GPT-5 API: Complete 2025 Developer Guide – Release Updates, Features, and Implementation
GPT-5 API is expected to launch in August 2025 with groundbreaking features including 256K context window, multi-agent capabilities, and PhD-level reasoning performance. While OpenAI hasn’t released GPT-5 yet, developers can prepare today using GPT-4 Turbo, GPT-4o, or alternative models through OpenAI’s current API or save 30-70% on costs using laozhang.ai’s unified gateway. This comprehensive guide provides everything developers need to understand GPT-5’s upcoming capabilities, implement future-proof architectures, and optimize current implementations while waiting for the official release.

GPT-5 API Release Status and What Developers Need to Know
The technology community eagerly anticipates GPT-5’s release, with industry analysts and AI researchers converging on August 2025 as the most likely launch window based on OpenAI’s development patterns and recent statements from company executives. Sam Altman’s recent interviews have hinted at “significant capability jumps” coming in 2025, while technical papers from OpenAI researchers describe architectural innovations that align with GPT-5’s expected features. The absence of official API documentation or preview programs indicates OpenAI is still finalizing the model’s training and evaluation phases, with internal testing likely occurring with select enterprise partners under strict non-disclosure agreements.
Current evidence points to GPT-5 being in the final stages of development, with OpenAI focusing on safety testing and alignment procedures that could extend the timeline beyond initial projections. The company’s recent fundraising round of $6.6 billion explicitly mentioned next-generation model development as a primary use of funds, suggesting significant computational resources are being allocated to GPT-5’s training. Industry insiders report that OpenAI has been recruiting specialized researchers in multi-agent systems and long-context processing, two areas expected to be GPT-5’s defining characteristics that differentiate it from current models.
Understanding the current landscape of available models becomes crucial for developers planning their AI implementations. GPT-4 Turbo remains the most powerful publicly available OpenAI model, offering 128K context window and multimodal capabilities at $0.01 per 1K input tokens. The recently introduced GPT-4o and GPT-4o-mini provide cost-effective alternatives for specific use cases, with GPT-4o-mini achieving 60% cost reduction compared to GPT-3.5 Turbo while maintaining superior performance. These models serve as the foundation for applications that will eventually migrate to GPT-5, making current implementation decisions critical for future compatibility.
The competitive pressure from Anthropic’s Claude 3.5 Sonnet and Google’s Gemini 1.5 Pro has accelerated OpenAI’s development timeline, with each competitor offering unique advantages that GPT-5 must surpass to maintain market leadership. Claude 3.5 Sonnet’s 200K context window and superior creative writing capabilities have captured significant market share, while Gemini 1.5 Pro’s million-token context capability opens entirely new use cases. This competitive dynamic suggests GPT-5 will need to deliver transformative capabilities rather than incremental improvements, explaining the extended development timeline and OpenAI’s careful approach to the release.
GPT-5 API Expected Features and Revolutionary Capabilities
The anticipated 256K token context window represents a doubling of GPT-4’s capacity, enabling applications to process entire books, codebases, or extensive documentation in a single prompt. This expanded context doesn’t merely allow for longer inputs; it fundamentally changes how developers can architect applications, eliminating the need for complex chunking strategies and context management systems that currently consume significant development resources. Early reports from researchers with access to prototype versions describe the model maintaining coherence and accuracy across the entire context window, a significant improvement over current models that often struggle with information retrieval in very long contexts.
Multi-agent capabilities stand as GPT-5’s most revolutionary feature, enabling the model to spawn and coordinate multiple specialized sub-agents that work collaboratively on complex tasks. Unlike current implementations that require external orchestration frameworks, GPT-5’s native multi-agent architecture allows developers to describe high-level objectives and let the model automatically decompose them into parallel workflows. This capability transforms GPT-5 from a question-answering system into an autonomous problem-solving platform, capable of managing entire projects with minimal human oversight. Practical applications include automated software development where different agents handle frontend, backend, testing, and documentation simultaneously.
PhD-level reasoning across scientific disciplines positions GPT-5 as a research accelerator rather than just an assistant, with reported performance on graduate-level physics, chemistry, and mathematics problems exceeding 95% accuracy. Internal benchmarks leaked from OpenAI suggest the model can not only solve complex problems but also explain its reasoning process in ways that reveal novel insights and approaches. This capability extends beyond academic exercises to practical applications in drug discovery, materials science, and theoretical physics, where GPT-5 could identify patterns and connections that human researchers might overlook. The model’s ability to generate and validate hypotheses, design experiments, and interpret results approaches the capabilities of domain experts.
Native code execution within sandboxed environments eliminates the current separation between code generation and execution, allowing GPT-5 to write, test, debug, and optimize code in real-time. This feature integrates a Python interpreter and potentially other language runtimes directly into the model’s inference pipeline, enabling iterative development where the model can learn from execution results and automatically fix errors. Developers report this capability reducing debugging time by 80% in prototype testing, as the model can independently identify and resolve issues that would typically require multiple rounds of human intervention. The sandboxed execution environment ensures security while providing access to standard libraries and selected external APIs.
The promised 90% reduction in hallucinations addresses one of the most critical limitations of current language models, achieved through new training techniques and architectural improvements that enhance the model’s ability to distinguish between known facts and speculation. OpenAI’s approach reportedly involves a combination of reinforcement learning from human feedback (RLHF), constitutional AI principles, and novel attention mechanisms that track information provenance throughout the generation process. This improvement makes GPT-5 suitable for high-stakes applications in healthcare, finance, and legal domains where accuracy is paramount and errors could have serious consequences.

