AI Image Generation
Read Now
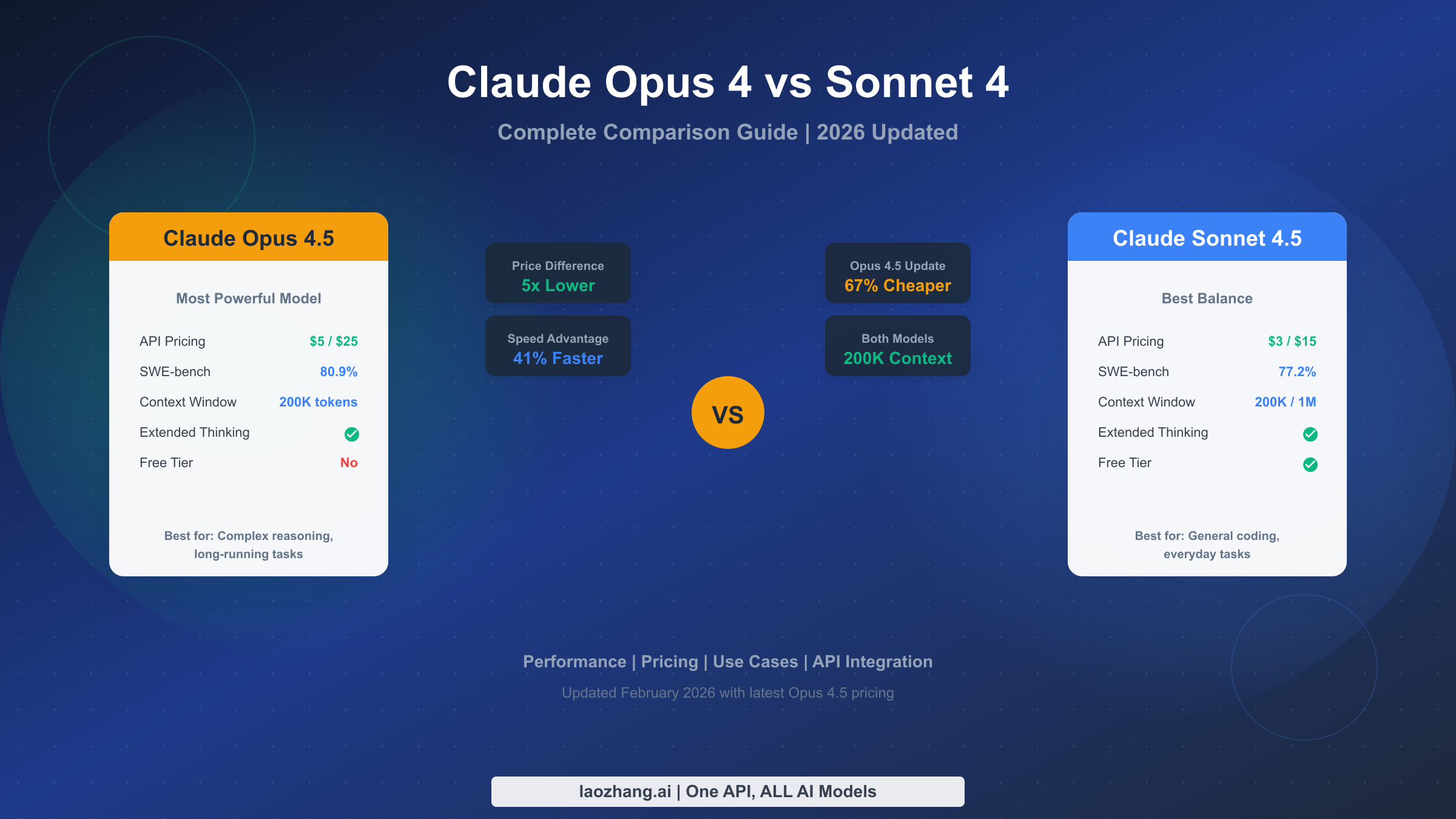
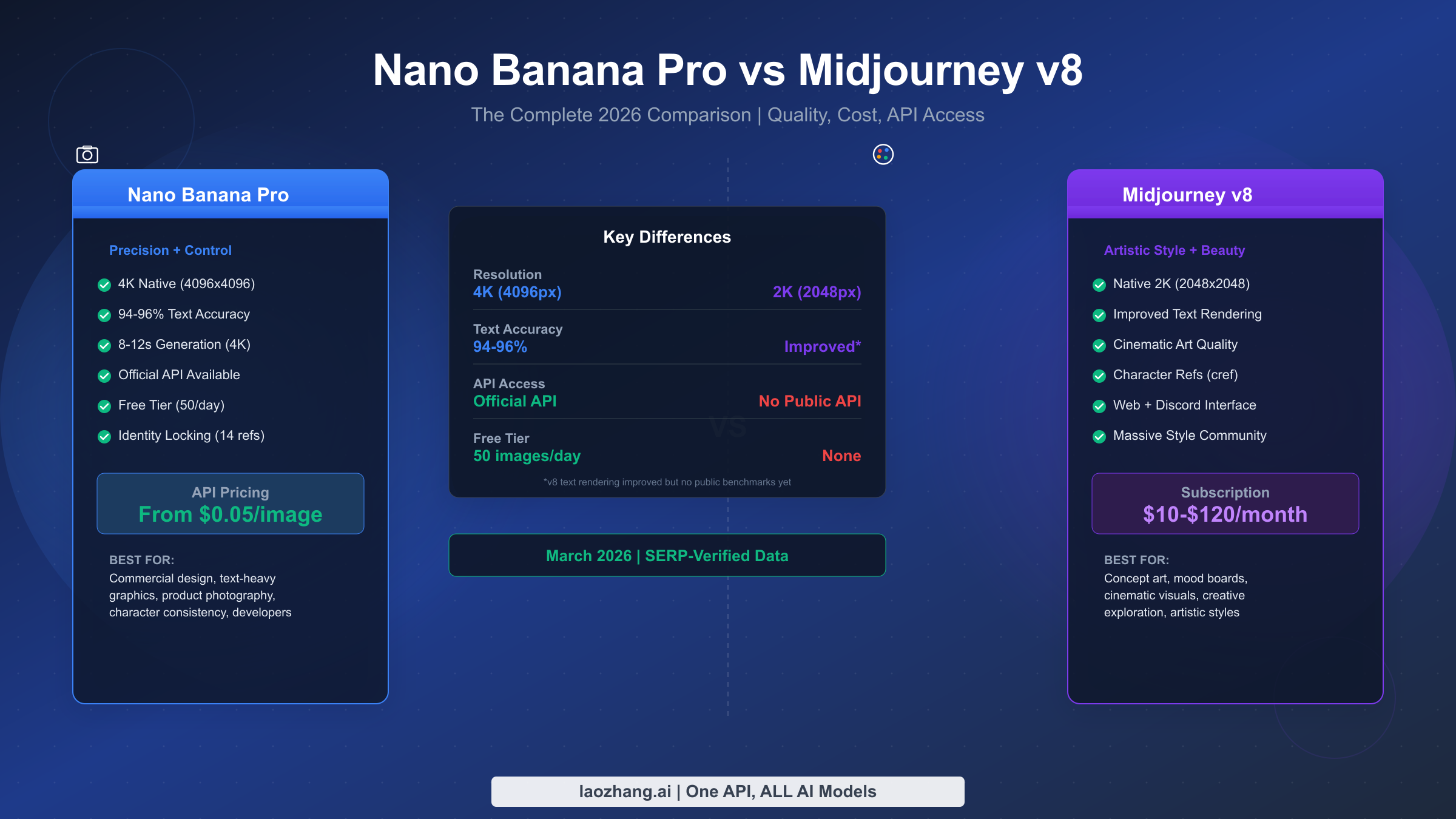
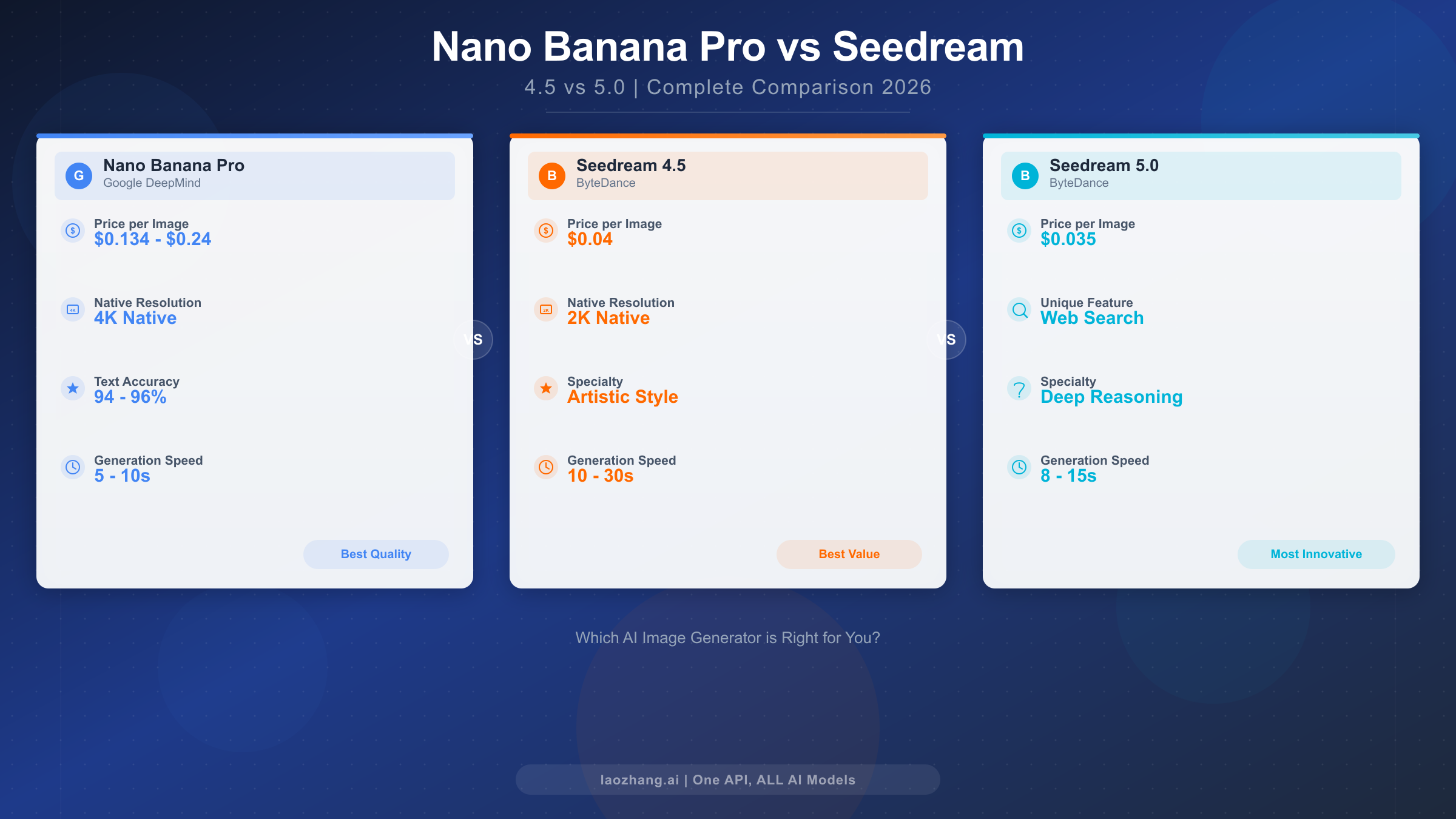
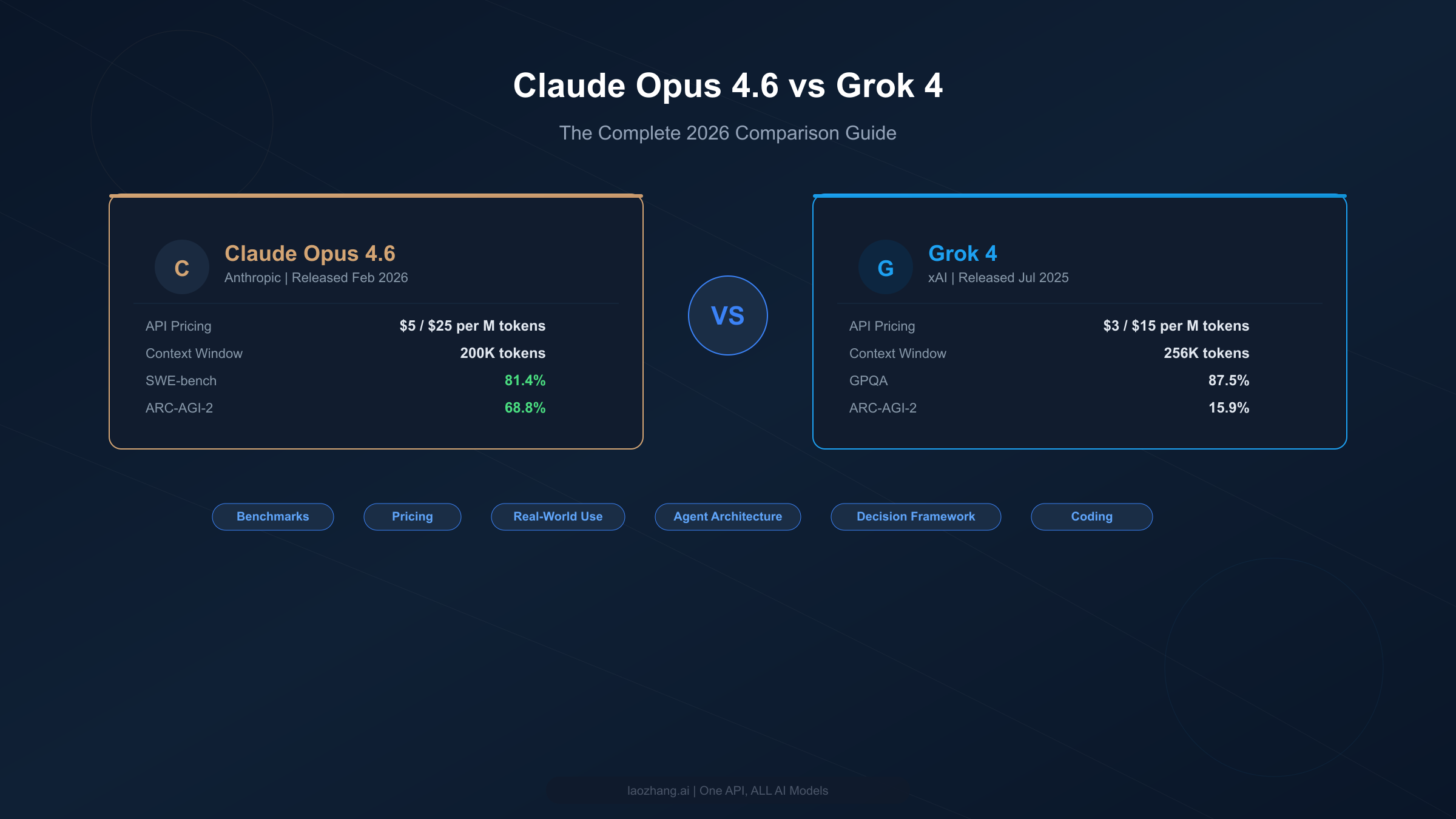
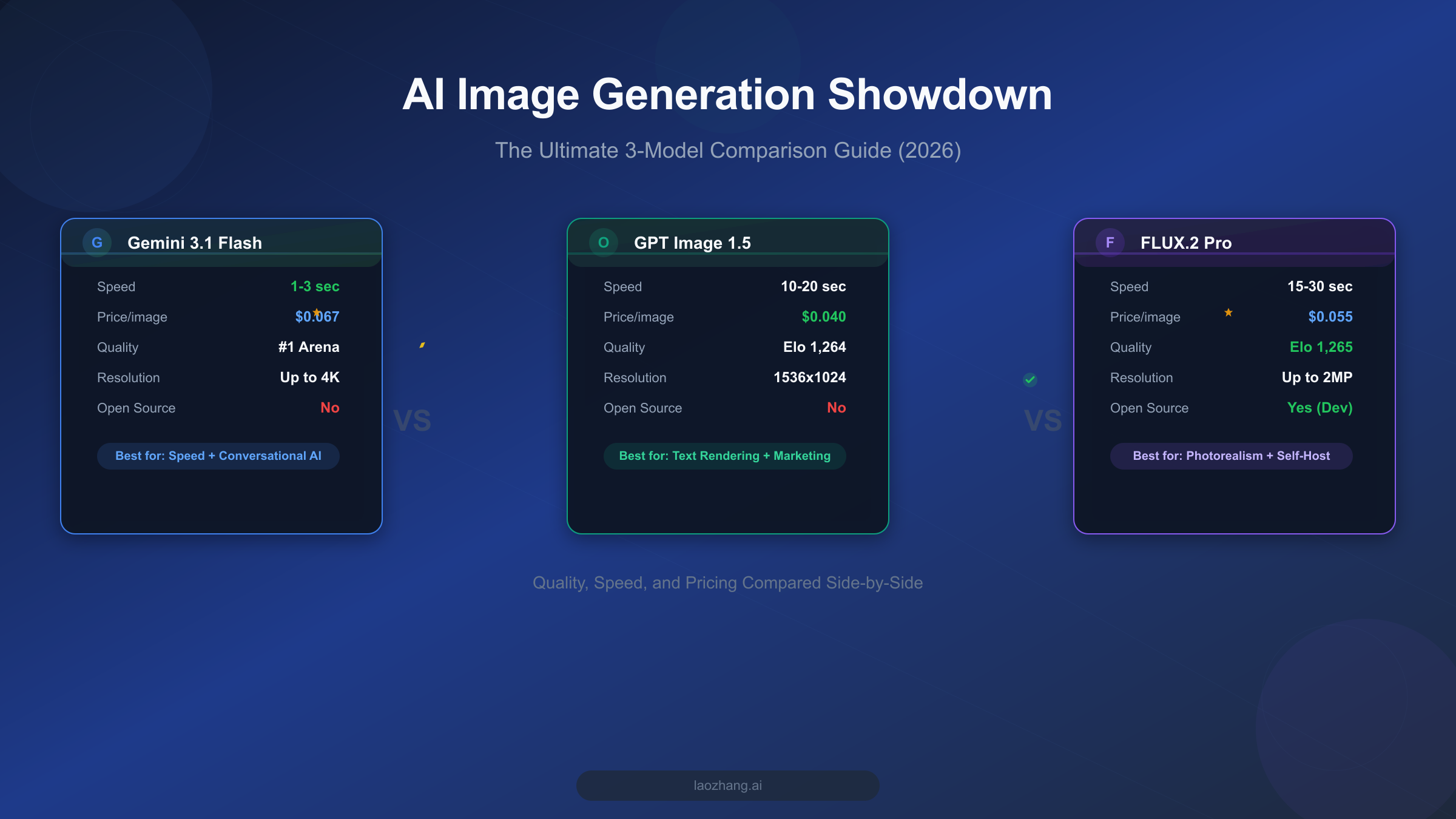
Nano Banana Pro vs Midjourney v8: The Complete 2026 Comparison (Cost, Quality, API)
Nano Banana Pro and Midjourney v8 represent two fundamentally different approaches to AI image generation. This guide compares quality benchmarks (94-96% vs improved text accuracy), real costs at four usage levels ($2.50-$134 vs $10-$120/month), API access (official vs none), and free trial options — all verified with March 2026 data.





