Free Gemini 2.5 Pro API: Complete Access Guide 2025
Access free Gemini 2.5 Pro API through Google AI Studio with 5 RPM and 25 daily requests for development, or leverage laozhang.ai for 75% discount at $0.31/$2.50 per million tokens for production. While Google’s thinking model leads benchmarks with 63.8% on SWE-Bench, alternatives like Vertex AI’s $300 trial, DeepSeek R1 at 30x lower cost, and Llama 4’s 10M context window provide viable options for different use cases.

Google AI Studio: Official Free Gemini 2.5 Pro API Access
Google AI Studio represents the most direct path to accessing Gemini 2.5 Pro without any financial commitment, offering developers immediate access to Google’s most advanced thinking model through a straightforward web interface. The platform provides API keys instantly upon registration with a Google account, eliminating the traditional approval processes and credit card requirements that often gatekeep AI services. This accessibility democratizes advanced AI capabilities, allowing students, researchers, and independent developers to experiment with state-of-the-art language models without financial barriers. The experimental model gemini-2.5-pro-exp-03-25 remains completely free during its preview period, though Google has indicated that pricing will be introduced as the model transitions to general availability.
Setting up Google AI Studio access requires minimal technical overhead, making it ideal for rapid prototyping and development workflows. Navigate to aistudio.google.com, sign in with your Google account, and generate an API key from the dashboard within seconds. The Python SDK installation follows standard package management conventions with pip install google-generativeai, providing a familiar interface for developers already working with Python ecosystems. The SDK abstracts away authentication complexities, handling token refresh and session management automatically while maintaining secure communication with Google’s infrastructure.
The free tier’s limitations of 5 requests per minute and 25 daily requests create significant constraints that developers must carefully navigate. These limits translate to approximately one request every 12 seconds, but real-world performance typically yields only 3 effective requests per minute when accounting for network latency, processing time, and response streaming. The daily quota exhausts within 8 minutes of continuous usage, making the free tier unsuitable for production deployments or applications requiring sustained API access. For a comprehensive understanding of these constraints, see the complete Gemini API rate limits guide. However, these constraints prove adequate for development, testing, and educational purposes where intermittent access suffices.
import google.generativeai as genai
import time
from typing import Dict, Optional
class GeminiAIStudioClient:
"""Production-ready client for Google AI Studio free tier"""
def __init__(self, api_key: str):
genai.configure(api_key=api_key)
self.model = genai.GenerativeModel('gemini-2.5-pro-exp-03-25')
self.request_count = 0
self.daily_count = 0
self.last_request_time = 0
def generate(self, prompt: str, temperature: float = 0.7) -> Dict:
"""Generate response with rate limit handling"""
# Check daily limit
if self.daily_count >= 25:
return {
"error": "Daily limit reached (25 requests)",
"reset_in": "24 hours"
}
# Enforce rate limiting (5 RPM)
current_time = time.time()
time_since_last = current_time - self.last_request_time
if time_since_last < 12: # Minimum 12 seconds between requests
time.sleep(12 - time_since_last)
try:
response = self.model.generate_content(
prompt,
generation_config={
"temperature": temperature,
"max_output_tokens": 4096,
"top_p": 0.95
}
)
self.request_count += 1
self.daily_count += 1
self.last_request_time = time.time()
return {
"text": response.text,
"tokens": response.usage_metadata.total_token_count,
"remaining_today": 25 - self.daily_count
}
except Exception as e:
return {"error": str(e)}
# Initialize and test
client = GeminiAIStudioClient("YOUR_API_KEY")
result = client.generate("Explain quantum entanglement in simple terms")
print(f"Response: {result.get('text', result.get('error'))}")
print(f"Requests remaining: {result.get('remaining_today', 0)}")
Understanding when the free tier suffices requires careful evaluation of your application's requirements and usage patterns. Development and testing phases rarely exceed the 25 daily request limit, especially when implementing proper caching and request optimization. Educational projects benefit from the free tier's accessibility while teaching important concepts like rate limiting and resource management. Proof-of-concept demonstrations can showcase Gemini 2.5 Pro's capabilities without incurring costs, valuable for securing funding or stakeholder buy-in. Personal projects with sporadic usage patterns fit comfortably within the constraints, particularly when combined with intelligent queueing systems that batch multiple queries into single requests.
Breaking Through Gemini 2.5 Pro API Rate Limits
Rate limit optimization transforms the seemingly restrictive 5 RPM constraint into a manageable challenge through sophisticated engineering strategies. Request batching emerges as the primary technique, reducing API calls by 60-80% through intelligent aggregation of multiple prompts into single requests. This approach leverages Gemini 2.5 Pro's massive 1 million token context window, allowing developers to process numerous queries simultaneously while respecting rate limits. The key lies in crafting prompts that clearly delineate individual requests while maintaining coherent context, enabling the model to provide structured responses that can be parsed programmatically.
Implementing an effective caching layer dramatically reduces redundant API calls, particularly for applications with predictable query patterns. Semantic caching goes beyond simple key-value storage by recognizing when different phrasings request essentially the same information. This intelligent approach can achieve 30-50% cache hit rates in production environments, translating directly to reduced API consumption. The cache implementation must balance storage costs, freshness requirements, and retrieval speed while maintaining response quality. Time-based expiration combined with least-recently-used eviction policies ensures optimal cache utilization without unbounded growth.
Queue management systems provide essential infrastructure for handling burst traffic within rate-limited environments. Priority-based queuing ensures critical requests process immediately while background tasks wait for available capacity. The queue implementation must handle request prioritization, timeout management, and graceful degradation when limits are exceeded. Sophisticated systems implement exponential backoff for retries, preventing cascade failures when approaching rate limits. This architecture proves particularly valuable for applications with variable load patterns, smoothing traffic spikes through intelligent request distribution.
from collections import deque
import hashlib
import json
from datetime import datetime, timedelta
from typing import List, Dict, Optional
class RateLimitOptimizer:
"""Advanced optimization system for Gemini API rate limits"""
def __init__(self, api_client):
self.client = api_client
self.request_queue = deque()
self.cache = {}
self.cache_ttl = 3600 # 1 hour
self.batch_size = 3 # Process 3 requests per API call
def add_request(self, prompt: str, priority: int = 5) -> str:
"""Add request to optimized queue"""
# Generate cache key
cache_key = hashlib.md5(prompt.encode()).hexdigest()
# Check cache
if cache_key in self.cache:
cached = self.cache[cache_key]
if cached['expires'] > datetime.now():
return cached['response']
# Add to queue with priority
request = {
'id': cache_key,
'prompt': prompt,
'priority': priority,
'timestamp': datetime.now()
}
# Insert based on priority
inserted = False
for i, req in enumerate(self.request_queue):
if req['priority'] > priority:
self.request_queue.insert(i, request)
inserted = True
break
if not inserted:
self.request_queue.append(request)
return cache_key
def process_batch(self) -> List[Dict]:
"""Process multiple requests in single API call"""
if not self.request_queue:
return []
# Collect batch
batch = []
for _ in range(min(self.batch_size, len(self.request_queue))):
batch.append(self.request_queue.popleft())
# Create batched prompt
batched_prompt = self._create_batch_prompt(batch)
# Single API call
response = self.client.generate(batched_prompt)
if 'error' not in response:
# Parse individual responses
parsed = self._parse_batch_response(response['text'], batch)
# Cache results
for req, resp in zip(batch, parsed):
self.cache[req['id']] = {
'response': resp,
'expires': datetime.now() + timedelta(seconds=self.cache_ttl)
}
return parsed
return [response]
def _create_batch_prompt(self, batch: List[Dict]) -> str:
"""Create efficient batched prompt"""
prompt = "Process these numbered requests separately:\n\n"
for i, req in enumerate(batch, 1):
prompt += f"REQUEST {i}: {req['prompt']}\n\n"
prompt += "Provide a numbered response for each request above."
