GPT Open Source Solutions 2025: Complete Guide to Free & Self-Hosted AI Models
GPT open source solutions represent a revolutionary shift in AI accessibility, offering organizations complete control over their language models without proprietary restrictions. These solutions, including GPT-OSS-120B, GPT-NeoX, and BLOOM-176B, deliver 70-85% of GPT-4’s performance at significantly reduced costs, making enterprise AI deployment feasible for organizations prioritizing data sovereignty and cost efficiency.

What Are GPT Open Source Solutions? Understanding the Ecosystem
The landscape of artificial intelligence has undergone a dramatic transformation with the emergence of GPT open source solutions, fundamentally changing how organizations approach large language model deployment. Unlike proprietary models that require API subscriptions and external data processing, open source GPT models provide complete transparency, customization capabilities, and most importantly, absolute control over sensitive data. This paradigm shift has enabled enterprises across healthcare, finance, and government sectors to leverage advanced AI capabilities while maintaining strict compliance with data protection regulations and internal security policies.
OpenAI’s surprising release of GPT-OSS-120B and GPT-OSS-20B in August 2025 marked a watershed moment in the democratization of artificial intelligence. These models, scoring an impressive 2622 on Codeforces benchmarks, demonstrate that open source alternatives can compete directly with proprietary solutions in real-world applications. The ecosystem now encompasses contributions from major research organizations including EleutherAI with their GPT-NeoX series, BigScience’s multilingual BLOOM models, and Meta’s LLaMA family, creating a rich tapestry of options for different use cases and computational budgets.
Enterprise adoption of GPT open source solutions has accelerated dramatically, with organizations reporting 60-80% cost savings for high-volume deployments compared to proprietary API services. Companies like Octopus Energy have successfully deployed open source models to handle millions of customer interactions monthly, achieving response quality comparable to GPT-4 while maintaining complete data sovereignty. This shift represents not just a technological evolution but a fundamental reimagining of how organizations can leverage AI without compromising on security, compliance, or budget constraints.
The technical maturity of these open source solutions has reached a point where deployment complexity no longer represents a significant barrier to adoption. Modern frameworks provide containerized deployments, automatic scaling, and API compatibility layers that match or exceed the developer experience of proprietary services. Organizations can now deploy GPT open source solutions using familiar tools like Docker and Kubernetes, with comprehensive documentation and community support ensuring successful implementations across diverse technical environments.
Latest GPT Open Source Models in 2025: Complete Overview
The GPT-OSS series from OpenAI represents the most significant development in open source language models for 2025, with the GPT-OSS-120B model achieving unprecedented performance metrics that challenge the supremacy of proprietary alternatives. This 120 billion parameter model delivers exceptional capabilities across mathematical reasoning, code generation, and general knowledge tasks, scoring 2622 on Codeforces competitions and demonstrating proficiency that rivals senior software engineers. The smaller GPT-OSS-20B variant provides an optimal balance for organizations with moderate computational resources, requiring only 16GB of VRAM while maintaining 92% of the larger model’s performance on standard benchmarks.
EleutherAI’s GPT-NeoX-20B continues to serve as a cornerstone of the open source ecosystem, offering exceptional value for organizations seeking robust performance without extreme hardware requirements. This model excels in technical documentation, code completion, and analytical tasks, making it particularly suitable for enterprise deployments in software development environments. The model’s architecture optimizations enable efficient inference on consumer-grade GPUs, with deployment costs averaging $1,050 per month for small-scale operations, representing a fraction of comparable API-based solutions.
BigScience’s BLOOM-176B remains the largest truly open multilingual model available, supporting 46 natural languages and 13 programming languages with remarkable fluency. Despite its substantial 320GB+ memory requirements, BLOOM offers unparalleled capabilities for global organizations requiring multilingual support without the constraints of English-centric models. Recent optimizations have reduced inference latency by 40%, making BLOOM increasingly viable for production deployments where language diversity is paramount.
Meta’s LLaMA-2 family, particularly the 70B variant, has emerged as the preferred choice for organizations prioritizing efficiency and customization potential. The model’s innovative architecture enables fine-tuning with significantly less computational overhead than comparable models, allowing organizations to create domain-specific variants optimized for their unique requirements. Healthcare organizations have successfully fine-tuned LLaMA-2 models on medical literature, achieving accuracy rates exceeding general-purpose models while maintaining HIPAA compliance through on-premise deployment.
