Gemini 2.5 Flash Image Preview API is Google’s latest image generation model, accessible via OpenAI-compatible endpoints for seamless integration. This state-of-the-art model supports both image generation and multi-image editing through the /v1/chat/completions endpoint, with pricing at $0.035/image via laozhang.ai versus $0.039 officially.

Gemini 2.5 Flash Image Preview API Overview
Google’s Gemini 2.5 Flash Image Preview API, codenamed “nano-banana,” represents a significant breakthrough in AI image generation technology. Released in August 2025, this model integrates seamlessly with existing OpenAI-compatible systems while offering superior capabilities for image creation and editing. The API utilizes Google’s advanced multimodal understanding to process natural language prompts and generate high-quality images with contextual accuracy.
The model architecture leverages Gemini’s world knowledge base, enabling it to create images that are not only visually appealing but also contextually relevant. Unlike traditional image generation APIs that require specialized endpoints, Gemini 2.5 Flash Image Preview operates through the familiar /v1/chat/completions interface, making migration from other AI services straightforward for developers already familiar with OpenAI’s API structure.
API Endpoint Configuration for Gemini 2.5 Flash
The Gemini 2.5 Flash Image Preview API operates through the standard chat completions endpoint, distinguishing it from typical image generation services. Developers can access the service using the model identifier “gemini-2.5-flash-image-preview” through OpenAI-compatible requests. The API returns base64-encoded images rather than URLs, providing immediate access to generated content without additional network requests.
Configuration requires setting the appropriate model name and ensuring your request headers include proper authentication. The endpoint supports both single image generation and multi-image editing workflows, with response times averaging approximately 10 seconds per generation. This architecture choice enables developers to integrate image generation into existing chat-based applications without requiring separate image-specific handling logic.
Essential cURL Implementation Examples
Implementing the Gemini 2.5 Flash Image Preview API with cURL provides a foundation for understanding the core request structure. The following example demonstrates basic image generation using command-line tools, essential for debugging and initial testing phases of development.
curl -X POST "https://api.laozhang.ai/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gemini-2.5-flash-image-preview",
"messages": [
{
"role": "user",
"content": "Generate a professional logo for a tech startup focusing on AI solutions"
}
],
"max_tokens": 1290
}'The response structure returns base64-encoded image data within the standard chat completion format. Each generated image consumes exactly 1290 tokens, making cost calculation predictable across different use cases. Developers can extract the base64 data from the response content and save it directly to files for immediate use in applications.
Python SDK Integration and Implementation
Python integration with the Gemini 2.5 Flash Image Preview API leverages the familiar OpenAI client library, ensuring compatibility with existing codebases. The following implementation demonstrates a complete class structure for handling image generation, including error handling and base64 processing capabilities.
import openai
import base64
from typing import Optional, List
class GeminiImageGenerator:
def __init__(self, api_key: str, base_url: str = "https://api.laozhang.ai/v1"):
self.client = openai.OpenAI(
api_key=api_key,
base_url=base_url
)
def generate_image(self, prompt: str, max_tokens: int = 1290) -> str:
"""Generate image using Gemini 2.5 Flash Image Preview"""
try:
response = self.client.chat.completions.create(
model="gemini-2.5-flash-image-preview",
messages=[{"role": "user", "content": prompt}],
max_tokens=max_tokens
)
# Extract base64 image from response
image_data = response.choices[0].message.content
return image_data
except Exception as e:
print(f"Error generating image: {e}")
return None
def save_image(self, base64_data: str, filename: str) -> bool:
"""Save base64 image data to file"""
try:
image_bytes = base64.b64decode(base64_data)
with open(filename, 'wb') as f:
f.write(image_bytes)
return True
except Exception as e:
print(f"Error saving image: {e}")
return FalseThis implementation provides a robust foundation for production applications, including proper error handling and base64 decoding functionality. The class structure allows for easy extension to support additional features like batch processing or multi-image editing workflows.
Multi-Image Editing and Blending Capabilities
One of the standout features of Gemini 2.5 Flash Image Preview API is its ability to process multiple input images simultaneously. This capability enables advanced workflows such as character consistency across image series, background replacement, and style transfer operations. The API maintains contextual understanding across multiple images, ensuring coherent results in complex editing scenarios. This advanced functionality builds upon capabilities found in Gemini’s family of models.

