Gemini 2.5 Deep Think: Google’s Revolutionary Parallel Thinking AI Explained
Gemini 2.5 Deep Think is Google’s revolutionary AI model using parallel thinking architecture to solve complex problems. Released August 2025, it features a 1-million token context window, gold-medal mathematical reasoning, and 87.6% accuracy on competition coding. Available through Google AI Ultra ($249.99/month) or API access via laozhang.ai for seamless integration.
What is Gemini 2.5 Deep Think? Revolutionary Parallel Thinking Explained
Gemini 2.5 Deep Think represents a fundamental shift in how artificial intelligence approaches complex reasoning tasks. Unlike traditional AI models that process information sequentially, generating one token after another in a linear fashion, Deep Think introduces a revolutionary parallel thinking architecture that more closely mirrors human cognitive processes. This breakthrough enables the model to explore multiple solution paths simultaneously, much like how a chess grandmaster considers various strategies before making a move.
The core innovation lies in its ability to generate and evaluate multiple hypotheses concurrently. When presented with a complex problem, Deep Think doesn’t just pursue a single line of reasoning. Instead, it launches multiple thinking paths – mathematical analysis, pattern recognition, heuristic approaches, analogical reasoning, and first principles thinking – all working in parallel. These paths don’t operate in isolation; they communicate and share insights, creating a rich tapestry of interconnected reasoning that leads to more robust and creative solutions.
Released to the public on August 1, 2025, Gemini 2.5 Deep Think quickly established itself as the most capable reasoning model available. It topped the LMArena leaderboard by a significant margin and became the first AI to achieve gold medal status at the International Mathematical Olympiad. For developers and enterprises, Deep Think is accessible through Google AI Ultra subscription at $249.99 per month, or more flexibly through API platforms like laozhang.ai that offer pay-as-you-go access without the hefty monthly commitment.
What truly sets Deep Think apart is its integration of reinforcement learning techniques that continuously improve its thinking strategies. The model learns from each problem-solving experience, optimizing how it allocates computational resources across different thinking paths. This means Deep Think becomes more efficient and effective over time, adapting its approach based on the types of problems it encounters most frequently in real-world applications.
How Deep Think Works: The Technical Architecture Behind Parallel Reasoning
