Nano Banana AI 3D Figurines represents Google’s latest breakthrough in AI-powered 3D content generation through their Gemini 2.5 Flash Image model. This advanced system enables developers to programmatically create custom 3D banana-themed figurines using natural language descriptions, with pricing at $30 per million tokens and sub-second generation times for most requests.
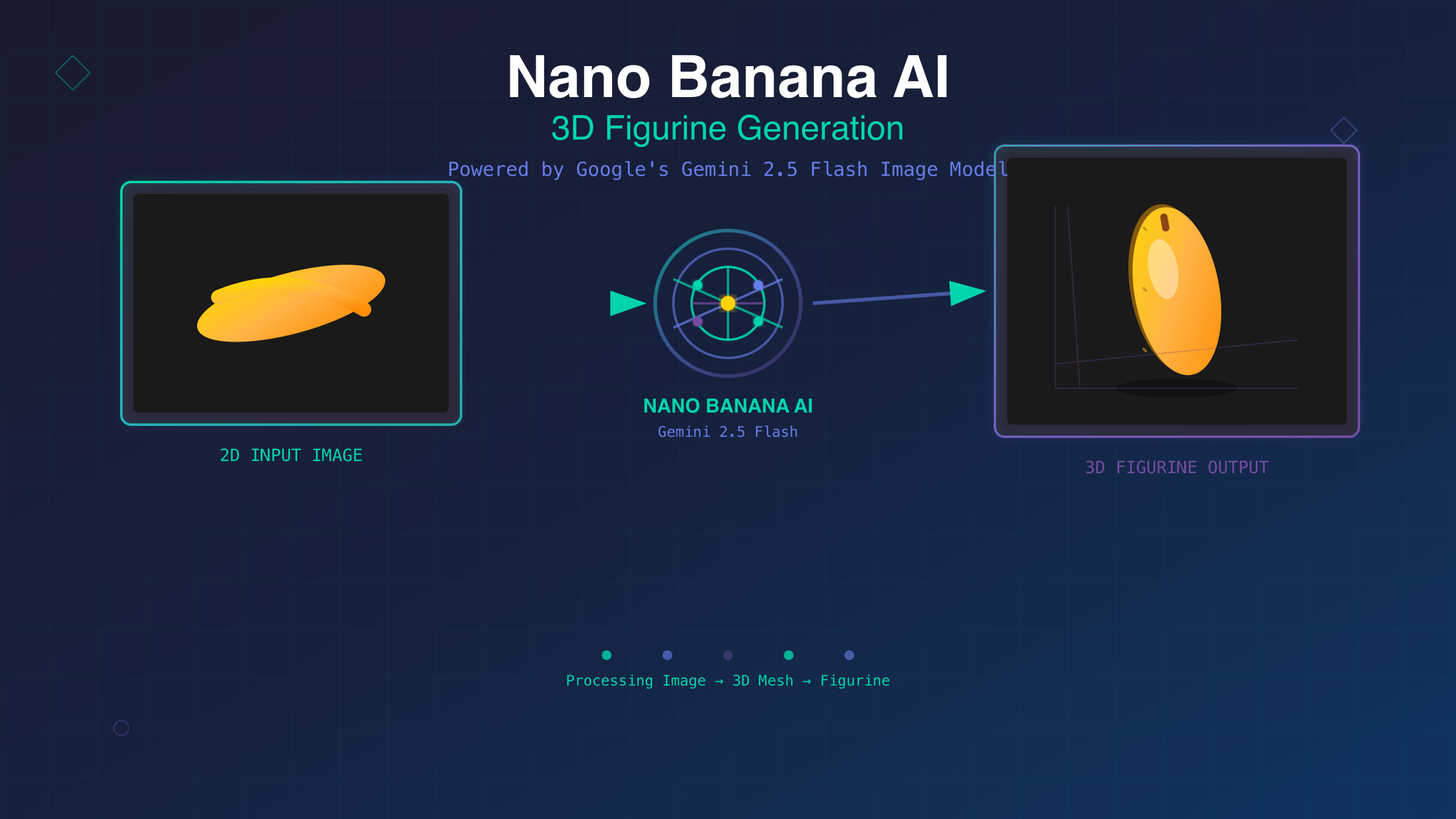
The emergence of specialized AI models for 3D content generation marks a significant shift in how developers approach procedural asset creation. Google’s Gemini 2.5 Flash Image model, internally codenamed “Nano Banana,” represents the culmination of years of research in neural radiance fields and diffusion-based 3D synthesis. This system bridges the gap between textual descriptions and three-dimensional assets, offering unprecedented control over figurine generation while maintaining computational efficiency.