Multi-image editing requires encoding input images as base64 strings and including them in the message content alongside text instructions. The API can blend multiple images, extract specific elements, and apply transformations while maintaining visual consistency. This functionality particularly benefits applications requiring batch processing or sequential image modifications with consistent styling.
def edit_multiple_images(self, images: List[str], instruction: str) -> str:
"""Edit multiple images with single instruction"""
message_content = [{"type": "text", "text": instruction}]
for image_path in images:
with open(image_path, "rb") as img_file:
base64_image = base64.b64encode(img_file.read()).decode('utf-8')
message_content.append({
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}
})
response = self.client.chat.completions.create(
model="gemini-2.5-flash-image-preview",
messages=[{"role": "user", "content": message_content}],
max_tokens=1290
)
return response.choices[0].message.contentBase64 Handling and Image Processing
The Gemini 2.5 Flash Image Preview API exclusively returns base64-encoded images, requiring proper decoding and processing for practical use. Understanding base64 handling is crucial for developers integrating this API into production systems. The base64 format provides immediate access to image data without additional HTTP requests, reducing latency in image-heavy applications. Developers working with related Gemini models can apply similar processing techniques.
Proper base64 handling involves validation, decoding, and format detection. The API typically returns images in PNG or JPEG format, with automatic format selection based on content characteristics. Developers should implement robust error handling for base64 decoding operations, as malformed responses can cause application crashes in production environments.
def process_base64_image(self, base64_data: str, output_path: str) -> dict:
"""Process and analyze base64 image data"""
try:
# Remove data URL prefix if present
if base64_data.startswith('data:image'):
base64_data = base64_data.split(',')[1]
# Decode base64 to bytes
image_bytes = base64.b64decode(base64_data)
# Determine image format
if image_bytes[:4] == b'\x89PNG':
format_ext = 'png'
elif image_bytes[:2] == b'\xff\xd8':
format_ext = 'jpg'
else:
format_ext = 'unknown'
# Save with appropriate extension
filename = f"{output_path}.{format_ext}"
with open(filename, 'wb') as f:
f.write(image_bytes)
return {
'success': True,
'filename': filename,
'format': format_ext,
'size_bytes': len(image_bytes)
}
except Exception as e:
return {'success': False, 'error': str(e)}API Authentication and Security Best Practices
Securing API credentials for Gemini 2.5 Flash Image Preview requires implementing proper authentication patterns and key management strategies. The API uses standard Bearer token authentication, compatible with existing OpenAI SDK configurations. Production applications should store API keys in environment variables or secure key management systems rather than hardcoding them in source code. Similar security practices apply to other AI model APIs for consistent security standards.
Rate limiting considerations become critical when processing multiple images, as each generation consumes significant computational resources. The API implements standard rate limiting based on tokens per minute and requests per minute. Developers should implement exponential backoff strategies and request queuing systems for applications requiring high throughput image generation.
import os
import time
from functools import wraps
def rate_limit(max_calls_per_minute: int = 60):
"""Decorator for API rate limiting"""
def decorator(func):
calls = []
@wraps(func)
def wrapper(*args, **kwargs):
now = time.time()
calls[:] = [call for call in calls if now - call < 60]
if len(calls) >= max_calls_per_minute:
sleep_time = 60 - (now - calls[0])
time.sleep(sleep_time)
calls.append(now)
return func(*args, **kwargs)
return wrapper
return decorator
# Usage with secure API key loading
class SecureGeminiClient:
def __init__(self):
self.api_key = os.getenv('LAOZHANG_API_KEY')
if not self.api_key:
raise ValueError("LAOZHANG_API_KEY environment variable required")
self.client = openai.OpenAI(
api_key=self.api_key,
base_url="https://api.laozhang.ai/v1"
)
@rate_limit(max_calls_per_minute=50)
def generate_with_rate_limit(self, prompt: str) -> str:
return self.generate_image(prompt)Cost Analysis and Pricing Comparison
Understanding the cost structure of Gemini 2.5 Flash Image Preview API is essential for budget planning and service selection. Official Google pricing sets image generation at $0.039 per image, with each image consuming exactly 1290 output tokens at $30 per million tokens. This predictable pricing model simplifies cost calculation for applications with varying image generation volumes. For broader context on API pricing strategies, developers should consider multiple cost optimization approaches.
