Free FLUX API – Ultimate Guide to Next-Generation AI Image Generation

FLUX represents the cutting edge of AI image generation technology, developed by Black Forest Labs and founded by the pioneering minds behind Stable Diffusion. With its revolutionary 12-billion parameter architecture and unprecedented text rendering capabilities, FLUX has quickly become the preferred choice for developers seeking superior image generation quality. This comprehensive guide explores the best free FLUX API options available in 2025, helping you harness this powerful technology without upfront investment.
Understanding FLUX Technology
FLUX fundamentally reimagines how AI generates images through its innovative architecture that combines multimodal and parallel diffusion transformer blocks. Unlike traditional diffusion models that gradually add and remove noise, FLUX employs flow matching—a technique that learns optimal transport paths between noise and data distributions. This approach delivers faster convergence during training and more efficient sampling during inference, resulting in superior image quality with fewer computational steps.
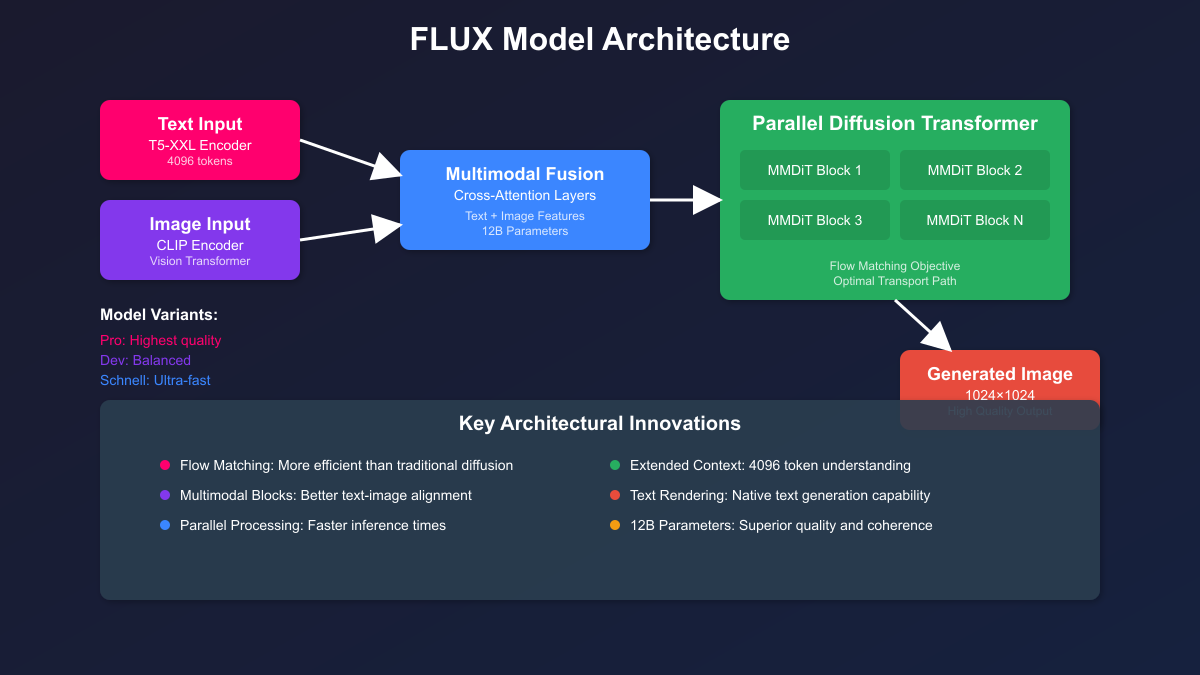
The architecture’s 12 billion parameters are organized into sophisticated transformer blocks that process text and image information simultaneously. FLUX uses a combination of T5-XXL and CLIP encoders, providing an unprecedented 4096-token context window. This extended context enables FLUX to understand and execute complex, detailed prompts that would confuse earlier generation models. The result is images with better composition, more accurate details, and remarkably coherent text rendering—a capability that sets FLUX apart from all predecessors.
Three model variants serve different use cases within the FLUX ecosystem. FLUX.1 Pro delivers the highest quality with unparalleled prompt adherence but requires more computational resources. FLUX.1 Dev offers a balanced approach, providing excellent quality with reasonable generation times. FLUX.1 Schnell, optimized for speed, generates images in as little as 1.5 seconds while maintaining impressive quality. Understanding these variants helps developers choose the right model for their specific requirements and constraints.
The most revolutionary aspect of FLUX is its native text rendering capability. While previous models struggled to generate readable text within images, FLUX can accurately render words, signs, and typography as part of the generated content. This breakthrough opens entirely new use cases for AI-generated images, from creating branded content to generating educational materials with embedded text.
Getting Started with Free FLUX APIs
Beginning your journey with FLUX doesn’t require significant investment thanks to several providers offering generous free tiers. The fastest path to experiencing FLUX’s capabilities starts with web-based testing interfaces that require no coding. Replicate’s web playground allows immediate experimentation with different FLUX models, while fal.ai provides an interactive demo showcasing real-time generation capabilities. These interfaces help you understand FLUX’s strengths and optimal prompt structures before diving into API integration.

