ChatGPT Guide
Read Now
ChatGPT Student Discount 2026: Complete Guide to Free & Discounted Access
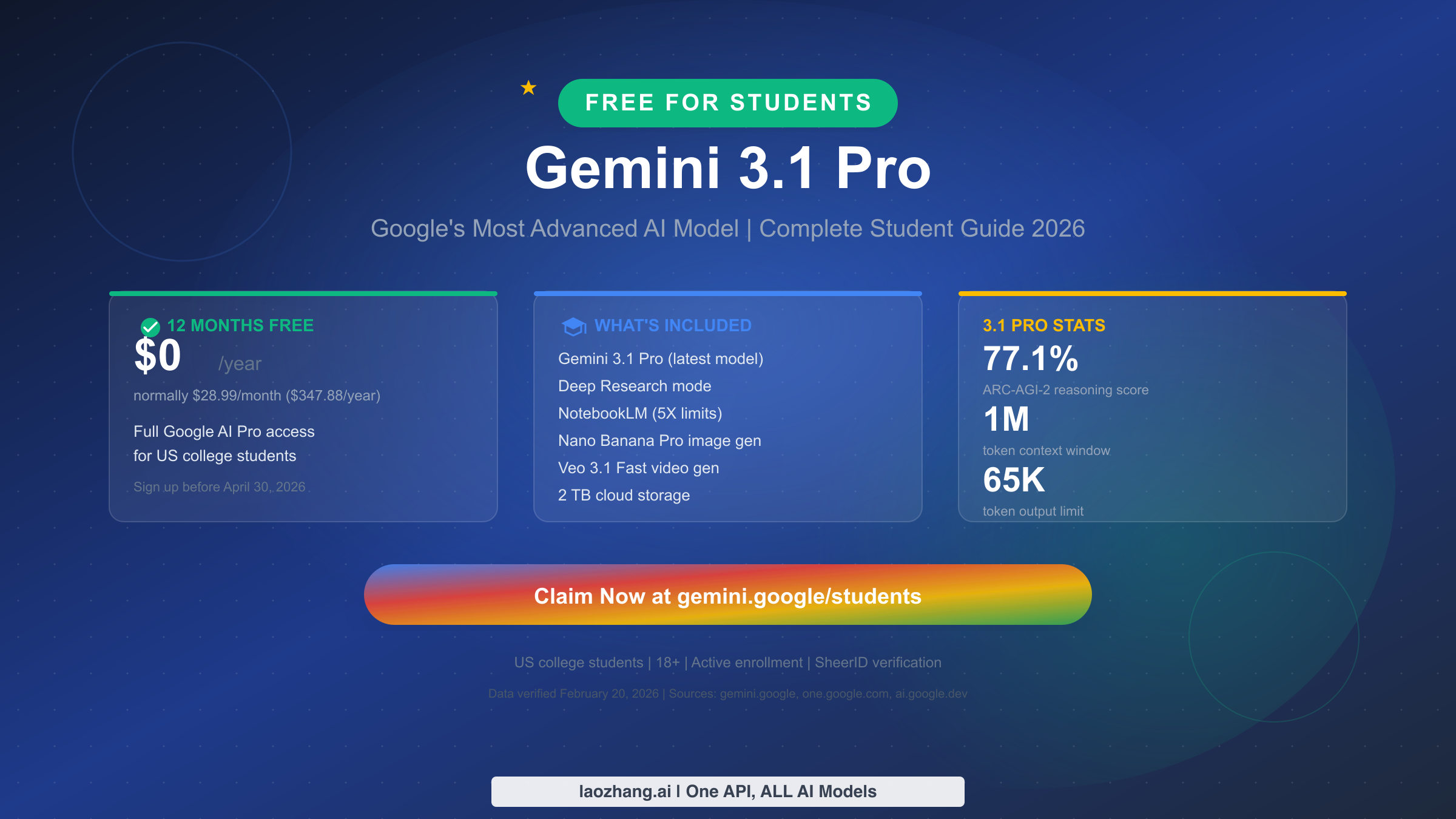
OpenAI does not offer an official ChatGPT student discount as of March 2026. However, students have at least 5 legitimate routes to access ChatGPT features at reduced cost or completely free—including ChatGPT Edu through universities, the budget-friendly Go plan at $8/month, the developer API route for as little as $3-5/month, and powerful free alternatives like Google Gemini Advanced (free for 1 year with student verification). This guide covers every option with honest pros, cons, and step-by-step instructions.



![Nano Banana 2 API Pricing Explained: Official vs Proxy Cost Comparison [2026]](/posts/en/nano-banana-2-api-pricing-guide/img/cover.png)



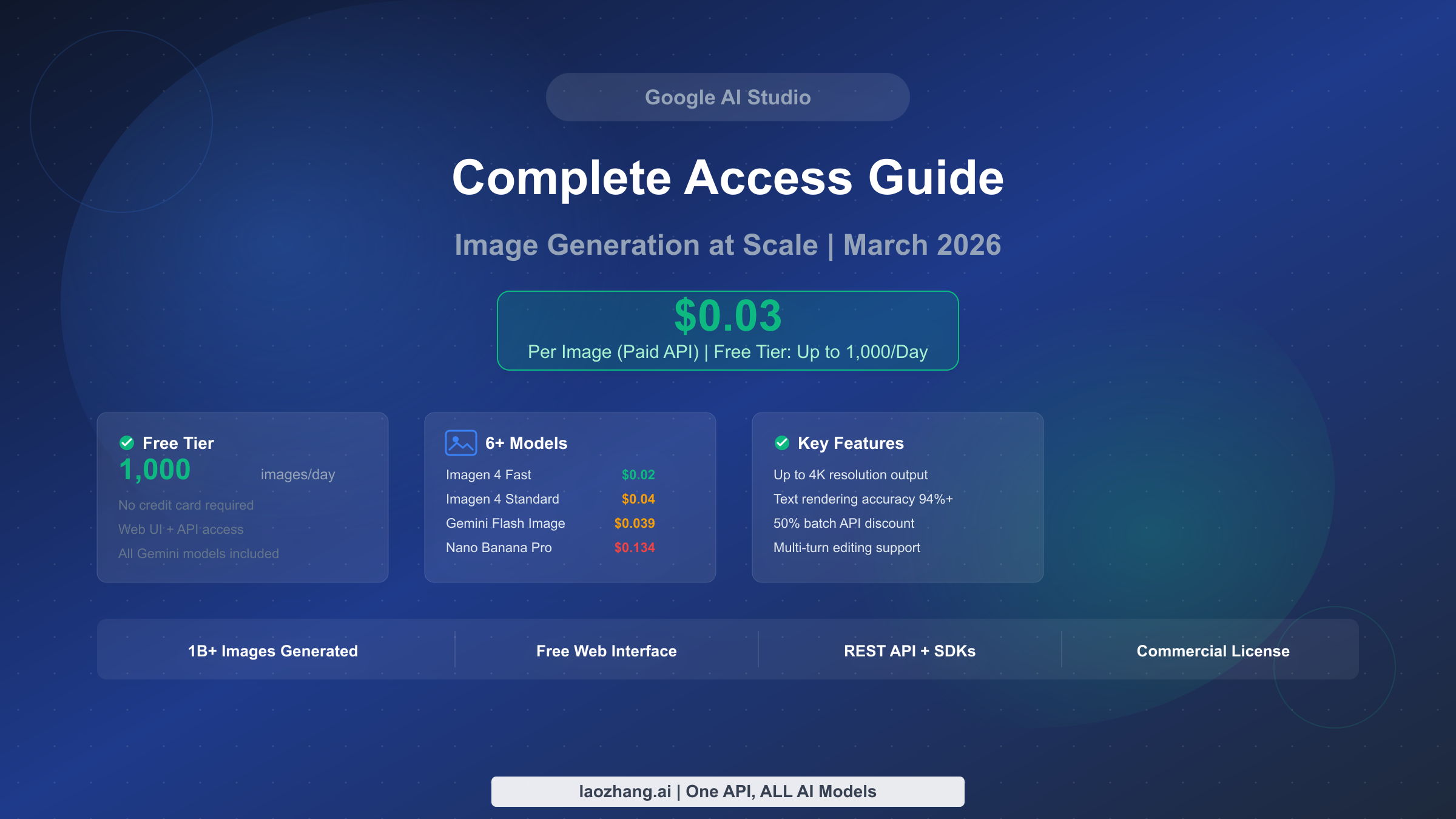
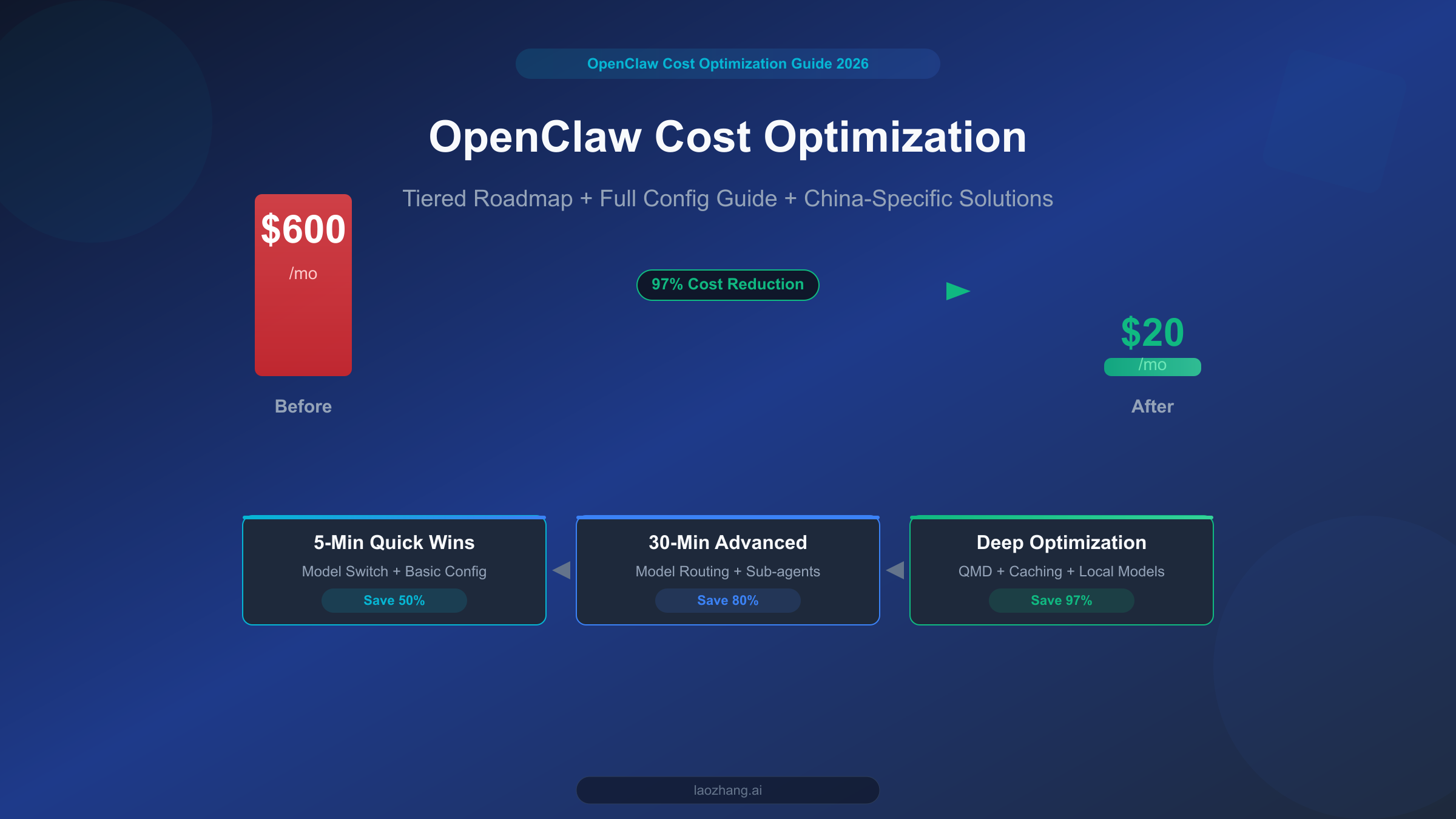
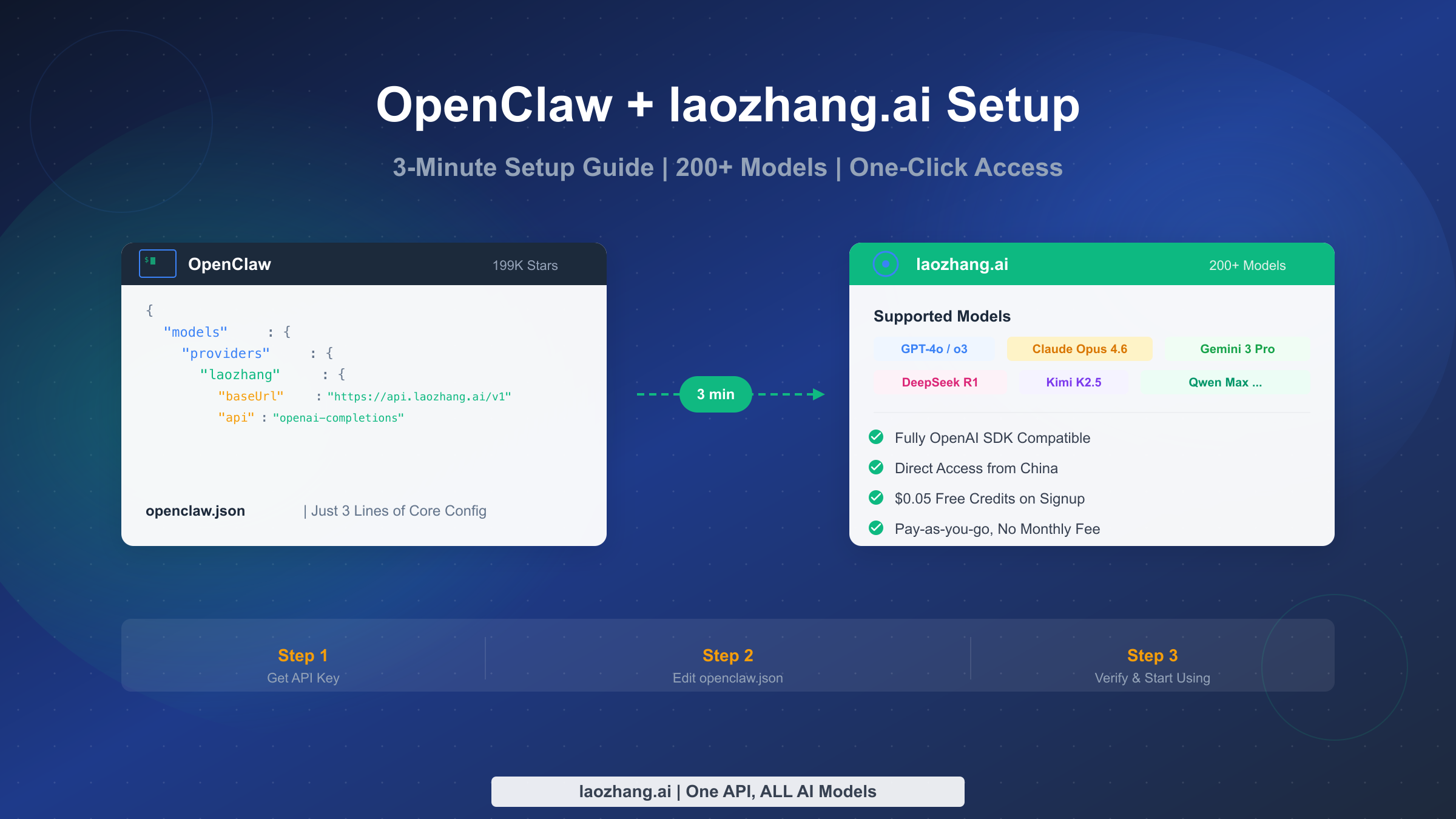

