OpenAI’s GPT-4o has revolutionized the AI landscape with its exceptional performance and multimodal capabilities. As developers and businesses integrate this powerful model into their applications, understanding its pricing structure becomes crucial for cost management. This comprehensive guide breaks down GPT-4o pricing, compares it with alternatives, and provides actionable strategies to optimize your API expenses.

GPT-4o Pricing Structure: What You Need to Know
GPT-4o uses a token-based pricing model, where costs are calculated separately for input (prompts) and output (responses). As of May 2024, the official pricing stands at:
- Input tokens: $2.50 per million tokens
- Output tokens: $10.00 per million tokens
- Cached input: $1.25 per million tokens (50% discount)
For context, tokens are pieces of text that the model processes, with approximately 750 words equaling 1,000 tokens. The 128K context window of GPT-4o allows for processing up to 128,000 tokens in a single request, making it suitable for complex, data-rich applications.
GPT-4o vs. Other OpenAI Models: Price Comparison
When evaluating GPT-4o’s cost-effectiveness, it’s essential to compare it with other available models:
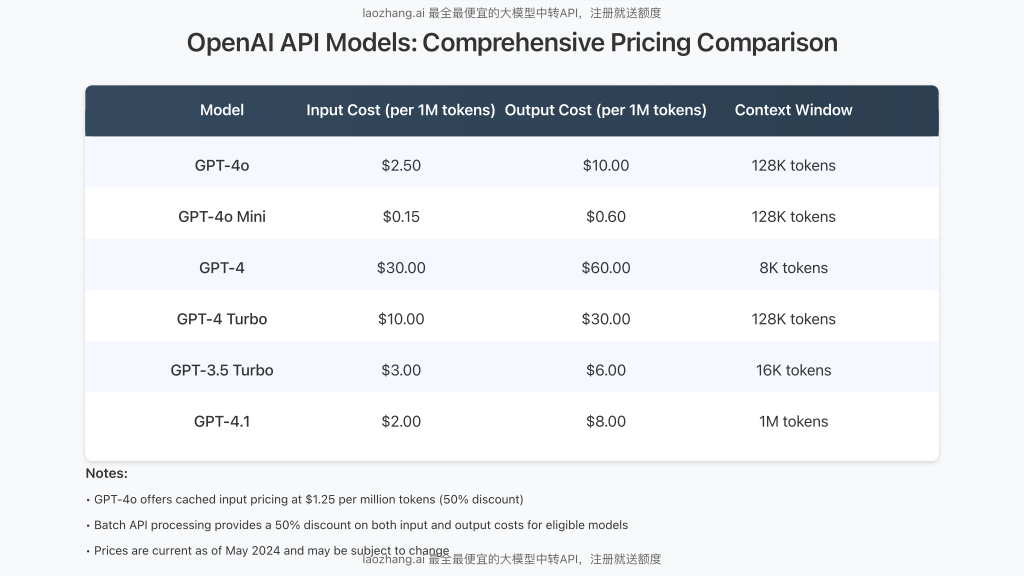
GPT-4o represents a significant price reduction compared to the original GPT-4, which costs $30.00 per million input tokens and $60.00 per million output tokens. Even GPT-4 Turbo at $10.00/$30.00 per million tokens is considerably more expensive.
For budget-conscious applications, GPT-4o Mini deserves special attention. At just $0.15 per million input tokens and $0.60 per million output tokens, it offers remarkable value while maintaining impressive capabilities and the same 128K context window as its larger counterpart.
GPT-4o vs. GPT-4.1: Latest Model Comparison
OpenAI’s newest model, GPT-4.1, offers a slightly lower price point at $2.00 per million input tokens and $8.00 per million output tokens, with a massive 1 million token context window. However, GPT-4o still excels in multimodal tasks with vision capabilities that may justify its slightly higher cost for specific use cases.
5 Proven Strategies to Optimize GPT-4o API Costs
Implementing the following optimization techniques can significantly reduce your GPT-4o API expenses:

1. Strategic Model Selection
Choose the appropriate model based on your specific requirements:
- Use GPT-4o for complex tasks requiring advanced reasoning, multimodal capabilities, or when output quality is critical
- Switch to GPT-4o Mini for simpler tasks, content generation, or when budget constraints are primary concerns
- Implement adaptive model selection that automatically selects the appropriate model based on the complexity and requirements of each query
2. Implement Caching for Repeated Inputs
Take advantage of OpenAI’s cached input pricing to reduce costs by 50%:
- Store and reuse frequently submitted prompts to leverage the $1.25 per million tokens cached input rate
- Implement client-side caching for common queries and responses
- Use consistent system messages across multiple requests to benefit from caching
3. Optimize Prompt Engineering
Refine your prompts to reduce token consumption:
- Create concise, specific instructions that minimize input token count
- Use the
max_tokensparameter to limit response length - Structure multi-turn conversations efficiently to avoid redundant context
- Remove unnecessary details, formatting, and repetitive information
4. Utilize Batch Processing
For non-time-sensitive applications, batch API processing offers a 50% discount on both input and output costs:
- Group similar requests together for bulk processing
- Schedule batch processing during off-peak hours
- Implement a queuing system for non-urgent requests
5. Implement Robust Monitoring and Analytics
Track and analyze your API usage to identify optimization opportunities:
- Monitor token consumption by endpoint, feature, and user
- Set up alerts for unusual usage patterns or cost spikes
- Regularly review and optimize high-volume or costly API calls
- Consider implementing rate limiting for fair usage across users
Real-World Cost Estimates for Common Applications
To put GPT-4o pricing into perspective, here are estimated costs for typical use cases:

