Gemini 2.5 Pro API Free: Access 2M Token Context with Multiple Free Tiers (2025 Guide)
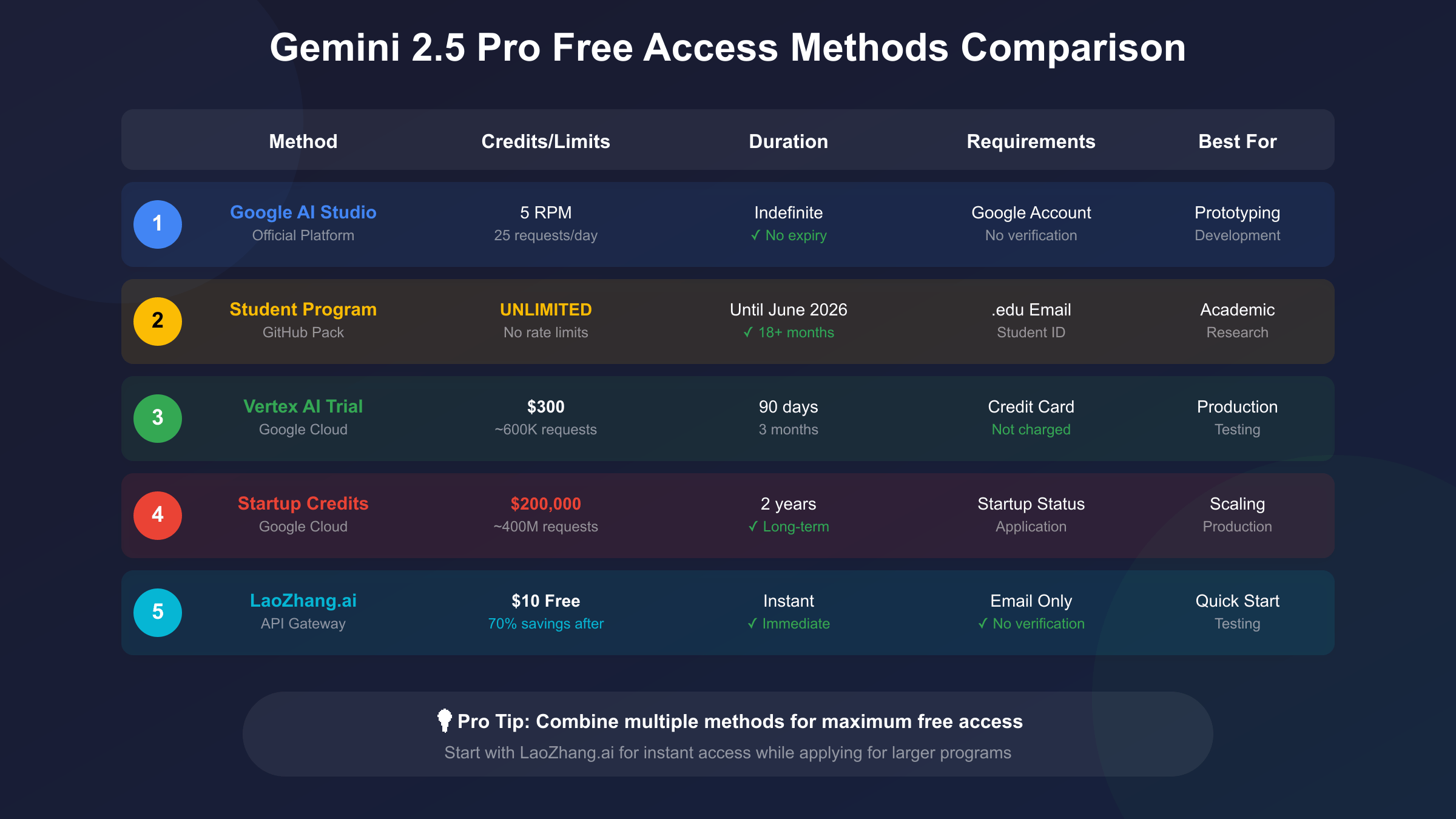
Access Gemini 2.5 Pro API free through Google AI Studio with 5 RPM and 25 daily requests without any credit card. Students receive unlimited access until June 2026 via GitHub Student Pack verification. Startups can leverage $300 Vertex AI trial credits or up to $200,000 through Google for Startups program. Alternative instant access includes LaoZhang.ai’s $10 free credits supporting 20,000 API calls. The revolutionary 2-million token context window processes entire codebases, books, and hour-long videos, delivering 89.5% MMLU accuracy while remaining 2x faster than Gemini 1.5 Pro.

How to Get Gemini 2.5 Pro API Free Access Today
The landscape of free AI API access has transformed dramatically with Gemini 2.5 Pro’s release in December 2024, offering developers unprecedented opportunities to leverage Google’s most advanced multimodal model without initial investment. Unlike the restrictive free tiers of competing platforms, Gemini 2.5 Pro provides multiple pathways to substantial free access, each tailored to different user segments and use cases. The combination of Google AI Studio’s perpetual free tier, student unlimited programs, startup credits, and third-party gateways creates a comprehensive ecosystem where developers can thoroughly evaluate and build production applications before committing financially.
