The AI landscape has dramatically evolved in 2025, with Anthropic’s Claude 3.7 Sonnet and OpenAI’s GPT o1 emerging as two of the most powerful large language models (LLMs) available today. Both models represent significant advances in AI reasoning, coding capabilities, and natural language understanding, but they excel in different areas and come with distinct pricing models and integration options.
In this comprehensive comparison, we’ll examine how Claude 3.7 Sonnet and GPT o1 stack up against each other across various performance benchmarks, real-world applications, and practical considerations to help you determine which model is best suited for your specific needs.

Key Differences at a Glance: Claude 3.7 Sonnet vs GPT o1
Before diving into detailed comparisons, let’s highlight the fundamental differences between these two powerful AI models:
| Feature | Claude 3.7 Sonnet | GPT o1 |
|---|---|---|
| Developer | Anthropic | OpenAI |
| Release Date | February 2025 | December 2024 |
| Primary Strength | Coding, extended reasoning, reliability | Logical reasoning, STEM problem-solving |
| Context Window | 200,000 tokens | 200,000 tokens |
| Input Pricing | $3 per million tokens | $15 per million tokens |
| Output Pricing | $15 per million tokens | $60 per million tokens |
| Knowledge Cutoff | April 2024 | October 2023 |
| Unique Feature | Extended thinking mode with visible reasoning | Internal chain-of-thought reasoning |
| API Access | Anthropic API, Amazon Bedrock, Google Cloud Vertex AI | OpenAI API, Azure OpenAI |
While both models represent the cutting edge of AI technology, Claude 3.7 Sonnet offers significantly lower costs (approximately 4x cheaper) while excelling in coding tasks. Meanwhile, GPT o1 delivers exceptional reasoning performance, particularly for mathematical and logic problems.
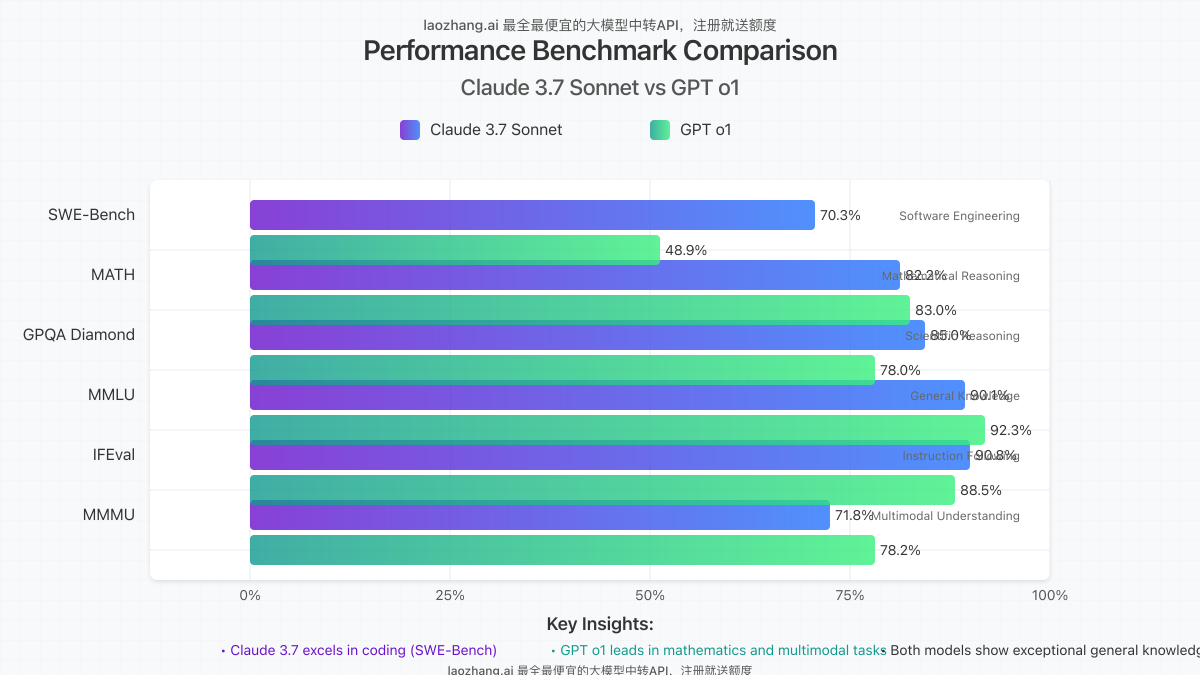
Performance Benchmarks: Who Wins on Paper?