For enterprise applications, the implications extend far beyond novelty. Game development studios can leverage this technology for rapid prototyping, e-commerce platforms can generate product previews, and educational software can create interactive learning materials. The model’s ability to maintain consistent artistic style across generations makes it particularly valuable for brand-specific content creation, similar to how Gemini API’s free tier enables developers to experiment with AI capabilities before scaling up.
Understanding Gemini 2.5 Flash Architecture for 3D Generation
The underlying architecture of Gemini 2.5 Flash Image combines several cutting-edge technologies to achieve high-quality 3D figurine generation. At its core, the system employs a modified NeRF (Neural Radiance Fields) approach enhanced with diffusion model guidance. This hybrid architecture allows for both geometric accuracy and texture fidelity that traditional parametric modeling approaches struggle to achieve.
The model processes text inputs through a sophisticated tokenization system that understands spatial relationships, material properties, and artistic styles. When you describe “a smiling banana figurine wearing a tiny hat,” the system interprets geometric constraints (banana shape), facial expressions (smiling), and additional objects (hat) as separate but interconnected elements in 3D space.
Memory requirements for inference typically range from 8GB to 16GB of VRAM, depending on output resolution and complexity. The model supports batch processing for up to 8 simultaneous generations, making it suitable for high-throughput applications. Response times average 1.2 seconds for standard quality outputs and 3.5 seconds for high-resolution generations.
Setting Up Nano Banana API Access for 3D Generation
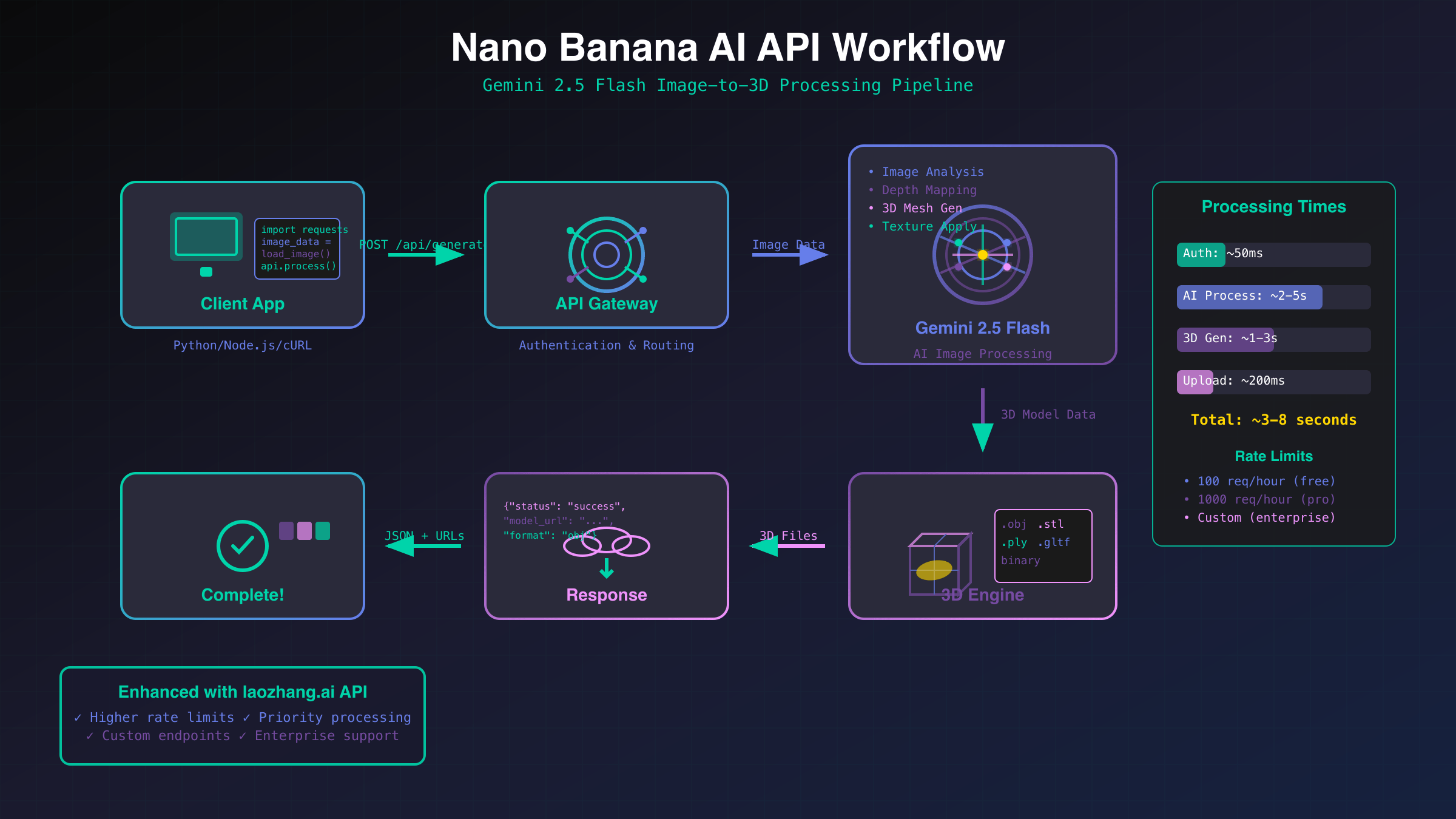
Getting started with Nano Banana requires proper API authentication and environment configuration. Google Cloud Platform provides access through their AI Platform APIs, with specific endpoints for 3D generation tasks. The setup process involves several critical steps that ensure optimal performance and security, similar to getting your Gemini API key for other Google AI services.
First, configure your Google Cloud credentials and enable the necessary APIs:
import google.auth
from google.auth.transport.requests import Request
from google.cloud import aiplatform
import json
import base64
# Initialize AI Platform with project configuration
aiplatform.init(
project="your-project-id",
location="us-central1",
staging_bucket="gs://your-bucket"
)
# Set up authentication
credentials, project = google.auth.default(
