GPT-4.5: Why Is OpenAI’s Most Expensive Model Not Worth Its Premium Price?
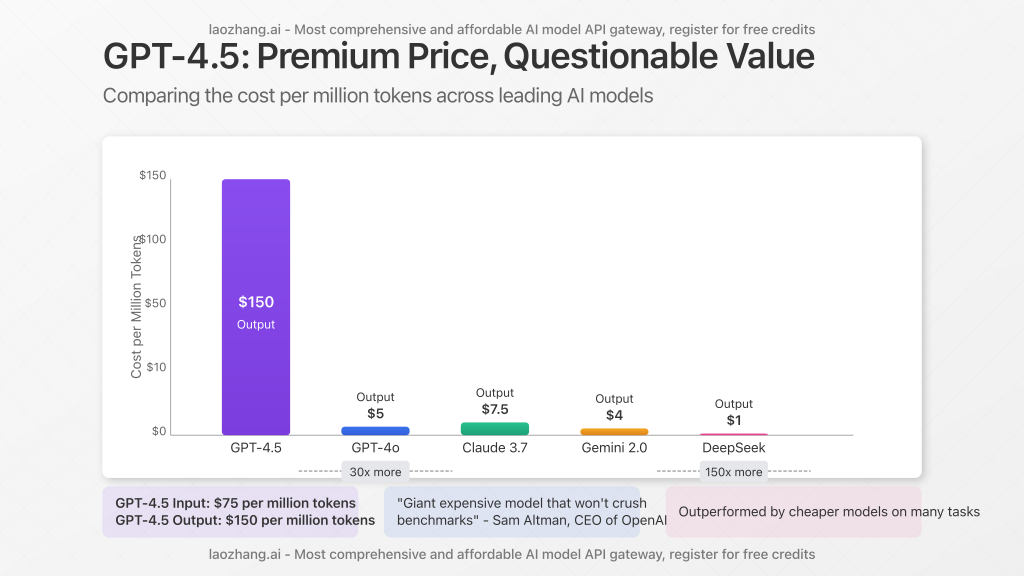
When OpenAI released GPT-4.5 on February 27, 2025, it came with a startling price tag that left many in the AI community questioning its value proposition. At $75 per million input tokens and $150 per million output tokens, GPT-4.5 is approximately 15-30 times more expensive than GPT-4o and a staggering 150-300 times costlier than some competing models. This article examines why GPT-4.5 commands such a premium price and whether its capabilities justify the cost compared to alternatives.
The Staggering Cost of GPT-4.5: By The Numbers
Let’s put GPT-4.5’s pricing in perspective with hard numbers:
- Input tokens: $75 per million (15x higher than GPT-4o at $5/million)
- Output tokens: $150 per million (30x higher than GPT-4o at $5/million)
- Monthly ChatGPT access: Initially required $200/month ChatGPT Pro subscription
- Business use case: A moderate API implementation could easily cost thousands per month versus hundreds for GPT-4o
Even OpenAI’s CEO Sam Altman acknowledged in a February 27 post that the new model is a “giant expensive model” that “won’t crush benchmarks.” This candid admission raises an important question: what makes GPT-4.5 so expensive to produce and operate?
Technical Reasons Behind GPT-4.5’s High Cost
According to AI experts and available information, several technical factors contribute to GPT-4.5’s astronomical pricing:
1. Massive Model Architecture
While OpenAI hasn’t officially disclosed GPT-4.5’s exact size, industry estimates suggest it contains significantly more parameters than GPT-4. For context, GPT-4 is believed to have approximately 1.8 trillion parameters across 120 layers, making it roughly 10 times larger than GPT-3. GPT-4.5 likely represents another substantial increase in model size.
2. Enormous Training Costs
Training a model of this scale requires immense computational resources. GPT-4 was estimated to cost around $63 million to train when accounting for computational power and training time. GPT-4.5, with its expanded capabilities, would have required even more extensive and costly training.
3. Hardware-Intensive Inference
Running GPT-4.5 for inference is extraordinarily resource-intensive. Large models like GPT-4.5 require specialized GPU clusters for deployment. According to industry analysis, GPT-4 needed 128 GPUs for inference, using 8-way tensor parallelism and 16-way pipeline parallelism. GPT-4.5 likely requires even more robust infrastructure.