Both Claude 3.7 Sonnet and GPT o1 have been extensively evaluated on standardized AI benchmarks. Here’s how they compare across key performance metrics:
Coding and Software Development
When it comes to coding tasks, Claude 3.7 Sonnet demonstrates clear superiority, particularly on real-world software development benchmarks:
- SWE-Bench Verified: Claude 3.7 Sonnet achieves 70.3% accuracy, significantly outperforming GPT o1’s 48.9%
- HumanEval: Claude 3.7 Sonnet performs exceptionally well, with early testing showing it can tackle complex web development tasks that other models struggle with
- Real-world coding applications: Partners like Cursor, Vercel and Replit consistently report that Claude 3.7 Sonnet produces higher quality, more reliable code
In practical terms, Claude 3.7 Sonnet demonstrates particular strength in generating working code, debugging complex issues, and handling full-stack development tasks. Its “extended thinking” feature allows it to work through programming challenges step-by-step, reducing errors in complex implementations.
Mathematical Reasoning
For mathematical reasoning tasks, GPT o1 generally outperforms Claude 3.7 Sonnet:
- MATH benchmark: GPT o1 scores 83% accuracy, compared to Claude 3.7 Sonnet’s 82.2%
- AIME (American Invitational Mathematics Examination): GPT o1 achieves approximately 83% accuracy versus Claude 3.7 Sonnet’s 80% in extended thinking mode
- GSM8K: Both models perform exceptionally well on grade-school math problems, with accuracy rates above 90%
While the gap isn’t enormous, GPT o1’s specific optimization for multi-step logical reasoning gives it a slight edge in pure mathematical problem-solving. However, Claude 3.7 Sonnet’s extended thinking mode narrows this gap considerably.
General Knowledge and Reasoning
For general knowledge and reasoning capabilities:
- GPQA Diamond (graduate-level scientific reasoning): Claude 3.7 Sonnet scores 85%, while GPT o1 achieves 78%
- MMLU (Massive Multitask Language Understanding): GPT o1 scores 92.3%, with Claude 3.7 Sonnet achieving competitive but slightly lower results
- IFEval (Instruction Following): Claude 3.7 Sonnet scores 90.8%, demonstrating exceptional ability to follow complex instructions
The results show that both models exhibit extraordinary general knowledge and reasoning capabilities, with Claude 3.7 Sonnet generally performing better on scientific reasoning and instruction following, while GPT o1 has a slight edge on multitask language understanding.
Multimodal Capabilities
Both models offer multimodal capabilities, accepting text and image inputs:
- MMMU (Massive Multimodal Understanding): GPT o1 scores 78.2%, while Claude 3.7 Sonnet achieves 71.8%
- Image analysis and understanding: Both models can analyze images, charts, and diagrams effectively, though neither generates images
In multimodal tasks, GPT o1 demonstrates a moderate advantage in understanding and reasoning about visual content alongside text.
Real-World Performance: Practical Tests and Use Cases
While benchmarks provide valuable insights, real-world performance often reveals more practical differences between these advanced AI models. Let’s examine how Claude 3.7 Sonnet and GPT o1 perform across various practical applications:
Programming and Software Development
Based on extensive testing and user feedback, Claude 3.7 Sonnet consistently outperforms GPT o1 in real-world programming tasks:
Example: Building a Real-time Collaborative Whiteboard
When tasked with creating a real-time collaborative whiteboard application in Next.js with WebSocket integration:
- Claude 3.7 Sonnet produced fully functional code with proper WebSocket implementation, error handling, and clean UI design in a single generation
- GPT o1 established the WebSocket connection but encountered issues with data parsing and struggled to implement the collaborative functionality completely
Even when guided to fix errors, GPT o1 couldn’t fully resolve the implementation issues, while Claude 3.7 Sonnet delivered production-ready code on the first attempt.