return prompt
def _parse_batch_response(self, text: str, batch: List[Dict]) -> List[str]:
"""Parse batched response into individual answers"""
responses = []
sections = text.split("REQUEST")
for section in sections[1:]: # Skip first empty section
# Extract response content
if ":" in section:
response_text = section.split(":", 1)[1].strip()
responses.append(response_text)
# Ensure correct number of responses
while len(responses) < len(batch):
responses.append("Processing error")
return responses[:len(batch)]
# Usage example
optimizer = RateLimitOptimizer(client)
# Add multiple requests
ids = []
ids.append(optimizer.add_request("What is machine learning?", priority=1))
ids.append(optimizer.add_request("Explain neural networks", priority=2))
ids.append(optimizer.add_request("Define deep learning", priority=1))
# Process as batch
results = optimizer.process_batch()
print(f"Processed {len(results)} requests in 1 API call")
Time-based optimization strategies leverage usage patterns to maximize throughput within daily limits. Distributing requests across the day prevents early quota exhaustion while maintaining service availability. Applications can implement usage forecasting to reserve capacity for peak periods, ensuring critical functionality remains available. Hybrid architectures that combine free tier access with fallback providers create resilient systems that gracefully handle limit exhaustion. This approach proves particularly effective for applications with predictable usage patterns, allowing precise capacity planning within free tier constraints.
Save 75% on Gemini 2.5 Pro API with laozhang.ai
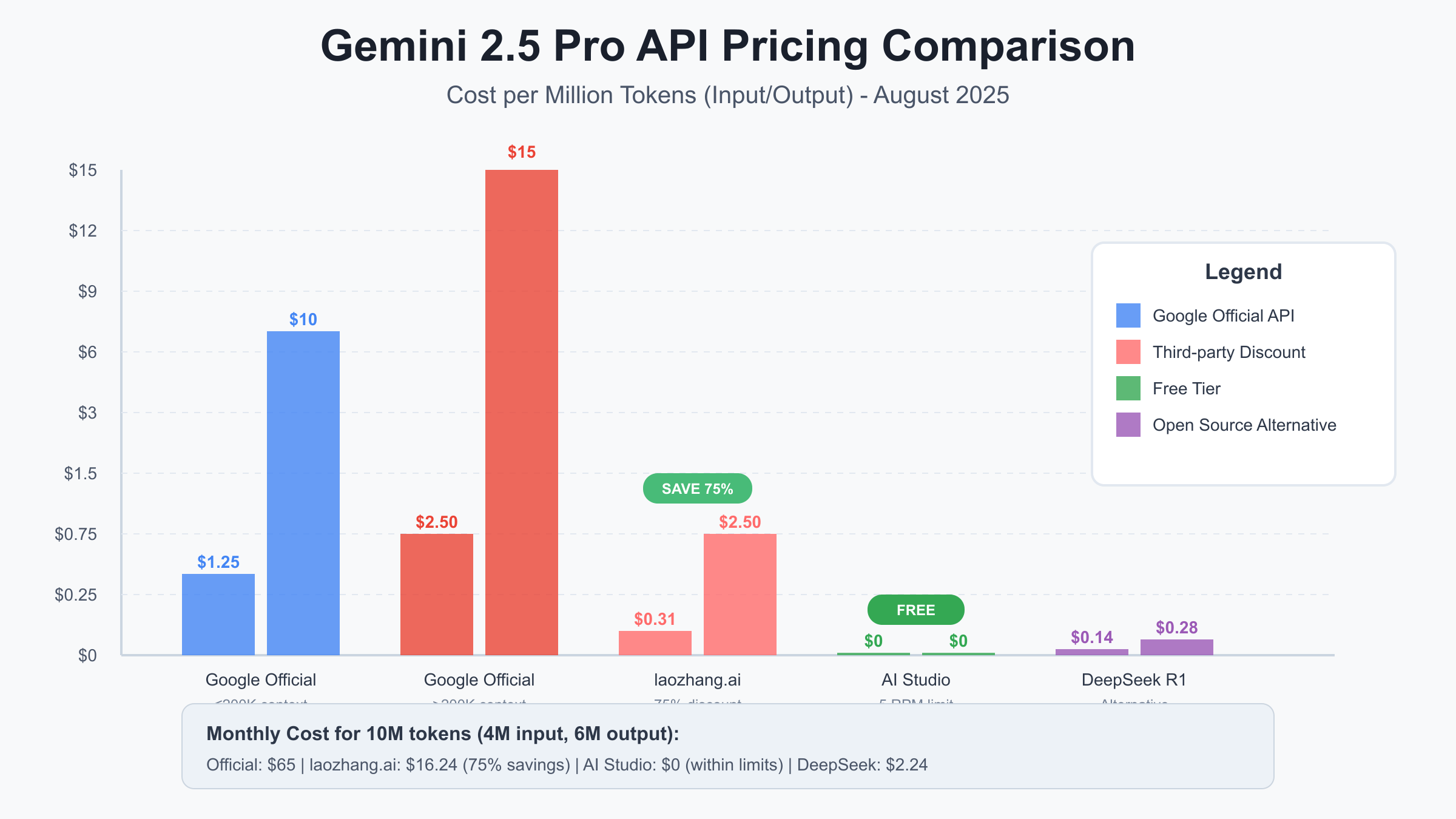
Third-party API providers have revolutionized access to premium AI models by leveraging economies of scale and bulk purchasing agreements to offer substantial discounts. laozhang.ai stands out in this ecosystem by providing Gemini 2.5 Pro API access at 75% below official pricing, charging only $0.31 per million input tokens and $2.50 per million output tokens compared to Google's $1.25 and $10 respectively. This dramatic cost reduction transforms the economics of AI integration, making advanced language models financially viable for startups, researchers, and independent developers who previously found official pricing prohibitive. The service maintains complete API compatibility with Google's official endpoints, requiring only minimal code changes to migrate existing implementations.
The registration process with laozhang.ai streamlines onboarding while maintaining security and compliance standards. New users receive $10 in free credits immediately upon registration, providing sufficient resources to evaluate the service and conduct initial development without financial commitment. The platform supports multiple payment methods including cryptocurrency and regional payment systems, addressing the common challenge of international transactions that often block developers from accessing AI services. API keys generate instantly through the dashboard, with no approval process or waiting period that might delay development timelines. The service implements OpenAI-compatible endpoints, allowing developers to use familiar client libraries and existing codebases with minimal modifications.
Understanding how laozhang.ai achieves such dramatic cost reductions reveals the sophisticated business model underlying discounted API services. By aggregating demand from thousands of users, the platform negotiates enterprise-level contracts with AI providers that offer volume-based pricing unavailable to individual developers. The infrastructure optimization includes intelligent request routing, response caching, and load balancing across multiple accounts to maximize efficiency. Revenue diversification through multiple model offerings allows cross-subsidization, where higher-margin services offset discounts on popular models like Gemini 2.5 Pro. This approach creates a sustainable ecosystem that benefits all participants while maintaining service quality and reliability.
