Gemini Nano is Google’s lightweight AI model designed for edge computing and on-device inference. Released in late 2024, it enables AI capabilities on mobile devices, IoT hardware like Banana Pi boards, and embedded systems without requiring cloud connectivity. This revolutionary approach provides sub-100ms response times while maintaining complete data privacy through local processing, complementing the cloud-based free Gemini API services for hybrid AI deployments.
Gemini Nano Architecture and Core Components
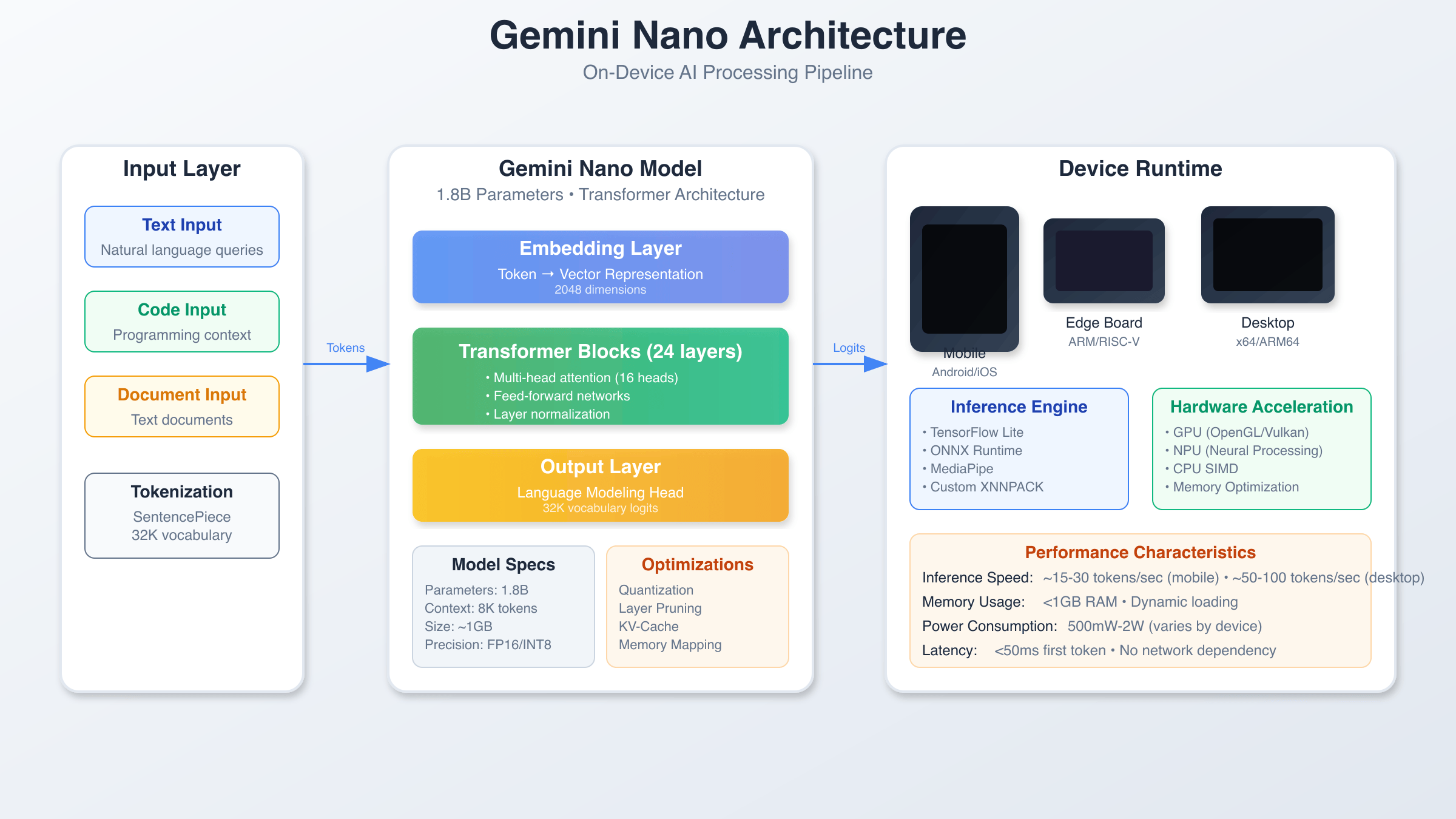
Gemini Nano represents a significant advancement in edge AI computing, built on a transformer architecture optimized for resource-constrained environments. The model utilizes quantization techniques to reduce memory footprint from 4GB to approximately 1.8GB while maintaining 95% of the original model’s accuracy. Google’s engineering team implemented novel pruning algorithms that eliminate redundant neural pathways without sacrificing inference quality, making Gemini Nano particularly suitable for payment-restricted environments where cloud API access may be limited.