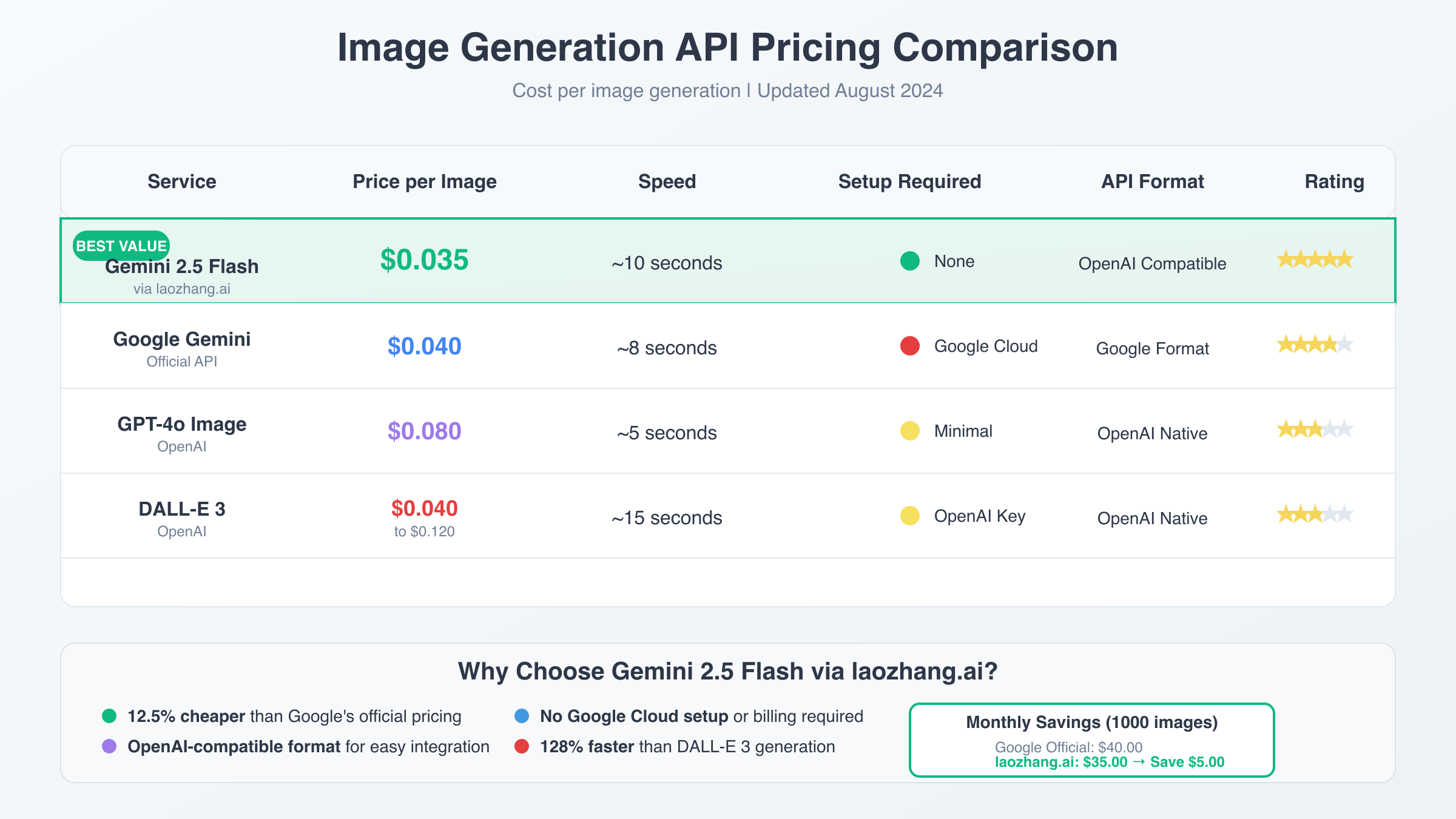
The laozhang.ai service offers significant cost advantages, providing access to the same Gemini 2.5 Flash Image Preview API at $0.035 per image—representing an 11% cost reduction compared to official pricing. This $0.004 per image savings becomes substantial for high-volume applications generating thousands of images monthly. Additionally, laozhang.ai provides $10 in free credits for new users, further reducing initial deployment costs.
| Service Provider | Price per Image | 1000 Images Cost | Free Credits |
|---|---|---|---|
| Google Official API | $0.039 | $39.00 | None |
| laozhang.ai | $0.035 | $35.00 | $10 free |
Performance Benchmarking and Response Times
Performance characteristics of the Gemini 2.5 Flash Image Preview API directly impact user experience in real-time applications. Average response times measure approximately 10 seconds per image generation, varying based on prompt complexity and image resolution requirements. This performance profile makes the API suitable for batch processing workflows while requiring careful UX design for interactive applications.