4. Enhanced Multimodal Capabilities
GPT-4.5 incorporates advanced multimodal functionalities, including improved visual understanding and conversational abilities. These capabilities require additional specialized training and parameters, further increasing costs.
The Great Paradox: Capabilities vs. Cost
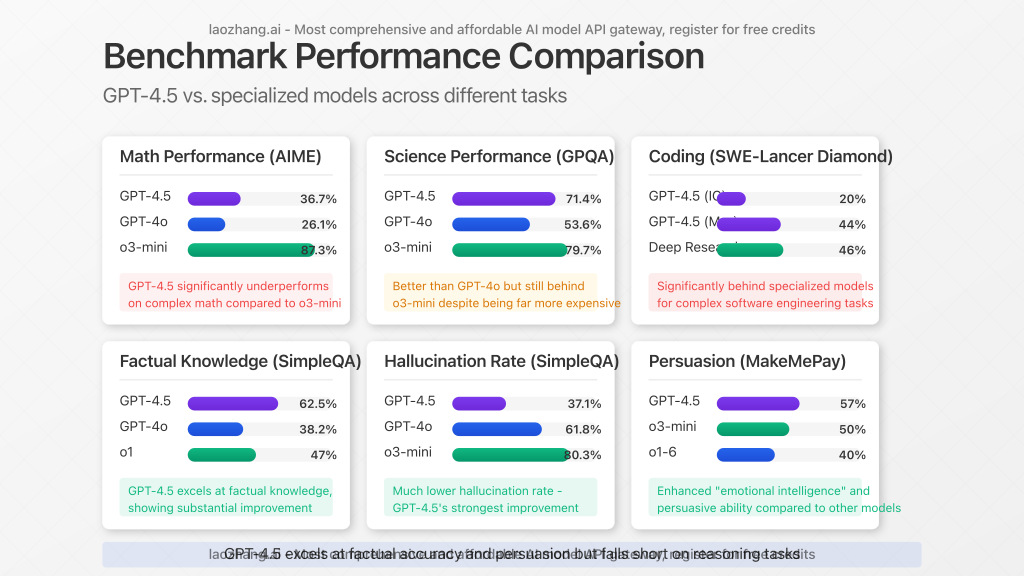
Despite its premium pricing, GPT-4.5 demonstrates a mixed performance profile when compared to both more affordable models and OpenAI’s own specialized offerings:
Areas Where GPT-4.5 Excels
GPT-4.5 does deliver meaningful improvements in several key areas:
- Reduced hallucinations: On OpenAI’s internal “SimpleQA” evaluation, GPT-4.5 achieved a 62.5% accuracy rate with a hallucination rate of only 37.1%, substantially better than GPT-4o’s 38.2% accuracy and concerning 61.8% hallucination rate.
- Enhanced conversational abilities: GPT-4.5 provides more natural, concise, and human-like responses, making interactions feel more authentic.
- Improved multimodal capabilities: The model demonstrates impressive abilities in processing and interpreting images, providing concise and accurate responses to visual inputs.
- “Emotional intelligence”: In OpenAI’s MakeMePay evaluation, GPT-4.5 achieved a 57% success rate at receiving payments—the highest among all tested models, suggesting enhanced persuasive capabilities.
Where GPT-4.5 Falls Short
Despite these strengths, GPT-4.5 underperforms in several critical areas, particularly when compared to more specialized and often less expensive models:
- Complex reasoning tasks: On AIME math competitions, GPT-4.5 scored just 36.7%, dramatically lower than o3-mini’s remarkable 87.3%.
- Science assessments: On GPQA science assessments, GPT-4.5 scored 71.4%, better than GPT-4o’s 53.6% but still lagging behind o3-mini’s 79.7%.
- Coding and software engineering: On SWE-Lancer Diamond, GPT-4.5 solved 20% of IC SWE tasks and 44% of SWE Manager tasks, still far behind deep research models.
- Benchmark performance: When compared to competitors like DeepSeek V3, GPT-4.5 consistently underperforms on GPQA, AIME 2024, and SWE-bench Verified benchmarks, despite costing orders of magnitude more.