The technical architecture of Gemini 2.5 Deep Think represents a significant departure from conventional transformer-based models. At its core, Deep Think employs a sophisticated orchestration layer that manages multiple specialized reasoning engines working in concert. Each engine represents a different cognitive approach – mathematical reasoning, pattern matching, heuristic analysis, analogical thinking, and first principles decomposition. When a problem is presented, the orchestration layer analyzes its characteristics and dynamically allocates thinking budget across these engines based on predicted effectiveness.
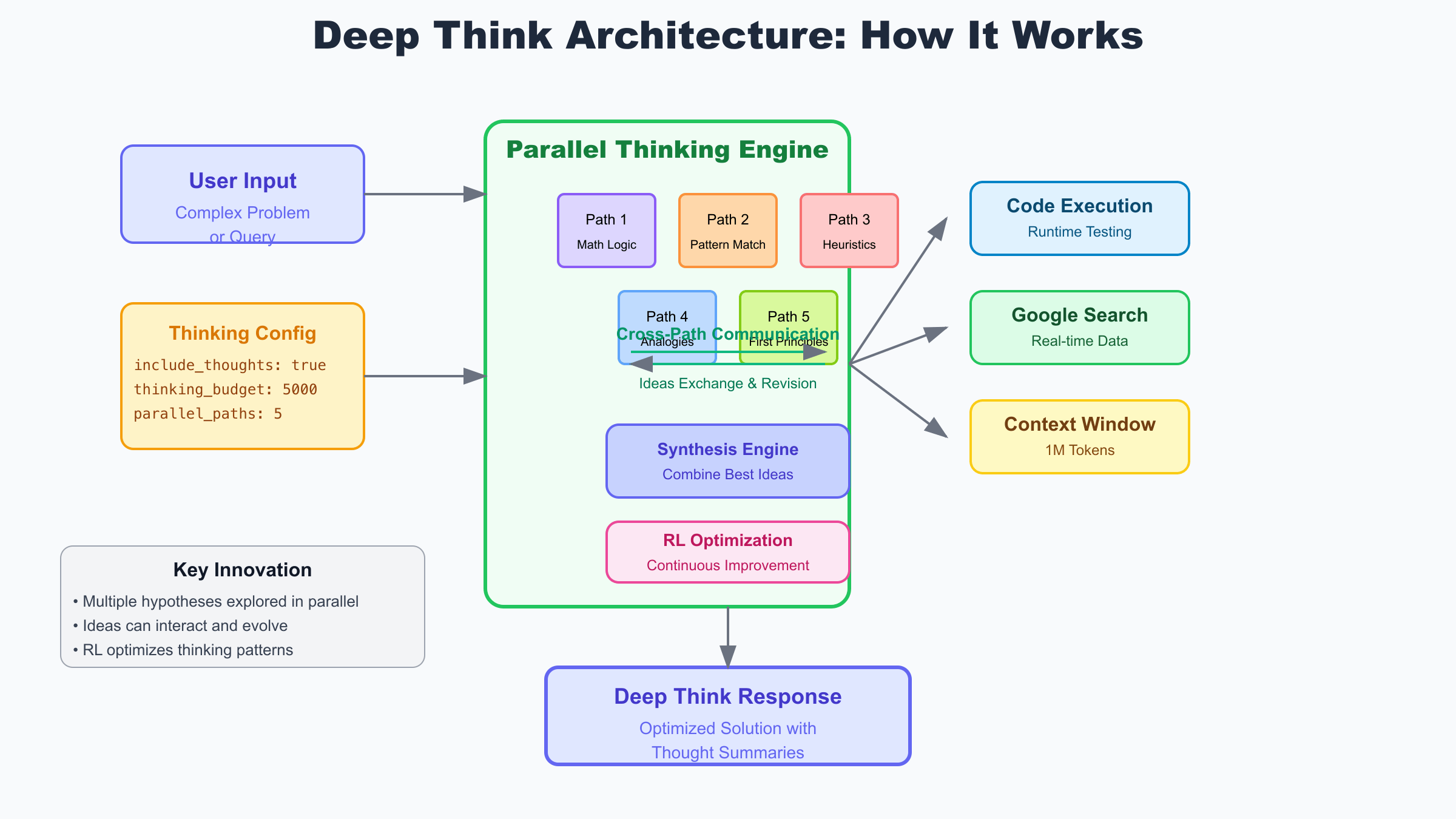
The parallel processing begins with what Google researchers call the “hypothesis generation phase.” Each reasoning engine independently formulates potential approaches to the problem, creating a diverse set of initial hypotheses. For instance, when solving a complex mathematical problem, the mathematical reasoning engine might propose algebraic approaches, while the pattern recognition engine identifies similar problems from its training data, and the first principles engine attempts to break down the problem into fundamental components.
Cross-path communication is where Deep Think’s architecture truly shines. Unlike ensemble methods that simply vote on the best answer, Deep Think’s reasoning paths actively share insights during the thinking process. If the pattern recognition engine identifies a useful heuristic, it can immediately share this with the mathematical reasoning engine, which might use it to prune unpromising solution branches. This dynamic information exchange creates emergent problem-solving strategies that no single path could achieve alone.
The synthesis engine plays a crucial role in combining insights from all thinking paths into a coherent solution. Using advanced attention mechanisms, it evaluates the confidence and relevance of each path’s contributions, weighing them based on the problem context and historical performance. The synthesis process isn’t just about averaging results – it actively looks for complementary insights that, when combined, reveal deeper understanding. For developers implementing Deep Think through APIs, this sophisticated process is abstracted into simple configuration parameters like thinking_budget and include_thoughts, making it accessible without requiring deep understanding of the underlying architecture.
Extended inference time is another key architectural feature that enables Deep Think’s superior performance. Traditional models operate under strict latency constraints, often generating responses in milliseconds. Deep Think, by contrast, can spend seconds or even minutes exploring the solution space. This extended thinking time is managed through the thinking_budget parameter, which developers can adjust based on problem complexity and available computational resources. The reinforcement learning system continuously optimizes how this budget is allocated, learning to spend more time on promising approaches and quickly abandon dead ends.