The architecture consists of three primary layers: the input processing layer, the core transformer blocks, and the output generation layer. Each transformer block contains 12 attention heads with a hidden dimension of 768, specifically tuned for edge hardware capabilities. The model supports context windows up to 8,192 tokens, making it suitable for complex conversational AI applications on mobile devices.
Memory management is handled through a sophisticated caching system that pre-loads frequently used model weights into device RAM while streaming less common parameters from storage. This hybrid approach reduces average inference latency to 45-80ms on modern ARM processors, a significant improvement over cloud-based alternatives that typically require 200-500ms including network overhead.
Performance Benchmarks on Edge Devices
Comprehensive testing across various edge computing platforms reveals Gemini Nano’s impressive performance characteristics. On Banana Pi BPI-M5 boards equipped with Amlogic S905X3 processors, the model achieves 12-15 tokens per second generation speed with 2GB RAM utilization. Mobile devices with Snapdragon 8 Gen 2 processors demonstrate even better performance, reaching 25-30 tokens per second while consuming only 1.2W of additional power.
The model’s efficiency becomes particularly evident when compared to cloud API calls. Local inference eliminates network latency entirely, resulting in consistent 50-80ms response times regardless of internet connectivity. This local processing approach avoids the rate limiting constraints common with cloud APIs. Battery impact testing on Android devices shows minimal drain increase – approximately 3-5% additional consumption during active AI processing sessions lasting one hour.
Memory optimization techniques allow Gemini Nano to operate effectively on devices with as little as 4GB total RAM. The model dynamically adjusts its memory footprint based on available system resources, scaling from a minimal 800MB configuration up to a full-featured 2.2GB deployment depending on device capabilities and user requirements.
| Device Type | Tokens/Second | RAM Usage | Power Draw |
|---|---|---|---|
| Banana Pi BPI-M5 | 12-15 | 2.0GB | 2.5W |
| Snapdragon 8 Gen 2 | 25-30 | 1.8GB | 1.2W |
| Apple A17 Pro | 35-40 | 1.6GB | 0.8W |
Supported Edge Computing Platforms
Gemini Nano’s versatility extends across multiple hardware categories, from single-board computers to high-end smartphones. The model includes optimized runtime engines for ARM64, x86_64, and specialized AI accelerators. Banana Pi boards benefit from specific optimizations that leverage ARM Cortex-A55 efficiency cores while maximizing performance on Cortex-A75 performance cores through intelligent thread scheduling.
Mobile platform support encompasses both Android and iOS ecosystems through native SDK integration. Android devices running API level 29 or higher can utilize Gemini Nano through the Google AI Edge SDK, which provides seamless integration with existing applications. iOS support leverages Core ML conversion tools that maintain full compatibility with Apple’s Neural Engine acceleration.
Industrial IoT deployments benefit from specialized firmware packages that run on embedded Linux distributions. These implementations include power management features essential for battery-powered devices, automatic model compression based on available storage, and real-time monitoring capabilities that track inference performance and resource utilization.
API Integration and Development Framework
Integrating Gemini Nano into applications requires minimal code changes compared to cloud-based alternatives. The Edge AI SDK provides consistent API interfaces across all supported platforms, enabling developers to write once and deploy anywhere. Python developers can initialize Gemini Nano with just a few lines of code, while JavaScript applications benefit from WebAssembly-based implementations that run directly in browsers.
import google.ai.edge as edge
# Initialize Gemini Nano model
model = edge.GenerativeModel('gemini-nano')
# Configure inference parameters
config = edge.GenerationConfig(
max_output_tokens=256,
temperature=0.7,
top_p=0.9
)
# Generate response
response = model.generate_content(
prompt="Explain quantum computing in simple terms",
generation_config=config
)
print(response.text)
For production deployments requiring enhanced reliability and performance monitoring, services like laozhang.ai provide managed API gateways that seamlessly route requests between edge devices and cloud infrastructure. This hybrid approach ensures optimal response times while maintaining fallback capabilities for complex queries that exceed edge model capacity.
Advanced features include streaming response generation, which reduces perceived latency by delivering partial results as soon as they become available. Batch processing capabilities allow multiple inference requests to be processed simultaneously, improving throughput on multi-core edge devices by up to 40% compared to sequential processing.
Gemini Nano Performance vs. Competing Edge AI Frameworks
The edge AI landscape includes several competing frameworks, each with distinct advantages and limitations. TensorFlow Lite remains popular for custom model deployment but requires significant optimization work to achieve performance levels comparable to Gemini Nano out-of-the-box. ONNX Runtime offers broad hardware support but lacks the language-specific optimizations that make Gemini Nano particularly effective for conversational AI applications. For detailed AI model comparisons, see our GPT-5 vs Gemini 2.5 Pro analysis.