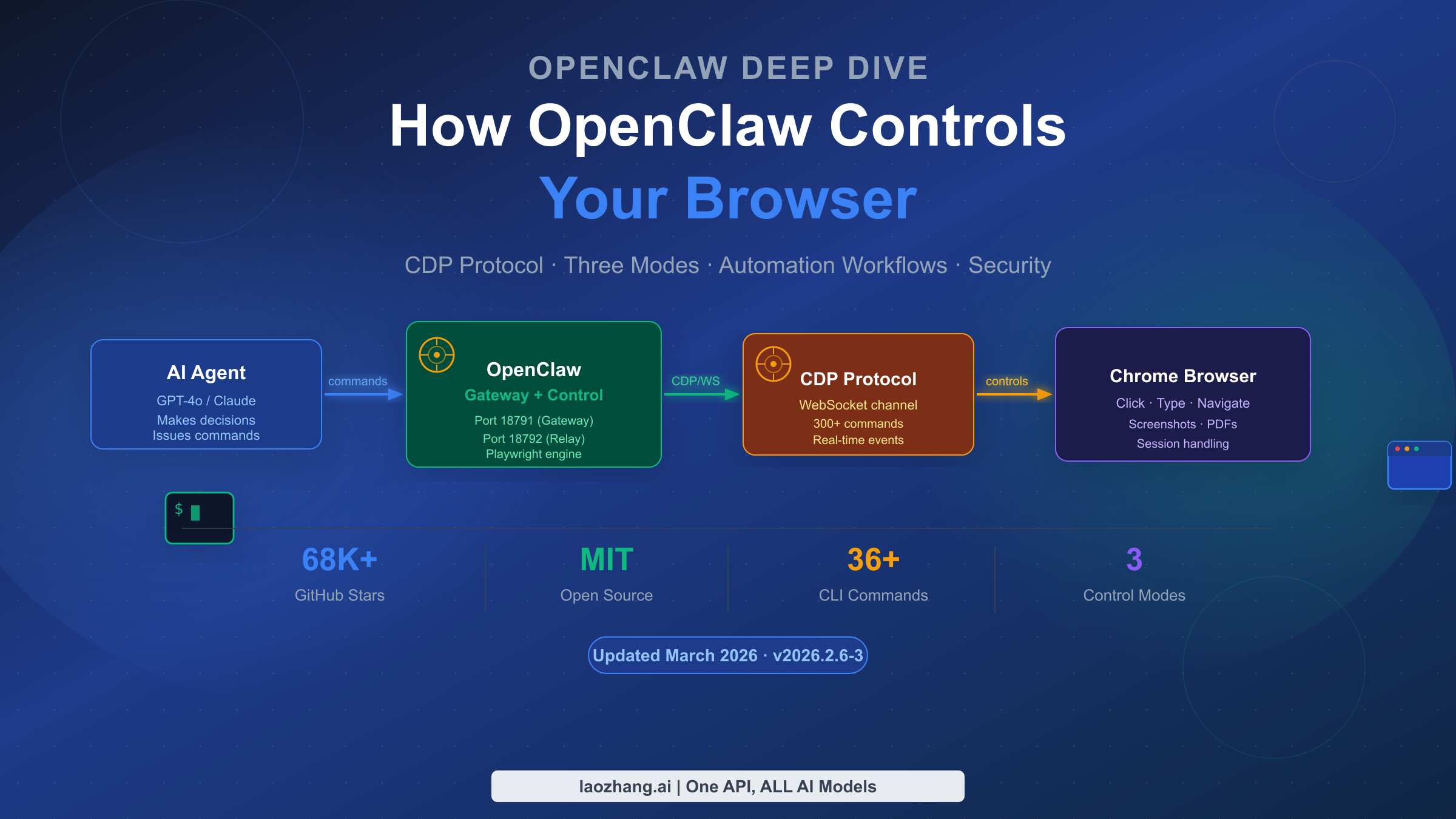
![OpenClaw Doctor and Gateway Restart: Complete Troubleshooting Guide [2026]](/posts/en/openclaw-doctor-gateway-restart/img/cover.png)










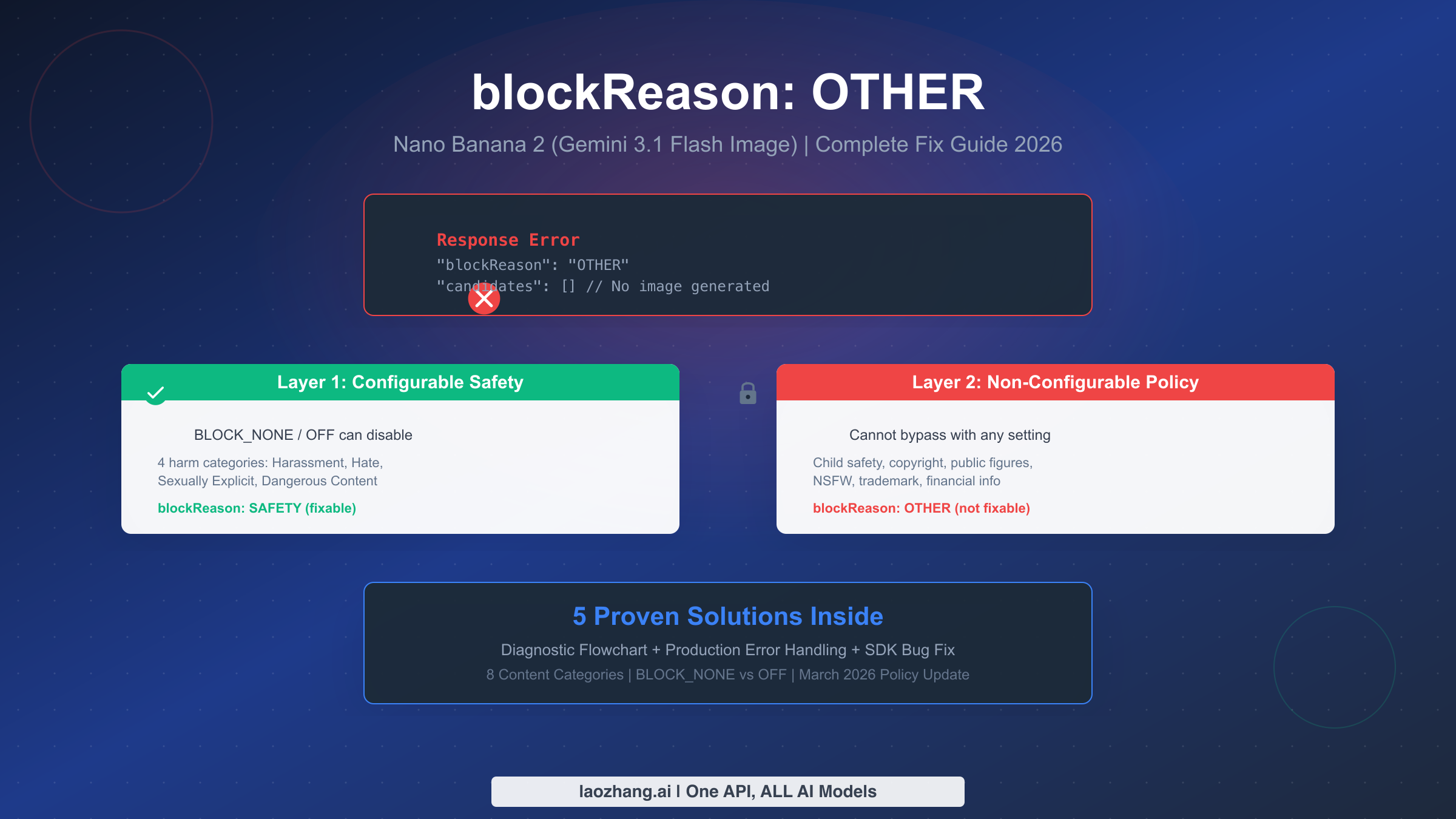
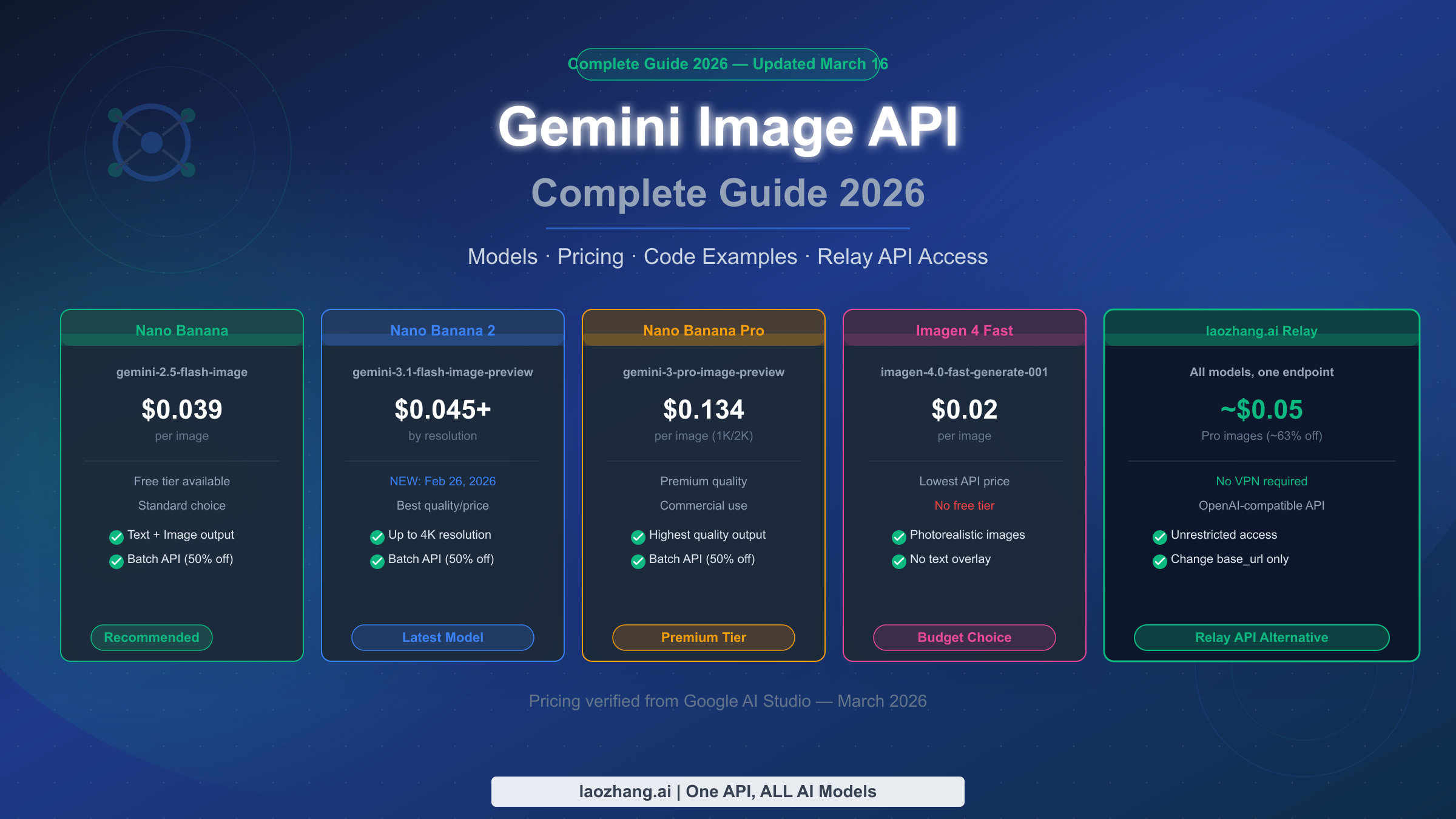
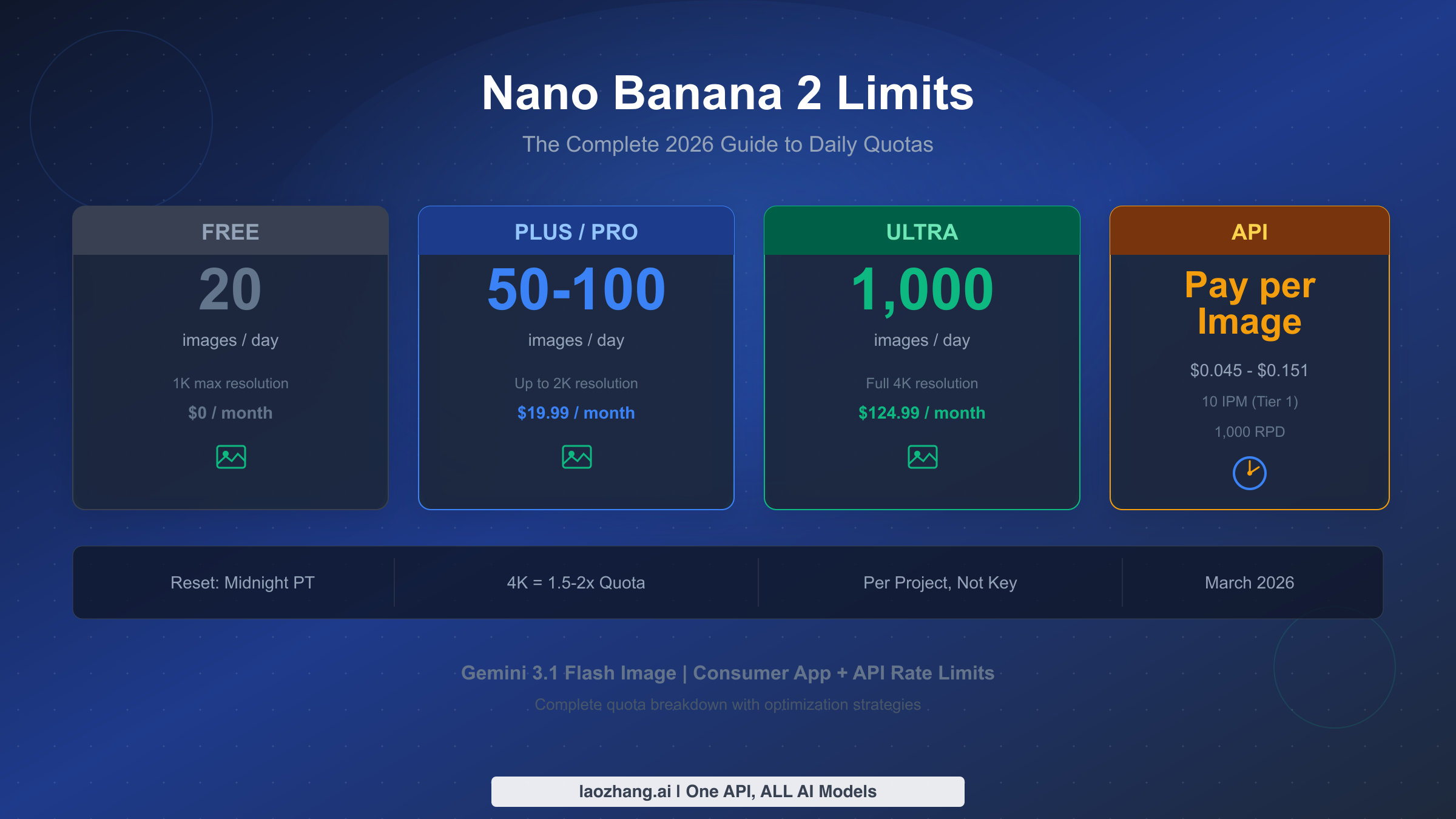
