Gemini API Price Guide 2025: Complete Cost Analysis & Calculator
Gemini API pricing starts at $0.0002 per 1K input tokens for Flash model, with Pro at $1.25 per million tokens. The generous free tier includes 1,500 daily requests. Batch processing offers 50% discounts. Compared to ChatGPT’s $30/million tokens, Gemini provides 24x cost savings. Most applications spend $50-500 monthly, with enterprise usage reaching $5,000+. Calculate exact costs using model choice, token volume, and batch ratios.

Understanding Gemini API Pricing Structure
The Gemini API pricing model operates on a token-based system that fundamentally differs from traditional API pricing structures. Unlike subscription-based services or per-request pricing, Gemini charges based on the actual computational resources consumed, measured in tokens. This granular approach ensures developers pay only for what they use, making it particularly attractive for applications with variable workloads. For developers just starting, obtaining a Gemini API key is the first step to accessing these competitive pricing tiers.
Tokens represent the atomic units of text processing in the Gemini ecosystem. In English text, one token approximately equals four characters or about three-quarters of a word. This means a typical 1,000-word document consumes roughly 1,333 tokens. However, tokenization varies significantly across languages, with languages like Chinese or Japanese often requiring more tokens per character due to their linguistic complexity. The official Google AI pricing documentation provides the most up-to-date token calculations.
The pricing structure distinguishes between input and output tokens, reflecting the computational asymmetry in AI processing. Input tokens, representing the prompts and context you send to the API, cost significantly less than output tokens generated by the model. For Gemini 1.5 Pro, input tokens cost $1.25 per million, while output tokens cost $5.00 per million—a 4:1 ratio that impacts cost optimization strategies.
Google’s free tier democratizes AI access by providing substantial daily quotas without requiring payment information. The Gemini 1.5 Flash model offers 1,500 requests per day, 15 requests per minute, and 1 million tokens per minute in the free tier. This generous allocation supports development, testing, and even small-scale production applications. The free tier resets daily at midnight Pacific Time, creating interesting optimization opportunities for global applications operating across time zones. Learn more about maximizing the free Gemini API to reduce your costs even further.
Gemini API Price Tiers: Complete 2025 Breakdown
Google structures Gemini API access into distinct pricing tiers, each designed to serve specific use cases and scale requirements. Understanding these tiers helps developers choose the most cost-effective option for their applications while avoiding unexpected expenses as usage grows.