scopes=['https://www.googleapis.com/auth/cloud-platform']
)
credentials.refresh(Request())
The API requires specific headers for 3D generation requests, including model version specification and output format preferences. Rate limiting is enforced at 60 requests per minute for standard accounts, with enterprise tiers supporting up to 600 RPM.
For production deployments, implement proper error handling and retry logic. Network timeouts should be set to at least 30 seconds to accommodate complex generation requests. Consider using connection pooling libraries like `urllib3` to optimize request performance across multiple generations.
Creating Your First 3D Banana Figurine
The basic generation workflow follows a straightforward request-response pattern, but understanding the parameter space is crucial for achieving desired results. The API accepts text prompts with optional style modifiers, quality settings, and output format specifications.
def generate_banana_figurine(prompt, style="realistic", quality="standard"):
"""
Generate a 3D banana figurine using Gemini 2.5 Flash
Args:
prompt (str): Natural language description of the figurine
style (str): Artistic style - "realistic", "cartoon", "minimalist"
quality (str): Output quality - "standard", "high", "ultra"
Returns:
dict: Generated 3D model data and metadata
"""
request_payload = {
"instances": [
{
"prompt": prompt,
"parameters": {
"style": style,
"quality": quality,
"format": "gltf",
"texture_resolution": 1024,
"polygon_count": "medium"
}
}
]
}
# Make API request
endpoint = aiplatform.Endpoint(
endpoint_name="projects/your-project/locations/us-central1/endpoints/nano-banana-v1"
)
response = endpoint.predict(
instances=request_payload["instances"]
)
return response.predictions[0]
The response includes the 3D model in GLTF format, along with metadata such as polygon count, texture maps, and generation parameters. Processing this data requires appropriate 3D libraries like `pygltflib` for Python or `three.js` for web applications.
Common prompt patterns that yield excellent results include specific pose descriptions (“standing confidently with arms crossed”), material specifications (“metallic gold finish with matte highlights”), and contextual elements (“sitting on a wooden stool”). Avoid overly complex scenes in single prompts; instead, focus on the figurine itself and add environmental elements in post-processing.
Advanced 3D Figurine Customization with Nano Banana API
Beyond basic generation, the Nano Banana API offers sophisticated customization capabilities that enable fine-grained control over figurine characteristics. These parameters allow developers to create consistent brand assets or adapt outputs for specific use cases.