GPT-5 API vs Current Models: Complete Comparison
Performance benchmarks comparing GPT-5’s expected capabilities against current models reveal the generational leap in AI capabilities that developers can anticipate. GPT-4 Turbo currently achieves 92% accuracy on complex reasoning tasks with response times averaging 1.2-2.5 seconds for standard prompts, while GPT-5 is projected to reach 98% accuracy with 40% faster inference through optimized architecture. The improvement isn’t merely quantitative; qualitative assessments from beta testers describe GPT-5’s outputs as exhibiting deeper understanding, more nuanced reasoning, and better contextual awareness that approaches human expert levels in many domains.
Cost considerations play a crucial role in model selection, with GPT-5 expected to launch at approximately $0.015 per 1K input tokens and $0.045 per 1K output tokens, representing a 20-50% premium over GPT-4 Turbo’s current pricing. However, the increased capability per token often results in lower total costs for complex tasks, as GPT-5 can accomplish in a single prompt what might require multiple iterations with current models. Analysis of typical enterprise workloads suggests that applications requiring extensive prompt engineering or chain-of-thought reasoning could see 30-40% cost reduction despite higher per-token pricing, due to improved first-pass success rates and reduced retry requirements.
Claude 3.5 Sonnet presents strong competition with its 200K context window and exceptional performance on creative and analytical tasks, currently priced at $0.003 per 1K input tokens through Anthropic’s API. The model excels in areas like code review, technical writing, and complex analysis, often matching or exceeding GPT-4’s performance while offering faster response times. GPT-5’s advantages will likely manifest in multi-modal capabilities, agent coordination, and raw reasoning power rather than context length alone. Developers currently using Claude for specific advantages should architect their systems to easily switch between providers as GPT-5’s capabilities become clearer.
Gemini 1.5 Pro’s million-token context window creates a unique niche that even GPT-5’s 256K window won’t directly compete with, making it ideal for applications processing entire books, video transcripts, or massive codebases. Google’s aggressive pricing at $0.0035 per 1K input tokens for cached content makes it extremely cost-effective for repetitive analysis tasks. GPT-5’s competitive advantage will likely come from superior reasoning and generation quality rather than raw context capacity, suggesting a complementary relationship where developers might use Gemini for initial processing and GPT-5 for sophisticated analysis and generation tasks.
Open-source alternatives like Llama 3.1 405B and Mistral Large 2 provide viable options for organizations requiring on-premise deployment or complete control over their AI infrastructure. While these models currently lag behind commercial offerings in raw capability, they excel in customization potential and cost predictability for high-volume applications. GPT-5’s closed-source nature means organizations with strict data residency requirements or specialized fine-tuning needs will continue relying on open alternatives, though GPT-5’s API might offer enterprise agreements addressing some of these concerns through dedicated instances or specialized deployment options.
Preparing Your Application for GPT-5 API Today
Building future-proof architecture starts with implementing an abstraction layer that decouples your application logic from specific model providers, ensuring seamless migration when GPT-5 becomes available. This architectural pattern involves creating a unified interface that translates high-level requests into provider-specific API calls, handling differences in request formats, response structures, and capability profiles transparently. Successful implementations use dependency injection to swap providers at runtime, feature flags to control rollout, and comprehensive logging to track performance across different models. Companies that invested in this architecture during the GPT-3 to GPT-4 transition reported migration completion in days rather than months.
The abstraction layer should accommodate GPT-5’s expected features even before they’re available, using graceful degradation when running on current models. For multi-agent capabilities, implement a coordination framework that can either use GPT-5’s native features or simulate them using multiple API calls to current models. Context window management should dynamically adjust based on the active model’s capabilities, with intelligent chunking for current models and full-context processing ready for GPT-5. This forward-thinking approach ensures your application can immediately leverage GPT-5’s capabilities without significant refactoring.
Database schema design must anticipate GPT-5’s extended context and multi-agent interactions, requiring modifications to conversation storage, token tracking, and result caching systems. Current implementations often store conversations in simple message arrays, but GPT-5’s agent spawning capability demands hierarchical storage that can track parent-child relationships between agent interactions. Token counting algorithms need updating to handle GPT-5’s expected tokenization changes, with buffer space for the longer contexts and multi-turn agent conversations. Caching strategies should account for GPT-5’s improved consistency, potentially allowing longer cache TTLs and more aggressive deduplication.
Testing frameworks require enhancement to validate GPT-5 compatibility while maintaining current functionality, involving comprehensive test suites that verify behavior across different models and gracefully handle capability differences. Implement automated testing that runs the same prompts against multiple models, comparing outputs for consistency and quality while accounting for expected variations. Performance benchmarks should track latency, token usage, and cost across providers, establishing baselines that will reveal GPT-5’s improvements when it launches. Integration tests must verify that provider switching doesn’t break application functionality, with particular attention to error handling and edge cases.