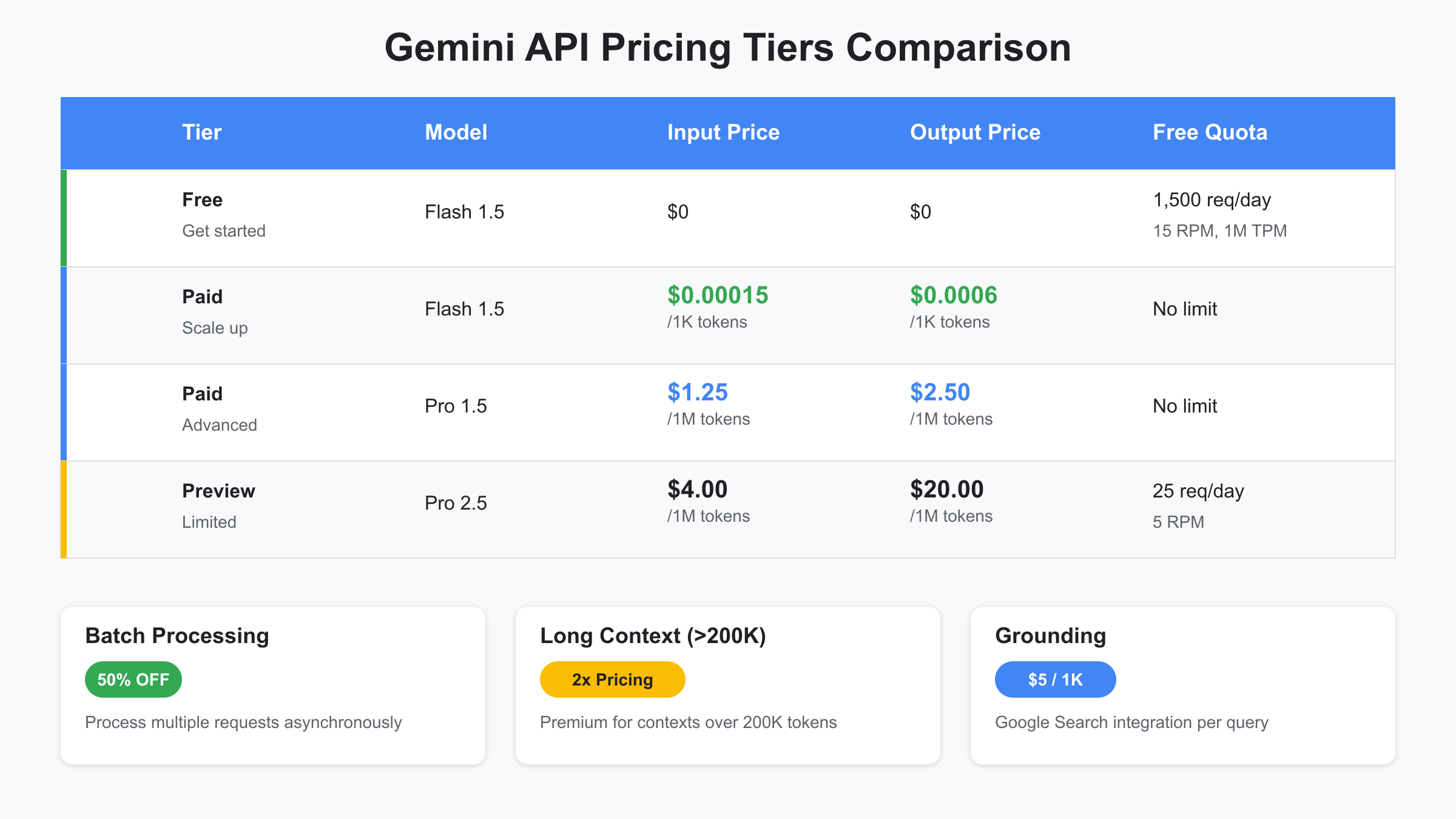
The Gemini 1.5 Flash model represents the entry point for most developers, offering an impressive balance between capability and cost. In the free tier, Flash provides 1,500 daily requests with rate limits of 15 RPM and 1 million TPM. When transitioning to paid usage, Flash charges just $0.00015 per thousand input tokens and $0.0006 per thousand output tokens. This translates to $0.15 and $0.60 per million tokens respectively, making it approximately 8x cheaper than the Pro model.
Gemini 1.5 Pro targets applications requiring advanced reasoning, creative generation, and complex analysis. With no free tier for API access (though available in Google AI Studio), Pro starts at $1.25 per million input tokens and $5.00 per million output tokens. Despite the higher cost, Pro delivers superior performance in tasks requiring nuanced understanding, making it the preferred choice for customer service automation, content creation, and technical documentation.
The preview release of Gemini 2.5 Pro introduces next-generation capabilities at premium pricing. Currently limited to 25 requests per day with 5 RPM in preview mode, the 2.5 Pro model charges $4.00 per million input tokens and $20.00 per million output tokens. Early adopters report significant improvements in reasoning depth and creative output quality, justifying the 3.2x price increase over 1.5 Pro for cutting-edge applications. For detailed analysis of the newer models, see our Gemini 2.5 Pro pricing guide.
Enterprise customers requiring custom solutions can negotiate directly with Google Cloud sales for tailored pricing. These agreements typically include volume discounts ranging from 10-50%, dedicated support channels, custom rate limits, and service level agreements (SLAs) guaranteeing uptime and performance. Organizations spending over $10,000 monthly often find enterprise agreements reduce total costs by 25-40% compared to standard pricing.
Special pricing modifiers significantly impact total costs. Batch processing, available for non-real-time workloads, provides a flat 50% discount with a 24-hour completion SLA. Long context requests exceeding 200,000 tokens incur 2x standard pricing, reflecting the increased computational complexity. The Grounding feature, which enhances responses with real-time Google Search data, adds $5 per 1,000 grounding queries, potentially doubling costs for fact-checking applications.
Gemini API Price Calculator: Real-Time Cost Estimation
Accurately estimating Gemini API costs requires understanding the interplay between token consumption, model selection, and usage patterns. Building a comprehensive cost calculator helps developers budget effectively and identify optimization opportunities before deployment.