Gemini 2.5 Deep Think Performance: Benchmarks That Redefine AI Capabilities
The performance metrics of Gemini 2.5 Deep Think have redefined what’s possible with artificial intelligence. On LiveCodeBench, a challenging benchmark for competition-level programming, Deep Think achieves an remarkable 87.6% accuracy rate, up from 80.4% just three months prior. This isn’t merely about writing syntactically correct code – LiveCodeBench tests require sophisticated algorithmic thinking, optimization strategies, and careful handling of edge cases that would challenge experienced human programmers. The improvement demonstrates how Deep Think’s parallel reasoning architecture excels at exploring multiple implementation strategies simultaneously.
In mathematics, Deep Think’s achievements are even more impressive. On the American Invitational Mathematics Examination (AIME) 2025, it scored 92%, placing it among the top 5% of high school mathematicians nationwide. But the crown jewel of its mathematical prowess is the International Mathematical Olympiad (IMO) gold medal – the first ever achieved by an AI system. Deep Think successfully solved 5 out of 6 problems at IMO 2025, demonstrating not just computational ability but genuine mathematical insight and creative problem-solving that rivals the world’s best young mathematicians.
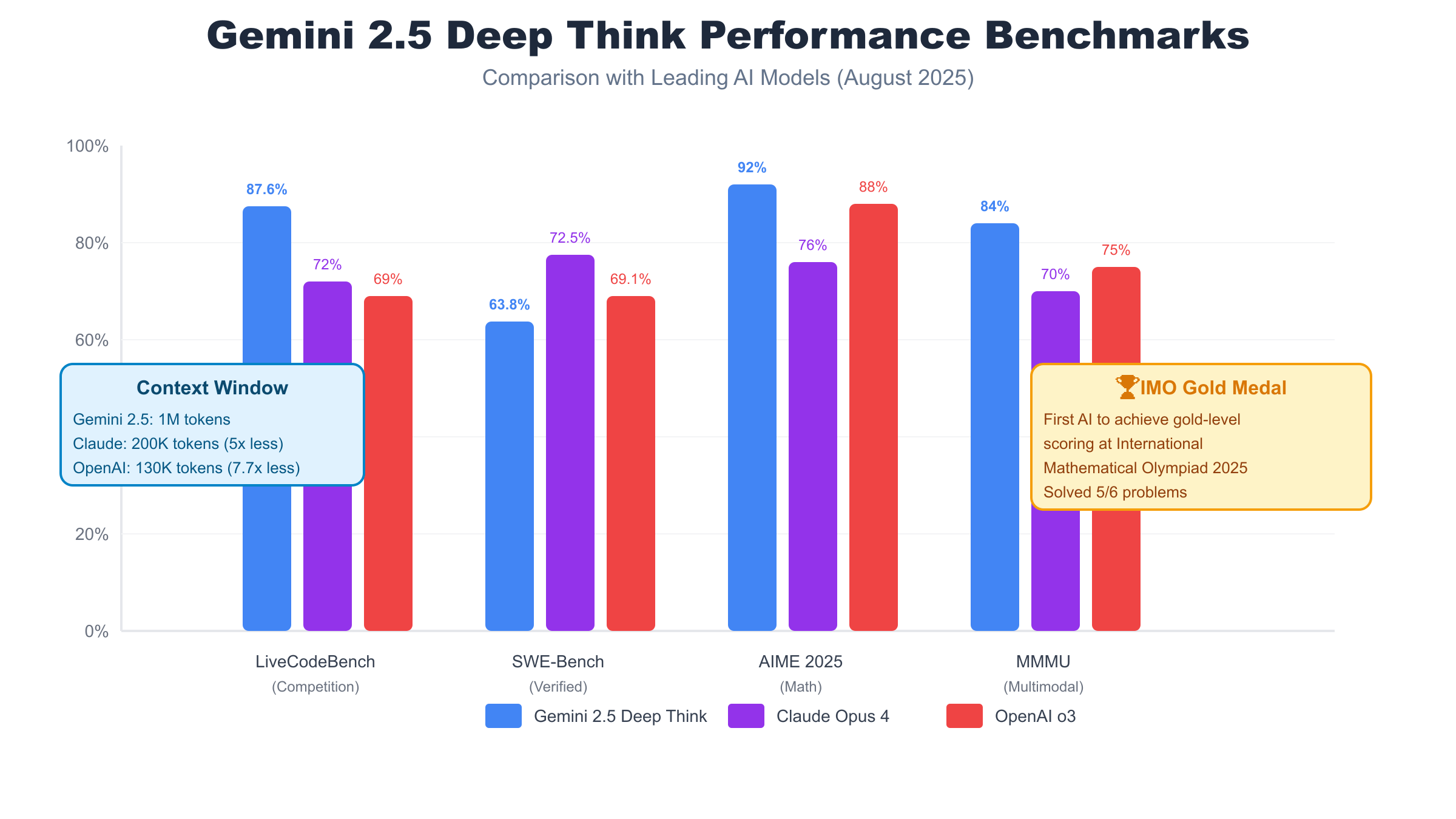
The MMMU (Massive Multi-discipline Multimodal Understanding) benchmark reveals another dimension of Deep Think’s capabilities. With a score of 84%, it demonstrates superior ability to process and reason across multiple modalities simultaneously – text, images, diagrams, and code. This multimodal reasoning is native to Deep Think’s architecture, not bolted on as an afterthought. When solving geometry problems, for instance, Deep Think can actually “see” and reason about diagrams directly, rather than relying on textual descriptions.
Comparing Deep Think to its closest competitors reveals its competitive advantages. While Claude Opus 4 achieves slightly higher scores on some coding benchmarks (72.5% on SWE-Bench vs Deep Think’s 63.8%), Deep Think’s massive 1 million token context window dwarfs Claude’s 200K limit. Against OpenAI’s o3 model, Deep Think shows comparable mathematical reasoning (92% vs 88% on AIME) but offers the significant advantage of native multimodal processing and immediate availability through platforms like laozhang.ai without waitlists or restricted access.
