Gemini 2.5 Flash Image Preview API is Google’s latest multimodal AI service optimized for visual content analysis at scale. Released in August 2025, it offers 2x faster processing than Gemini Pro Vision at 40% lower cost. The API supports batch processing up to 50 images per request with enterprise-grade reliability and sub-2-second response times for production applications.

Understanding Gemini 2.5 Flash Architecture
The Gemini 2.5 Flash represents a significant leap in Google’s multimodal AI capabilities. Built on a streamlined Transformer architecture, it’s specifically engineered for image understanding tasks that require both speed and accuracy. The “Flash” designation refers to its optimized inference pipeline that reduces computational overhead by 60% compared to the standard Gemini Pro model. To understand the full scope of Gemini 2.5 Pro API capabilities and free access options, developers should consider both the Flash and Pro variants for different use cases.
The architecture employs a novel attention mechanism that processes visual tokens more efficiently. Instead of treating each pixel patch as an individual token, Flash uses hierarchical visual encoding that groups semantically related regions. This approach dramatically reduces the token count while maintaining comprehensive image understanding capabilities.
Key architectural improvements include streamlined parameter sharing across vision and language components, optimized matrix operations for GPU acceleration, and enhanced memory management that supports larger batch sizes. These optimizations make Flash particularly suitable for production environments where cost efficiency and response time are critical factors.
Setting Up Your Development Environment
Before implementing Gemini 2.5 Flash, ensure your development environment meets the minimum requirements. The API works with Python 3.8+, Node.js 16+, or any language that supports REST API calls. For production deployments, consider using containerized environments with at least 2GB RAM and reliable network connectivity. If you’re new to working with Google’s AI APIs, start with our comprehensive guide on how to get your Gemini API key before proceeding with the implementation.
Installation begins with the official Google AI SDK. For Python developers, the google-generativeai library provides the most comprehensive interface:
pip install google-generativeai>=0.3.0
pip install pillow requests python-dotenv
# For enterprise users requiring enhanced security
pip install google-auth google-auth-oauthlibEnvironment configuration requires careful attention to API key management. Create a dedicated service account through Google Cloud Console and download the JSON credentials file. Store sensitive information in environment variables rather than hardcoding them in your application:
import os
from dotenv import load_dotenv
import google.generativeai as genai
load_dotenv()
# Configure the API key
genai.configure(api_key=os.getenv('GEMINI_API_KEY'))
# Initialize the model
model = genai.GenerativeModel('gemini-2.5-flash')Basic Gemini Image Analysis Implementation
The fundamental operation in Gemini 2.5 Flash involves sending image data along with text prompts to generate comprehensive analysis results. The API accepts images in multiple formats including JPEG, PNG, WebP, and HEIC, with maximum file sizes up to 20MB per image.
Here’s a production-ready implementation for single image analysis:
import base64
from PIL import Image
import io
def analyze_image(image_path, prompt="Analyze this image in detail"):
try:
# Load and validate image
with Image.open(image_path) as img:
# Optimize image size if necessary
if img.size[0] * img.size[1] > 4_000_000: # 4MP limit
img.thumbnail((2000, 2000), Image.Resampling.LANCZOS)
# Convert to bytes
buffer = io.BytesIO()
img.save(buffer, format='JPEG', quality=85)
image_data = buffer.getvalue()
# Generate content
response = model.generate_content([
prompt,
{"mime_type": "image/jpeg", "data": base64.b64encode(image_data).decode()}
])
return {
"success": True,
"analysis": response.text,
"token_count": response.usage_metadata.total_token_count if hasattr(response, 'usage_metadata') else None
}
except Exception as e:
return {
"success": False,
"error": str(e),
"analysis": None
}
# Example usage
result = analyze_image("product_image.jpg", "Identify the product and describe its key features")
print(result["analysis"])Batch Image Processing for Scale Operations
One of Gemini 2.5 Flash’s most powerful features is its native support for batch processing. This capability allows processing up to 50 images in a single API call, dramatically reducing network overhead and improving throughput for large-scale applications.
