AI Subscriptions
Read Now
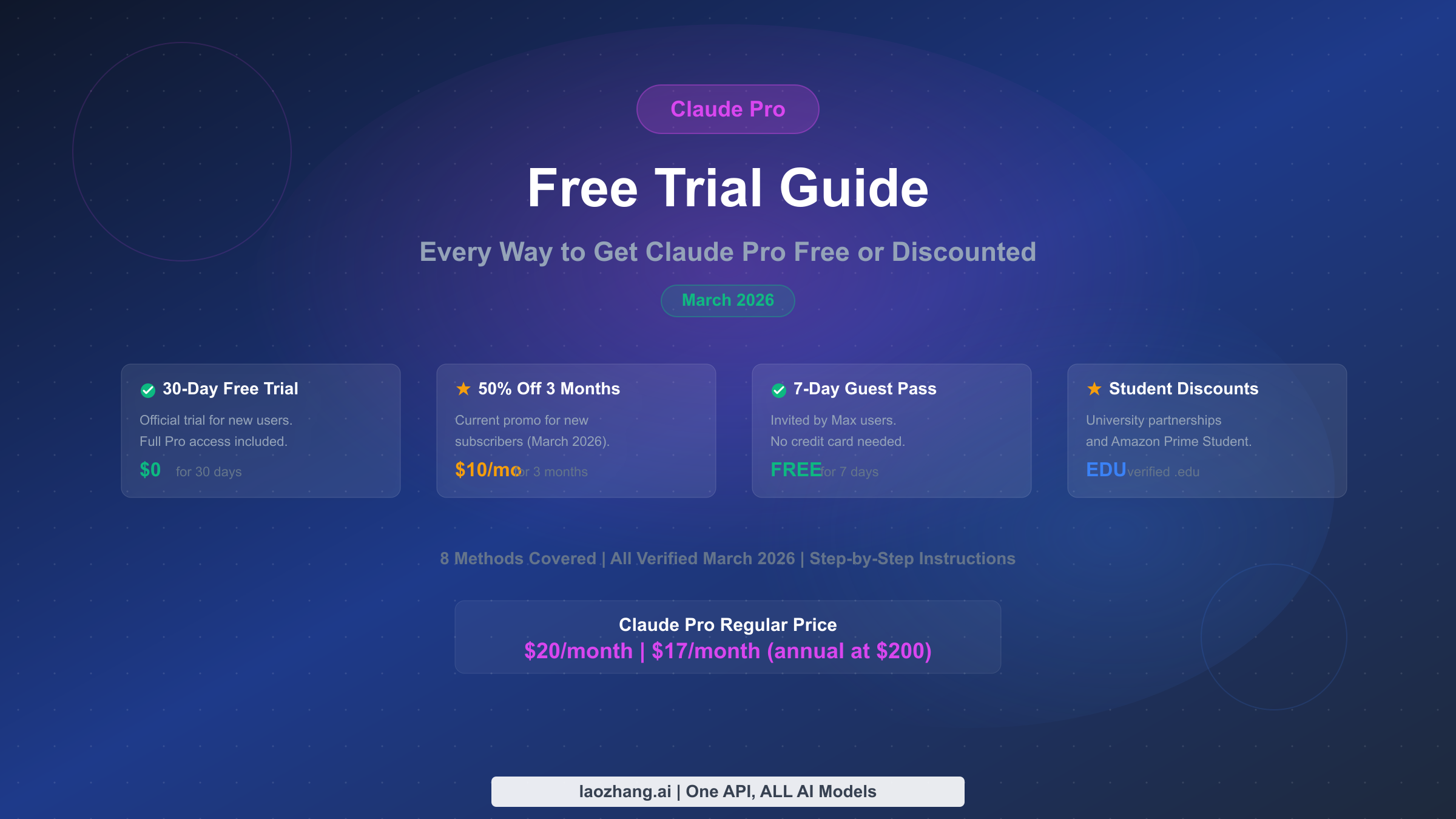
Claude Pro Free Trial 2026: Every Way to Get It Free or Discounted
Yes, Claude Pro has a free trial. New users get 30 days free with a payment method. There are also 50% off promotions, 7-day Guest Passes, student discounts, and more. This guide covers all 8 verified ways to access Claude Pro without paying full price in March 2026.