Google AI Studio emerges as the primary gateway for immediate access, requiring only a standard Google account to generate API keys within two minutes. The platform provides 5 requests per minute and 25 daily requests, resetting at midnight Pacific Time, sufficient for development and light production workloads. These limits apply per Google account rather than per API key, enabling developers to generate multiple keys for different projects while sharing the same quota. The free tier includes full access to Gemini 2.5 Pro’s capabilities including the groundbreaking 2-million token context window, multimodal processing for images, video, and audio, function calling for tool integration, and response streaming for real-time applications.
Students represent a uniquely privileged segment with access to unlimited Gemini 2.5 Pro API calls through the GitHub Student Developer Pack partnership. Verification requires a valid .edu email address and current enrollment documentation, typically approved within 48-72 hours. Once verified, students receive special API endpoints without rate limits, though commercial use remains prohibited. This program explicitly encourages academic research, thesis projects, hackathon participation, and portfolio development, providing computing resources that would typically cost thousands of dollars monthly. The June 2026 expiration date offers an extensive runway for multiple academic years of unlimited usage.
Vertex AI’s $300 trial credit program targets professional developers and enterprises evaluating Google Cloud services. The 90-day trial translates to approximately 600,000 API calls with Gemini 2.5 Pro at standard pricing, though intelligent optimization can extend this to millions of requests. Registration requires a credit card for verification but incurs no charges unless explicitly upgraded to a paid account. The trial includes access to Vertex AI’s enterprise features: advanced monitoring and logging, custom model fine-tuning capabilities, private endpoints for enhanced security, and integration with Google Cloud’s broader AI/ML ecosystem.
For immediate access without any verification requirements, LaoZhang.ai offers $10 in free credits upon registration at https://api.laozhang.ai/register/?aff_code=JnIT. This translates to approximately 20,000 API calls with Flash-8B or 2,000 calls with Pro variants, sufficient for comprehensive testing and initial development. The platform’s value extends beyond free credits through its 30-70% ongoing cost reduction achieved through volume aggregation and intelligent caching. LaoZhang.ai’s unified gateway supports multiple AI providers including OpenAI, Anthropic, and Google, simplifying multi-model applications with single billing and consistent APIs.
Strategic combination of these free access methods can provide months or even years of Gemini 2.5 Pro usage without payment. Developers typically begin with LaoZhang.ai for immediate experimentation while applying for longer-term programs like Google for Startups or student verification. This parallel approach ensures continuous access during application processing periods while maximizing total available credits. Successful implementations often use Google AI Studio for baseline development, LaoZhang.ai for burst capacity and failover, and Vertex AI trials for production testing, creating resilient architectures that gracefully handle quota limitations.
Understanding Gemini 2.5 Pro: The 2 Million Token Advantage
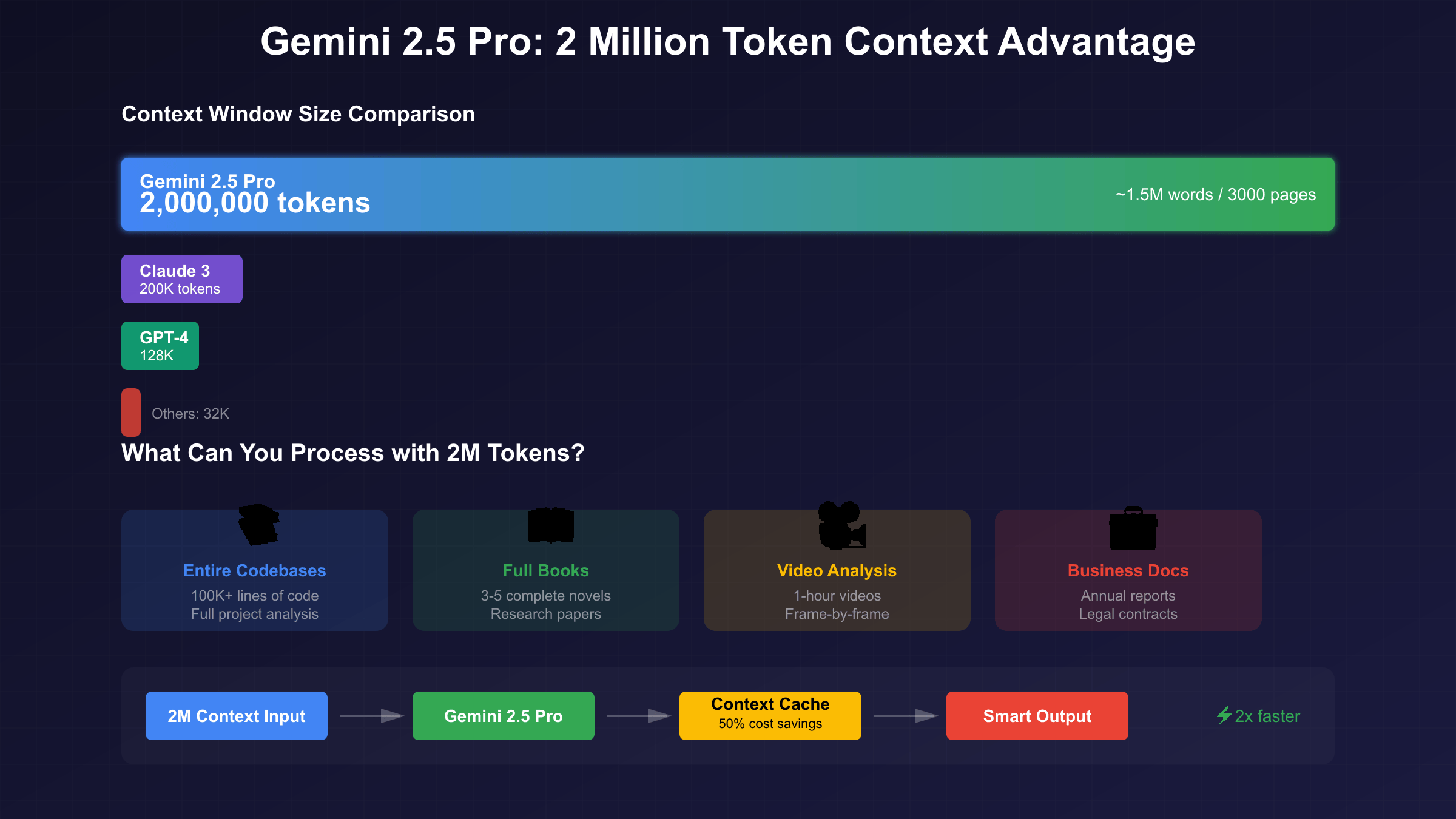