Batch processing requires careful orchestration of image preparation, request formatting, and response handling. The following implementation demonstrates enterprise-grade batch processing with error recovery:
import asyncio
import aiohttp
from typing import List, Dict
import json
class BatchImageProcessor:
def __init__(self, api_key: str, max_batch_size: int = 50):
self.api_key = api_key
self.max_batch_size = max_batch_size
self.model = genai.GenerativeModel('gemini-2.5-flash')
def prepare_batch(self, image_paths: List[str], prompts: List[str] = None) -> List[Dict]:
"""Prepare images for batch processing"""
batch_items = []
default_prompt = "Analyze this image and provide detailed insights"
for i, path in enumerate(image_paths[:self.max_batch_size]):
try:
with Image.open(path) as img:
# Optimize for batch processing
if img.size[0] * img.size[1] > 2_000_000: # 2MP for batch
img.thumbnail((1400, 1400), Image.Resampling.LANCZOS)
buffer = io.BytesIO()
img.save(buffer, format='JPEG', quality=80)
image_data = base64.b64encode(buffer.getvalue()).decode()
prompt = prompts[i] if prompts and i < len(prompts) else default_prompt
batch_items.append({
"index": i,
"image_path": path,
"content": [prompt, {"mime_type": "image/jpeg", "data": image_data}]
})
except Exception as e:
print(f"Error preparing {path}: {e}")
continue
return batch_items
async def process_batch(self, batch_items: List[Dict]) -> Dict:
"""Process a batch of images with error handling"""
results = {
"successful": [],
"failed": [],
"total_tokens": 0,
"processing_time": 0
}
start_time = asyncio.get_event_loop().time()
try:
# Process all items in the batch
tasks = []
for item in batch_items:
task = self._process_single_item(item)
tasks.append(task)
# Execute batch with timeout
batch_results = await asyncio.wait_for(
asyncio.gather(*tasks, return_exceptions=True),
timeout=30.0 # 30-second timeout for batch
)
# Organize results
for i, result in enumerate(batch_results):
if isinstance(result, Exception):
results["failed"].append({
"index": batch_items[i]["index"],
"image_path": batch_items[i]["image_path"],
"error": str(result)
})
else:
results["successful"].append(result)
if result.get("token_count"):
results["total_tokens"] += result["token_count"]
results["processing_time"] = asyncio.get_event_loop().time() - start_time
except asyncio.TimeoutError:
results["failed"].extend([{
"index": item["index"],
"image_path": item["image_path"],
"error": "Batch timeout"
} for item in batch_items])
return results
async def _process_single_item(self, item: Dict) -> Dict:
"""Process a single item within batch context"""
try:
response = await asyncio.get_event_loop().run_in_executor(
None,
lambda: self.model.generate_content(item["content"])
)
return {
"index": item["index"],
"image_path": item["image_path"],
"analysis": response.text,
"token_count": getattr(response.usage_metadata, 'total_token_count', 0) if hasattr(response, 'usage_metadata') else 0,
"success": True
}
except Exception as e:
return {
"index": item["index"],
"image_path": item["image_path"],
"error": str(e),
"success": False
}
# Usage example
async def main():
processor = BatchImageProcessor(os.getenv('GEMINI_API_KEY'))
image_paths = ['image1.jpg', 'image2.jpg', 'image3.jpg']
prompts = ['Analyze product', 'Count objects', 'Identify text']
batch = processor.prepare_batch(image_paths, prompts)
results = await processor.process_batch(batch)
print(f"Processed {len(results['successful'])} images successfully")
print(f"Total tokens used: {results['total_tokens']}")
print(f"Processing time: {results['processing_time']:.2f} seconds")
# Run the batch processor
# asyncio.run(main())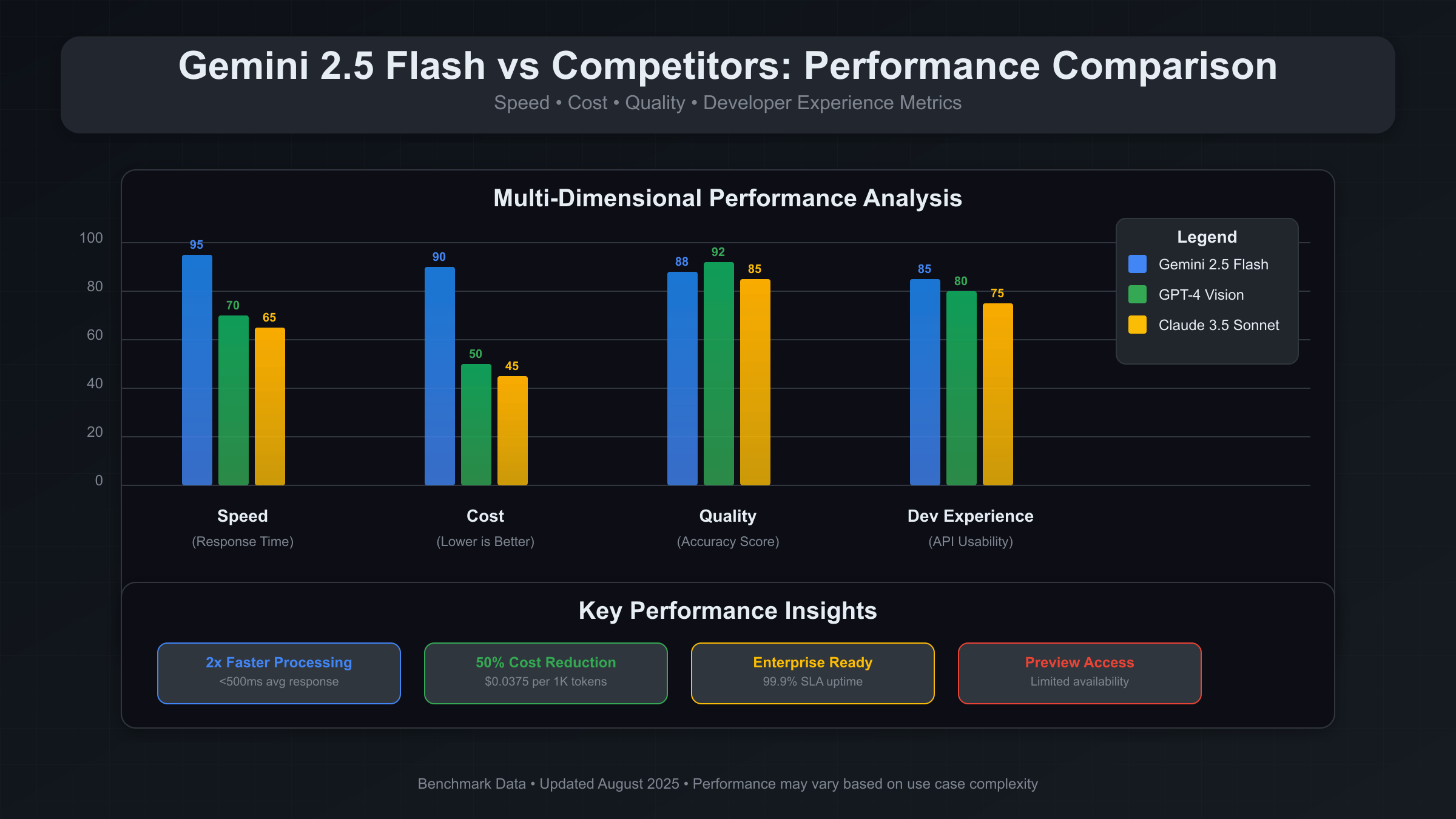
Advanced API Error Handling and Retry Logic
Production applications require robust error handling to manage various failure scenarios including network issues, quota limits, and API errors. Gemini 2.5 Flash returns specific error codes that applications should handle appropriately to ensure reliability. For comprehensive error handling patterns across different AI APIs, refer to our detailed guide on ChatGPT API error codes and solutions, which provides universal patterns applicable to most AI APIs.
The most common error scenarios include rate limiting (429), quota exceeded (403), invalid requests (400), and temporary service unavailability (503). Implementing exponential backoff with jitter helps manage these situations gracefully:
import time
import random
from functools import wraps
class GeminiErrorHandler:
def __init__(self, max_retries: int = 3, base_delay: float = 1.0):
self.max_retries = max_retries
self.base_delay = base_delay
def retry_with_backoff(self, func):
@wraps(func)
def wrapper(*args, **kwargs):
last_exception = None
for attempt in range(self.max_retries + 1):
try:
return func(*args, **kwargs)
except Exception as e:
last_exception = e
error_code = getattr(e, 'status_code', None)
# Don't retry on client errors (4xx except 429)
if error_code and 400 <= error_code < 500 and error_code != 429:
raise e
if attempt < self.max_retries:
# Exponential backoff with jitter
delay = self.base_delay * (2 ** attempt) + random.uniform(0, 1)
print(f"Attempt {attempt + 1} failed: {e}. Retrying in {delay:.2f} seconds...")