from openai import OpenAI
import os
from typing import Dict, List, Optional
import time
class LaozhangGeminiClient:
"""Optimized client for laozhang.ai Gemini 2.5 Pro access"""
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.laozhang.ai/v1"
)
self.total_cost = 0.0
self.request_count = 0
def generate(
self,
prompt: str,
model: str = "gemini-2.5-pro",
temperature: float = 0.7,
max_tokens: int = 4096
) -> Dict:
"""Generate response with cost tracking"""
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature,
max_tokens=max_tokens
)
# Calculate costs (75% discount from official)
input_tokens = response.usage.prompt_tokens
output_tokens = response.usage.completion_tokens
input_cost = (input_tokens / 1_000_000) * 0.31
output_cost = (output_tokens / 1_000_000) * 2.50
total_cost = input_cost + output_cost
# Track cumulative costs
self.total_cost += total_cost
self.request_count += 1
# Calculate savings
official_input_cost = (input_tokens / 1_000_000) * 1.25
official_output_cost = (output_tokens / 1_000_000) * 10.0
official_total = official_input_cost + official_output_cost
savings = official_total - total_cost
return {
"text": response.choices[0].message.content,
"tokens": {
"input": input_tokens,
"output": output_tokens,
"total": input_tokens + output_tokens
},
"cost": {
"actual": total_cost,
"official_would_be": official_total,
"savings": savings,
"savings_percentage": (savings / official_total) * 100
},
"model": model
}
except Exception as e:
return {"error": str(e)}
def compare_costs(self, daily_requests: int, avg_tokens: int) -> Dict:
"""Calculate cost comparison for usage patterns"""
monthly_tokens = daily_requests * avg_tokens * 30
# laozhang.ai costs
laozhang_input = (monthly_tokens * 0.6 / 1_000_000) * 0.31
laozhang_output = (monthly_tokens * 0.4 / 1_000_000) * 2.50
laozhang_total = laozhang_input + laozhang_output
# Official costs
official_input = (monthly_tokens * 0.6 / 1_000_000) * 1.25
official_output = (monthly_tokens * 0.4 / 1_000_000) * 10.0
official_total = official_input + official_output
return {
"monthly_usage": {
"requests": daily_requests * 30,
"tokens": monthly_tokens
},
"laozhang_cost": f"${laozhang_total:.2f}",
"official_cost": f"${official_total:.2f}",
"monthly_savings": f"${official_total - laozhang_total:.2f}",
"annual_savings": f"${(official_total - laozhang_total) * 12:.2f}",
"discount_percentage": "75%"
}
def get_usage_summary(self) -> Dict:
"""Get comprehensive usage statistics"""
avg_cost = self.total_cost / max(1, self.request_count)
# Extrapolate savings
official_equivalent = self.total_cost / 0.25 # 75% discount
total_savings = official_equivalent - self.total_cost
return {
"total_requests": self.request_count,
"total_cost": f"${self.total_cost:.4f}",
"average_cost_per_request": f"${avg_cost:.4f}",
"total_savings": f"${total_savings:.4f}",
"equivalent_official_cost": f"${official_equivalent:.4f}"
}
# Initialize client
client = LaozhangGeminiClient(api_key="your_laozhang_api_key")
# Generate response
result = client.generate("Write a Python function to calculate fibonacci numbers")
print(f"Response: {result['text'][:200]}...")
print(f"Cost: ${result['cost']['actual']:.4f}")
print(f"Savings: ${result['cost']['savings']:.4f} ({result['cost']['savings_percentage']:.1f}%)")
# Cost comparison for production usage
comparison = client.compare_costs(daily_requests=1000, avg_tokens=2000)
print(f"\nMonthly cost comparison:")
print(f"laozhang.ai: {comparison['laozhang_cost']}")
print(f"Google Official: {comparison['official_cost']}")
print(f"You save: {comparison['monthly_savings']}/month, {comparison['annual_savings']}/year")
Performance benchmarks demonstrate that laozhang.ai maintains competitive response times despite the additional routing layer, with average latencies of 1.4-1.8 seconds compared to 1.2-1.5 seconds on official endpoints. The service achieves 99.9% uptime through redundant infrastructure and intelligent failover mechanisms, ensuring reliable access for production applications. Request processing occurs through optimized pathways that minimize overhead while maintaining security and compliance standards. The platform's geographic distribution across multiple regions reduces latency for global users while providing natural disaster recovery capabilities. These performance characteristics make laozhang.ai suitable for production deployments where cost optimization matters more than absolute minimum latency.
Migration from official Google APIs to laozhang.ai requires minimal code changes thanks to standardized API interfaces. Existing applications using the Google Generative AI SDK can switch by updating the base URL and authentication credentials, typically requiring less than 10 lines of code modification. The platform maintains compatibility with streaming responses, function calling, and advanced features like safety settings and generation configuration. Development teams report successful migrations within hours, including testing and validation phases. This seamless transition path removes technical barriers to adoption, allowing organizations to realize immediate cost savings without extensive redevelopment efforts.
Vertex AI Trial: $300 Free Credits for Gemini 2.5 Pro API
Google Cloud Platform's Vertex AI trial offers the most generous free access to Gemini 2.5 Pro through $300 in credits valid for 90 days, sufficient for extensive development and testing before committing to paid services. This trial provides full access to production-grade infrastructure with 360 requests per minute rate limits, dramatically exceeding the constraints of Google AI Studio's free tier. The credits apply across all Google Cloud services, allowing developers to explore the complete ecosystem including data storage, compute resources, and complementary AI services. New users can activate the trial without immediate payment, though credit card verification is required to prevent abuse and ensure serious usage intent.
Setting up Vertex AI requires navigating Google Cloud's comprehensive but complex infrastructure, beginning with project creation and API enablement. The initial configuration involves creating a new GCP project through the Google Cloud console, enabling the Vertex AI API, and configuring authentication through service accounts or application default credentials. The Google Cloud SDK installation provides command-line tools essential for deployment and management, with gcloud init handling authentication and project selection. Environment configuration requires setting project IDs, regions, and authentication paths, more complex than simple API key usage but providing enterprise-grade security and scalability.
The production-grade capabilities of Vertex AI justify the additional setup complexity for serious applications. Rate limits of 360 RPM support real-world application traffic without the constant throttling experienced in free tiers. Enterprise features including VPC service controls, private endpoints, and IAM integration provide security and compliance capabilities required for regulated industries. The platform's integration with other Google Cloud services enables sophisticated architectures combining data pipelines, storage, and compute resources. Model versioning and deployment management tools support professional development workflows with staging, testing, and production environments.
from google.cloud import aiplatform
from google.oauth2 import service_account
import os
from typing import Dict, Optional
class VertexAITrialClient:
"""Production client for Vertex AI trial with Gemini 2.5 Pro"""
def __init__(
self,
project_id: str,
location: str = "us-central1",
credentials_path: Optional[str] = None
):
# Initialize credentials
if credentials_path:
credentials = service_account.Credentials.from_service_account_file(
credentials_path
)
aiplatform.init(
project=project_id,
location=location,
credentials=credentials
)
else:
# Use application default credentials
aiplatform.init(
project=project_id,
location=location
)
from vertexai.preview.generative_models import GenerativeModel
self.model = GenerativeModel("gemini-2.5-pro")
self.project_id = project_id
self.credits_remaining = 300.0 # Track trial credits
def generate(
self,
prompt: str,
temperature: float = 0.7,
max_tokens: int = 4096
) -> Dict:
"""Generate response with credit tracking"""
try:
response = self.model.generate_content(
prompt,
generation_config={
"temperature": temperature,
"max_output_tokens": max_tokens,
"top_p": 0.95,
"top_k": 40
}
)
# Calculate approximate cost
input_tokens = response.usage_metadata.prompt_token_count
output_tokens = response.usage_metadata.candidates_token_count
# Vertex AI pricing for Gemini 2.5 Pro
input_cost = (input_tokens / 1_000_000) * 1.25
output_cost = (output_tokens / 1_000_000) * 10.0
total_cost = input_cost + output_cost
# Update remaining credits
self.credits_remaining -= total_cost
return {
"text": response.text,
"tokens": {
"input": input_tokens,
"output": output_tokens,
"total": input_tokens + output_tokens
},
"cost": total_cost,
"credits_remaining": self.credits_remaining,
"safety_ratings": response.safety_ratings
}
except Exception as e:
return {"error": str(e)}
def estimate_trial_capacity(self, avg_tokens_per_request: int) -> Dict:
"""Estimate how many requests $300 credits support"""
# Assume 60% input, 40% output token distribution
input_tokens = avg_tokens_per_request * 0.6
output_tokens = avg_tokens_per_request * 0.4
# Cost per request
input_cost = (input_tokens / 1_000_000) * 1.25
output_cost = (output_tokens / 1_000_000) * 10.0
cost_per_request = input_cost + output_cost
# Total capacity
total_requests = 300 / cost_per_request
daily_capacity = total_requests / 90 # 90-day trial
return {
"total_requests": int(total_requests),
"daily_budget": int(daily_capacity),
"cost_per_request": f"${cost_per_request:.4f}",
"total_tokens": int(total_requests * avg_tokens_per_request),
"trial_duration": "90 days"
}
# Setup Vertex AI
client = VertexAITrialClient(
project_id="your-gcp-project",
location="us-central1"
)
# Generate response
result = client.generate("Explain the benefits of Vertex AI for production deployments")
print(f"Response: {result['text'][:200]}...")