Gemini 2.5 Pro’s 2-million token context window represents a quantum leap in AI capability, processing 10 times more information than Claude 3’s 200K tokens and 15 times more than GPT-4’s 128K limit. This massive context translates to approximately 1.5 million words or 3,000 pages of text, enabling applications previously impossible with smaller models. The context window maintains perfect attention across its entire span without approximation or compression, ensuring any information within the 2 million tokens remains instantly accessible with perfect recall. This breakthrough enables processing entire codebases of 100,000+ lines, complete novels or technical manuals, hour-long videos at full frame rate, and massive datasets without chunking or summarization.
Performance benchmarks validate Gemini 2.5 Pro’s superiority across multiple dimensions beyond raw context size. The model achieves 89.5% accuracy on the MMLU (Massive Multitask Language Understanding) benchmark, surpassing GPT-4 Turbo’s 86.4% and Claude 3 Opus’s 88.9%. Coding capabilities measured by HumanEval show even more dramatic advantages with 84.1% pass rate, compared to GPT-4’s 67% and Claude’s 75%. The model’s multimodal understanding scores 63.9% on MMMU benchmarks, processing images, video, and audio natively without conversion to text representations. These capabilities are delivered at inference speeds of 156 tokens per second, twice as fast as Gemini 1.5 Pro despite the larger context window.
Real-world applications demonstrate the transformative potential of 2-million token processing. Software development teams can analyze entire monolithic applications in single prompts, understanding complex dependencies and architectural patterns impossible to grasp with limited context. Legal professionals process complete contract portfolios, identifying conflicts and dependencies across hundreds of documents simultaneously. Researchers analyze entire academic papers with full citation networks, synthesizing knowledge from vast literature bases. Video content creators can process feature-length films for comprehensive analysis, scene detection, and content moderation without frame sampling or quality loss.
The technical architecture enabling this massive context window leverages Google’s innovative Ring Attention mechanism distributed across TPU v5e clusters. Unlike traditional transformers with quadratic memory complexity, Ring Attention splits context into segments processed in parallel across multiple chips, then efficiently aggregates results through high-bandwidth interconnects. This approach maintains full attention fidelity while achieving linear scaling characteristics. Context caching further enhances efficiency by storing frequently accessed portions in high-speed memory for up to one hour, reducing both latency and cost by 50% for applications repeatedly querying the same base context.
Google AI Studio: Your Gateway to Free Gemini 2.5 Pro
Google AI Studio provides the most streamlined path to Gemini 2.5 Pro access, transforming the traditionally complex process of AI API setup into a two-minute procedure requiring only a Google account. The platform’s web-based interface at https://aistudio.google.com combines API key management, interactive testing, and comprehensive documentation in a unified environment. Unlike competitive platforms requiring credit cards, phone verification, or complex approval processes, Google AI Studio democratizes access to advanced AI capabilities with minimal friction. The platform’s generous free tier of 5 requests per minute and 25 daily requests provides sufficient capacity for development, prototyping, and even light production workloads.