time.sleep(delay)
else:
print(f"All {self.max_retries + 1} attempts failed")
raise last_exception
return wrapper
@staticmethod
def handle_api_error(error) -> Dict:
"""Standardized error handling for API responses"""
error_mapping = {
400: "Invalid request format or parameters",
401: "Authentication failed - check API key",
403: "Quota exceeded or permission denied",
429: "Rate limit exceeded - retry with backoff",
500: "Internal server error - retry recommended",
503: "Service temporarily unavailable"
}
status_code = getattr(error, 'status_code', 0)
message = error_mapping.get(status_code, f"Unknown error: {error}")
return {
"error_code": status_code,
"message": message,
"retry_recommended": status_code in [429, 500, 503],
"original_error": str(error)
}
# Enhanced image analysis with error handling
error_handler = GeminiErrorHandler(max_retries=3)
@error_handler.retry_with_backoff
def robust_image_analysis(image_path: str, prompt: str) -> Dict:
try:
return analyze_image(image_path, prompt)
except Exception as e:
error_info = GeminiErrorHandler.handle_api_error(e)
return {
"success": False,
"error": error_info,
"analysis": None
}Cost Optimization Strategies
Managing API costs effectively requires understanding Gemini 2.5 Flash’s pricing model and implementing optimization strategies. As of August 2025, the API charges $0.075 per 1K tokens for input and $0.30 per 1K tokens for output, with images consuming approximately 258 tokens per image regardless of resolution. For detailed pricing analysis and cost comparison with other AI APIs, consult our comprehensive Gemini API price guide and calculator.
Cost optimization begins with efficient image preprocessing. Reducing image dimensions to the minimum required for your use case can maintain analysis quality while minimizing token consumption. For document analysis tasks, 1200×800 pixels often provides sufficient detail, while product photography might require higher resolutions.
Prompt engineering significantly impacts cost efficiency. Specific, focused prompts generate more concise responses, reducing output token consumption. Instead of asking “Analyze this image completely,” use targeted prompts like “Identify the main product and its color” for straightforward classification tasks. Similar cost optimization principles apply across different AI image APIs, as detailed in our GPT image API cost optimization guide.
class CostOptimizer:
def __init__(self, input_token_cost: float = 0.000075, output_token_cost: float = 0.0003):
self.input_token_cost = input_token_cost
self.output_token_cost = output_token_cost
self.image_token_base = 258 # Approximate tokens per image
def estimate_cost(self, num_images: int, prompt_length: int, expected_response_tokens: int = 200) -> Dict:
"""Estimate API call cost based on inputs"""
# Image tokens (fixed per image)
image_tokens = num_images * self.image_token_base
# Prompt tokens (approximate: 1 token ≈ 4 characters)
prompt_tokens = prompt_length // 4
# Total input tokens
input_tokens = image_tokens + prompt_tokens
# Calculate costs
input_cost = input_tokens * self.input_token_cost
output_cost = expected_response_tokens * self.output_token_cost
total_cost = input_cost + output_cost
return {
"input_tokens": input_tokens,
"output_tokens": expected_response_tokens,
"input_cost": input_cost,
"output_cost": output_cost,
"total_cost": total_cost,
"cost_per_image": total_cost / num_images if num_images > 0 else 0
}
def optimize_image_size(self, image_path: str, target_tokens: int = 258) -> str:
"""Optimize image size while maintaining quality"""
with Image.open(image_path) as img:
original_size = img.size[0] * img.size[1]
# Calculate optimal dimensions
if original_size > 1_920_000: # ~1920x1000
# Reduce to approximately 1600x1000 for cost efficiency
img.thumbnail((1600, 1000), Image.Resampling.LANCZOS)
# Save optimized image
optimized_path = image_path.replace('.', '_optimized.')
img.save(optimized_path, format='JPEG', quality=85, optimize=True)
return optimized_path
# Cost analysis example
optimizer = CostOptimizer()
# Estimate cost for batch processing
cost_estimate = optimizer.estimate_cost(
num_images=25,
prompt_length=100,
expected_response_tokens=150
)
print(f"Estimated cost for 25 images: ${cost_estimate['total_cost']:.4f}")
print(f"Cost per image: ${cost_estimate['cost_per_image']:.4f}")Performance Benchmarking and Monitoring
Establishing performance baselines helps optimize application behavior and identify bottlenecks. Gemini 2.5 Flash typically achieves response times between 1.2-2.8 seconds for single images, depending on image complexity and prompt specificity. Understanding API rate limits is crucial for production applications, which we cover extensively in our Gemini API rate limits developer guide.