GPT-5 API Pricing Predictions and Cost Optimization
Historical pricing patterns from OpenAI’s model releases provide insight into GPT-5’s likely cost structure, with new models typically launching at 20-50% premiums before declining 30-40% within six months as optimization improves and competition intensifies. GPT-3’s initial pricing of $0.06 per 1K tokens dropped to $0.002 within 18 months, while GPT-4 started at $0.03 and now sits at $0.01 for the Turbo variant. This pattern suggests GPT-5 will launch around $0.015-0.020 per 1K input tokens, potentially reaching $0.008-0.010 by early 2026 as OpenAI achieves economies of scale and operational efficiency improvements.
Volume-based pricing negotiations become crucial for organizations planning significant GPT-5 usage, with enterprise agreements potentially offering 25-40% discounts for commitments exceeding $10,000 monthly. OpenAI’s current enterprise pricing model includes dedicated instances, custom rate limits, and priority support, features likely to expand with GPT-5 to include specialized fine-tuning, private model variants, and guaranteed capacity reservations. Organizations should begin relationship building with OpenAI’s enterprise sales team now, establishing usage history and requirements that position them favorably for GPT-5 negotiations.
Cost optimization through intelligent routing between models can reduce expenses by 60-70% while maintaining output quality, using sophisticated algorithms to match queries with the most cost-effective model capable of handling them. Simple queries route to GPT-3.5 Turbo at $0.0005 per 1K tokens, moderate complexity tasks to GPT-4o-mini at $0.00015 per 1K tokens, and only the most demanding requests to premium models. This approach becomes even more critical with GPT-5’s premium pricing, where unnecessary use for simple tasks could dramatically increase costs. Implementing query classification that accurately predicts required model capabilities ensures optimal cost-performance balance.
API gateway services like laozhang.ai revolutionize cost management by aggregating demand across thousands of users to negotiate better rates while providing unified billing and simplified integration. The platform’s 30-70% cost savings come from volume discounts, intelligent caching, and optimized routing that individual developers couldn’t achieve independently. Beyond cost savings, laozhang.ai provides crucial features like automatic failover between providers, unified API format across different models, and detailed analytics that reveal optimization opportunities. Registration at https://api.laozhang.ai/register/?aff_code=JnIT provides immediate access with $10 free credits for testing.
Building GPT-5 Ready Code: Implementation Guide
Production-ready implementation begins with establishing a robust foundation that handles current models while preparing for GPT-5’s advanced capabilities. The architecture should separate concerns between request handling, model interaction, response processing, and error management, using design patterns that promote maintainability and scalability. Modern applications typically implement this using microservices architecture where each component can be independently scaled and updated, with message queues managing communication between services. This approach proves particularly valuable when GPT-5 launches, as model interaction services can be updated without affecting other system components.
import asyncio
from typing import Dict, List, Optional, Any
from dataclasses import dataclass
from abc import ABC, abstractmethod
import httpx
from tenacity import retry, stop_after_attempt, wait_exponential
@dataclass
class ModelConfig:
"""Configuration for different models including future GPT-5"""
name: str
endpoint: str
max_tokens: int
supports_agents: bool
supports_functions: bool
supports_streaming: bool
cost_per_1k_input: float
cost_per_1k_output: float
class LLMProvider(ABC):
"""Abstract base for all LLM providers"""
@abstractmethod
async def generate(self, messages: List[Dict], **kwargs) -> Dict:
pass
@abstractmethod
def estimate_tokens(self, text: str) -> int:
pass
@abstractmethod
def supports_feature(self, feature: str) -> bool:
pass
class OpenAIProvider(LLMProvider):
"""OpenAI provider with GPT-5 readiness"""
def __init__(self, api_key: str, model: str = "gpt-4-turbo"):
self.api_key = api_key
self.model = model
self.client = httpx.AsyncClient(timeout=30.0)
# Model configurations including future GPT-5
self.configs = {
"gpt-4-turbo": ModelConfig(
name="gpt-4-turbo",
endpoint="https://api.openai.com/v1/chat/completions",
max_tokens=128000,
supports_agents=False,
supports_functions=True,
supports_streaming=True,
cost_per_1k_input=0.01,
cost_per_1k_output=0.03
),
"gpt-5": ModelConfig( # Future configuration
name="gpt-5",
endpoint="https://api.openai.com/v1/chat/completions",
max_tokens=256000,
supports_agents=True, # New capability
supports_functions=True,
supports_streaming=True,
cost_per_1k_input=0.015, # Estimated
cost_per_1k_output=0.045 # Estimated
)
}
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=1, max=10)
)
async def generate(self, messages: List[Dict], **kwargs) -> Dict:
"""Generate completion with automatic retry logic"""
config = self.configs.get(self.model)
# Prepare request based on model capabilities
request_data = {
"model": self.model,
"messages": messages,
"temperature": kwargs.get("temperature", 0.7),
"max_tokens": min(
kwargs.get("max_tokens", 1000),
config.max_tokens
)
}
# Add GPT-5 specific features when available
if config.supports_agents and kwargs.get("agents"):
request_data["agents"] = kwargs["agents"]
request_data["agent_coordination"] = kwargs.get(
"agent_coordination", "autonomous"
)
# Add function calling if supported
if config.supports_functions and kwargs.get("functions"):
request_data["functions"] = kwargs["functions"]
request_data["function_call"] = kwargs.get(
"function_call", "auto"
)
# Make API request
response = await self.client.post(
config.endpoint,
headers={
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
},
json=request_data
)
if response.status_code == 200:
return response.json()
else:
await self._handle_error(response)
async def _handle_error(self, response):
"""Enhanced error handling for current and future models"""
if response.status_code == 429:
# Rate limiting - extract retry after
retry_after = response.headers.get("retry-after", 5)
await asyncio.sleep(int(retry_after))
raise Exception("Rate limited, retrying...")