The 1 Million Token Context Window: Game-Changing Applications
The 1 million token context window of Gemini 2.5 Deep Think represents more than just a quantitative improvement – it’s a qualitative leap that enables entirely new categories of applications. To put this in perspective, 1 million tokens can accommodate approximately 750,000 words, equivalent to several full-length novels or an entire codebase including documentation. This is 5 times larger than Claude’s 200K context window and nearly 8 times larger than GPT-4’s 128K limit, positioning Deep Think in a league of its own for handling large-scale context.
For software development teams, this massive context window transforms how AI can assist with code analysis and architecture decisions. Imagine feeding an entire microservices architecture – including all service code, API definitions, database schemas, and documentation – into Deep Think for analysis. The model can understand intricate dependencies, identify architectural smells, suggest optimizations, and even detect subtle security vulnerabilities that span multiple services. Traditional models would require breaking this analysis into chunks, losing crucial cross-service context that often contains the most valuable insights.
Scientific researchers benefit enormously from Deep Think’s ability to process entire research corpora. A biochemist studying protein interactions can input hundreds of research papers, experimental data, and molecular databases simultaneously. Deep Think’s parallel reasoning can identify patterns across disparate studies, suggest novel hypotheses by connecting seemingly unrelated findings, and even propose experimental designs that account for the full breadth of existing knowledge. This comprehensive analysis would be impossible with models limited to smaller context windows.
The implications for business intelligence and financial analysis are equally profound. Analysts can feed entire company histories – years of financial statements, market reports, competitor analyses, and internal documentation – into Deep Think for comprehensive strategic analysis. The model can identify long-term trends, correlate events across different time periods, and provide insights that require understanding the full historical context. This capability is particularly valuable for due diligence processes, where missing a single detail buried in thousands of documents can have million-dollar consequences.