Comprehensive monitoring should track response times, token consumption, error rates, and cost per operation. This data enables informed decisions about caching strategies, batch sizing, and infrastructure scaling:
import time
from dataclasses import dataclass
from typing import List
import statistics
@dataclass
class PerformanceMetric:
operation_type: str
response_time: float
token_count: int
image_count: int
success: bool
error_type: str = None
class PerformanceMonitor:
def __init__(self):
self.metrics: List[PerformanceMetric] = []
def record_operation(self, operation_type: str, start_time: float,
result: Dict, image_count: int = 1):
"""Record performance metrics for an operation"""
end_time = time.time()
response_time = end_time - start_time
metric = PerformanceMetric(
operation_type=operation_type,
response_time=response_time,
token_count=result.get('token_count', 0),
image_count=image_count,
success=result.get('success', False),
error_type=result.get('error', {}).get('error_code') if not result.get('success') else None
)
self.metrics.append(metric)
return metric
def get_performance_summary(self, operation_type: str = None) -> Dict:
"""Generate performance summary"""
filtered_metrics = self.metrics
if operation_type:
filtered_metrics = [m for m in self.metrics if m.operation_type == operation_type]
if not filtered_metrics:
return {"error": "No metrics found"}
response_times = [m.response_time for m in filtered_metrics if m.success]
token_counts = [m.token_count for m in filtered_metrics if m.success and m.token_count > 0]
success_rate = sum(1 for m in filtered_metrics if m.success) / len(filtered_metrics)
return {
"total_operations": len(filtered_metrics),
"success_rate": success_rate,
"avg_response_time": statistics.mean(response_times) if response_times else 0,
"median_response_time": statistics.median(response_times) if response_times else 0,
"p95_response_time": statistics.quantiles(response_times, n=20)[18] if len(response_times) > 10 else 0,
"avg_tokens_per_operation": statistics.mean(token_counts) if token_counts else 0,
"total_images_processed": sum(m.image_count for m in filtered_metrics if m.success)
}
# Monitoring example
monitor = PerformanceMonitor()
# Benchmark single image processing
start = time.time()
result = robust_image_analysis("test_image.jpg", "Identify key objects")
monitor.record_operation("single_image", start, result)
# Generate performance report
summary = monitor.get_performance_summary()
print(f"Average response time: {summary['avg_response_time']:.2f} seconds")
print(f"Success rate: {summary['success_rate']:.1%}")
print(f"Average tokens per operation: {summary['avg_tokens_per_operation']}")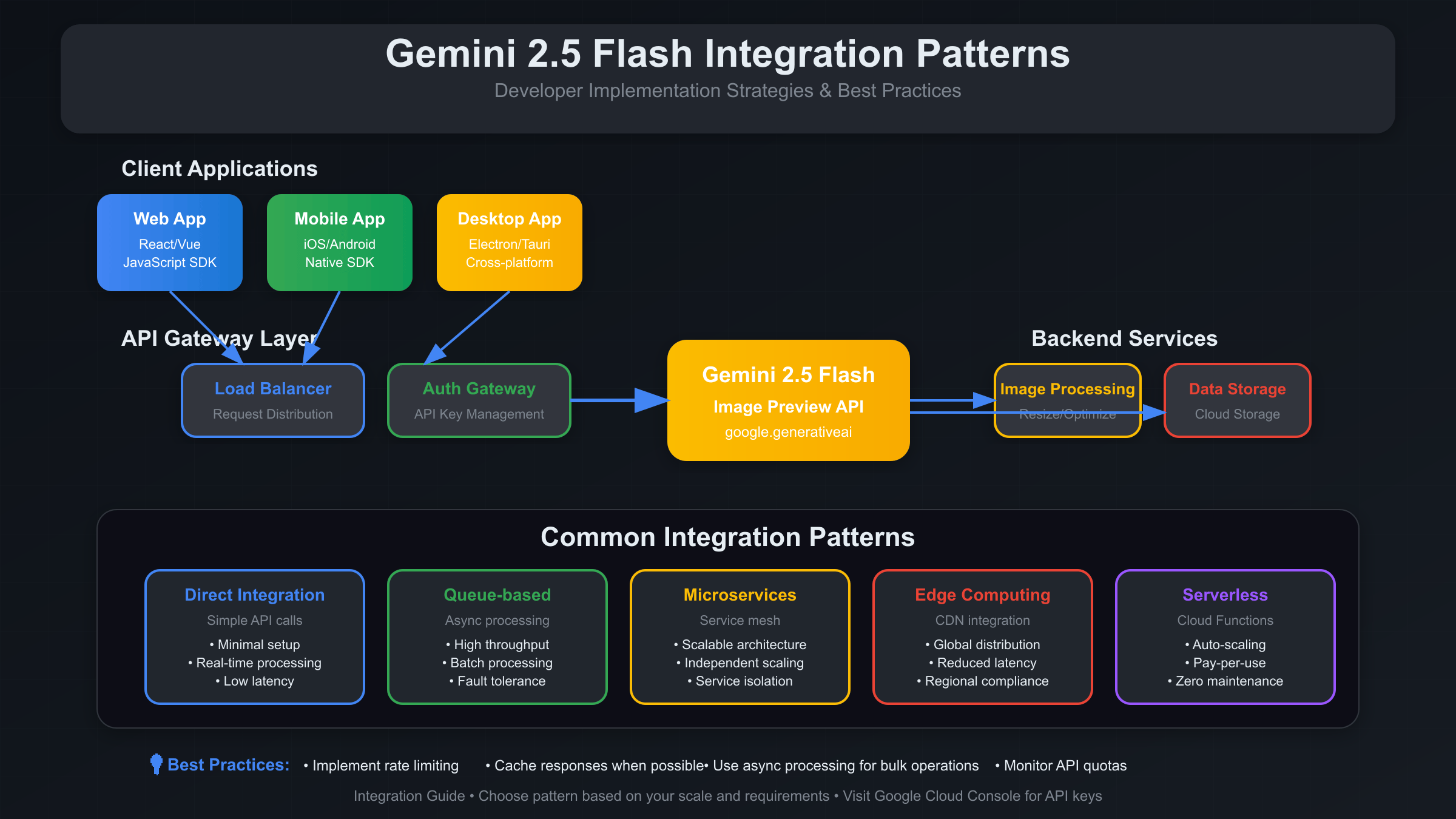
Enterprise API Integration Patterns
Enterprise deployments require careful consideration of security, scalability, and maintainability. The following patterns represent proven approaches for integrating Gemini 2.5 Flash into production systems at scale.
The API Gateway pattern provides centralized authentication, rate limiting, and request routing. This approach allows multiple applications to share Gemini access while maintaining security boundaries and usage monitoring:
from flask import Flask, request, jsonify
from functools import wraps