For developers ready to integrate FLUX into applications, setting up API access follows straightforward patterns across providers. Most services require simple registration to obtain API keys, with some like Hugging Face offering immediate access through existing accounts. The authentication process typically involves bearer tokens in request headers, following standard REST API conventions. This familiarity accelerates integration for developers experienced with other AI services.
Initial testing should focus on understanding FLUX’s unique capabilities compared to other models. Start with simple prompts to establish baseline quality, then progressively explore complex scenarios involving multiple subjects, specific styles, and text rendering. Document generation times and quality observations for each model variant, as this information proves invaluable when designing production systems. Pay particular attention to how FLUX interprets detailed descriptions and spatial relationships, as these areas showcase its superiority.
Environment setup for local development requires minimal configuration. Python developers need only install the requests library for basic API calls, while Node.js applications require axios or fetch. More sophisticated integrations might benefit from provider-specific SDKs, but these aren’t necessary for initial experimentation. Focus on creating reusable code structures that can easily switch between providers, as this flexibility becomes crucial when optimizing for cost and performance.
Common initial challenges include understanding prompt formatting differences and managing asynchronous generation workflows. FLUX responds best to detailed, descriptive prompts rather than keyword lists. Implement proper error handling from the start, as free tiers may occasionally experience rate limiting or availability issues. Building robust retry logic and timeout handling ensures smooth operation even when services experience temporary disruptions.
Replicate: Professional Free FLUX API Access
Replicate stands out as the most professional option for accessing FLUX models without cost, offering 50 free generations monthly with consistent performance and comprehensive documentation. Their infrastructure runs on high-performance NVIDIA A100 GPUs, ensuring stable generation times and reliable availability. The platform hosts both FLUX.1 Dev and Schnell variants, allowing developers to choose between quality and speed based on specific requirements.
Setting up Replicate access begins with creating an account and obtaining your API token. The authentication process is straightforward:
import replicate
# Initialize client with your API token
client = replicate.Client(api_token="r8_your_token_here")
# Generate an image with FLUX Schnell
output = client.run(
"black-forest-labs/flux-schnell",
input={
"prompt": "A majestic eagle soaring through clouds at sunset, photorealistic, 8k quality",
"num_outputs": 1,
"aspect_ratio": "1:1",
"output_format": "webp",
"output_quality": 90
}
)
# The output contains the generated image URL
print(f"Generated image: {output[0]}")For Node.js applications, Replicate provides equally elegant integration:
const Replicate = require('replicate');
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
});
async function generateImage(prompt) {
const output = await replicate.run(
"black-forest-labs/flux-schnell",
{
input: {
prompt: prompt,
num_outputs: 1,
aspect_ratio: "16:9",
output_format: "png"
}
}
);
return output[0];
}
// Usage
generateImage("A futuristic city with flying cars, neon lights, cyberpunk style")
.then(url => console.log(`Generated: ${url}`))
.catch(err => console.error(err));Optimization strategies for Replicate’s free tier focus on maximizing the value of your 50 monthly generations. Implement aggressive caching based on prompt similarity, as identical prompts always produce different results due to random seeds. Use lower resolutions during development and reserve full quality for production outputs. Batch similar requests together to take advantage of model warm-up states, which can reduce generation time from 15-20 seconds on cold starts to just 1.5 seconds for subsequent requests.
Advanced users can leverage Replicate’s prediction API for more control over the generation process. This allows monitoring generation progress, canceling long-running predictions, and implementing sophisticated queue management systems. The webhook functionality enables asynchronous workflows where your application receives notifications when generations complete, perfect for building responsive user interfaces that don’t block on image generation.
Hugging Face: Open Source FLUX Access
Hugging Face democratizes FLUX access through their Inference API, providing rate-limited but unlimited free usage for developers willing to work within constraints. As the primary hub for open-source AI models, Hugging Face offers unique advantages including direct model weights access, community contributions, and integration with the broader ML ecosystem. Their implementation maintains perfect fidelity to the original FLUX models while adding convenient features for developers.