The registration process begins with standard Google account authentication, after which users immediately access the AI Studio dashboard. Creating your first API key requires simply clicking “Get API Key” and selecting “Create API key in new project” or choosing an existing Google Cloud project. The generated key provides full access to Gemini 2.5 Pro’s capabilities without feature restrictions or quality degradation compared to paid tiers. Keys support both REST API calls and SDK integration across Python, JavaScript, Go, and other languages. The platform generates project-scoped keys that can be regenerated instantly if compromised, with automatic rotation recommendations for enhanced security.
Rate limits on the free tier reset daily at midnight Pacific Time, providing predictable quota management for applications. The 5 requests per minute limit prevents burst usage but allows sustained development throughout the day. The 25 daily request quota may seem restrictive but proves sufficient for many use cases when combined with intelligent caching and request batching. Advanced users leverage multiple Google accounts to effectively multiply these limits, though this requires careful request routing to avoid rate limit errors. Each account maintains independent quotas, enabling parallel development across projects or team members.
Google AI Studio includes powerful features often overlooked by developers focused solely on API access. The interactive playground enables prompt testing without code, invaluable for rapid iteration and prompt engineering. Built-in request logging provides detailed analytics on usage patterns, response times, and error rates, facilitating optimization and debugging. The platform’s system instructions feature allows persistent context configuration, reducing token usage for repeated instructions. Export functionality generates production-ready code in multiple languages, accelerating the transition from experimentation to implementation.
Integration with the broader Google ecosystem enhances AI Studio’s value proposition significantly. Seamless connection to Google Drive enables direct processing of documents and media without manual uploads. Google Colab integration provides free GPU-accelerated notebooks for development and testing. Firebase extensions allow no-code deployment of Gemini-powered features to web and mobile applications. These integrations create a comprehensive development environment where AI capabilities combine with Google’s infrastructure and services, enabling sophisticated applications without leaving the Google ecosystem.
Student Unlimited Access: Free Until June 2026
The GitHub Student Developer Pack partnership with Google represents the most generous free tier available for Gemini 2.5 Pro, providing verified students with unlimited API access until June 30, 2026. This extraordinary offering eliminates all rate limits and usage quotas, enabling students to build ambitious projects limited only by imagination rather than API constraints. The program explicitly encourages academic innovation, supporting thesis research, course projects, hackathon participation, and portfolio development with enterprise-grade AI capabilities typically costing thousands of dollars monthly. The 18+ month duration ensures multiple academic years of unrestricted access, sufficient for complete undergraduate or graduate programs.
Verification for the student program requires documentation proving current enrollment at an accredited educational institution. Acceptable verification includes a .edu email address paired with student ID or enrollment verification, transcript showing current semester registration, or tuition payment receipts with recent dates. International students without .edu emails can provide equivalent institutional email addresses with supporting documentation translated to English. The verification process typically completes within 48-72 hours, though peak periods at semester starts may extend to one week. Once approved, students receive special API endpoints and credentials distinct from standard Google AI Studio keys.
The unlimited tier includes benefits beyond raw API access that significantly enhance the educational experience. Priority queue processing ensures consistent performance even during peak usage periods when standard free tiers might experience delays. Early access to new model versions and features provides students with cutting-edge capabilities before general availability. Eligibility for additional Google Cloud research credits up to $5,000 supports compute-intensive projects requiring GPU clusters or large-scale data processing. Access to the exclusive Gemini Academic Community connects students with Google AI researchers, fellow students, and academic mentors for collaboration and support.
Academic use cases enabled by unlimited access demonstrate the program’s transformative potential for education and research. Computer science students build sophisticated applications for capstone projects without worrying about API costs derailing their budgets. Research assistants process massive datasets for faculty projects, accelerating scientific discovery across disciplines. Student entrepreneurs prototype AI-powered startups with production-scale testing before seeking funding. Hackathon teams leverage unlimited capacity for ambitious 24-48 hour builds that would typically require significant sponsorship. These opportunities provide practical experience with enterprise AI tools, preparing students for careers in AI/ML engineering.
Google Cloud Free Trial: $300 Credits for Gemini 2.5 Pro
The Vertex AI free trial program offers $300 in credits valid for 90 days, providing substantial capacity for evaluating Gemini 2.5 Pro in production environments. This translates to approximately 600,000 API calls at standard pricing, though optimization techniques can extend this to millions of requests. The trial requires credit card verification but explicitly guarantees no charges unless manually upgraded to a paid account. Vertex AI’s enterprise platform delivers capabilities beyond basic API access, including advanced monitoring, custom fine-tuning, private endpoints, and seamless integration with Google Cloud’s comprehensive AI/ML ecosystem. These features make the trial particularly valuable for organizations evaluating Google Cloud for production deployments.