The foundation of cost calculation starts with token estimation. Since billing depends on actual token usage rather than character or word counts, implementing accurate token counting becomes crucial. The following Python implementation provides a robust framework for cost estimation:
import tiktoken # OpenAI's tokenizer, similar to Gemini's approach
class GeminiCostCalculator:
def __init__(self):
self.pricing = {
'flash': {'input': 0.00015, 'output': 0.0006}, # per 1K tokens
'pro': {'input': 1.25, 'output': 5.0}, # per 1M tokens
'pro_2_5': {'input': 4.0, 'output': 20.0} # per 1M tokens
}
def estimate_tokens(self, text: str) -> int:
"""Estimate token count for given text"""
# Rough estimation: 1 token ≈ 4 characters
return len(text) // 4
def calculate_request_cost(self, model: str, input_text: str,
expected_output_tokens: int,
use_batch: bool = False) -> dict:
"""Calculate cost for a single request"""
input_tokens = self.estimate_tokens(input_text)
if model == 'flash':
input_cost = (input_tokens / 1000) * self.pricing['flash']['input']
output_cost = (expected_output_tokens / 1000) * self.pricing['flash']['output']
else:
input_cost = (input_tokens / 1_000_000) * self.pricing[model]['input']
output_cost = (expected_output_tokens / 1_000_000) * self.pricing[model]['output']
total_cost = input_cost + output_cost
if use_batch:
total_cost *= 0.5 # 50% discount for batch processing
return {
'input_tokens': input_tokens,
'output_tokens': expected_output_tokens,
'input_cost': input_cost,
'output_cost': output_cost,
'total_cost': total_cost,
'batch_savings': total_cost if use_batch else 0
}
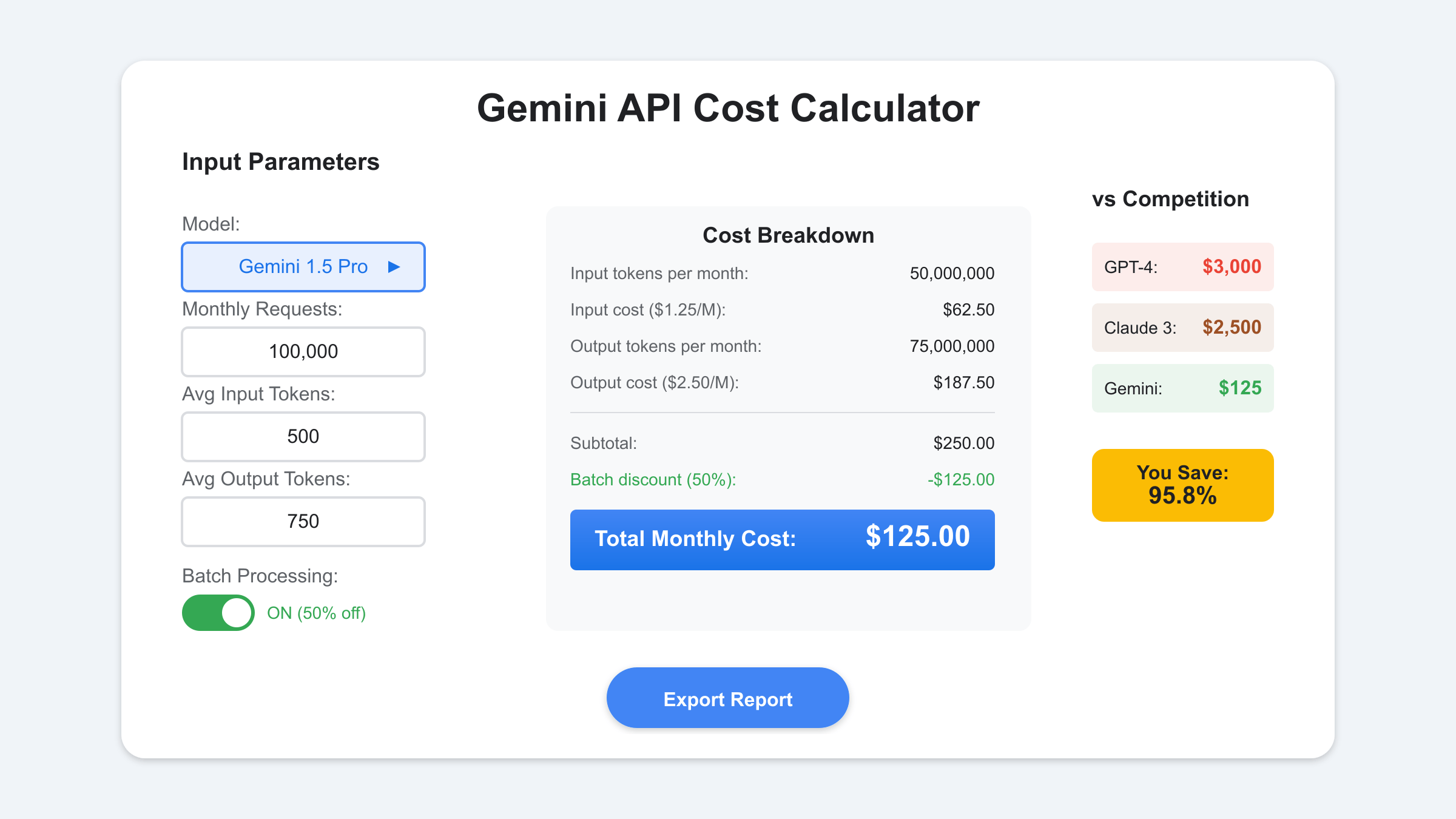
Real-world applications require monthly cost projections based on expected usage patterns. For a typical chatbot handling 10,000 daily conversations with average input of 200 tokens and output of 300 tokens, the monthly costs vary dramatically by model choice. Using Gemini 1.5 Pro, this translates to 60 million input tokens and 90 million output tokens monthly, resulting in $75 for input and $450 for output—a total of $525. The same workload on Flash costs just $55 monthly, while GPT-4 would cost $4,500.
Advanced cost optimization involves dynamic model routing based on query complexity. Simple queries route to Flash for cost efficiency, while complex reasoning tasks utilize Pro for accuracy. Implementing intelligent routing can reduce costs by 60-80% while maintaining output quality. The key lies in developing reliable complexity detection that considers factors like query length, technical terminology, required reasoning depth, and expected output format.
Gemini API Price vs ChatGPT: Detailed Comparison
The pricing battle between Gemini and ChatGPT represents a fundamental shift in the AI API marketplace. While OpenAI pioneered commercial large language model APIs, Google’s aggressive pricing strategy with Gemini has redefined cost expectations for AI integration.