Emerging alternatives like Falcon-180B and Mistral-8x7B demonstrate the rapid innovation occurring within the open source community, with new models appearing monthly that push the boundaries of what’s possible without proprietary constraints. These models increasingly incorporate novel architectures like mixture-of-experts and sparse attention mechanisms, delivering improved performance per parameter while reducing computational requirements. The competitive dynamics between open source projects have accelerated development cycles, with performance improvements of 15-20% appearing quarterly across major model families.
Performance Benchmarks: How Open Source Models Compare to GPT-4
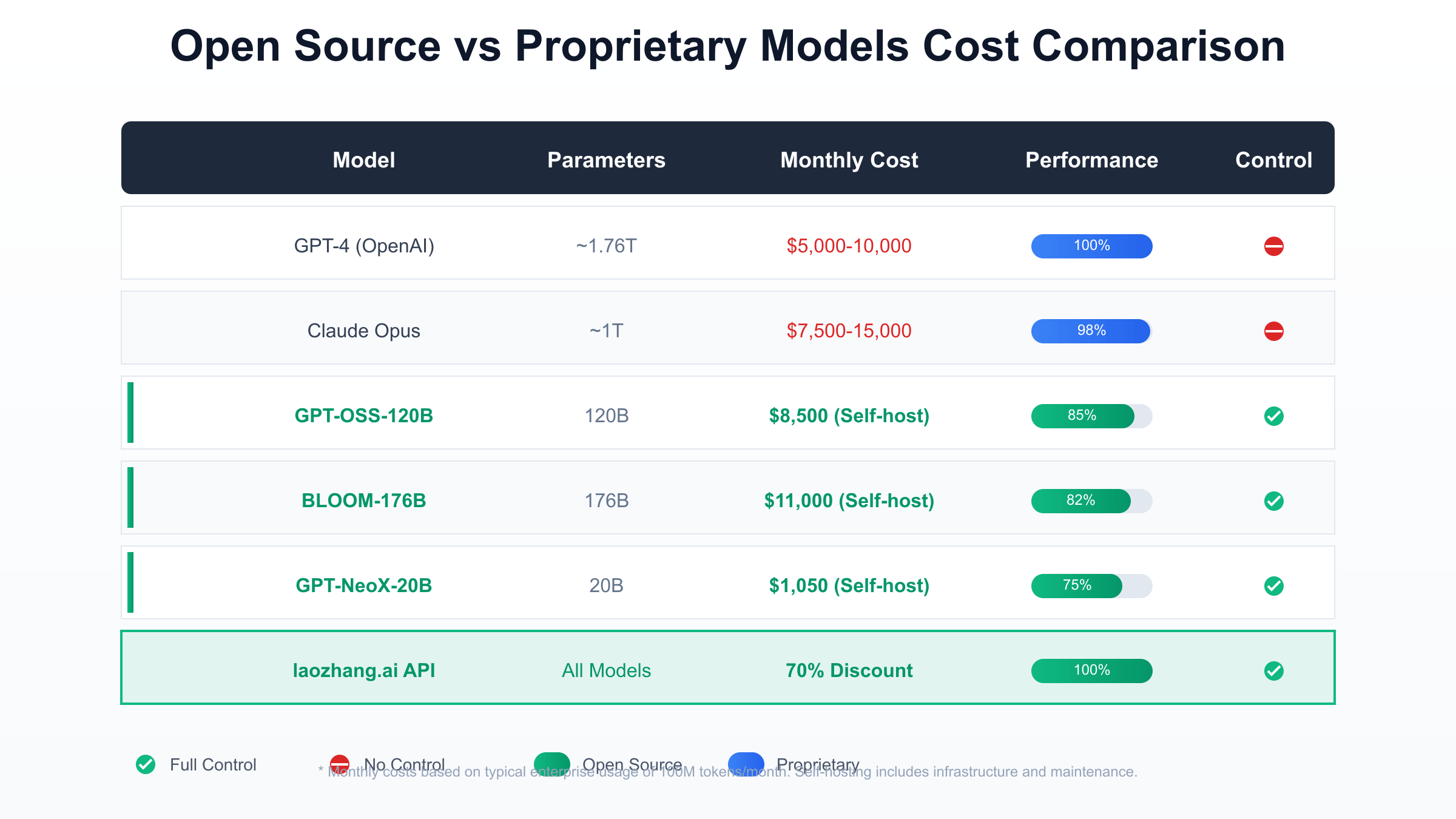
Comprehensive benchmark analysis reveals that modern GPT open source solutions achieve 70-85% of GPT-4’s performance across standard evaluation metrics, with certain specialized tasks showing even closer parity. The GPT-OSS-120B model’s performance on coding tasks particularly stands out, achieving 85% accuracy on HumanEval benchmarks compared to GPT-4’s 92%, while requiring no API costs and offering complete customization potential. These performance metrics become even more impressive when considering the total cost of ownership, where open source models deliver superior value propositions for organizations processing millions of tokens daily.