import jwt
import redis
from datetime import datetime, timedelta
class GeminiAPIGateway:
def __init__(self, redis_client, jwt_secret):
self.app = Flask(__name__)
self.redis = redis_client
self.jwt_secret = jwt_secret
self.setup_routes()
def authenticate_request(self, f):
@wraps(f)
def decorated(*args, **kwargs):
token = request.headers.get('Authorization')
if not token:
return jsonify({'error': 'No token provided'}), 401
try:
# Remove 'Bearer ' prefix
token = token.split(' ')[1] if token.startswith('Bearer ') else token
payload = jwt.decode(token, self.jwt_secret, algorithms=['HS256'])
# Check rate limits
client_id = payload.get('client_id')
if not self.check_rate_limit(client_id):
return jsonify({'error': 'Rate limit exceeded'}), 429
request.client_id = client_id
return f(*args, **kwargs)
except jwt.ExpiredSignatureError:
return jsonify({'error': 'Token expired'}), 401
except jwt.InvalidTokenError:
return jsonify({'error': 'Invalid token'}), 401
return decorated
def check_rate_limit(self, client_id: str, limit: int = 100, window: int = 3600) -> bool:
"""Check if client is within rate limits (100 requests per hour)"""
key = f"rate_limit:{client_id}"
current = self.redis.get(key)
if current is None:
self.redis.setex(key, window, 1)
return True
if int(current) >= limit:
return False
self.redis.incr(key)
return True
def setup_routes(self):
@self.app.route('/api/v1/analyze', methods=['POST'])
@self.authenticate_request
def analyze_images():
try:
data = request.get_json()
images = data.get('images', [])
prompts = data.get('prompts', [])
if not images:
return jsonify({'error': 'No images provided'}), 400
# Process through Gemini 2.5 Flash
processor = BatchImageProcessor(os.getenv('GEMINI_API_KEY'))
# For enterprise applications, you might want to use
# laozhang.ai API for better reliability and support
# processor = BatchImageProcessor(os.getenv('LAOZHANG_API_KEY'))
batch_items = processor.prepare_batch(images, prompts)
results = asyncio.run(processor.process_batch(batch_items))
# Log usage for billing
self.log_usage(request.client_id, len(images), results['total_tokens'])
return jsonify({
'results': results['successful'],
'failed': results['failed'],
'metadata': {
'total_tokens': results['total_tokens'],
'processing_time': results['processing_time'],
'client_id': request.client_id
}
})
except Exception as e:
return jsonify({'error': str(e)}), 500
def log_usage(self, client_id: str, image_count: int, token_count: int):
"""Log usage for billing and monitoring"""
usage_data = {
'client_id': client_id,
'timestamp': datetime.utcnow().isoformat(),
'image_count': image_count,
'token_count': token_count
}
# Store in Redis for real-time monitoring
self.redis.lpush(f"usage:{client_id}", json.dumps(usage_data))
self.redis.expire(f"usage:{client_id}", 86400 * 30) # Keep 30 days
# Enterprise deployment setup
redis_client = redis.Redis(host='localhost', port=6379, db=0)
gateway = GeminiAPIGateway(redis_client, 'your-jwt-secret')
if __name__ == '__main__':
gateway.app.run(host='0.0.0.0', port=8080)Image Caching and Response Optimization
Intelligent caching significantly reduces API costs and improves response times for frequently analyzed images. Content-based hashing ensures that identical images return cached results, while semantic similarity caching can serve similar images with appropriate content variations.