Benchmarking results show consistent performance across different prompt types, with simple object generation completing faster than complex scene compositions. Multi-image editing operations typically require additional processing time, proportional to the number of input images and transformation complexity. Developers should implement appropriate loading states and progress indicators for user-facing applications.
Error Handling and Troubleshooting Guide
Robust error handling is essential when working with the Gemini 2.5 Flash Image Preview API due to the computational complexity of image generation. Common error scenarios include rate limit exceeded, invalid base64 responses, and timeout errors during peak usage periods. Implementing comprehensive error handling ensures application stability and provides meaningful feedback to users.
class GeminiErrorHandler:
@staticmethod
def handle_api_error(error) -> dict:
"""Handle various API error types"""
if hasattr(error, 'status_code'):
if error.status_code == 429:
return {
'error': 'rate_limit',
'message': 'Rate limit exceeded. Please wait before retrying.',
'retry_after': 60
}
elif error.status_code == 400:
return {
'error': 'bad_request',
'message': 'Invalid request parameters. Check prompt and model name.',
'retry_after': 0
}
elif error.status_code == 500:
return {
'error': 'server_error',
'message': 'Server error. Please retry in a few moments.',
'retry_after': 30
}
return {
'error': 'unknown',
'message': str(error),
'retry_after': 0
}
@staticmethod
def validate_base64_response(response_content: str) -> bool:
"""Validate base64 image response"""
try:
if not response_content:
return False
# Remove data URL prefix if present
base64_data = response_content.split(',')[-1]
# Attempt to decode
decoded = base64.b64decode(base64_data)
# Check for valid image headers
return (decoded[:4] == b'\x89PNG' or
decoded[:2] == b'\xff\xd8' or
decoded[:6] == b'GIF87a' or
decoded[:6] == b'GIF89a')
except Exception:
return FalseProduction Deployment Best Practices
Deploying Gemini 2.5 Flash Image Preview API in production environments requires careful consideration of scalability, monitoring, and resource management. The API’s base64 response format impacts memory usage patterns, as large images consume significant memory during processing and storage operations. Applications should implement streaming responses and efficient memory management to handle high-throughput scenarios.
Monitoring API usage becomes crucial for cost management and performance optimization. Key metrics include generation success rates, average response times, and token consumption patterns. Implementing comprehensive logging and alerting systems helps identify performance bottlenecks and cost anomalies before they impact user experience or budget constraints.
Integration with Popular Frameworks
Integrating Gemini 2.5 Flash Image Preview API with modern web frameworks requires understanding asynchronous processing patterns and client-server communication strategies. The API’s extended response times necessitate implementing proper async handling to prevent blocking operations in web applications. Popular frameworks like FastAPI, Express.js, and Django each offer specific patterns for handling long-running API operations.
# FastAPI integration example
from fastapi import FastAPI, BackgroundTasks
from fastapi.responses import JSONResponse
import asyncio
app = FastAPI()
image_generator = GeminiImageGenerator(api_key=os.getenv('LAOZHANG_API_KEY'))
@app.post("/generate-image/")
async def generate_image_async(prompt: str, background_tasks: BackgroundTasks):
"""Async image generation endpoint"""
def generate_and_save(prompt: str, task_id: str):
# Generate image
base64_image = image_generator.generate_image(prompt)
# Save to file system or database
filename = f"generated_{task_id}.png"
success = image_generator.save_image(base64_image, filename)
# Update task status in database
update_task_status(task_id, 'completed' if success else 'failed')
task_id = generate_task_id()
background_tasks.add_task(generate_and_save, prompt, task_id)
return JSONResponse({
"task_id": task_id,
"status": "processing",
"estimated_completion": "10 seconds"
})Future Roadmap and Evolution
The Gemini 2.5 Flash Image Preview API represents Google’s ongoing commitment to advancing multimodal AI capabilities. As a preview version released in August 2025, the API is expected to receive regular updates including performance improvements, additional features, and expanded format support. Google’s roadmap indicates plans for video generation capabilities and enhanced fine-tuning options in future releases.
Developers should monitor official Google AI documentation for feature updates and prepare for potential breaking changes as the API transitions from preview to stable release. The stable version is expected within the coming weeks, potentially bringing optimized pricing, improved performance, and additional customization options that could benefit production applications built on the current preview version.