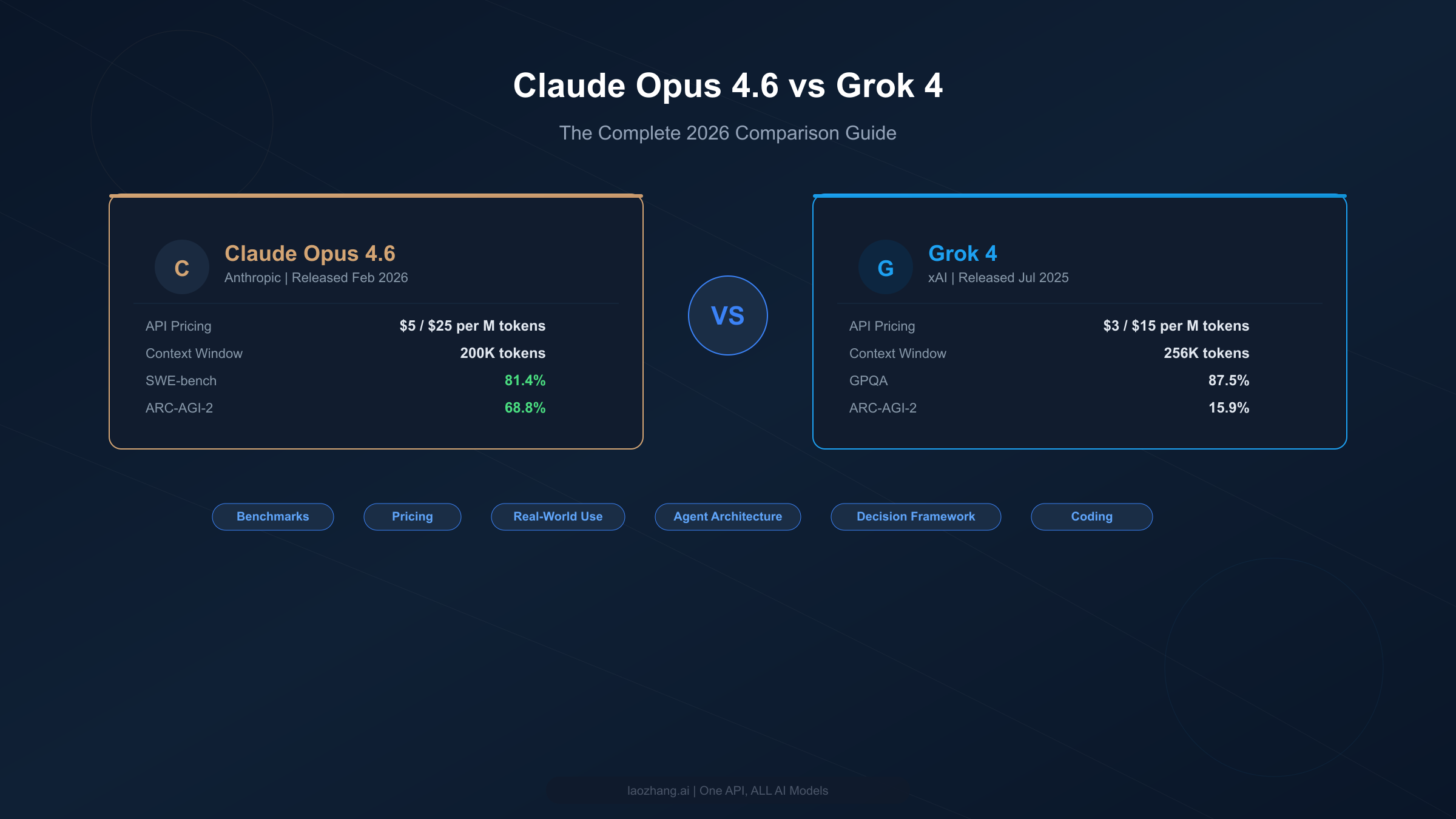


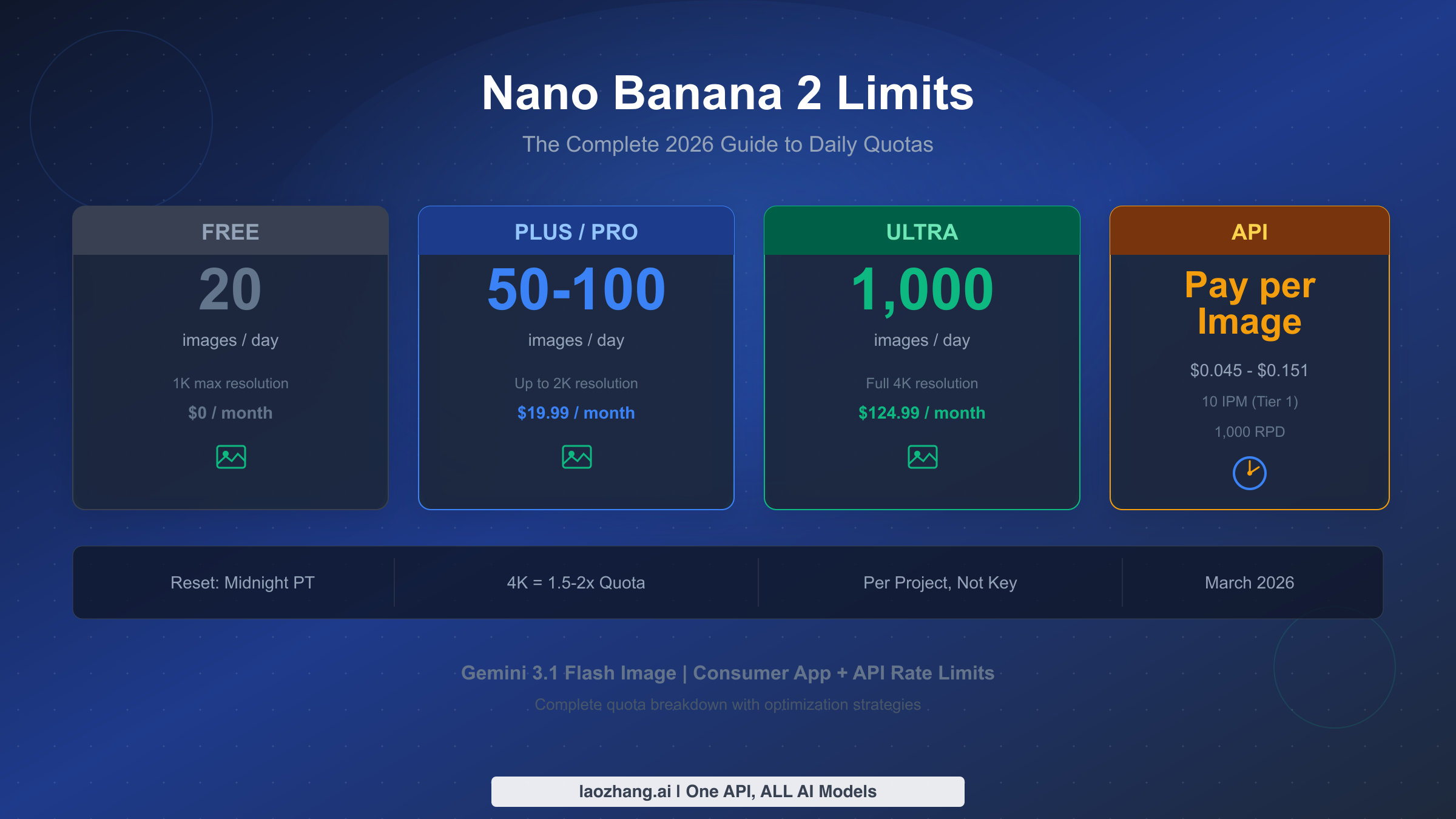
