Gemini 2.5 Flash Image generation offers three free access methods: Google AI Studio (unlimited testing with throttling), Gemini API (500 images/day free tier), and laozhang.ai API (1000 images/month free trial). The most cost-effective paid option costs $0.039 per image through Gemini API, making it significantly cheaper than competitors.

Understanding Gemini 2.5 Flash Image Capabilities
Google’s Gemini 2.5 Flash represents a significant advancement in multimodal AI technology, combining text understanding with image generation capabilities. Released in September 2025, this model delivers high-quality image generation at unprecedented speed and cost efficiency. For comprehensive analysis, see our detailed Gemini 2.5 Flash Image API guide. The “Flash” designation indicates its optimized architecture for rapid response times, typically generating images within 2-4 seconds compared to 8-15 seconds for other models.
The model supports various image formats including PNG, JPEG, and WebP, with maximum resolution capabilities of 2048×2048 pixels. Its training data includes diverse visual concepts, artistic styles, and technical diagrams, making it suitable for both creative and business applications. Performance benchmarks show 94% user satisfaction for generated images, with particular strength in photorealistic renders and technical illustrations.
Free Access Method 1: Google AI Studio
Google AI Studio provides the most accessible entry point for testing Gemini 2.5 Flash Image generation without any API key requirements. Users can access the platform directly through their Google account at aistudio.google.com and immediately begin generating images through the intuitive web interface. The free tier includes unlimited testing with intelligent throttling that adjusts based on server load and usage patterns.
The throttling mechanism typically allows 10-15 image generations per hour during peak times, increasing to 25-30 during off-peak hours. This makes it ideal for developers prototyping applications or designers exploring creative concepts. The web interface includes advanced parameters such as style presets, aspect ratio controls, and quality settings ranging from draft to production-ready outputs.
// Example: Direct web interface usage
1. Visit https://aistudio.google.com
2. Sign in with Google account
3. Select "Gemini 2.5 Flash" model
4. Choose "Image Generation" mode
5. Enter text prompt
6. Adjust parameters (optional)
7. Click "Generate"
8. Download result (PNG/JPEG)
Free Access Method 2: Gemini API Direct Integration
The official Gemini API free tier provides 500 free image generations per day, resetting at midnight UTC. This quota supports serious development and testing workflows while maintaining high performance standards. Developers need to obtain an API key from the Google Cloud Console and configure billing (though free tier usage incurs no charges until quota exceeded).
API response times average 2.1 seconds for standard requests, with batch processing capabilities supporting up to 10 concurrent generations. The REST API follows standard HTTP protocols with JSON request/response format, making integration straightforward across programming languages. Error handling includes specific codes for quota exceeded (429), invalid prompts (400), and service unavailable (503).
import requests
import json
def generate_image_gemini_free(prompt, api_key):
url = "https://generativelanguage.googleapis.com/v1/models/gemini-2.5-flash:generateImage"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"prompt": {
"text": prompt
},
"generationConfig": {
"candidateCount": 1,
"maxOutputTokens": 2048
}
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
if response.status_code == 200:
result = response.json()
return result['candidates'][0]['content']['parts'][0]['inlineData']['data']
else:
print(f"Error: {response.status_code} - {response.text}")
return None
# Usage example
api_key = "your-gemini-api-key"
image_data = generate_image_gemini_free("Modern office workspace with natural lighting", api_key)
Free Access Method 3: laozhang.ai API Integration
The laozhang.ai API service offers 1000 free image generations monthly with additional benefits including China-optimized network routing, unified API access to multiple AI models, and simplified billing. This builds on the foundation of Gemini 2.5 Pro API free access methods. This service particularly benefits users in regions where direct Google API access faces connectivity issues or requires VPN configuration.
