The release of OpenAI’s o3 model series represents a significant leap in AI capabilities, delivering unprecedented reasoning power for STEM fields, complex problem-solving, and code generation. However, these enhanced capabilities come with substantial cost implications that developers and organizations must carefully consider before implementation.
This comprehensive guide analyzes the latest OpenAI o3 API pricing structure as of April 2025, providing practical optimization strategies to maximize your return on investment.
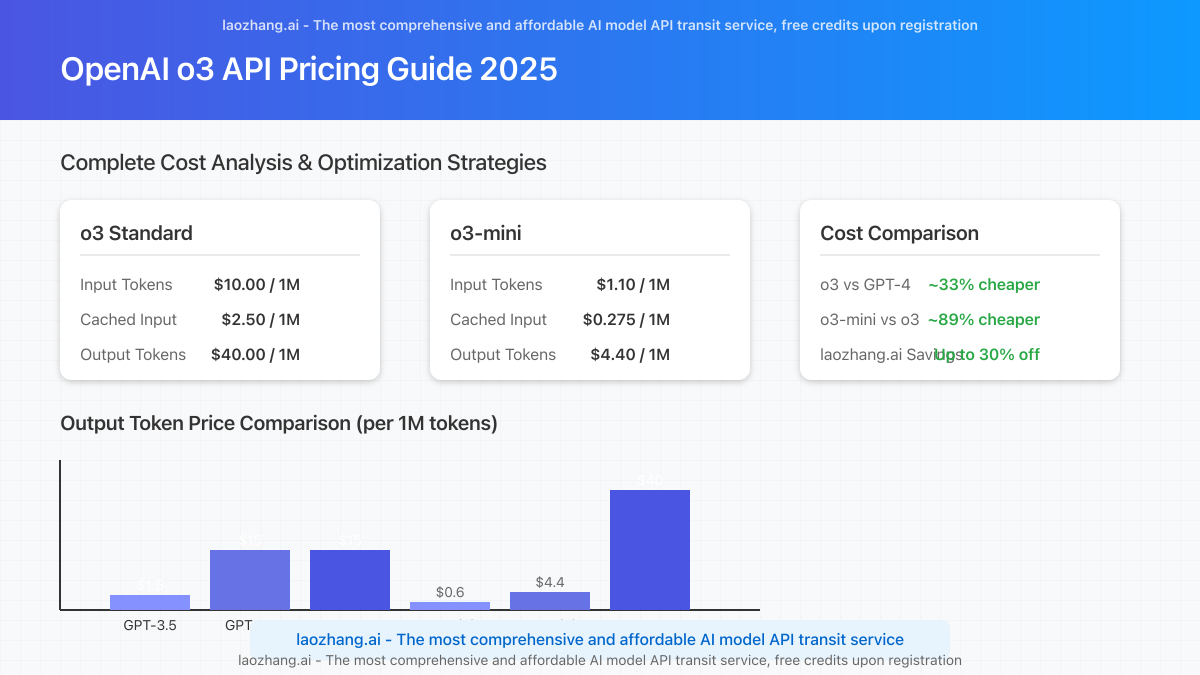
Complete o3 API Pricing Breakdown (Updated April 2025)
OpenAI’s o3 model series represents their most advanced reasoning models, with pricing that reflects the significant computational resources required to power these systems:
o3 (Standard) Model Pricing
| Token Type | Cost per 1M Tokens | Cost per 1K Tokens |
|---|---|---|
| Input Tokens | $10.00 | $0.01 |
| Cached Input | $2.50 | $0.0025 |
| Output Tokens | $40.00 | $0.04 |
o3-mini Model Pricing
| Token Type | Cost per 1M Tokens | Cost per 1K Tokens |
|---|---|---|
| Input Tokens | $1.10 | $0.0011 |
| Cached Input | $0.275 | $0.000275 |
| Output Tokens | $4.40 | $0.0044 |
Key Insight: o3-mini delivers approximately 85-90% of the capabilities of the full o3 model at just ~11% of the cost, making it the more cost-effective choice for most applications.