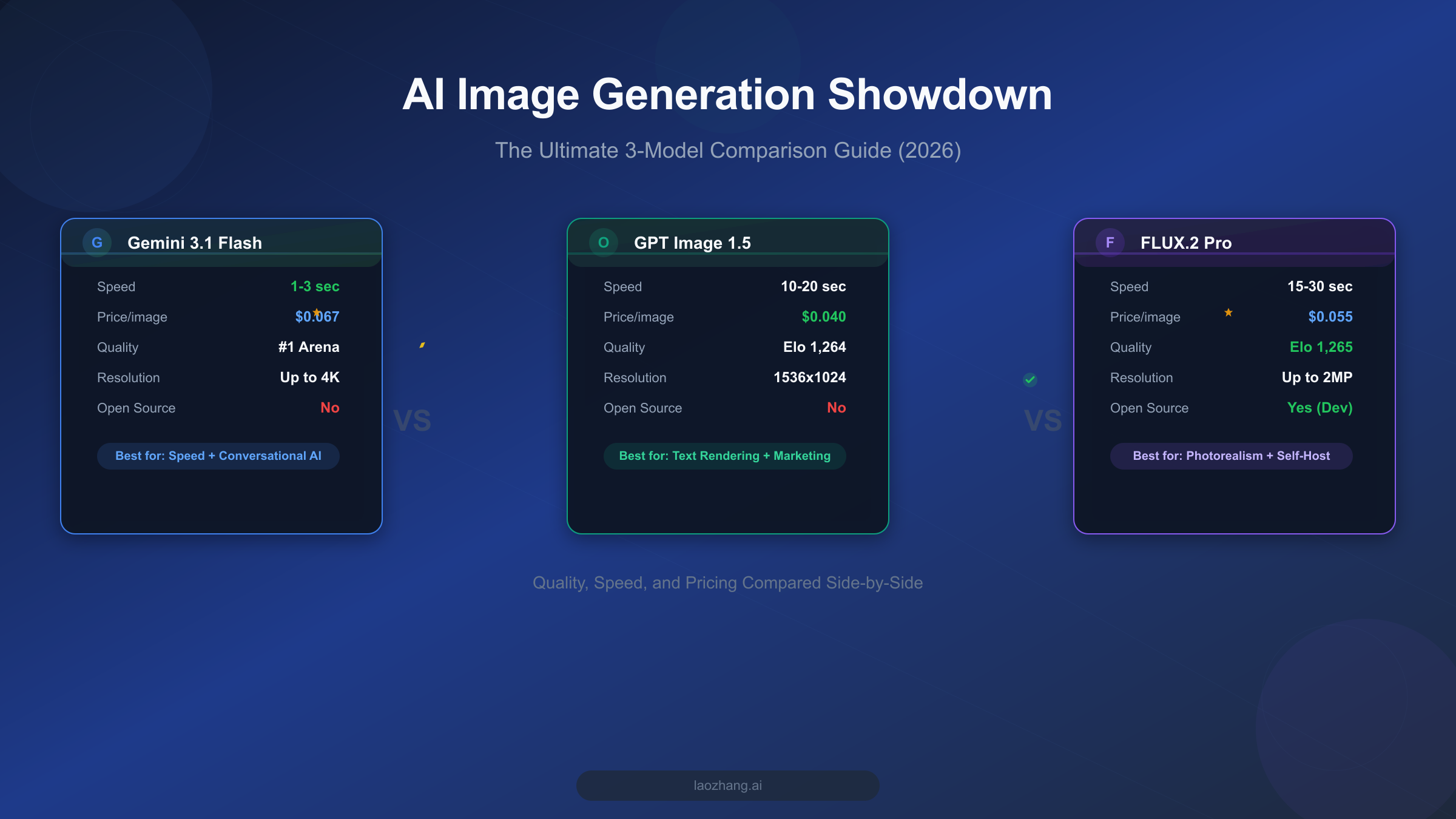




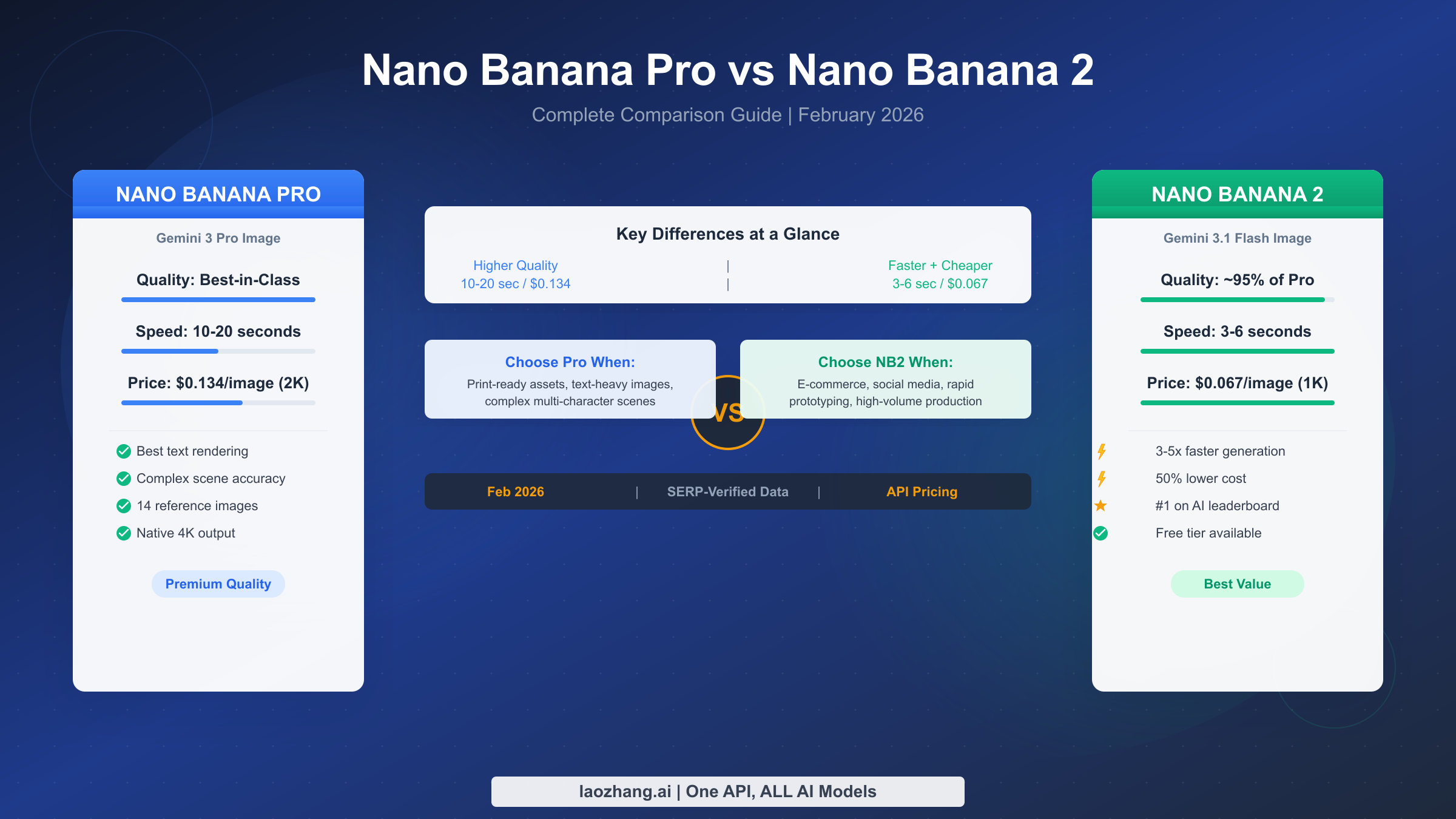
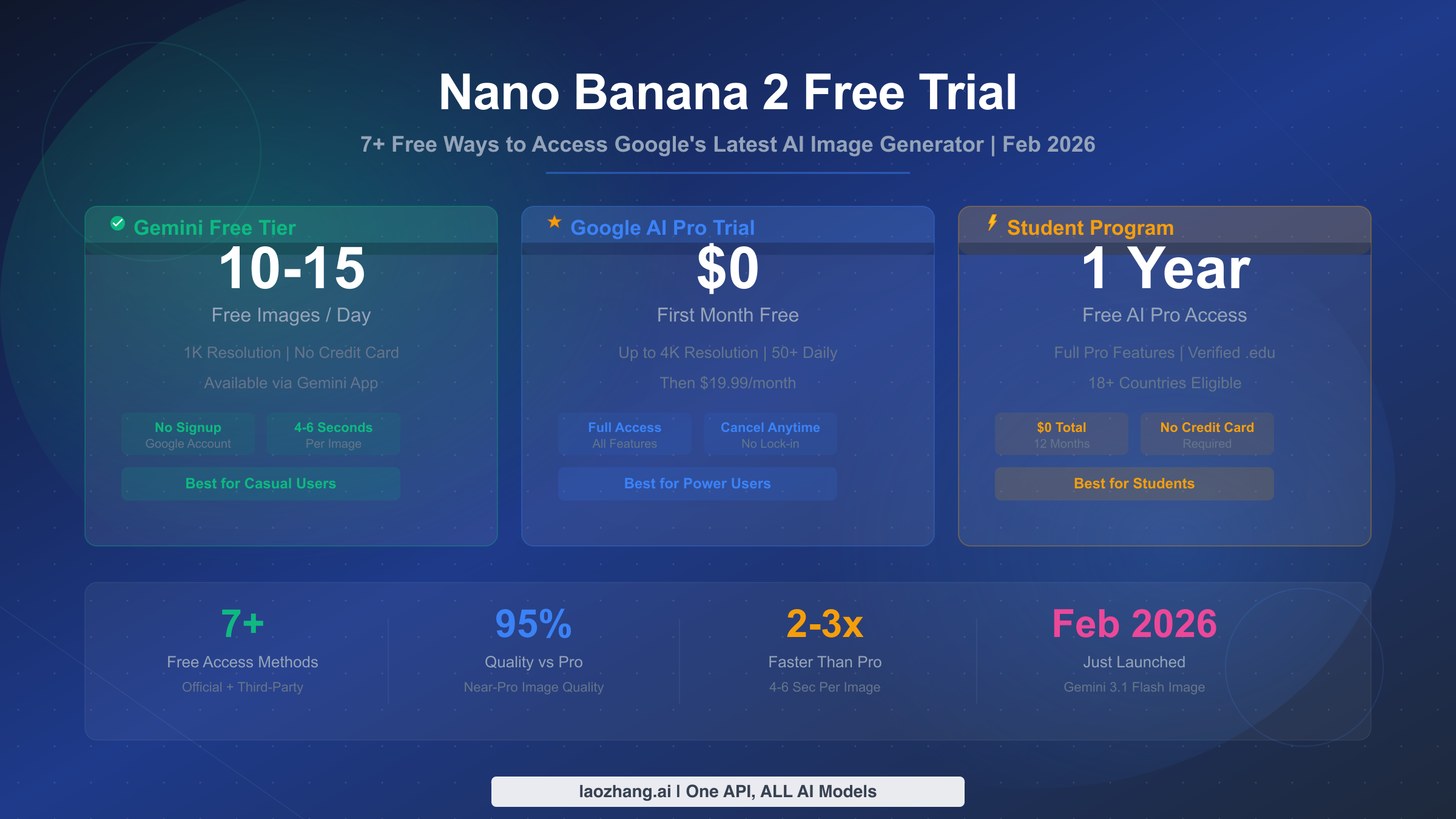
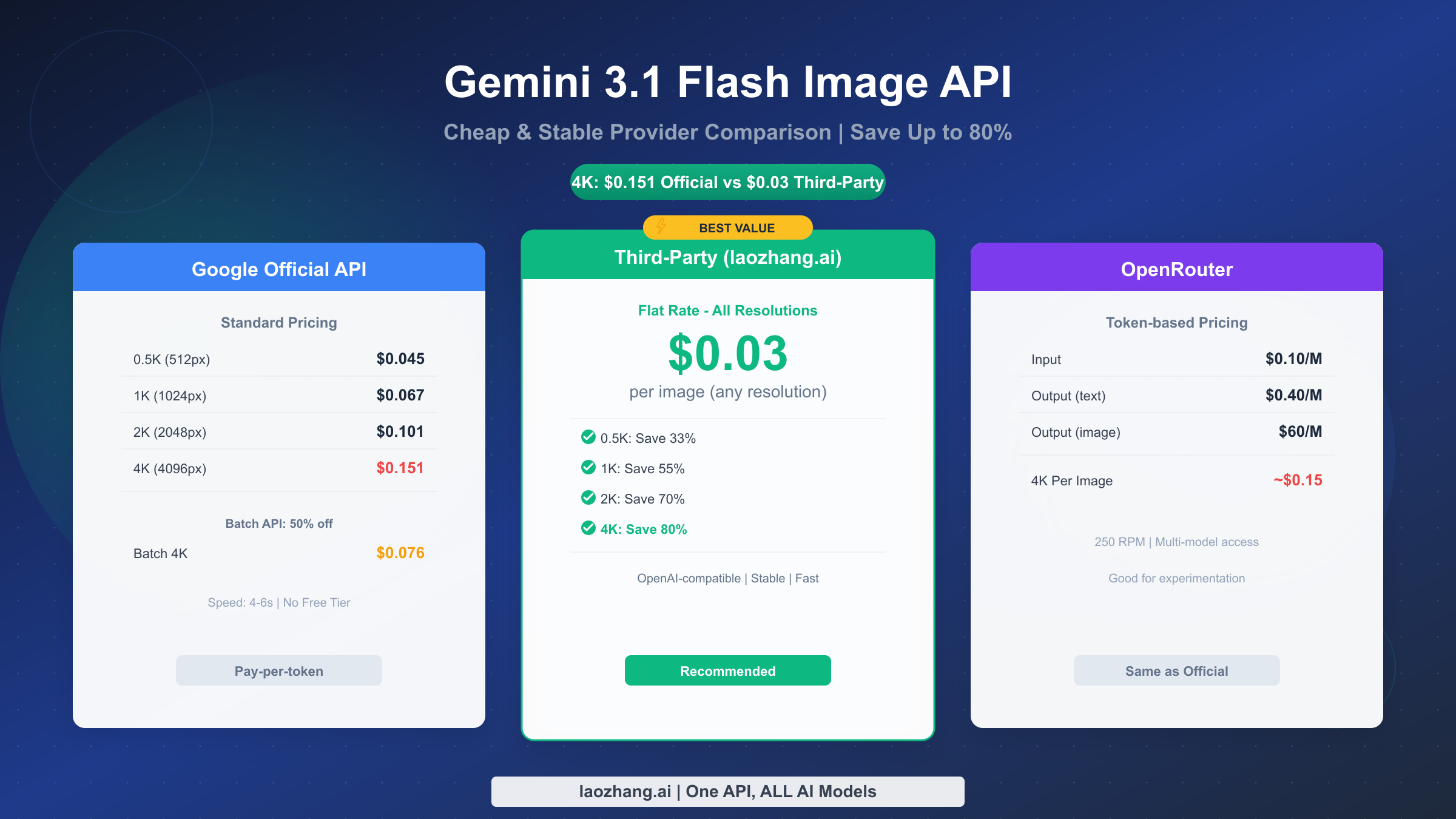
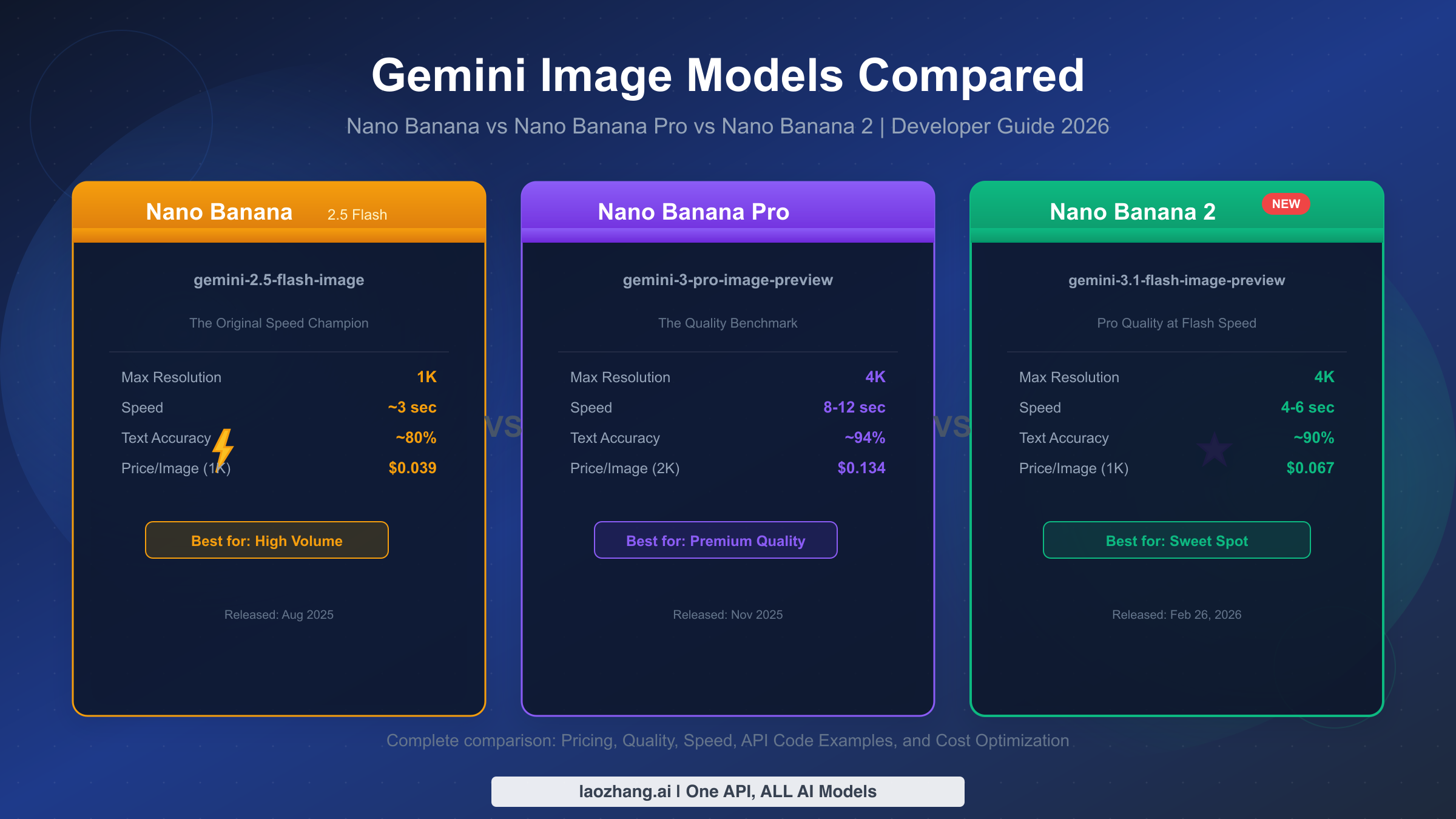
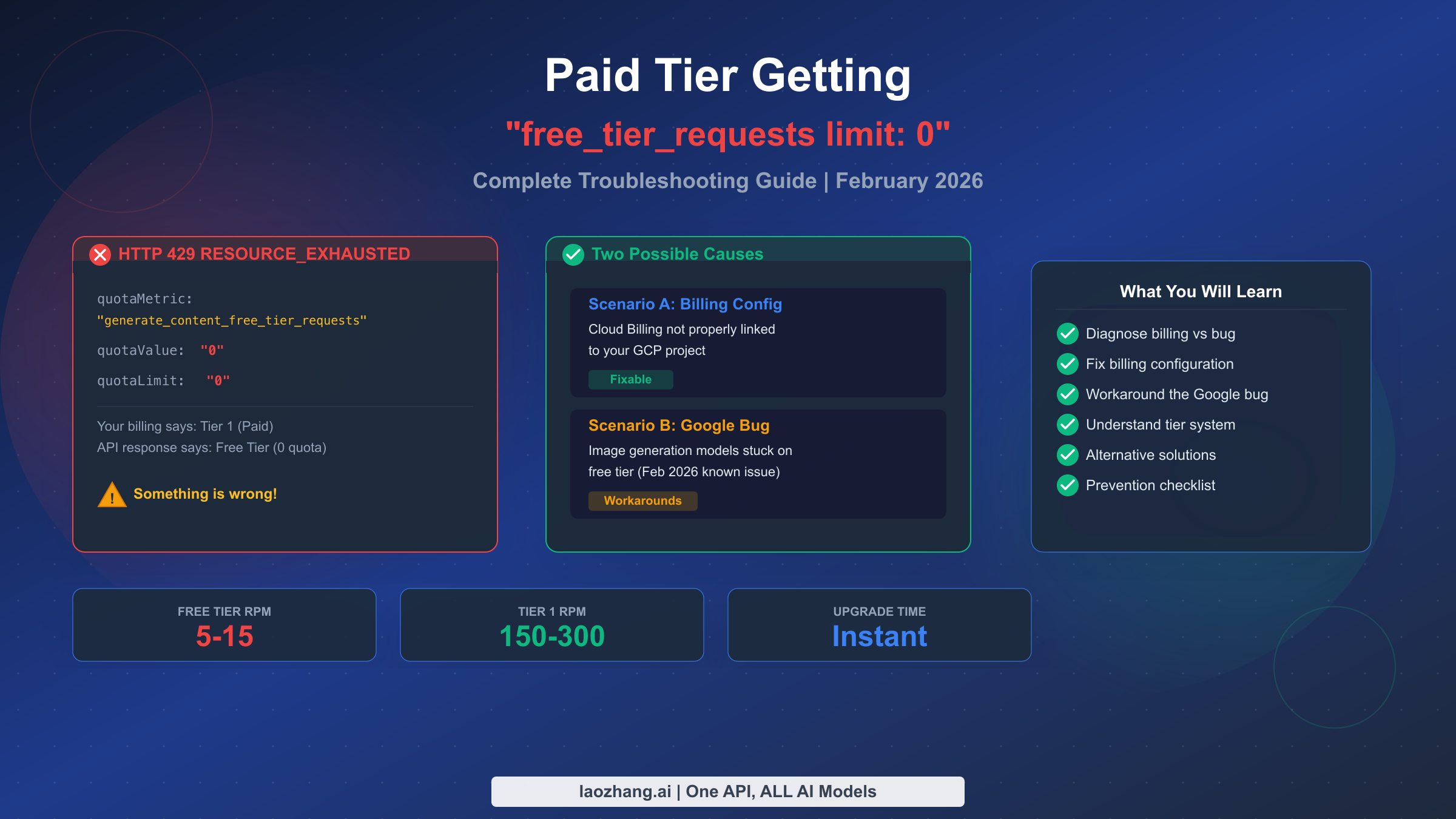