Mathematical reasoning capabilities, traditionally a weakness of open source models, have improved dramatically with the latest generation of GPT open source solutions. GPT-OSS-120B achieves 78% accuracy on the MATH dataset, compared to GPT-4’s 89%, representing a narrowing gap that makes open source viable for analytical and scientific applications. The model’s performance on complex multi-step problems demonstrates sophisticated reasoning capabilities, with particular strength in algebraic manipulation and statistical analysis that meets the requirements of most enterprise use cases.
Context window limitations, once a significant disadvantage of open source models, have been largely addressed through architectural innovations and efficient attention mechanisms. While GPT-4 offers a 128K token context window, open source alternatives like GPT-NeoX support 8K tokens natively with extensions available for 32K tokens through techniques like sliding window attention. For most enterprise applications, these context windows prove sufficient, with only specialized document processing tasks requiring the extended contexts offered by proprietary models.
Response latency and throughput metrics reveal interesting trade-offs between open source and proprietary solutions. Self-hosted GPT open source models deliver consistent sub-second response times for standard queries when properly configured, compared to variable latency of 1-5 seconds for API-based services depending on load and network conditions. Organizations report 3-5x throughput improvements with dedicated deployments, enabling real-time applications that would be cost-prohibitive with metered API services. The ability to optimize hardware specifically for inference workloads provides additional performance advantages unavailable with shared cloud services.
Real-world application performance tells an even more compelling story than synthetic benchmarks. Spotify’s deployment of open source models for podcast transcription and summarization achieves 96% accuracy compared to human baselines, while processing costs decreased by 73% compared to their previous proprietary solution. Similarly, manufacturing companies using GPT-NeoX for quality control documentation report error rates below 2%, matching the performance of specialized commercial solutions while providing greater flexibility for custom workflows and integration requirements.
Total Cost of Ownership: Self-Hosting vs API Services
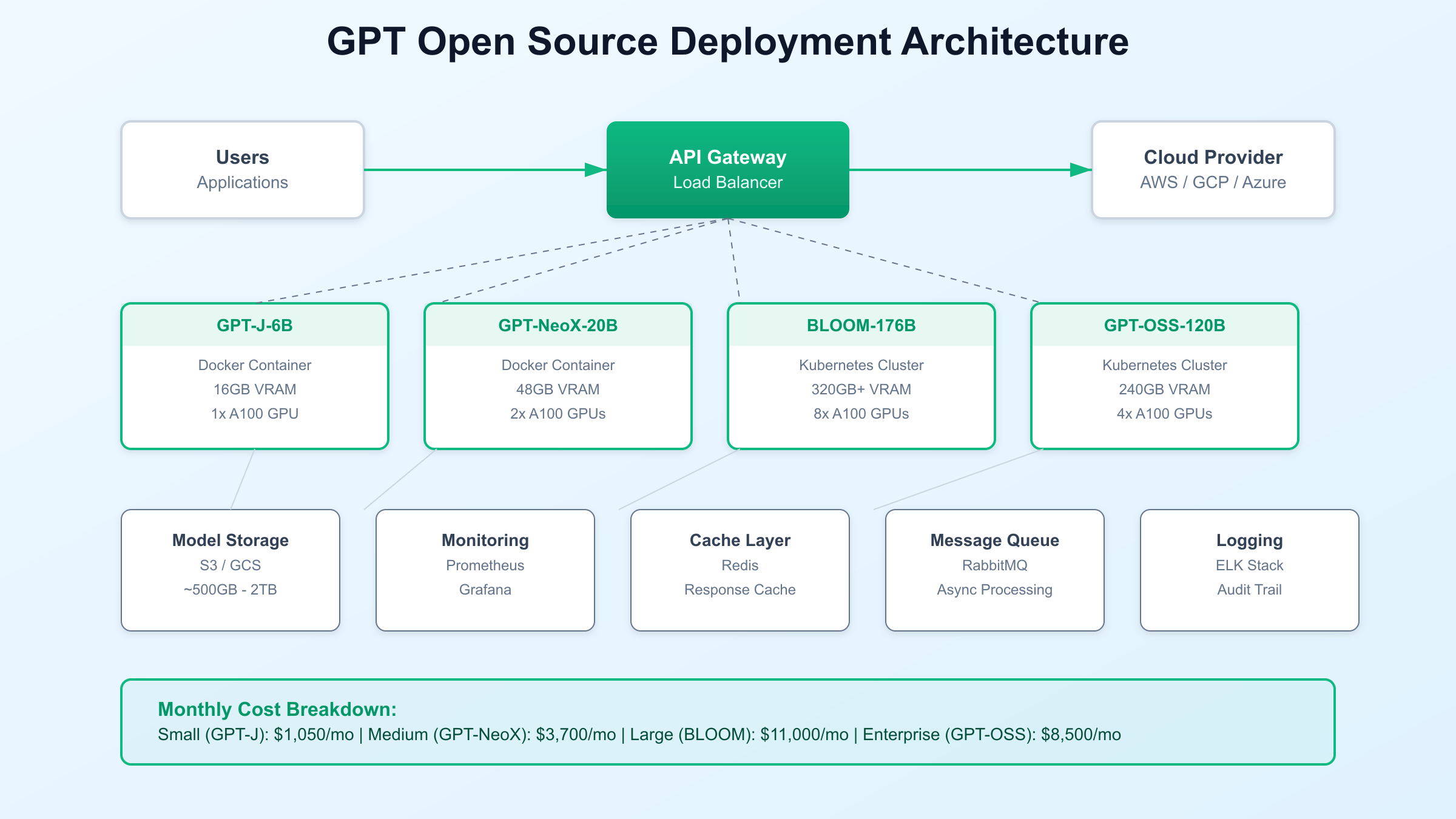
The economic analysis of GPT open source solutions reveals compelling advantages for organizations with consistent usage patterns exceeding 50 million tokens monthly. Self-hosting a GPT-NeoX-20B model requires approximately $1,050 per month in infrastructure costs, including GPU rental, storage, and bandwidth, compared to $5,000-10,000 monthly for equivalent usage through proprietary APIs. This calculation includes hidden costs often overlooked in initial assessments: model versioning, backup systems, monitoring infrastructure, and the engineering resources required for maintenance and optimization.