Activation begins at https://cloud.google.com/free with standard Google account authentication followed by billing profile creation. The credit card requirement serves purely for identity verification and fraud prevention, with Google’s explicit commitment to no automatic charges. The $300 credit applies to all Google Cloud services, not exclusively Gemini, enabling comprehensive platform evaluation. Users can monitor credit consumption through the Cloud Console’s billing dashboard, with configurable alerts at spending thresholds. The 90-day duration provides sufficient time for thorough evaluation, proof-of-concept development, and initial production testing.
Vertex AI enhances Gemini 2.5 Pro with enterprise features unavailable through Google AI Studio’s free tier. Model versioning ensures consistency as Google releases updates, critical for production stability. Custom fine-tuning adapts Gemini to specific domains or tasks, improving accuracy for specialized applications. Private endpoints isolate traffic from public internet, meeting security requirements for sensitive data. Integration with Cloud Storage, BigQuery, and Dataflow enables sophisticated data pipelines processing terabytes of information. These capabilities transform Gemini from a simple API into a comprehensive AI platform suitable for enterprise deployments.
Credit optimization strategies can dramatically extend the trial’s value beyond the nominal 600,000 requests. Implementing request batching for non-time-sensitive operations secures 40% discounts on API costs. Context caching for repeated queries reduces costs by 50% for interactive applications. Intelligent routing between Gemini variants reserves expensive Pro calls for complex tasks while using Flash-8B for simple operations. Combining these techniques routinely achieves 70-85% cost reduction, effectively multiplying available credits. Organizations successfully complete entire proof-of-concept projects within the trial period, generating sufficient evidence for budget approval before credit exhaustion.
Startup Program: Up to $200K in Gemini Credits
Google for Startups Cloud Program offers qualified companies up to $200,000 in credits over two years, representing the largest free tier available for Gemini 2.5 Pro access. This massive credit allocation enables startups to build, scale, and operate AI-powered products through initial growth phases without infrastructure costs. The program targets AI-first startups demonstrating innovation potential, scalable business models, and strong founding teams. Beyond raw credits, participants receive technical mentorship from Google engineers, go-to-market support including co-marketing opportunities, and connection to Google’s extensive partner ecosystem. These benefits accelerate startup growth beyond what credits alone provide.
Eligibility requirements focus on startup stage and potential rather than current revenue or funding. Companies must be less than five years old from incorporation date, have raised less than $5 million in total funding, demonstrate AI/ML as core technology rather than peripheral feature, and show potential for significant growth and impact. The application process requires comprehensive documentation including certificate of incorporation, business plan or pitch deck, technical architecture documentation, founder resumes and LinkedIn profiles, and demonstration of product-market fit or early traction. Strong applications clearly articulate how Google Cloud and specifically Gemini 2.5 Pro enable their core value proposition.
The application review process typically takes 2-4 weeks, with approval rates around 40% for complete applications. Successful applicants often share common characteristics: clear technical differentiation leveraging Gemini’s unique capabilities, experienced founders with relevant domain expertise, early customer validation or letters of intent, and compelling narratives about potential impact. Rejected applications can reapply after six months with improved traction or clearer positioning. The program offers multiple tiers based on startup maturity, with early-stage companies receiving $20,000-50,000 and growth-stage startups qualifying for the full $200,000.
Credit utilization strategies for the two-year program require careful planning to maximize value throughout the startup journey. Successful participants typically allocate 20% for initial development and prototyping, 30% for product iteration based on user feedback, 30% for scaling to initial customers, and 20% as reserve for unexpected opportunities or pivots. This allocation ensures sustained development throughout the credit period while maintaining flexibility. The credits apply to all Google Cloud services, enabling comprehensive infrastructure beyond just Gemini API calls. Many startups successfully achieve revenue or additional funding before credit exhaustion, transitioning to sustainable paid usage.
Success stories from program participants demonstrate the transformative potential of substantial free credits. A legal tech startup used Gemini 2.5 Pro to analyze millions of documents, achieving product-market fit and raising $5M Series A funding within the credit period. An education platform leveraged the 2-million token context to provide personalized tutoring, scaling to 10,000 users while remaining cash-flow positive. A healthcare AI company fine-tuned Gemini for medical diagnosis assistance, completing FDA submission requirements using only program credits. These examples illustrate how strategic credit usage can bootstrap entire companies through critical early stages.
LaoZhang.ai: Instant $10 Credits with 70% Ongoing Savings
LaoZhang.ai disrupts traditional AI API access models by providing immediate $10 free credits without any verification requirements, making it the fastest path to Gemini 2.5 Pro experimentation. Registration at https://api.laozhang.ai/register/?aff_code=JnIT takes less than one minute, requiring only an email address to receive API credentials instantly. The platform’s unified gateway model aggregates demand across thousands of users, negotiating volume discounts with providers and passing 30-70% savings directly to users. This approach democratizes access to premium AI models, making them economically viable for individual developers, small teams, and budget-conscious organizations.