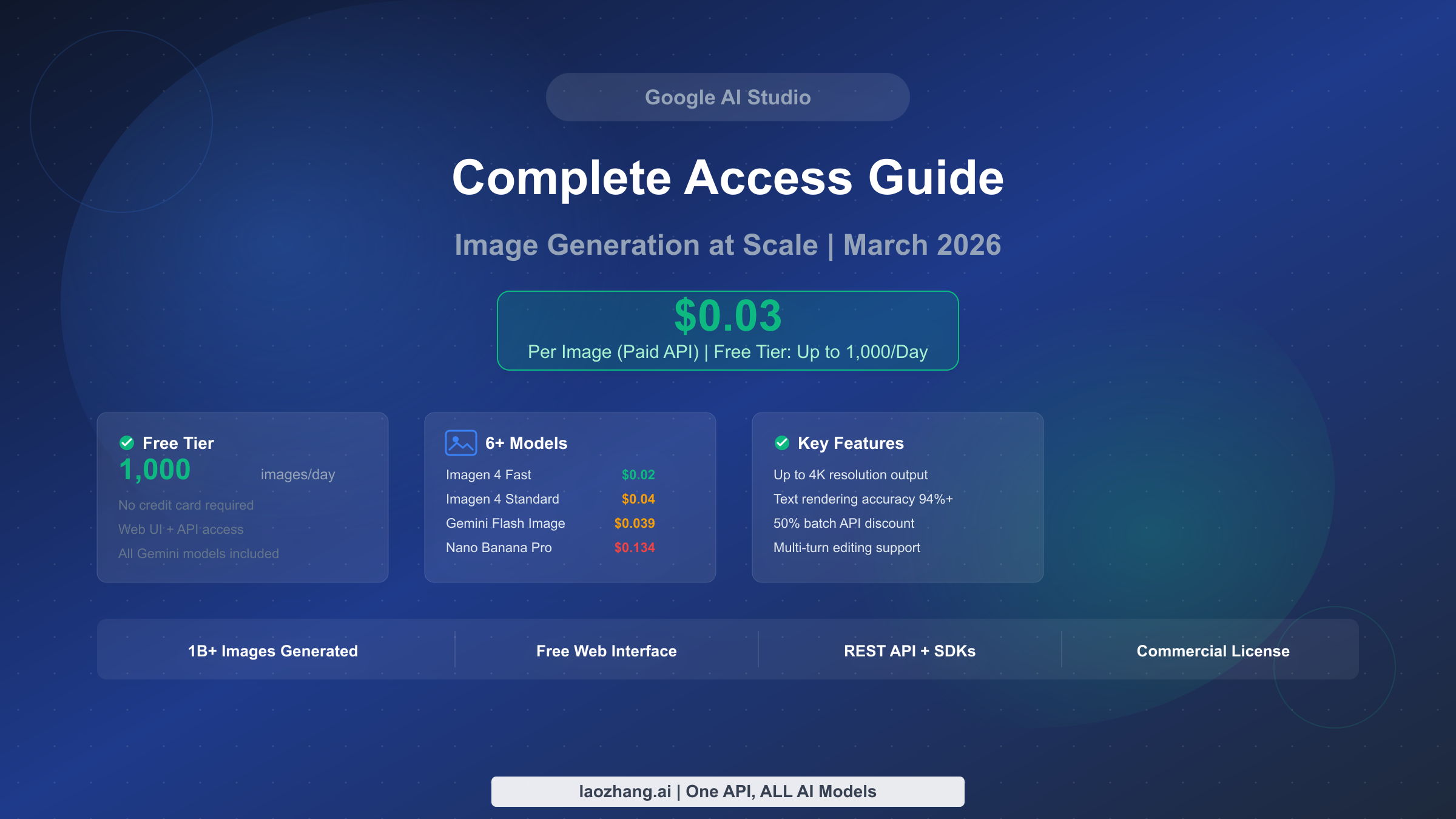
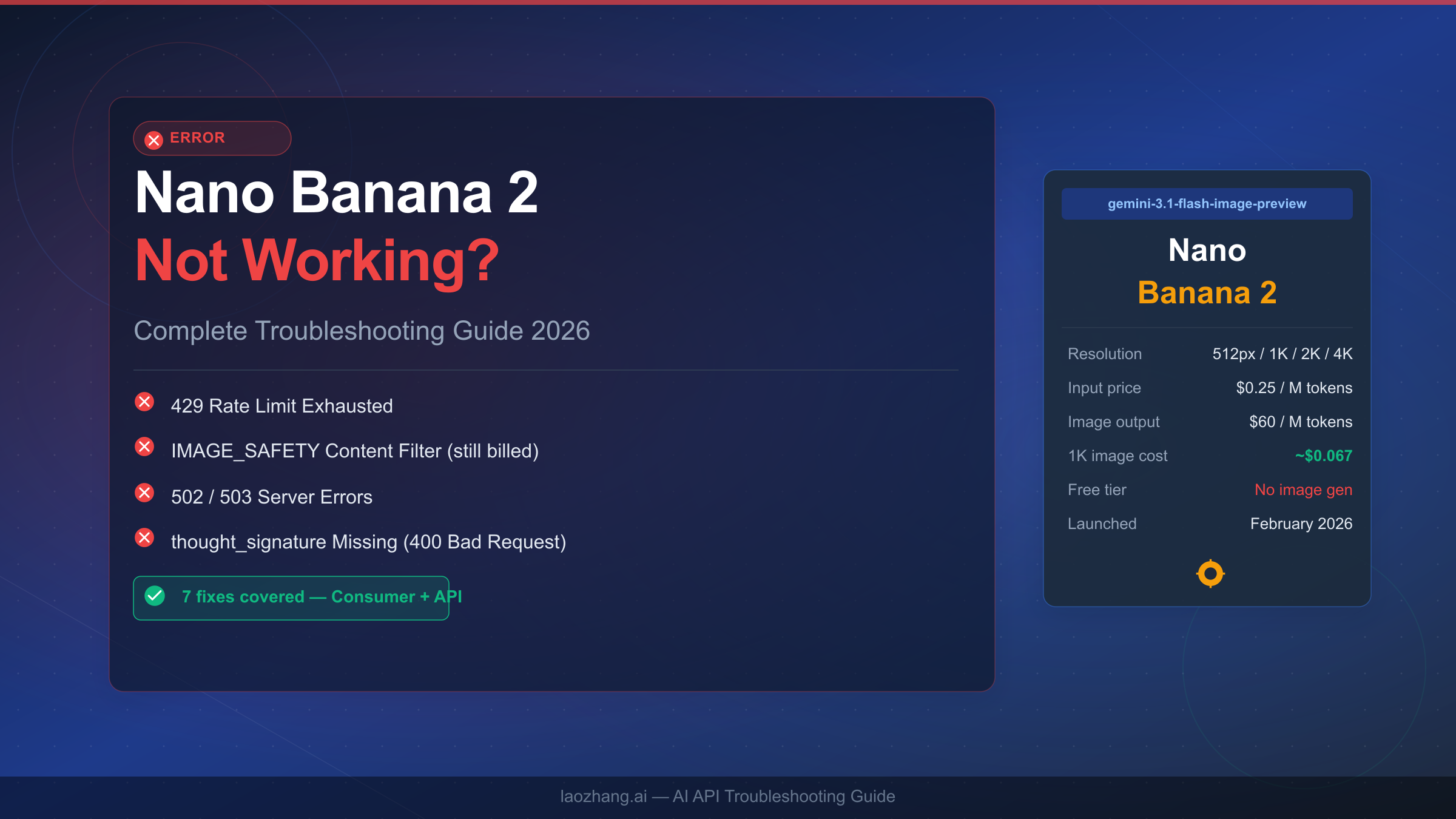
![Nano Banana 2 API Pricing Explained: Official vs Proxy Cost Comparison [2026]](/posts/en/nano-banana-2-api-pricing-guide/img/cover.png)

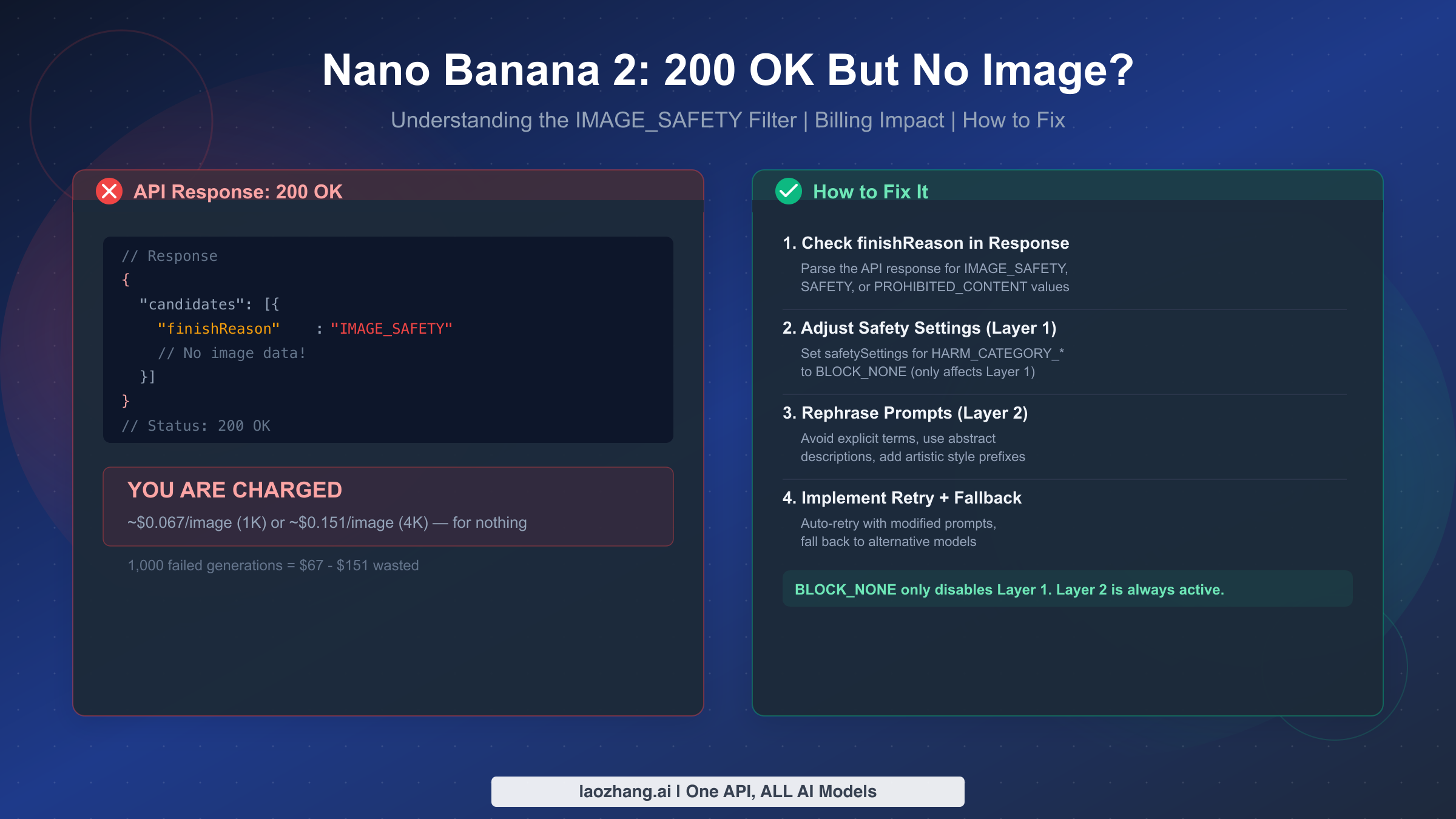




