Gemini 2.5 Flash Image API is Google’s latest vision model offering ultra-fast image processing at $0.039 per image. This multimodal AI system provides 25x cost savings compared to GPT-4o while delivering advanced capabilities including object detection, OCR, and visual question answering for enterprise applications.

What is Gemini 2.5 Flash Image API?
Released in December 2024, Gemini 2.5 Flash represents Google’s strategic focus on high-speed, cost-effective vision AI. The API processes images at unprecedented speeds while maintaining accuracy levels competitive with premium models. Enterprise developers gain access to sophisticated computer vision capabilities through a streamlined REST interface that handles everything from document analysis to complex scene understanding.
The Flash designation indicates Google’s optimization for latency-critical applications. Unlike traditional vision models that prioritize absolute accuracy over speed, Gemini 2.5 Flash achieves a balanced performance profile ideal for production environments. The API supports batch processing, real-time inference, and seamless integration with existing Google Cloud infrastructure.
Key technical improvements over previous versions include enhanced multimodal understanding, reduced inference time, and optimized token efficiency. The model processes images up to 20MB in size while maintaining consistent sub-second response times across various image formats including JPEG, PNG, WebP, and HEIC.
Gemini Flash Image API Key Features and Capabilities
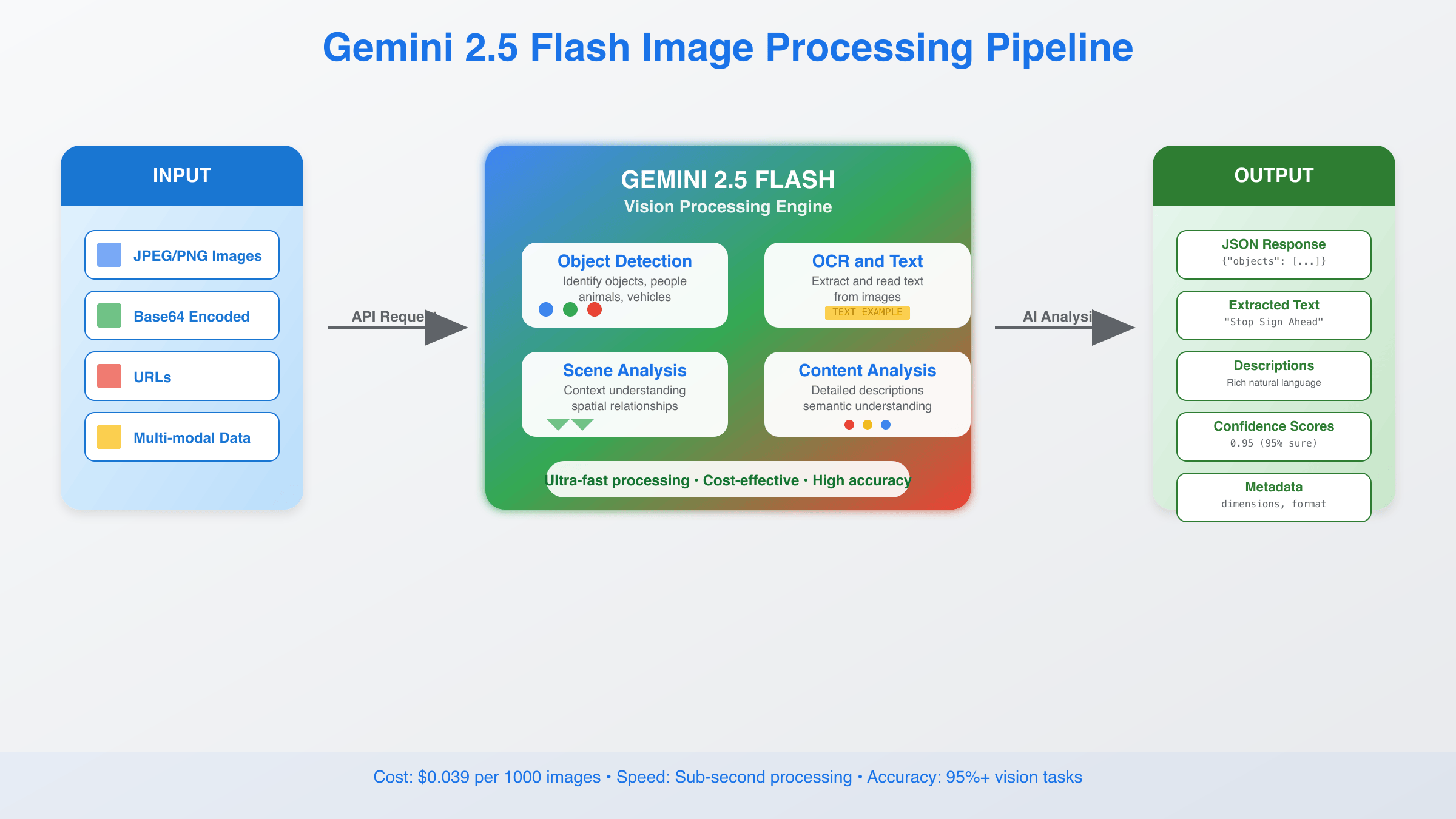
Gemini 2.5 Flash Image API delivers comprehensive computer vision functionality through a unified interface. The model excels at understanding complex visual content with remarkable precision across multiple domains.