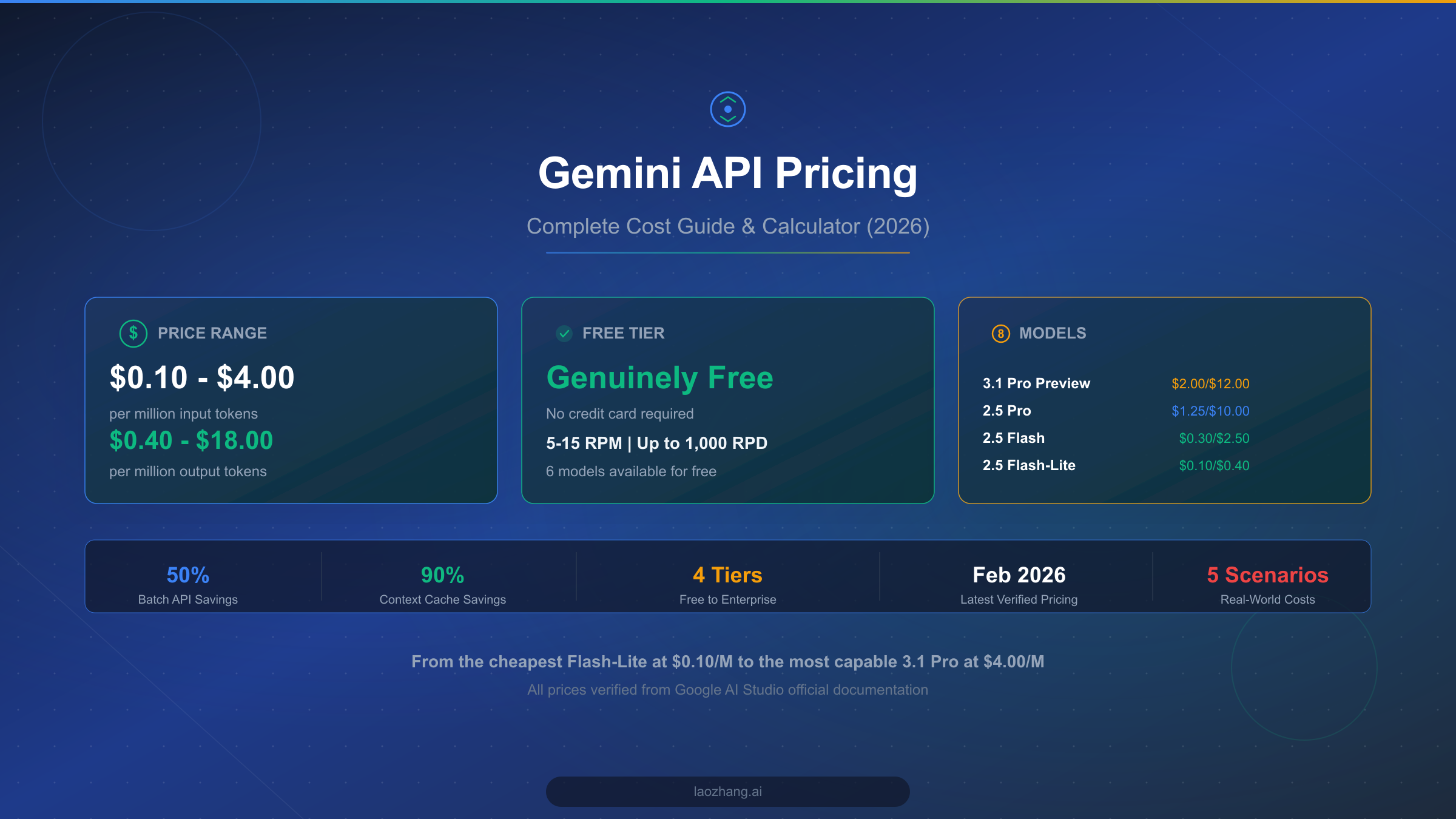

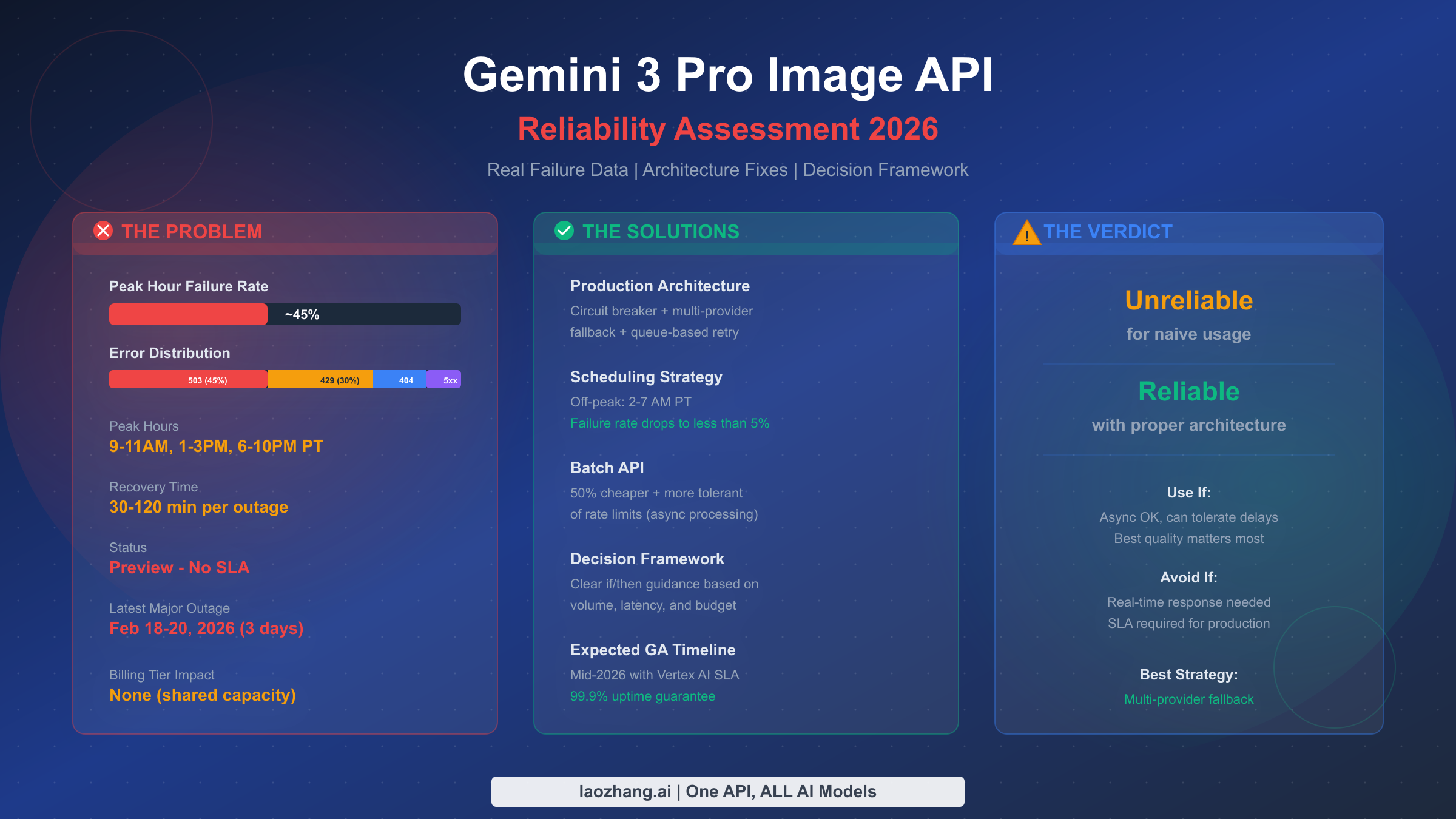
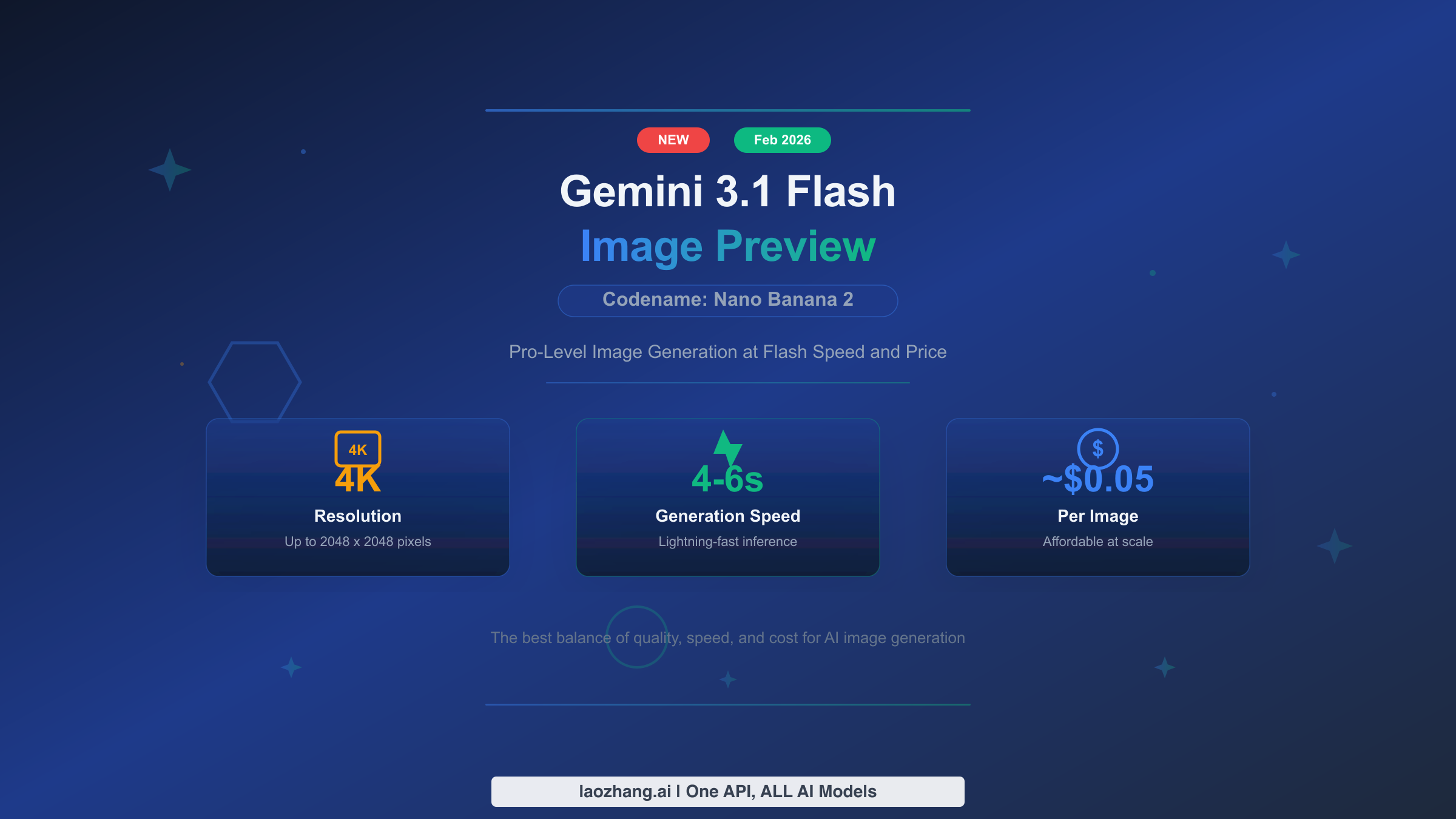
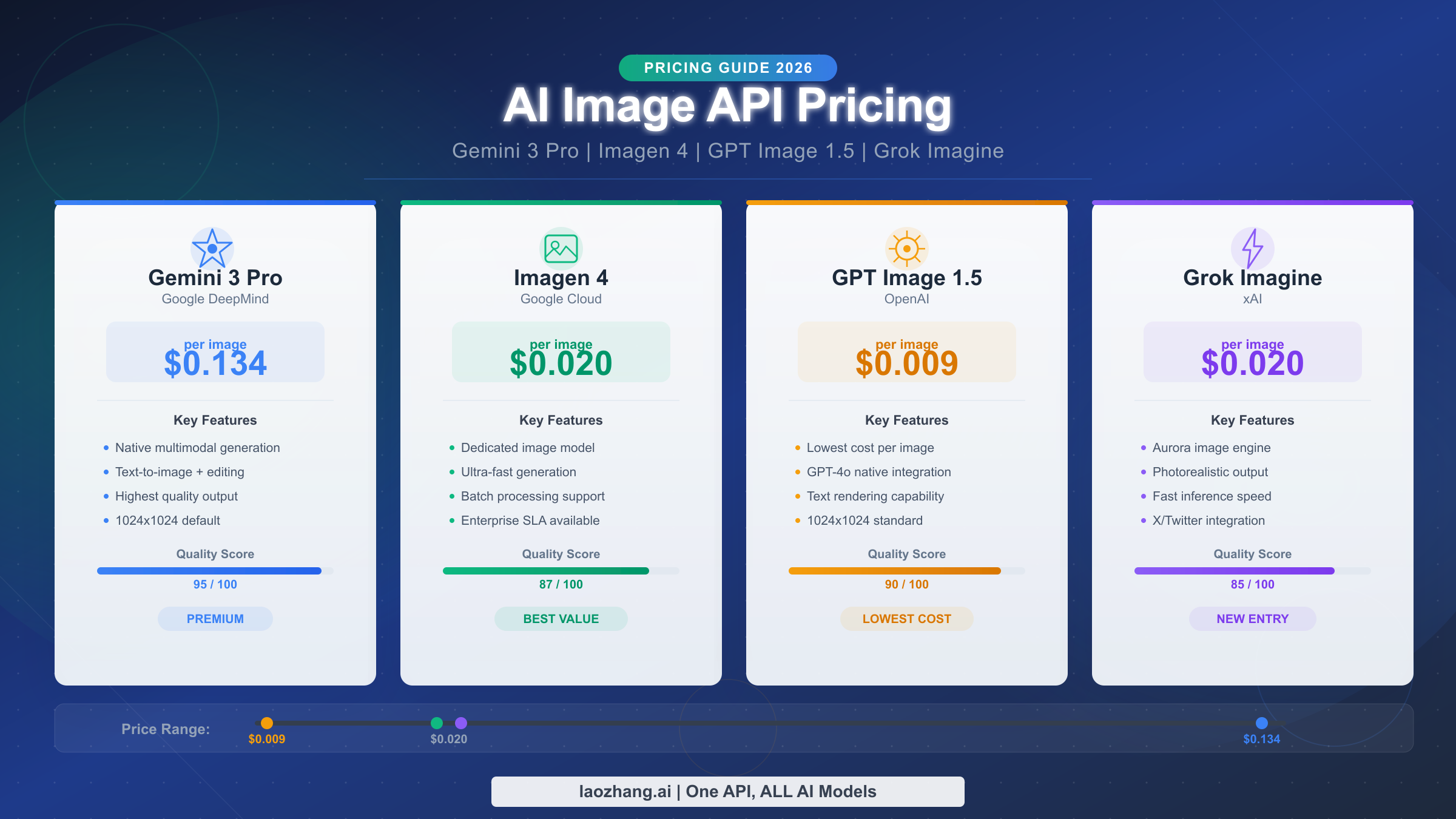