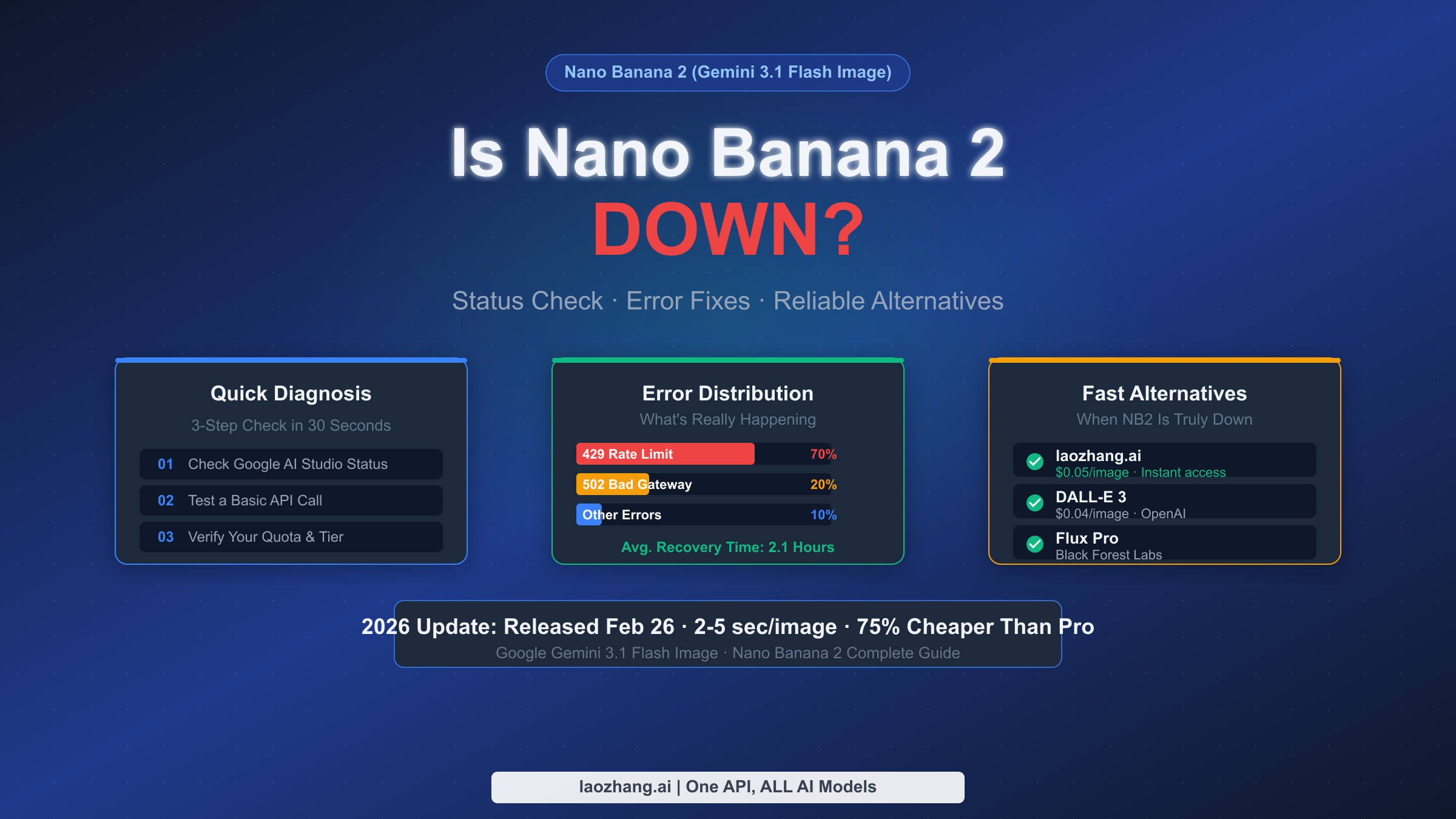





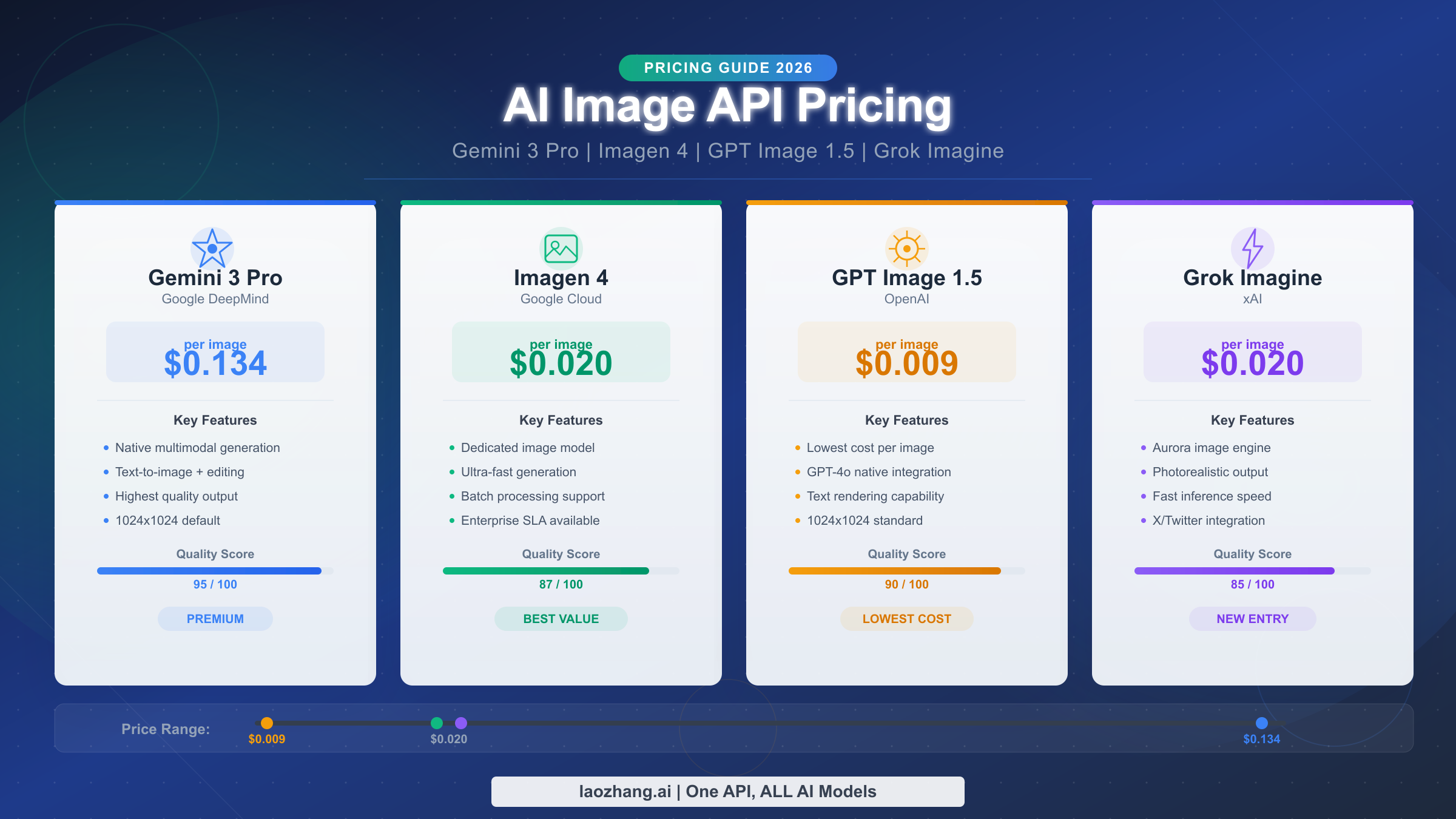


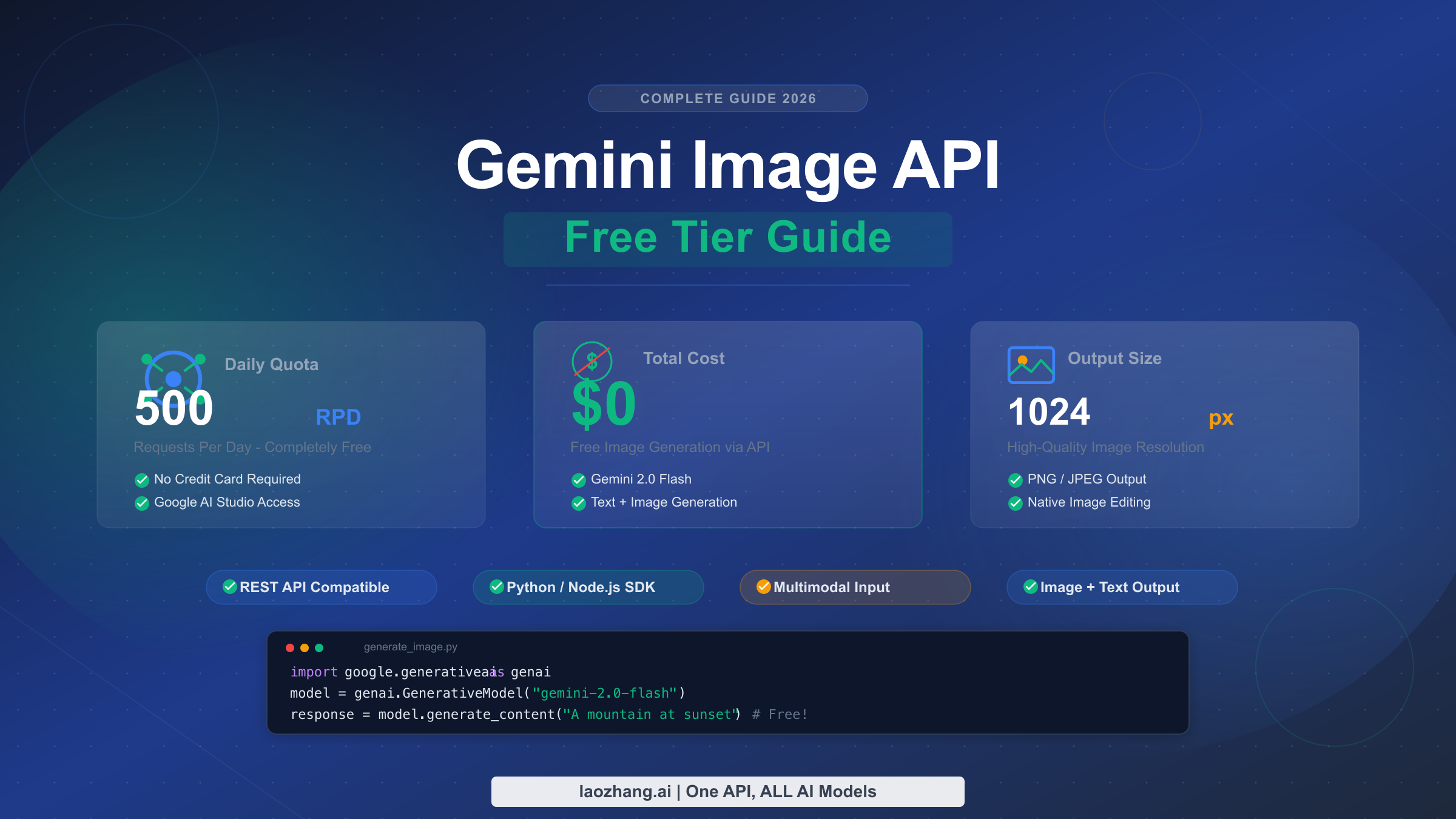
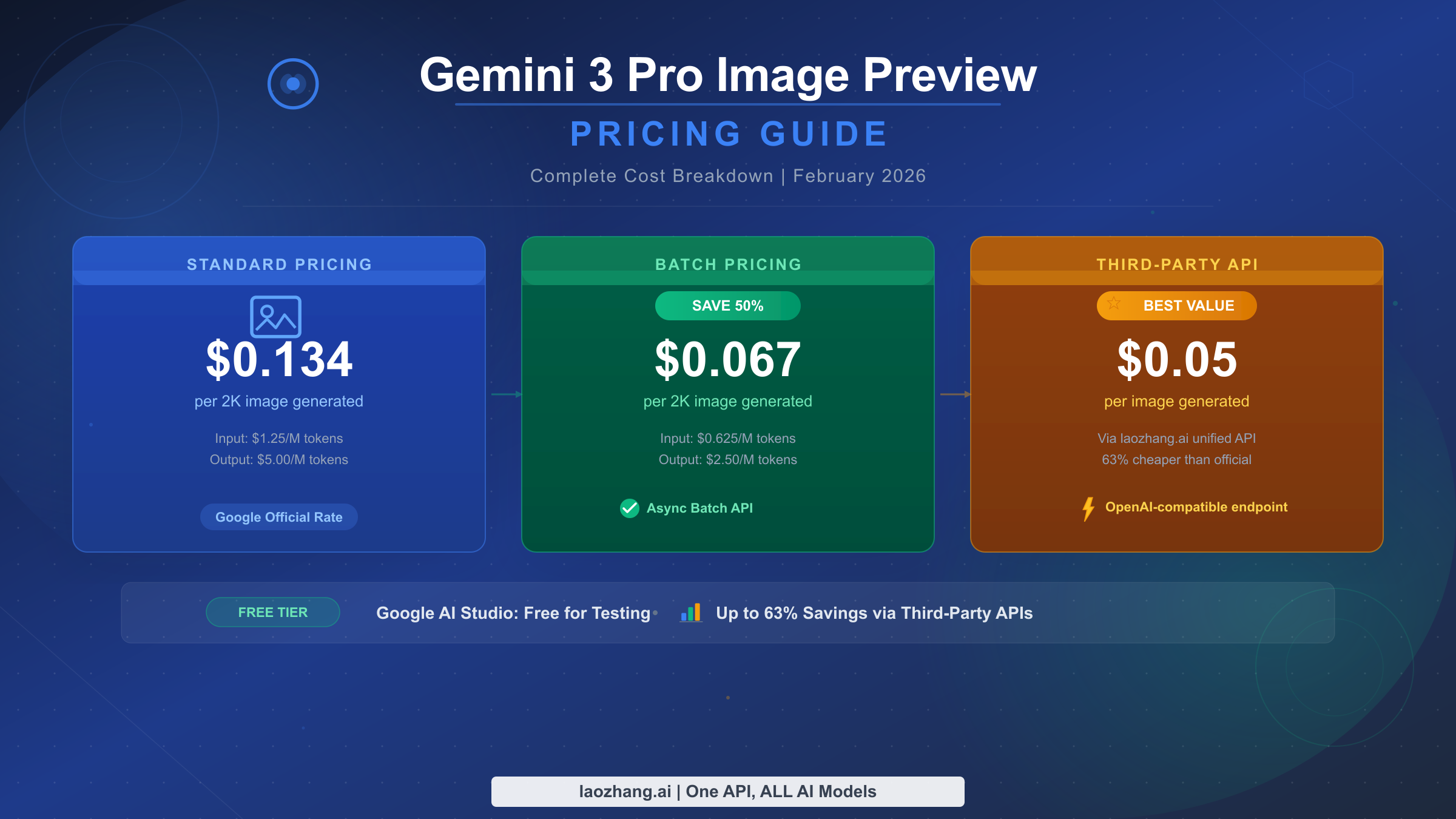
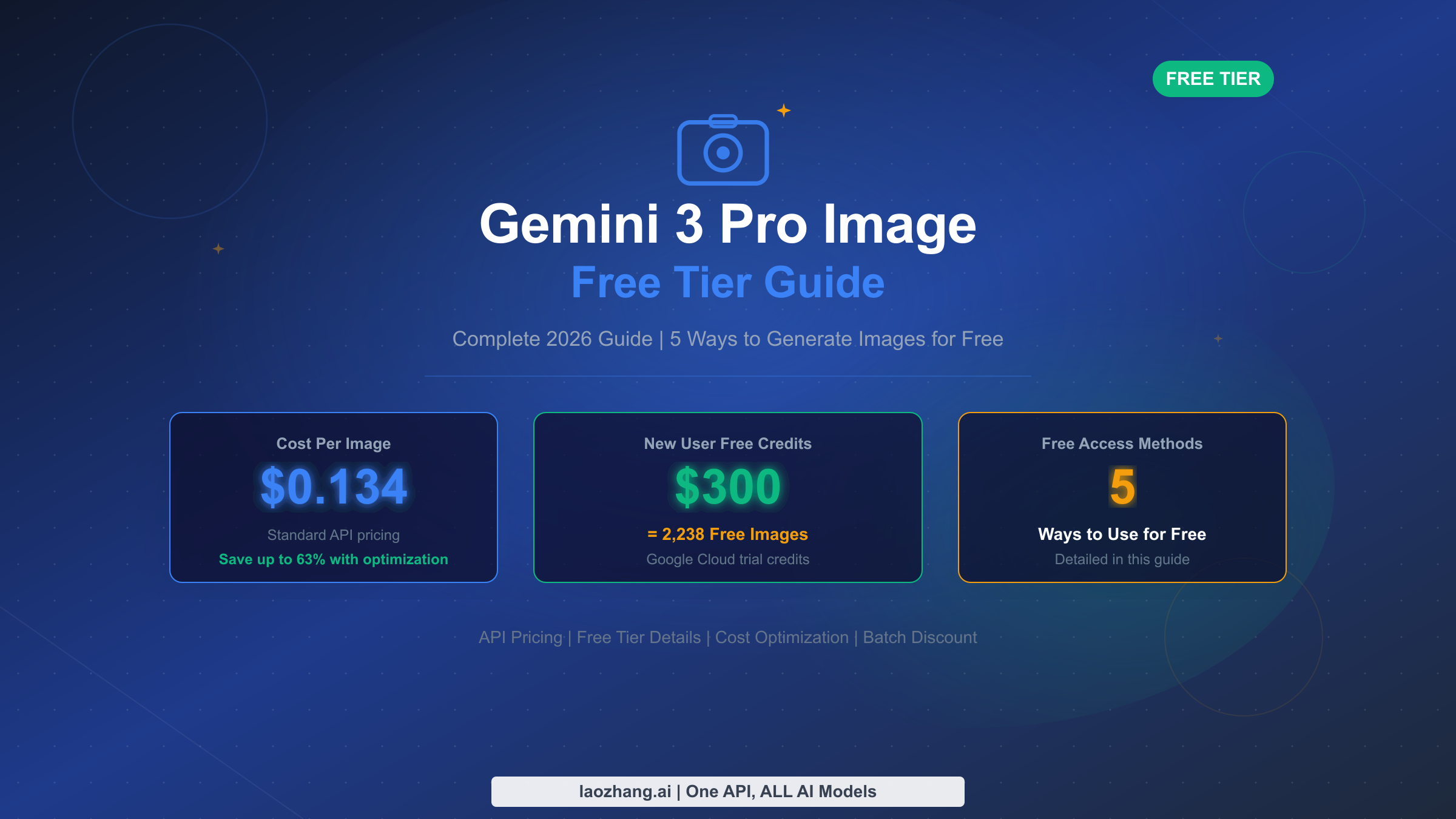

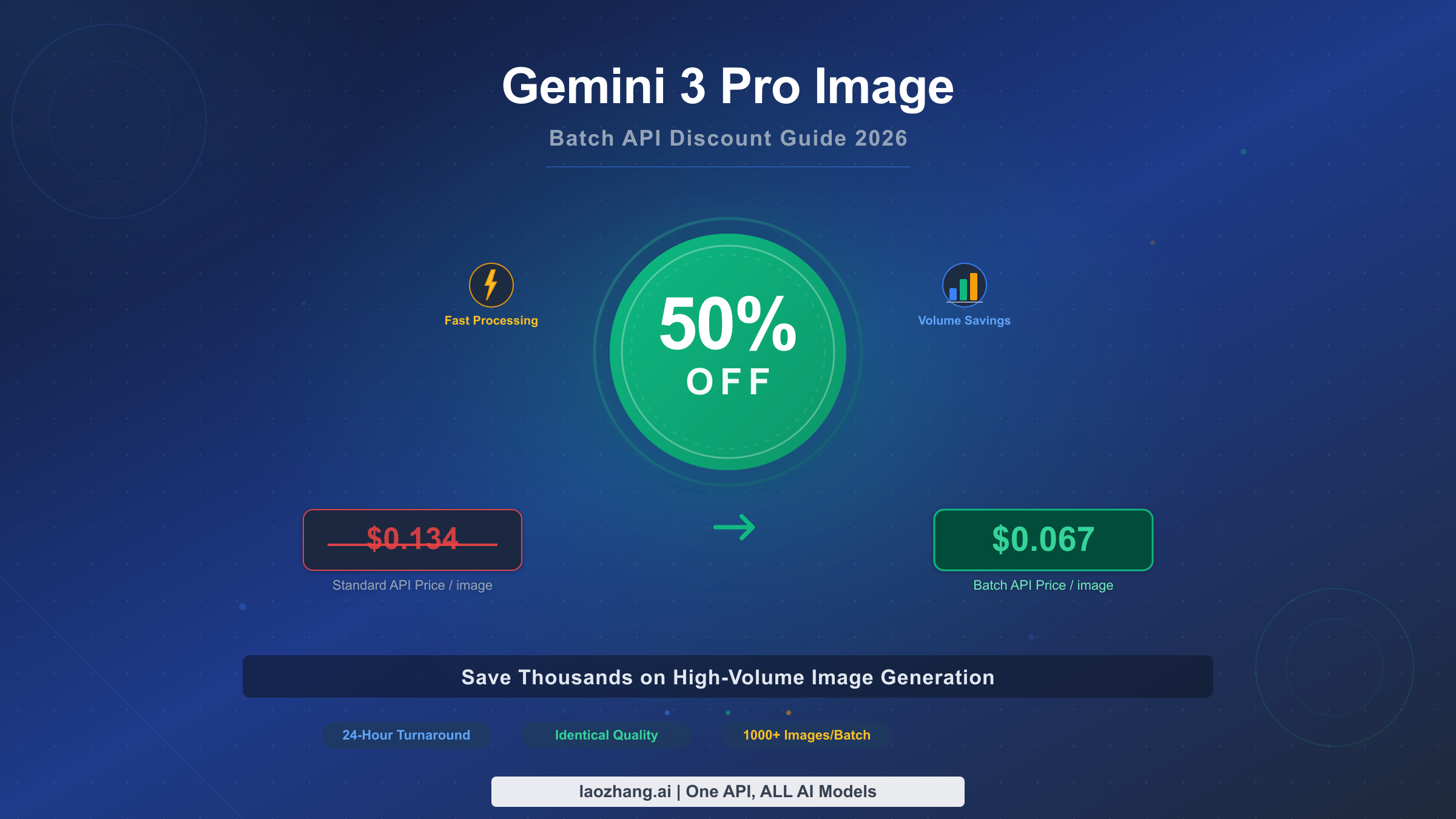
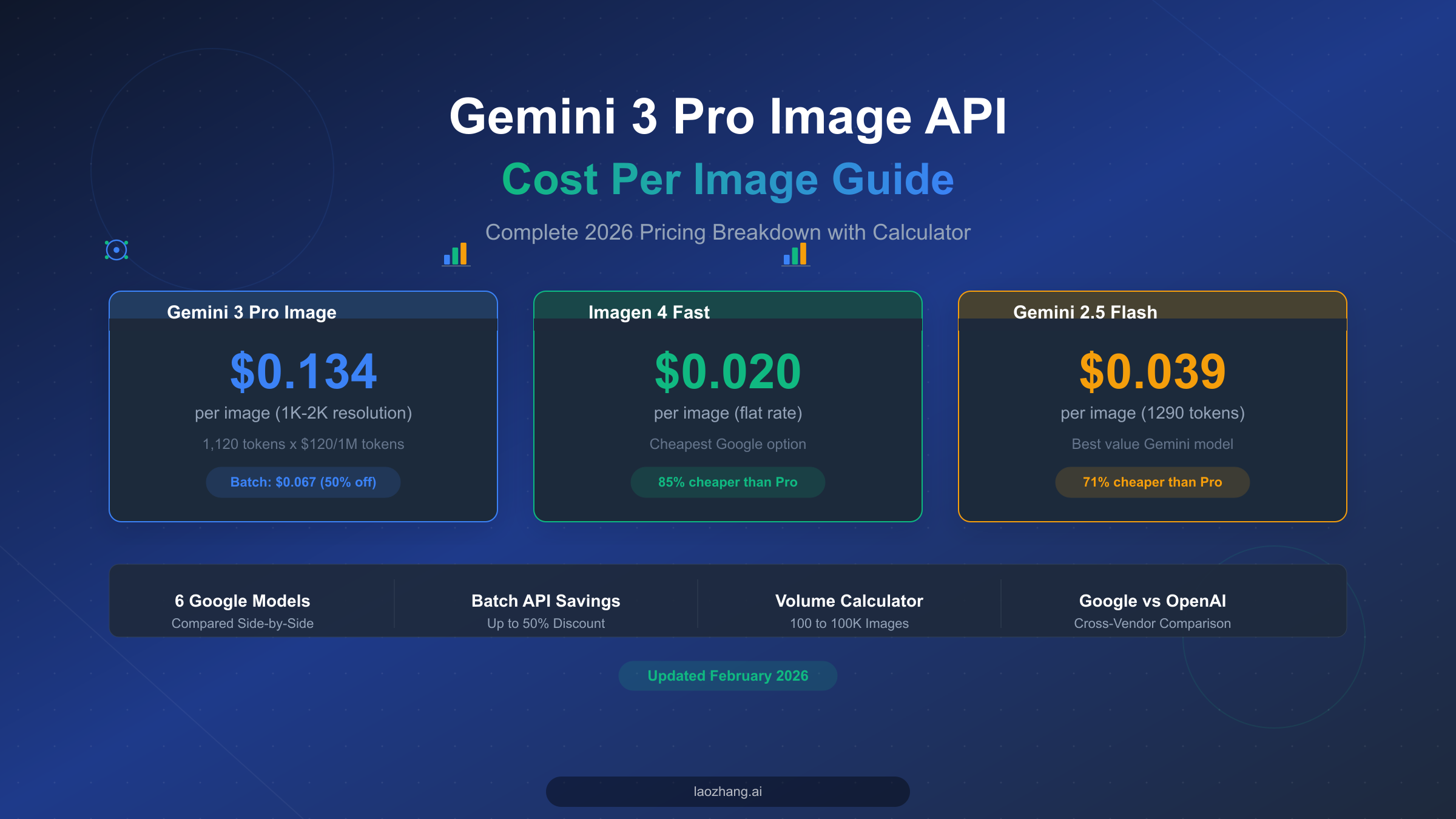
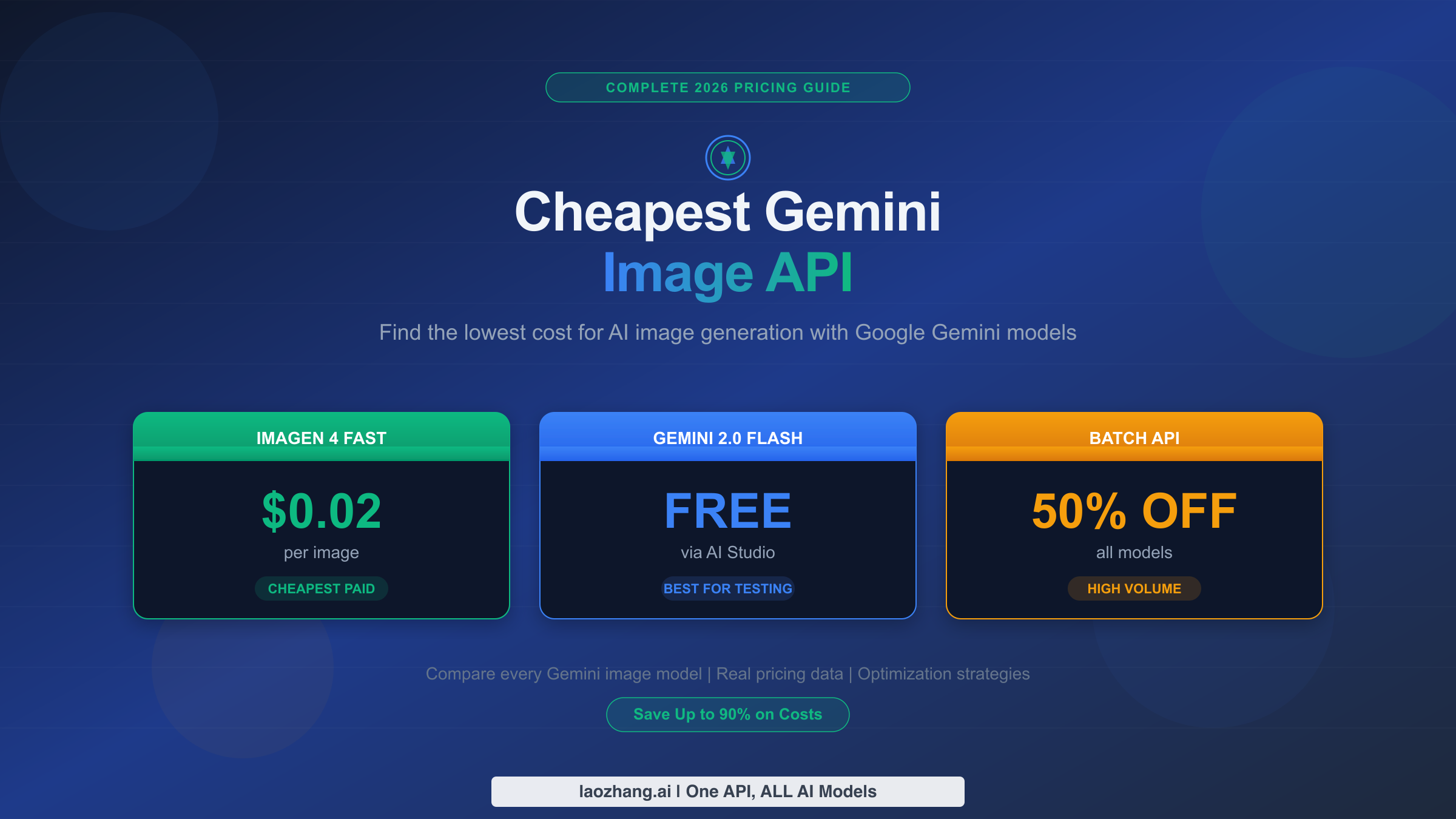