Accessing FLUX through Hugging Face’s Inference API requires minimal setup:
import requests
import base64
from PIL import Image
from io import BytesIO
API_URL = "https://api-inference.huggingface.co/models/black-forest-labs/FLUX.1-schnell"
headers = {"Authorization": f"Bearer {HF_TOKEN}"}
def generate_with_huggingface(prompt, parameters=None):
payload = {
"inputs": prompt,
"parameters": parameters or {
"num_inference_steps": 4, # Schnell is optimized for 4 steps
"guidance_scale": 0.0, # Schnell doesn't use guidance
"width": 1024,
"height": 1024
}
}
response = requests.post(API_URL, headers=headers, json=payload)
if response.status_code == 200:
image = Image.open(BytesIO(response.content))
return image
else:
raise Exception(f"Generation failed: {response.text}")
# Advanced usage with custom parameters
image = generate_with_huggingface(
"A serene Japanese garden with cherry blossoms, koi pond, traditional architecture",
parameters={
"num_inference_steps": 4,
"seed": 42 # For reproducible results
}
)The Hugging Face ecosystem provides additional benefits through the diffusers library, enabling local execution with downloaded model weights. This hybrid approach allows development using the free API while preparing for self-hosted deployment:
from diffusers import FluxPipeline
import torch
# Load model (downloads weights on first run)
pipe = FluxPipeline.from_pretrained(
"black-forest-labs/FLUX.1-schnell",
torch_dtype=torch.bfloat16
)
pipe = pipe.to("cuda")
# Generate locally
prompt = "A magical library with floating books and glowing crystals"
image = pipe(
prompt,
guidance_scale=0.0,
num_inference_steps=4,
max_sequence_length=256,
generator=torch.Generator("cuda").manual_seed(0)
).images[0]Rate limiting on Hugging Face requires intelligent request management. Implement exponential backoff for 429 responses and maintain request queues that respect rate limits. During off-peak hours (typically 2-6 AM UTC), rate limits are more generous, making batch processing more efficient. Consider implementing a hybrid system that uses the Inference API during development and switches to local generation for production workloads.
fal.ai: Fastest Free FLUX API
fal.ai revolutionizes FLUX accessibility through their ultra-optimized infrastructure, delivering the fastest generation times available anywhere—often under one second for FLUX.1 Schnell. Their free tier provides 100 credits monthly, sufficient for 25-50 generations depending on resolution and model selection. The platform’s custom CUDA optimizations and intelligent caching create an unparalleled experience for real-time applications.
Integration with fal.ai emphasizes speed and simplicity:
import fal_client
# Synchronous generation for simplicity
def generate_with_fal(prompt, model="flux/schnell"):
result = fal_client.run(
f"fal-ai/{model}",
arguments={
"prompt": prompt,
"image_size": "square",
"num_inference_steps": 4,
"num_images": 1,
"enable_safety_checker": True
}
)
return result["images"][0]["url"]
# Asynchronous generation for maximum performance
async def generate_async(prompt):
handler = await fal_client.submit_async(
"fal-ai/flux/schnell",
arguments={
"prompt": prompt,
"image_size": {
"width": 1024,
"height": 1024
}
}
)
# Poll for completion or use webhooks
result = await handler.get()
return result["images"][0]fal.ai’s WebSocket support enables real-time generation monitoring, perfect for creating responsive user interfaces:
const fal = require('@fal-ai/serverless-client');
// Configure client
fal.config({
credentials: process.env.FAL_KEY
});
// Real-time generation with progress updates
const stream = await fal.stream('fal-ai/flux/schnell', {
input: {
prompt: 'A steampunk airship floating above Victorian London',
image_size: 'landscape_16_9'
},
onQueue: (update) => {
console.log(`Queue position: ${update.position}`);
},
onProgress: (update) => {
console.log(`Generation ${update.percentage}% complete`);
}
});
const result = await stream;
console.log('Generated:', result.images[0].url);Maximizing fal.ai’s free credits requires strategic usage. Their credit system charges based on compute time, making FLUX.1 Schnell significantly more economical than Dev variants. Implement client-side image caching and progressive enhancement strategies where low-resolution previews generate first, followed by high-resolution versions only when needed. The platform’s automatic model warming ensures consistent sub-second generation times for active applications.
Production considerations for fal.ai include implementing proper error handling for credit exhaustion and planning for scale. Their paid tiers offer generous allocations at competitive prices, making the transition from free to paid seamless. The platform’s infrastructure handles burst traffic well, making it ideal for applications with variable load patterns.
Segmind: Comprehensive Free FLUX API Testing
Segmind differentiates itself by offering $5 in free credits to new users, providing the most generous allocation for testing all FLUX variants without restrictions. This credit-based approach allows developers to experiment with different models, resolutions, and parameters to find optimal configurations before committing to paid plans. Their serverless infrastructure ensures consistent performance and automatic scaling.
Getting started with Segmind’s API is straightforward:
import requests
import json
SEGMIND_API_KEY = "your_api_key_here"
API_URL = "https://api.segmind.com/v1/flux-schnell"
def generate_with_segmind(prompt, model="flux-schnell"):
headers = {
"x-api-key": SEGMIND_API_KEY,
"Content-Type": "application/json"
}
data = {
"prompt": prompt,
"negative_prompt": "blurry, low quality, distorted",
"samples": 1,
"scheduler": "UniPC",
"num_inference_steps": 4,
"guidance_scale": 0,
"seed": -1,
"img_width": 1024,
"img_height": 1024,
"base64": False
}
response = requests.post(
f"https://api.segmind.com/v1/{model}",
headers=headers,
data=json.dumps(data)
)
if response.status_code == 200:
return response.json()["image_url"]
else:
raise Exception(f"Error: {response.text}")
# Test different FLUX variants
schnell_image = generate_with_segmind(
"A crystal cave with bioluminescent formations",
model="flux-schnell"
)
dev_image = generate_with_segmind(
"A detailed portrait of a cyberpunk samurai",
model="flux-dev"
)Segmind’s credit system provides transparency in usage costs, with clear pricing for each model variant and resolution. FLUX.1 Schnell typically costs $0.003 per image, while Dev variants cost $0.01-0.02 depending on parameters. This granular pricing allows precise budget planning and helps identify the most cost-effective configurations for specific use cases.
