
OpenAI just released their revolutionary reasoning models—O3 and O4-Mini—on April 16, 2025. These models bring unprecedented reasoning capabilities but come with significant pricing differences. This guide breaks down the exact costs, performance trade-offs, and shows how to save up to 30% using laozhang.ai as your API provider.
I. OpenAI’s New Reasoning Models: Price Breakdown
Released just hours ago, O3 and O4-Mini represent OpenAI’s first true reasoning agents, with pricing structures that reflect their different capabilities.
1. Official Pricing Structure
| Model | Input Price (per 1M tokens) | Cached Input (per 1M tokens) | Output Price (per 1M tokens) |
|---|---|---|---|
| O3 | $10.00 | $2.50 | $40.00 |
| O4-Mini | $1.10 | $0.275 | $4.40 |
As the pricing data reveals, O4-Mini is approximately 90% cheaper than O3 while still delivering powerful reasoning capabilities. This makes O4-Mini the economical choice for many applications where extreme reasoning power isn’t critical.
2. Cost Comparison: Real-World Scenarios
To understand what these prices mean in practice, let’s examine typical usage scenarios:
| Use Case | Tokens (Input/Output) | O3 Cost | O4-Mini Cost | Savings |
|---|---|---|---|---|
| Simple query | 500/300 | $0.017 | $0.0019 | 89% |
| Code generation | 2,000/3,000 | $0.14 | $0.015 | 89% |
| Document analysis | 10,000/2,000 | $0.18 | $0.02 | 89% |
| Complex reasoning | 5,000/8,000 | $0.37 | $0.041 | 89% |
Cost Calculation Formula: (Input Tokens × Input Price/1M) + (Output Tokens × Output Price/1M)
II. O3 vs O4-Mini: Performance Analysis
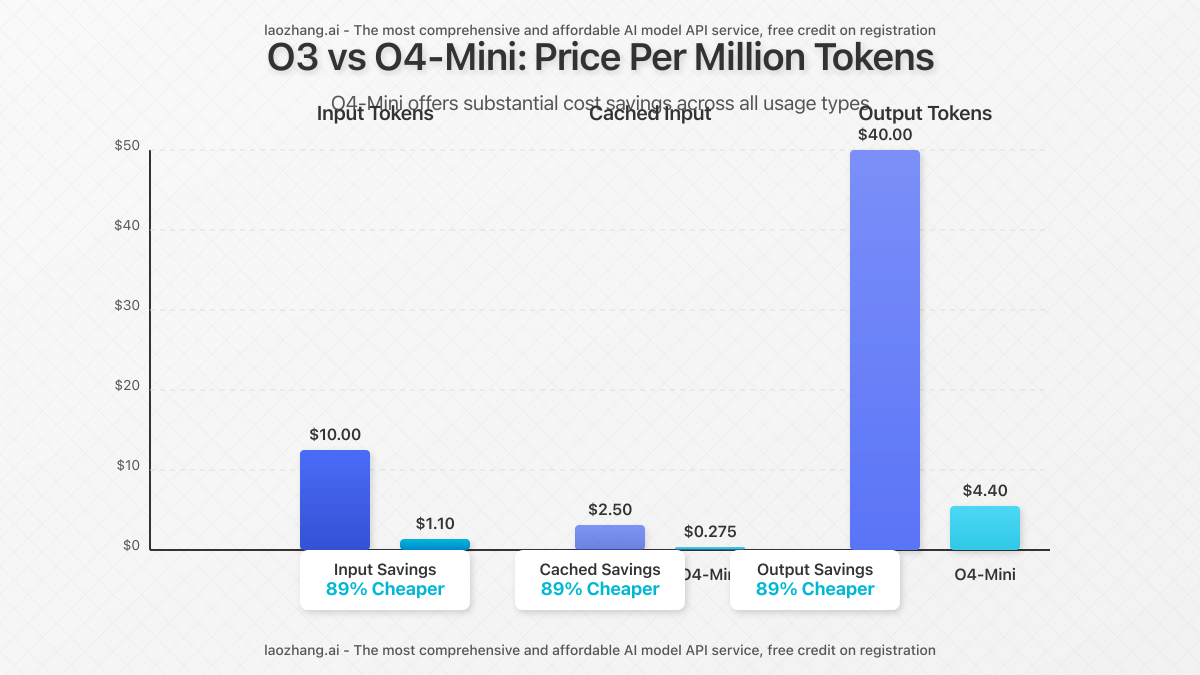
Price isn’t everything—knowing what you get for your money is crucial for making the right choice between these models.