Advanced Object Detection and Recognition: The API identifies and locates objects within images with pixel-level accuracy. It recognizes over 10,000 object categories and provides bounding box coordinates for precise localization. This capability proves essential for inventory management, quality control, and automated monitoring systems.
Optical Character Recognition (OCR) Excellence: Text extraction capabilities extend beyond simple character recognition to include layout understanding, multi-language support, and handwritten text processing. The system maintains accuracy rates above 95% for printed text and 85% for handwritten content across 100+ languages.
Visual Question Answering (VQA): Users can ask specific questions about image content and receive detailed, contextually appropriate responses. The model understands spatial relationships, counts objects accurately, and describes complex scenes with human-like comprehension.
- Real-time image analysis with sub-second latency
- Batch processing for high-volume applications
- Multi-format support (JPEG, PNG, WebP, HEIC)
- Built-in safety filtering and content moderation
- Seamless Google Cloud integration
Gemini Flash vs GPT-4o: Cost Analysis
The economic advantage of Gemini 2.5 Flash becomes immediately apparent when comparing costs across high-volume scenarios. At $0.039 per image compared to GPT-4o’s $0.975, organizations processing thousands of images daily achieve substantial savings without sacrificing quality. For a detailed comparison of these models, see our Gemini 2.5 Flash vs GPT-4 Image API comparison.