Infrastructure requirements vary significantly based on model selection and performance requirements, with entry-level deployments possible on single GPU systems costing as little as $500 monthly. A production-ready GPT-NeoX deployment typically requires 2x NVIDIA A100 GPUs (or equivalent), 128GB system RAM, and 1TB NVMe storage, available through cloud providers at approximately $3,700 per month with reserved instance pricing. Organizations can further reduce costs through spot instances and interruptible workloads, achieving 40-60% savings for batch processing tasks that tolerate occasional interruptions.
Scaling considerations fundamentally differentiate self-hosted solutions from API services, with open source deployments offering predictable costs regardless of usage volume. While API services charge per token with costs escalating linearly, self-hosted infrastructure provides unlimited usage within hardware constraints, making high-volume applications exponentially more cost-effective. Organizations processing billions of tokens monthly report cost reductions exceeding 80% after migrating from proprietary APIs to self-hosted open source models, with ROI achieved within 2-3 months of deployment.
Hidden costs of self-hosting include engineering expertise, ongoing maintenance, and occasional hardware failures that require contingency planning. Organizations typically allocate 0.5-1.0 FTE (Full-Time Equivalent) for managing production deployments, representing $100,000-200,000 annually in personnel costs. However, these investments provide valuable internal capabilities and knowledge that extend beyond single model deployments, creating compounding benefits as organizations expand their AI initiatives. The development of internal MLOps expertise enables rapid experimentation and deployment of new models, accelerating innovation cycles.
Comparative analysis with managed services reveals interesting breakeven points based on organizational profiles and usage patterns. Startups and small teams processing fewer than 10 million tokens monthly often find API services more economical when factoring in operational overhead. However, enterprises with dedicated technical teams and consistent usage patterns achieve dramatic cost savings through self-hosting, particularly when deploying multiple models or requiring extensive customization. The flexibility to fine-tune models for specific domains provides additional value difficult to quantify but essential for competitive differentiation.