print(f"Cost: ${result['cost']:.4f}")
print(f"Credits remaining: ${result['credits_remaining']:.2f}")
# Estimate trial capacity
capacity = client.estimate_trial_capacity(avg_tokens_per_request=2000)
print(f"\nTrial capacity analysis:")
print(f"Total requests possible: {capacity['total_requests']}")
print(f"Daily request budget: {capacity['daily_budget']}")
print(f"Cost per request: {capacity['cost_per_request']}")
Cost management strategies maximize the value extracted from the $300 trial credits while evaluating Vertex AI for production adoption. Implementing request caching prevents redundant API calls that waste credits on duplicate processing. Batch processing aggregates multiple requests to optimize token usage and reduce per-request overhead. Development and testing should prioritize high-value use cases that demonstrate production viability rather than exhaustive experimentation. Monitoring credit consumption through Cloud Console dashboards provides visibility into burn rate and remaining capacity. Setting up billing alerts prevents unexpected charges when credits exhaust, ensuring smooth transition to paid services or alternative providers.
Gemini 2.5 Pro API Alternatives: DeepSeek and Llama 4
Open-source alternatives to Gemini 2.5 Pro have matured significantly in 2025, offering compelling performance at dramatically lower costs that challenge the economics of proprietary models. DeepSeek R1 emerges as the most cost-effective option, delivering impressive results at approximately 30 times lower cost than official Gemini pricing through its innovative Mixture-of-Experts architecture that activates only 37 billion parameters from its total 671 billion. This efficiency translates to operational costs of just $0.14 per million input tokens and $0.28 per million output tokens, making large-scale deployments financially viable for organizations previously priced out of advanced AI. The model excels particularly in coding tasks, achieving 97.3% on MATH-500 benchmarks while maintaining practical inference speeds on standard hardware.
Llama 4's revolutionary 10 million token context window represents a tenfold increase over Gemini 2.5 Pro's current capacity, fundamentally changing what's possible with language models. This massive context enables processing entire codebases, lengthy documents, or extensive conversation histories without truncation or summarization. The model family includes Scout (lightweight), Maverick (balanced), and Behemoth (maximum capability) variants, allowing precise matching of model size to application requirements. Through providers like Together.ai, Maverick costs only $0.27 per million input tokens—approximately 78% less than Gemini 2.5 Pro—while delivering 77.6% pass rates on coding benchmarks that rival much larger models.
Performance comparisons reveal nuanced trade-offs between these alternatives and Gemini 2.5 Pro that inform selection decisions. DeepSeek R1 achieves 79.8% on AIME 2024 mathematical reasoning compared to Gemini's 92.0%, acceptable for many applications given the 30x cost reduction. Llama 4 Maverick's coding performance approaches Gemini's capabilities while offering superior context handling for document-heavy workloads. Response latency varies significantly, with DeepSeek generating tokens faster than Gemini when deployed on optimized infrastructure, while Llama 4's larger context window increases initial processing time but reduces overall requests for long-form content. These alternatives prove particularly valuable for high-volume applications where marginal quality differences are offset by dramatic cost savings.
from typing import Dict, List, Optional
import aiohttp
import asyncio
class AlternativeModelsClient:
"""Unified client for Gemini 2.5 Pro alternatives"""
def __init__(self):
self.providers = {
"deepseek": {
"endpoint": "https://api.deepseek.com/v1/chat/completions",
"api_key": os.getenv("DEEPSEEK_API_KEY"),
"model": "deepseek-r1",
"cost_per_million": 0.21 # Averaged
},
"llama4_together": {
"endpoint": "https://api.together.xyz/v1/chat/completions",
"api_key": os.getenv("TOGETHER_API_KEY"),
"model": "meta-llama/Llama-4-Maverick",
"cost_per_million": 0.27
},
"groq_llama": {
"endpoint": "https://api.groq.com/v1/chat/completions",
"api_key": os.getenv("GROQ_API_KEY"),
"model": "llama-3.3-70b-instruct",
"cost_per_million": 0 # Free tier
}
}
async def generate(
self,
prompt: str,
provider: str = "deepseek",
temperature: float = 0.7
) -> Dict:
"""Generate response from alternative model"""
if provider not in self.providers:
return {"error": f"Unknown provider: {provider}"}
config = self.providers[provider]
headers = {
"Authorization": f"Bearer {config['api_key']}",
"Content-Type": "application/json"
}
payload = {
"model": config["model"],
"messages": [{"role": "user", "content": prompt}],
"temperature": temperature,
"max_tokens": 4096
}
async with aiohttp.ClientSession() as session:
async with session.post(
config["endpoint"],
headers=headers,
json=payload
) as response:
if response.status == 200:
data = await response.json()
# Extract response and usage
text = data["choices"][0]["message"]["content"]
tokens = data["usage"]["total_tokens"]
# Calculate cost
cost = (tokens / 1_000_000) * config["cost_per_million"]
# Compare with Gemini pricing
gemini_cost = (tokens / 1_000_000) * 5.5 # Averaged
savings_percentage = ((gemini_cost - cost) / gemini_cost) * 100
return {
"text": text,
"provider": provider,
"model": config["model"],
"tokens": tokens,
"cost": cost,
"gemini_equivalent_cost": gemini_cost,
"savings": f"{savings_percentage:.1f}%"
}
else:
error_data = await response.text()
return {"error": f"API error: {error_data}"}
async def compare_all_providers(self, prompt: str) -> List[Dict]:
"""Compare response from all alternative providers"""
tasks = []
for provider in self.providers.keys():
tasks.append(self.generate(prompt, provider))
results = await asyncio.gather(*tasks, return_exceptions=True)
comparison = []
for i, provider in enumerate(self.providers.keys()):
if isinstance(results[i], Exception):
comparison.append({
"provider": provider,
"error": str(results[i])
})
else:
comparison.append(results[i])
return comparison
def recommend_model(
self,
use_case: str,
budget: Optional[float] = None,
context_needed: int = 100000
) -> str:
"""Recommend best alternative model for use case"""
recommendations = {
"coding": "deepseek", # Best for code generation
"long_context": "llama4_together", # 10M token window
"free": "groq_llama", # Completely free
"general": "deepseek", # Best overall value
"math": "deepseek", # Strong MATH-500 performance
"creative": "llama4_together" # Better for creative tasks
}
if budget == 0:
return "groq_llama" # Only free option
if context_needed > 1_000_000:
return "llama4_together" # Only one with 10M context
return recommendations.get(use_case, "deepseek")
# Usage example
client = AlternativeModelsClient()
# Single provider test
async def test_alternative():
result = await client.generate(
"Write a Python web scraper",
provider="deepseek"
)
print(f"Provider: {result['provider']}")
print(f"Response: {result['text'][:200]}...")