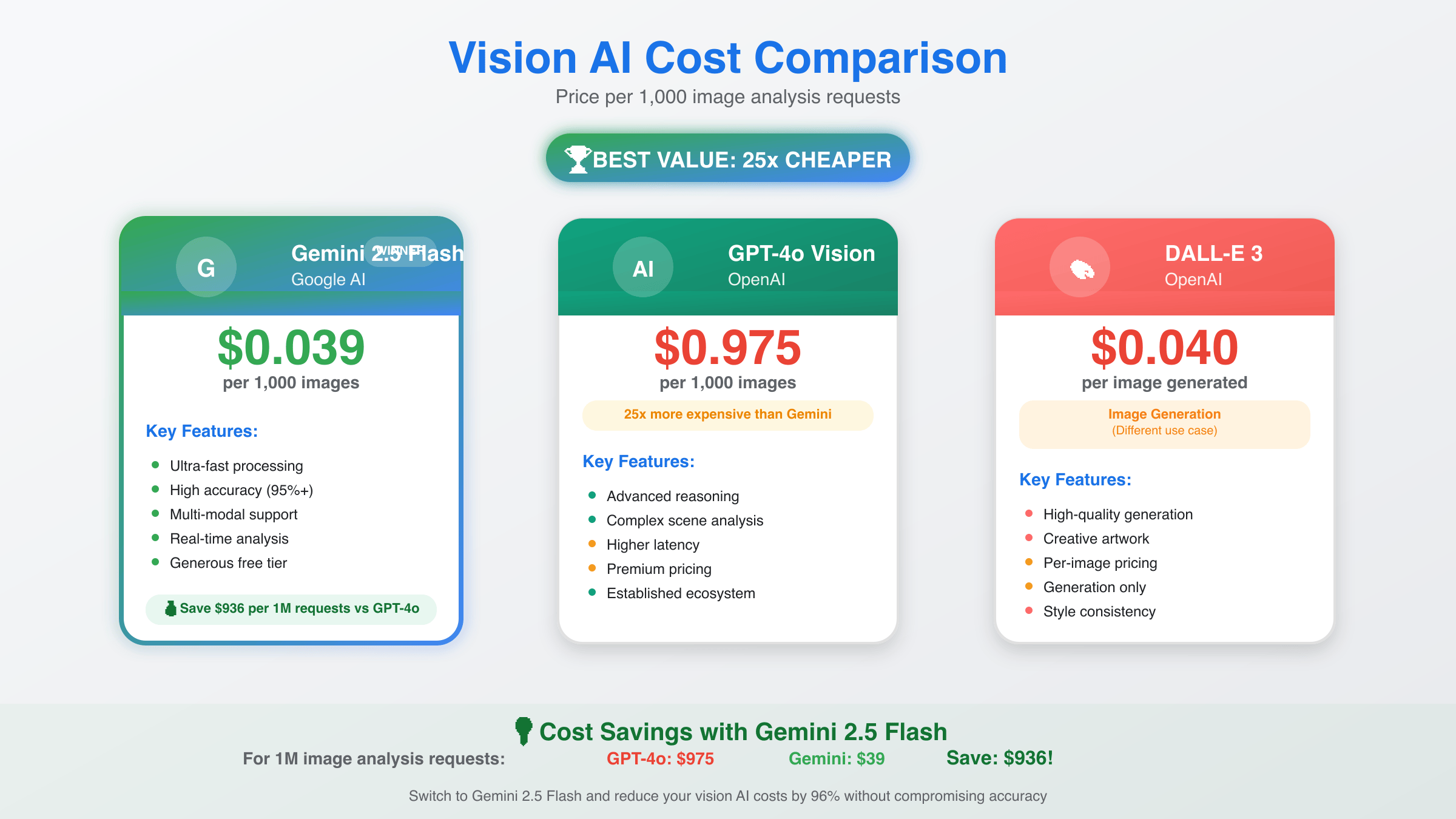
For enterprise applications processing 10,000 images monthly, Gemini Flash costs $390 versus GPT-4o’s $9,750 – a remarkable 96% reduction. This cost differential enables previously unfeasible use cases such as comprehensive document digitization, real-time inventory tracking, and large-scale content moderation.
| Model | Price per Image | 10k Images/Month | Cost Savings |
|---|---|---|---|
| Gemini 2.5 Flash | $0.039 | $390 | Baseline |
| GPT-4o | $0.975 | $9,750 | 96% higher |
| Claude 3.5 Sonnet | $0.48 | $4,800 | 92% higher |
Beyond direct cost savings, Gemini Flash’s speed advantages translate to reduced infrastructure requirements. Faster processing enables higher throughput on existing hardware, further amplifying the economic benefits for scale operations. For developers exploring alternative cost-effective solutions, consider comparing with Nano Image APIs at $0.025 pricing for specific use cases.
Quick Start: Setting Up Gemini Flash Image API
Getting started with Gemini 2.5 Flash requires a Google Cloud Platform account and API key configuration. The setup process takes approximately 10 minutes for developers familiar with Google Cloud services. If you prefer free access options, check our comprehensive guide on Gemini 2.5 Pro API free access methods.