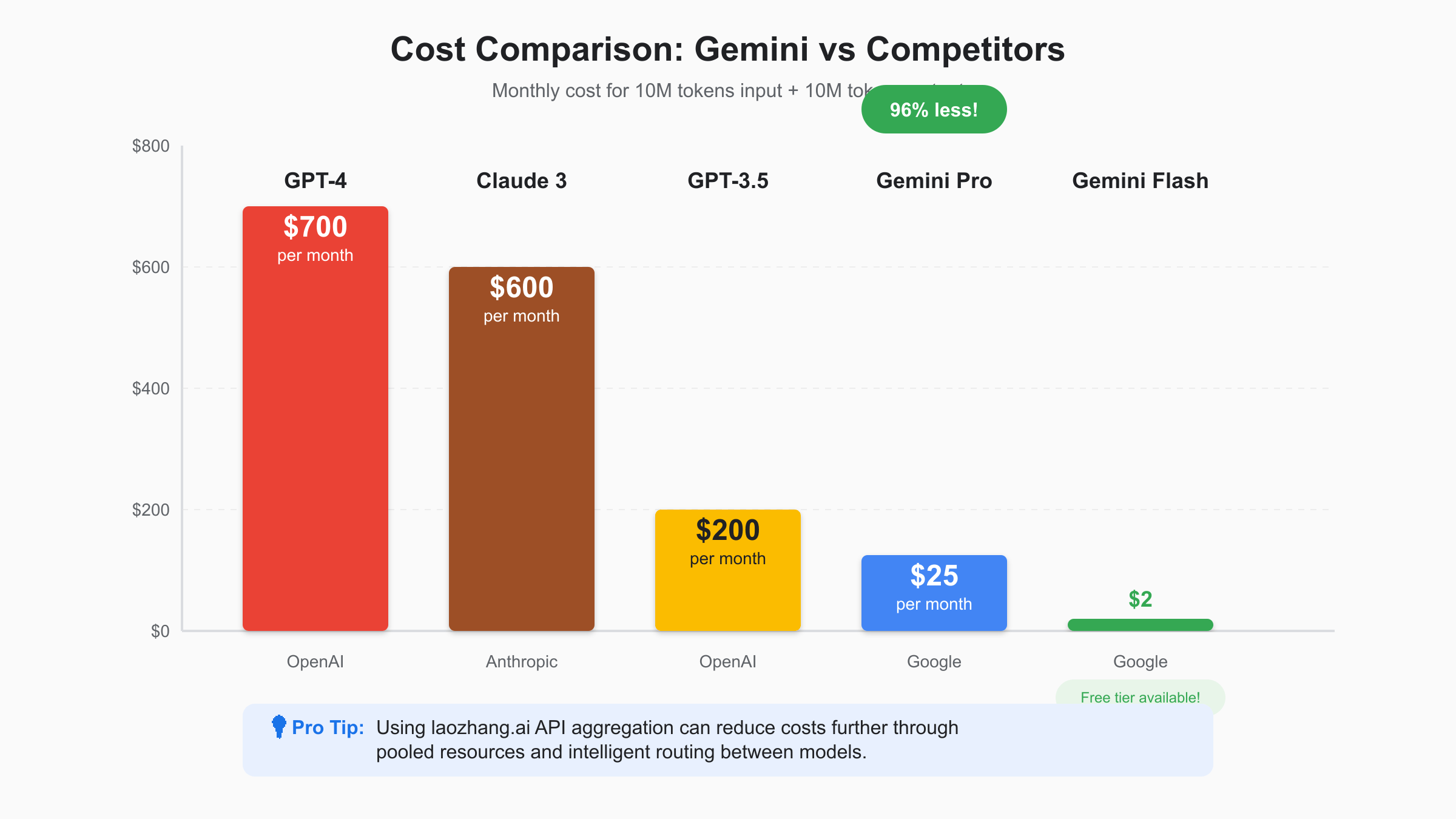
ChatGPT’s pricing structure reflects its market position and computational requirements. GPT-4, OpenAI’s flagship model, charges $30 per million input tokens and $60 per million output tokens—24 times more expensive than Gemini 1.5 Pro. Even GPT-3.5 Turbo, positioned as the budget option, costs $0.50 per million input tokens and $1.50 per million output tokens, making it 3.3x more expensive than Gemini Flash for comparable tasks. For the latest OpenAI pricing details, check our GPT-4o API pricing guide.
Feature availability creates additional differentiation beyond raw pricing. Gemini offers a 1 million token context window even in the free tier, compared to ChatGPT’s 128K limit for GPT-4. This massive context capacity enables processing entire books, extensive codebases, or lengthy conversation histories without truncation. For applications requiring extensive context, Gemini’s advantage becomes even more pronounced when considering ChatGPT’s lack of a true free tier for API access.
Performance per dollar analysis reveals nuanced trade-offs between platforms. Independent benchmarks show Gemini 1.5 Pro achieving 92% of GPT-4’s performance on complex reasoning tasks while costing 96% less. For creative writing and code generation, the performance gap narrows to just 5-8%, making Gemini’s cost advantage overwhelming for most commercial applications. However, GPT-4 maintains advantages in specific domains like medical diagnosis and legal analysis where maximum accuracy justifies premium pricing.
