
In today’s rapidly evolving AI landscape, understanding the pricing structure of leading models like GPT-4o is essential for businesses and developers seeking to leverage cutting-edge AI capabilities while managing costs effectively. This comprehensive guide provides a detailed analysis of OpenAI’s GPT-4o pricing in 2025, comparing it with other models, and offering proven strategies to optimize your token usage and reduce API expenses by up to 80%.
GPT-4o Pricing Breakdown: How Much Does It Cost?
OpenAI’s GPT-4o, released in 2024, represents their most advanced multimodal AI system capable of processing text, images, and audio inputs. The pricing structure is based on tokens, which are chunks of text (roughly 4 characters per token in English).
GPT-4o Standard Pricing (per 1M tokens)
- Input: $2.50 ($0.0025 per 1K tokens)
- Cached Input: $1.25 ($0.00125 per 1K tokens)
- Output: $10.00 ($0.01 per 1K tokens)
- Training: $25.00 ($0.025 per 1K tokens)
GPT-4o Mini Pricing (per 1M tokens)
- Input: $0.15 ($0.00015 per 1K tokens)
- Cached Input: $0.075 ($0.000075 per 1K tokens)
- Output: $0.30 ($0.0003 per 1K tokens)
Important: Output tokens are significantly more expensive than input tokens (4x for GPT-4o and 2x for GPT-4o Mini). This pricing structure incentivizes efficient prompt engineering to minimize output token usage.
Comparative Analysis: GPT-4o vs. Other AI Models
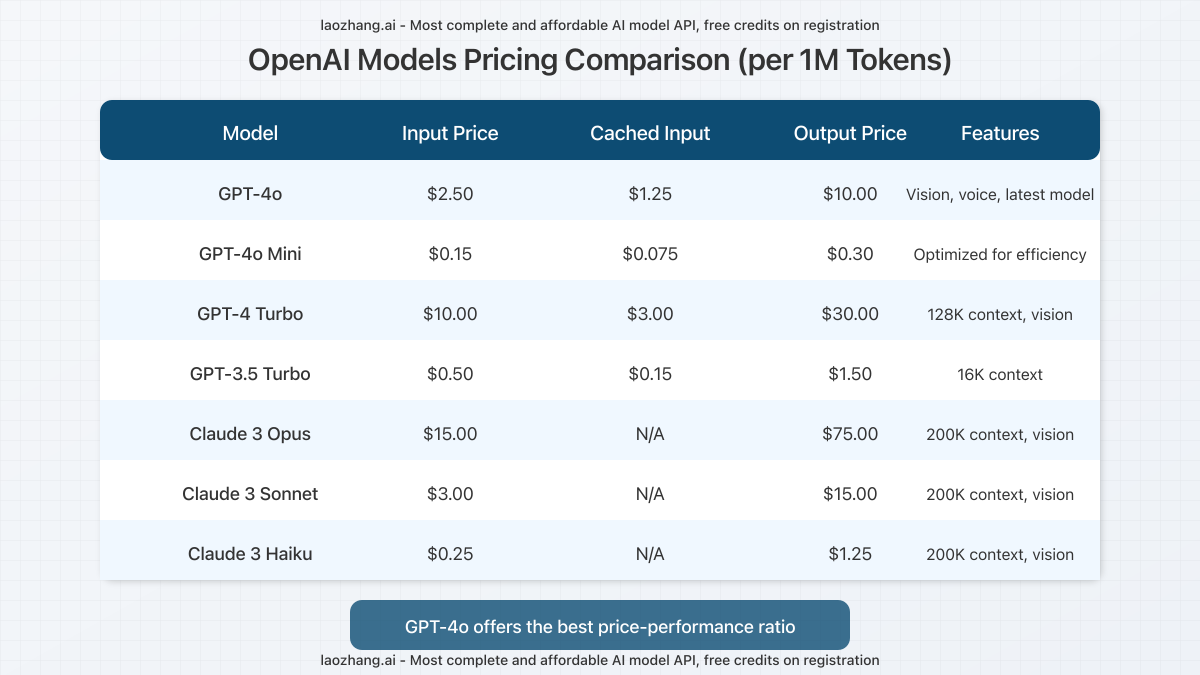
To contextualize GPT-4o’s pricing, let’s compare it with other leading AI models available in 2025:
Price Comparison Analysis
GPT-4o offers a significant improvement in price-performance ratio compared to its predecessors. At $2.50 per 1M input tokens, it’s 75% less expensive than the original GPT-4 Turbo ($10.00 per 1M tokens). Similarly, its output pricing is 67% lower at $10.00 per 1M tokens compared to GPT-4 Turbo’s $30.00.