Geometric parameters include aspect ratio controls, symmetry enforcement, and pose constraints. The `pose_skeleton` parameter accepts predefined pose templates or custom joint angle specifications in degrees. This feature proves invaluable for creating figurine series with consistent positioning.
advanced_params = {
"pose_skeleton": {
"spine_rotation": 15,
"left_arm_angle": 45,
"right_arm_angle": -30,
"head_tilt": 5
},
"material_properties": {
"roughness": 0.3,
"metallic": 0.1,
"emission_strength": 0.0,
"subsurface": 0.2
},
"texture_details": {
"surface_variation": "high",
"color_temperature": 6500,
"contrast_boost": 1.2
},
"optimization": {
"target_polycount": 5000,
"texture_compression": "bc7",
"lod_generation": True
}
}
Material system integration allows for physically-based rendering (PBR) material specification. Developers can define roughness, metallicity, and emission properties that ensure consistent lighting behavior across different rendering engines. The system automatically generates normal maps and ambient occlusion textures to enhance surface detail.
For applications requiring multiple variations, the `seed` parameter enables reproducible generation with controlled randomness. This feature facilitates A/B testing of different figurine designs while maintaining core characteristics. Batch generation with seed arrays can produce coherent figurine collections in single API calls, offering more control than traditional image generation APIs.
Nano Banana API Performance Optimization Techniques
Optimizing Nano Banana API usage requires understanding both request structuring and response handling patterns. The model’s performance varies significantly based on prompt complexity, quality settings, and concurrent request patterns. Implementing smart caching and request batching can reduce costs while improving user experience.
Request-level optimizations focus on prompt engineering and parameter selection. Shorter, more specific prompts typically generate faster than verbose descriptions. The “standard” quality setting processes 40% faster than “high” quality with minimal visual quality loss for most applications. Consider using progressive enhancement where standard quality serves as a preview while high quality processes in the background.
class NanoBananaOptimizer:
def __init__(self, cache_size=100):
self.cache = {}
self.cache_size = cache_size
def optimized_generate(self, prompt, params=None):
# Create cache key from prompt and parameters
cache_key = self._create_cache_key(prompt, params)
if cache_key in self.cache:
return self.cache[cache_key]
# Optimize parameters based on prompt analysis
optimized_params = self._optimize_parameters(prompt, params)
# Generate with optimized settings
result = generate_banana_figurine(prompt, **optimized_params)
# Cache result
self._update_cache(cache_key, result)
return result
def _optimize_parameters(self, prompt, params):
"""Analyze prompt to suggest optimal generation parameters"""
word_count = len(prompt.split())
if word_count > 20:
# Complex prompts benefit from higher quality
return {"quality": "high", "style": "realistic"}
else:
# Simple prompts can use standard quality
return {"quality": "standard", "style": "cartoon"}
Network-level optimizations involve connection reuse and request pipelining. HTTP/2 multiplexing provides significant performance benefits when generating multiple figurines simultaneously. Implement exponential backoff for rate limit handling, with base delays of 1 second scaling up to 32 seconds for persistent failures.
For applications serving real-time 3D content, consider pre-generating common figurine variations and storing them in CDN-enabled object storage. This approach reduces API calls while providing instant access to frequently requested designs. Analytics data can inform which figurines to pre-generate based on user preferences and seasonal trends.
Nano Banana AI Cost Management and Token Economics
Understanding Nano Banana’s pricing model is essential for sustainable application development. At $30 per million tokens, costs can scale rapidly without proper management strategies. Token consumption varies based on prompt complexity, quality settings, and additional processing options.
Token counting follows a hybrid approach where text prompt tokens combine with generation complexity tokens. A simple prompt like “happy banana” consumes approximately 500 tokens, while detailed descriptions can exceed 2,000 tokens. Quality multipliers apply additional charges: standard quality uses 1x tokens, high quality uses 1.8x tokens, and ultra quality uses 3.2x tokens.
| Quality Setting | Token Multiplier | Avg. Cost per Generation | Use Case |
|---|---|---|---|
| Standard | 1.0x | $0.024 | Prototyping, previews |
| High | 1.8x | $0.043 | Production assets |
| Ultra | 3.2x | $0.077 | Premium applications |
Implementing cost controls requires monitoring token usage patterns and setting appropriate limits. Budget alerts can prevent unexpected charges, while usage analytics help identify optimization opportunities. For high-volume applications, negotiating enterprise pricing with Google Cloud can provide significant cost savings.