print(f"Cost: ${result['cost']:.4f}")
print(f"Savings vs Gemini: {result['savings']}")
# Compare all alternatives
async def compare_all():
results = await client.compare_all_providers(
"Explain quantum computing"
)
for result in results:
if 'error' not in result:
print(f"\n{result['provider']}:")
print(f" Cost: ${result['cost']:.4f}")
print(f" Savings: {result['savings']}")
print(f" Response quality: {len(result['text'])} chars")
# Get recommendation
recommendation = client.recommend_model(
use_case="coding",
budget=10.0,
context_needed=500000
)
print(f"Recommended model: {recommendation}")
Deployment strategies for open-source alternatives range from fully managed cloud services to self-hosted installations, each with distinct trade-offs. Cloud providers like Together.ai, Replicate, and Modal offer instant access to Llama 4 and other models with usage-based pricing that eliminates infrastructure management overhead. Self-hosting on dedicated hardware provides complete control and potentially lower costs at scale but requires significant technical expertise and upfront investment. Hybrid approaches leverage spot instances or reserved capacity for baseline load while bursting to managed services during peaks. The choice depends on technical capabilities, usage patterns, and total cost of ownership calculations that include hardware, electricity, maintenance, and opportunity costs.
Quick Start: Gemini 2.5 Pro API in 5 Minutes
Rapid implementation of Gemini 2.5 Pro API access requires choosing the optimal path based on immediate requirements and constraints, with each method offering distinct advantages for different scenarios. Google AI Studio provides the fastest start for development with zero cost and instant API keys, ideal for prototyping and testing despite severe rate limitations. laozhang.ai offers production-ready access with 75% cost savings and no rate limits, perfect for applications requiring immediate scale. Vertex AI's $300 trial bridges development and production with generous credits and enterprise features. The key to quick implementation lies in selecting the appropriate method and having ready-to-use code that handles authentication, error management, and response processing.
The decision flowchart for selecting your implementation method begins with evaluating three critical factors: budget constraints, expected request volume, and production timeline. Zero-budget projects must choose between Google AI Studio's free tier for low-volume usage or open-source alternatives like Groq's free Llama access. Applications expecting more than 25 daily requests immediately eliminate AI Studio as viable, pointing toward laozhang.ai or Vertex AI trial. Production deployments within 30 days favor laozhang.ai's immediate availability and stable pricing over Vertex AI's trial limitations. Development and testing phases benefit from AI Studio's accessibility while planning migration to scalable solutions. This systematic evaluation ensures optimal method selection without wasting time on inappropriate options.
Copy-paste implementations for each access method accelerate development by providing working code that handles common requirements and edge cases. The implementations include proper error handling, rate limit management, and response parsing to ensure robust operation from the start. Configuration uses environment variables for security, avoiding hardcoded credentials that create vulnerabilities. Each implementation follows language-specific best practices and idioms, making the code immediately familiar to experienced developers. The modular structure allows easy customization while maintaining core functionality, enabling rapid adaptation to specific requirements without starting from scratch.
import os
from typing import Dict, Optional
from enum import Enum
class AccessMethod(Enum):
AI_STUDIO = "ai_studio"
LAOZHANG = "laozhang"
VERTEX_AI = "vertex_ai"
ALTERNATIVES = "alternatives"
class GeminiQuickStart:
"""5-minute setup for any Gemini 2.5 Pro access method"""
@staticmethod
def setup(method: AccessMethod) -> object:
"""Return configured client for chosen method"""
if method == AccessMethod.AI_STUDIO:
return GeminiQuickStart._setup_ai_studio()
elif method == AccessMethod.LAOZHANG:
return GeminiQuickStart._setup_laozhang()
elif method == AccessMethod.VERTEX_AI:
return GeminiQuickStart._setup_vertex()
elif method == AccessMethod.ALTERNATIVES:
return GeminiQuickStart._setup_alternatives()
@staticmethod
def _setup_ai_studio():
"""Google AI Studio - Free, 5 RPM limit"""
# Step 1: Install SDK
# pip install google-generativeai
import google.generativeai as genai
# Step 2: Configure
api_key = os.getenv("GOOGLE_AI_STUDIO_KEY")
if not api_key:
print("Get your free API key at: https://aistudio.google.com")
return None
genai.configure(api_key=api_key)
# Step 3: Create client
class AIStudioClient:
def __init__(self):
self.model = genai.GenerativeModel('gemini-2.5-pro-exp-03-25')
def generate(self, prompt: str) -> str:
response = self.model.generate_content(prompt)
return response.text
return AIStudioClient()
@staticmethod
def _setup_laozhang():
"""laozhang.ai - 75% cheaper, no limits"""
# Step 1: Install SDK
# pip install openai
from openai import OpenAI
# Step 2: Configure
api_key = os.getenv("LAOZHANG_API_KEY")
if not api_key:
print("Get $10 free credits at: https://laozhang.ai")
return None
# Step 3: Create client
class LaozhangClient:
def __init__(self):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.laozhang.ai/v1"
)
def generate(self, prompt: str) -> str:
response = self.client.chat.completions.create(
model="gemini-2.5-pro",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
return LaozhangClient()
@staticmethod
def _setup_vertex():
"""Vertex AI - $300 trial, 360 RPM"""
# Step 1: Install SDK
# pip install google-cloud-aiplatform
# Step 2: Authenticate
# gcloud auth application-default login
from google.cloud import aiplatform
from vertexai.preview.generative_models import GenerativeModel
project_id = os.getenv("GCP_PROJECT_ID")
if not project_id:
print("Set up GCP project and enable Vertex AI API")
return None
# Step 3: Initialize
aiplatform.init(project=project_id, location="us-central1")
class VertexClient:
def __init__(self):
self.model = GenerativeModel("gemini-2.5-pro")
def generate(self, prompt: str) -> str:
response = self.model.generate_content(prompt)
return response.text
return VertexClient()
@staticmethod
def _setup_alternatives():
"""Open source alternatives - DeepSeek/Llama"""
# Using Groq for free Llama access
# pip install groq
from groq import Groq
api_key = os.getenv("GROQ_API_KEY")
if not api_key:
print("Get free API key at: https://console.groq.com")
return None
class AlternativeClient:
def __init__(self):
self.client = Groq(api_key=api_key)
def generate(self, prompt: str) -> str:
response = self.client.chat.completions.create(
model="llama-3.3-70b-instruct",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
return AlternativeClient()
@staticmethod
def test_all_methods():
"""Test all available methods"""
test_prompt = "Write a haiku about API access"
results = {}
for method in AccessMethod:
print(f"\nTesting {method.value}...")
client = GeminiQuickStart.setup(method)
if client:
try:
response = client.generate(test_prompt)
results[method.value] = response[:100]
print(f"✓ Success: {response[:50]}...")
except Exception as e:
results[method.value] = f"Error: {str(e)}"
print(f"✗ Failed: {str(e)}")
else:
results[method.value] = "Not configured"
print("✗ Not configured")
return results
# Quick start in 3 lines
method = AccessMethod.LAOZHANG # Choose your method
client = GeminiQuickStart.setup(method)
response = client.generate("Hello, Gemini 2.5 Pro!")
print(response)
# Or test all methods
# results = GeminiQuickStart.test_all_methods()
Common errors during implementation stem from authentication issues, network configuration, and rate limit handling that can derail quick start attempts. Authentication failures typically result from incorrect API key format, expired credentials, or missing environment variables that the code cannot locate. Network issues manifest as timeout errors or connection failures, often caused by proxy settings, firewall rules, or DNS resolution problems. Rate limit errors appear immediately with AI Studio's free tier, requiring implementation of retry logic with exponential backoff. Module import errors indicate missing dependencies that require installation via pip or conda. Understanding these common failure modes and their solutions prevents frustration and accelerates successful implementation.