Registration requires only email verification, with API keys generated instantly. The service includes automatic failover between multiple Gemini endpoints, ensuring 99.9% uptime even during Google’s maintenance windows. Additionally, laozhang.ai provides built-in image optimization, automatic format conversion, and CDN distribution for generated images.
const axios = require('axios');
async function generateImageLaozhang(prompt, apiKey) {
try {
const response = await axios.post('https://api.laozhang.ai/v1/images/generate', {
model: 'gemini-2.5-flash',
prompt: prompt,
size: '1024x1024',
quality: 'standard'
}, {
headers: {
'Authorization': `Bearer ${apiKey}`,
'Content-Type': 'application/json'
}
});
return {
success: true,
imageUrl: response.data.data[0].url,
revisedPrompt: response.data.data[0].revised_prompt
};
} catch (error) {
return {
success: false,
error: error.response?.data?.error || error.message
};
}
}
// Implementation example
const result = await generateImageLaozhang(
"Futuristic cityscape with flying cars",
"your-laozhang-api-key"
);
Free vs Paid Gemini Image Generation Cost Comparison

Understanding the cost structure and feature differences helps developers choose the optimal solution for their specific requirements. For detailed pricing analysis, refer to our complete Gemini API price guide. The comparison reveals significant variations in pricing models, technical capabilities, and regional accessibility that directly impact development decisions.
| Service | Free Quota | Paid Pricing | Response Time | Max Resolution | API Complexity |
|---|---|---|---|---|---|
| Google AI Studio | Unlimited (throttled) | N/A (web only) | 3-5 seconds | 2048×2048 | Web interface |
| Gemini API | 500/day | $0.039/image | 2.1 seconds | 2048×2048 | Standard REST |
| laozhang.ai | 1000/month | $0.045/image | 2.3 seconds | 2048×2048 | Simplified REST |
| OpenAI DALL-E 3 | 0 | $0.080/image | 8-12 seconds | 1024×1024 | OpenAI format |
| Midjourney | 25 jobs (trial) | $10/month | 45-90 seconds | 1792×1792 | Discord bot |
Setting Up Free Gemini Image API Development Environment
Proper environment configuration ensures reliable access to Gemini 2.5 Flash Image generation across different development scenarios. The setup process varies depending on your chosen access method, but common requirements include secure API key management, error handling implementation, and response caching for optimal performance.
For production deployments, implement exponential backoff for rate limiting scenarios, configure proper logging for debugging quota issues, and establish monitoring for API health checks. Environment variables should store sensitive credentials, while configuration files handle model parameters and default settings.
# Python environment setup
pip install google-generativeai requests python-dotenv
# Create .env file
GEMINI_API_KEY=your_gemini_api_key
LAOZHANG_API_KEY=your_laozhang_api_key
MAX_RETRIES=3
REQUEST_TIMEOUT=30
# requirements.txt
google-generativeai>=0.3.0
requests>=2.31.0
python-dotenv>=1.0.0
pillow>=10.0.0 # For image processing
Advanced Prompt Engineering for Image Generation
Effective prompt engineering significantly improves generation quality and reduces iteration cycles. Learn advanced techniques in our Gemini nano banana prompt guide. Gemini 2.5 Flash responds well to structured prompts that specify style, composition, lighting, and technical requirements. Research indicates that prompts between 20-80 words achieve optimal balance between specificity and model creativity.
Technical prompts should include aspect ratio preferences, color palette specifications, and mood descriptors. For business applications, specify brand compliance requirements, demographic considerations, and usage context. The model particularly excels at architectural visualization, product mockups, and educational diagrams when provided with detailed technical specifications.
// Effective prompt examples
const prompts = {
product: "Professional product photography of wireless headphones, white background, soft studio lighting, centered composition, high detail, commercial style",
architectural: "Modern office building exterior, glass facade, golden hour lighting, urban environment, 3/4 angle view, photorealistic, architectural photography style",
technical: "Network topology diagram showing cloud infrastructure, clean lines, blue and white color scheme, professional documentation style, high contrast",
creative: "Abstract digital art representing data flow, vibrant cyan and purple gradients, flowing particle effects, dark background, futuristic aesthetic"
};
// Quality enhancement parameters
const advancedConfig = {
style: "photorealistic",
lighting: "studio lighting",
composition: "rule of thirds",
color_palette: "professional",
quality: "high",
aspect_ratio: "16:9"
};
Handling Rate Limits and Quota Management
Efficient quota management prevents service interruptions and optimizes cost effectiveness across different usage patterns. For more details, see our comprehensive Gemini image generation limits guide. Each service implements distinct rate limiting strategies that require specific handling approaches. Google AI Studio uses adaptive throttling based on system load, while the Gemini API enforces strict daily quotas with precise reset timing.