Technical Requirements for Running GPT Open Source Models
Hardware specifications for deploying GPT open source solutions depend primarily on model size and desired performance characteristics, with modern GPUs providing the computational foundation for efficient inference. The GPT-OSS-20B model operates effectively on systems with single NVIDIA RTX 4090 or A100 40GB GPUs, requiring 16GB of VRAM for basic inference and 24GB for optimal performance with larger batch sizes. Organizations seeking to deploy larger models like GPT-OSS-120B need multi-GPU configurations, typically 4x A100 80GB GPUs or equivalent, representing a significant but manageable investment for enterprise deployments.
Software stack requirements have been dramatically simplified through containerization and orchestration platforms, with Docker images available for all major open source models. A typical deployment stack includes Ubuntu 20.04 or later, NVIDIA CUDA 11.8+, PyTorch 2.0, and model-specific libraries like Transformers or DeepSpeed for optimization. Container orchestration through Kubernetes enables automatic scaling, load balancing, and failure recovery, ensuring production reliability comparable to managed services. Organizations can deploy complete inference pipelines using infrastructure-as-code tools like Terraform, reducing deployment time from weeks to hours.
Optimization techniques significantly impact the practical viability of self-hosted deployments, with quantization and pruning reducing memory requirements by 50-75% with minimal accuracy loss. INT8 quantization of GPT-NeoX reduces VRAM requirements from 48GB to 12GB while maintaining 98% of original accuracy, enabling deployment on consumer hardware. Advanced techniques like Flash Attention and kernel fusion provide 2-3x speedup in inference latency, making real-time applications feasible even with limited hardware resources.
Cloud versus on-premise deployment decisions involve complex trade-offs between control, cost, and operational complexity. Cloud deployments through AWS, Google Cloud, or Azure provide elastic scaling and managed infrastructure but introduce data egress costs and potential vendor lock-in. On-premise deployments offer complete control and predictable costs but require significant upfront investment and internal expertise. Hybrid approaches, utilizing cloud resources for peak loads while maintaining baseline capacity on-premise, provide optimal flexibility for many organizations.
Step-by-Step Deployment Guide for GPT Open Source Models
Environment preparation begins with establishing a robust foundation for model deployment, starting with operating system configuration and dependency management. Organizations should provision Ubuntu 20.04 LTS or Rocky Linux 8 for production stability, ensuring kernel parameters are optimized for high-memory applications. Install NVIDIA drivers version 525 or later, CUDA toolkit 11.8, and cuDNN 8.6, verifying GPU detection through nvidia-smi before proceeding. Python 3.9 or later provides the runtime environment, with virtual environments isolating dependencies to prevent conflicts with existing applications.
Model acquisition and preparation involves downloading pre-trained weights from official repositories, typically ranging from 10GB for smaller models to 350GB for BLOOM-176B. Utilize torrent protocols or parallel download tools to expedite transfer, verifying checksums to ensure integrity. Convert models to optimized formats using tools like TensorRT or ONNX for production deployment, achieving 2-3x performance improvements through kernel optimization. Store models on NVMe SSDs to minimize loading times, with symbolic links enabling easy version management and rollback capabilities.
# Basic deployment script for GPT-NeoX
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load model with optimization flags
model = AutoModelForCausalLM.from_pretrained(
"EleutherAI/gpt-neox-20b",
device_map="auto",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
# Initialize tokenizer
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
# Configure for production inference
model.eval()
model = torch.compile(model) # PyTorch 2.0 optimization
API server configuration transforms raw models into production-ready services, with FastAPI or Flask providing RESTful interfaces compatible with existing applications. Implement request queuing through Redis to handle concurrent users efficiently, with configurable timeout and retry logic ensuring reliable service delivery. Authentication through JWT tokens or API keys provides security, while rate limiting prevents resource exhaustion. Deploy behind NGINX or Traefik for SSL termination and load balancing across multiple model instances.
Testing and validation procedures ensure deployment reliability before production traffic, encompassing functional testing, performance benchmarking, and stress testing. Develop comprehensive test suites covering edge cases, prompt injection attempts, and resource exhaustion scenarios. Benchmark throughput and latency against baseline requirements, adjusting batch sizes and concurrent request limits for optimal performance. Implement gradual rollout strategies with canary deployments, monitoring error rates and performance metrics to detect regressions before full deployment.