Migration economics strongly favor switching from ChatGPT to Gemini for most use cases. A typical SaaS application processing 100 million tokens monthly would save $2,850 per month migrating from GPT-4 to Gemini Pro, or $34,200 annually. Even accounting for migration costs including code changes, testing, and potential performance tuning, most applications achieve positive ROI within 2-3 months. The savings become even more dramatic when leveraging Gemini’s batch processing and free tier capabilities.
Hidden Costs in Gemini API Pricing
While Gemini’s headline pricing appears straightforward, several hidden costs can significantly impact total expenses for unprepared developers. Understanding these additional charges helps create accurate budgets and avoid surprise bills that can derail project economics.
The Grounding feature represents the most substantial hidden cost for applications requiring real-time information. At $5 per 1,000 grounding queries, costs accumulate quickly for news aggregators, fact-checking systems, or research assistants. A customer service bot checking product availability 100,000 times daily would incur $500 per day in grounding fees alone—potentially exceeding base model costs. Developers must carefully evaluate whether grounding adds sufficient value to justify the 10-20x cost multiplier compared to standard generation.
Long context pricing catches many developers off guard when scaling applications. Requests exceeding 200,000 tokens incur 2x standard pricing, effectively doubling costs for document analysis, code review, or extensive conversation processing. This pricing structure creates a cliff effect where a 201,000 token request costs twice as much as a 199,000 token request. Smart applications implement context windowing or summarization to stay below the threshold, potentially saving thousands monthly.
Regional variations add complexity to international deployments. While Google maintains USD pricing globally, additional costs emerge from currency conversion fees (typically 2-3%), regional taxes (VAT/GST ranging from 5-27%), and payment method restrictions. European customers face 19-27% higher effective costs due to VAT, while some Asian markets require expensive wire transfers for payment. These factors can increase total costs by 30% or more compared to US-based deployments.
Failed request policies provide some relief but require careful implementation. Google only charges for successful responses (HTTP 200 status codes), meaning network errors, rate limit violations, and malformed requests don’t incur costs. However, this policy creates interesting optimization challenges—aggressive retry strategies might reduce apparent costs while increasing infrastructure load. Applications must balance reliability requirements against the temptation to exploit free retries.
How to Optimize Gemini API Costs: Proven Strategies
Cost optimization for Gemini API usage extends beyond choosing the right model—it requires systematic implementation of proven strategies that can reduce expenses by 50-80% while maintaining or improving application performance.
Batch processing stands as the single most impactful optimization technique, offering a flat 50% discount for non-real-time workloads. Implementing effective batching requires rethinking application architecture to accumulate requests and process them asynchronously. The following pattern demonstrates production-ready batch implementation:
from datetime import datetime, timedelta
import asyncio
from typing import List, Dict
class BatchProcessor:
def __init__(self, batch_size: int = 100, max_wait_time: int = 300):
self.batch_size = batch_size
self.max_wait_time = max_wait_time # seconds
self.pending_requests = []
self.batch_start_time = datetime.now()
async def add_request(self, request_id: str, prompt: str, callback):
"""Add request to batch queue"""
self.pending_requests.append({
'id': request_id,
'prompt': prompt,
'callback': callback,
'timestamp': datetime.now()
})
# Process batch if size or time threshold reached
if len(self.pending_requests) >= self.batch_size or \
(datetime.now() - self.batch_start_time).seconds > self.max_wait_time:
await self.process_batch()
async def process_batch(self):
"""Process accumulated requests as batch"""
if not self.pending_requests:
return
batch_prompts = [req['prompt'] for req in self.pending_requests]
# Combine prompts with clear delimiters
combined_prompt = "\n[BATCH_DELIMITER]\n".join(batch_prompts)
# Single API call with batch flag
response = await gemini_batch_api_call(combined_prompt)
# Parse responses and execute callbacks
individual_responses = response.split("[BATCH_DELIMITER]")
for i, req in enumerate(self.pending_requests):
if i < len(individual_responses):
req['callback'](individual_responses[i])
# Reset for next batch
self.pending_requests = []
self.batch_start_time = datetime.now()
Model routing based on query complexity provides another powerful optimization lever. By analyzing query characteristics and routing simple requests to Flash while reserving Pro for complex tasks, applications can reduce costs by 60-80% without sacrificing quality. Effective routing considers multiple factors including query length, presence of technical terms, requirement for reasoning, and output format expectations. Machine learning classifiers trained on historical data can achieve 95%+ accuracy in model selection.
Context window optimization prevents costly overages from long context pricing. Since requests exceeding 200,000 tokens cost double, implementing intelligent context management becomes crucial. Strategies include sliding window approaches that maintain only recent relevant context, semantic chunking that preserves topical coherence, and dynamic summarization that condenses historical information. These techniques can reduce context size by 70-90% while maintaining conversation quality.