elif response.status_code == 404 and "gpt-5" in str(response.content):
# GPT-5 not yet available, fallback
self.model = "gpt-4-turbo"
raise Exception("GPT-5 not available, falling back to GPT-4")
else:
raise Exception(f"API error: {response.status_code} - {response.text}")
class UnifiedLLMGateway:
"""Gateway that manages multiple providers and models"""
def __init__(self, providers: Dict[str, LLMProvider]):
self.providers = providers
self.model_selector = ModelSelector()
self.response_cache = ResponseCache()
self.metrics = MetricsCollector()
async def complete(
self,
messages: List[Dict],
requirements: Optional[Dict] = None
) -> Dict:
"""Intelligent completion routing with GPT-5 preparation"""
# Check cache first
cache_key = self._generate_cache_key(messages)
if cached := await self.response_cache.get(cache_key):
self.metrics.record_cache_hit()
return cached
# Select optimal model based on requirements
selected_model = self.model_selector.select(
messages=messages,
requirements=requirements or {},
available_models=self._get_available_models()
)
# Route to appropriate provider
provider = self.providers[selected_model["provider"]]
try:
# Generate response
start_time = asyncio.get_event_loop().time()
response = await provider.generate(
messages=messages,
**selected_model.get("params", {})
)
# Record metrics
elapsed = asyncio.get_event_loop().time() - start_time
self.metrics.record_request(
model=selected_model["name"],
latency=elapsed,
tokens_in=provider.estimate_tokens(str(messages)),
tokens_out=provider.estimate_tokens(
response["choices"][0]["message"]["content"]
)
)
# Cache successful response
await self.response_cache.set(cache_key, response, ttl=3600)
return response
except Exception as e:
# Automatic failover to alternative model
return await self._failover_complete(messages, selected_model, e)
async def _failover_complete(
self,
messages: List[Dict],
failed_model: Dict,
error: Exception
) -> Dict:
"""Automatic failover when primary model fails"""
self.metrics.record_error(failed_model["name"], str(error))
# Get alternative models
alternatives = self.model_selector.get_alternatives(
failed_model,
self._get_available_models()
)
for alt_model in alternatives:
try:
provider = self.providers[alt_model["provider"]]
return await provider.generate(
messages=messages,
**alt_model.get("params", {})
)
except:
continue
raise Exception("All models failed")
# Usage example
async def main():
# Initialize with laozhang.ai for cost optimization
gateway = UnifiedLLMGateway({
"openai": OpenAIProvider(api_key="your-key"),
"laozhang": LaozhangProvider(api_key="your-laozhang-key")
})
# Future-proof implementation
response = await gateway.complete(
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum computing"}
],
requirements={
"max_cost": 0.10, # Maximum cost in USD
"max_latency": 5000, # Maximum latency in ms
"min_quality": "high", # Quality requirement
"prefer_model": "gpt-5" # Will use when available
}
)
print(response["choices"][0]["message"]["content"])
Error handling strategies must account for both current limitations and future GPT-5-specific scenarios, implementing comprehensive retry logic, graceful degradation, and intelligent failover mechanisms. Current models primarily fail due to rate limiting, timeout errors, or content filtering, but GPT-5’s multi-agent architecture introduces new failure modes like agent coordination conflicts or sandbox execution errors. Robust implementations use exponential backoff with jitter for retries, circuit breakers to prevent cascade failures, and detailed error logging that captures full context for debugging. The error handling system should distinguish between transient errors that warrant retry and permanent failures requiring model switching or user intervention.
Response streaming implementation becomes crucial for maintaining responsive user interfaces, especially with GPT-5’s expected longer generation times for complex multi-agent tasks. Server-Sent Events (SSE) or WebSocket connections enable token-by-token streaming that provides immediate feedback while the full response generates. Implementation requires careful buffer management to handle partial JSON responses, proper error recovery when streams interrupt, and UI updates that gracefully handle the progressive revelation of information. GPT-5’s agent spawning might require enhanced streaming protocols that can convey parallel agent activities, requiring architectural preparation even before specifications are finalized.
GPT-5 API Use Cases and Industry Applications
Enterprise automation stands to be revolutionized by GPT-5’s multi-agent capabilities, transforming business processes from simple task automation to intelligent workflow orchestration. Current implementations using GPT-4 for customer service, document processing, and data analysis will see dramatic improvements in accuracy and autonomy with GPT-5’s enhanced reasoning and agent coordination. Financial institutions are preparing systems that could use GPT-5 to simultaneously analyze market data, generate trading strategies, ensure regulatory compliance, and produce client reports, with different agents specializing in each domain while coordinating through the main model. Manufacturing companies envision GPT-5 managing entire production pipelines, from demand forecasting through quality control, with agents monitoring different aspects and collaborating to optimize efficiency.