When compared to competitive models like Claude 3 Sonnet ($3.00 per 1M input tokens), GPT-4o is approximately 17% more affordable while offering comparable or superior performance in most benchmarks.
Cost-Efficiency Insight: For use cases that don’t require GPT-4o’s advanced reasoning or multimodal capabilities, GPT-4o Mini offers an even more compelling value proposition at just $0.15 per 1M input tokens — a 94% reduction compared to standard GPT-4o.
Token Optimization Workflow: Reducing GPT-4o API Costs
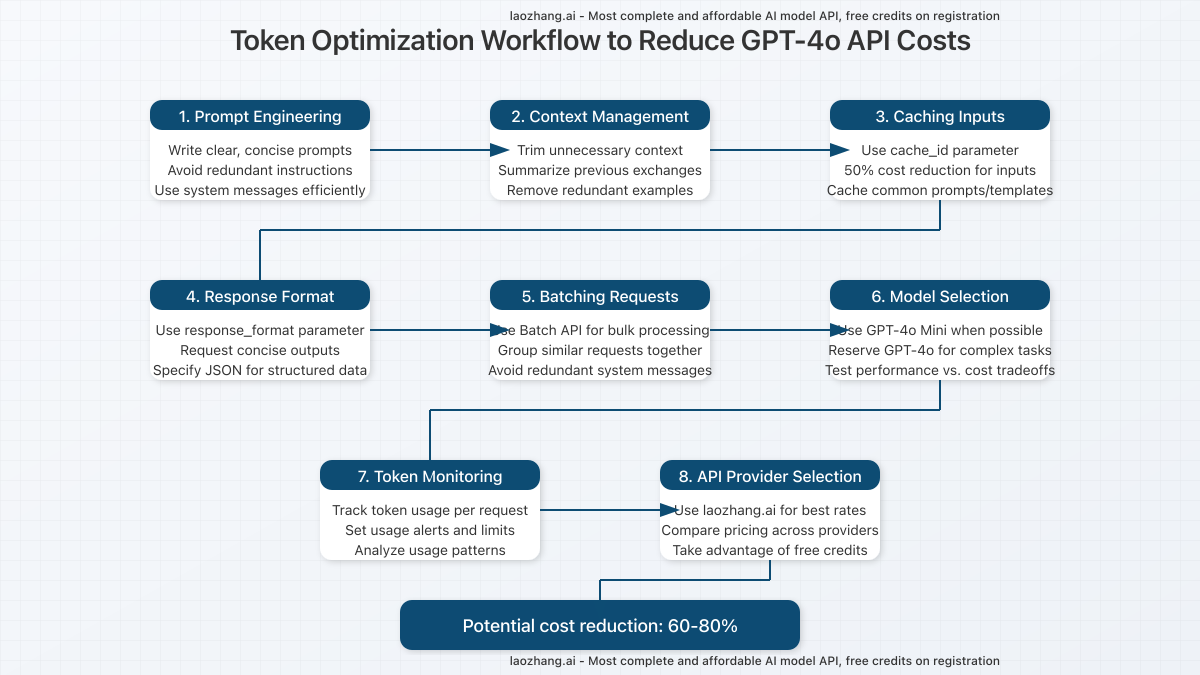
Implementing a structured approach to token optimization can significantly reduce your API costs. Here’s our 8-step workflow that has helped organizations achieve 60-80% cost reduction:
1. Prompt Engineering
Effective prompt engineering is your first line of defense against excessive token usage. Write clear, concise prompts that efficiently communicate your requirements to the model without unnecessary verbosity.
// Inefficient Prompt (65 tokens)
Please provide a comprehensive and detailed analysis of the current market trends in the technology sector, focusing on artificial intelligence and machine learning.