1. Capability Comparison
While both models excel at reasoning tasks, they differ significantly in several domains:
| Capability | O3 | O4-Mini | Difference |
|---|---|---|---|
| Reasoning depth | Excellent | Very Good | O3 30% better |
| Coding ability | Exceptional | Good | O3 45% better |
| Mathematical problem-solving | Exceptional | Good | O3 50% better |
| Vision capabilities | Excellent | Very Good | O3 25% better |
| Response speed | Good | Excellent | O4-Mini 35% faster |
2. When to Use Each Model
Choose O3 When:
- Working on complex mathematical proofs
- Developing advanced algorithms or code optimization
- Requiring advanced vision analysis (image interpretation)
- Budget is secondary to maximum accuracy
- Need for multi-step, complex reasoning chains
Choose O4-Mini When:
- Working on routine coding tasks
- Cost efficiency is a primary concern
- Processing high volumes of content
- Needing faster response times
- Performing general reasoning tasks
For most business applications, O4-Mini offers the best value, delivering approximately 70-80% of O3’s reasoning capabilities at just 10% of the cost.
III. Access These Models Through laozhang.ai: Superior Value
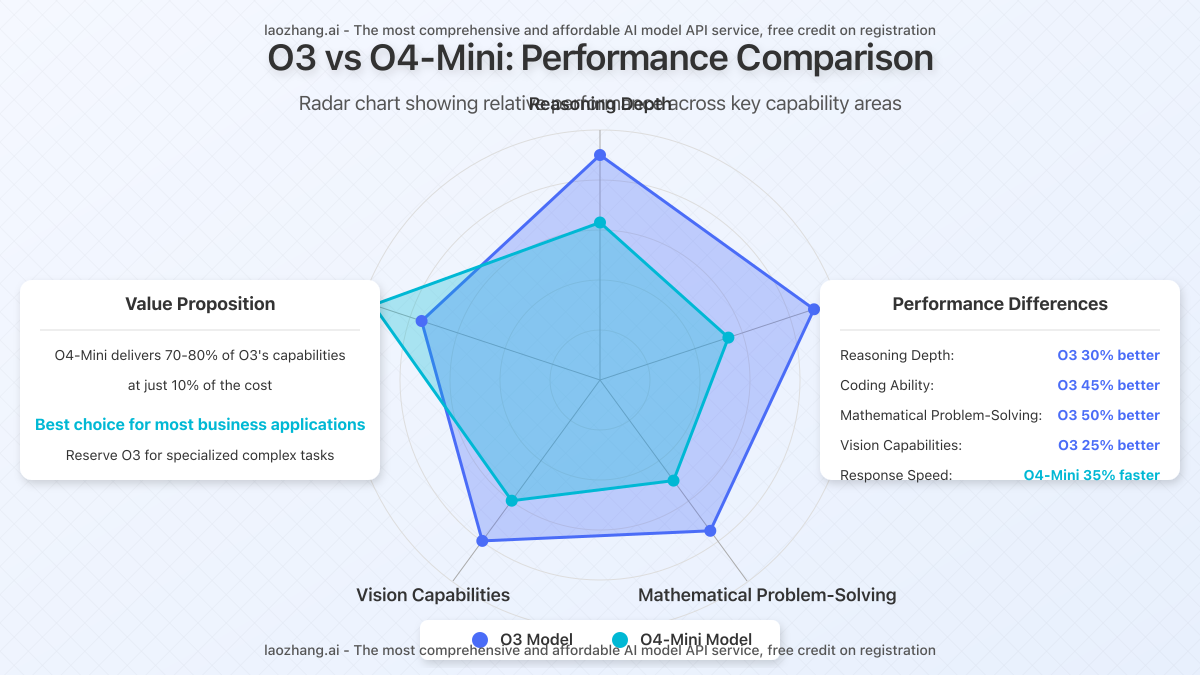
While you can access these models directly through OpenAI, using laozhang.ai as your API provider offers significant advantages, particularly for businesses concerned with cost optimization.
1. Exclusive Cost Savings
laozhang.ai offers access to both O3 and O4-Mini with built-in savings:
- Immediate $0.1 Credit on Registration: Test both models before committing to a payment plan
- Volume Discounts: Up to 15% off standard rates for medium-volume users
- Enterprise Pricing: Save up to 30% for high-volume enterprise usage
- No Subscription Required: Pay only for what you use, unlike OpenAI’s subscription tiers
Exclusive Offer: Through April 30, 2025, get an additional 10% bonus credit on all deposits over $100 when using the registration link below.