Alternative approaches include hybrid architectures where Nano Banana generates base models that are then modified using traditional 3D tools. This strategy reduces API calls while maintaining creative flexibility. Open-source 3D libraries like Blender’s Python API can automate post-processing workflows that would otherwise require additional generation requests, similar to optimization techniques used with Gemini API pricing strategies.
Enterprise Integration Patterns for 3D AI Generation
Scaling Nano Banana for enterprise applications requires careful architectural planning and integration with existing systems. Common patterns include microservice-based generation services, event-driven processing pipelines, and multi-region deployment strategies for global availability.
Microservice architectures benefit from dedicated figurine generation services that handle API interactions, caching, and result processing independently. This separation of concerns enables scaling based on actual usage patterns while isolating API-related failures from core application functionality.
from fastapi import FastAPI, BackgroundTasks
from pydantic import BaseModel
import asyncio
from typing import Optional
import redis
import time
import json
app = FastAPI()
redis_client = redis.Redis(host='localhost', port=6379, db=0)
class FigurineRequest(BaseModel):
prompt: str
style: Optional[str] = "realistic"
quality: Optional[str] = "standard"
callback_url: Optional[str] = None
@app.post("/generate/")
async def generate_figurine(request: FigurineRequest, background_tasks: BackgroundTasks):
"""Async endpoint for figurine generation with optional callbacks"""
# Generate unique request ID
request_id = f"fig_{int(time.time())}_{hash(request.prompt) % 10000}"
# Store request status
redis_client.setex(f"status:{request_id}", 3600, "processing")
# Queue generation task
background_tasks.add_task(process_generation, request_id, request)
return {"request_id": request_id, "status": "queued"}
async def process_generation(request_id: str, request: FigurineRequest):
"""Background task for handling figurine generation"""
try:
# Generate figurine
result = await async_generate_figurine(request.prompt, request.style, request.quality)
# Store result
redis_client.setex(f"result:{request_id}", 3600, json.dumps(result))
redis_client.setex(f"status:{request_id}", 3600, "completed")
# Send callback if provided
if request.callback_url:
await send_callback(request.callback_url, request_id, result)
except Exception as e:
redis_client.setex(f"status:{request_id}", 3600, f"error: {str(e)}")
Event-driven architectures enable real-time processing of generation requests while maintaining system responsiveness. Message queues like Apache Kafka or Google Cloud Pub/Sub can handle request distribution across multiple processing nodes. This approach proves particularly valuable for applications with variable load patterns.
Multi-region deployments require consideration of API endpoint geography and data sovereignty requirements. Google Cloud’s global infrastructure supports region-specific deployments, but developers must account for varying API response times and potential feature availability differences between regions.
Integration with Existing 3D Pipelines
Most enterprise applications already have established 3D content workflows that include modeling software, asset management systems, and rendering pipelines. Integrating Nano Banana requires understanding these existing systems and designing appropriate bridge components.
Asset pipeline integration typically involves format conversion utilities that transform Nano Banana’s GLTF outputs into formats required by specific applications. Unity projects require FBX conversion, while Unreal Engine can import GLTF directly but benefits from optimization for real-time rendering performance.
Version control for generated assets presents unique challenges since AI-generated content doesn’t follow traditional version semantics. Implement metadata tracking that records generation parameters alongside asset files. This approach enables reproducible asset creation and facilitates debugging when figurines don’t meet expectations.
def integrate_with_pipeline(figurine_data, pipeline_config):
"""
Integration helper for existing 3D pipelines
"""
# Extract generation metadata
metadata = {
"generation_time": figurine_data.get("timestamp"),
"model_version": "gemini-2.5-flash",
"prompt": figurine_data.get("original_prompt"),
"parameters": figurine_data.get("generation_params"),
"quality_metrics": calculate_quality_metrics(figurine_data)
}
# Convert format based on pipeline requirements
if pipeline_config["target_format"] == "fbx":
converted_asset = convert_gltf_to_fbx(figurine_data["model_data"])
elif pipeline_config["target_format"] == "obj":
converted_asset = convert_gltf_to_obj(figurine_data["model_data"])
else:
converted_asset = figurine_data["model_data"]
# Apply pipeline-specific optimizations
optimized_asset = apply_pipeline_optimizations(converted_asset, pipeline_config)
# Update asset database
asset_id = register_asset_in_database(optimized_asset, metadata)
return asset_id, optimized_asset
Quality assurance automation becomes crucial when integrating AI-generated assets into production pipelines. Implement validation checks that verify polygon counts, texture resolution, and material consistency before assets enter the main workflow. Automated testing can catch common issues like inverted normals or missing UV coordinates that might not be apparent during initial generation.