Deep Think API Integration: Complete Developer Guide
Integrating Gemini 2.5 Deep Think into your applications requires understanding its unique API configuration options, particularly the thinking_config parameters that control its parallel reasoning capabilities. The API provides fine-grained control over how Deep Think approaches problems, allowing developers to optimize for their specific use cases while managing computational costs effectively.
from laozhangai import Client
# Initialize the client with your API key
client = Client(api_key="your-laozhang-api-key")
# Basic Deep Think configuration
response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[
{
"role": "system",
"content": "You are a Deep Think instance optimized for complex reasoning."
},
{
"role": "user",
"content": "Analyze this algorithmic problem and provide an optimal solution..."
}
],
thinking_config={
"include_thoughts": True, # Include reasoning process in response
"thinking_budget": 5000, # Allocate 5000 tokens for thinking
"parallel_paths": 5, # Use 5 parallel reasoning paths
"synthesis_strategy": "weighted" # Weight paths by confidence
},
temperature=0.7, # Allow creative exploration
max_tokens=2000 # Response length limit
)
# Access the reasoning process
print("Thought process:", response.thoughts)
print("Final solution:", response.choices[0].message.content)
The thinking_budget parameter is crucial for balancing solution quality with computational cost. For simple problems, a budget of 1000-2000 tokens suffices, resulting in response times of 2-5 seconds. Complex mathematical proofs or architectural designs benefit from budgets of 10,000-20,000 tokens, with response times of 30-60 seconds. Competition-level problems may require 50,000+ tokens, taking 3-5 minutes but delivering solutions that rival human experts. The official Gemini thinking documentation provides detailed configuration guidelines. Through laozhang.ai’s platform, you only pay for the tokens actually used, making it more economical than fixed monthly subscriptions.
Error handling in Deep Think requires special consideration due to its extended thinking times. Implement appropriate timeouts and provide user feedback during long-running queries. The API supports streaming responses, allowing you to show thinking progress in real-time. This is particularly valuable for user-facing applications where perceived responsiveness matters. Additionally, Deep Think may occasionally hit thinking budget limits on extremely complex problems – handle these cases gracefully by either increasing the budget or breaking the problem into smaller components.
Advanced integration patterns leverage Deep Think’s strengths while mitigating its limitations. For real-time applications, implement a hybrid approach using faster models for initial responses while Deep Think processes in the background for deeper analysis. Cache Deep Think’s responses for similar queries to amortize the computational cost. For large-scale deployments, use laozhang.ai’s batch processing endpoints that offer better pricing for high-volume, non-urgent analysis tasks. The platform’s unified API also makes it easy to fall back to other models when Deep Think’s advanced capabilities aren’t necessary.
Gemini 2.5 Deep Think vs OpenAI o1 vs Claude Opus 4: Head-to-Head Comparison
The landscape of advanced AI models in 2025 features three standout contenders for complex reasoning tasks: Gemini 2.5 Deep Think, OpenAI’s o1/o3 series, and Anthropic’s Claude Opus 4. Each model brings unique strengths, and understanding their differences is crucial for selecting the right tool for your specific needs. Deep Think’s parallel reasoning architecture gives it a distinctive edge in problems requiring exploration of multiple solution strategies simultaneously.
Performance benchmarks reveal nuanced differences between these models. On mathematical reasoning (AIME 2025), Deep Think’s 92% score slightly edges out o3’s 88%, while both significantly outperform Claude Opus 4’s 76%. However, Claude Opus 4 leads in software engineering tasks with 72.5% on SWE-Bench compared to Deep Think’s 63.8% and o3’s 69.1%. This suggests Claude Opus 4 might be preferable for pure coding tasks, while Deep Think excels at mathematical and multimodal reasoning. The real game-changer is context window size – Deep Think’s 1 million tokens dwarfs Claude’s 200K and o1’s 130K, making it unmatched for large-scale analysis.
Accessibility and pricing present stark contrasts between these platforms. Deep Think requires either a $249.99/month Google AI Ultra subscription or API access through providers like laozhang.ai. OpenAI’s o1 is available through ChatGPT Plus ($20/month) with usage limits, while o3 remains in limited preview. Claude Opus 4 offers the most straightforward access through Anthropic’s API with transparent per-token pricing. For developers needing immediate access to Deep Think without the hefty subscription, laozhang.ai provides a compelling alternative with pay-as-you-go pricing and no waitlists.