OpenAI Models Cost Comparison
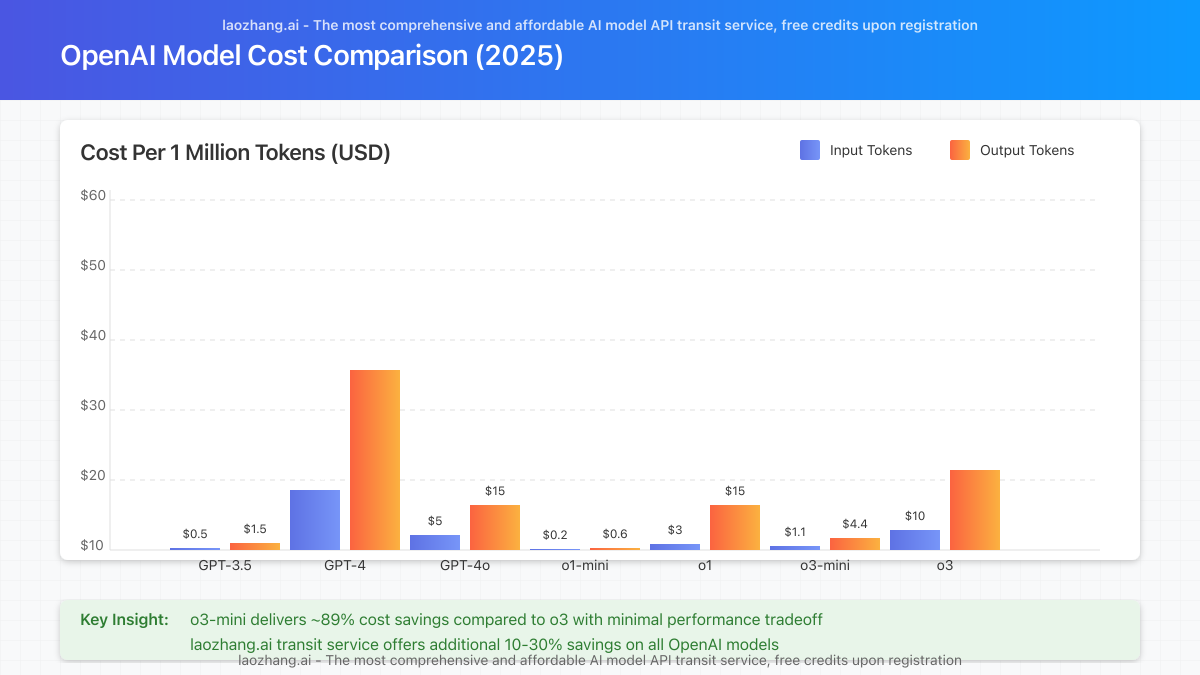
To put these costs in perspective, here’s how o3 pricing compares with other OpenAI models:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Relative Power |
|---|---|---|---|
| GPT-3.5 Turbo | $0.50 | $1.50 | Base level |
| GPT-4 | $30.00 | $60.00 | Advanced |
| GPT-4o | $5.00 | $15.00 | Advanced+ |
| o1-mini | $0.20 | $0.60 | Reasoning level 1 |
| o1 | $3.00 | $15.00 | Advanced reasoning |
| o3-mini | $1.10 | $4.40 | Powerful reasoning |
| o3 | $10.00 | $40.00 | Elite reasoning |
Real-World Cost Analysis: Practical Examples
Understanding theoretical pricing is one thing, but what does this mean for actual applications? Let’s examine some typical use cases and their associated costs.
Case Study 1: Enterprise Research Assistant
- Average input: 8,000 tokens per query
- Average output: 4,000 tokens per response
- Daily queries: 50
- Monthly cost using o3:
- Input: 8,000 × 50 × 30 × $0.01/1K tokens = $120
- Output: 4,000 × 50 × 30 × $0.04/1K tokens = $240
- Total: $360/month
- Monthly cost using o3-mini:
- Input: 8,000 × 50 × 30 × $0.0011/1K tokens = $13.20
- Output: 4,000 × 50 × 30 × $0.0044/1K tokens = $26.40
- Total: $39.60/month
- Potential savings: $320.40/month ($3,844.80/year)
Case Study 2: SaaS Code Generation Platform
- Average input: 3,000 tokens per query
- Average output: 5,000 tokens per response
- Daily queries: 2,000
- Monthly cost using o3:
- Input: 3,000 × 2,000 × 30 × $0.01/1K tokens = $1,800
- Output: 5,000 × 2,000 × 30 × $0.04/1K tokens = $12,000
- Total: $13,800/month
- Monthly cost using o3-mini:
- Input: 3,000 × 2,000 × 30 × $0.0011/1K tokens = $198
- Output: 5,000 × 2,000 × 30 × $0.0044/1K tokens = $1,320
- Total: $1,518/month
- Potential savings: $12,282/month ($147,384/year)
Critical Note: The o3 model’s advanced reasoning capabilities typically result in more thorough outputs, which often leads to 20-30% higher token counts than expected. Budget accordingly.