For developers, Claude 3.7 Sonnet offers significant advantages in:
- Handling complex, full-stack applications
- Implementing correct error handling
- Understanding and working with modern frameworks
- Producing code that works the first time with fewer bugs
For organizations building software, Claude 3.7 Sonnet’s superior coding capabilities translate to faster development cycles and reduced debugging time.
Mathematical Problem Solving
When it comes to complex mathematical reasoning, GPT o1 demonstrates exceptional capabilities:
Example: Solving Complex Math SAT Questions
In tests with challenging SAT math problems:
- GPT o1 correctly solved approximately 85% of the problems, showing strong performance comparable to specialized reasoning models
- Claude 3.7 Sonnet solved about 75% correctly, performing well but showing occasional limitations with complex mathematical reasoning
GPT o1’s advantage in mathematical reasoning makes it particularly valuable for:
- Academic research requiring complex calculations
- Financial modeling and analysis
- Scientific computing applications
- Engineering problem-solving
Reasoning with New Contexts
An interesting area of comparison is how these models handle reasoning when presented with familiar scenarios that contain subtle but important modifications:
Example: Modified Classic Puzzles
When tested with modified versions of well-known puzzles (like the Monty Hall problem with key details changed):
- Claude 3.7 Sonnet adapted to the new context remarkably well, correctly analyzing the modified scenarios without being overly influenced by its training data
- GPT o1 showed a stronger tendency to apply reasoning based on the standard version of the puzzles, sometimes missing the critical modifications
This suggests that Claude 3.7 Sonnet may be more flexible in adapting to new contexts and variations on familiar problems, which is valuable for novel problem-solving scenarios.
Content Creation and Writing
Both models excel at content creation, though with different strengths:
- Claude 3.7 Sonnet produces exceptionally natural, human-like writing with nuanced tone and style adaptation
- GPT o1 delivers coherent, well-structured content with strong factual accuracy
For creative writing, marketing copy, and long-form content, Claude 3.7 Sonnet’s natural writing style often receives higher ratings from human evaluators. For technical writing and fact-dense content, GPT o1’s precision can be advantageous.
Business Analytics and Decision Support
For business analytics applications, both models demonstrate strong capabilities:
- Claude 3.7 Sonnet excels at analyzing large documents (utilizing its 200K token context window) and extracting insights from unstructured data
- GPT o1 performs exceptionally well at structured data analysis and logical reasoning for business decision-making
The choice between models for business applications often depends on whether the primary need is for processing large volumes of unstructured text (where Claude 3.7 Sonnet excels) or complex analytical reasoning (where GPT o1 may have an edge).