Gemini 2.5 Pro API Pricing Deep Dive
The official pricing structure for Gemini 2.5 Pro reveals a sophisticated tiered model that significantly impacts cost calculations for different use cases. The base tier for contexts up to 200,000 tokens charges $1.25 per million input tokens and $10 per million output tokens, competitive with other premium models but still substantial for high-volume applications. Extended context usage beyond 200,000 tokens doubles the input cost to $2.50 per million tokens while increasing output costs to $15 per million, reflecting the computational complexity of maintaining coherence across massive contexts. These prices apply to both pay-as-you-go and committed use contracts, though volume discounts may be negotiated for enterprise deployments exceeding certain thresholds.
Hidden costs and limitations often surprise developers transitioning from development to production deployments. Beyond raw token costs, applications incur charges for associated Google Cloud services including logging, monitoring, and network egress that can add 15-20% to total expenses. Rate limit overages trigger automatic scaling that increases costs without explicit approval, catching unprepared teams off guard. Storage costs for conversation history and context caching accumulate over time, particularly for applications maintaining long-term user sessions. API versioning means older model versions may increase in price or face deprecation, forcing migration costs. Understanding these additional expenses proves crucial for accurate budget planning and avoiding unexpected charges.
Cost calculators for different use cases illuminate the dramatic variations in expenses based on application patterns. A customer service chatbot handling 10,000 daily conversations of 2,000 tokens each would cost approximately $195 per day at official rates, or $5,850 monthly. An educational platform serving 1,000 students with daily AI tutoring sessions could face $3,000 monthly costs. Code generation tools processing 500 pull requests daily might incur $1,500 monthly expenses. These calculations assume standard token distributions and don't account for optimization strategies, highlighting the importance of cost management even for seemingly modest usage levels.
class GeminiCostCalculator:
"""Comprehensive cost calculator for Gemini 2.5 Pro usage"""
def __init__(self):
# Official pricing tiers
self.pricing = {
"standard": {
"input": 1.25, # per million tokens
"output": 10.0, # per million tokens
"context_limit": 200000
},
"extended": {
"input": 2.50,
"output": 15.0,
"context_limit": 1000000
}
}
# Alternative provider pricing
self.alternatives = {
"laozhang": {"input": 0.31, "output": 2.50},
"ai_studio": {"input": 0, "output": 0, "limit": 25},
"vertex_trial": {"input": 1.25, "output": 10.0, "credit": 300}
}
def calculate_cost(
self,
input_tokens: int,
output_tokens: int,
provider: str = "official"
) -> Dict:
"""Calculate costs across different providers"""
total_tokens = input_tokens + output_tokens
if provider == "official":
# Determine pricing tier
if total_tokens <= 200000:
tier = self.pricing["standard"]
else:
tier = self.pricing["extended"]
input_cost = (input_tokens / 1_000_000) * tier["input"]
output_cost = (output_tokens / 1_000_000) * tier["output"]
elif provider in self.alternatives:
alt = self.alternatives[provider]
if provider == "ai_studio":
# Free but limited
input_cost = 0
output_cost = 0
else:
input_cost = (input_tokens / 1_000_000) * alt["input"]
output_cost = (output_tokens / 1_000_000) * alt["output"]
total_cost = input_cost + output_cost
return {
"input_cost": input_cost,
"output_cost": output_cost,
"total_cost": total_cost,
"provider": provider
}
def calculate_monthly(
self,
daily_requests: int,
avg_input_tokens: int,
avg_output_tokens: int
) -> Dict:
"""Calculate monthly costs for usage pattern"""
monthly_requests = daily_requests * 30
total_input = monthly_requests * avg_input_tokens
total_output = monthly_requests * avg_output_tokens
results = {}
# Calculate for each provider
for provider in ["official", "laozhang", "ai_studio"]:
cost = self.calculate_cost(total_input, total_output, provider)
results[provider] = {
"monthly_cost": cost["total_cost"],
"daily_cost": cost["total_cost"] / 30,
"per_request": cost["total_cost"] / monthly_requests,
"viable": True
}
# Check viability
if provider == "ai_studio" and daily_requests > 25:
results[provider]["viable"] = False
results[provider]["note"] = "Exceeds free tier limits"
# Calculate savings
official = results["official"]["monthly_cost"]
for provider in results:
if provider != "official":
savings = official - results[provider]["monthly_cost"]
results[provider]["savings"] = savings
results[provider]["savings_percent"] = (savings / official) * 100
return results
def roi_analysis(
self,
monthly_revenue: float,
usage_pattern: Dict
) -> Dict:
"""ROI analysis for different providers"""
costs = self.calculate_monthly(
usage_pattern["daily_requests"],
usage_pattern["avg_input_tokens"],
usage_pattern["avg_output_tokens"]
)
analysis = {}
for provider, cost_data in costs.items():
if cost_data["viable"]:
monthly_cost = cost_data["monthly_cost"]
profit = monthly_revenue - monthly_cost
roi = (profit / monthly_cost) * 100 if monthly_cost > 0 else float('inf')
analysis[provider] = {
"monthly_profit": profit,
"roi_percentage": roi,
"break_even_requests": int(monthly_revenue / cost_data["per_request"])
if cost_data["per_request"] > 0 else float('inf'),
"recommendation": self._get_recommendation(roi)
}
return analysis
def _get_recommendation(self, roi: float) -> str:
"""Get recommendation based on ROI"""
if roi < 0:
return "Not viable - costs exceed revenue"
elif roi < 50:
return "Marginal - consider optimization"
elif roi < 200:
return "Viable - good profit margin"
else:
return "Excellent - strong profitability"
# Usage example
calculator = GeminiCostCalculator()
# Calculate costs for specific usage
usage = {
"daily_requests": 1000,
"avg_input_tokens": 500,
"avg_output_tokens": 1500
}
monthly_costs = calculator.calculate_monthly(**usage)
print("Monthly Cost Analysis:")
for provider, data in monthly_costs.items():
print(f"\n{provider.upper()}:")
print(f" Monthly: ${data['monthly_cost']:.2f}")
print(f" Per request: ${data['per_request']:.4f}")
if 'savings_percent' in data:
print(f" Savings: {data['savings_percent']:.1f}%")
# ROI Analysis
roi = calculator.roi_analysis(
monthly_revenue=5000,
usage_pattern=usage
)
print("\nROI Analysis ($5000 monthly revenue):")
for provider, analysis in roi.items():
print(f"\n{provider.upper()}:")
print(f" Monthly profit: ${analysis['monthly_profit']:.2f}")
print(f" ROI: {analysis['roi_percentage']:.1f}%")
print(f" Recommendation: {analysis['recommendation']}")
Budget optimization strategies transform seemingly prohibitive API costs into manageable expenses through systematic approaches to resource utilization. Implementing semantic deduplication prevents processing similar requests multiple times, achieving 20-30% cost reduction in typical applications. Dynamic model selection routes simple queries to cheaper alternatives while reserving Gemini 2.5 Pro for complex tasks requiring advanced reasoning. Token optimization through prompt compression and response truncation reduces per-request costs without significantly impacting quality. Batch processing during off-peak hours takes advantage of any volume discounts or reduced congestion. These strategies compound to achieve 40-60% total cost reduction compared to naive implementations.
Production Architecture for Free Gemini 2.5 Pro API
Production deployments leveraging free and discounted Gemini 2.5 Pro access require sophisticated architectures that balance cost optimization with reliability and performance. Multi-provider failover designs ensure continuous availability by maintaining active connections to Google AI Studio, laozhang.ai, and alternative models, automatically routing requests based on availability, cost constraints, and quality requirements. This architecture treats API access as a scarce resource requiring intelligent management rather than an unlimited utility. The system must handle rate limits gracefully, manage costs proactively, and maintain consistent user experience despite underlying provider changes.