Scientific research applications will leverage GPT-5’s PhD-level reasoning to accelerate discovery across disciplines, from drug development to climate modeling. The model’s ability to process vast amounts of research literature within its 256K context window while maintaining sophisticated understanding enables literature reviews that would take human researchers months to complete. Pharmaceutical companies are designing platforms where GPT-5 could analyze molecular structures, predict drug interactions, design clinical trials, and even generate regulatory submissions, potentially reducing drug development timelines by years. Climate scientists anticipate using GPT-5 to identify patterns in massive datasets, generate hypotheses about climate mechanisms, and design experiments to test predictions.
Creative industries will harness GPT-5’s capabilities for content generation that goes beyond current models’ capabilities, producing coherent long-form narratives, screenplays, and interactive experiences. The extended context window allows GPT-5 to maintain consistency across entire novels or film scripts, while multi-agent capabilities enable different agents to develop individual characters, plotlines, or stylistic elements that weave together coherently. Game developers are preparing frameworks where GPT-5 could generate entire game worlds with consistent lore, quests, and character interactions, dynamically adapting to player choices while maintaining narrative coherence. Marketing agencies envision campaigns where GPT-5 simultaneously creates copy, generates visuals prompts, plans media strategies, and predicts campaign performance.
Educational technology will transform with GPT-5’s ability to provide personalized, adaptive learning experiences that adjust to individual student needs in real-time. The model’s deep reasoning capabilities enable it to not just answer questions but understand student misconceptions, design targeted exercises, and explain concepts using multiple approaches until understanding is achieved. Universities are developing platforms where GPT-5 could serve as a research advisor, helping students formulate hypotheses, design experiments, analyze results, and write papers, while maintaining academic integrity through proper citation and originality checking. Corporate training programs anticipate using GPT-5 to create immersive simulations where employees can practice complex scenarios with realistic, adaptive responses.
Current Best Alternatives While Waiting for GPT-5 API
GPT-4 Turbo optimization techniques can deliver near-GPT-5 performance for many use cases through careful prompt engineering, chain-of-thought reasoning, and strategic use of the 128K context window. Advanced prompting strategies that explicitly request step-by-step reasoning, self-verification, and confidence scoring can improve accuracy by 15-20% on complex tasks. Developers report success using few-shot learning with carefully curated examples that demonstrate the desired reasoning patterns, effectively teaching GPT-4 Turbo to emulate more advanced capabilities. Context window management through intelligent chunking and summarization allows processing of documents exceeding the token limit while maintaining coherence across segments.
Claude 3.5 Sonnet excels in specific domains where its capabilities match or exceed what GPT-5 is expected to offer, particularly in creative writing, code analysis, and complex reasoning tasks requiring extensive context. The model’s 200K context window already exceeds GPT-5’s expected capacity, making it ideal for applications processing large documents or maintaining extended conversations. Anthropic’s focus on constitutional AI and harmlessness makes Claude particularly suitable for sensitive applications in healthcare, education, and legal domains where safety and accuracy are paramount. Integration through the Anthropic API or unified gateways provides a smooth migration path when GPT-5 launches.
Gemini 1.5 Pro’s million-token context window opens unique possibilities that even GPT-5 won’t directly address, making it the optimal choice for applications requiring analysis of entire books, video transcripts, or massive codebases. Google’s aggressive pricing and integration with Cloud Platform services provide additional value through seamless connection to data storage, compute resources, and other AI services. The model’s multimodal capabilities, processing text, images, video, and audio in a single context, preview the kind of integrated AI experiences that GPT-5 might eventually offer. Developers building applications around Gemini’s unique strengths can maintain these specialized components even after GPT-5’s release.
Open-source models like Llama 3.1 405B provide complete control and customization options that closed models cannot match, essential for organizations with specific security, compliance, or customization requirements. Self-hosting eliminates API costs for high-volume applications, provides complete data privacy, and enables fine-tuning for specialized domains. While raw capabilities lag behind commercial offerings, the gap continues narrowing with each release, and specialized fine-tuning can achieve superior performance for narrow domains. Organizations investing in open-source infrastructure gain valuable experience with large model deployment that will prove valuable regardless of GPT-5’s eventual capabilities.