![Nano Banana 2 API Pricing Explained: Official vs Proxy Cost Comparison [2026]](/posts/en/nano-banana-2-api-pricing-guide/img/cover.png)

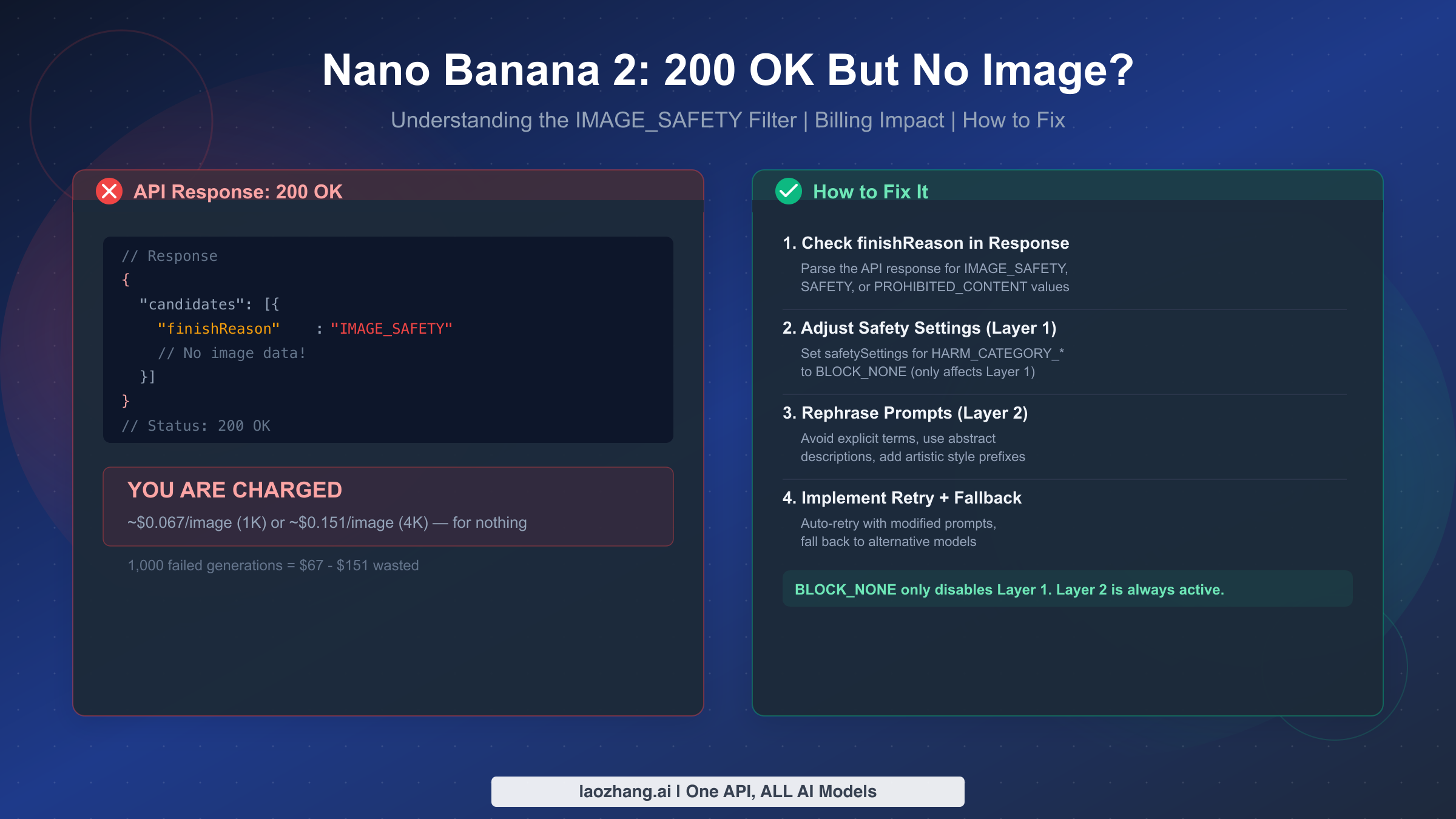