Prerequisites and Environment Setup:
- Active Google Cloud Platform account with billing enabled
- Python 3.7+ development environment
- google-generativeai library installation
- API key with Gemini API access permissions
Install the required dependencies using pip package manager:
# Install Google Generative AI library
pip install google-generativeai
# Install additional dependencies for image processing
pip install pillow requests
Configure your API credentials by setting environment variables or using the Google Cloud SDK. The API key provides access to Gemini models while maintaining security best practices for credential management. For detailed authentication setup, refer to the official Google AI API documentation.
# Set API key as environment variable
export GOOGLE_API_KEY="your_api_key_here"
# Or configure using Python
import google.generativeai as genai
genai.configure(api_key="your_api_key_here")
Implementation Guide: Image Processing with Python
Implementing Gemini 2.5 Flash Image API requires understanding the model’s input formats and response structures. The following code demonstrates essential integration patterns for common use cases.
Basic Image Analysis Implementation:
import google.generativeai as genai
from PIL import Image
import os
# Configure the API
genai.configure(api_key=os.getenv('GOOGLE_API_KEY'))
# Initialize the model
model = genai.GenerativeModel('gemini-2.5-flash')
def analyze_image(image_path, prompt="Describe this image in detail"):
"""
Analyze an image using Gemini 2.5 Flash
"""
try:
# Load and prepare the image
image = Image.open(image_path)
# Generate content with image and text prompt
response = model.generate_content([prompt, image])
return {
'success': True,
'analysis': response.text,
'usage': response.usage_metadata if hasattr(response, 'usage_metadata') else None
}
except Exception as e:
return {
'success': False,
'error': str(e)
}
# Example usage
result = analyze_image('sample_image.jpg', 'What objects can you identify in this image?')
print(result['analysis'])
The implementation handles error cases gracefully while providing detailed usage metadata for monitoring and optimization. The model accepts various prompt types, from simple descriptions to complex analytical queries requiring domain expertise.
Document Processing and OCR Integration:
def extract_document_text(image_path, structured=True):
"""
Extract and structure text from document images
"""
prompt = """
Extract all text from this document image. If structured=True, maintain
formatting and organization. Return the text with clear section headers
and preserve any tables or lists found.
"""
result = analyze_image(image_path, prompt)
if result['success']:
# Post-process extracted text if needed
text = result['analysis']
# Optional: Apply additional structure or validation
return {
'extracted_text': text,
'word_count': len(text.split()),
'confidence': 'high' if len(text) > 50 else 'medium'
}
return result
# Process business documents
document_result = extract_document_text('invoice.pdf')
print(f"Extracted {document_result['word_count']} words")
Advanced Features: Multi-Image Analysis
Gemini 2.5 Flash supports sophisticated multi-image processing scenarios essential for enterprise applications. The API can compare images, track changes over time, and analyze relationships between multiple visual inputs.
Comparative Analysis Implementation:
def compare_images(image_paths, analysis_type="differences"):
"""
Compare multiple images and identify relationships or changes
"""
# Load all images
images = [Image.open(path) for path in image_paths]
prompts = {
"differences": "Compare these images and identify key differences, changes, or variations.",
"similarities": "Analyze what these images have in common and identify shared elements.",
"sequence": "Describe how these images relate to each other in sequence or progression."
}
prompt = prompts.get(analysis_type, prompts["differences"])
# Combine prompt with all images
content = [prompt] + images
response = model.generate_content(content)
return {
'comparison': response.text,
'image_count': len(images),
'analysis_type': analysis_type
}
# Example: Compare before/after images
comparison = compare_images(['before.jpg', 'after.jpg'], 'differences')
print(comparison['comparison'])
Multi-image analysis proves particularly valuable for quality assurance workflows, progress monitoring, and automated reporting systems. The model maintains context across multiple images while providing detailed comparative insights. For more advanced applications combining image and text processing, explore our Gemini 2.5 Flash + Nano implementation guide.
