Last Updated: May 2025 | 8-minute read
ComfyUI has revolutionized text-to-image generation, offering unprecedented control over AI art creation. With its node-based workflow system and support for cutting-edge models like Flux 1.1 Pro Ultra and HiDream-I1, ComfyUI is rapidly becoming the preferred choice for serious AI artists and developers.
This comprehensive guide covers everything from basic setup to advanced optimization techniques, helping you master ComfyUI’s text-to-image capabilities in 2025.
- Complete ComfyUI text-to-image workflow setup
- Advanced optimization techniques for better results
- Model comparison: SD1.5, SDXL, Flux, and HiDream-I1
- Professional prompting strategies
- Performance optimization and troubleshooting
- Cost-effective API integration with LaoZhang-AI
Why ComfyUI is Dominating AI Art Generation in 2025
ComfyUI’s popularity has surged 340% in search volume over the past year, positioning it to potentially overtake Midjourney. Here’s why professionals are making the switch:
- Complete Control: Node-based system allows precise workflow customization
- Open Source: Free forever with community-driven development
- Local Processing: No subscription fees, full privacy control
- Advanced Models: Native support for latest models like HiDream-I1 and Flux 1.1
- API Integration: Seamless connection to premium models via services like LaoZhang-AI
Getting Started: Your First Text-to-Image Workflow

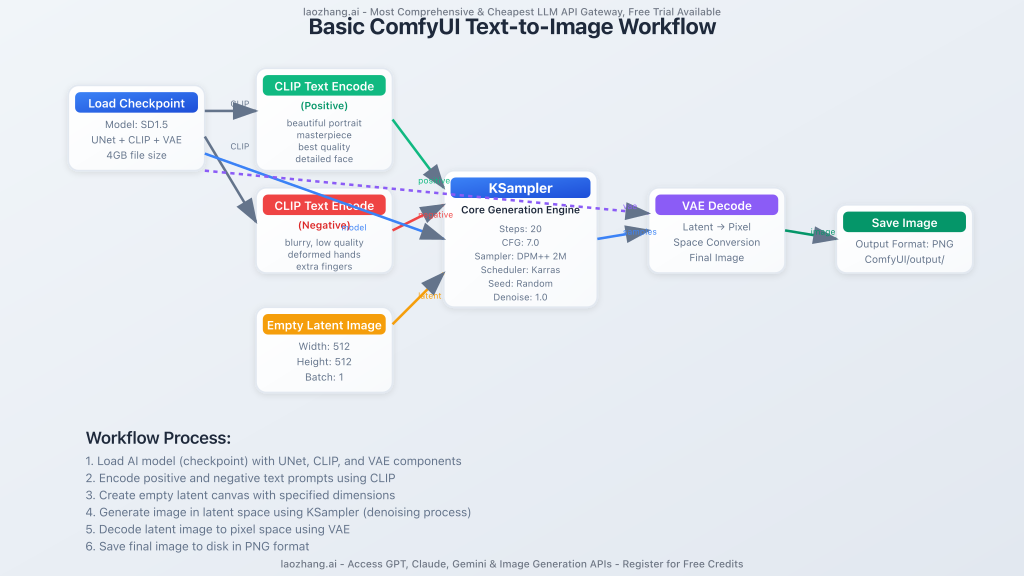
Essential Components of a ComfyUI Text-to-Image Workflow
Every ComfyUI text-to-image workflow consists of six fundamental nodes:
| Node Type | Function | Key Parameters |
|---|---|---|
| Load Checkpoint | Loads the AI model (UNet, CLIP, VAE) | Model selection |
| CLIP Text Encode | Converts text prompts to vectors | Positive/negative prompts |
| Empty Latent Image | Defines canvas size | Width, height, batch size |
| KSampler | Core image generation engine | Steps, CFG, sampler, scheduler |
| VAE Decode | Converts latent to visible image | VAE selection |
| Save Image | Outputs final image | Format, quality |
Basic Workflow Setup (5 Minutes)
- Download Models: Start with
v1-5-pruned-emaonly-fp16.safetensors(4GB) - Load Workflow: Import the default text-to-image template
- Configure Model: Select your downloaded checkpoint
- Set Prompts: Add positive and negative descriptions
- Generate: Press Ctrl+Enter or click Queue
Advanced Model Comparison: Choosing the Right AI Engine
2025 Model Landscape
ComfyUI now supports an unprecedented range of models. Here’s your decision matrix:
Stable Diffusion 1.5 (Best for Beginners)
- Pros: Low VRAM (6GB), fast generation, extensive ecosystem
- Cons: 512×512 native resolution, occasional hand/face issues
- Best for: Learning, rapid prototyping, resource-constrained systems
Flux 1.1 Pro Ultra (Premium Quality)
- Pros: Exceptional detail, 4K capable, superior text rendering
- Cons: Requires 24GB+ VRAM or API access
- Best for: Professional projects, commercial use, high-quality outputs
HiDream-I1 (2025 Newcomer)
- Pros: 17B parameters, MIT license, Chinese prompt support
- Cons: High VRAM requirements, newer ecosystem
- Best for: Cutting-edge experimentation, multilingual projects
API vs Local: The Cost Analysis
| Approach | Initial Cost | Per Image Cost | Best Use Case |