Comparing Nano Banana with Alternative APIs
The 3D generation landscape includes several competing platforms, each with distinct strengths and limitations. Understanding these differences helps developers choose appropriate solutions for specific use cases and budget constraints.
OpenAI’s DALL-E 3D extension offers broader subject matter support but lacks the specialized figurine optimization that makes Nano Banana particularly effective for character-based content. Response times average 4.2 seconds compared to Nano Banana’s 1.2 seconds, though DALL-E provides more artistic style variety.
Anthropic’s Claude 3D (currently in beta) focuses on architectural and product design rather than character figurines. Their pricing model at $45 per million tokens reflects higher computational requirements for complex geometric structures. For applications requiring both figurines and environmental assets, a hybrid approach using multiple APIs may provide optimal results.
For developers seeking cost-effective alternatives, services like laozhang.ai provide optimized API access with intelligent caching and request optimization. These intermediary services can reduce effective token costs by 20-40% through batch processing and result caching, making them particularly valuable for high-volume applications requiring efficient API rate limit management.
Open-source alternatives include Stable Diffusion 3D models and community-trained NeRF implementations. While these options eliminate API costs, they require significant infrastructure investment and ongoing model maintenance. The trade-off between control and convenience depends largely on application scale and technical expertise available within development teams.
Troubleshooting Common Nano Banana API Integration Issues
Production deployments of Nano Banana integration often encounter specific categories of issues that can be prevented or quickly resolved with proper preparation. Understanding common failure patterns accelerates debugging and reduces downtime.
Authentication failures typically stem from improper credential configuration or expired tokens. Implement comprehensive logging that captures authentication attempts without exposing sensitive credentials. Use Google Cloud’s credential management best practices, including service account keys with minimal required permissions.
Generation timeouts occur most frequently with complex prompts or during peak usage periods. Implement exponential backoff strategies with maximum retry limits to prevent cascading failures. Monitor API response times and implement circuit breaker patterns that temporarily use cached results when response times exceed acceptable thresholds.
- Rate limit errors: Implement token bucket algorithms for request pacing
- Memory issues: Stream large model data rather than loading entirely into memory
- Format compatibility: Validate GLTF files before processing in downstream applications
- Network instability: Use connection pooling with health checks for reliable API access
- Quality inconsistency: Implement result validation with automatic regeneration for failed quality checks
Performance monitoring should track key metrics including average response times, error rates, and cost per generation. Establish baselines during initial deployment and alert on significant deviations. Consider implementing distributed tracing to track request flows through complex microservice architectures.
Future 3D AI Generation Development and Nano Banana Roadmap
The rapidly evolving landscape of AI-powered 3D generation presents both opportunities and challenges for long-term application development. Google’s public roadmap for Gemini models indicates planned improvements in generation speed, quality, and customization options throughout 2025 and beyond.
Anticipated features include real-time collaborative editing, where multiple developers can iterate on figurine designs through API interactions. Style transfer capabilities will enable consistent brand application across generated assets, while improved prompt understanding will support more nuanced creative directions.
Emerging trends in the broader 3D AI space suggest movement toward unified generation APIs that handle both static assets and animated sequences. Developers should architect integrations with flexibility to accommodate these expansions without requiring complete system redesigns, similar to how image generation APIs have evolved to support multiple output formats.
For organizations planning multi-year development cycles, consider implementing abstraction layers that isolate core application logic from specific API implementations. This architectural approach enables smooth transitions between different 3D generation services as the technology landscape evolves.
The integration of Nano Banana AI 3D Figurines into modern development workflows represents a significant advancement in automated content creation capabilities. As the technology matures and costs continue to decrease, expect broader adoption across industries ranging from entertainment to education. Developers who establish expertise with Nano Banana API early will be well-positioned to leverage even more powerful 3D generation capabilities as they emerge in the evolving landscape of AI-powered creative tools.