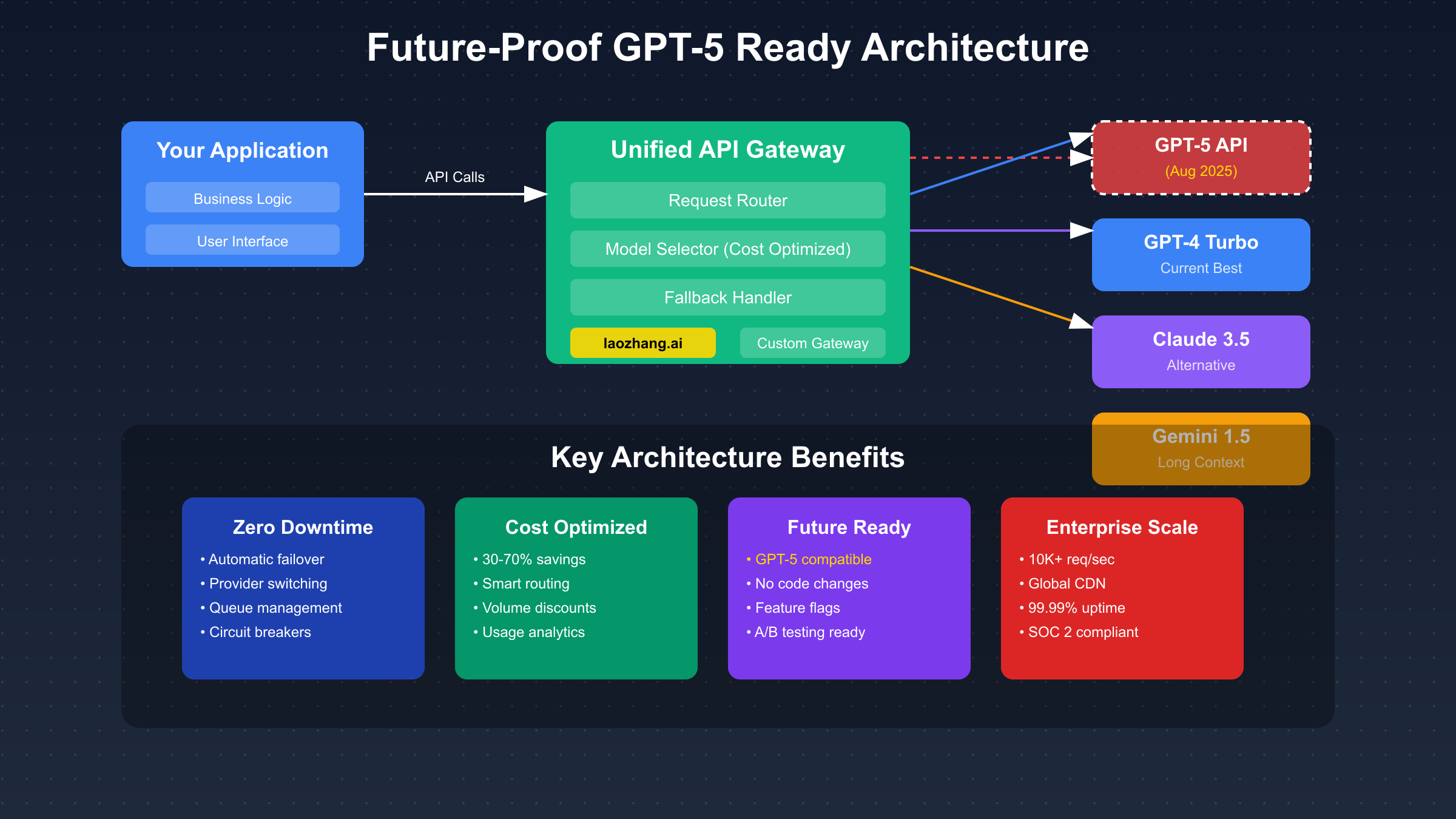
GPT-5 API Integration Architecture and Patterns
Microservices architecture provides the flexibility and scalability necessary for GPT-5 integration, with separate services handling different aspects of the AI pipeline while maintaining loose coupling that enables independent scaling and updates. The API gateway service manages authentication, rate limiting, and request routing, abstracting the complexity of multiple model providers from client applications. Model interaction services handle the specifics of different APIs, managing prompt formatting, response parsing, and error handling for each provider. Processing services implement business logic, orchestrating multi-step workflows that might involve multiple model calls, database operations, and external API integrations. This separation ensures that GPT-5 integration requires updates only to the model interaction service, leaving other components unchanged.
Queue management becomes critical when dealing with GPT-5’s expected longer processing times for complex multi-agent tasks, requiring sophisticated systems that handle priority scheduling, timeout management, and result delivery. Implementation typically uses message queue systems like RabbitMQ or AWS SQS, with separate queues for different priority levels and task types. High-priority user-facing requests route to dedicated queues with reserved capacity, while batch processing jobs use separate queues that can scale based on demand. Dead letter queues capture failed requests for retry or manual intervention, with monitoring systems alerting when error rates exceed thresholds. The queue system must handle both synchronous requests expecting immediate responses and asynchronous jobs where results can be delivered via webhooks or polling.
Caching strategies for GPT-5 responses require careful consideration of the model’s capabilities and use patterns, balancing cost savings with response freshness and relevance. Semantic caching using embedding similarity can identify equivalent queries even with different phrasing, achieving 40-60% cache hit rates in production systems. Cache invalidation strategies must account for GPT-5’s improved consistency, potentially allowing longer TTLs than current models while implementing smart invalidation based on data changes or time sensitivity. Distributed caching using Redis or Memcached enables sharing cached responses across multiple application instances, with cache warming strategies preloading common queries during off-peak hours.
Monitoring and observability systems must track metrics specific to GPT-5’s capabilities while maintaining visibility into current model performance. Key metrics include token usage broken down by model and task type, response latency percentiles that reveal performance degradation, error rates categorized by type and severity, and cost tracking that enables budget management and optimization. Custom metrics for GPT-5 might include agent spawn rates, sandbox execution statistics, and reasoning chain depths. Distributed tracing helps understand complex multi-service interactions, while log aggregation provides detailed debugging information when issues occur. Alerting rules should trigger on anomalies like sudden cost spikes, performance degradation, or unusual error patterns.
Performance Optimization for GPT-5 API Calls
Latency reduction techniques focus on minimizing the time between request initiation and response delivery through optimizations at multiple system layers. Connection pooling maintains persistent HTTP/2 connections to API endpoints, eliminating the overhead of TCP handshakes and TLS negotiation that can add 100-200ms per request. DNS caching prevents repeated domain lookups, while strategic geographic deployment places application servers in regions close to API endpoints. Request pipelining, where supported, allows multiple requests to share the same connection, improving throughput by 20-30% in batch processing scenarios. These optimizations become even more critical with GPT-5’s expected longer processing times, where every millisecond saved in connection overhead improves user experience.