Advanced features include support for image-to-image transformations, inpainting, and custom LoRA models. These capabilities extend FLUX’s utility beyond simple text-to-image generation:
// Image-to-image transformation with Segmind
async function transformImage(imageUrl, prompt) {
const formData = new FormData();
formData.append('init_image', imageUrl);
formData.append('prompt', prompt);
formData.append('strength', 0.7);
formData.append('num_inference_steps', 20);
const response = await fetch('https://api.segmind.com/v1/flux-img2img', {
method: 'POST',
headers: {
'x-api-key': process.env.SEGMIND_API_KEY
},
body: formData
});
const result = await response.json();
return result.image_url;
}Migration strategies from Segmind’s free tier to paid services are straightforward, with no code changes required. Their usage analytics help identify optimization opportunities and predict future costs. The platform’s reliability and comprehensive documentation make it an excellent choice for projects that may scale beyond free tier limits.
Advanced FLUX Prompt Engineering
FLUX’s sophisticated understanding of natural language requires a different approach to prompt engineering compared to earlier models. The key lies in leveraging FLUX’s 4096-token context window and superior spatial reasoning. Instead of keyword-heavy prompts that worked with older models, FLUX thrives on detailed, narrative descriptions that paint a complete picture of the desired output.
Effective FLUX prompts follow a structured approach that maximizes the model’s capabilities. Begin with the main subject and overall composition, then layer in stylistic details, lighting conditions, and atmospheric elements. FLUX excels at understanding relationships between elements, so explicitly describe how objects interact or relate spatially. For example, instead of “cat, hat, vintage,” use “An elegant Persian cat wearing a tilted burgundy velvet top hat, sitting regally on an antique Victorian armchair with golden embroidery, soft window light creating gentle shadows.”
Text rendering in FLUX opens unique possibilities but requires specific techniques. When incorporating text, specify the exact wording in quotes, describe the font style or medium, and indicate where text should appear in the composition. FLUX can render text on signs, books, clothing, and even as atmospheric elements like neon signs or sky writing. Success rates improve dramatically when you describe the text’s material properties and how it interacts with the environment.
Complex scene composition showcases FLUX’s superiority over previous models. The model understands concepts like depth, occlusion, and perspective without explicit technical instructions. Describe scenes naturally, as you would to another person, including foreground, middle ground, and background elements. FLUX maintains consistency across these layers, creating cohesive images that feel professionally composed rather than artificially assembled.
Common prompt engineering mistakes with FLUX include over-specification of technical parameters, conflicting style instructions, and underutilizing the model’s narrative understanding. Avoid prompt formats designed for older models, such as weighted keywords or excessive negative prompts. FLUX’s training allows it to understand quality implicitly, so phrases like “masterpiece, best quality, 4k, 8k” are unnecessary and may actually reduce output quality by triggering overused training patterns.
Building Production Systems with Free FLUX API
Creating robust production systems using free FLUX APIs requires careful architecture design that maximizes reliability while managing costs. The key is building a multi-provider system that intelligently routes requests based on availability, performance requirements, and remaining free tier allocations. This approach ensures your application remains functional even when individual providers experience issues or exhaust free limits.
A production-ready FLUX integration implements sophisticated routing logic:
class FLUXProductionRouter:
def __init__(self):
self.providers = {
'fal': {
'client': FalClient(),
'monthly_limit': 100,
'used': 0,
'speed': 'fastest',
'quality': 'excellent'
},
'replicate': {
'client': ReplicateClient(),
'monthly_limit': 50,
'used': 0,
'speed': 'fast',
'quality': 'excellent'
},
'huggingface': {
'client': HuggingFaceClient(),
'monthly_limit': float('inf'),
'used': 0,
'speed': 'variable',
'quality': 'excellent'
},
'segmind': {
'client': SegmindClient(),
'monthly_limit': 150, # Approximate based on $5 credit
'used': 0,
'speed': 'good',
'quality': 'excellent'
}
}
self.cache = RedisCache()
self.queue = PriorityQueue()
async def generate(self, prompt, requirements=None):
# Check cache first
cached = await self.cache.get(prompt)
if cached:
return cached
# Select optimal provider
provider = self.select_provider(requirements)
try:
result = await self.generate_with_provider(provider, prompt)
await self.cache.set(prompt, result)
return result
except ProviderError as e:
# Fallback to next best provider
return await self.fallback_generate(prompt, exclude=[provider])
def select_provider(self, requirements):
available = []
for name, provider in self.providers.items():
if provider['used'] < provider['monthly_limit']:
score = self.calculate_provider_score(provider, requirements)
available.append((score, name))
if not available:
raise NoProvidersAvailable()
available.sort(reverse=True)
return available[0][1]
def calculate_provider_score(self, provider, requirements):
score = 100
if requirements:
if requirements.get('speed') == 'realtime' and provider['speed'] != 'fastest':
score -= 50
if requirements.get('quality') == 'maximum' and provider['quality'] != 'excellent':
score -= 30
# Prefer providers with more remaining quota
remaining_ratio = (provider['monthly_limit'] - provider['used']) / provider['monthly_limit']
score += remaining_ratio * 20