o3 vs. o3-mini: Strategic Model Selection Framework
With a nearly 10× price difference between o3 and o3-mini, selecting the right model is crucial for cost management. Here’s a practical framework to guide your decision:
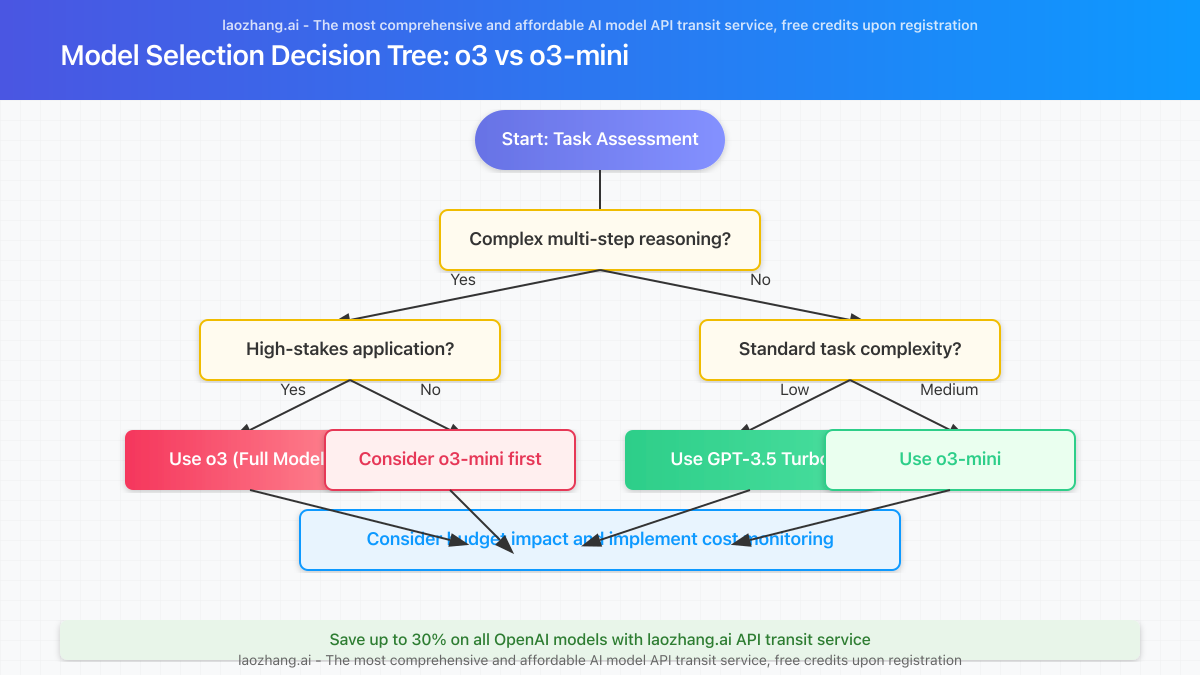
When to Use o3 (Full Model)
- Complex reasoning tasks: Mathematical proofs, scientific research analysis, advanced code architecture design
- Multi-step problem solving: Tasks requiring several logical steps and deep analysis
- High-stakes applications: Medical analysis, financial modeling, critical infrastructure
- Research applications: When exploring the cutting edge of what AI can accomplish
When to Use o3-mini
- Standard coding tasks: Code completion, bug fixing, simple feature implementation
- Content enhancement: Writing assistance, content generation, summarization
- Educational applications: Standard math and science problem solving
- Customer support: Advanced but straightforward query resolution
- Data analysis: Pattern recognition and basic statistical analysis
5 Proven Cost Optimization Strategies
Implementing these strategies can significantly reduce your API costs while maintaining high-quality outputs:
1. Implement Token-Efficient Prompting
Carefully craft prompts to minimize token usage without sacrificing quality:
- Use precise instructions that clearly define the required output format
- Remove unnecessary context and examples
- Structure prompts with clear delimiters
- Consider using system instructions to set global parameters
2. Utilize Response Caching
Implement a robust caching system to avoid redundant API calls:
- Cache common queries and their responses
- Use semantic similarity to match new queries with cached responses
- Implement tiered caching with expiration policies based on content type
3. Implement Hybrid Model Approach
Use different models based on task complexity:
- Start with GPT-3.5 Turbo for simple tasks (lowest cost)
- Use o3-mini for moderately complex reasoning tasks
- Reserve o3 only for tasks that specifically require its advanced capabilities
4. Optimize for Token Efficiency
Fine-tune your implementation to minimize token usage:
- Compress input data when appropriate
- Use function calling for structured outputs
- Implement proper chunking for large documents
- Set maximum token limits for responses
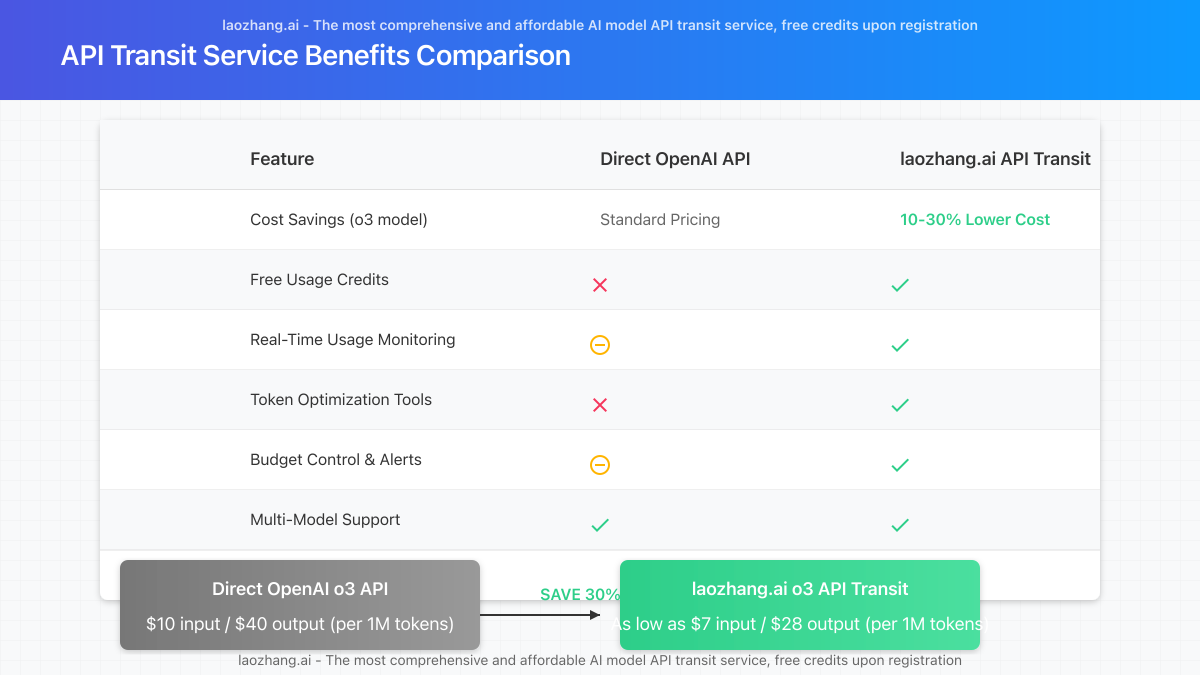
5. Consider API Transit Services
Use API transit services to access OpenAI models at reduced rates:
- Services like laozhang.ai offer discounted access to OpenAI models
- Save 10-30% on standard API costs through volume purchasing
- Benefit from additional features like usage monitoring and cost controls
Implementation Best Practices
For optimal results and cost-efficiency with o3 models, follow these implementation guidelines:
Monitoring and Budgeting
// Cost monitoring system
function monitorApiCosts(currentUsage) {
const dailyBudget = 100; // $100 per day budget
const warningThreshold = 0.7; // Alert at 70% of budget
if ((currentUsage / dailyBudget) > warningThreshold) {
sendAlert(`API usage at ${Math.round(currentUsage / dailyBudget * 100)}% of daily budget`);
}
if (currentUsage > dailyBudget) {
enableEmergencyRateLimiting();
}
}
Adaptive Model Selection
function selectOptimalModel(query) {
// Simple complexity analysis
let complexity = calculateQueryComplexity(query);
// Select model based on complexity score
if (complexity < 3) return 'gpt-3.5-turbo';
if (complexity < 7) return 'o3-mini';
return 'o3';
}
function calculateQueryComplexity(query) {
let score = 0;
// Length-based complexity
score += query.length / 100;
// Keyword-based complexity
const complexKeywords = ['prove', 'analyze', 'compare', 'synthesize'];
complexKeywords.forEach(keyword => {
if (query.toLowerCase().includes(keyword)) score += 1;
});
// Domain-specific complexity
const technicalDomains = ['mathematics', 'physics', 'machine learning'];
technicalDomains.forEach(domain => {
if (query.toLowerCase().includes(domain)) score += 1;
});
return score;
}
Implementation Example with laozhang.ai API Transit
Here’s a practical example of accessing o3 models through laozhang.ai’s cost-effective API transit service:
// Example code for accessing o3 via laozhang.ai API transit
const fetch = require('node-fetch');
async function generateO3Response(prompt) {
const response = await fetch('https://api.laozhang.ai/v1/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${process.env.LAOZHANG_API_KEY}`
},
body: JSON.stringify({
model: 'o3', // Use 'o3-mini' for cost efficiency
messages: [
{ role: 'user', content: prompt }
],
temperature: 0.7,
max_tokens: 1000
})
});
return await response.json();
}
// Usage example
generateO3Response("Explain quantum computing in simple terms")
.then(response => console.log(response))
.catch(error => console.error(error));
Get Started: Register for laozhang.ai API transit service at https://api.laozhang.ai/register/?aff_code=JnIT and receive bonus credits upon registration.
Frequently Asked Questions