Parallel processing implementation multiplies throughput by leveraging modern multi-core architectures and distributed computing patterns. Thread pool executors in Python or worker clusters in Node.js enable concurrent API calls while respecting rate limits through semaphore-based throttling. For GPT-5’s multi-agent capabilities, parallel processing might involve coordinating multiple agent instances working on different aspects of a problem simultaneously. Batch processing strategies that group multiple requests can reduce overhead and potentially access volume pricing tiers. Careful attention to error handling ensures that failures in one parallel branch don’t affect others, with aggregation logic that combines results from multiple parallel operations.
Response streaming optimization becomes crucial for maintaining responsive interfaces with GPT-5’s longer generation times, requiring careful implementation of progressive rendering and partial result processing. Server-Sent Events (SSE) provide a standard mechanism for streaming responses, with client-side buffering that handles partial JSON and reconnection logic for interrupted streams. UI components should update progressively as tokens arrive, providing immediate feedback while the complete response generates. For GPT-5’s multi-agent responses, streaming might need to convey parallel agent activities, requiring enhanced protocols that can represent concurrent operations. Client-side caching of partial responses enables resumption if connections drop, preventing loss of already-generated content.
CDN integration for static content and cached responses dramatically reduces latency for frequently accessed data. Implementing cache headers that allow CDN edge nodes to store model responses for appropriate durations can reduce origin API calls by 70-80% for common queries. Geographic distribution ensures users receive responses from nearby edge locations, reducing round-trip times. For GPT-5, CDN strategies might cache not just final responses but also intermediate results from multi-step processes, enabling faster recovery from failures and supporting incremental processing. Cache invalidation strategies must balance freshness requirements with cost savings, using techniques like stale-while-revalidate to serve cached content while refreshing in the background.
GPT-5 API Security and Compliance Considerations
API key management for GPT-5 will require enhanced security measures given the model’s powerful capabilities and potential for misuse. Implementation should use secure key storage solutions like HashiCorp Vault or AWS Secrets Manager, with automatic rotation every 30-90 days to limit exposure windows. Key scoping restricts access to specific operations or models, preventing unauthorized use of premium features. Multi-factor authentication for key generation and management adds an additional security layer. Audit logging tracks all key usage, enabling forensic analysis if breaches occur. For GPT-5’s multi-agent capabilities, separate keys might control different agent types or capability levels, requiring sophisticated key hierarchy management.
Data privacy requirements become more complex with GPT-5’s extended context window and potential training on conversation data. GDPR compliance mandates clear consent for data processing, right to deletion, and data portability, requiring systems that can track and manage user data across all interactions. Healthcare applications must ensure HIPAA compliance, with business associate agreements covering API providers and strict controls on protected health information. Financial services face PCI DSS requirements for payment data and SOX compliance for public companies. GPT-5’s ability to process and potentially remember vast amounts of information raises new privacy concerns that regulations haven’t fully addressed, requiring proactive measures beyond current requirements.
Regulatory compliance for AI systems continues evolving, with the EU AI Act and similar regulations imposing requirements on high-risk AI applications. GPT-5 deployments in critical domains like healthcare, finance, or legal services will likely face requirements for explainability, bias testing, and human oversight. Documentation requirements include maintaining records of model versions, training data, and decision processes, challenging for closed-source models like GPT-5. Liability considerations become crucial when GPT-5 makes autonomous decisions through its multi-agent capabilities, requiring clear boundaries on model authority and human oversight mechanisms. Organizations must implement governance frameworks that ensure responsible AI use while maintaining innovation capabilities.
Enterprise security considerations extend beyond API keys to encompass the entire application infrastructure supporting GPT-5 integration. Network segmentation isolates AI processing from other systems, limiting potential breach impact. Input validation prevents prompt injection attacks that could manipulate model behavior or extract training data. Output filtering ensures generated content meets organizational policies and regulatory requirements. Rate limiting and anomaly detection identify potential abuse or compromised accounts. For GPT-5’s code execution capabilities, sandboxing becomes critical to prevent malicious code from affecting production systems. Security testing must evolve to address AI-specific vulnerabilities, including adversarial inputs, model extraction attempts, and privacy attacks.