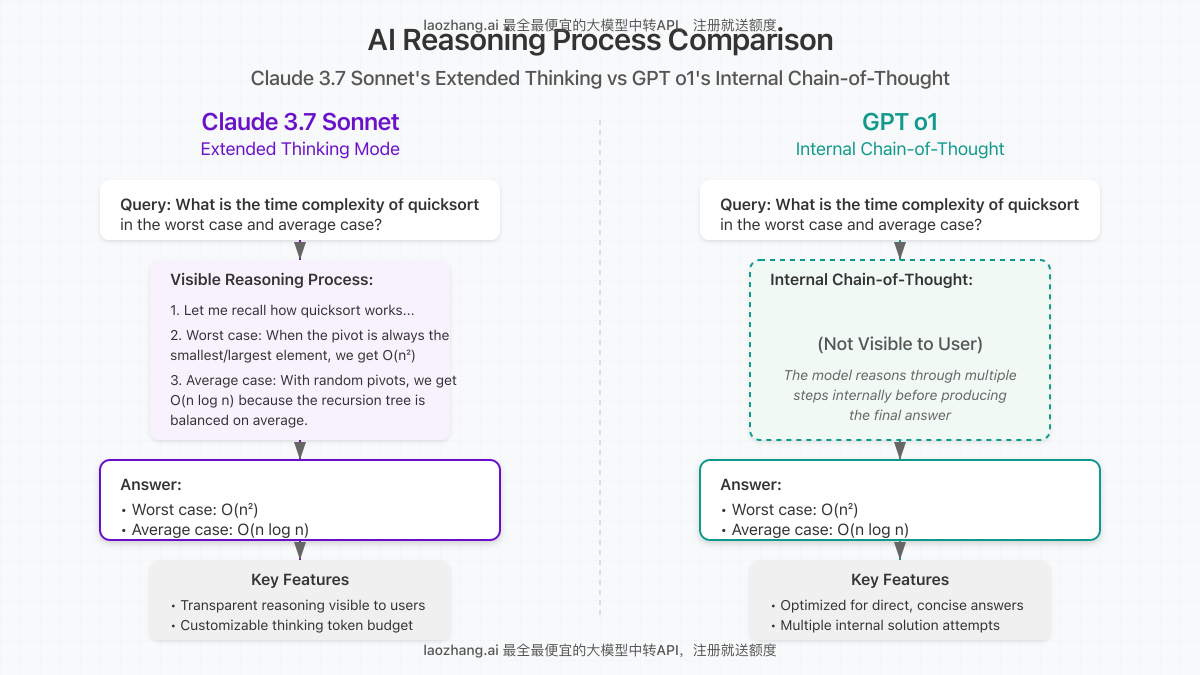
Hybrid Reasoning: Extended Thinking vs. Internal Chain-of-Thought
One of the most significant differentiators between these models is their approach to complex reasoning:
Claude 3.7 Sonnet’s Extended Thinking
Claude 3.7 Sonnet introduces a revolutionary “extended thinking” feature that allows users to toggle between standard fast responses and in-depth reasoning:
- Visible reasoning: In extended thinking mode, Claude shows its step-by-step thought process to the user, creating transparency in how it reaches conclusions
- Customizable thinking budget: API users can specify how many tokens Claude should dedicate to thinking before providing an answer
- Unified model: Both quick responses and deep reasoning come from the same model, creating a seamless experience
This approach gives users control over the speed-quality tradeoff and provides valuable insight into the model’s reasoning process.
GPT o1’s Internal Chain-of-Thought
OpenAI’s GPT o1 employs an internal chain-of-thought mechanism:
- Hidden reasoning: The model performs deep reasoning internally but typically only presents the final answer to users
- Self-consistency: GPT o1 can generate multiple potential solutions internally before selecting the most reliable one
- Optimized for accuracy: This approach prioritizes producing the correct answer without exposing the intermediate steps
While this approach can deliver highly accurate results, it provides less transparency into how the model reached its conclusions.
Reasoning Approach Comparison
Claude 3.7 Sonnet (Extended Thinking): “Let me think about this step by step… [displays detailed reasoning process] Therefore, the answer is X.”
GPT o1: “The answer is X.” (Internal reasoning process not shown)
The choice between these approaches depends on your specific needs:
- If transparency and understanding the model’s reasoning is important, Claude 3.7 Sonnet’s visible thinking provides significant advantages
- If you’re primarily concerned with the final answer and less about how it was derived, GPT o1’s approach may be more efficient
Pricing and Accessibility: Cost-Performance Trade-offs
A critical factor in choosing between these models is the significant difference in pricing:
Cost Comparison
| Cost (per 1M tokens) | Claude 3.7 Sonnet | GPT o1 | Difference |
|---|---|---|---|
| Input tokens | $3.00 | $15.00 | GPT o1 is 5x more expensive |
| Output tokens | $15.00 | $60.00 | GPT o1 is 4x more expensive |
| Extended thinking tokens | Included in output price | N/A (internal) | N/A |
Claude 3.7 Sonnet offers substantially better pricing, making it significantly more cost-effective for most applications. This pricing advantage becomes especially pronounced for:
- High-volume applications with many API calls
- Use cases requiring lengthy outputs (like code generation or document creation)
- Applications where extended context windows are needed
Availability and Integration
Both models are accessible through multiple platforms:
- Claude 3.7 Sonnet: Available via Claude.ai (web), Anthropic API, Amazon Bedrock, and Google Cloud Vertex AI
- GPT o1: Accessible through ChatGPT Plus, OpenAI API, and Azure OpenAI Service
Claude 3.7 Sonnet’s integration with major cloud providers (AWS and GCP) offers advantages for enterprises already using these platforms. Meanwhile, GPT o1’s availability through OpenAI’s ecosystem provides seamless integration with other OpenAI services.