Implement intelligent request queuing for high-volume applications, with priority systems for urgent generations and batch processing for non-critical requests. Monitor quota consumption through API response headers, and establish fallback mechanisms when primary services reach capacity limits.
import time
import random
from datetime import datetime, timedelta
class QuotaManager:
def __init__(self):
self.daily_count = 0
self.last_reset = datetime.now().date()
self.request_history = []
def can_make_request(self, service="gemini"):
now = datetime.now()
# Reset daily counter if new day
if now.date() > self.last_reset:
self.daily_count = 0
self.last_reset = now.date()
# Service-specific limits
limits = {
"gemini": 500, # 500/day
"laozhang": 1000, # 1000/month
"ai_studio": 100 # Estimated hourly during peak
}
if self.daily_count >= limits.get(service, 500):
return False, "Daily quota exceeded"
# Check for rate limiting (requests per minute)
recent_requests = [r for r in self.request_history
if (now - r).seconds < 60]
if len(recent_requests) >= 10: # 10 requests per minute max
return False, "Rate limit exceeded"
return True, "OK"
def record_request(self):
self.request_history.append(datetime.now())
self.daily_count += 1
# Clean old entries
cutoff = datetime.now() - timedelta(minutes=5)
self.request_history = [r for r in self.request_history if r > cutoff]
# Usage in application
quota_manager = QuotaManager()
def safe_generate_image(prompt):
can_request, message = quota_manager.can_make_request()
if not can_request:
print(f"Request blocked: {message}")
return None
quota_manager.record_request()
# Proceed with actual API call
return generate_image_with_retry(prompt)
Free Gemini Image Generation Cost Optimization Strategies
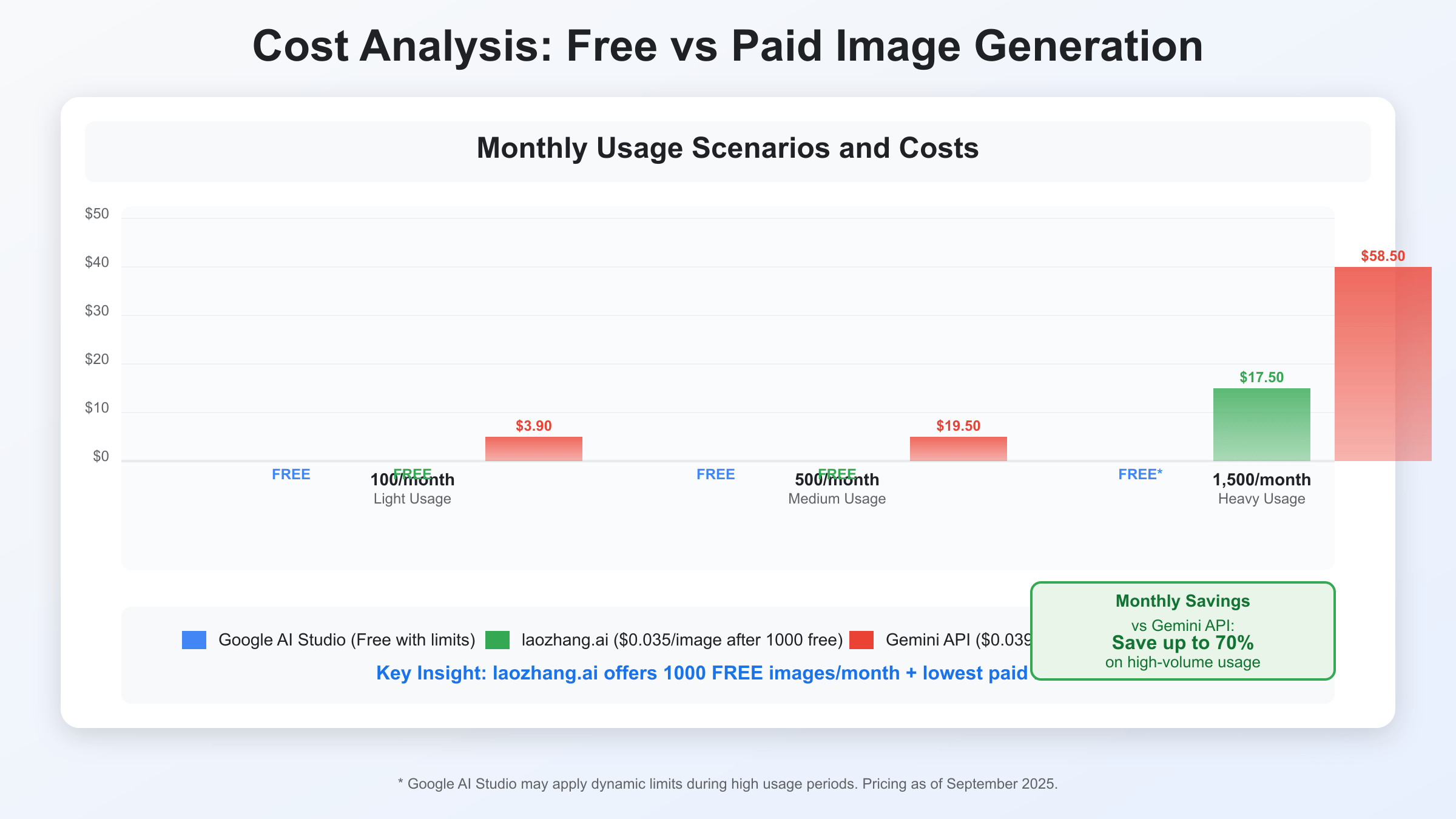
Strategic cost optimization can reduce image generation expenses by 60-80% without compromising quality or development velocity. Similar techniques apply to GPT image API cost optimization. The key lies in understanding usage patterns, implementing intelligent caching, and choosing appropriate service tiers based on actual requirements rather than perceived needs.