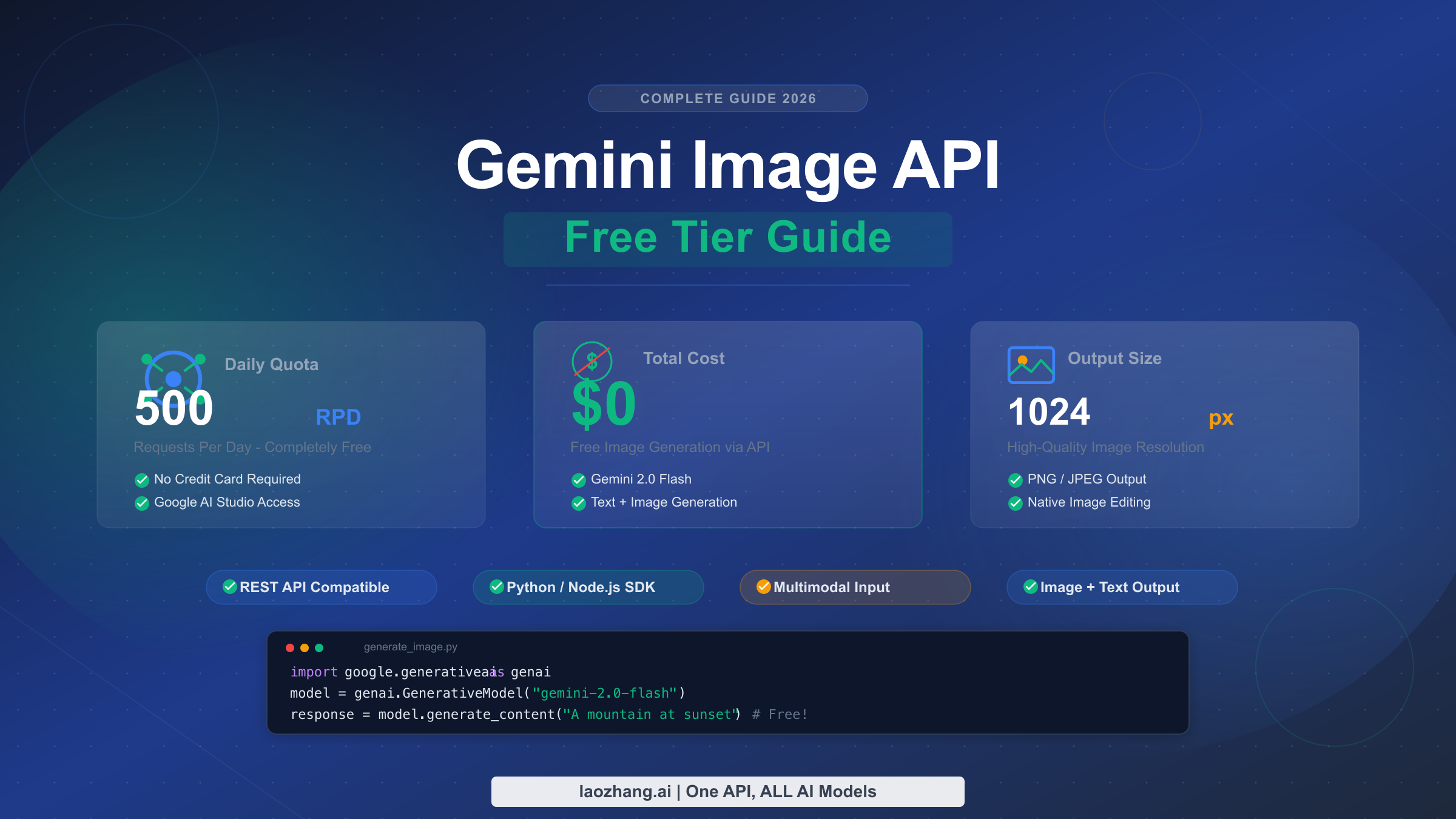
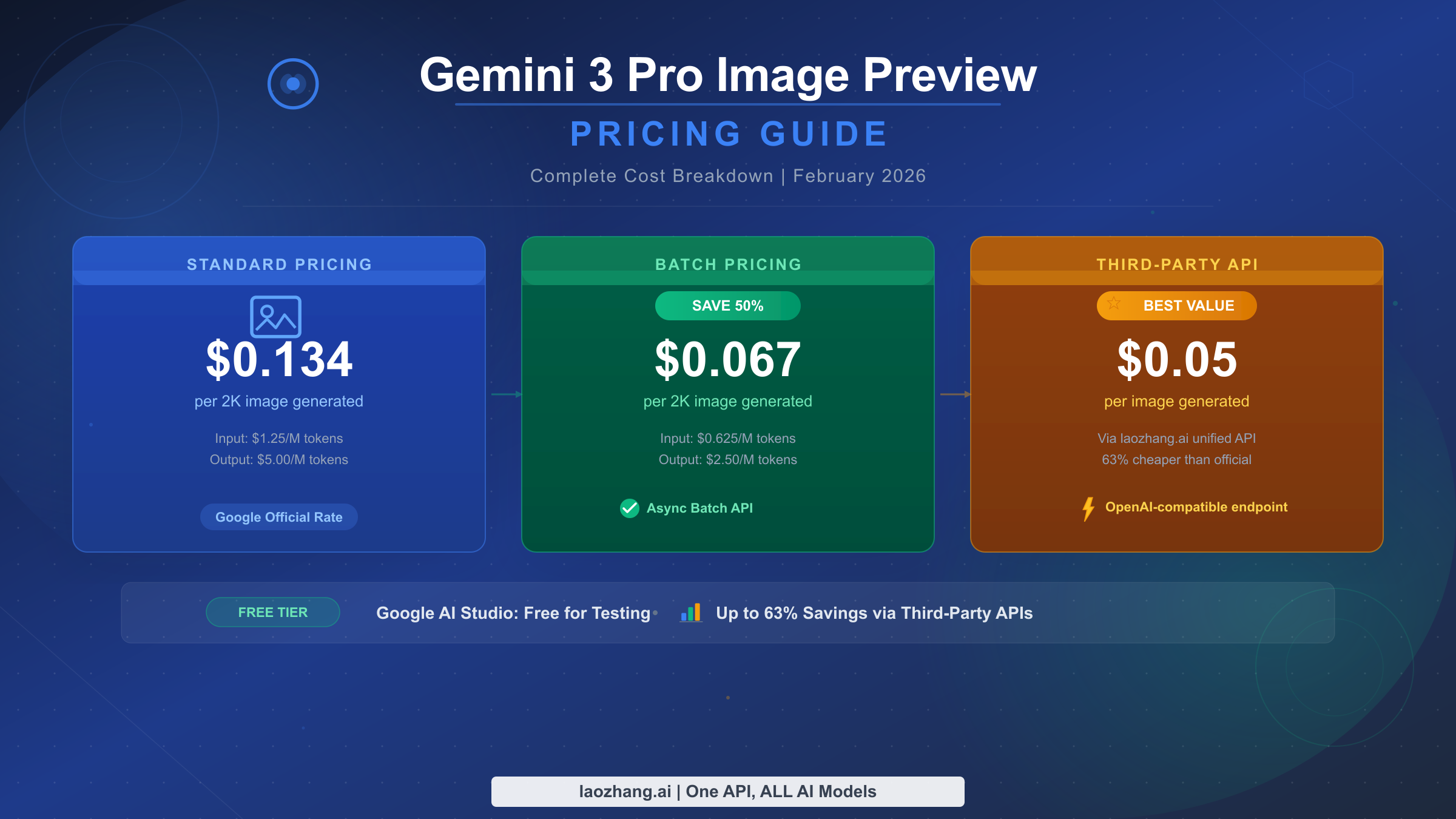
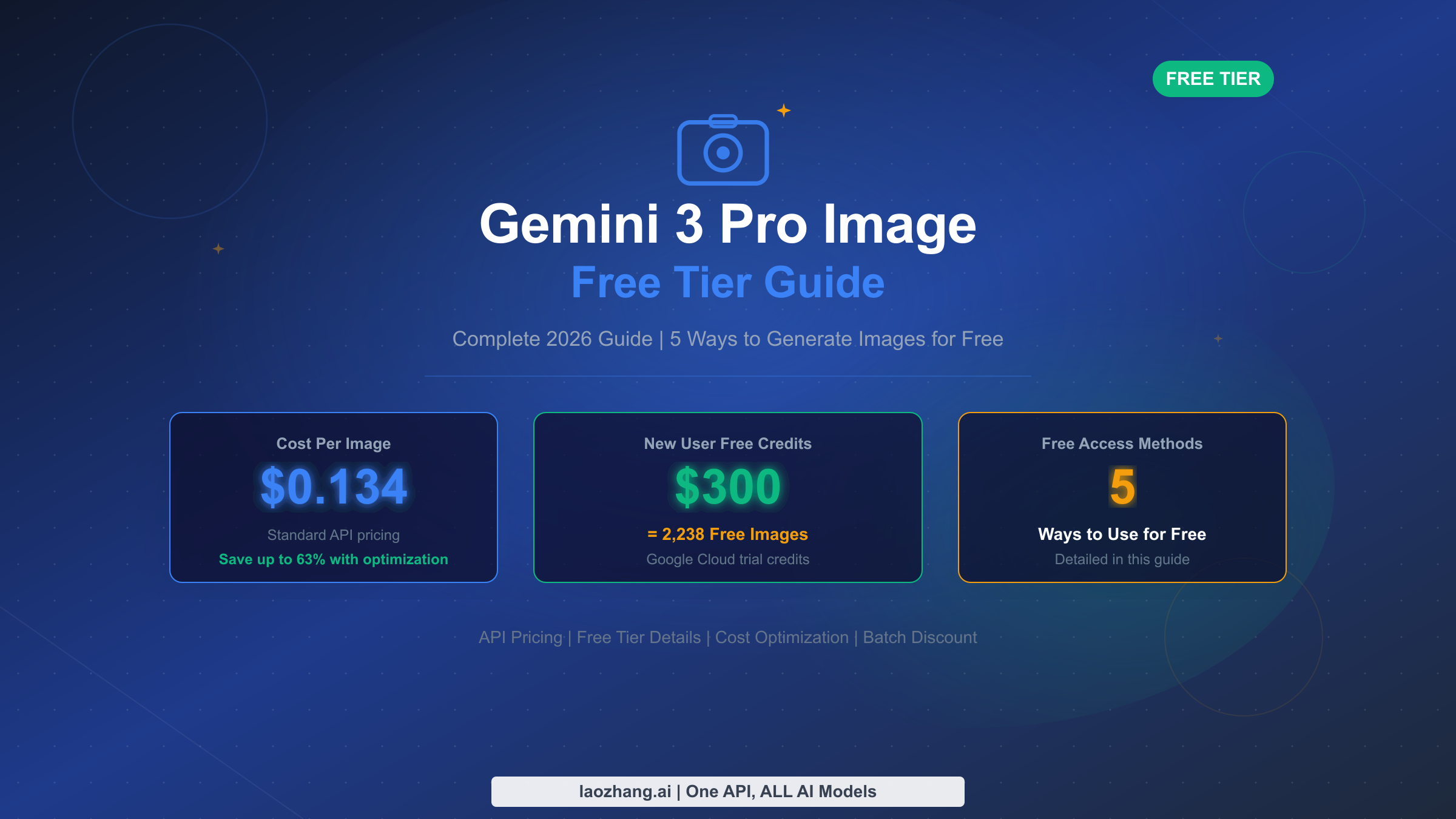