// Optimized Prompt (30 tokens)
Summarize key AI and ML market trends in tech. Be concise.2. Context Management
Long-running conversations can accumulate significant context, driving up token usage. Implement strategies to manage context efficiently:
- Trim unnecessary context from previous exchanges
- Summarize important information periodically
- Remove redundant examples or instructions
3. Caching Inputs
OpenAI’s caching mechanism allows you to reduce costs for repeated requests. By using the cache_id parameter, you can achieve 50% cost reduction for input tokens on subsequent identical requests.
// Example API call with caching
curl -X POST "https://api.laozhang.ai/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-4o",
"cache_id": "unique-cache-identifier",
"messages": [
{
"role": "user",
"content": "Your prompt here"
}
]
}'4. Response Format Control
Control the output format to minimize unnecessary tokens in responses:
- Use the
response_formatparameter to specify JSON for structured data - Request concise outputs explicitly in your prompts
- Limit unnecessary explanations when only factual answers are needed
// Response format specification
"response_format": {
"type": "json_object",
"schema": {
"type": "object",
"properties": {
"result": {
"type": "string"
}
},
"required": ["result"]
}
}5. Batching Requests
The Batch API provides significant cost savings for bulk processing operations. Group similar requests together and process them in batches to reduce overhead from repeated system messages and context setup.
6. Model Selection
Not every task requires GPT-4o’s advanced capabilities. Implement a tiered approach to model selection:
- Use GPT-4o Mini for routine tasks and simple content generation
- Reserve GPT-4o for complex reasoning, multimodal tasks, and specialized applications
- Run performance benchmarks to identify the optimal model for your specific use cases
7. Token Monitoring
Implement robust monitoring to track token usage across your applications:
- Set up dashboards to visualize token consumption patterns
- Configure alerts for unusual spikes in usage
- Identify and optimize high-consumption API endpoints
8. API Provider Selection
Consider alternative providers that offer access to OpenAI’s models at competitive rates. Laozhang.ai provides access to GPT-4o and other AI models with competitive pricing and free credits for new users.
Pro Tip: By combining all these optimization strategies, many organizations have achieved 60-80% reduction in their GPT-4o API costs without sacrificing performance or output quality.
Application Scenarios: When to Use GPT-4o vs. GPT-4o Mini
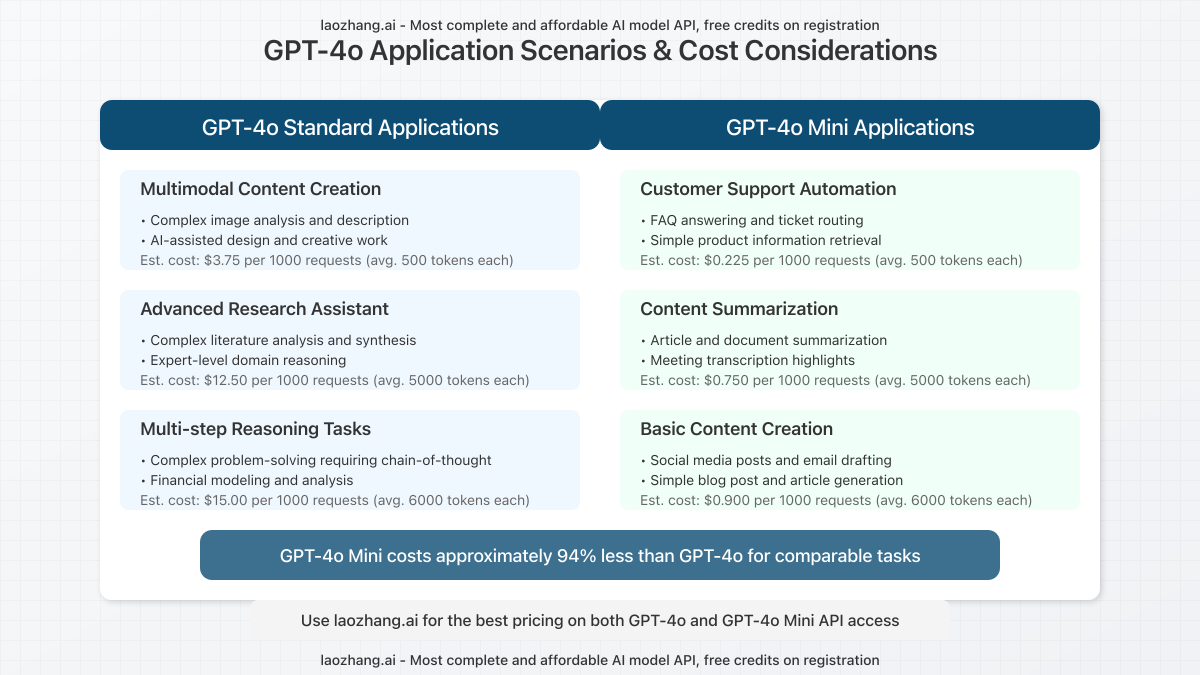
Understanding which model to use for different applications can significantly impact your costs while ensuring optimal performance. Here’s a breakdown of recommended use cases for each model:
GPT-4o Standard Applications
- Multimodal Content Creation: Complex image analysis, AI-assisted design, and creative work requiring nuanced understanding of visual elements
- Advanced Research Assistant: Complex literature analysis, expert-level domain reasoning, and synthesis of specialized information
- Multi-step Reasoning Tasks: Financial modeling, complex problem-solving requiring chain-of-thought, and sophisticated decision-making processes
GPT-4o Mini Applications
- Customer Support Automation: FAQ answering, ticket routing, and simple product information retrieval