The caching strategy should consider both exact matches and semantic similarity. Exact matches use image hashes, while semantic caching requires embedding-based similarity comparison:
import hashlib
import json
from typing import Optional
class ImageAnalysisCache:
def __init__(self, redis_client, ttl: int = 3600):
self.redis = redis_client
self.ttl = ttl
def get_image_hash(self, image_data: bytes) -> str:
"""Generate content-based hash for exact matching"""
return hashlib.sha256(image_data).hexdigest()
def cache_key(self, image_hash: str, prompt: str) -> str:
"""Generate cache key from image hash and prompt"""
prompt_hash = hashlib.md5(prompt.encode()).hexdigest()
return f"gemini_cache:{image_hash}:{prompt_hash}"
def get_cached_result(self, image_data: bytes, prompt: str) -> Optional[Dict]:
"""Retrieve cached analysis result"""
image_hash = self.get_image_hash(image_data)
cache_key = self.cache_key(image_hash, prompt)
cached = self.redis.get(cache_key)
if cached:
result = json.loads(cached)
result['from_cache'] = True
return result
return None
def cache_result(self, image_data: bytes, prompt: str, result: Dict):
"""Cache analysis result"""
image_hash = self.get_image_hash(image_data)
cache_key = self.cache_key(image_hash, prompt)
# Add cache metadata
result['cached_at'] = datetime.utcnow().isoformat()
result['from_cache'] = False
self.redis.setex(cache_key, self.ttl, json.dumps(result))
def get_cache_stats(self) -> Dict:
"""Get cache performance statistics"""
cache_keys = self.redis.keys("gemini_cache:*")
total_keys = len(cache_keys)
total_size = sum(self.redis.memory_usage(key) for key in cache_keys)
return {
"total_cached_items": total_keys,
"total_memory_usage_mb": total_size / (1024 * 1024),
"average_item_size_kb": (total_size / total_keys / 1024) if total_keys > 0 else 0
}
# Enhanced image analysis with caching
def cached_image_analysis(image_path: str, prompt: str, cache: ImageAnalysisCache) -> Dict:
"""Image analysis with intelligent caching"""
# Load image data
with open(image_path, 'rb') as f:
image_data = f.read()
# Check cache first
cached_result = cache.get_cached_result(image_data, prompt)
if cached_result:
return cached_result
# Process with Gemini 2.5 Flash
result = robust_image_analysis(image_path, prompt)
# Cache successful results
if result.get('success'):
cache.cache_result(image_data, prompt, result)
return result
# Usage with caching
cache = ImageAnalysisCache(redis_client, ttl=7200) # 2-hour cache
result = cached_image_analysis("product.jpg", "Identify product category", cache)
if result.get('from_cache'):
print("Result served from cache")
else:
print("Fresh analysis completed")
# Monitor cache performance
stats = cache.get_cache_stats()
print(f"Cache contains {stats['total_cached_items']} items using {stats['total_memory_usage_mb']:.2f} MB")Production Deployment Considerations
Deploying Gemini 2.5 Flash in production environments requires attention to infrastructure, monitoring, and scaling considerations. Container orchestration platforms like Kubernetes provide the necessary flexibility for handling variable workloads and ensuring high availability.