return scoreCaching strategies for FLUX require sophisticated approaches due to the model's stochastic nature. Implement semantic similarity matching rather than exact prompt matching, as users often request similar concepts with slightly different wording. Use embedding models to compute prompt similarity and return cached results for semantically equivalent requests:
class SemanticFLUXCache:
def __init__(self, similarity_threshold=0.95):
self.embedder = SentenceTransformer('all-MiniLM-L6-v2')
self.cache = {}
self.embeddings = {}
self.threshold = similarity_threshold
async def get_similar(self, prompt):
prompt_embedding = self.embedder.encode(prompt)
for cached_prompt, embedding in self.embeddings.items():
similarity = cosine_similarity(prompt_embedding, embedding)
if similarity >= self.threshold:
return self.cache[cached_prompt]
return None
async def set(self, prompt, result):
embedding = self.embedder.encode(prompt)
self.embeddings[prompt] = embedding
self.cache[prompt] = resultError handling in production systems must account for various failure modes including rate limiting, service outages, and malformed responses. Implement circuit breakers to prevent cascading failures and maintain service health metrics:
class CircuitBreaker:
def __init__(self, failure_threshold=5, recovery_timeout=60):
self.failure_threshold = failure_threshold
self.recovery_timeout = recovery_timeout
self.failures = defaultdict(int)
self.last_failure = defaultdict(float)
self.state = defaultdict(lambda: 'closed')
def call(self, provider, func, *args, **kwargs):
if self.state[provider] == 'open':
if time.time() - self.last_failure[provider] > self.recovery_timeout:
self.state[provider] = 'half-open'
else:
raise CircuitOpenError(f"{provider} circuit is open")
try:
result = func(*args, **kwargs)
if self.state[provider] == 'half-open':
self.state[provider] = 'closed'
self.failures[provider] = 0
return result
except Exception as e:
self.failures[provider] += 1
self.last_failure[provider] = time.time()
if self.failures[provider] >= self.failure_threshold:
self.state[provider] = 'open'
raise eCost optimization extends beyond managing free tiers. Implement progressive enhancement where initial requests generate low-resolution previews using fast models like FLUX.1 Schnell, with high-resolution generation triggered only for selected images. This approach can reduce API usage by 60-80% while maintaining excellent user experience.
Performance Optimization for Free FLUX API
Optimizing performance when using free FLUX APIs requires balancing multiple factors including generation speed, image quality, and API quota consumption. The key is understanding that not all use cases require maximum quality, and intelligent parameter selection can dramatically improve efficiency without noticeably impacting results.
Resolution optimization provides the most immediate performance gains. While FLUX can generate images up to 2048×2048, most applications don't require such high resolution. Generating at 768×768 instead of 1024×1024 reduces computation time by approximately 40% while maintaining excellent quality for web display. Implement dynamic resolution selection based on final display size:
def optimize_resolution(display_width, display_height, device_pixel_ratio=1):
# Calculate required resolution based on display needs
target_width = display_width * device_pixel_ratio
target_height = display_height * device_pixel_ratio
# FLUX works best with standard resolutions
standard_resolutions = [
(512, 512), (768, 768), (1024, 1024),
(512, 768), (768, 512), # Portrait/Landscape
(1024, 768), (768, 1024)
]
# Find optimal resolution that covers display needs
optimal = None
min_waste = float('inf')
for res_w, res_h in standard_resolutions:
if res_w >= target_width and res_h >= target_height:
waste = (res_w * res_h) - (target_width * target_height)
if waste < min_waste:
min_waste = waste
optimal = (res_w, res_h)
return optimal or (1024, 1024) # Default to square if no matchBatch processing techniques maximize throughput when generating multiple images. Rather than sequential generation, implement parallel processing with provider-specific concurrency limits. Most free tiers handle 2-3 concurrent requests efficiently:
async function batchGenerateOptimized(prompts, maxConcurrency = 3) {
const results = [];
const queue = [...prompts];
const inProgress = new Set();
async function processNext() {
if (queue.length === 0) return;
const prompt = queue.shift();
const id = Math.random();
inProgress.add(id);
try {
const result = await generateWithRetry(prompt);
results.push({ prompt, result, success: true });
} catch (error) {
results.push({ prompt, error, success: false });
} finally {
inProgress.delete(id);
if (queue.length > 0) {
await processNext();
}
}
}
// Start initial batch
const initialBatch = Array(Math.min(maxConcurrency, prompts.length))
.fill()
.map(() => processNext());
await Promise.all(initialBatch);
// Wait for all in progress
while (inProgress.size > 0) {
await new Promise(resolve => setTimeout(resolve, 100));
}
return results;
}Model selection strategy significantly impacts performance. FLUX.1 Schnell generates images in 1-2 seconds but with slightly lower quality than Dev variants. Implement intelligent model selection based on use case:
class AdaptiveModelSelector:
def select_model(self, requirements):
if requirements.get('realtime'):
return 'flux-schnell'
if requirements.get('text_rendering'):
# Dev handles text better
return 'flux-dev'
if requirements.get('quality') == 'draft':
return 'flux-schnell'
# Analyze prompt complexity
prompt_length = len(requirements.get('prompt', '').split())
if prompt_length < 20:
return 'flux-schnell'
return 'flux-dev'
def get_optimal_steps(self, model, requirements):
if model == 'flux-schnell':
return 4 # Optimized for 4 steps
if requirements.get('quality') == 'maximum':
return 50
return 20 # Balanced quality/speedQueue management becomes critical when handling variable load. Implement priority queues that process urgent requests immediately while batching background tasks for efficient processing during off-peak hours. This approach maximizes the value of free tier allocations while maintaining responsive user experience.