Practical Use Case Recommendations
Based on our comprehensive analysis, here are our recommendations for which model to choose for specific use cases:
Choose Claude 3.7 Sonnet for:
- Software Development: Claude’s superior coding capabilities make it the clear choice for programming assistance, debugging, and building complex applications
- Content Creation: Its natural, human-like writing style excels at creative content, marketing copy, and long-form writing
- Document Analysis: The large 200K token context window combined with reasonable pricing makes it ideal for analyzing extensive documents
- Cost-Sensitive Applications: For high-volume or budget-conscious projects, Claude’s pricing offers significant advantages
- Educational Use: The visible reasoning process makes it excellent for learning and understanding complex concepts
- Customer Support: Natural communication style and reliability make it well-suited for customer-facing applications
Choose GPT o1 for:
- Advanced Mathematical Reasoning: Superior performance on complex math and logic problems
- Scientific Computing: Excellent at handling scientific and technical reasoning tasks
- Multimodal Understanding: Slightly better performance on tasks involving image analysis alongside text
- Financial Analysis: Strong logical reasoning makes it well-suited for complex financial modeling
- Integration with OpenAI Ecosystem: Better choice if you’re already heavily invested in other OpenAI services
Expert Recommendation
For most general-purpose applications, especially those involving coding or content creation, Claude 3.7 Sonnet offers the best combination of performance and value. Its significantly lower cost and comparable or superior performance in many areas make it the recommended default choice.
Consider GPT o1 for specialized applications requiring the absolute highest level of mathematical reasoning or for integration with existing OpenAI workflows where the cost premium is justified.
Future Developments and Model Evolution
The AI landscape continues to evolve rapidly, with both Anthropic and OpenAI pursuing aggressive development roadmaps:
- Anthropic has positioned Claude 3.7 Sonnet as a hybrid reasoning model that bridges the gap between fast chatbots and specialized reasoning systems
- OpenAI’s o-series represents a new direction focusing on deep reasoning capabilities, with future versions likely to build on this foundation
- Both companies are expected to introduce internet browsing capabilities to their models in upcoming releases
As these models continue to develop, we can expect further improvements in reasoning capabilities, multimodal understanding, and tool use. The competition between these leading AI providers will likely drive continued innovation and performance improvements.
Conclusion: Choosing the Right Model for Your Needs
Claude 3.7 Sonnet and GPT o1 represent two different philosophies in advanced AI development, with different strengths and cost structures:
- Claude 3.7 Sonnet offers exceptional coding capabilities, natural writing, transparent reasoning, and significantly better pricing, making it the better overall value for most applications
- GPT o1 excels in deep mathematical reasoning and logical problem-solving, with advantages in multimodal tasks, albeit at a substantially higher price point
For developers, content creators, and businesses looking to integrate advanced AI capabilities, Claude 3.7 Sonnet typically offers the best combination of performance and value. The visible reasoning process and superior coding abilities make it particularly valuable for software development and educational contexts.
For specialized applications in scientific computing, advanced mathematics, or financial modeling where reasoning performance is the absolute priority regardless of cost, GPT o1 may be worth the premium pricing.
As these models continue to evolve, we can expect the performance gap to narrow in various domains, but for now, understanding these distinct strengths will help you choose the right AI partner for your specific needs.
Ready to try these models for yourself?
Register at LaoZhang AI for the most affordable access to both Claude 3.7 Sonnet and GPT o1, along with other top AI models. Get started with a free trial and the lowest per-token pricing available.