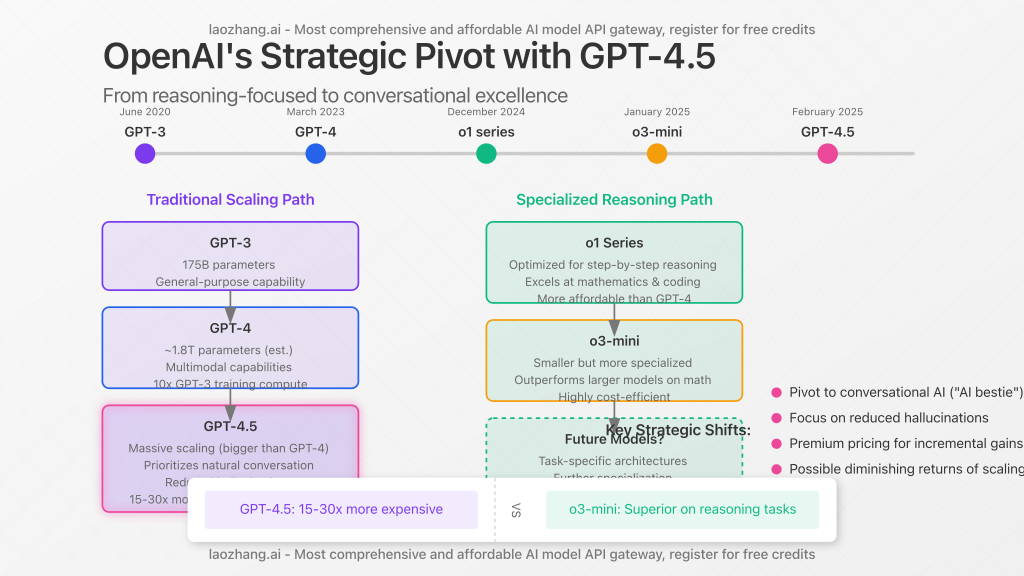
Strategic Shift: OpenAI’s Pivot to Conversational Excellence
GPT-4.5 represents a strategic pivot for OpenAI away from the reasoning-focused approach that has dominated recent releases. Rather than emphasizing step-by-step problem-solving like their specialized reasoning models o1 and o3-mini, GPT-4.5 leverages unsupervised learning to create more fluid, succinct, and conversational responses.
According to OpenAI’s own documentation, GPT-4.5 is “not a frontier model,” despite being their largest language model to date. As Dan Shipper, CEO of AI newsletter Every, aptly described: “It’s more like a personality, communication, and creativity upgrade than a huge intelligence leap. It’s like OpenAI is pivoting its base model from ‘bland assistant’ to ‘AI bestie.'”
The Diminishing Returns of Traditional LLM Scaling
GPT-4.5’s modest performance improvements despite massive computational investment raise profound questions about the future of AI development. As Ars Technica noted, GPT-4.5 “seems to prove that longstanding rumors of diminishing returns in training unsupervised-learning LLMs were correct and that the so-called ‘scaling laws’ cited by many for years have possibly met their natural end.”
Former OpenAI researcher Andrej Karpathy observed that GPT-4.5 is better than GPT-4o but in ways that are “subtle and difficult to express,” noting that “everything is a little bit better and it’s awesome, but also not exactly in ways that are trivial to point to.” This highlights the challenge of evaluating a model whose improvements are more qualitative than quantitative.
When Is GPT-4.5 Worth Its Premium Price?
For organizations weighing whether to adopt GPT-4.5, the decision comes down to a careful cost-benefit analysis. The model may be justified in scenarios where:
Scenarios Where GPT-4.5 Might Be Worth The Cost
- Factual accuracy is paramount: In medical, legal, or financial contexts where errors could have serious consequences, the reduced hallucination rate might justify the premium.
- Natural, human-like interactions are essential: Customer service applications where conversational fluency significantly impacts user experience may benefit from GPT-4.5’s more natural responses.
- Creative content generation: For writers, marketers, and content creators, GPT-4.5’s improvements in natural language generation may provide value that justifies the cost.
- High-stakes persuasive applications: GPT-4.5’s enhanced “emotional intelligence” could be valuable in applications requiring subtle persuasion or nuanced human interaction.
Better Alternatives for Most Use Cases
For most general-purpose applications, more cost-effective alternatives include:
- GPT-4o: For general tasks, GPT-4o offers comparable performance at a fraction of the cost.