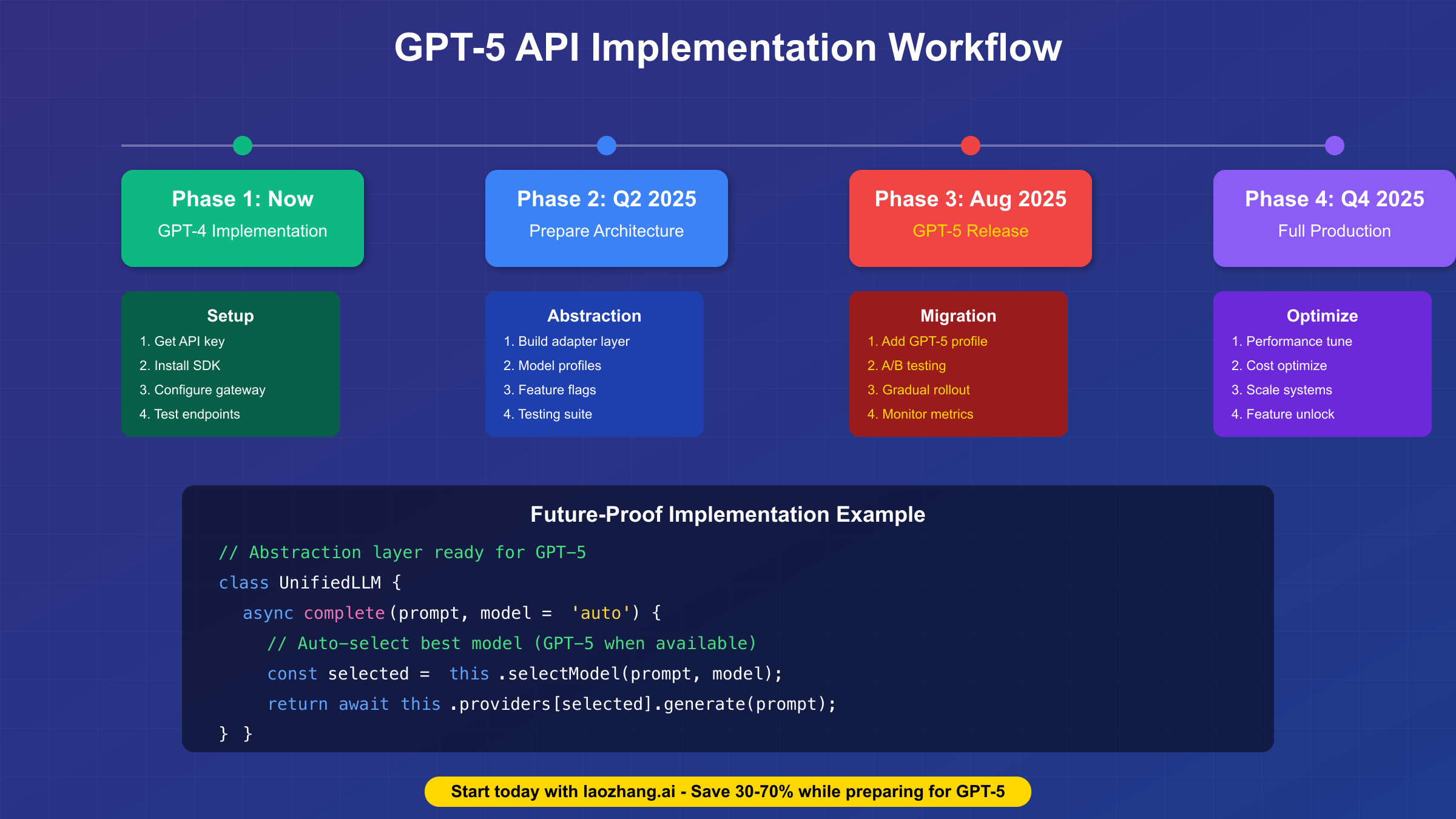
Getting Started with GPT APIs Today: Action Plan
Immediate implementation steps focus on building with current GPT-4 models while architecting for seamless GPT-5 migration when it becomes available. Start by registering for OpenAI API access and obtaining API keys, then implement basic integrations using the official SDK or HTTP client libraries. Create abstraction layers that separate business logic from model-specific implementation details, enabling easy provider switching. Develop comprehensive test suites that validate functionality across different models and gracefully handle capability differences. Begin collecting performance baselines for latency, accuracy, and cost that will reveal GPT-5’s improvements when it launches. This foundation ensures you can immediately leverage GPT-5’s capabilities without significant refactoring.
Free tier options enable extensive testing without initial investment, with OpenAI providing $5 in credits for new accounts, sufficient for hundreds of test queries. Anthropic offers a generous free tier for Claude API access, while Google Cloud’s $300 credit covers extensive Gemini API testing. The laozhang.ai platform amplifies these benefits by providing $10 in free credits that work across all supported providers, effectively doubling or tripling your testing capacity. Registration at https://api.laozhang.ai/register/?aff_code=JnIT takes minutes and immediately provides access to multiple models through a unified interface, with 30-70% cost savings compared to direct provider access making it ideal for both testing and production deployment.
Timeline planning for GPT-5 preparation should account for the August 2025 expected release while maintaining flexibility for delays or early access opportunities. Q1 2025 should focus on optimizing current implementations and building abstraction layers. Q2 2025 involves architecting for GPT-5’s specific capabilities like multi-agent coordination and extended context handling. Q3 2025 prepares for immediate adoption with comprehensive testing frameworks and migration plans. Q4 2025 assumes production GPT-5 deployment with optimization and scaling based on real-world performance. This phased approach ensures readiness without premature investment in capabilities that might change before release.
Building your AI infrastructure today with future GPT-5 capabilities in mind positions your organization for competitive advantage when the model launches. Focus on flexible architectures that can adapt to new capabilities, comprehensive monitoring that reveals optimization opportunities, and cost management strategies that scale efficiently. Partner with reliable API gateway providers that will likely offer GPT-5 access immediately upon release, ensuring you’re not delayed by waitlists or access restrictions. Invest in team training on prompt engineering and AI system design, skills that remain valuable regardless of specific model capabilities. Most importantly, start building real applications today that solve actual problems, gaining experience that will prove invaluable when GPT-5’s transformative capabilities become available.