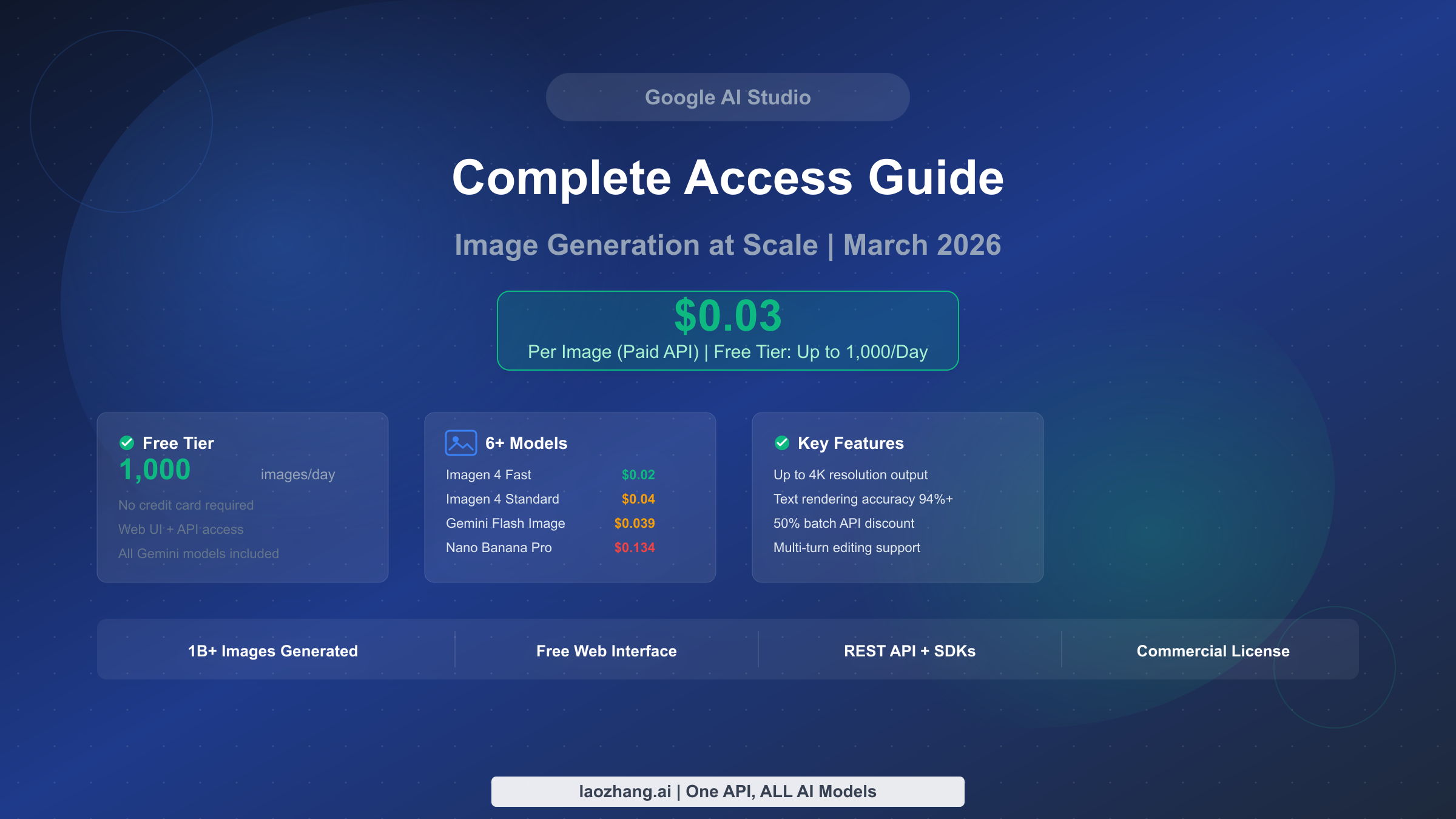
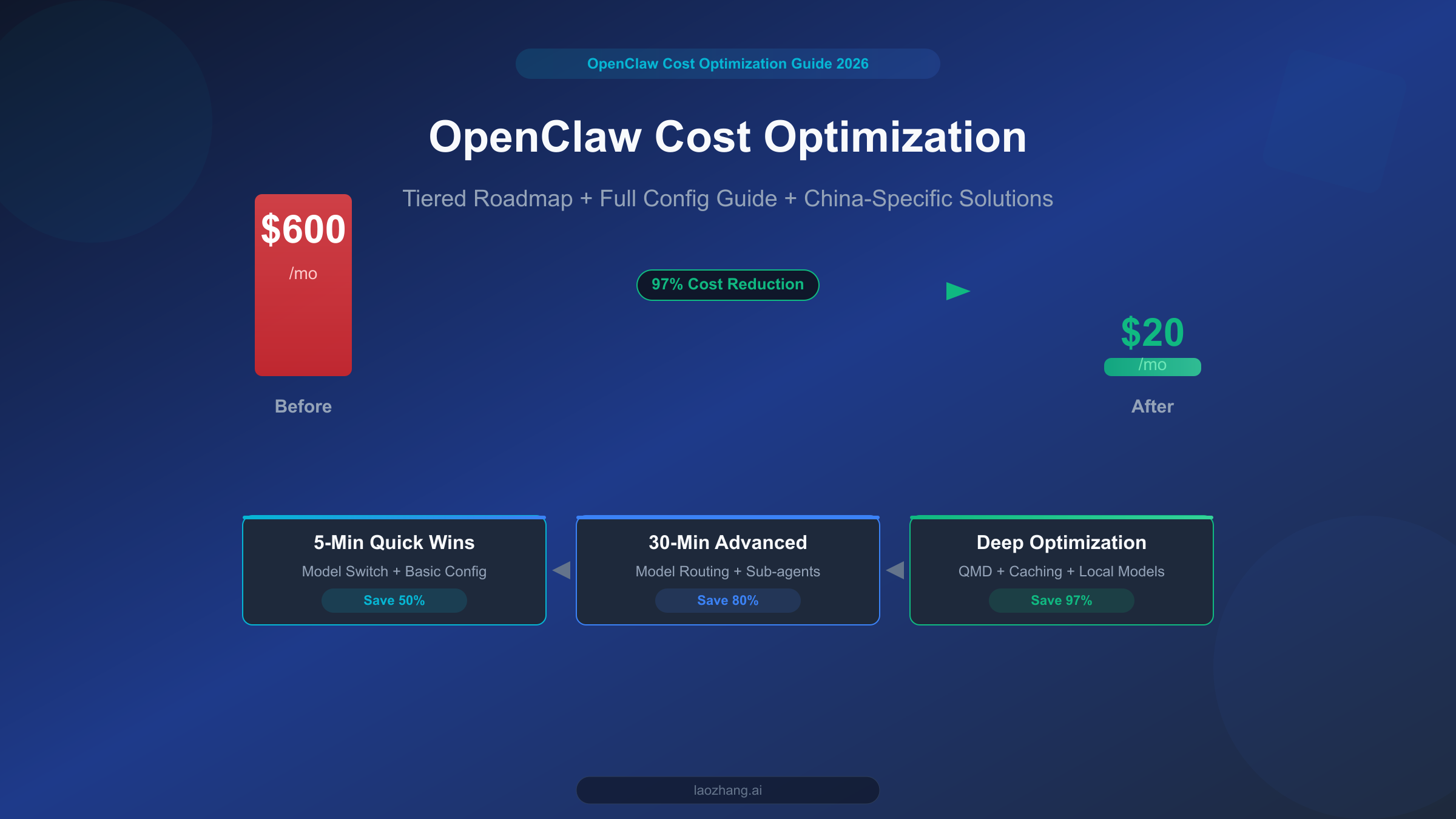