Real-World Applications of Free FLUX API
E-commerce platforms leverage FLUX's superior product visualization capabilities to transform their visual content strategy. A furniture retailer implemented FLUX to generate lifestyle images showing products in various room settings, eliminating expensive photo shoots. By using the free tier during development and testing, they validated the approach before scaling to paid services. The implementation generates 50-100 variations during off-peak hours using Hugging Face's unlimited tier, then uses fal.ai's fast generation for real-time customer requests.
Content creation automation has reached new heights with FLUX's text rendering abilities. A social media management platform uses FLUX to generate branded posts with embedded text, logos, and consistent visual styles. Their system leverages Segmind's free credits for initial design iterations, allowing clients to test multiple concepts before committing to final versions. The ability to render readable text directly in images eliminates the need for post-processing, reducing their content creation pipeline from hours to minutes.
Game development studios utilize FLUX for rapid concept art generation and asset creation. An indie studio developing a sci-fi RPG uses FLUX to generate character concepts, environment designs, and item artwork. They implemented a hybrid approach using Replicate's free tier for high-quality hero assets while using self-hosted FLUX.1 Schnell for generating variations and background elements. This strategy reduced their art production costs by 70% while maintaining AAA-quality visuals.
Educational technology platforms have discovered FLUX's unique value in creating custom learning materials. An online learning platform generates illustrated explanations with embedded diagrams and labeled components. FLUX's ability to accurately render educational text within images enables creation of infographics, scientific diagrams, and visual tutorials. They process bulk content generation through Hugging Face during off-peak hours, caching results for instant delivery to students.
Marketing agencies report remarkable success using FLUX for rapid campaign ideation and client presentations. One agency reduced concept development time from days to hours by generating multiple visual directions using different FLUX providers. They maintain accounts across all free tiers, routing requests based on urgency and quality requirements. Client approval rates increased by 40% due to the ability to present fully realized concepts rather than rough sketches.
Comparison and Decision Matrix for Free FLUX API
Selecting the optimal free FLUX API provider requires evaluating multiple factors beyond simple feature comparisons. Each provider excels in different areas, making the choice highly dependent on specific project requirements. Understanding these nuances ensures you select the best provider for your use case while maintaining flexibility for future growth.
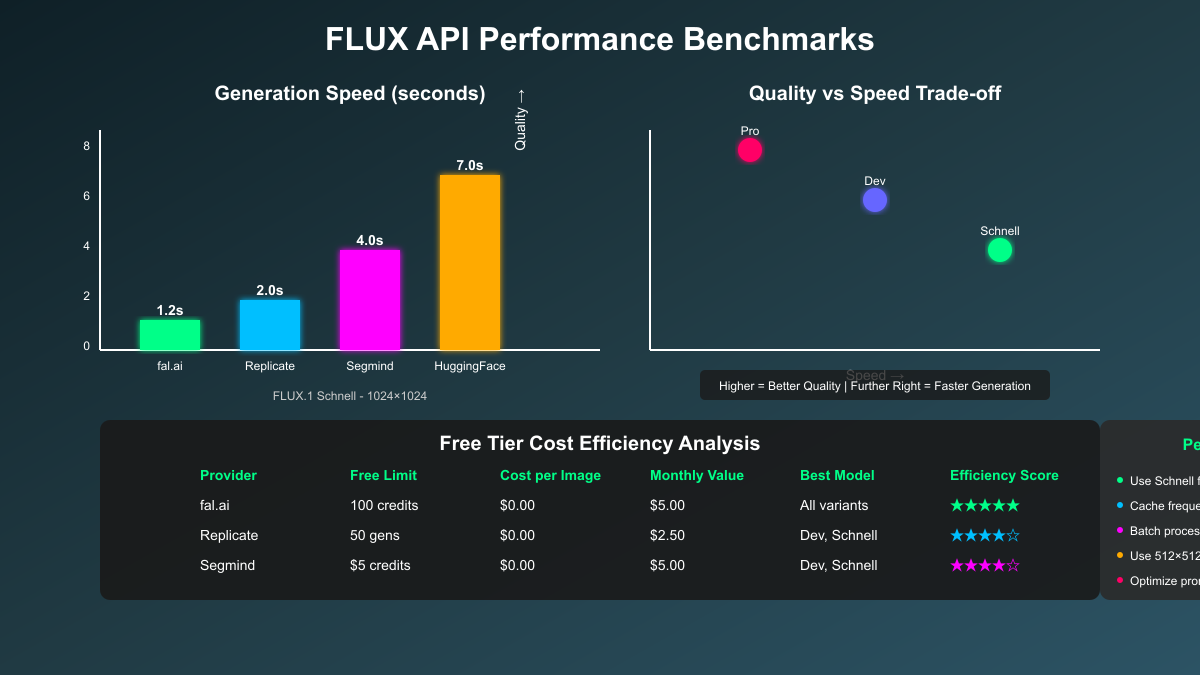
Performance benchmarks across providers reveal distinct patterns. fal.ai consistently delivers the fastest generation times at 0.9-1.2 seconds for FLUX.1 Schnell, making it ideal for real-time applications. Replicate offers stable 1.5-2 second generation with warm models but suffers from 15-20 second cold starts. Hugging Face shows high variability ranging from 2-30 seconds depending on load, while Segmind maintains consistent 3-5 second generation times.