- Specialized reasoning models: For mathematics, coding, and complex reasoning, models like o3-mini or DeepSeek provide superior performance at significantly lower prices.
- Competing multimodal models: Claude 3.7 Sonnet and Gemini Flash 2.0 offer strong performance across multiple domains at substantially lower costs.
- Fine-tuned smaller models: For specific applications, fine-tuning smaller models can often yield better performance than using a generic large model.
Looking Forward: The Future of AI Model Development
GPT-4.5’s mixed reception points to several important trends that will likely shape AI development in the coming years:
- Specialized over general-purpose: The superior performance of specialized models in reasoning, math, and coding suggests that the future may belong to purpose-built AI systems rather than one-size-fits-all models.
- Efficiency over scale: Models like Meta’s LLama 3 and Mistral 7B show that smaller, highly optimized models can outperform massive models in certain tasks with much lower compute costs.
- New architectures over brute force scaling: The true frontier may lie not in scaling existing approaches but in developing new architectures and training methods that combine the reasoning power of specialized models with conversational fluency.
Conclusion: A Premium Price for Incremental Gains
GPT-4.5 represents an incremental advance in certain aspects of AI performance, particularly in natural conversation, reduced hallucinations, and multimodal capabilities. However, its astronomical pricing and underwhelming performance on reasoning tasks compared to much cheaper alternatives make it a hard sell for many potential users.
As AI researcher Aran Komatsuzaki noted, GPT-4.5 costs around 15-20 times more than GPT-4o to access via API, while Ashutosh Shrivastava described the pricing as “insane,” asking “What on earth are they even thinking??”
The value proposition for businesses solving complex technical problems is particularly weak when specialized models offer superior performance at a fraction of the cost. As noted in The Algorithmic Bridge, “Who would pay 300 times the price to use this sloth when competitors have already commoditized its value?”
For most users and organizations, the dramatically higher cost of GPT-4.5 simply doesn’t justify its incremental improvements over more affordable alternatives. As the AI landscape continues to evolve, GPT-4.5 may be remembered less as a revolutionary breakthrough and more as a transitional model that signaled the limits of traditional scaling approaches in artificial intelligence.
For those seeking the best balance of performance and cost, exploring specialized models, fine-tuning smaller architectures, or using more affordable general-purpose models like GPT-4o, Claude 3.7, or Gemini will likely yield better results for most applications.
To access the most cost-effective AI APIs including GPT, Claude, and Gemini models, consider LaoZhang-AI – the unified, low-cost API gateway with the lowest prices and a free trial for developers worldwide.
Frequently Asked Questions
Why is GPT-4.5 so much more expensive than other models?
GPT-4.5’s high price reflects its massive computational requirements for both training and inference, its expanded parameter count, and its advanced multimodal capabilities. OpenAI likely also factors in the R&D costs of developing such a large model.
Does GPT-4.5 outperform other models on every task?
No. While GPT-4.5 excels in conversational abilities and has reduced hallucinations, it underperforms compared to specialized models on reasoning tasks, mathematics, and coding challenges. Models like o3-mini achieve significantly better results on these tasks at a fraction of the cost.
Will GPT-5 be even more expensive than GPT-4.5?
If OpenAI continues with traditional scaling approaches, GPT-5 would likely be substantially more expensive. However, the diminishing returns seen with GPT-4.5 might push OpenAI to explore more efficient architectures and training methods for future models.
What alternatives should I consider instead of GPT-4.5?
For most general applications, GPT-4o offers similar capabilities at much lower costs. For specific tasks, specialized models like o3-mini (reasoning, math, coding) or models from competitors like Claude 3.7 Sonnet and Gemini Flash 2.0 provide excellent performance at significantly lower prices.
Is GPT-4.5’s reduced hallucination rate worth the price premium?
For high-stakes applications in medicine, law, or finance where factual accuracy is critical, the reduced hallucination rate might justify the cost. For most general applications, however, the improvement doesn’t warrant the 15-30x price increase.
How can I access AI models at more affordable rates?
Services like LaoZhang-AI offer unified API access to a range of models including GPT, Claude, and Gemini at significantly reduced prices, with free trials available for developers.