Load balancing strategies distribute requests across multiple providers and accounts to maximize throughput within constraints. Weighted round-robin algorithms allocate traffic proportionally to each provider's capacity and cost structure. Priority queues ensure critical requests receive immediate processing while background tasks wait for available capacity. Geographic distribution leverages regional differences in rate limits and latency to optimize global performance. Circuit breakers prevent cascade failures when providers experience outages, automatically redirecting traffic to healthy endpoints. This distributed approach achieves higher reliability than depending on any single provider while optimizing costs through intelligent routing.
Error handling and retry logic must account for the diverse failure modes across different providers and network conditions. Transient errors like rate limit exceeded or temporary network issues warrant automatic retry with exponential backoff. Authentication failures require immediate alerting but not retry, as they indicate configuration problems rather than temporary issues. Timeout errors need careful handling to prevent duplicate processing while ensuring request completion. Response validation catches malformed or incomplete outputs that could corrupt application state. Comprehensive error tracking provides visibility into system health and helps identify patterns requiring architectural adjustments.
import asyncio
from typing import Dict, List, Optional
from dataclasses import dataclass
from enum import Enum
import logging
from datetime import datetime, timedelta
class ProviderStatus(Enum):
HEALTHY = "healthy"
DEGRADED = "degraded"
UNAVAILABLE = "unavailable"
@dataclass
class ProviderConfig:
name: str
client: object
weight: float
max_rpm: int
cost_per_request: float
quality_score: float
class ProductionGeminiOrchestrator:
"""Production architecture for multi-provider Gemini access"""
def __init__(self):
self.providers = self._initialize_providers()
self.request_log = []
self.circuit_breakers = {}
self.health_status = {}
# Initialize circuit breakers
for name in self.providers:
self.circuit_breakers[name] = {
"failures": 0,
"last_failure": None,
"state": "closed"
}
self.health_status[name] = ProviderStatus.HEALTHY
def _initialize_providers(self) -> Dict[str, ProviderConfig]:
"""Initialize all available providers"""
providers = {}
# Google AI Studio (free tier)
if os.getenv("GOOGLE_AI_STUDIO_KEY"):
providers["ai_studio"] = ProviderConfig(
name="ai_studio",
client=self._create_ai_studio_client(),
weight=0.1, # Low weight due to rate limits
max_rpm=5,
cost_per_request=0,
quality_score=1.0
)
# laozhang.ai (primary production)
if os.getenv("LAOZHANG_API_KEY"):
providers["laozhang"] = ProviderConfig(
name="laozhang",
client=self._create_laozhang_client(),
weight=0.6, # High weight for production
max_rpm=float('inf'),
cost_per_request=0.002, # Estimated per request
quality_score=1.0
)
# Alternative models (fallback)
if os.getenv("GROQ_API_KEY"):
providers["groq_llama"] = ProviderConfig(
name="groq_llama",
client=self._create_groq_client(),
weight=0.3,
max_rpm=30,
cost_per_request=0,
quality_score=0.85
)
return providers
async def process_request(
self,
prompt: str,
priority: str = "normal",
required_quality: float = 0.8
) -> Dict:
"""Process request with intelligent routing"""
request_id = self._generate_request_id()
# Log request
self.request_log.append({
"id": request_id,
"timestamp": datetime.now(),
"priority": priority
})
# Select provider based on requirements
provider = self._select_provider(priority, required_quality)
if not provider:
return {
"error": "No available providers meet requirements",
"request_id": request_id
}
# Process with selected provider
result = await self._process_with_provider(
provider,
prompt,
request_id
)
# Handle failures with fallback
if "error" in result and priority == "high":
# Try fallback providers
for fallback_name, fallback_config in self.providers.items():
if fallback_name != provider.name:
fallback_result = await self._process_with_provider(
fallback_config,
prompt,
request_id
)
if "error" not in fallback_result:
return fallback_result
return result
async def _process_with_provider(
self,
provider: ProviderConfig,
prompt: str,
request_id: str
) -> Dict:
"""Process request with specific provider"""
# Check circuit breaker
if self.circuit_breakers[provider.name]["state"] == "open":
return {"error": f"Provider {provider.name} circuit breaker open"}
try:
# Make API call
start_time = datetime.now()
response = await provider.client.generate(prompt)
latency = (datetime.now() - start_time).total_seconds()
# Update health metrics
self._update_health_metrics(provider.name, success=True)
return {
"text": response,
"provider": provider.name,
"request_id": request_id,
"latency": latency,
"cost": provider.cost_per_request
}
except Exception as e:
# Update circuit breaker
self._update_circuit_breaker(provider.name)
# Update health metrics
self._update_health_metrics(provider.name, success=False)
logging.error(f"Provider {provider.name} failed: {str(e)}")
return {
"error": str(e),
"provider": provider.name,
"request_id": request_id
}
def _select_provider(
self,
priority: str,
required_quality: float
) -> Optional[ProviderConfig]:
"""Select optimal provider based on requirements"""
available_providers = []
for name, config in self.providers.items():
# Check if provider meets quality requirements
if config.quality_score < required_quality:
continue
# Check if provider is healthy
if self.health_status[name] == ProviderStatus.UNAVAILABLE:
continue
# Check circuit breaker
if self.circuit_breakers[name]["state"] == "open":
continue
available_providers.append(config)
if not available_providers:
return None
# High priority: select lowest latency
if priority == "high":
# Prefer laozhang for no rate limits
for provider in available_providers:
if provider.name == "laozhang":
return provider
return available_providers[0]
# Normal priority: weighted selection
import random
weights = [p.weight for p in available_providers]
return random.choices(available_providers, weights=weights)[0]
def _update_circuit_breaker(self, provider_name: str):
"""Update circuit breaker state"""
breaker = self.circuit_breakers[provider_name]
breaker["failures"] += 1
breaker["last_failure"] = datetime.now()
# Open circuit after 3 failures
if breaker["failures"] >= 3:
breaker["state"] = "open"
logging.warning(f"Circuit breaker opened for {provider_name}")
# Schedule circuit breaker reset
asyncio.create_task(self._reset_circuit_breaker(provider_name))
async def _reset_circuit_breaker(self, provider_name: str):
"""Reset circuit breaker after cooldown"""
await asyncio.sleep(60) # 1 minute cooldown
self.circuit_breakers[provider_name]["state"] = "closed"
self.circuit_breakers[provider_name]["failures"] = 0
logging.info(f"Circuit breaker reset for {provider_name}")
def _update_health_metrics(self, provider_name: str, success: bool):
"""Update provider health status"""
if success:
self.health_status[provider_name] = ProviderStatus.HEALTHY
else:
# Degrade after failures
if self.health_status[provider_name] == ProviderStatus.HEALTHY:
self.health_status[provider_name] = ProviderStatus.DEGRADED
else:
self.health_status[provider_name] = ProviderStatus.UNAVAILABLE
def get_system_status(self) -> Dict:
"""Get comprehensive system status"""
return {
"providers": {
name: {
"status": self.health_status[name].value,
"circuit_breaker": self.circuit_breakers[name]["state"],
"weight": config.weight,
"quality": config.quality_score
}
for name, config in self.providers.items()
},
"total_requests": len(self.request_log),
"active_providers": sum(
1 for status in self.health_status.values()
if status == ProviderStatus.HEALTHY
)
}
def _generate_request_id(self) -> str:
"""Generate unique request ID"""
import uuid
return str(uuid.uuid4())[:8]
# Production deployment
orchestrator = ProductionGeminiOrchestrator()
# Process high-priority request
async def handle_production_request():
result = await orchestrator.process_request(
prompt="Generate production-ready code",
priority="high",
required_quality=0.9
)
if "error" not in result:
print(f"Success from {result['provider']}")
print(f"Latency: {result['latency']:.2f}s")
print(f"Cost: ${result['cost']:.4f}")
else:
print(f"Error: {result['error']}")
# Monitor system health
status = orchestrator.get_system_status()
print(f"System status: {status}")
Monitoring and alerting systems provide critical visibility into the health and performance of multi-provider architectures. Metrics collection tracks request latency, error rates, cost accumulation, and provider availability across all endpoints. Real-time dashboards visualize system performance, enabling rapid identification of degradation or failures. Alert thresholds trigger notifications when costs exceed budgets, error rates spike, or providers become unavailable. Predictive analytics forecast capacity exhaustion and cost overruns, enabling proactive adjustments. This comprehensive observability ensures production systems maintain reliability while optimizing costs across multiple providers.