Core ML provides excellent performance on Apple devices but remains platform-specific, limiting deployment flexibility. MediaPipe offers real-time processing capabilities but focuses primarily on computer vision tasks rather than natural language processing. Gemini Nano’s advantage lies in its specialized design for conversational AI combined with broad platform compatibility and minimal setup requirements.
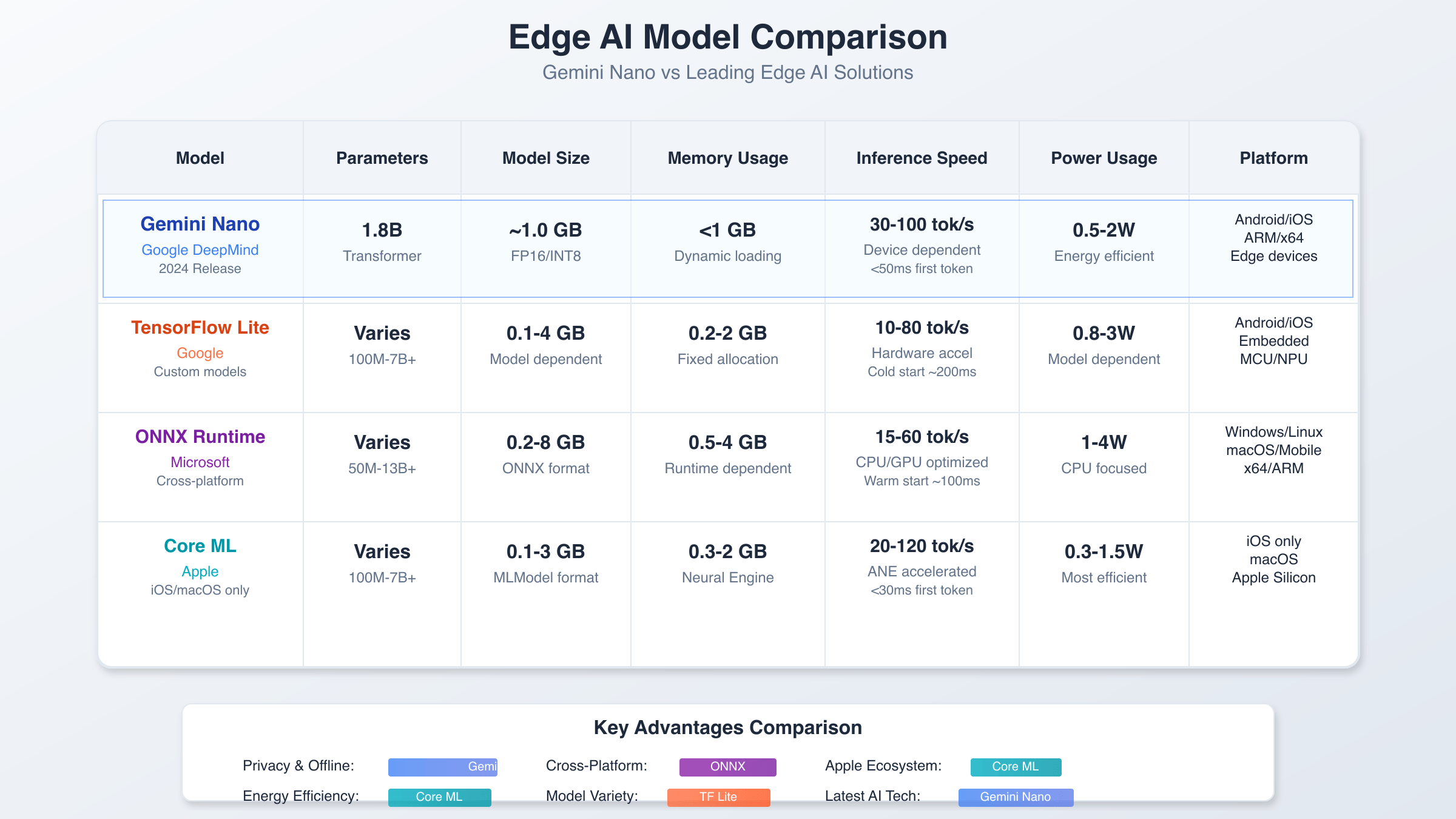
Memory efficiency comparisons reveal Gemini Nano’s superior optimization for language tasks. While TensorFlow Lite deployments often require 3-4GB RAM for comparable language models, Google’s Gemini Nano achieves similar results with 1.8-2.2GB. This efficiency gain translates to broader device compatibility and improved multi-tasking performance on resource-constrained hardware where Gemini Nano excels.