Is o3 worth the significant price premium over o3-mini?
For most applications, o3-mini delivers 85-90% of the capabilities at just 11% of the cost. The full o3 model is primarily justified for research applications, complex reasoning tasks, and cases where absolute top-tier performance is required regardless of cost considerations.
How do token limits work with o3 models?
The o3 model supports a 128K context window, while o3-mini supports a 64K context window. Remember that longer contexts contribute to higher input token costs, so optimize your prompts to include only necessary information.
Are there volume discounts available for o3 API usage?
OpenAI offers enterprise plans with customized pricing for high-volume users. Organizations with significant usage should contact OpenAI’s sales team or consider using transit services like laozhang.ai that offer more favorable rates through bulk purchasing.
How accurately can I estimate costs before implementation?
Use OpenAI’s tokenizer tools to estimate token counts for typical prompts and expected responses. Multiply by your anticipated volume and the per-token rates to get a baseline estimate. Add a 20-30% buffer for unexpected usage patterns and longer-than-expected responses from the o3 model.
Can I switch between o3 and o3-mini dynamically?
Yes, the API allows you to specify the model for each request. Implementing dynamic model selection based on query complexity is a recommended strategy for optimizing costs while maintaining quality where needed.
Conclusion: Maximizing ROI with Strategic Implementation
OpenAI’s o3 model series represents a significant advance in AI capabilities but requires careful implementation to manage costs effectively. Organizations should:
- Start with o3-mini for most applications, reserving the full o3 model for specific use cases that truly require its advanced reasoning
- Implement strict cost controls including token limits, caching, and usage monitoring
- Optimize prompts to reduce token usage while maintaining response quality
- Consider API transit services like laozhang.ai for more favorable pricing, especially for higher volumes
- Regularly review usage patterns to identify opportunities for further optimization
By following these strategies, organizations can leverage the powerful capabilities of o3 models while keeping costs under control, ensuring a sustainable implementation that delivers maximum value.
For more information or personalized assistance with API integration, contact: WeChat: ghj930213