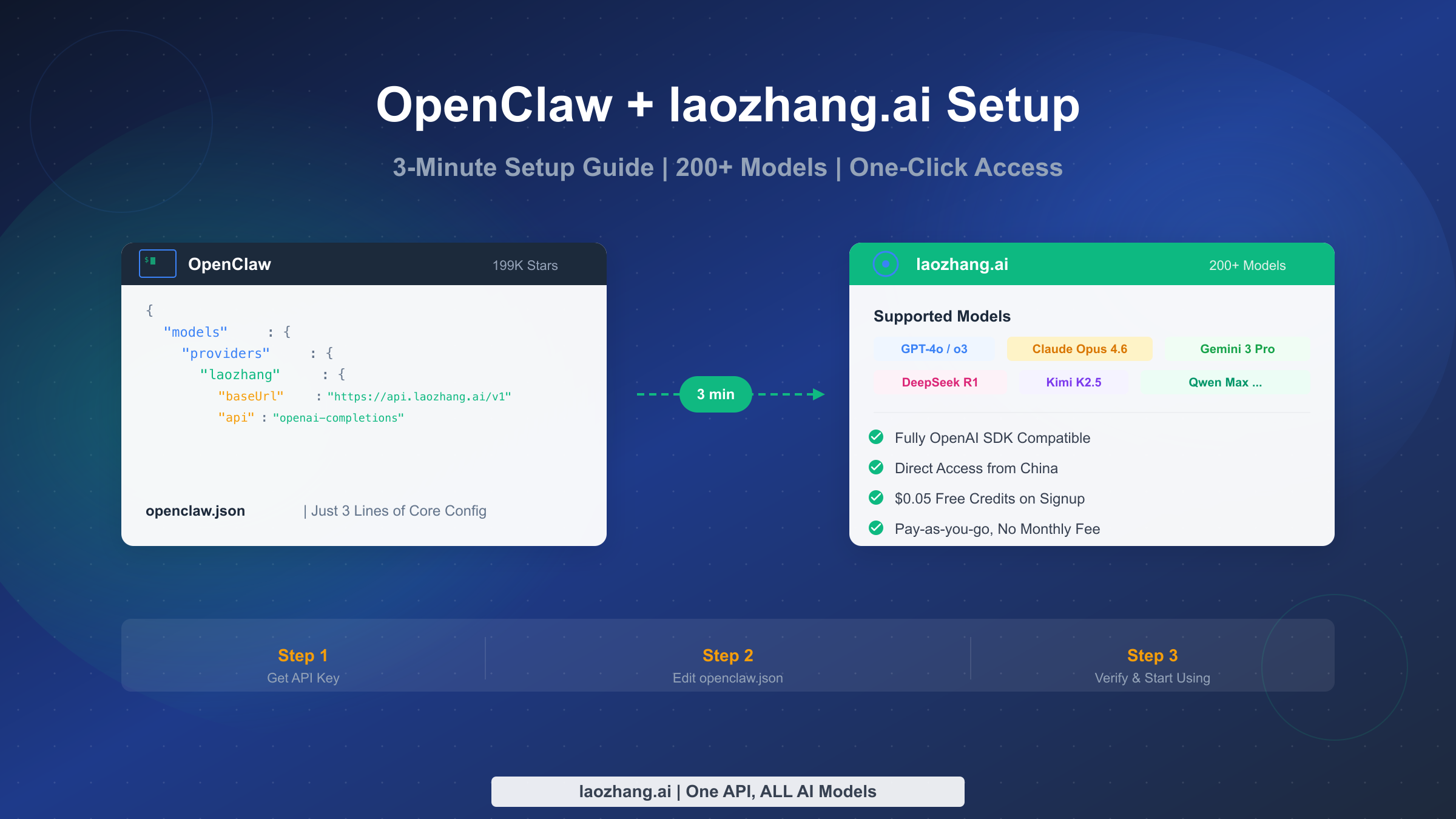