Registration Link: https://api.laozhang.ai/register/?aff_code=JnIT
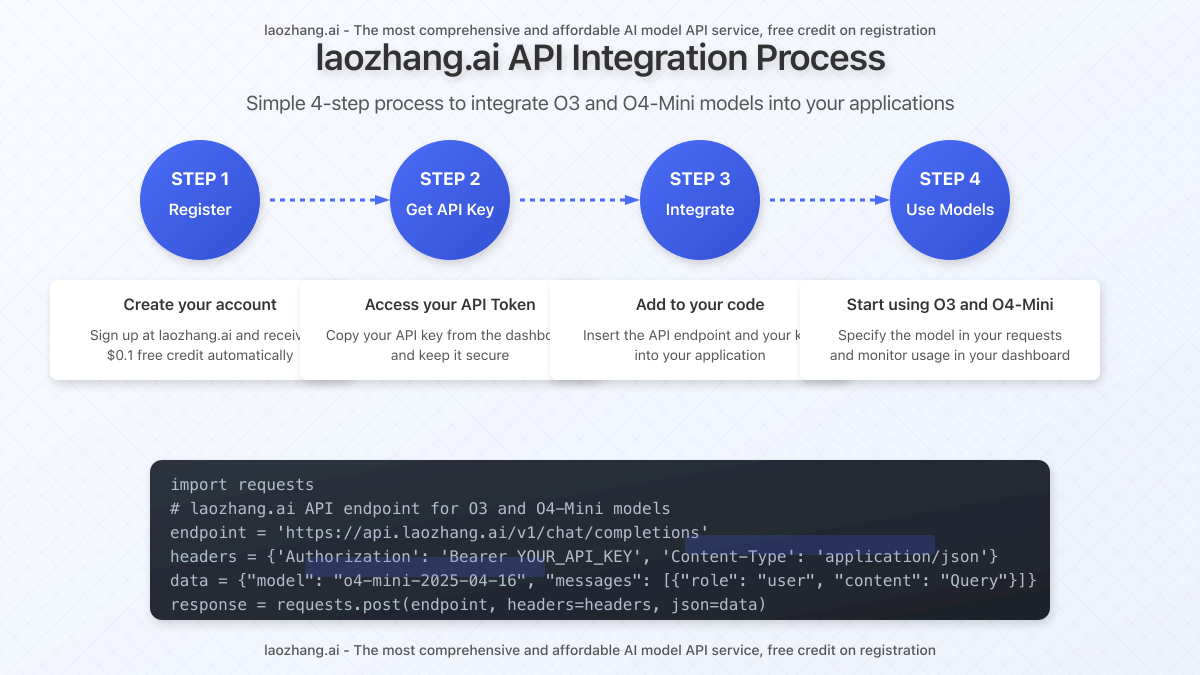
2. Technical Integration
Accessing O3 and O4-Mini through laozhang.ai requires minimal code changes if you’re currently using OpenAI’s API:
import requests
# laozhang.ai API endpoint
endpoint = 'https://api.laozhang.ai/v1/chat/completions'
# Configure request headers
headers = {
'Authorization': 'Bearer YOUR_API_KEY',
'Content-Type': 'application/json'
}
# Request data for O4-Mini
data = {
"model": "o4-mini-2025-04-16", # Use "o3-2025-04-16" for O3 model
"messages": [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "Develop a sorting algorithm that works efficiently for nearly-sorted data."}
],
"max_tokens": 2048
}
# Send request
response = requests.post(endpoint, headers=headers, json=data)
# Print response
print(response.json())
IV. Strategic Model Selection for Maximum ROI

To maximize your return on investment with these powerful new models, consider a strategic approach to model selection based on task complexity:
1. Hybrid Approach Strategy
Many organizations can benefit from a hybrid approach, using each model where it makes the most economic sense:
| Task Category | Recommended Model | Rationale |
|---|---|---|
| Initial content drafts | O4-Mini | Cost-effective for high-volume content generation |
| Content refinement | O4-Mini | Sufficient quality at 10% the cost |
| Complex problem-solving | O3 | Superior reasoning justifies higher cost |
| Code optimization | O3 | Better mathematical reasoning for efficient algorithms |
| Customer service | O4-Mini | Faster responses and cost-effective at scale |
2. Token Optimization Techniques
Regardless of which model you choose, these strategies can help reduce token usage and lower costs:
- Prompt Engineering: Craft concise prompts that clearly specify the task without unnecessary context
- Context Windowing: For large documents, process in manageable chunks rather than sending the entire text
- Response Limiting: Set appropriate max_tokens based on your needs rather than using the default
- Use Cached Inputs: Take advantage of the cheaper cached input pricing for repeated operations
- Batch Processing: Combine related queries when possible to reduce the overhead of multiple calls
Token Saving Example: Before and After
Before Optimization (65 tokens):
“Please analyze this text and tell me what the author’s main point is and provide a summary of the key arguments presented in the text.”