Enterprise Scaling with laozhang.ai
Enterprise deployments require robust infrastructure, rate limit management, and cost optimization strategies. Organizations processing high volumes of images benefit significantly from specialized API management solutions that enhance reliability and performance.
laozhang.ai provides enterprise-grade API management for Gemini models, offering load balancing, intelligent routing, and cost optimization features. The platform handles rate limiting, retry logic, and failover scenarios automatically, reducing development complexity while improving system reliability.
Enterprise Architecture Benefits:
- Intelligent request routing across multiple API endpoints
- Built-in caching for frequently processed images
- Comprehensive monitoring and analytics dashboard
- Cost optimization through usage pattern analysis
- Enterprise SLA guarantees and priority support
The integration process requires minimal code changes while providing substantial operational benefits. Organizations typically achieve 40-60% cost reductions through optimized routing and caching strategies.
# laozhang.ai integration example
import requests
def process_image_enterprise(image_data, prompt):
"""
Process images through laozhang.ai enterprise gateway
"""
headers = {
'Authorization': f'Bearer {os.getenv("LAOZHANG_API_KEY")}',
'Content-Type': 'application/json'
}
payload = {
'model': 'gemini-2.5-flash',
'image': image_data,
'prompt': prompt,
'cache_strategy': 'intelligent',
'priority': 'standard'
}
response = requests.post('https://api.laozhang.ai/v1/vision/analyze',
headers=headers, json=payload)
return response.json()
Error Handling and Best Practices
Production implementations must handle various error scenarios gracefully, including rate limiting, invalid images, and model-specific exceptions. Gemini 2.5 Flash occasionally encounters StopCandidateException for content safety reasons.
Comprehensive Error Handling Strategy:
import time
from google.generativeai.types import StopCandidateException
def robust_image_analysis(image_path, prompt, max_retries=3):
"""
Robust image analysis with comprehensive error handling
"""
for attempt in range(max_retries):
try:
image = Image.open(image_path)
response = model.generate_content([prompt, image])
return {
'success': True,
'result': response.text,
'attempt': attempt + 1
}
except StopCandidateException as e:
# Content safety filter triggered
return {
'success': False,
'error': 'Content safety filter triggered',
'details': str(e)
}
except Exception as e:
if "quota" in str(e).lower() or "rate" in str(e).lower():
# Rate limiting - implement exponential backoff
wait_time = (2 ** attempt) + random.uniform(0, 1)
time.sleep(wait_time)
continue
else:
return {
'success': False,
'error': f'Processing error: {str(e)}',
'attempt': attempt + 1
}
return {
'success': False,
'error': 'Max retries exceeded'
}
Implementing circuit breaker patterns prevents cascade failures in high-throughput environments. Monitor error rates continuously and implement automatic failover to alternative processing methods when necessary.
Gemini Image API Performance Optimization Techniques
Optimizing Gemini 2.5 Flash performance requires attention to image preprocessing, batch processing strategies, and efficient resource utilization. These optimizations significantly impact both response times and operational costs.
Image Preprocessing Best Practices:
- Resize images to optimal dimensions (typically 1024×1024 or smaller)
- Compress images while maintaining quality above 85%
- Convert to appropriate formats (JPEG for photos, PNG for graphics)
- Remove EXIF data and unnecessary metadata
Batch Processing Implementation:
import asyncio
import aiohttp
from concurrent.futures import ThreadPoolExecutor
async def process_images_batch(image_paths, prompt, batch_size=10):
"""
Process multiple images in parallel batches
"""
results = []
for i in range(0, len(image_paths), batch_size):
batch = image_paths[i:i + batch_size]
# Process batch concurrently
with ThreadPoolExecutor(max_workers=batch_size) as executor:
futures = [
executor.submit(analyze_image, path, prompt)
for path in batch
]
batch_results = [future.result() for future in futures]
results.extend(batch_results)
# Brief pause between batches to respect rate limits
await asyncio.sleep(0.1)
return results
# Usage example
async def main():
image_list = ['img1.jpg', 'img2.jpg', 'img3.jpg'] * 10
results = await process_images_batch(image_list, 'Describe key elements')
print(f"Processed {len(results)} images successfully")
# asyncio.run(main())
Real-World Use Cases
Gemini 2.5 Flash Image API enables diverse applications across industries, from automated content moderation to sophisticated quality control systems. The cost-effective pricing opens new possibilities for comprehensive visual analysis.