Caching frequently requested information dramatically reduces API calls and costs. Implementing semantic caching that recognizes similar queries even with different phrasing can achieve 30-50% cache hit rates in production. The key lies in balancing cache freshness with cost savings—cached responses for factual information might remain valid for days, while personalized content requires more frequent updates.
Gemini API Free Tier: Maximizing Value
The Gemini API free tier represents one of the most generous offerings in the AI API landscape, providing substantial daily quotas that support development, testing, and even small-scale production deployments. Understanding how to maximize this free allocation can save thousands of dollars while validating application concepts.
Daily quota management requires strategic thinking about request distribution. With 1,500 requests per day for Gemini 1.5 Flash, applications must implement intelligent queuing and prioritization. The quota resets at midnight Pacific Time, creating opportunities for global applications to leverage time zone differences. Asian businesses can schedule batch processing during their morning hours when fresh quotas become available, effectively doubling their free tier capacity.
Rate limit optimization within the free tier demands careful request pacing. The 15 RPM limit for Flash means applications can make one request every 4 seconds. Implementing a token bucket algorithm ensures smooth request distribution without hitting rate limits:
import time
from collections import deque
class FreeQuotaOptimizer:
def __init__(self, daily_limit=1500, rpm_limit=15):
self.daily_limit = daily_limit
self.rpm_limit = rpm_limit
self.daily_used = 0
self.minute_requests = deque()
self.last_reset = time.time()
def can_make_request(self) -> bool:
"""Check if request can be made within free tier limits"""
current_time = time.time()
# Reset daily counter at midnight PT
if self._is_new_day():
self.daily_used = 0
# Clean old requests from minute window
minute_ago = current_time - 60
while self.minute_requests and self.minute_requests[0] < minute_ago:
self.minute_requests.popleft()
# Check both limits
if self.daily_used >= self.daily_limit:
return False
if len(self.minute_requests) >= self.rpm_limit:
return False
return True
def record_request(self):
"""Record a successful request"""
self.daily_used += 1
self.minute_requests.append(time.time())
Use case recommendations for the free tier focus on applications with predictable, moderate usage. Development and testing environments benefit most obviously, but several production scenarios work well within free tier limits. Personal assistants serving individual users, prototype demonstrations, educational applications with controlled access, and backup systems for primary APIs all operate successfully within the 1,500 daily request boundary.
Upgrade timing strategies prevent service disruption while maximizing free tier value. Monitor usage patterns for two weeks to establish baselines, identifying peak hours and average daily consumption. When daily usage consistently exceeds 1,200 requests (80% of limit), initiate the upgrade process. The seamless transition from free to paid tiers ensures no service interruption, with billing beginning only after exceeding free quotas.
Enterprise Gemini API Pricing and Negotiations
Enterprise pricing for Gemini API transforms the standard rate card into a starting point for negotiations. Organizations with substantial API spending gain access to volume discounts, custom terms, and dedicated support that can reduce total costs by 40% or more compared to published pricing.
Volume discount tiers typically begin at $10,000 monthly spend, though unofficial reports suggest meaningful negotiations start around $25,000. The discount structure follows predictable patterns based on committed monthly spending. Organizations committing to $25,000-$50,000 monthly often receive 15-20% discounts, while those exceeding $100,000 can negotiate 30-40% reductions. The largest customers, spending millions annually, achieve even deeper discounts approaching 50-60% off list prices.
Committed use discounts (CUDs) provide another avenue for cost reduction. Similar to Google Cloud's infrastructure pricing, committing to specific usage levels for 1-3 years unlocks automatic discounts. One-year commitments typically yield 25-37% savings, while three-year agreements can reach 45-55% discounts. These commitments require careful capacity planning but offer predictable costs for finance teams.
SLA considerations become paramount for enterprise deployments. Standard Gemini API terms include 99.9% uptime guarantees, but enterprise agreements can negotiate 99.95% or even 99.99% availability. Each additional "nine" of reliability typically costs 10-15% in pricing premiums but includes proportional service credits for downtime. Enterprise SLAs also cover response time guarantees, support escalation procedures, and dedicated technical account management.
Contract negotiation strategies for maximum value require preparation and leverage. Document current usage patterns, growth projections, and competitive alternatives before entering negotiations. Highlight multicloud deployments and willingness to consolidate workloads as bargaining chips. Request custom rate limits, dedicated endpoint URLs, and priority queuing alongside pricing discounts. Most importantly, negotiate caps on annual price increases—typically 5-10%—to protect against future rate changes.
Real-World Gemini API Cost Scenarios
Understanding Gemini API costs through real-world scenarios provides practical insights that abstract pricing tables cannot convey. These detailed examples demonstrate how different application types and usage patterns translate into monthly expenses.
Customer service chatbots represent one of the most common Gemini API applications. Consider a mid-sized e-commerce company handling 15,000 customer inquiries daily. Each conversation averages 3 exchanges, with 150 input tokens and 250 output tokens per exchange. Using Gemini 1.5 Pro for quality responses, monthly costs calculate as follows: 15,000 conversations × 3 exchanges × 30 days = 1,350,000 total exchanges. Input tokens total 202.5 million (1,350,000 × 150), costing $253. Output tokens reach 337.5 million, costing $1,687. The total monthly cost of $1,940 compares favorably to hiring additional customer service staff or using competitive APIs costing $15,000+ for similar volume.