Customer Support Automation
For a customer support chatbot handling approximately 1,000 queries per day:
- Average tokens per query: ~1,000 (250 input, 750 output)
- Daily cost with GPT-4o: ~$13.00
- Daily cost with GPT-4o Mini: ~$0.90
- Potential monthly savings: Up to $360 by using GPT-4o Mini for tier-1 support
Content Generation
For a platform generating 100 articles or product descriptions daily:
- Average tokens per article: ~2,500 (500 input, 2,000 output)
- Daily cost with GPT-4o: ~$3.10
- Daily cost with GPT-4o Mini: ~$0.22
- Additional optimization: Implement batching for another 50% reduction
Coding Assistant
For a development team using AI for code generation and review:
- Average tokens per session: ~4,000 (1,000 input, 3,000 output)
- Cost per session with GPT-4o: ~$0.050
- Cost per session with GPT-4o Mini: ~$0.0036
- Monthly cost for 50 developers: $9-$125 depending on model choice and usage intensity
API Integration: Accessing GPT-4o Through LaoZhang.AI
While direct OpenAI API access remains the standard option, cost-conscious developers should consider LaoZhang.AI, a unified API gateway offering competitive pricing for GPT-4o, Claude, and Gemini models. This service provides:
- Simplified access to multiple AI models through a standardized API
- Free token credits for new users to test functionality
- Straightforward integration using the familiar OpenAI API format
Here’s a basic example of how to access GPT-4o via LaoZhang.AI:
curl -X POST "https://api.laozhang.ai/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "Summarize the key features of GPT-4o pricing"
}
]
}'Planning for the Future: Long-Term Cost Management
As AI technology evolves, consider these strategies for sustainable cost management:
- Hybrid approach: Combine GPT-4o for complex tasks with GPT-4o Mini for routine operations
- Fine-tuning evaluation: Assess whether fine-tuning smaller models might deliver comparable results at lower costs
- Regular model reassessment: Stay informed about new model releases and pricing changes
- Usage-based scaling: Implement dynamic model selection based on actual usage patterns and ROI
Conclusion: Maximizing GPT-4o Value
GPT-4o represents a significant advancement in AI capabilities while offering more competitive pricing compared to previous flagship models. By implementing the optimization strategies outlined in this guide, organizations can effectively balance performance requirements with budget constraints.
The introduction of GPT-4o Mini provides an excellent option for cost-sensitive applications, offering impressive capabilities at a fraction of the cost. For most applications, a thoughtful implementation combining both models based on task complexity will yield the optimal balance of performance and cost-effectiveness.
Remember that the AI landscape continues to evolve rapidly. Staying informed about pricing changes, new model releases, and optimization techniques will be essential for maintaining competitive advantage while managing costs effectively.
Frequently Asked Questions
What is the difference between input and output tokens in GPT-4o pricing?
Input tokens represent the text you send to the model (your prompt), while output tokens are what the model generates in response. GPT-4o charges $2.50 per million input tokens and $10.00 per million output tokens.
Is GPT-4o cheaper than GPT-4?
Yes, GPT-4o is significantly cheaper than the original GPT-4. GPT-4o costs $2.50/$10.00 per million tokens (input/output), while GPT-4 costs $30.00/$60.00 per million tokens.
How many tokens is GPT-4o’s context window?
GPT-4o features a 128K token context window, allowing it to process up to 128,000 tokens in a single request. This is the same as GPT-4 Turbo but smaller than GPT-4.1’s 1 million token window.
What is GPT-4o cached input pricing?
Cached inputs are tokens that have been previously processed by the model and can be reused at a discounted rate of $1.25 per million tokens, offering a 50% saving compared to standard input pricing.
Should I use GPT-4o or GPT-4o Mini for my application?
GPT-4o is recommended for complex tasks requiring advanced reasoning and multimodal capabilities, while GPT-4o Mini is ideal for simpler tasks, content generation, and applications with tight budget constraints. For many applications, a hybrid approach using both models based on task complexity offers the best balance.