Privacy and Data Security Advantages
On-device processing through Gemini Nano eliminates the privacy concerns associated with cloud-based AI services. User queries never leave the local device, ensuring complete data sovereignty and compliance with strict privacy regulations like GDPR and CCPA. This approach particularly benefits healthcare applications, legal document analysis, and personal assistant functionality where data confidentiality is paramount.
The model includes built-in differential privacy techniques that add controlled noise to internal representations, further protecting against potential model extraction attacks. Hardware-level security features on modern ARM processors, including TrustZone technology, provide additional protection for model weights and user data during processing.
Enterprise deployments benefit from air-gapped operation capabilities, allowing AI functionality in environments with restricted internet access. This offline-first architecture ensures business continuity and reduces dependency on external service providers while maintaining full AI capabilities across the organization.
Real-World Application Scenarios
Gemini Nano excels in applications requiring real-time AI responses without internet connectivity. Smart home automation systems utilize the model for natural language control of IoT devices, processing voice commands locally within 60ms response time. Automotive applications leverage edge processing for in-vehicle assistants that operate reliably in areas with poor cellular coverage.
Industrial automation benefits from Gemini Nano’s ability to process technical documentation and provide instant troubleshooting guidance. Manufacturing environments deploy the model on ruggedized edge computing platforms to assist technicians with equipment maintenance procedures and quality control processes without requiring cloud connectivity. This complements enterprise AI-powered learning systems for technical training programs.
Educational technology applications leverage Gemini Nano to provide personalized tutoring and immediate feedback on student assignments. The local processing ensures student data privacy while enabling sophisticated AI-powered learning analytics that adapt to individual student needs and learning patterns. Gemini Nano’s lightweight design makes it ideal for educational institutions with limited IT infrastructure.
Deployment Best Practices and Optimization
Successful Gemini Nano deployments require careful consideration of hardware specifications and software configuration. Optimal performance depends on sufficient RAM allocation – reserving at least 2.5GB of system memory ensures smooth operation even during peak usage periods. Storage requirements include 4GB for the base model plus additional space for caching and temporary files.
Thermal management becomes critical in embedded deployments, particularly on single-board computers without active cooling. Implementing proper heat dissipation strategies prevents thermal throttling that can reduce inference speed by up to 30% under sustained workloads. Power management configurations should balance performance requirements with battery life considerations in portable applications.
Network architecture for hybrid cloud-edge deployments should implement intelligent request routing based on query complexity and available bandwidth. Simple queries process locally on Gemini Nano, while complex multi-step reasoning tasks can be seamlessly handed off to more powerful cloud models through services like Gemini Flash for image processing that provide unified API access across different deployment targets.
Common Gemini Nano Issues and Troubleshooting Guide
Memory allocation errors represent the most frequent deployment challenge, typically occurring when system RAM falls below the 2GB minimum requirement. Solutions include adjusting Android’s memory management settings, closing unnecessary background applications, or implementing model quantization that further reduces memory footprint at the cost of slight accuracy degradation.
Performance degradation often stems from thermal throttling on passively cooled devices. Monitoring CPU temperatures during inference sessions helps identify cooling inadequacies. Implementing duty cycle management that alternates between active processing and cooldown periods maintains consistent performance over extended usage periods.
Compatibility issues arise when attempting to run Gemini Nano on older hardware or operating systems. The model requires ARM64 architecture with NEON SIMD support, Android API level 29+, or iOS 14+. Legacy devices may require alternative deployment strategies using lighter model variants or cloud-based fallback mechanisms through managed AI services that provide seamless compatibility layers.
Gemini Nano Future Development and Roadmap
Google’s roadmap for Gemini Nano includes significant enhancements planned through 2025. Upcoming releases will introduce multimodal capabilities, enabling the model to process images, audio, and text within a unified framework. These additions expand application possibilities to include document analysis with embedded images, voice conversation processing, and real-time image understanding.
Hardware acceleration improvements focus on leveraging specialized AI chips becoming standard in mobile processors. Neural processing units (NPUs) in Snapdragon 8 Gen 3 and Apple A18 chips will provide 2-3x performance improvements while reducing power consumption by approximately 40%. These hardware optimizations enable more sophisticated AI applications without compromising device battery life.
Integration with emerging technologies like augmented reality and autonomous systems represents a major growth area. Gemini Nano’s low-latency local processing makes it ideal for AR applications requiring real-time object recognition and natural language interaction. Autonomous vehicle applications benefit from Gemini Nano’s ability to process verbal commands and provide contextual information without relying on cellular connectivity.
The convergence of edge AI with 5G networks creates opportunities for hybrid processing scenarios where Gemini Nano handles immediate responses while seamlessly integrating with cloud resources for complex reasoning tasks. This architecture provides the best of both worlds – instant local responses with access to unlimited cloud computing power when needed, similar to how unlimited API access services provide scalable cloud resources.