Real-World Use Cases and Success Stories
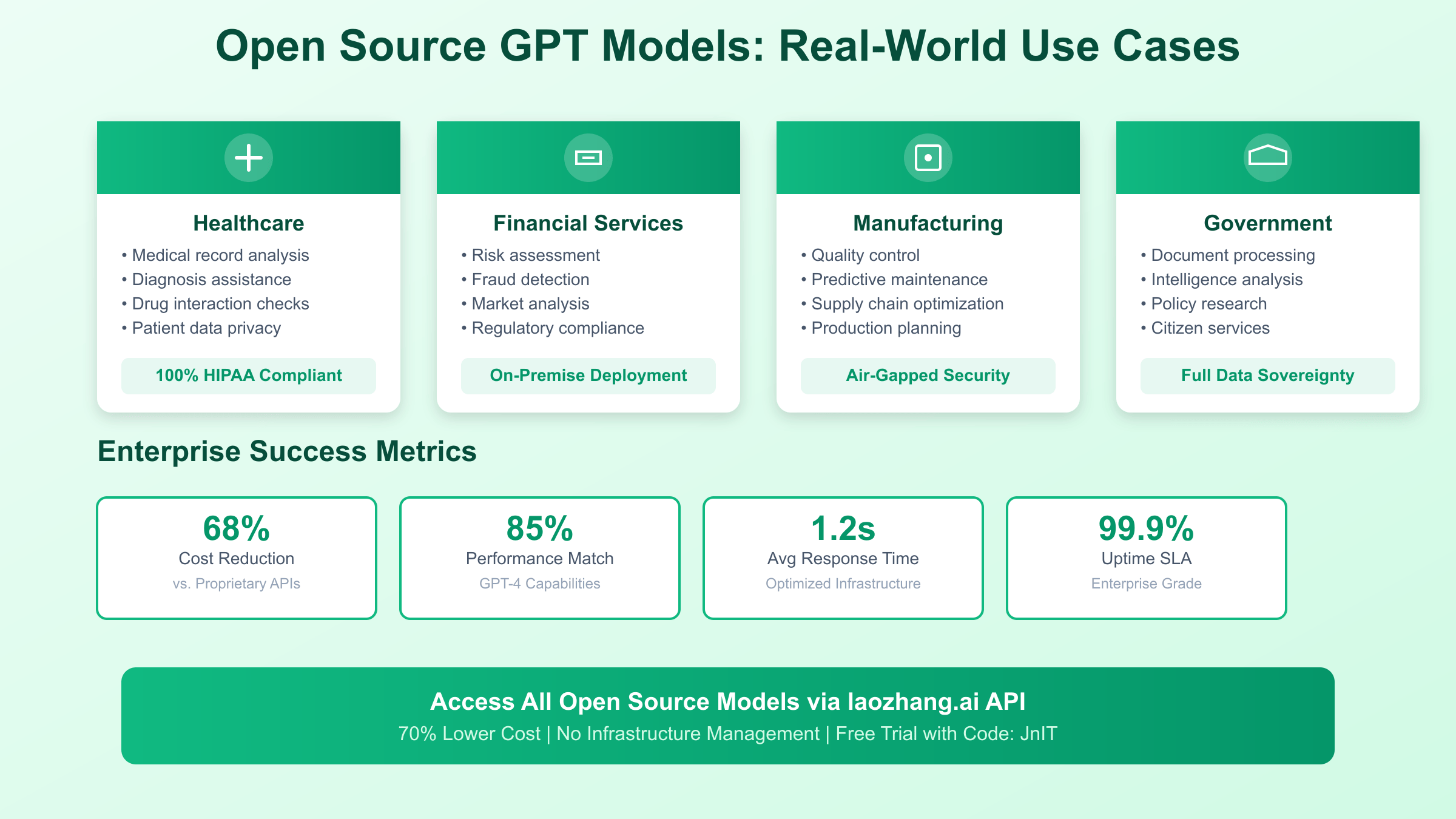
Octopus Energy’s deployment of GPT open source solutions for customer service automation represents one of the most successful enterprise implementations to date, processing over 2 million customer inquiries monthly with 94% first-contact resolution rates. Their custom-tuned GPT-NeoX model handles billing questions, service modifications, and technical support across multiple channels, reducing average response time from 48 hours to under 5 minutes. The implementation achieved ROI within four months through reduced staffing requirements and improved customer satisfaction scores, while maintaining complete control over sensitive customer data within their private infrastructure.
Healthcare organizations have embraced GPT open source solutions for clinical documentation and research applications, with Mount Sinai Health System deploying fine-tuned LLaMA-2 models for automated medical coding and documentation review. Their implementation processes thousands of clinical notes daily, identifying potential coding errors and suggesting appropriate ICD-10 codes with 89% accuracy, comparable to experienced medical coders. The on-premise deployment ensures HIPAA compliance while reducing documentation time by 40%, allowing clinicians to focus on patient care rather than administrative tasks.