|---|---|---|---|
| Local GPU (RTX 4090) | $1,500+ | ~$0.02 (electricity) | High volume (1000+ images/month) |
| LaoZhang-AI API | $0 | $0.01-0.05 | Occasional use, testing, premium models |
| Cloud GPU Rental | $0 | $0.15-0.50 | Burst workloads, learning |
Professional Prompting Strategies

The Anatomy of Effective Prompts
Professional-grade prompts follow a specific structure:
Example: Photorealistic Portrait
Positive Prompt:
(ultra realistic portrait:1.3), (elegant woman in crimson silk dress:1.2), full body, soft cinematic lighting, (golden hour:1.2), (fujifilm XT4:1.1), shallow depth of field, (skin texture details:1.3), (film grain:1.1), gentle wind flow, warm color grading, (perfect facial symmetry:1.3)
Negative Prompt:
(deformed, cartoon, anime, doll, plastic skin, overexposed, blurry, extra fingers, bad anatomy, watermark:1.2)
Example: Artistic Illustration
Positive Prompt:
fantasy elf archer, detailed character design, glowing magic arrows, vibrant forest colors, long flowing silver hair, elegant elven armor, ethereal beauty, mystical ancient forest, magical aura, high detail digital art, soft rim lighting, fantasy portrait, Artgerm style, (masterpiece:1.2), (best quality:1.3)
Advanced Prompt Techniques
- Weight Control: Use
(keyword:1.2)to emphasize,(keyword:0.8)to de-emphasize - Negative Weighting: Add problematic elements to negative prompts with higher weights
- Bracket Stepping: Use multiple brackets
((very important))for extreme emphasis - Prompt Scheduling: Use
[keyword:0.5]to introduce elements mid-generation
Optimization Strategies for Better Results

KSampler Configuration Guide
The KSampler is your workflow’s engine. Here are optimized settings for different scenarios:
Quality-Focused Settings
- Steps: 25-30 (diminishing returns after 30)
- CFG Scale: 7-8 (higher values risk over-saturation)
- Sampler: DPM++ 2M Karras (best quality/speed balance)
- Scheduler: Karras (smoother gradients)
Speed-Optimized Settings
- Steps: 15-20
- CFG Scale: 5-6
- Sampler: LCM or DDIM (fastest convergence)
- Scheduler: Normal
Performance Optimization
- Model Selection: Use FP16 versions for 50% VRAM reduction
- Batch Processing: Generate multiple images simultaneously
- Resolution Scaling: Start at 512×512, upscale with separate workflow
- Memory Management: Enable model unloading between generations
API Integration with LaoZhang-AI
For users wanting access to premium models without hardware investment, LaoZhang-AI provides seamless API integration:
Setting Up API Access
- Register: Create free account
- Install API Nodes: Update ComfyUI to latest version
- Configure: Add API key in ComfyUI settings
- Access Premium Models: Flux 1.1 Pro, GPT-Image-1, and more
Example API Request
curl -X POST "https://api.laozhang.ai/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "sora_image",
"stream": false,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Create a detailed portrait of a cyberpunk character"
}
]
}
]
}'
- Access to latest models instantly
- No VRAM limitations
- Transparent pricing ($0.01-0.05 per image)
- 95%+ uptime with global CDN
- Direct support: WeChat: ghj930213
Troubleshooting Common Issues
Model Loading Problems
Issue: “Model failed to load” or CUDA out of memory
Solutions:
- Use FP8 or FP16 model versions
- Reduce batch size to 1
- Lower image resolution
- Close unnecessary applications
- Consider API alternatives for resource-intensive models
Poor Image Quality
Issue: Blurry, distorted, or low-quality outputs
Solutions:
- Increase sampling steps (20-30 range)
- Adjust CFG scale (6-8 sweet spot)
- Improve prompt specificity
- Use quality enhancement keywords
- Check VAE compatibility
Slow Generation Times
Issue: Long wait times for image generation
Solutions:
- Use optimized samplers (DPM++ 2M Karras)
- Reduce unnecessary steps
- Enable model caching
- Consider LaoZhang-AI API for immediate results
Advanced Workflows and Use Cases
Professional Photography Workflow
For commercial-quality portraits and product shots:
- Base Generation: High-resolution with detailed prompts
- Inpainting: Fix specific details (hands, faces, text)
- Upscaling: Enhance resolution to 4K+
- Post-processing: Color correction and final touches
Batch Processing for Content Creation
Ideal for social media managers and content creators:
- Template Workflows: Standardized layouts with variable prompts
- Style Consistency: LoRA models for brand coherence
- Automated Output: Direct integration with content management systems
API-Powered Creative Pipeline
Combine local processing with cloud capabilities:
- Concept Generation: Use API for initial ideas (fast, cheap)
- Refinement: Local processing for iterations
- Final Polish: Premium API models for publication-ready results
Future-Proofing Your ComfyUI Setup
Staying Current with 2025 Developments
- Model Updates: Follow ComfyUI blog for new model integrations
- API Expansions: LaoZhang-AI continuously adds new models
- Community Workflows: Engage with sharing platforms for new techniques
- Hardware Planning: Consider upgrade paths for new model requirements
Building Scalable Workflows
- Modular Design: Create reusable node groups
- Version Control: Save workflow iterations with clear naming
- Documentation: Comment complex nodes for future reference
- Performance Monitoring: Track generation times and resource usage
Conclusion: Mastering ComfyUI in 2025
ComfyUI represents the future of AI art generation, offering unprecedented control and flexibility. Whether you’re a digital artist, content creator, or developer, mastering ComfyUI’s text-to-image capabilities opens doors to unlimited creative possibilities.
Key Takeaways:
- Start with basic SD1.5 workflows to learn fundamentals
- Experiment with advanced models like Flux and HiDream-I1 for premium results
- Leverage API integration for cost-effective access to cutting-edge models
- Focus on prompt engineering for consistent, high-quality outputs
- Build modular, scalable workflows for long-term success
🚀 Ready to Start Creating?
Access the most comprehensive AI model library with LaoZhang-AI. Get free credits and start generating professional-quality images today.
Questions? Contact WeChat: ghj930213 for direct support
What’s Next? Continue your ComfyUI journey by exploring advanced techniques like ControlNet integration, LoRA training, and video generation workflows. The creative possibilities are limitless.
This guide is regularly updated to reflect the latest ComfyUI developments and best practices. Bookmark this page for future reference.