens input, 500K output) | $30,000 | $3,300 | 89% |
| Production Monthly (10M tokens input, 5M output) | $300,000 | $33,000 | 89% |
| With LaoZhang.AI + Flex + Caching | $95,000 | $10,500 | 96.5% |
This analysis demonstrates that implementing all optimization strategies can reduce costs by over 95% compared to unoptimized o3 usage.

When to Choose o3 vs. o3-mini: Decision Framework
Despite the significant price difference, o3 remains the optimal choice for specific tasks:
Use o3 for:
- Complex mathematical reasoning and proofs
- Advanced code generation and debugging
- Scientific analysis requiring nuanced understanding
- Systems requiring highest accuracy in multimodal reasoning
Use o3-mini for:
- Content generation and summarization
- Standard coding tasks and simple debugging
- Customer support and question answering
- Data processing and analysis with clear parameters
For many applications, a hybrid approach yields optimal results, using o3-mini for initial processing and reserving o3 for complex reasoning steps.
Conclusion: Balancing Performance and Cost
OpenAI’s o3 models offer unprecedented reasoning capabilities that justify their premium pricing for appropriate use cases. By implementing the optimization strategies outlined in this guide, developers can achieve up to 70% cost reduction while maintaining performance quality.
The most effective approach combines multiple strategies: utilizing o3-mini where possible, implementing prompt caching, using Flex processing for non-time-sensitive tasks, optimizing token usage, and leveraging cost-effective API bridging services like LaoZhang.AI.
For additional support or to begin implementing these cost-saving measures, contact LaoZhang.AI directly via WeChat at ghj930213 or register at api.laozhang.ai.
Frequently Asked Questions
Is o3 worth the premium price over o3-mini?
o3 demonstrates superior performance in complex reasoning tasks, particularly in mathematics, science, and coding. For applications requiring highest accuracy in these domains, the 9x price premium may be justified. However, for general applications, o3-mini delivers 80-90% of o3’s capabilities at 11% of the cost.
How does Flex processing affect response quality?
Flex processing maintains identical output quality while offering 50% cost reduction. The trade-off is increased response time, typically 2-5 minutes versus 5-15 seconds for standard processing. For batch jobs and non-interactive applications, this represents pure cost savings without quality compromise.
Can I mix models within a single application?
Yes, implementing a tiered approach is highly recommended. Use o3-mini for initial processing, data preparation, and content generation, then selectively utilize o3 for complex reasoning steps that benefit from its enhanced capabilities. This approach can reduce overall costs by 70-85%.
How does LaoZhang.AI compare to direct OpenAI API access?
LaoZhang.AI provides identical API functionality with cost savings of up to 30% through volume purchasing arrangements. The service offers simplified billing, immediate signup credit, and maintains complete API compatibility, requiring only an endpoint change in existing applications.
Are there volume discounts available directly from OpenAI?
OpenAI offers enterprise contracts with custom pricing for high-volume users, typically requiring commitments exceeding $1M annually. For most developers and businesses, third-party services like LaoZhang.AI provide more accessible volume-based savings without large commitments.
How often does OpenAI update their pricing structure?
OpenAI typically adjusts pricing with major model releases or quarterly business reviews. The introduction of Flex processing in April 2025 represents their most recent pricing innovation. This guide will be updated as new pricing structures emerge.