Content generation platforms showcase batch processing benefits. A marketing automation platform generating 5,000 blog posts monthly, each requiring 1,000 token prompts and producing 3,000 token articles, would normally cost $15,625 using Gemini 1.5 Pro. However, since content generation rarely requires real-time processing, utilizing batch mode reduces costs by 50% to $7,812. Further optimization through model routing—using Flash for simple posts and Pro only for complex topics—can reduce costs to approximately $3,000 monthly while maintaining quality.
Code analysis systems demonstrate the importance of context window management. A development tool analyzing pull requests might process 1,000 PRs daily, each containing 10,000 tokens of code context. Without optimization, this 300 million tokens monthly would cost $375 on Gemini 1.5 Pro. However, implementing semantic chunking to extract only relevant code sections reduces average context to 3,000 tokens, cutting costs to $112 monthly. Adding caching for common code patterns further reduces costs to under $75.
Research assistants highlight grounding cost implications. An AI research tool making 50,000 queries daily, with 30% requiring grounding for current information, faces significant additional costs. Base generation might cost $500 monthly, but grounding fees add 50,000 × 0.30 × 30 / 1,000 × $5 = $2,250 monthly. This 4.5x cost multiplier forces careful evaluation of when grounding adds sufficient value. Implementing a hybrid approach using cached knowledge for historical queries and grounding only for time-sensitive information can reduce grounding costs by 70%.
Gemini API Billing and Payment Guide
Navigating Google Cloud's billing system for Gemini API requires understanding both the technical setup process and ongoing management best practices. Proper configuration prevents billing surprises and enables sophisticated cost tracking across projects and teams.
Google Cloud billing setup begins with creating a billing account linked to your payment method. Unlike some services requiring prepayment, Google Cloud operates on a post-paid model with monthly invoicing. The setup process involves creating a Google Cloud project, enabling the Generative AI API, linking a billing account, and configuring API credentials. New accounts receive $300 in credits valid for 90 days, applicable to Gemini API usage. Detailed billing setup instructions are available in the Google Cloud billing documentation.
Payment methods vary by region and spending level. Most countries support credit cards for monthly charges under $10,000. Higher spending levels may require ACH transfers or wire payments, particularly for enterprise accounts. Google Cloud accepts major credit cards, debit cards with sufficient limits, bank account direct debit (selected countries), and wire transfers for enterprise agreements. Payment processing occurs monthly, typically between the 1st and 5th of each month for the previous month's usage.
Invoice management becomes crucial for accounting and budget tracking. Google Cloud provides detailed invoices breaking down usage by project, API, and time period. Configure invoice delivery to multiple email addresses, ensuring both technical and finance teams receive copies. The invoice includes line items for each API call type, token usage summaries, any applicable discounts, taxes based on your location, and payment terms. Export invoice data to CSV or BigQuery for advanced analysis and chargeback calculations.
Usage monitoring tools within Google Cloud Console provide real-time visibility into API consumption and costs. Set up custom dashboards displaying current month spending, daily usage trends, cost per project breakdown, and model-specific consumption patterns. Implement Cloud Monitoring alerts for unusual usage spikes that might indicate bugs or abuse. The Gemini-specific metrics include tokens consumed per model, request counts by status code, average latency by operation, and grounding query volumes.
Budget alerts configuration prevents unexpected charges from development errors or usage spikes. Create budgets at multiple levels—organization, project, and API-specific. Configure alerts at 50%, 80%, 90%, and 100% of budget thresholds. Advanced configurations can automatically disable APIs when budgets are exceeded, though this requires careful implementation to avoid service disruptions. Email alerts should route to both development teams and management for rapid response to anomalies.
Migrating to Gemini API: Cost Analysis Tools
Migration from competing AI APIs to Gemini requires comprehensive cost analysis encompassing not just API pricing differences but total migration expenses including development effort, testing requirements, and operational changes. Building accurate migration calculators helps organizations make data-driven decisions.
The migration calculator must account for multiple cost dimensions beyond simple API pricing. Development costs include code modifications to accommodate API differences, testing and quality assurance efforts, documentation updates, and team training on new capabilities. Operational costs cover dual-running periods during migration, monitoring and debugging tools updates, and potential performance optimization needs. Opportunity costs factor in delayed feature development and temporary productivity reductions.