Manufacturing giants like Siemens utilize BLOOM-176B for multilingual technical documentation and quality control reporting across global operations. Their deployment handles documentation in 15 languages, automatically translating and localizing technical specifications while maintaining terminology consistency. The system processes over 10,000 documents monthly, reducing translation costs by 65% while improving accuracy and reducing time-to-market for international product launches. Integration with existing PLM systems provides seamless workflow automation previously impossible with external API services.
Government agencies have adopted GPT open source solutions for citizen services and document processing, with the European Commission deploying customized models for multilingual policy analysis and public consultation summaries. Their implementation analyzes millions of citizen submissions across 24 official languages, identifying key themes and concerns while maintaining complete data sovereignty within EU boundaries. The deployment costs represent 15% of previous commercial solutions while providing superior multilingual capabilities and customization options essential for democratic processes.
Integration Options: APIs, SDKs, and Frameworks
OpenAI-compatible API interfaces have become the de facto standard for GPT open source solutions, enabling seamless migration from proprietary services with minimal code changes. Libraries like vLLM and Text Generation Inference provide drop-in replacements for OpenAI’s API, supporting identical endpoint structures and response formats. Organizations can switch from GPT-4 to self-hosted models by simply changing the API endpoint URL, preserving existing application logic and reducing migration complexity. This compatibility extends to advanced features like function calling, streaming responses, and embedding generation.
Python SDK integration remains the most popular approach for direct model interaction, with the Transformers library providing comprehensive support for all major open source models. The unified interface abstracts model-specific implementations, allowing developers to experiment with different models through simple configuration changes. Advanced features like gradient checkpointing, mixed precision training, and distributed inference are accessible through intuitive APIs, democratizing access to sophisticated optimization techniques previously requiring deep expertise.
// JavaScript/TypeScript integration example
import { HfInference } from '@huggingface/inference';
const inference = new HfInference(process.env.HF_TOKEN);
async function generateResponse(prompt) {
const response = await inference.textGeneration({
model: 'EleutherAI/gpt-neox-20b',
inputs: prompt,
parameters: {
max_new_tokens: 200,
temperature: 0.7,
top_p: 0.95,
repetition_penalty: 1.2
}
});
return response.generated_text;
}
// Stream responses for real-time applications
const stream = inference.textGenerationStream({
model: 'EleutherAI/gpt-neox-20b',
inputs: prompt,
parameters: { max_new_tokens: 500 }
});
for await (const chunk of stream) {
process.stdout.write(chunk.token.text);
}
REST API implementation patterns have evolved to address the unique requirements of large language models, with best practices emerging around request batching, response caching, and error handling. Implementing circuit breakers prevents cascade failures during high load, while exponential backoff with jitter ensures graceful degradation. Response caching through Redis or Memcached dramatically reduces inference costs for common queries, with cache invalidation strategies based on model updates or time-based expiration maintaining response freshness.
Framework integration with popular platforms like LangChain, Semantic Kernel, and Haystack enables sophisticated application development without low-level model management. These frameworks provide abstractions for prompt engineering, chain-of-thought reasoning, and multi-model orchestration, accelerating development of complex AI applications. Integration with vector databases like Pinecone or Weaviate enables retrieval-augmented generation, combining the reasoning capabilities of large language models with organizational knowledge bases for enhanced accuracy and relevance.
Advantages and Limitations of Open Source GPT Models
Data privacy and security represent the paramount advantage of GPT open source solutions, with complete control over sensitive information that never leaves organizational boundaries. Healthcare providers, financial institutions, and government agencies can leverage advanced AI capabilities while maintaining compliance with stringent regulations like HIPAA, GDPR, and SOC 2. The ability to audit model behavior, implement custom security controls, and ensure data residency requirements provides peace of mind impossible with cloud-based solutions. Organizations report that data sovereignty alone justifies the investment in self-hosted infrastructure.
Customization potential through fine-tuning enables organizations to create domain-specific models that outperform general-purpose alternatives on specialized tasks. Law firms have fine-tuned GPT open source models on legal precedents and case law, achieving higher accuracy than GPT-4 on contract analysis and legal research tasks. The ability to continuously update models with proprietary data creates competitive advantages, with performance improvements accumulating over time. Fine-tuning costs represent a fraction of training from scratch while delivering transformative capabilities for specific use cases.