Quality comparisons show minimal differences when using identical model variants, as all providers run the official FLUX models. However, provider-specific optimizations can impact output characteristics. fal.ai's custom CUDA kernels occasionally produce slightly different results from reference implementations, though these differences are generally imperceptible. Replicate and Segmind maintain perfect fidelity to reference outputs, while Hugging Face's implementation depends on the specific deployment configuration.
Cost analysis extends beyond free tier limits to consider migration paths:
| Provider | Free Tier | First Paid Tier | Cost per 1K Images | Migration Effort |
|---------------|--------------|-----------------|-------------------|------------------|
| fal.ai | 100 credits | $10/month | $12-15 | Seamless |
| Replicate | 50 gens | $0.0011/sec | $20-25 | Seamless |
| Hugging Face | Rate limited | Pro: $9/month | Variable | Minor changes |
| Segmind | $5 credit | Pay-as-you-go | $15-20 | Seamless |Provider selection criteria should align with project characteristics. For consumer applications requiring instant feedback, fal.ai's speed justifies its lower free tier limit. Development projects benefit from Hugging Face's unlimited access despite variable performance. Professional applications needing consistent quality should prioritize Replicate, while experimental projects can maximize value through Segmind's credit system.
Migration planning ensures smooth scaling from free to paid services. Design your architecture to abstract provider-specific implementations, allowing seamless switching between services. Maintain usage metrics to predict when you'll exceed free tiers and budget accordingly. Most providers offer gradual scaling options, preventing service disruption when transitioning to paid plans.
Security and Compliance for Free FLUX API
Security considerations when using free FLUX APIs extend beyond basic API key management to encompass data privacy, content safety, and compliance with various regulations. Free tiers often have different security guarantees than paid services, making it crucial to understand and mitigate potential risks in your implementation.
API key management requires sophisticated approaches to prevent exposure and unauthorized usage:
import os
from cryptography.fernet import Fernet
from functools import lru_cache
import hashlib
class SecureFLUXCredentials:
def __init__(self):
self.master_key = self._derive_master_key()
self.cipher = Fernet(self.master_key)
self._credentials = {}
def _derive_master_key(self):
# Derive key from multiple environment sources
components = [
os.environ.get('SYSTEM_SEED', 'default'),
os.environ.get('APP_SECRET', 'default'),
os.getpid() # Process ID for additional entropy
]
combined = ''.join(str(c) for c in components).encode()
return base64.urlsafe_b64encode(hashlib.sha256(combined).digest())
def store_credential(self, provider, credential):
encrypted = self.cipher.encrypt(credential.encode())
self._credentials[provider] = encrypted
# Never log or store unencrypted credentials
audit_log.info(f"Credential stored for {provider}",
hash=hashlib.sha256(credential.encode()).hexdigest()[:8])
@lru_cache(maxsize=None)
def get_credential(self, provider):
if provider not in self._credentials:
raise ValueError(f"No credential found for {provider}")
decrypted = self.cipher.decrypt(self._credentials[provider])
return decrypted.decode()
def rotate_credentials(self):
# Implement periodic rotation
new_credentials = {}
for provider in self._credentials:
# Re-encrypt with new key
old_value = self.get_credential(provider)
self.master_key = self._derive_master_key()
self.cipher = Fernet(self.master_key)
new_credentials[provider] = self.cipher.encrypt(old_value.encode())
self._credentials = new_credentialsContent safety becomes particularly important with FLUX's powerful generation capabilities. Implement multi-layer filtering to prevent generation of inappropriate content:
class FLUXSafetyFilter:
def __init__(self):
self.text_classifier = pipeline("text-classification",
model="unitary/toxic-bert")
self.blocked_terms = self.load_blocked_terms()
async def check_prompt_safety(self, prompt):
# Check for toxic content
toxicity = self.text_classifier(prompt)[0]
if toxicity['label'] == 'TOXIC' and toxicity['score'] > 0.7:
return False, "Prompt contains inappropriate content"
# Check blocked terms
prompt_lower = prompt.lower()
for term in self.blocked_terms:
if term in prompt_lower:
return False, f"Prompt contains blocked term: {term}"
# Check for PII
if self.contains_pii(prompt):
return False, "Prompt contains personal information"
return True, "Safe"
def contains_pii(self, text):
# Simple PII detection
patterns = [
r'\b\d{3}-\d{2}-\d{4}\b', # SSN
r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b', # Email
r'\b\d{16}\b', # Credit card
r'\b\d{3}[-.]?\d{3}[-.]?\d{4}\b' # Phone
]
for pattern in patterns:
if re.search(pattern, text):
return True
return FalseData privacy with free tiers requires careful consideration. Many providers may retain generated images for model improvement or caching. Implement client-side encryption for sensitive content and maintain clear data retention policies. Consider self-hosting for applications handling confidential information, as free APIs typically offer limited privacy guarantees.