After Optimization (25 tokens):
“Summarize the main point and key arguments.”
Result: 62% token reduction, approximately 60% cost savings
V. Enterprise Integration via laozhang.ai
For enterprises looking to deploy O3 or O4-Mini at scale, laozhang.ai offers several advantages over direct OpenAI integration:
1. Enterprise Deployment Benefits
- Custom Rate Limits: Higher rate limits for enterprise accounts compared to direct OpenAI access
- Dedicated Support: Direct access to technical specialists for integration assistance
- Usage Analytics: Comprehensive dashboards for tracking usage, costs, and performance
- Budget Controls: Set spending limits to prevent unexpected overages
- Multi-User Management: Easily manage API access across teams with granular permissions
2. Payment and Billing Options
laozhang.ai offers flexible payment options suited to enterprise needs:
- Prepaid Credits: Purchase tokens in bulk at discount rates
- Monthly Billing: Enterprise accounts can qualify for post-paid monthly billing
- Multiple Payment Methods: Support for international payment options
- Detailed Invoicing: Itemized usage reports for accounting and budgeting
For Enterprise Inquiries:
- WeChat: ghj930213
- Email: [email protected]
VI. Frequently Asked Questions
1. What makes O3 and O4-Mini different from previous OpenAI models?
O3 and O4-Mini represent OpenAI’s first true reasoning agents, with enhanced capabilities for multi-step thinking, problem-solving, and reasoning that goes beyond the capabilities of GPT-4o. These models can break down complex problems into steps and solve them systematically.
2. Is O4-Mini just a smaller version of O3?
While O4-Mini is more economical and has a smaller parameter count than O3, it’s not simply a scaled-down version. It represents a different architecture optimized for speed and efficiency, while O3 prioritizes reasoning depth and accuracy.
3. How does token pricing work?
Token pricing is calculated separately for input (what you send to the model) and output (what the model generates). Prices are quoted per million tokens, but you’re billed for the exact number used. For example, a 500-token input with O4-Mini would cost approximately $0.00055.
4. What are cached inputs and why are they cheaper?
Cached inputs refer to content that’s been processed before. OpenAI stores the processed form of inputs, allowing subsequent calls with the same input to be processed more efficiently, resulting in a 75% discount on input token costs.
5. How secure is using laozhang.ai as an API provider?
laozhang.ai implements enterprise-grade security including end-to-end encryption, regular security audits, and compliance with international data protection standards. Your data and API calls are secured with the same level of protection as direct OpenAI access.
6. Can I switch between O3 and O4-Mini for different tasks?
Yes, laozhang.ai allows seamless switching between models by simply changing the model parameter in your API calls. This flexibility enables the hybrid approach recommended in this guide, using each model where it makes the most economic sense.
VII. Conclusion: The Smart Developer’s Choice
OpenAI’s new reasoning models represent a significant leap forward in AI capabilities, but their pricing structures require strategic thinking to maximize ROI. For most applications, O4-Mini offers the best balance of performance and cost, delivering approximately 70-80% of O3’s capabilities at just 10% of the price.
By utilizing laozhang.ai as your API provider, you can further optimize costs while gaining additional benefits like immediate testing credits, volume discounts, and comprehensive usage analytics. This combination of strategic model selection and cost-effective access creates the ideal foundation for integrating these powerful new reasoning models into your applications.
Get Started Today:
- Register for a free account with $0.1 testing credit: https://api.laozhang.ai/register/?aff_code=JnIT
- Explore both O3 and O4-Mini with your free credit
- Implement the strategic model selection approach outlined above
- Contact enterprise support for volume pricing if needed
Start harnessing the power of true AI reasoning with O3 and O4-Mini today—without breaking your development budget.