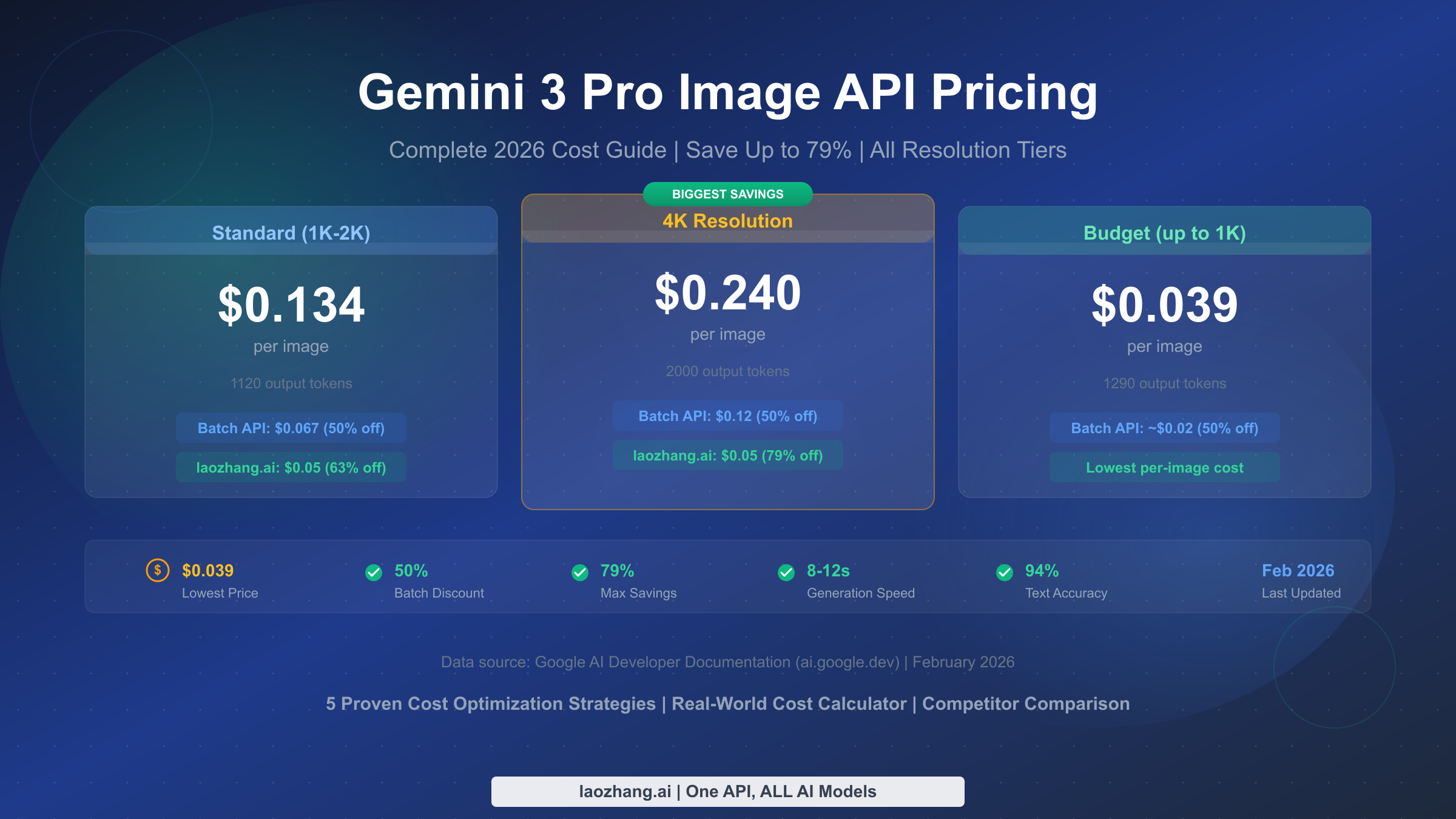
![Fix Gemini 3 Pro Image 503 Overloaded: Complete Troubleshooting Guide [2026]](/posts/en/fix-gemini-3-pro-image-503-overloaded/img/cover.png)























![Fix OpenClaw context_length_exceeded: Complete Troubleshooting Guide [2026]](/posts/en/openclaw-context-length-exceeded/img/cover.png)

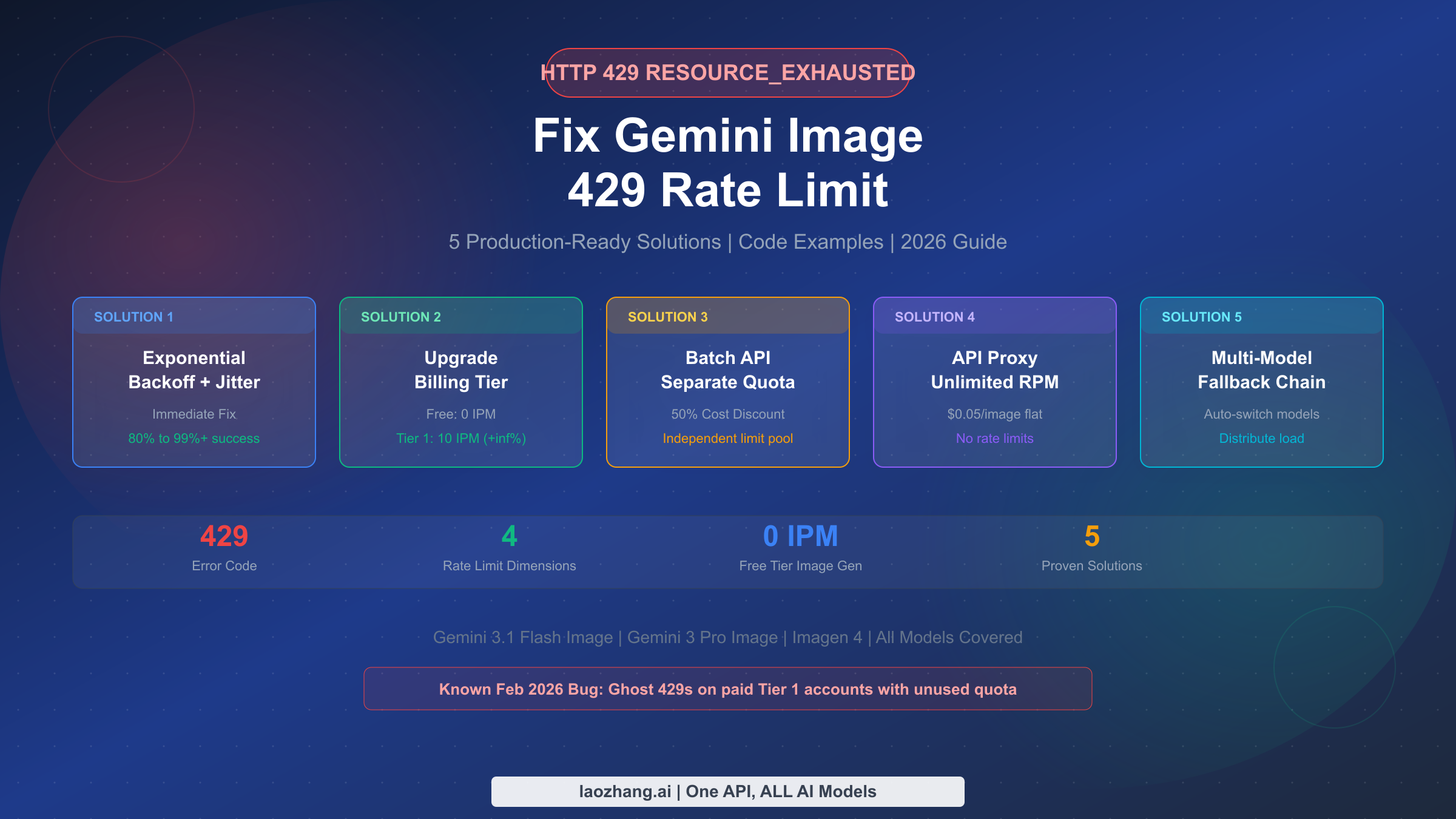
![Fix OpenClaw Rate Limit Exceeded (429): Complete Troubleshooting Guide [2026]](/posts/en/openclaw-rate-limit-exceeded-429/img/cover.png)
![Fix OpenClaw Invalid Beta Flag Error: Complete Guide [2026]](/posts/en/openclaw-invalid-beta-flag/img/cover.png)

![Fix OpenClaw Anthropic API Key Error: Complete Guide [2026]](/posts/en/openclaw-anthropic-api-key-error/img/cover.png)
![Gemini 3 Complete Comparison: Pro, Flash, Nano Banana Pro Full Guide [2026 Update]](/posts/en/gemini-3-comparison/img/cover.png)