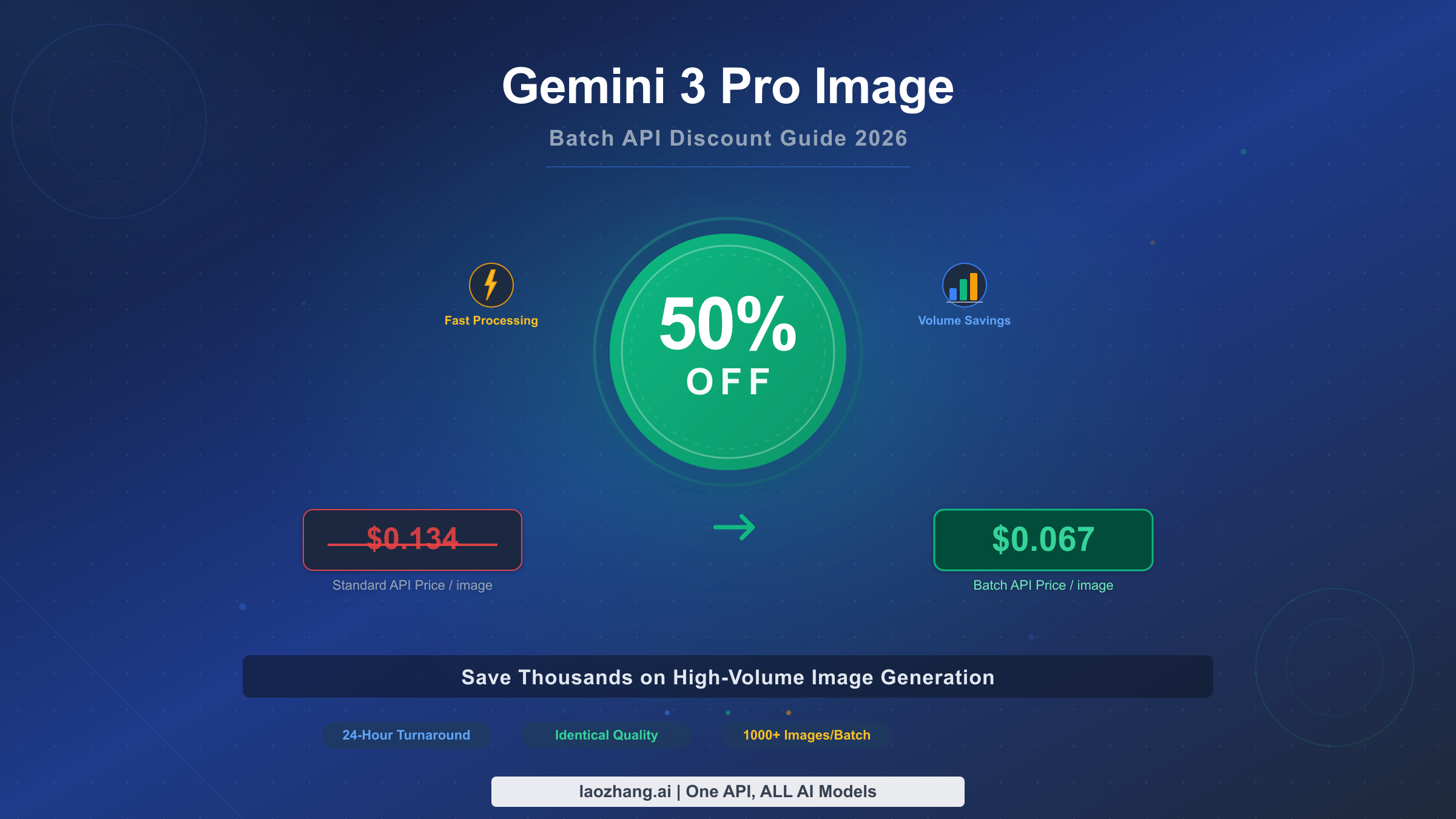
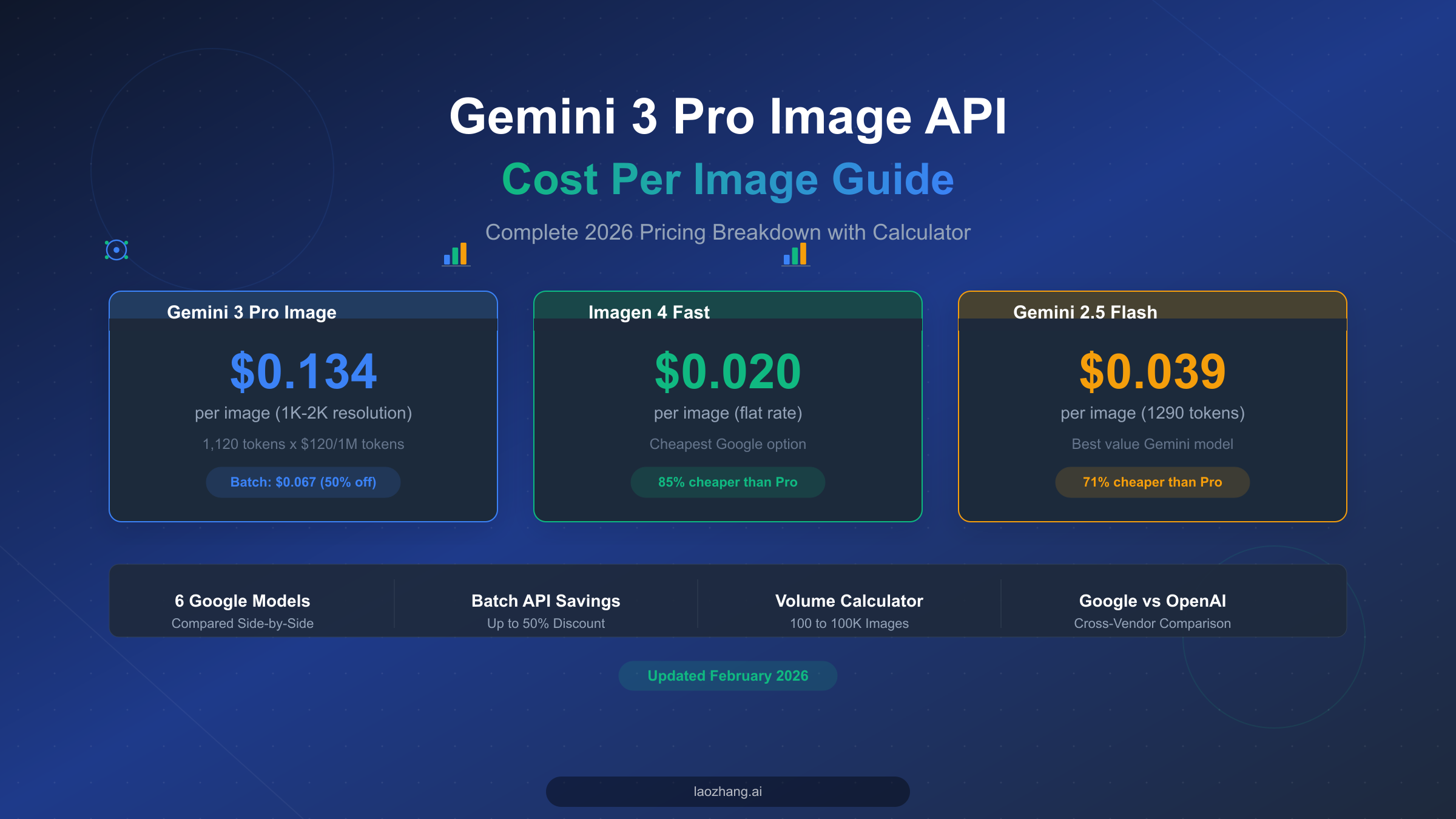
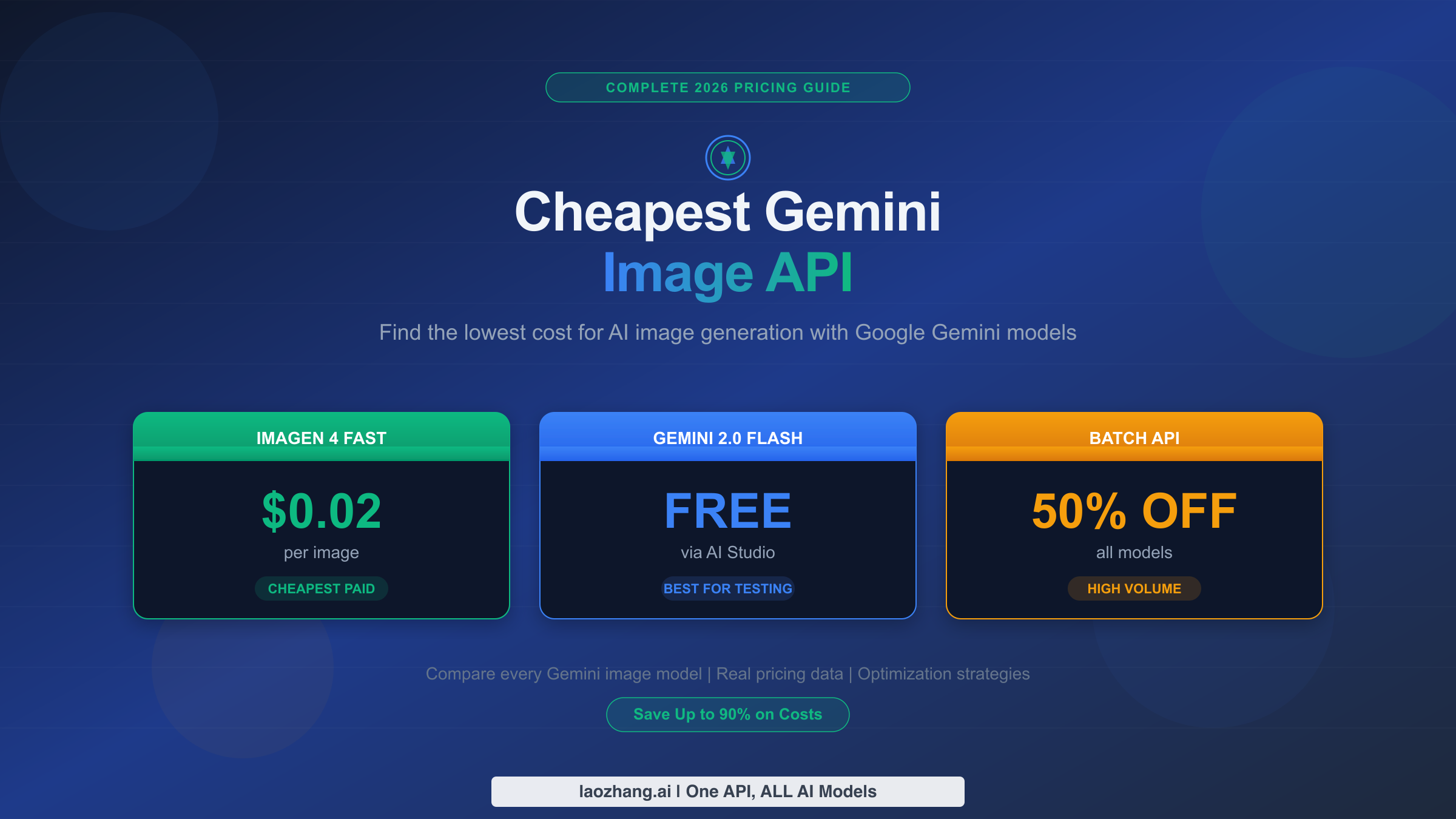
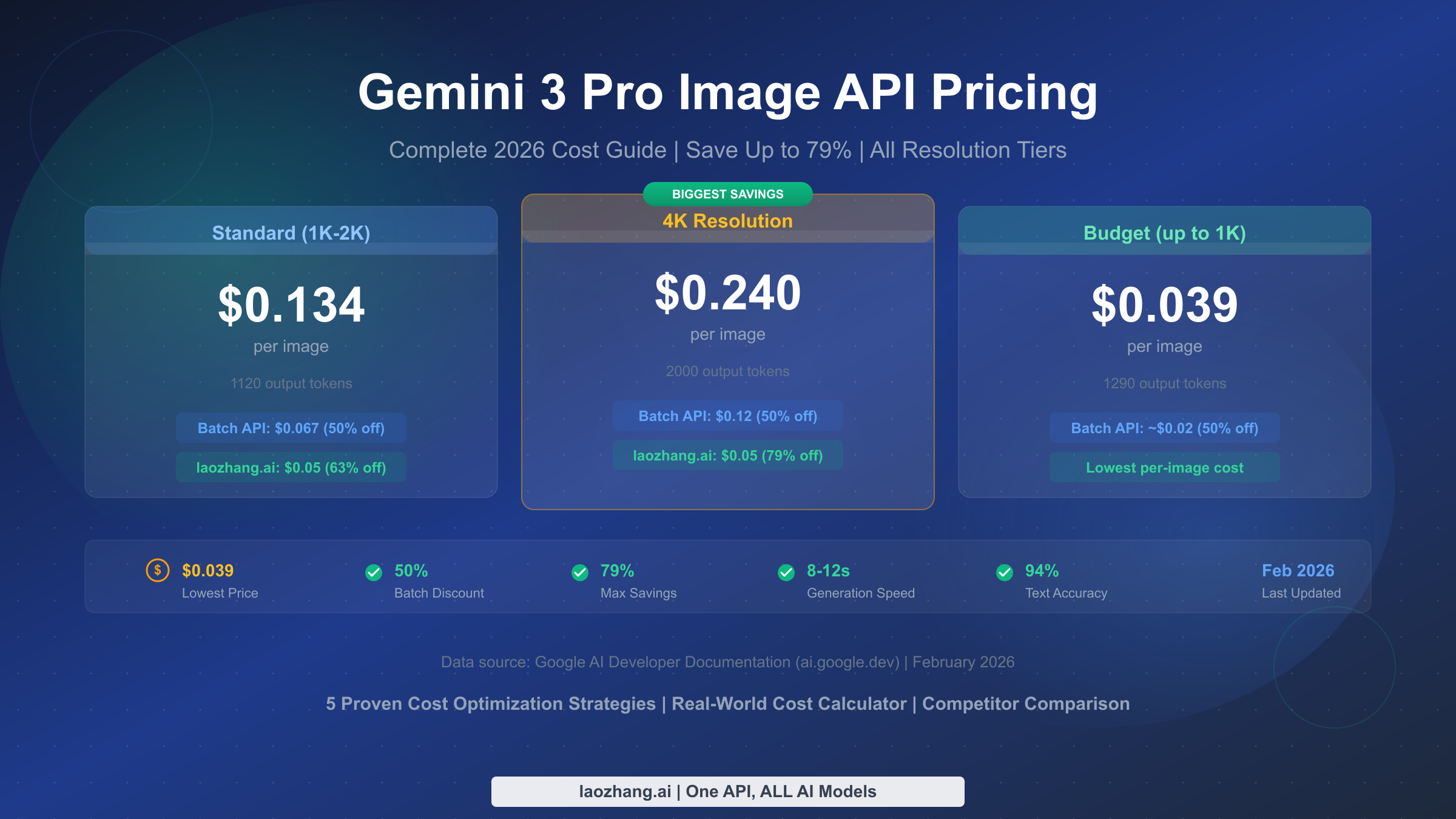
![Fix Gemini 3 Pro Image 503 Overloaded: Complete Troubleshooting Guide [2026]](/posts/en/fix-gemini-3-pro-image-503-overloaded/img/cover.png)
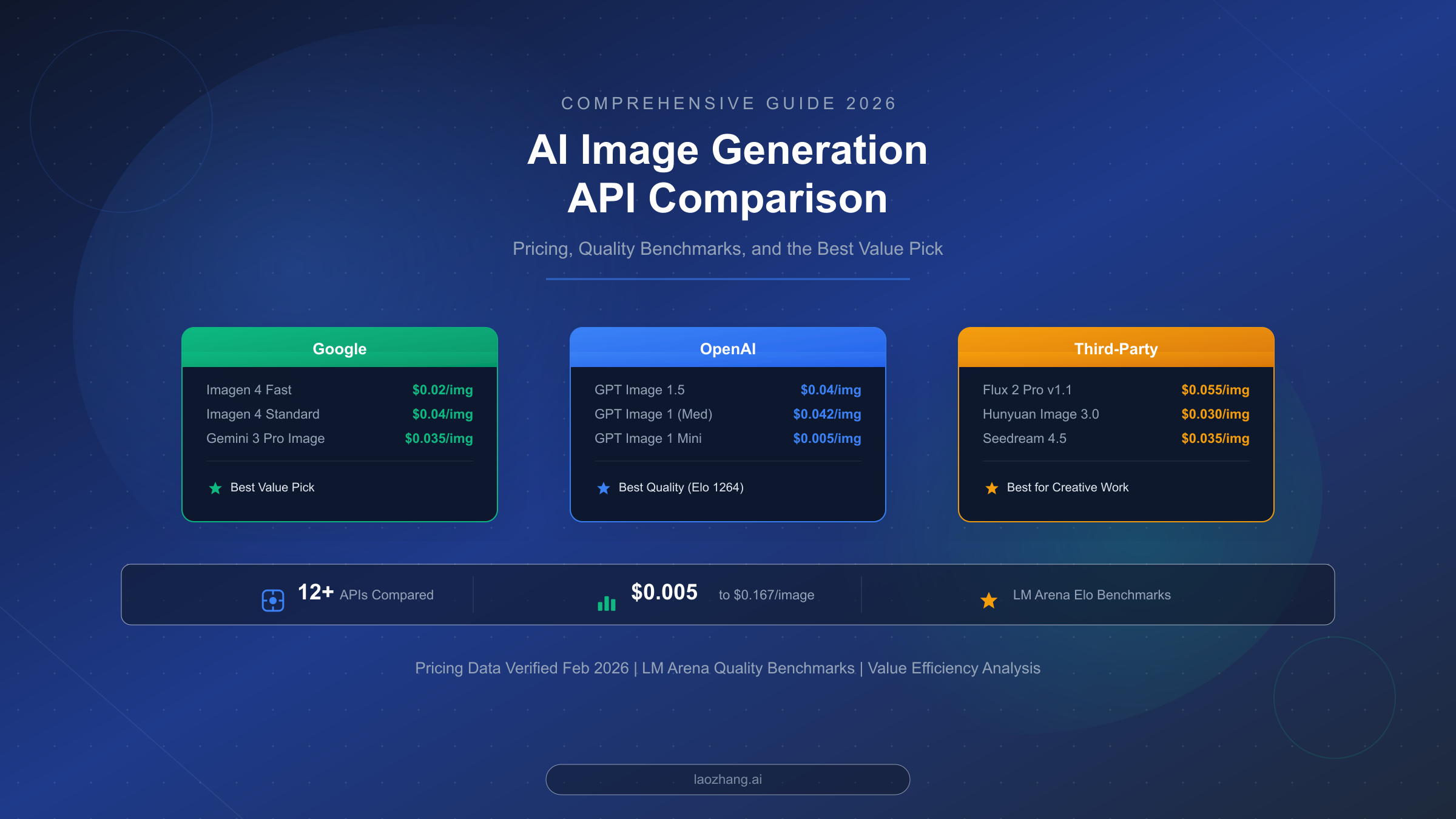