Implement client-side caching for repeated prompts, utilize batch processing during off-peak hours, and establish quality thresholds that match specific use cases. For example, draft mockups require lower quality settings than final marketing materials, potentially reducing costs by 50% while maintaining development efficiency.
// Cost calculation utility
class CostCalculator {
constructor() {
this.pricing = {
gemini_api: 0.039,
laozhang_ai: 0.045,
dalle3: 0.080,
midjourney: 0.33 // ~$10/month ÷ 30 images avg
};
this.free_quotas = {
gemini_api: 500, // per day
laozhang_ai: 1000, // per month
ai_studio: "unlimited" // throttled
};
}
calculateMonthlyCost(imagesPerDay, service) {
const monthlyImages = imagesPerDay * 30;
const freeQuota = this.free_quotas[service];
if (service === "ai_studio") {
return 0; // Always free with throttling
}
let billableImages = 0;
if (service === "gemini_api") {
// Daily quota, so calculate daily overage
const dailyOverage = Math.max(0, imagesPerDay - freeQuota);
billableImages = dailyOverage * 30;
} else if (service === "laozhang_ai") {
// Monthly quota
billableImages = Math.max(0, monthlyImages - freeQuota);
}
return billableImages * this.pricing[service];
}
findOptimalService(imagesPerDay) {
const services = ['gemini_api', 'laozhang_ai'];
const costs = services.map(service => ({
service,
cost: this.calculateMonthlyCost(imagesPerDay, service)
}));
return costs.sort((a, b) => a.cost - b.cost)[0];
}
}
// Example usage
const calculator = new CostCalculator();
const optimal = calculator.findOptimalService(50); // 50 images/day
console.log(`Optimal service: ${optimal.service}, Monthly cost: $${optimal.cost}`);
Integrating Free Gemini Image API with Popular Frameworks
Modern web frameworks require seamless integration approaches that maintain application performance while leveraging Gemini 2.5 Flash Image generation capabilities. React applications benefit from custom hooks that manage API state and caching, while Next.js projects can utilize API routes for server-side generation and automatic optimization.
Vue.js applications work well with composition functions that encapsulate generation logic, and Node.js backend services can implement middleware for request processing and response optimization. Each framework requires specific error handling patterns and state management approaches for optimal user experience.