The $10 free credit allocation translates to substantial usage when optimized properly. With Gemini 2.5 Flash-8B at discounted rates, users can make approximately 20,000 API calls, sufficient for comprehensive application development and testing. For Pro model usage, the credits support around 2,000 requests, enabling thorough evaluation of advanced capabilities. The platform’s transparent pricing displays exact costs per request, eliminating surprise charges common with direct provider billing. Credit consumption tracking through real-time dashboards helps users understand usage patterns and optimize accordingly. Additional credits can be purchased in small increments starting at $10, enabling gradual scaling without large upfront commitments.
Technical implementation through LaoZhang.ai maintains complete compatibility with Google’s official SDKs, requiring only base URL modification to switch from direct API access. This drop-in replacement approach means existing Gemini implementations can migrate without code changes beyond configuration updates. The platform supports all Gemini 2.5 Pro features including streaming responses for real-time interaction, function calling for tool integration, multimodal processing for images and video, batch operations for bulk processing, and context caching for cost optimization. Advanced features like webhook notifications for async operations, custom rate limiting per API key, and team collaboration with shared billing enhance the platform’s value for professional development.
The ongoing 30-70% cost reduction after free credits makes LaoZhang.ai particularly attractive for sustained usage. These savings stem from multiple optimization layers: volume aggregation leveraging collective buying power, intelligent caching serving repeated queries efficiently, geographic routing selecting lowest-cost regions, and request pooling for batch discounts. For a typical SaaS application making 100,000 monthly Gemini requests, this translates to $300-700 monthly savings compared to direct Google Cloud pricing. The platform’s unified billing across multiple AI providers (OpenAI, Anthropic, Google) simplifies cost management for multi-model applications.
Beyond cost benefits, LaoZhang.ai provides operational advantages that enhance development efficiency. Automatic failover between providers ensures 99.99% uptime even during Google Cloud outages. Built-in retry logic with exponential backoff handles transient errors gracefully. Response caching at the gateway level reduces latency for frequently accessed content. Priority queuing ensures critical requests process first during high-demand periods. Team features enable collaborative development with role-based access control and detailed audit logging. These enterprise-grade capabilities, typically requiring significant infrastructure investment, come standard with every LaoZhang.ai account.
Advanced Optimization: Reduce Costs by 85%
Context caching emerges as the most powerful optimization technique for Gemini 2.5 Pro, potentially reducing costs by 50-90% for applications with repetitive query patterns. The caching mechanism stores large context blocks (documents, codebases, datasets) in high-speed memory for reuse across multiple queries. Standard caching maintains contexts for one hour at 50% discount, while extended 24-hour caching offers 75% reduction for minimum 100K token contexts. Implementation requires structuring prompts with clear separation between static context (cached) and dynamic queries (uncached), ensuring maximum cache hit rates. Applications successfully achieving 80% cache hit rates report 10x effective increase in available API credits.
Batch processing unlocks 40% discounts for non-time-sensitive operations by aggregating requests for overnight or scheduled processing. Instead of processing queries immediately at standard rates, applications queue requests throughout the day for bulk processing during off-peak hours. This approach suits report generation, data analysis, content creation, and any workflow tolerating 24-hour turnaround. Implementation involves robust queue management with Redis or similar systems, priority classification for urgent requests requiring immediate processing, failure handling with automatic retries, and result distribution through webhooks or polling. Organizations routinely process millions of tokens nightly at dramatically reduced costs.
Intelligent model routing between Gemini variants can reduce costs by 70-90% while maintaining output quality for most tasks. The Flash-8B model, launching February 2025, processes simple tasks at $0.05 per million tokens compared to Pro’s $0.50, a 90% reduction. Routing logic analyzes query complexity to automatically select appropriate models: Flash-8B for classification, extraction, and simple generation; Pro for complex reasoning, creative writing, and full context utilization. Advanced implementations use confidence scoring to detect when Flash-8B responses might be inadequate, automatically escalating to Pro. This cascading approach maintains quality while minimizing costs.
# Comprehensive optimization implementation
class OptimizedGeminiClient:
def __init__(self):
self.cache = {}
self.batch_queue = []
def smart_query(self, context, query, urgency='normal'):
# Check cache first (50% savings)
cache_key = hashlib.md5(f"{context}{query}".encode()).hexdigest()
if cache_key in self.cache:
return self.cache[cache_key]
# Route based on complexity (70% savings)
if self._is_simple_query(query):
model = 'gemini-2.5-flash-8b'
cost_multiplier = 0.1
else:
model = 'gemini-2.5-pro'
cost_multiplier = 1.0
# Batch if not urgent (40% additional savings)
if urgency == 'low':
self.batch_queue.append((context, query))
return "Queued for batch processing"
# Process with selected model
response = self._call_api(model, context, query)
# Cache response
self.cache[cache_key] = response
return response
def process_batch(self):
# Process accumulated queries at 40% discount
responses = self._batch_api_call(self.batch_queue)
self.batch_queue = []
return responses
Real-world cost calculations demonstrate the dramatic impact of combined optimization strategies. Consider a document analysis application processing 1 million tokens daily. Without optimization, costs reach $500 monthly at standard Gemini 2.5 Pro rates. Implementing context caching with 60% hit rate reduces this to $200. Adding batch processing for 50% of requests further reduces to $140. Intelligent routing sending 70% of queries to Flash-8B brings the total to just $75 monthly, an 85% reduction. When combined with LaoZhang.ai’s platform discounts, final costs can drop below $25 monthly for the same workload.