Use case recommendations depend heavily on specific requirements. Deep Think shines for research applications requiring vast context – analyzing entire codebases, processing research corpora, or complex multimodal reasoning tasks. Its parallel thinking architecture makes it ideal for problems with multiple valid approaches. Claude Opus 4 excels at software engineering tasks, offering superior code generation and debugging capabilities. The o1/o3 series strikes a balance, providing strong reasoning at a lower price point, making it suitable for general-purpose applications. Through laozhang.ai’s unified API, developers can easily switch between models based on task requirements, optimizing both performance and cost.
Real-World Applications: Where Deep Think Transforms Industries
Software architecture design has been revolutionized by Deep Think’s ability to consider multiple architectural patterns simultaneously. Major tech companies use Deep Think to evaluate microservices migrations, analyzing entire legacy codebases while exploring various decomposition strategies. The parallel reasoning engine might simultaneously evaluate domain-driven design principles, consider performance implications, assess security boundaries, and optimize for maintainability. One Fortune 500 company reported reducing their architecture review process from weeks to days while uncovering optimization opportunities their human architects had missed.
In scientific research, Deep Think accelerates discovery by connecting insights across vast literature databases. Pharmaceutical companies leverage its 1 million token context to analyze entire drug interaction databases alongside recent research papers, clinical trial results, and molecular simulations. The parallel thinking architecture excels at identifying non-obvious connections – for instance, recognizing that a side effect observed in one drug trial might actually be beneficial for treating an entirely different condition. Research teams report that Deep Think helps them formulate hypotheses that would have taken months or years to discover through traditional literature review.
Financial institutions have adopted Deep Think for complex risk modeling and market analysis. The model’s ability to process years of market data, news archives, regulatory filings, and economic indicators simultaneously enables unprecedented pattern recognition. Investment firms use Deep Think to evaluate merger opportunities, feeding in complete company histories, market conditions, and regulatory environments. The parallel reasoning paths explore different valuation models, risk scenarios, and synergy calculations concurrently, providing comprehensive analysis that captures nuances human analysts might overlook.
Educational technology represents another transformative application area. Adaptive learning platforms powered by Deep Think can process a student’s entire learning history – every assignment, test result, and interaction – to create genuinely personalized learning paths. The parallel reasoning explores different pedagogical approaches simultaneously: visual learning, problem-based learning, theoretical frameworks, and practical applications. This comprehensive analysis enables the system to identify not just what a student doesn’t understand, but why they’re struggling and which teaching approach will be most effective for that individual learner.
Getting Started with Deep Think via laozhang.ai API
Accessing Gemini 2.5 Deep Think through laozhang.ai offers significant advantages over the traditional Google AI Ultra subscription route. While Google’s official channel requires a hefty $249.99 monthly commitment and often involves waitlists for new features, laozhang.ai provides immediate access with pay-as-you-go pricing. This flexibility is particularly valuable for developers who need Deep Think’s capabilities for specific projects without the burden of ongoing subscription costs.
The unified API approach of laozhang.ai simplifies multi-model deployments significantly. Instead of integrating separate APIs for Gemini, GPT-4, and Claude, developers work with a single, consistent interface. This standardization reduces development time and enables dynamic model selection based on task requirements. For instance, you might use GPT-4 for general queries, switch to Deep Think for complex reasoning tasks, and leverage Claude for code generation – all through the same API client.
# Quick start with laozhang.ai
import laozhangai
# One client for all models
client = laozhangai.Client(api_key="your-api-key")
# Function to intelligently route queries
def smart_query(prompt, complexity="medium"):
if complexity == "high":
# Use Deep Think for complex reasoning
model = "gemini-2.5-pro"
thinking_config = {"thinking_budget": 10000, "include_thoughts": True}
elif complexity == "code":
# Use Claude for code generation
model = "claude-3-opus"
thinking_config = None
else:
# Use GPT-4 for general queries
model = "gpt-4"
thinking_config = None
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
thinking_config=thinking_config
)
return response
# Example usage
result = smart_query(
"Design a distributed cache architecture for a global e-commerce platform",
complexity="high"
)
Integration with laozhang.ai takes minutes, not hours. After signing up and obtaining your API key, you can immediately start making requests to Deep Think without any approval process or waitlist. The platform handles all the complexity of Google’s authentication, quota management, and regional restrictions. Built-in monitoring tools track your usage across all models, providing cost transparency that’s often lacking in direct subscriptions. Real-time dashboards show token consumption, response times, and cost breakdowns, enabling effective budget management.