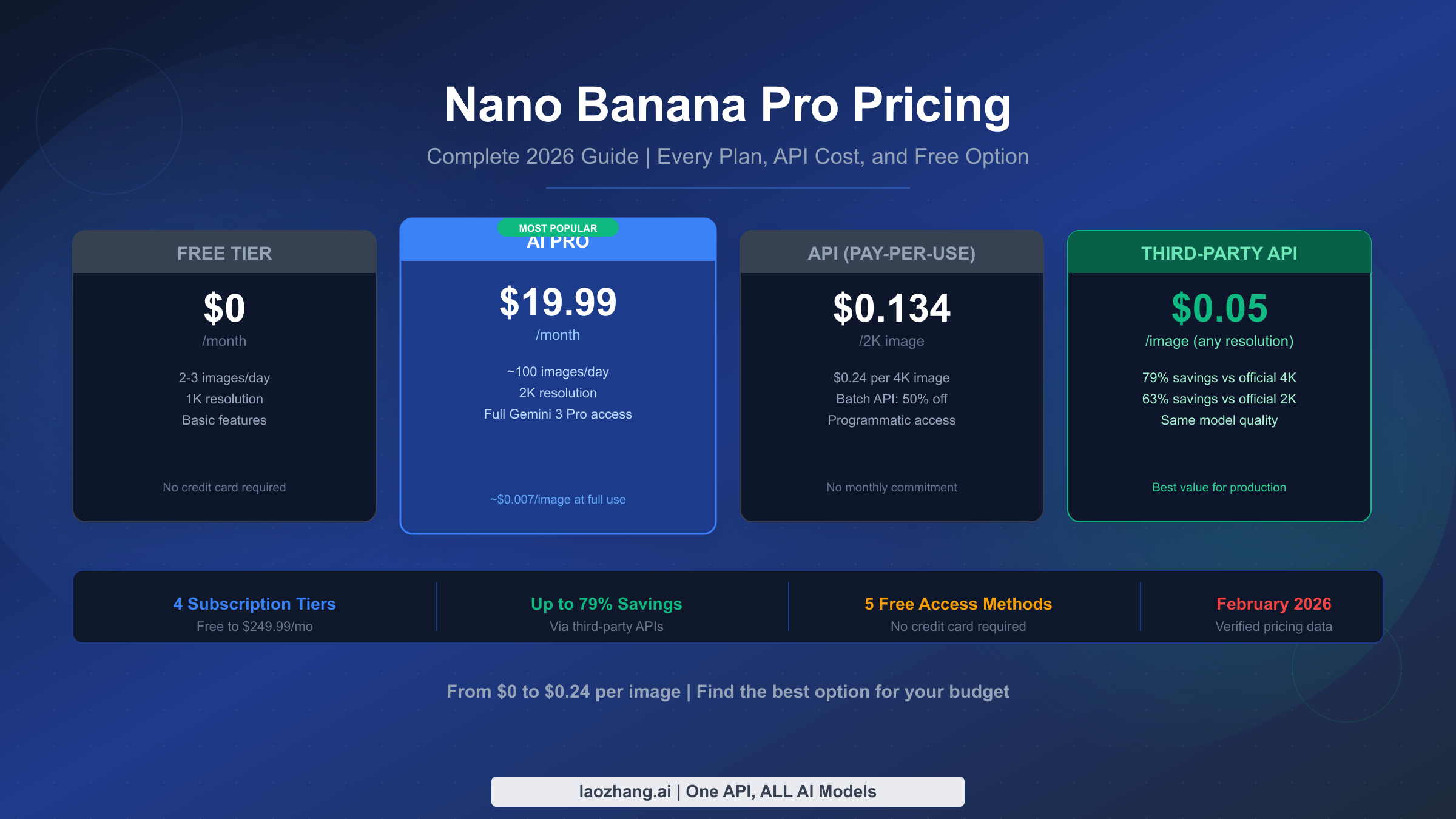
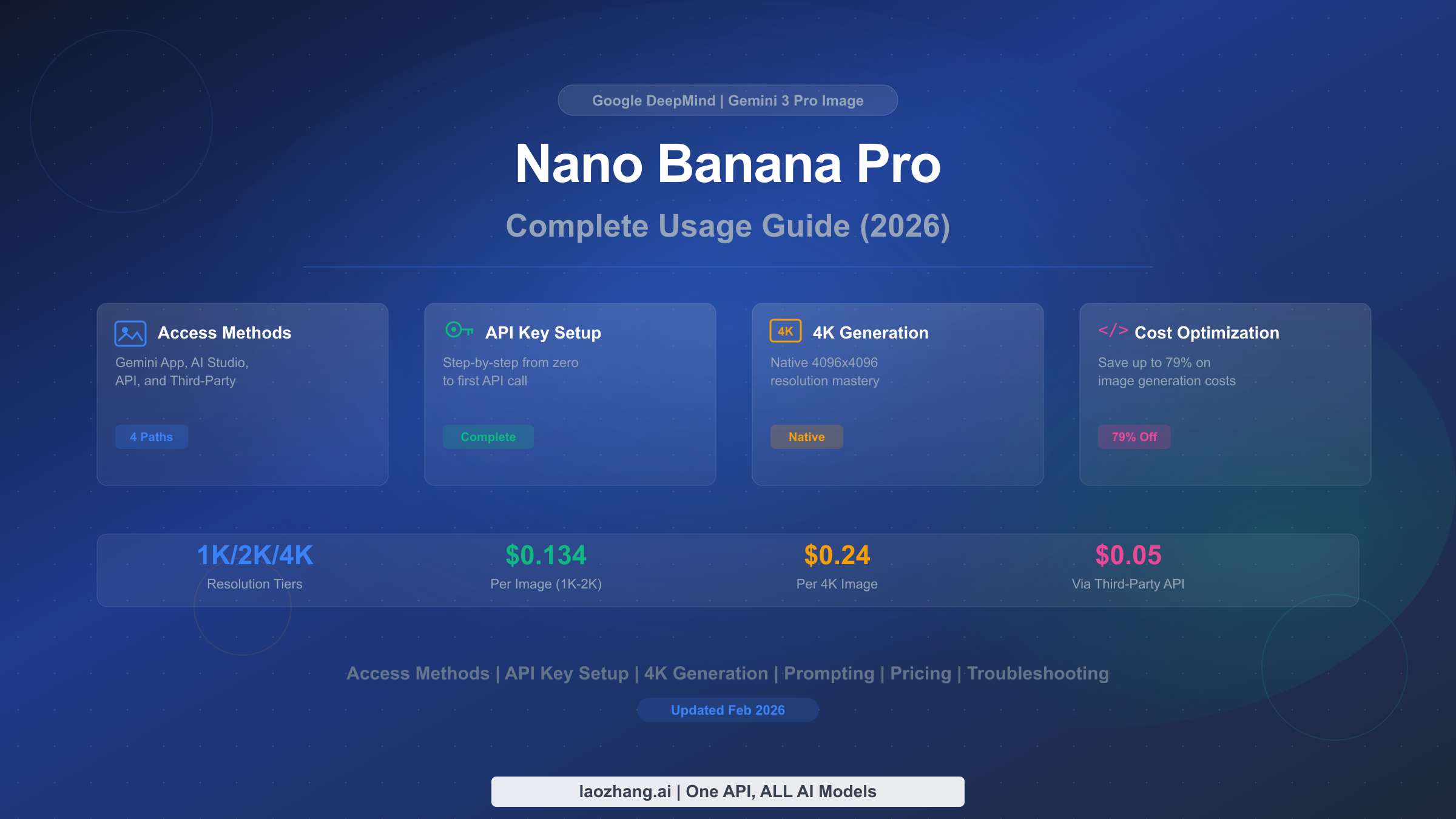
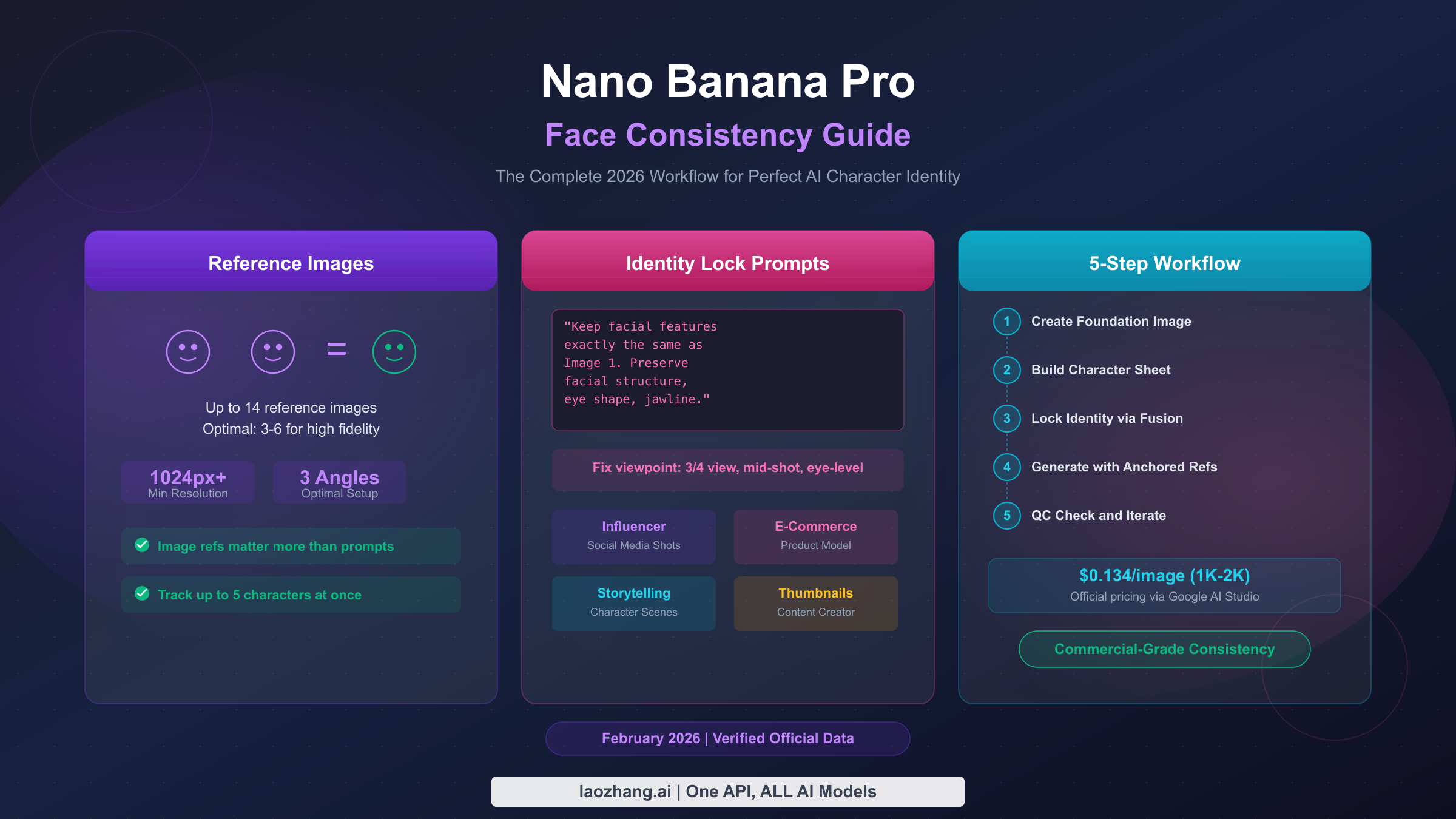





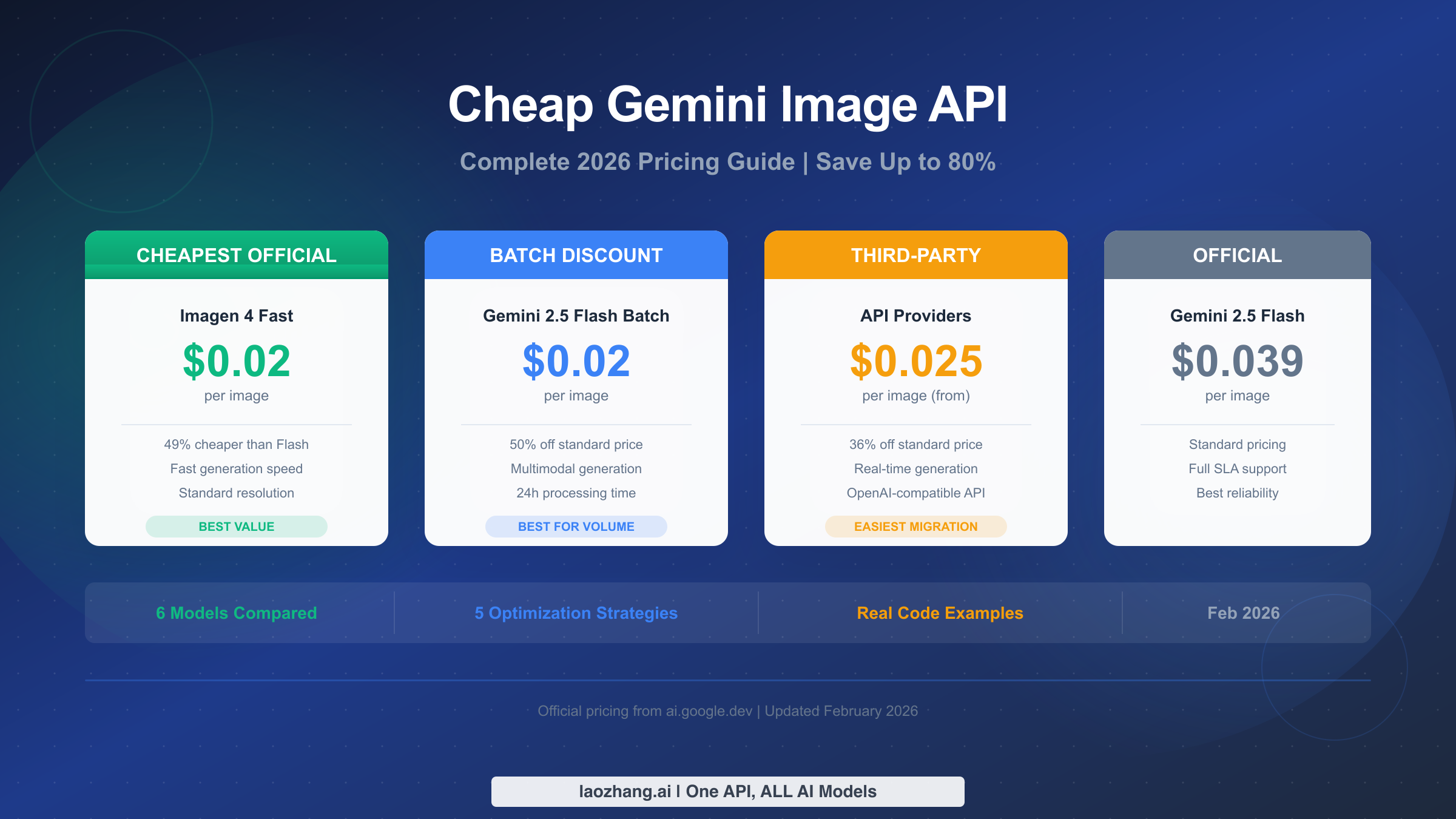
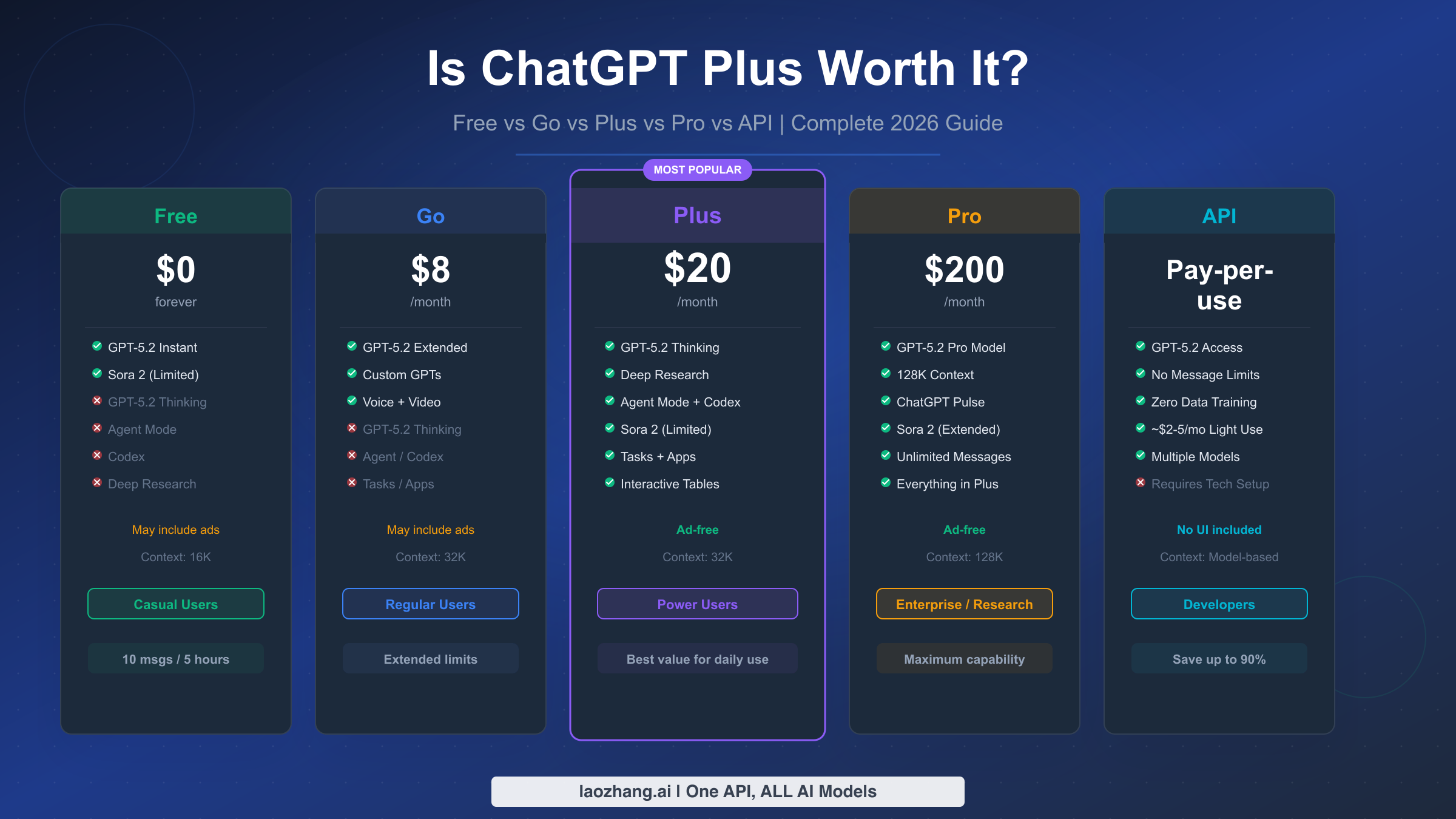