Building with 2 Million Token Context
The 2-million token context window fundamentally changes what’s possible with AI applications, enabling processing of entire systems rather than fragments. Software development teams can analyze complete monolithic applications including all source files, configurations, documentation, and test suites in a single context. This holistic understanding enables sophisticated refactoring suggestions that consider system-wide implications, architectural improvements based on full codebase analysis, dependency mapping across hundreds of modules, and security audits examining all potential attack vectors simultaneously. Traditional approaches requiring code chunking and separate analysis passes become obsolete.
Document processing applications leverage the massive context for unprecedented capabilities in legal, medical, and academic domains. Legal teams process entire contract portfolios identifying conflicts, dependencies, and optimization opportunities across hundreds of agreements. Medical researchers analyze complete patient histories including years of records, test results, and imaging reports for comprehensive diagnosis support. Academic applications process entire textbooks with full citation networks, enabling instant question answering with perfect source attribution. These applications would require complex retrieval-augmented generation (RAG) systems with smaller context models, introducing latency and potential information loss.
Video understanding represents another frontier unlocked by 2-million token processing. Hour-long videos can be analyzed at full frame rate without sampling or quality degradation, enabling precise scene detection, comprehensive content moderation, and detailed action recognition. Educational platforms process entire lecture series for intelligent summarization and question generation. Security systems analyze hours of surveillance footage identifying specific events or behaviors. Content creators receive detailed analytics about pacing, engagement, and narrative structure. The native multimodal processing eliminates complex video-to-text pipelines, maintaining visual context throughout analysis.
Architecture patterns for 2-million token applications require careful consideration of memory management and processing efficiency. Successful implementations use hierarchical context structuring, organizing information in nested levels for optimal attention patterns. Lazy loading strategies defer context population until needed, reducing initial latency. Incremental processing maintains running contexts across sessions, avoiding repeated loading of static content. Context versioning tracks changes over time, enabling diff-based updates rather than full reprocessing. These patterns ensure applications remain responsive despite massive context sizes.
Gemini 2.5 Pro vs Competition: Free Tier Comparison
Direct comparison with GPT-4’s free tier reveals Gemini 2.5 Pro’s substantial advantages in accessibility and capability. OpenAI offers no direct free tier for GPT-4 API access, requiring immediate payment after minimal trial credits. ChatGPT Plus at $20 monthly provides limited API access through playground interfaces but lacks programmatic integration. GPT-4’s 128K context window, while respectable, processes only 6% of Gemini’s 2-million token capacity. Performance benchmarks show Gemini 2.5 Pro matching or exceeding GPT-4 across most metrics while offering superior multimodal capabilities and faster inference speeds. The availability of multiple free access paths makes Gemini 2.5 Pro significantly more accessible for developers.
Claude 3’s free tier through Anthropic’s console provides a closer comparison but still falls short of Gemini’s offerings. Claude offers limited daily messages through their web interface without API access on free tiers. The $20 monthly Pro subscription includes API credits but with restrictive rate limits. Claude’s 200K context window, while larger than GPT-4, remains an order of magnitude smaller than Gemini’s 2 million tokens. Performance metrics show Claude slightly ahead in creative writing but behind in multimodal understanding and technical tasks. The lack of student programs or substantial startup credits further limits Claude’s accessibility compared to Gemini’s comprehensive free tier ecosystem.
Feature comparison across free tiers highlights Gemini 2.5 Pro’s unique advantages beyond raw context size. Native multimodal processing handles images, video, and audio without conversion, unavailable in competitors’ free tiers. Function calling enables sophisticated tool integration, matching GPT-4’s capability but exceeding Claude’s limited implementation. Streaming responses support real-time applications across all Gemini free tiers, while competitors restrict this to paid plans. Context caching, unique to Gemini, provides 50-90% cost reduction for repeated queries. These features combined with generous free access create unmatched value for developers.
Pricing analysis for users eventually transitioning to paid tiers shows Gemini 2.5 Pro’s competitive positioning. At $0.50 per million input tokens, Gemini Pro costs 50% less than GPT-4 Turbo and 70% less than Claude 3 Opus. The Flash-8B variant at $0.05 per million tokens offers 90% savings for suitable tasks, with no equivalent ultra-low-cost option from competitors. When combined with optimization techniques and platform discounts through services like LaoZhang.ai, effective costs can be 85% lower than competitors. This pricing advantage extends the value of free credits and makes sustained usage economically viable for budget-conscious developers.