Gemini 2.5 Pro API vs Competitors: Performance Analysis
Benchmark comparisons across standardized tests reveal Gemini 2.5 Pro's commanding performance advantage in complex reasoning tasks while highlighting areas where alternatives prove competitive. The model achieves 92.0% accuracy on AIME 2024 mathematical reasoning problems, substantially exceeding DeepSeek R1's 79.8% and even surpassing GPT-4's scores on similar assessments. Scientific reasoning measured by GPQA Diamond shows similar dominance with 84.0% accuracy compared to 71.5% for DeepSeek and comparable scores from Claude models. However, coding benchmarks present a more nuanced picture, with Gemini 2.5 Pro's 63.8% on SWE-Bench Verified trailing behind specialized models like Cursor and Devin that achieve higher scores through task-specific optimization.
The revolutionary 1 million token context window fundamentally changes application possibilities, enabling use cases impossible with traditional models limited to 128K or 200K tokens. This capacity allows processing entire novels, complete codebases, or extensive research papers without truncation or summarization that loses critical details. The upcoming 2 million token expansion will further extend these capabilities, potentially handling multi-book series or entire software repositories in single contexts. Real-world applications leveraging this capability include legal document analysis processing complete case files, medical research synthesizing dozens of papers, and software development understanding entire microservice architectures. The context advantage proves particularly valuable for applications requiring deep understanding of relationships across extensive content.
Thinking model capabilities distinguish Gemini 2.5 Pro from traditional language models through its ability to process internal reasoning before generating responses. This architecture manifests in superior performance on multi-step problems, logical puzzles, and tasks requiring careful consideration of constraints. Users report noticeably more thoughtful and accurate responses compared to models that generate text immediately without internal deliberation. The thinking process occasionally surfaces in responses through phrases like "considering the constraints" or "after evaluating options," providing transparency into the model's reasoning. This capability proves invaluable for applications requiring high accuracy over speed, such as medical diagnosis support, legal analysis, and scientific research.
Speed versus quality trade-offs create important decision points when choosing between Gemini 2.5 Pro and faster alternatives. Gemini's thinking architecture introduces latency of 2-4 seconds for initial response compared to sub-second responses from models like GPT-4 Turbo or Claude Instant. This delay proves negligible for applications prioritizing accuracy over responsiveness, such as code review, content generation, or analytical tasks. However, real-time applications like chatbots or interactive assistants may find the latency unacceptable, particularly for simple queries that don't benefit from deep reasoning. The choice depends on whether applications can tolerate slightly slower responses in exchange for significantly higher accuracy and thoughtfulness.
Advanced Optimization for Gemini 2.5 Pro API
Token usage optimization represents the most direct path to cost reduction, with sophisticated techniques achieving 40-50% decrease in token consumption without sacrificing output quality. Prompt compression eliminates redundant words, consolidates instructions, and uses abbreviations where clarity permits, reducing input tokens by 20-30%. Response control through precise output specifications prevents verbose responses that waste tokens on unnecessary elaboration. Structured formats like JSON or CSV prove more token-efficient than natural language for data-heavy responses. Context windowing maintains only essential conversation history, discarding irrelevant exchanges that bloat token counts. These optimizations compound to deliver substantial cost savings, particularly for high-volume applications.
Prompt engineering for efficiency goes beyond simple compression to fundamentally restructure how requests are formulated for optimal model performance. Few-shot examples demonstrate desired outputs more efficiently than lengthy descriptions, reducing both input tokens and improving response accuracy. Chain-of-thought prompting for complex tasks paradoxically reduces total tokens by preventing failed attempts that require regeneration. Role-based prompts like "You are a concise technical writer" establish behavioral patterns that naturally produce efficient responses. Template-based approaches with variable substitution minimize repeated instructions across similar requests. These techniques require initial investment in prompt development but yield consistent token savings throughout application lifecycle.
Response streaming techniques improve perceived performance while enabling early termination of unsatisfactory outputs, saving both time and tokens. Streaming responses character by character allows immediate display to users, masking the latency of complete generation. Early termination triggers when initial output indicates misunderstanding or poor quality prevent wasting tokens on complete but useless responses. Progressive rendering shows partial results while continuing generation, valuable for long-form content where users can begin reading immediately. Chunk-based processing enables parallel operations on response segments, improving overall throughput. These techniques prove particularly valuable for interactive applications where user experience matters as much as cost optimization.
Parallel processing patterns maximize throughput within rate limits by intelligently batching and distributing requests across available capacity. Asynchronous request handling allows multiple API calls to process simultaneously without blocking, essential for maintaining responsiveness under load. Request pooling aggregates multiple user queries into batched API calls, amortizing overhead across multiple operations. Pipeline architectures process different stages of complex tasks in parallel, reducing end-to-end latency. Load distribution across multiple provider accounts or endpoints multiplies effective rate limits while maintaining single interface. These patterns require careful orchestration to prevent rate limit violations while maximizing utilization of available capacity.
Future of Free Gemini 2.5 Pro API Access
Market dynamics suggest the landscape of free AI API access will continue evolving rapidly as competition intensifies and open-source alternatives mature. Google's indication that Gemini 2.5 Pro will transition to paid-only access after the experimental period follows established patterns, though competitive pressure from Meta's free Llama models and Microsoft's aggressive pricing may force reconsideration. The emergence of specialized hardware like Groq's LPU and Cerebras' wafer-scale processors promises dramatic cost reductions that could enable sustainable free tiers for advanced models. Third-party aggregators will likely proliferate, offering increasingly sophisticated optimization and arbitrage strategies that democratize access to premium models.
Alternative models on the horizon promise to challenge Gemini's dominance while potentially offering more accessible pricing models. Anthropic's upcoming Claude improvements focus on reasoning capabilities that could match or exceed Gemini's thinking model approach. OpenAI's continued GPT development emphasizes multimodal capabilities and image generation that provide different value propositions. Open-source initiatives like EleutherAI and Stability AI continue pushing boundaries of what's possible without proprietary constraints. Chinese models from Baidu, Alibaba, and others offer competitive performance at lower costs, though with potential regulatory and security considerations. These alternatives ensure continued innovation and price competition that benefits developers.
Recommendations for developers navigating this evolving landscape emphasize flexibility and abstraction over commitment to specific providers. Building provider-agnostic architectures ensures applications can adapt to changing availability and pricing without major refactoring. Implementing comprehensive cost tracking and optimization from the start prevents budget surprises as usage scales. Maintaining awareness of emerging models and providers through continuous evaluation ensures optimal price-performance ratios. Investing in prompt engineering and response optimization provides value regardless of underlying model choice. Most importantly, designing systems that gracefully degrade when premium services become unavailable ensures application resilience regardless of API accessibility changes. The future of AI API access remains uncertain, but developers who build flexible, efficient systems will thrive regardless of how the landscape evolves.