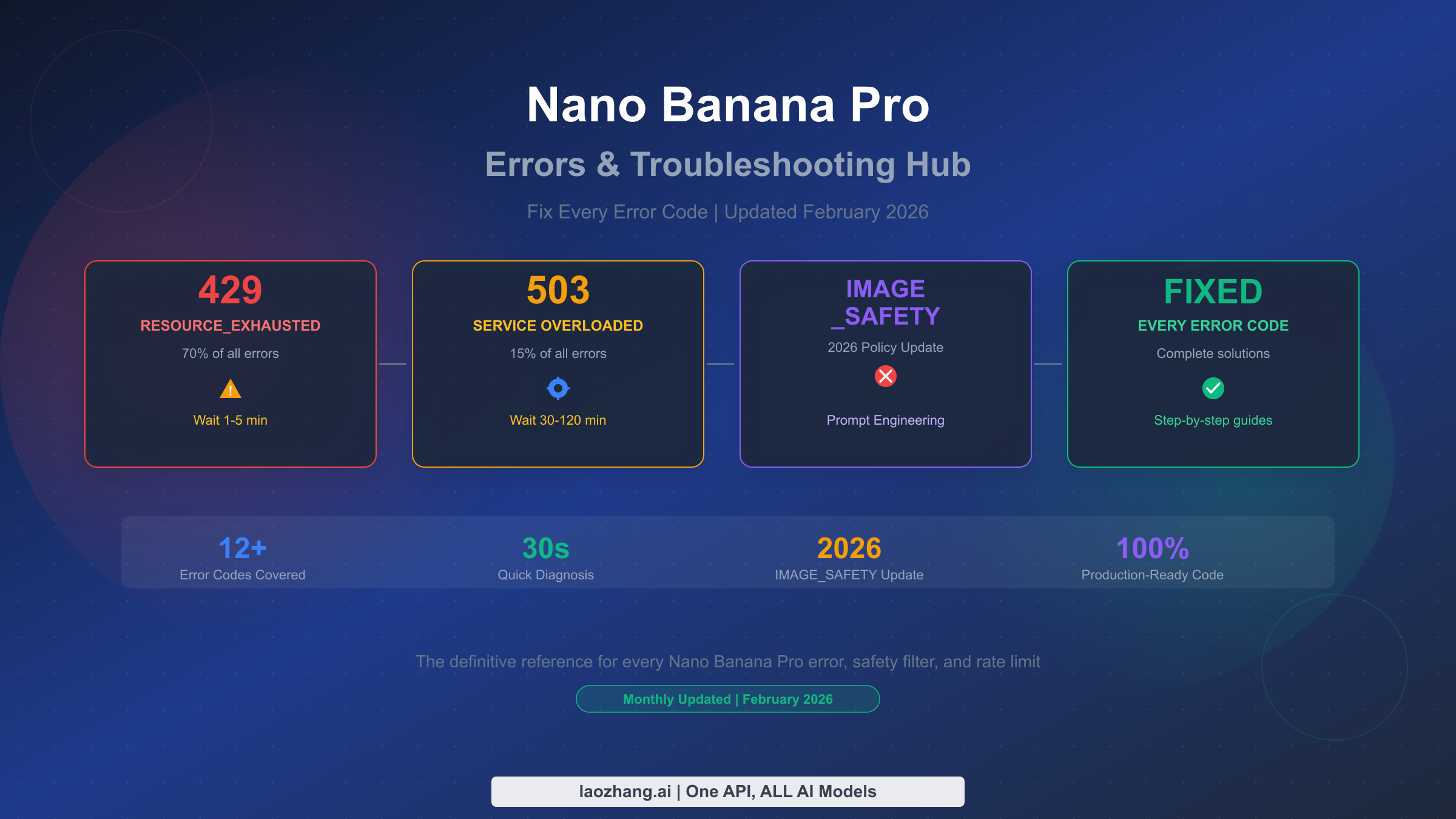

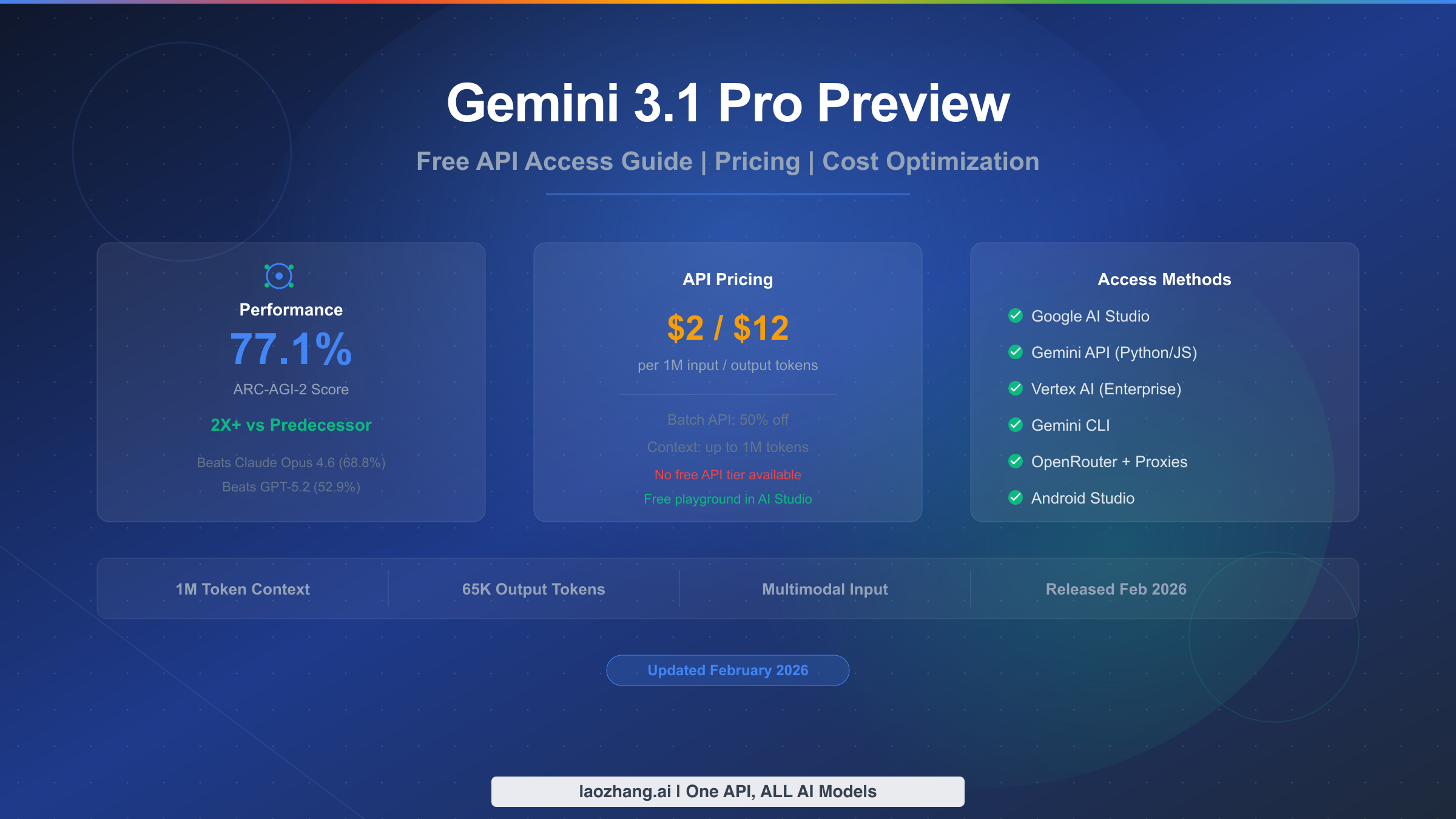
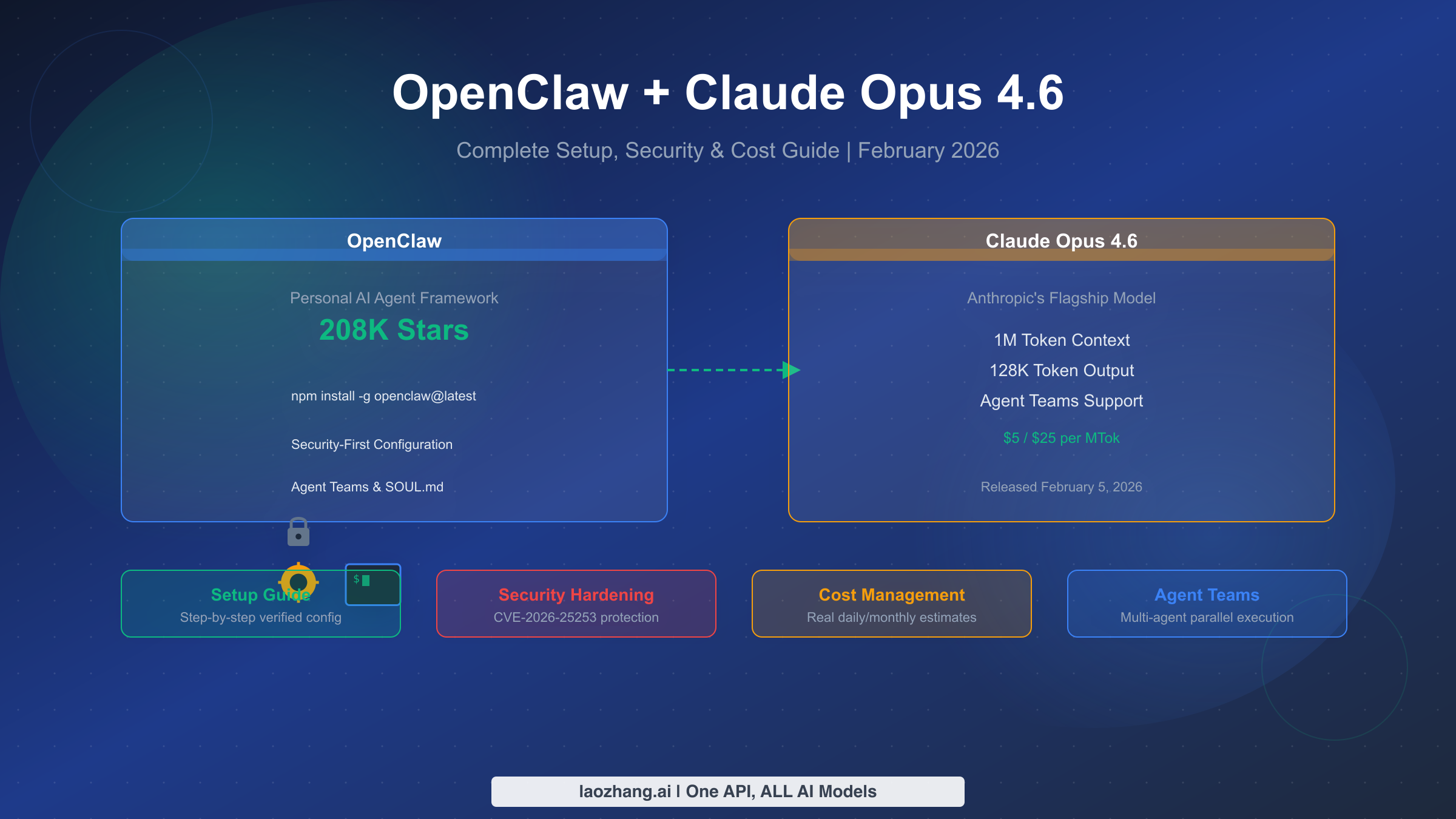

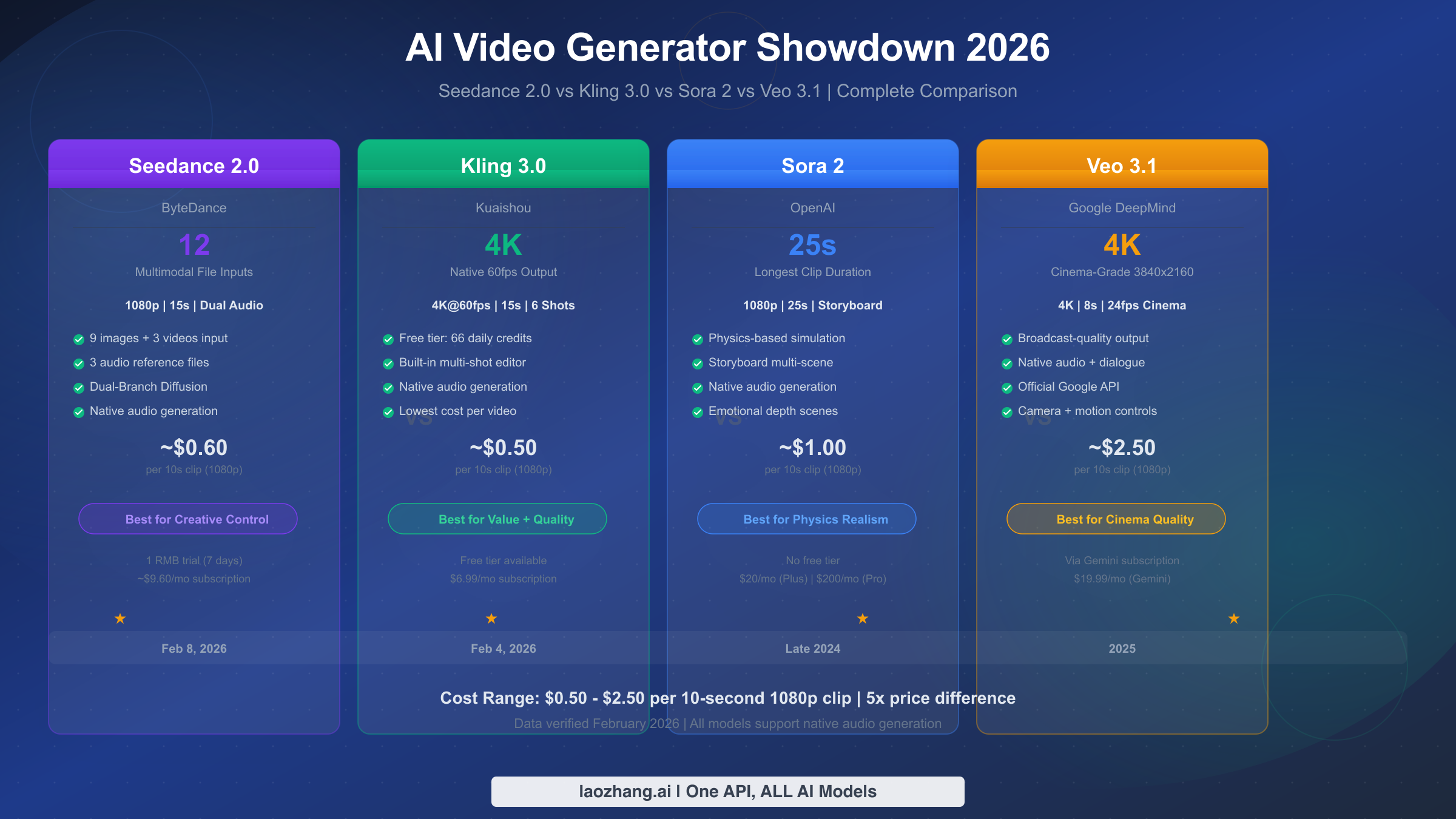
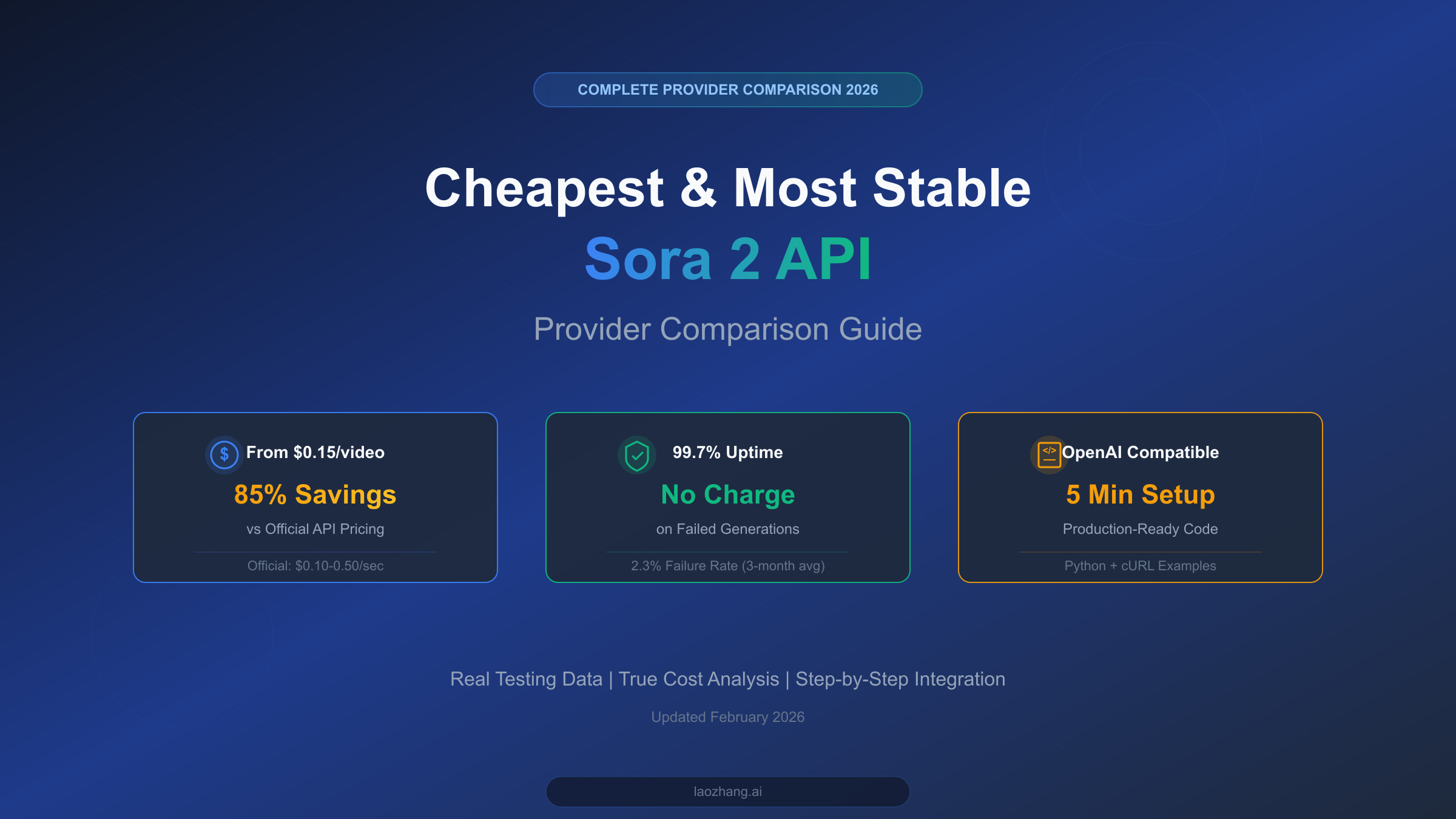