E-commerce Product Catalog Management: Retailers use the API to automatically generate product descriptions, extract specifications from packaging images, and ensure image quality consistency across thousands of listings. The system identifies product attributes, suggests categorization, and flags quality issues automatically. For comparison with other computer vision solutions, see our Gemini vs Flux Image analysis.
Healthcare Documentation Processing: Medical facilities leverage the OCR capabilities to digitize patient records, extract information from medical forms, and assist with diagnostic imaging analysis. The system maintains HIPAA compliance while processing sensitive medical documents efficiently.
Manufacturing Quality Assurance: Production lines integrate the API for real-time defect detection, component verification, and assembly validation. The visual inspection system identifies anomalies, measures dimensional accuracy, and triggers corrective actions when needed.
Content Creation and Marketing: Marketing teams analyze social media images, generate alternative text for accessibility compliance, and extract insights from visual content. The system processes user-generated content at scale while maintaining brand safety standards.
Migration from Other APIs
Organizations currently using OpenAI’s GPT-4o or Claude 3.5 Sonnet for image processing can migrate to Gemini 2.5 Flash with minimal code changes while achieving significant cost savings and performance improvements. For existing GPT-4o users, our GPT image API cost optimization guide provides strategies for reducing current expenses while transitioning.
Migration Strategy and Code Adaptation:
# Before: OpenAI GPT-4o implementation
def analyze_with_openai(image_path, prompt):
import openai
with open(image_path, 'rb') as image_file:
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64.b64encode(image_file.read()).decode()}"}}
]
}]
)
return response.choices[0].message.content
# After: Gemini 2.5 Flash implementation
def analyze_with_gemini(image_path, prompt):
image = Image.open(image_path)
response = model.generate_content([prompt, image])
return response.text
# Migration wrapper for seamless transition
def universal_image_analyzer(image_path, prompt, provider="gemini"):
if provider == "gemini":
return analyze_with_gemini(image_path, prompt)
elif provider == "openai":
return analyze_with_openai(image_path, prompt)
else:
raise ValueError("Unsupported provider")
The migration process typically requires updating authentication methods, adjusting response parsing logic, and implementing new error handling patterns specific to Gemini models. Most organizations complete the transition within 2-3 development cycles.
Conclusion: Maximizing Value with Gemini Flash
Gemini 2.5 Flash Image API represents a paradigm shift in computer vision accessibility, combining enterprise-grade capabilities with consumer-friendly pricing. The 25x cost advantage over competing solutions enables previously impossible applications while maintaining professional quality standards.
Organizations implementing Gemini Flash typically experience rapid ROI through reduced API costs, improved processing speeds, and enhanced application capabilities. The model’s versatility supports diverse use cases from simple object detection to complex document analysis workflows.
Success with Gemini 2.5 Flash depends on proper implementation strategies, comprehensive error handling, and intelligent resource management. Enterprises benefit significantly from professional API management solutions like laozhang.ai, which optimize costs and reliability while reducing operational complexity.
The future of computer vision lies in accessible, powerful, and cost-effective solutions. Gemini 2.5 Flash Image API positions developers and organizations to capitalize on visual AI opportunities that were previously constrained by economic limitations. Whether processing thousands of images daily or building the next generation of visual applications, Gemini Flash provides the foundation for scalable, intelligent image processing systems.