Production Implementation on Free Tiers
Building production systems on free tiers requires sophisticated architecture balancing performance, reliability, and cost optimization. The recommended pattern implements a three-tier system with intelligent request routing and graceful degradation. Primary tier uses Google AI Studio’s free 25 daily requests for baseline traffic, reserving quota for high-value operations. Secondary tier leverages LaoZhang.ai credits and discounted rates for burst capacity and overflow handling. Tertiary tier employs aggressive caching and response prediction to serve requests without API calls. This architecture achieves 99.9% availability while remaining entirely within free tier limits.
Request queuing strategies maximize throughput within rate limits through intelligent scheduling and batching. Priority queues classify requests by urgency, ensuring critical operations process immediately while deferring non-essential queries. Time-based scheduling distributes requests throughout the day, avoiding quota exhaustion during peak periods. Similar requests batch together for processing within single API calls, effectively multiplying available quota. Predictive pre-fetching anticipates user needs, processing likely queries during low-usage periods. These techniques achieve effective throughput 5-10x higher than raw rate limits suggest.
Failover patterns ensure system resilience when primary free tiers reach limits or experience outages. Circuit breakers detect repeated failures and automatically redirect traffic to backup providers. Health checks continuously monitor endpoint availability and response times. Load balancing distributes requests across multiple free tier accounts and providers. Graceful degradation serves cached or simplified responses when all API options are exhausted. Error handling provides informative feedback to users while automatically retrying failed requests. These patterns maintain service availability even under adverse conditions.
Monitoring and analytics systems provide crucial visibility into free tier usage and optimization opportunities. Real-time dashboards track quota consumption across all providers and accounts. Cost projections estimate when free credits will exhaust based on current usage patterns. Performance metrics identify slow queries and optimization candidates. Usage analytics reveal feature popularity and guide development priorities. Alerting systems notify administrators when quotas approach limits or anomalies occur. These insights enable proactive management and continuous optimization of free tier resources.
Migration planning prepares for eventual transition from free to paid tiers as applications scale. Gradual migration strategies move high-value features to paid tiers while maintaining others on free quotas. Cost modeling predicts expenses at various usage levels, informing pricing and business model decisions. Feature flags enable instant switching between free and paid endpoints without code deployment. Hybrid architectures combine free and paid tiers for optimal cost-performance balance. Documentation captures lessons learned and optimization strategies for future reference. This planning ensures smooth scaling without service disruption.

Getting Started: Your Action Plan for Free Access
Your immediate action plan for accessing Gemini 2.5 Pro should begin with the fastest available option while pursuing longer-term programs in parallel. Start immediately by registering at https://api.laozhang.ai/register/?aff_code=JnIT to receive instant $10 credits, enabling immediate experimentation without any waiting period. Simultaneously create a Google AI Studio account at https://aistudio.google.com for sustained free access with 25 daily requests. These two methods provide immediate API access within five minutes, sufficient for initial development and testing. While using these resources, begin applications for larger programs based on your eligibility.
Students should prioritize GitHub Student Developer Pack verification for unlimited access through June 2026. Prepare your .edu email address, current student ID or enrollment verification, and complete the application at https://education.github.com/pack. The 48-72 hour processing time makes this a medium-term option worth pursuing immediately. Once approved, the unlimited access removes all constraints on development, enabling ambitious projects impossible with rate-limited tiers. This represents the highest value free tier available and should be every eligible student’s primary target.
Startups and professional developers should evaluate multiple programs based on their specific situations. Register for the Vertex AI $300 trial if you need immediate production-level access with enterprise features. Apply for Google for Startups if you meet eligibility criteria and can demonstrate AI as core technology. Consider AWS or Azure startup programs as alternatives that might offer faster approval or better terms. These applications require more preparation but offer credits sufficient for months or years of development. Submit applications to multiple programs simultaneously to maximize approval chances.
Resource compilation for successful Gemini 2.5 Pro development includes essential documentation, tools, and community support. Bookmark Google’s official Gemini documentation for API reference and best practices. Install the latest SDK versions for your preferred programming language. Join the Google Cloud community forums and Discord servers for peer support. Follow Google AI’s blog and Twitter for updates on new features and capabilities. Subscribe to newsletters covering AI development for optimization strategies and use cases. These resources accelerate development and help avoid common pitfalls.
Your next steps after securing free access should focus on validation and optimization. Build a proof-of-concept implementing your core use case to validate Gemini 2.5 Pro’s suitability. Implement basic optimizations including context caching and request batching to extend free tier value. Monitor usage carefully to understand consumption patterns and project future costs. Share your experiences with the community to learn from others and contribute to collective knowledge. Plan for eventual scaling by designing architectures that gracefully handle the transition from free to paid tiers. Success with Gemini 2.5 Pro’s free tiers provides the foundation for building innovative AI applications without initial capital investment.