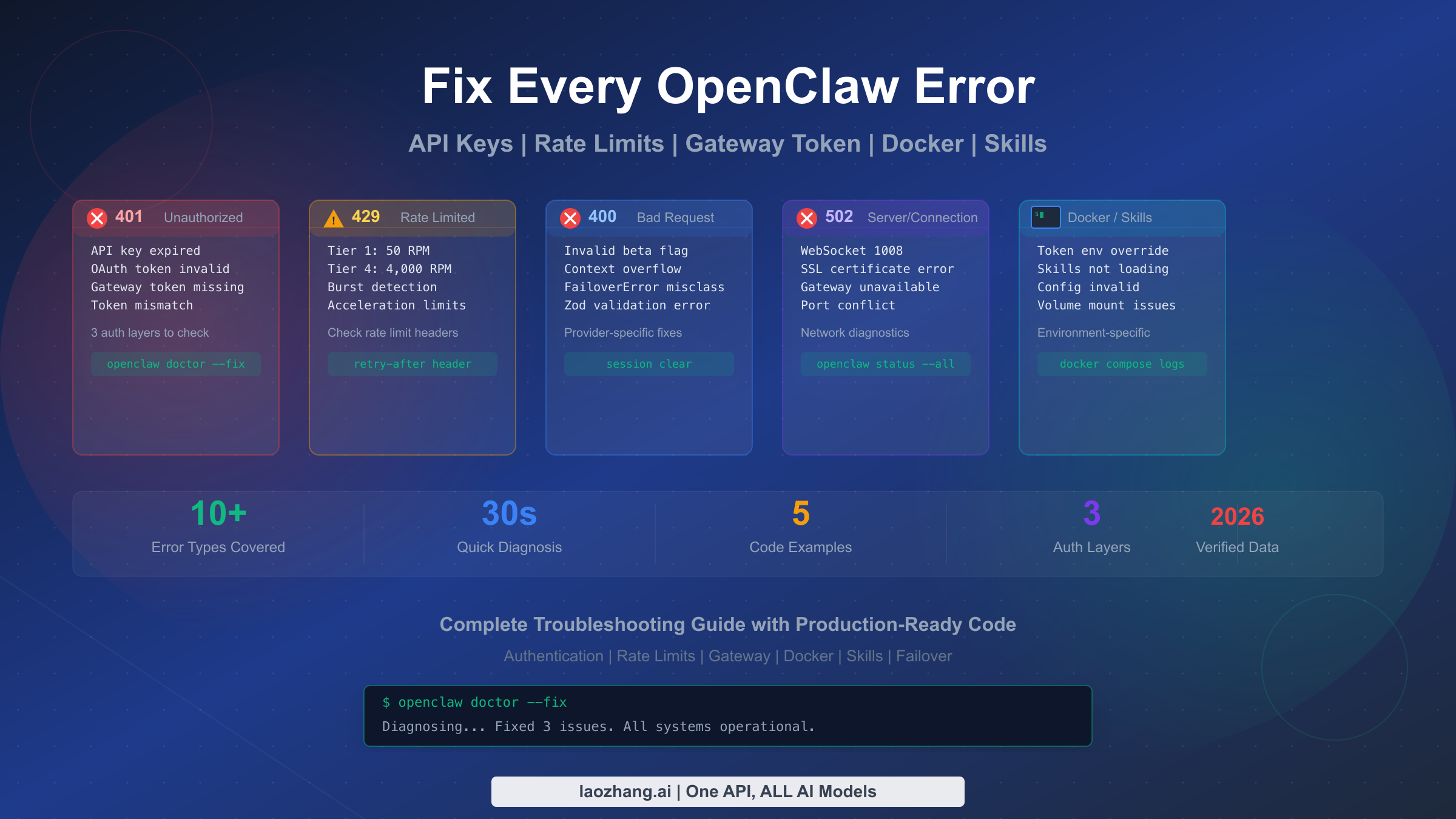


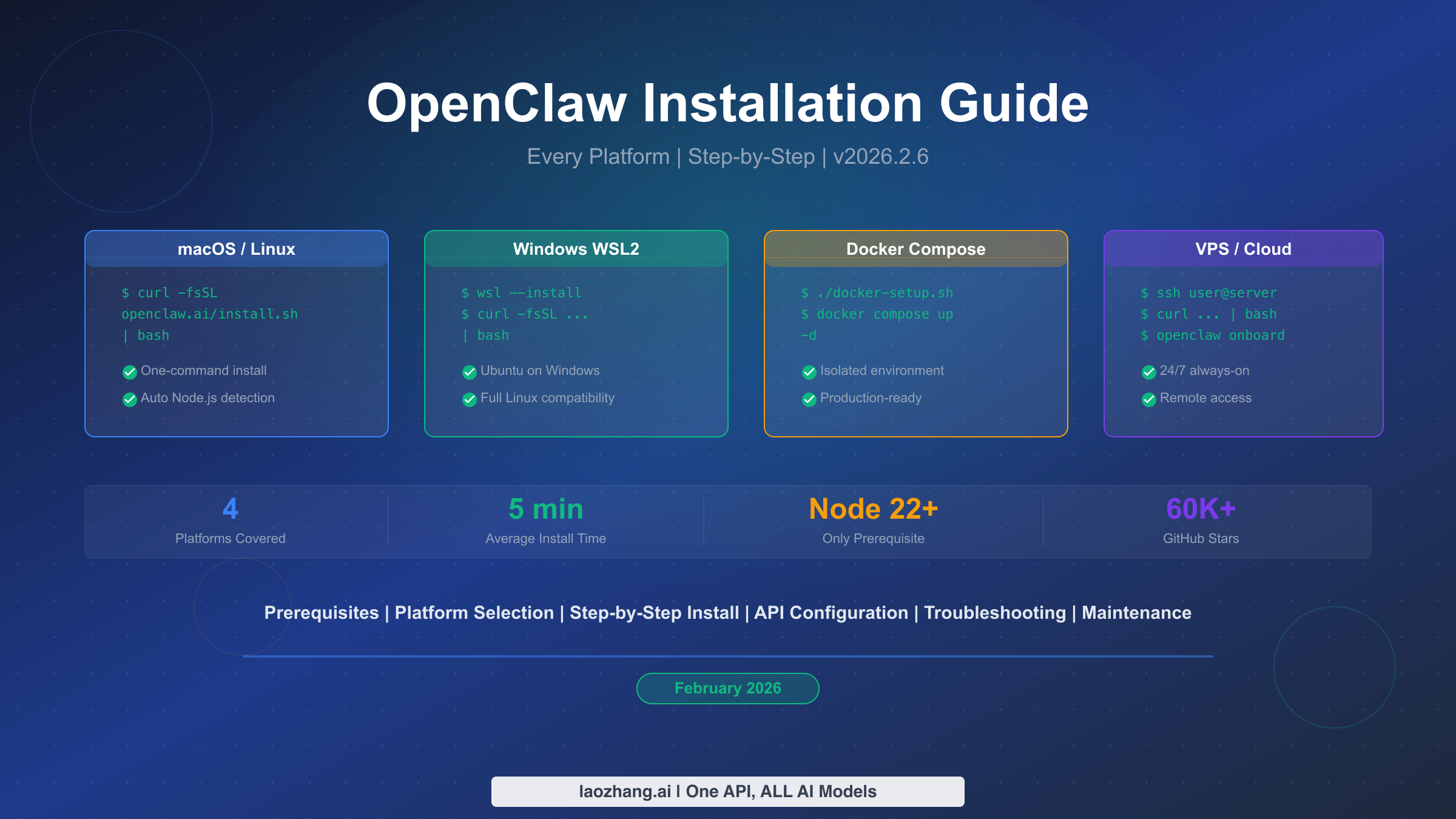
![Fix OpenClaw context_length_exceeded: Complete Troubleshooting Guide [2026]](/posts/en/openclaw-context-length-exceeded/img/cover.png)

![Fix OpenClaw Rate Limit Exceeded (429): Complete Troubleshooting Guide [2026]](/posts/en/openclaw-rate-limit-exceeded-429/img/cover.png)
![Fix OpenClaw Invalid Beta Flag Error: Complete Guide [2026]](/posts/en/openclaw-invalid-beta-flag/img/cover.png)

![Fix OpenClaw Anthropic API Key Error: Complete Guide [2026]](/posts/en/openclaw-anthropic-api-key-error/img/cover.png)
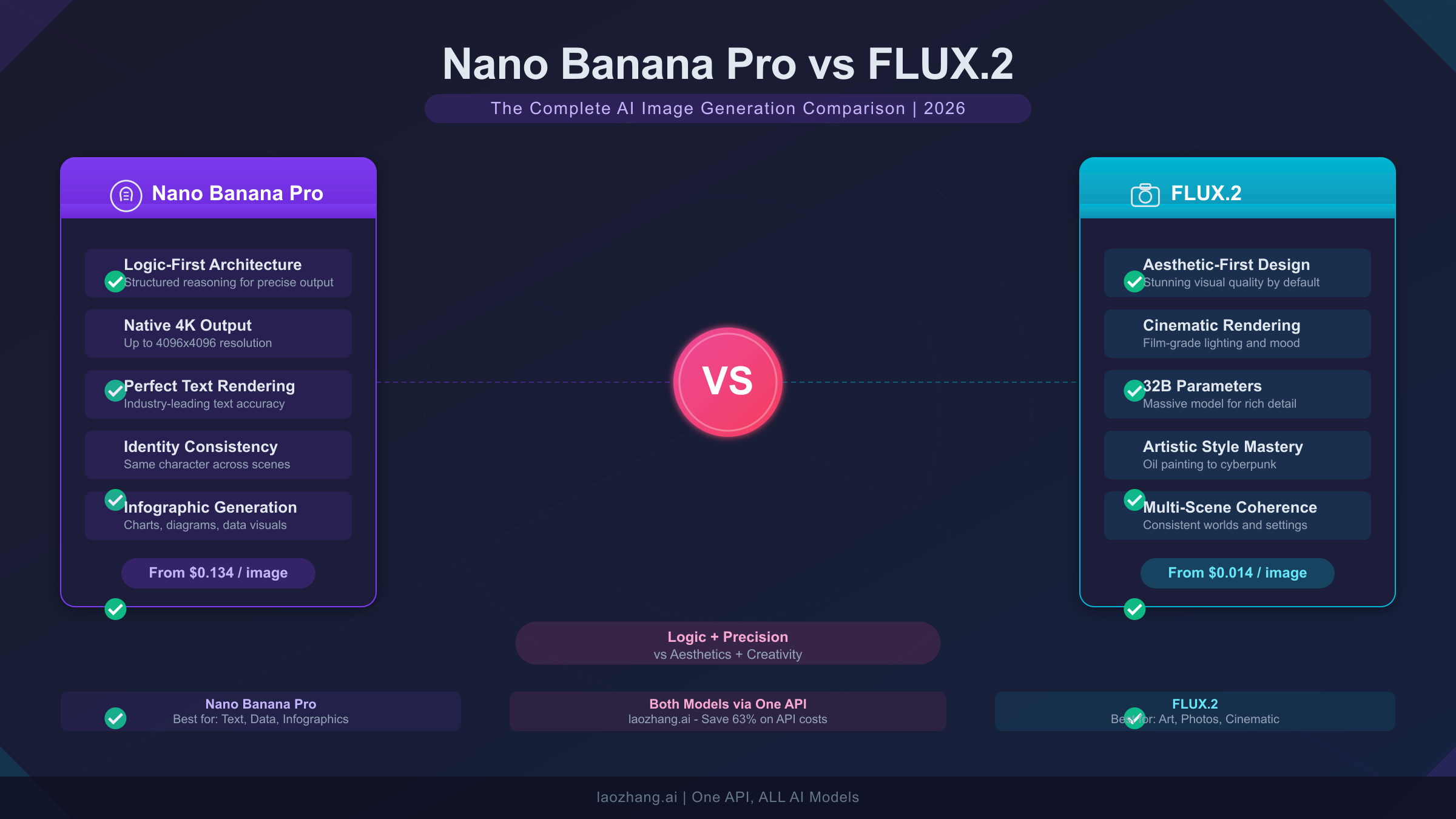
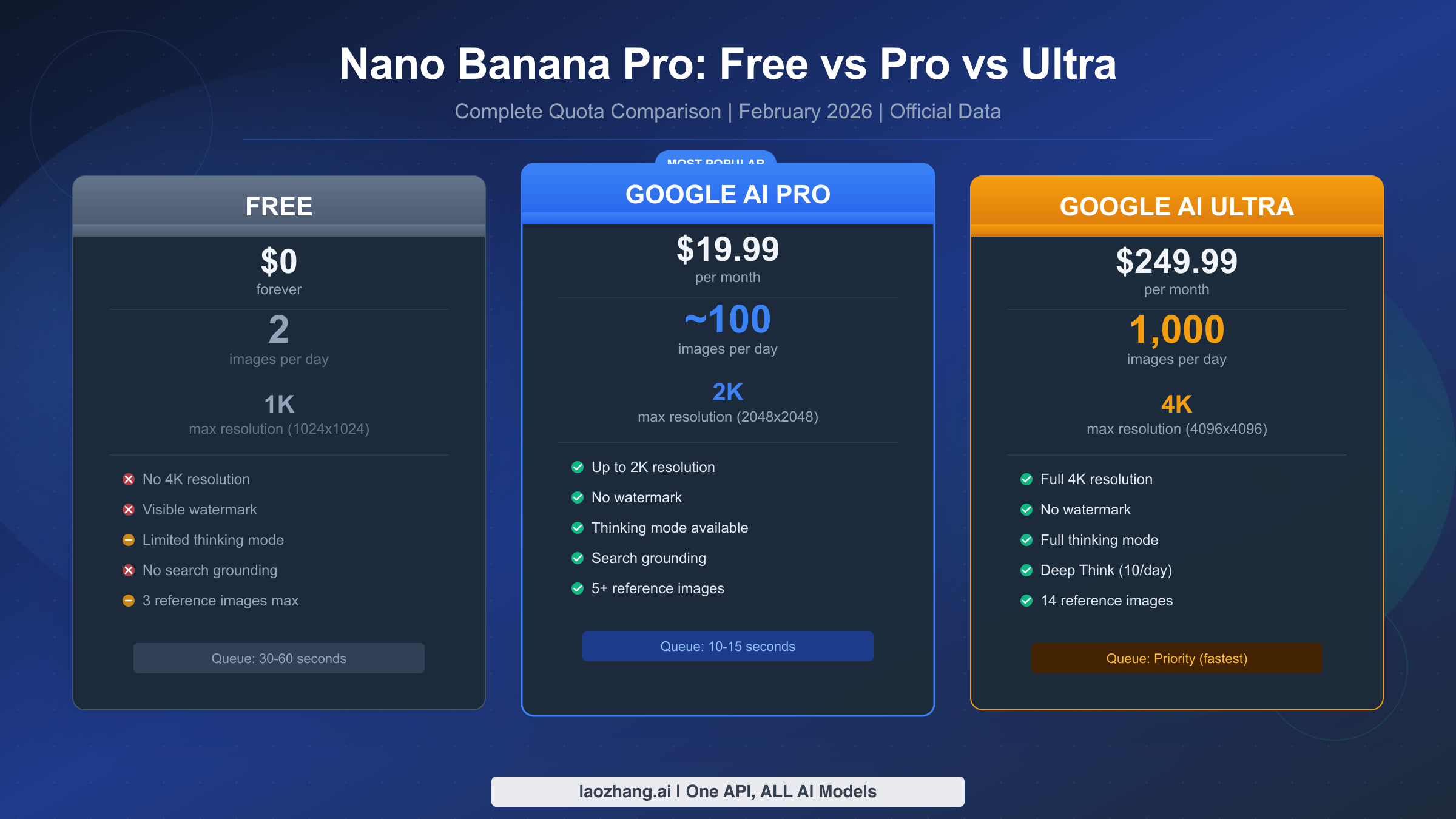
![Gemini 3 Complete Comparison: Pro, Flash, Nano Banana Pro Full Guide [2026 Update]](/posts/en/gemini-3-comparison/img/cover.png)