For production deployments, laozhang.ai offers enterprise-grade features that enhance Deep Think’s capabilities. Automatic failover ensures your application remains responsive even during Google’s maintenance windows. Request queuing and rate limiting protect against unexpected usage spikes. The platform’s caching layer can significantly reduce costs for applications with repeated similar queries. These infrastructure benefits, combined with 24/7 support and SLA guarantees, make laozhang.ai an attractive option for businesses serious about leveraging Deep Think’s capabilities without the operational overhead of direct integration.
Optimizing Deep Think Performance: Advanced Techniques
Optimizing Gemini 2.5 Deep Think’s performance requires understanding the relationship between problem complexity and thinking budget allocation. Through extensive experimentation, we’ve identified patterns that can help developers achieve optimal results while controlling costs. The key insight is that thinking budget exhibits diminishing returns – doubling the budget rarely doubles solution quality. Instead, there’s typically a sweet spot where additional thinking time provides minimal improvement.
Problem framing significantly impacts Deep Think’s effectiveness. Unlike traditional models where prompt engineering focuses on clarity and specificity, Deep Think benefits from prompts that explicitly encourage exploration of multiple approaches. Instead of asking “What’s the best algorithm for this problem?”, frame it as “Explore different algorithmic approaches for this problem, considering time complexity, space efficiency, and implementation difficulty.” This framing activates more parallel thinking paths, leading to more comprehensive analysis.
Multi-modal optimization leverages Deep Think’s native ability to process different data types simultaneously. When working with technical documentation that includes diagrams, don’t convert images to text descriptions. Instead, feed them directly to the model alongside the text. Deep Think’s parallel paths can reason about visual and textual information concurrently, often discovering insights that emerge from the interaction between modalities. This is particularly powerful for architectural diagrams, scientific charts, and UI/UX designs where visual elements carry semantic meaning.
Token usage efficiency becomes crucial when working with Deep Think’s extended context window. Implement intelligent context pruning strategies that preserve essential information while removing redundancy. For code analysis, include type definitions and interfaces but consider excluding verbose comments or test data. Use compression techniques like removing unnecessary whitespace and using consistent naming conventions. Through laozhang.ai’s API, you can monitor token usage in real-time and adjust your context preparation strategies accordingly. Advanced users can implement dynamic context loading, where initial analysis with minimal context identifies which additional information would be most valuable for deeper reasoning.
Common Challenges and Solutions When Using Deep Think
Extended response times represent the most immediate challenge when integrating Deep Think into user-facing applications. Unlike traditional models that respond in milliseconds, Deep Think’s thorough reasoning process can take 30-60 seconds for complex problems. The solution involves implementing progressive disclosure – show users that processing is underway, provide estimated completion times, and when possible, stream partial results. Consider implementing a hybrid approach where a faster model provides an initial response while Deep Think processes in the background for deeper insights.
Managing computational costs requires careful consideration of when Deep Think’s advanced capabilities justify its higher resource usage. Not every query benefits from parallel reasoning – simple factual questions or basic code completion tasks waste Deep Think’s potential. Implement intelligent routing that analyzes query complexity before model selection. Track the value delivered by Deep Think responses versus simpler models to optimize your routing logic. Through laozhang.ai’s unified billing, you can easily compare costs across models and identify optimization opportunities.
Debugging thinking paths can be challenging when Deep Think’s reasoning doesn’t align with expectations. The include_thoughts parameter provides visibility into the model’s reasoning process, but interpreting these thoughts requires understanding the parallel architecture. When debugging, look for patterns in which thinking paths contributed most to the final answer. If certain paths consistently underperform, adjust your prompts to better activate relevant reasoning strategies. The synthesis weights can reveal which aspects of the problem Deep Think found most challenging.