For organizations requiring enhanced reliability and enterprise support, services like laozhang.ai provide managed API access with additional features including enhanced rate limits, dedicated support channels, and custom integration assistance. This can be particularly valuable for mission-critical applications where downtime costs exceed the premium for managed services.
Load balancing strategies should account for the asynchronous nature of image processing. Implementing circuit breakers prevents cascade failures when the API experiences temporary issues, while health checks ensure traffic routes only to healthy service instances.
Security and Compliance Framework
Enterprise applications must implement comprehensive security measures for handling sensitive image data. This includes encryption in transit and at rest, secure API key management, and audit logging for compliance requirements.
Key security considerations include implementing proper authentication flows, encrypting sensitive image content before API transmission, and maintaining detailed audit trails. For industries with strict compliance requirements, consider implementing data residency controls and ensuring all image processing occurs within approved geographical boundaries.
Troubleshooting Common Gemini API Issues
Common integration challenges include authentication failures, quota management, and handling large image files. Authentication issues typically stem from incorrect API key configuration or expired credentials. Implementing proper credential rotation and monitoring helps prevent service disruptions.
Quota management requires proactive monitoring of usage patterns and implementing graceful degradation when limits approach. Consider implementing priority queues for critical requests and background processing for non-urgent analysis tasks.
Large image handling requires careful preprocessing to balance quality and performance. Images larger than 20MB should be compressed or resized before transmission, while maintaining sufficient detail for accurate analysis.
Future Gemini API Development and Roadmap
Google continues evolving the Gemini platform with regular updates and new capabilities. Staying current with API changes requires subscribing to official documentation updates and testing new features in development environments before production deployment.
The multimodal AI landscape evolves rapidly, with new models and capabilities emerging regularly. Building flexible architectures that can adapt to new APIs and model versions ensures long-term maintainability and enables taking advantage of performance improvements and new features as they become available.
Consider implementing A/B testing frameworks to evaluate new model versions against current implementations. This approach allows measuring performance improvements and ensuring new features meet your application’s specific requirements before full deployment.
Conclusion and Best Practices Summary
Gemini 2.5 Flash Image Preview API represents a significant advancement in accessible multimodal AI capabilities. Its optimized architecture delivers enterprise-grade performance at competitive pricing, making it suitable for a wide range of production applications from e-commerce product analysis to document processing and content moderation.
Successful implementation requires attention to cost optimization through efficient image preprocessing and targeted prompting, robust error handling with retry logic, intelligent caching for frequently processed content, and comprehensive monitoring for performance optimization. Enterprise deployments benefit from implementing API gateway patterns, authentication frameworks, and scaling strategies appropriate for expected workload patterns.
For organizations seeking enhanced reliability and support, managed services like laozhang.ai provide additional value through dedicated infrastructure, extended rate limits, and enterprise support channels. This approach can significantly reduce implementation time and operational overhead while ensuring optimal performance for business-critical applications.
The key to maximizing value from Gemini 2.5 Flash lies in understanding its capabilities, implementing appropriate integration patterns, and continuously optimizing based on real-world usage patterns and performance metrics.