class ComprehensiveMigrationCalculator:
def __init__(self):
self.api_costs = {
'current': {'gpt-4': 30, 'claude-3': 15}, # per million input tokens
'target': {'gemini-pro': 1.25, 'gemini-flash': 0.15}
}
self.migration_factors = {
'development_hours': 160, # estimated hours
'hourly_rate': 150, # developer cost
'testing_multiplier': 1.5, # testing effort vs development
'dual_run_months': 2 # parallel operation period
}
def calculate_total_migration_cost(self, current_api: str,
monthly_tokens: int,
migration_months: int = 6) -> dict:
"""Calculate comprehensive migration costs and ROI"""
# Current monthly API cost
current_monthly = (monthly_tokens / 1_000_000) * self.api_costs['current'][current_api]
# Target Gemini cost (using Pro as baseline)
gemini_monthly = (monthly_tokens / 1_000_000) * self.api_costs['target']['gemini-pro']
# One-time migration costs
dev_cost = self.migration_factors['development_hours'] * self.migration_factors['hourly_rate']
testing_cost = dev_cost * self.migration_factors['testing_multiplier']
# Dual running costs
dual_run_cost = (current_monthly + gemini_monthly) * self.migration_factors['dual_run_months']
# Total migration investment
total_migration_cost = dev_cost + testing_cost + dual_run_cost
# Monthly savings after migration
monthly_savings = current_monthly - gemini_monthly
# ROI calculations
payback_months = total_migration_cost / monthly_savings if monthly_savings > 0 else float('inf')
roi_first_year = (monthly_savings * 12 - total_migration_cost) / total_migration_cost * 100
# 3-year total savings
three_year_savings = monthly_savings * 36 - total_migration_cost
return {
'current_monthly_cost': current_monthly,
'gemini_monthly_cost': gemini_monthly,
'monthly_savings': monthly_savings,
'migration_investment': total_migration_cost,
'payback_months': payback_months,
'first_year_roi': roi_first_year,
'three_year_savings': three_year_savings,
'break_even_date': f"{int(payback_months)} months"
}
Total cost of ownership analysis extends beyond API pricing to include infrastructure, support, and operational considerations. Gemini's integration with Google Cloud services reduces infrastructure complexity compared to standalone API providers. Native integration with Cloud Logging, Monitoring, and IAM eliminates the need for third-party tools costing $500-2,000 monthly. Google's global infrastructure provides better latency for international applications, potentially improving user experience and reducing timeout-related costs.
Implementation cost factors vary significantly based on architecture complexity and team expertise. Simple chatbot migrations might complete in 2-3 weeks with minimal code changes, while complex systems requiring prompt optimization and response parsing updates could take 2-3 months. Teams familiar with Google Cloud services typically complete migrations 40% faster due to familiarity with authentication, project structure, and deployment patterns.
The role of API aggregation services like laozhang.ai in reducing migration complexity deserves special consideration. By providing a unified interface across multiple AI providers, laozhang.ai enables gradual migration without code changes. Applications can route traffic percentages between providers, test performance differences in production, and rollback instantly if issues arise. The service's automatic failover between providers ensures reliability during transition periods. Most importantly, laozhang.ai's aggregated volume pricing often provides 20-30% additional savings compared to direct API access, accelerating ROI timelines.
Future of Gemini API Pricing: 2025 Predictions
The trajectory of Gemini API pricing through 2025 reflects broader trends in AI commoditization, infrastructure improvements, and competitive dynamics. Understanding likely pricing evolution helps organizations make strategic decisions about AI platform investments and architecture choices.
Expected price reductions follow historical patterns in cloud services where increased scale and competition drive costs down 20-30% annually. Industry analysts predict Gemini Pro pricing will decrease to $0.80-1.00 per million input tokens by late 2025, with Flash potentially reaching $0.10 per million tokens. These reductions reflect Google's massive infrastructure investments, improved model efficiency, and competitive pressure from OpenAI, Anthropic, and emerging players.
New model releases will introduce pricing tiers for specialized capabilities. Gemini 3.0, expected in Q4 2025, will likely launch with premium pricing 2-3x current Pro rates before gradually decreasing. Specialized models for domains like healthcare, legal, and finance may command 50-100% premiums due to additional training and compliance requirements. Multimodal models processing images, video, and audio alongside text will introduce new pricing dimensions based on media type and processing complexity.
Regional pricing variations will expand as Google builds local infrastructure to meet data residency requirements. European deployments may see 10-15% price premiums to cover GDPR compliance costs. Asian markets could receive 5-10% discounts to compete with local providers. These regional differences create arbitrage opportunities for globally distributed applications willing to route traffic based on cost optimization.
The competitive landscape will intensify with new entrants and evolving strategies from existing players. OpenAI's focus on premium capabilities, Anthropic's emphasis on safety and reliability, and Meta's potential open-source disruption all influence Gemini API pricing strategies. Chinese providers like Baidu and Alibaba may offer aggressive pricing for international expansion. This competition benefits developers through lower prices, better features, and improved service quality. For comparison with newer models, see our analysis of Claude 3.7 Sonnet pricing and emerging alternatives.
Investment recommendations for organizations center on architectural flexibility and cost optimization capabilities. Build applications with provider-agnostic designs enabling easy switching between AI services. Implement sophisticated cost tracking and optimization from day one rather than retrofitting later. Consider API aggregation services that provide pricing arbitrage and simplified multi-provider management. Most importantly, negotiate enterprise agreements before usage scales, as retroactive discounts rarely match forward-looking commitments. The organizations best positioned for 2025's AI landscape will combine technical excellence with commercial sophistication in managing AI service costs.