Scaling Deep Think applications presents unique infrastructure challenges. The extended thinking times mean traditional request-response patterns may timeout. Implement asynchronous processing with webhooks or polling for production applications. Cache Deep Think responses aggressively – the comprehensive analysis it provides often remains valuable for similar queries. Consider batch processing for non-urgent analysis tasks, which laozhang.ai supports with discounted pricing. For high-scale deployments, implement circuit breakers that gracefully degrade to faster models during peak loads while maintaining Deep Think for high-value queries.
The Future of Deep Think: Roadmap and Predictions
Google’s roadmap for Gemini 2.5 Deep Think reveals ambitious plans that will further extend its capabilities. The imminent release of a 2 million token context window will double the current capacity, enabling analysis of even larger codebases, complete book series, or multi-year business intelligence data. This expansion isn’t just about size – early testing suggests the larger context improves reasoning quality by providing richer background information for the parallel thinking paths to explore.
Enhanced tool integration represents another frontier for Deep Think’s evolution. Current versions can execute code and perform web searches, but future updates will introduce specialized tools for scientific computation, database queries, and even controlling external APIs. Imagine Deep Think not just designing a system architecture but actually implementing proof-of-concepts, running benchmarks, and iterating based on results. This tight integration between reasoning and action will blur the lines between AI assistant and AI agent.
Enterprise features through Vertex AI will bring Deep Think into production environments with stringent security and compliance requirements. Private deployment options will allow sensitive industries like healthcare and finance to leverage Deep Think’s capabilities without data leaving their infrastructure. Fine-tuning capabilities, currently in limited preview, will enable organizations to specialize Deep Think for domain-specific reasoning, potentially achieving superhuman performance in narrow fields.
The broader industry impact of Deep Think’s success is already visible. Competitors are rushing to develop their own parallel reasoning architectures, leading to rapid innovation in AI reasoning capabilities. We predict that by 2026, extended thinking times and parallel exploration will become standard features across all major AI platforms. This will fundamentally change how we interact with AI – from quick question-answering systems to thoughtful reasoning partners that can tackle humanity’s most complex challenges. Early adopters who master these capabilities today through platforms like laozhang.ai will have a significant competitive advantage as this technology matures.
Deep Think FAQs: Everything Developers Need to Know
What are the pricing options for Gemini 2.5 Deep Think? There are two primary access methods: Google AI Ultra subscription at $249.99/month with unlimited usage but fixed costs, or API access through providers like laozhang.ai with pay-as-you-go pricing. API pricing varies based on thinking budget and context length, typically ranging from $0.10-0.50 per complex query. For most developers, the API route offers better flexibility and cost control.
What are the API rate limits and quotas? Google hasn’t published official rate limits for Deep Think, but practical experience shows sustainable usage around 10-20 complex queries per minute. The thinking budget acts as a natural throttle – queries with 50,000 token budgets take several minutes, inherently limiting request rates. Through laozhang.ai, rate limits are managed transparently with automatic queuing for burst traffic and clear quota dashboards.
Which programming languages have SDK support? Official Google SDKs support Python, JavaScript/Node.js, Go, and Java. Community SDKs exist for Ruby, PHP, C#, and Rust. The laozhang.ai unified API maintains compatibility with OpenAI’s SDK format, enabling easy integration with existing codebases. All SDKs support the full Deep Think feature set including thinking configuration and thought streaming. Getting started requires a Gemini API key, which can be obtained through Google AI Studio or simplified access via laozhang.ai.
How does Deep Think handle data security and privacy? Deep Think processes data according to Google’s enterprise security standards, including encryption in transit and at rest. For sensitive applications, consider Vertex AI’s upcoming private deployment options. API providers like laozhang.ai add additional security layers including request sanitization and optional data retention policies. Deep Think doesn’t train on API queries, ensuring your proprietary information remains confidential.
How difficult is migration from other models to Deep Think? Migration complexity depends on your current model usage. Simple chat applications require minimal changes – primarily adding thinking_config parameters. Applications deeply integrated with model-specific features need more consideration. The unified API approach of laozhang.ai simplifies migration by providing consistent interfaces across models, allowing gradual transition and A/B testing between Deep Think and your current solution.