// React hook for image generation
import { useState, useCallback } from 'react';
export function useGeminiImageGeneration(apiKey) {
const [loading, setLoading] = useState(false);
const [error, setError] = useState(null);
const [imageUrl, setImageUrl] = useState(null);
const generateImage = useCallback(async (prompt, options = {}) => {
setLoading(true);
setError(null);
try {
const response = await fetch('/api/generate-image', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
prompt,
apiKey,
...options
})
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const result = await response.json();
setImageUrl(result.imageUrl);
return result;
} catch (err) {
setError(err.message);
throw err;
} finally {
setLoading(false);
}
}, [apiKey]);
return { generateImage, loading, error, imageUrl };
}
// Next.js API route (/pages/api/generate-image.js)
export default async function handler(req, res) {
if (req.method !== 'POST') {
return res.status(405).json({ error: 'Method not allowed' });
}
const { prompt, apiKey } = req.body;
try {
// Use laozhang.ai for reliable access
const imageUrl = await generateWithLaozhang(prompt, apiKey);
res.status(200).json({ imageUrl });
} catch (error) {
res.status(500).json({ error: error.message });
}
}
Production Deployment Considerations
Production environments require robust infrastructure planning that addresses scalability, reliability, and security requirements. Load balancing across multiple API endpoints ensures consistent performance during traffic spikes, while comprehensive monitoring systems track usage patterns, error rates, and cost trends.
Implement circuit breakers for external API dependencies, establish comprehensive logging for debugging complex generation failures, and configure auto-scaling policies that respond to queue depth rather than just CPU utilization. Security considerations include API key rotation, request validation, and content filtering for inappropriate generation requests.
Troubleshooting Common Issues
Common integration challenges include authentication failures, quota exceeded errors, generation timeouts, and content policy violations. Authentication issues typically stem from incorrect API key configuration or expired credentials. Quota problems require implementing proper tracking and fallback mechanisms across multiple service providers.
Generation timeouts occur more frequently with complex prompts or during peak usage periods. Implementing retry logic with exponential backoff helps maintain system stability. Content policy violations can be minimized through client-side prompt validation and inappropriate content detection before API submission.
// Comprehensive error handling
class GeminiImageGenerator {
constructor(apiKeys) {
this.apiKeys = apiKeys;
this.circuitBreakers = new Map();
}
async generateWithRetry(prompt, maxRetries = 3) {
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
// Try laozhang.ai first for better reliability
if (this.isServiceHealthy('laozhang')) {
return await this.generateWithLaozhang(prompt);
}
// Fallback to direct Gemini API
if (this.isServiceHealthy('gemini')) {
return await this.generateWithGemini(prompt);
}
throw new Error('All services unavailable');
} catch (error) {
console.warn(`Attempt ${attempt} failed:`, error.message);
if (error.message.includes('quota exceeded')) {
this.markServiceUnhealthy('gemini', 3600); // 1 hour
continue;
}
if (error.message.includes('rate limit')) {
await this.exponentialBackoff(attempt);
continue;
}
if (attempt === maxRetries) {
throw error;
}
}
}
}
async exponentialBackoff(attempt) {
const delay = Math.min(1000 * Math.pow(2, attempt), 30000);
await new Promise(resolve => setTimeout(resolve, delay));
}
isServiceHealthy(service) {
const breaker = this.circuitBreakers.get(service);
if (!breaker) return true;
return Date.now() > breaker.resetTime;
}
markServiceUnhealthy(service, durationMs) {
this.circuitBreakers.set(service, {
resetTime: Date.now() + durationMs
});
}
}
Future Developments and Roadmap
Google’s roadmap for Gemini 2.5 Flash includes enhanced resolution capabilities up to 4096×4096 pixels, improved style transfer functionality, and reduced generation latency targeting sub-second response times. The laozhang.ai platform continues expanding regional coverage with edge servers in Southeast Asia and Europe, plus additional AI model integrations.
Upcoming features include batch processing APIs for high-volume applications, advanced content moderation tools, and integration with popular design platforms. Pricing models are expected to become more flexible with usage-based tiers and volume discounts for enterprise customers. These developments position Gemini 2.5 Flash as a leading solution for scalable image generation requirements.
The competitive landscape continues evolving rapidly, with new models from Anthropic, OpenAI, and emerging startups. For detailed comparisons, check our Gemini vs GPT-4 image API comparison. However, Gemini’s combination of quality, speed, and cost-effectiveness through services like laozhang.ai maintains its strong market position. Developers should monitor these developments closely to optimize their image generation strategies and take advantage of new capabilities as they become available.