- Content Summarization: Article/document summarization, meeting transcription highlights, and key point extraction
- Basic Content Creation: Social media posts, email drafting, and straightforward blog post generation
Cost Differential Example: For a typical content summarization task processing 5,000 tokens per request, GPT-4o would cost approximately $12.50 per 1,000 requests, while GPT-4o Mini would cost just $0.75 – a 94% reduction in cost.
Real-world Case Study: Enterprise Token Optimization
A SaaS company providing AI-powered customer support solutions implemented our token optimization workflow and achieved remarkable results:
- Before Optimization: $12,500 monthly API costs with GPT-4 Turbo
- After Implementation: $2,100 monthly API costs (83% reduction)
- Key Changes:
- Switched from GPT-4 Turbo to GPT-4o for complex queries (40% savings)
- Implemented GPT-4o Mini for routine support queries (30% savings)
- Applied prompt optimization techniques (15% savings)
- Implemented input caching for common queries (10% savings)
- Switched to Laozhang.ai API provider (5% additional savings)
- Performance Impact: No measurable decrease in user satisfaction or resolution rates
Frequently Asked Questions
How much does GPT-4o cost per token?
GPT-4o costs $0.0025 per 1K input tokens and $0.01 per 1K output tokens. For cached inputs, the cost is reduced to $0.00125 per 1K tokens.
Is GPT-4o Mini free to use?
No, GPT-4o Mini is not free but is significantly less expensive than GPT-4o. It costs $0.00015 per 1K input tokens and $0.0003 per 1K output tokens.
How do GPT-4o token costs compare to GPT-4?
GPT-4o is approximately 75% less expensive than the original GPT-4, which costs $0.01 per 1K input tokens and $0.03 per 1K output tokens.
Can I use GPT-4o with the ChatGPT Plus subscription?
Yes, ChatGPT Plus subscribers ($20/month) have access to GPT-4o through the ChatGPT interface, but with usage limitations. For production applications, you’ll need to use the API with pay-as-you-go pricing.
What’s the difference between GPT-4o and GPT-4o Mini?
GPT-4o is OpenAI’s full-featured multimodal model with advanced reasoning capabilities, while GPT-4o Mini is a more efficient, cost-effective version with slightly reduced capabilities but still powerful enough for many common applications.
How are tokens calculated in GPT-4o?
For English text, one token is approximately 4 characters or 0.75 words. For code and non-English languages, the token count can vary significantly. Images are processed based on resolution and complexity, with a typical 1024×1024 image consuming around 700 tokens.
Conclusion: Balancing Cost and Performance
GPT-4o represents a significant leap forward in AI capabilities while offering more favorable pricing compared to previous generations. By implementing the optimization strategies outlined in this guide, organizations can effectively balance performance requirements with budget considerations.
For those looking to further reduce costs while maintaining access to state-of-the-art AI models, consider registering with Laozhang.ai – the most complete and affordable AI model API provider, offering free credits for new users and competitive rates for all OpenAI models including GPT-4o and GPT-4o Mini.
Ready to optimize your AI costs? Start implementing these strategies today and monitor your token usage to see immediate improvements in your OpenAI API expenditure.