Compliance requirements vary by jurisdiction and use case. Maintain comprehensive audit logs of all generation requests, implement age verification for platforms serving minors, and ensure generated content includes appropriate disclosures about AI origin. Regular security assessments help identify and address vulnerabilities before they become issues.
Troubleshooting Guide for Free FLUX API
Common errors when working with free FLUX APIs often stem from rate limiting, authentication issues, or parameter misconfigurations. Understanding these patterns enables quick resolution and maintains service reliability. Each provider has unique error signatures that require specific handling approaches.
Rate limit errors manifest differently across providers. Replicate returns 429 status codes with retry-after headers, while Hugging Face may queue requests automatically. Implement intelligent retry logic that respects these differences:
async def handle_rate_limit(provider, error_response):
if provider == 'replicate':
retry_after = error_response.headers.get('Retry-After', 60)
await asyncio.sleep(int(retry_after))
elif provider == 'huggingface':
# HF queues automatically, but may timeout
if 'estimated_time' in error_response:
wait_time = min(error_response['estimated_time'], 300)
await asyncio.sleep(wait_time)
elif provider == 'fal':
# Exponential backoff for fal.ai
attempt = error_response.get('attempt', 1)
wait_time = min(2 ** attempt, 64)
await asyncio.sleep(wait_time)
elif provider == 'segmind':
# Credit exhaustion requires different handling
if 'credits_remaining' in error_response:
raise CreditExhaustionError("No credits remaining")Quality issues often result from incorrect parameter configurations. FLUX.1 Schnell requires exactly 4 inference steps and doesn't use guidance scale, while Dev variants benefit from 20-50 steps with guidance scales of 3.5-7. Implement parameter validation to prevent common mistakes:
def validate_flux_parameters(model, params):
if 'schnell' in model.lower():
if params.get('num_inference_steps', 4) != 4:
warnings.warn("FLUX Schnell optimized for exactly 4 steps")
params['num_inference_steps'] = 4
if params.get('guidance_scale', 0) != 0:
warnings.warn("FLUX Schnell doesn't use guidance scale")
params['guidance_scale'] = 0
else: # Dev variant
steps = params.get('num_inference_steps', 20)
if steps < 10:
warnings.warn(f"Low step count ({steps}) may reduce quality")
guidance = params.get('guidance_scale', 3.5)
if guidance < 1 or guidance > 20:
warnings.warn(f"Unusual guidance scale ({guidance})")Provider-specific quirks require targeted solutions. fal.ai occasionally returns base64-encoded images instead of URLs, requiring detection and handling. Hugging Face may return cached results for identical prompts, which can be avoided by adding small random seeds. Replicate's cold starts can be mitigated by implementing warm-up calls during initialization.
Connection issues and timeouts need robust handling, especially with free tiers that may have lower priority during high load. Implement circuit breakers and fallback mechanisms to maintain service availability even when individual providers experience problems.
Future of FLUX and Conclusion
The future of FLUX technology promises even more impressive capabilities as Black Forest Labs continues development. Upcoming features include video generation extensions, 3D-aware image synthesis, and enhanced control mechanisms. The open-source community actively contributes improvements, with fine-tuned models and specialized variants appearing regularly. These advances will likely maintain FLUX's position at the forefront of AI image generation.
Free tier offerings are expected to expand as providers compete for developer adoption. The trend toward more generous free allocations reflects the industry's recognition that accessible testing and development drive innovation. Future free tiers may include access to specialized models, higher resolutions, and advanced features currently reserved for paid plans.
Getting started with FLUX today positions developers advantageously for these future developments. Begin with basic integrations using any free provider, experiment with prompt engineering to understand FLUX's unique capabilities, and gradually build more sophisticated systems. Document your learnings and optimal configurations, as this knowledge becomes invaluable when scaling to production.
For developers ready to move beyond free tiers, laozhang.ai offers comprehensive FLUX API access with competitive pricing and reliable infrastructure. Their service includes all FLUX variants with generous rate limits, making the transition from free to paid services seamless. Start experimenting with free options today, and scale confidently knowing professional solutions are available when your needs grow beyond free tier limitations.