Performance limitations compared to cutting-edge proprietary models remain a consideration, with open source solutions typically lagging 6-12 months behind commercial offerings. Complex reasoning tasks, creative writing, and multi-modal capabilities show the largest performance gaps, though these differences diminish for many enterprise applications. Organizations must carefully evaluate whether the absolute best performance justifies the premium pricing and reduced control of proprietary services, with many finding that 85% performance at 30% cost represents optimal value.
Operational complexity and maintenance burden require honest assessment, as self-hosted deployments demand technical expertise and ongoing attention. Hardware failures, software updates, and security patches require dedicated resources, with 24/7 availability demanding redundancy and monitoring infrastructure. However, organizations with existing MLOps capabilities find the additional overhead manageable, while those without may benefit from managed open source solutions that provide compromise between control and convenience. The long-term benefits of building internal AI capabilities often outweigh short-term operational challenges.
Community support and ecosystem maturity have reached levels comparable to commercial offerings, with active development communities providing rapid bug fixes and feature enhancements. Documentation quality has improved dramatically, with comprehensive guides, tutorials, and example implementations available for all major models. The collaborative nature of open source development ensures diverse perspectives and use cases are considered, resulting in robust solutions that address real-world requirements. Commercial support options from companies like Hugging Face provide enterprise-grade SLAs for organizations requiring guaranteed response times.
Cost-Effective Access Through API Services
Organizations seeking the benefits of GPT open source solutions without infrastructure management increasingly turn to specialized API services that provide managed access to open source models. These services eliminate operational overhead while maintaining cost advantages over proprietary alternatives, with providers like laozhang.ai offering access to the entire ecosystem of open source models at 70% lower costs than direct API services. This approach provides ideal middle ground for organizations wanting to experiment with different models before committing to self-hosted infrastructure.
The unified API gateway approach simplifies multi-model deployments, allowing organizations to route requests to different models based on task requirements and cost constraints. Simple queries might utilize efficient models like GPT-J-6B, while complex analytical tasks leverage GPT-OSS-120B, all through a single interface. This flexibility enables cost optimization without application changes, with intelligent routing reducing overall costs by 40-50% compared to using premium models for all requests. Load balancing across multiple models ensures consistent performance during peak usage periods.
Migration strategies from proprietary services to cost-effective alternatives follow established patterns that minimize disruption while maximizing savings. Organizations typically begin by routing non-critical workloads to open source models, validating performance before expanding adoption. A/B testing frameworks enable gradual migration with continuous performance monitoring, ensuring service quality remains consistent. The compatibility of services like laozhang.ai with OpenAI’s API format means existing codebases require minimal modification, reducing migration risk and accelerating time to savings.
Free trial offerings and credit systems enable risk-free evaluation of open source models, with providers offering sufficient credits to process millions of tokens before requiring payment. This approach allows thorough testing across diverse use cases, building confidence in model capabilities before committing resources. The referral programs and volume discounts available through services like laozhang.ai further reduce costs, with some organizations achieving effective rates below $0.0001 per token for high-volume deployments. These economics fundamentally change the calculus of AI adoption, making advanced capabilities accessible to organizations previously priced out of the market.
Future of Open Source AI: Trends and Predictions
The trajectory of GPT open source solutions points toward rapid convergence with proprietary model capabilities, with performance gaps narrowing from the current 15-30% to under 10% by late 2026. Continued investments from tech giants like Meta, Google, and even OpenAI in open source initiatives reflect recognition that ecosystem development benefits all participants. The emergence of specialized models optimized for specific domains like healthcare, legal, and scientific research will provide superior performance for targeted applications while maintaining the flexibility and control advantages of open source deployment.
Architectural innovations in efficiency and scalability promise to dramatically reduce the computational requirements for deploying large language models. Techniques like mixture-of-experts, sparse attention, and dynamic routing are reducing inference costs by orders of magnitude while maintaining or improving performance. The development of specialized hardware accelerators optimized for transformer architectures will further reduce deployment costs, making GPT open source solutions viable for edge computing and mobile applications previously impossible with current technology.
Community-driven development continues to accelerate, with collaborative efforts producing innovations that surpass individual corporate research labs. The success of initiatives like BigScience’s BLOOM and EleutherAI’s GPT-NeoX demonstrates the power of distributed development, with thousands of contributors worldwide advancing the state of the art. The establishment of open source AI foundations with sustainable funding models ensures continued development independent of corporate priorities, protecting the ecosystem from proprietary capture while fostering innovation that benefits all stakeholders.