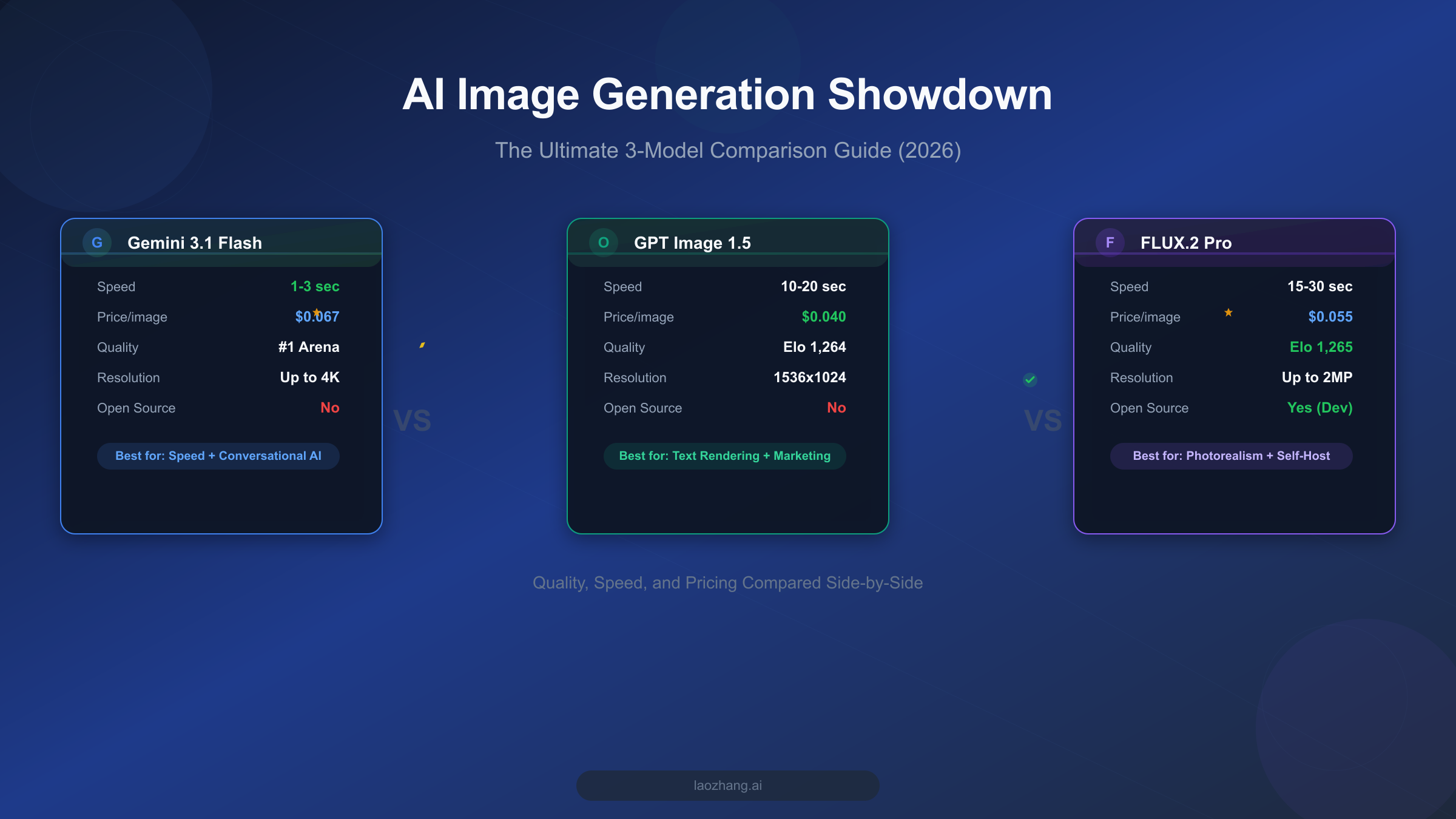

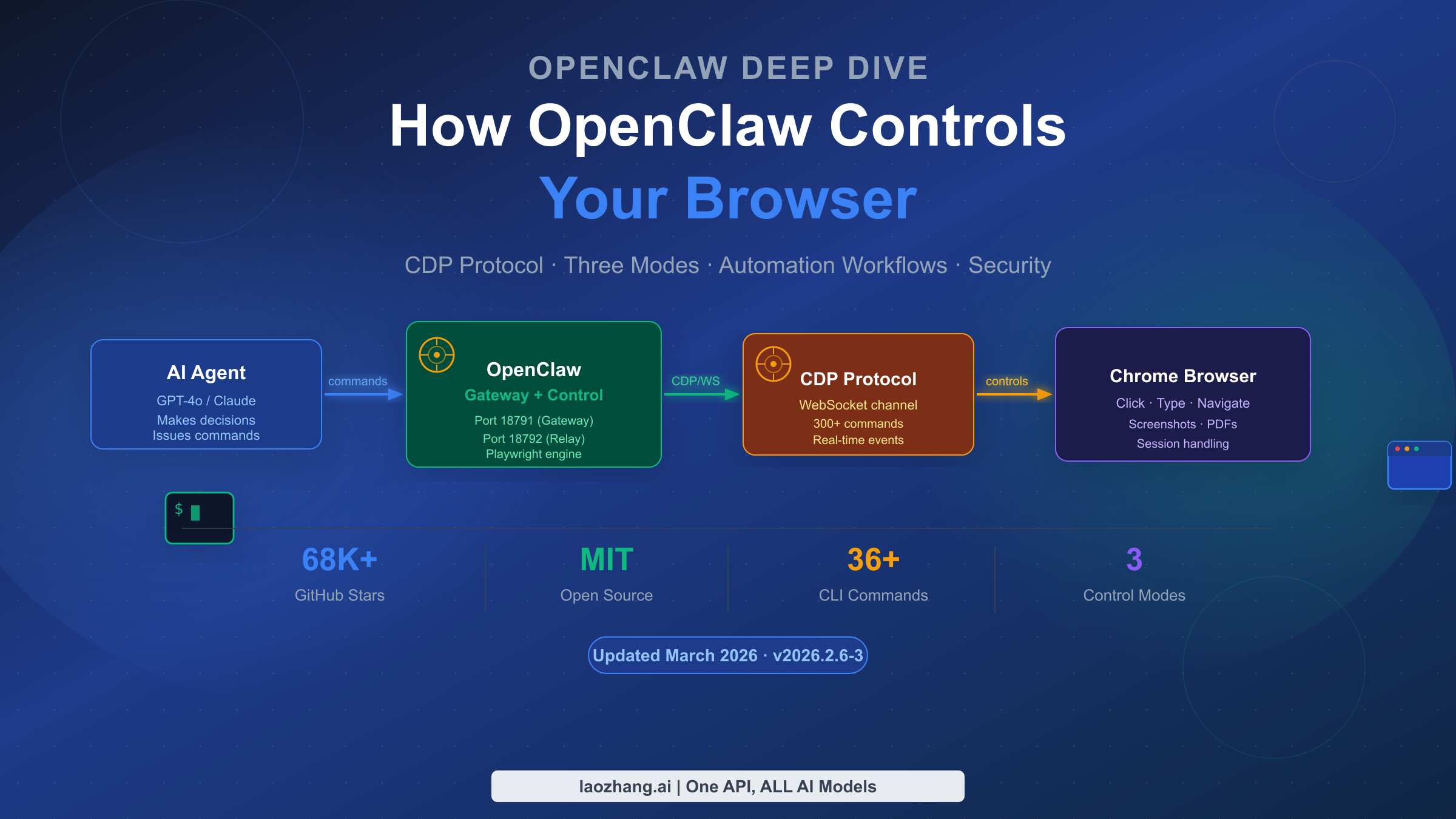
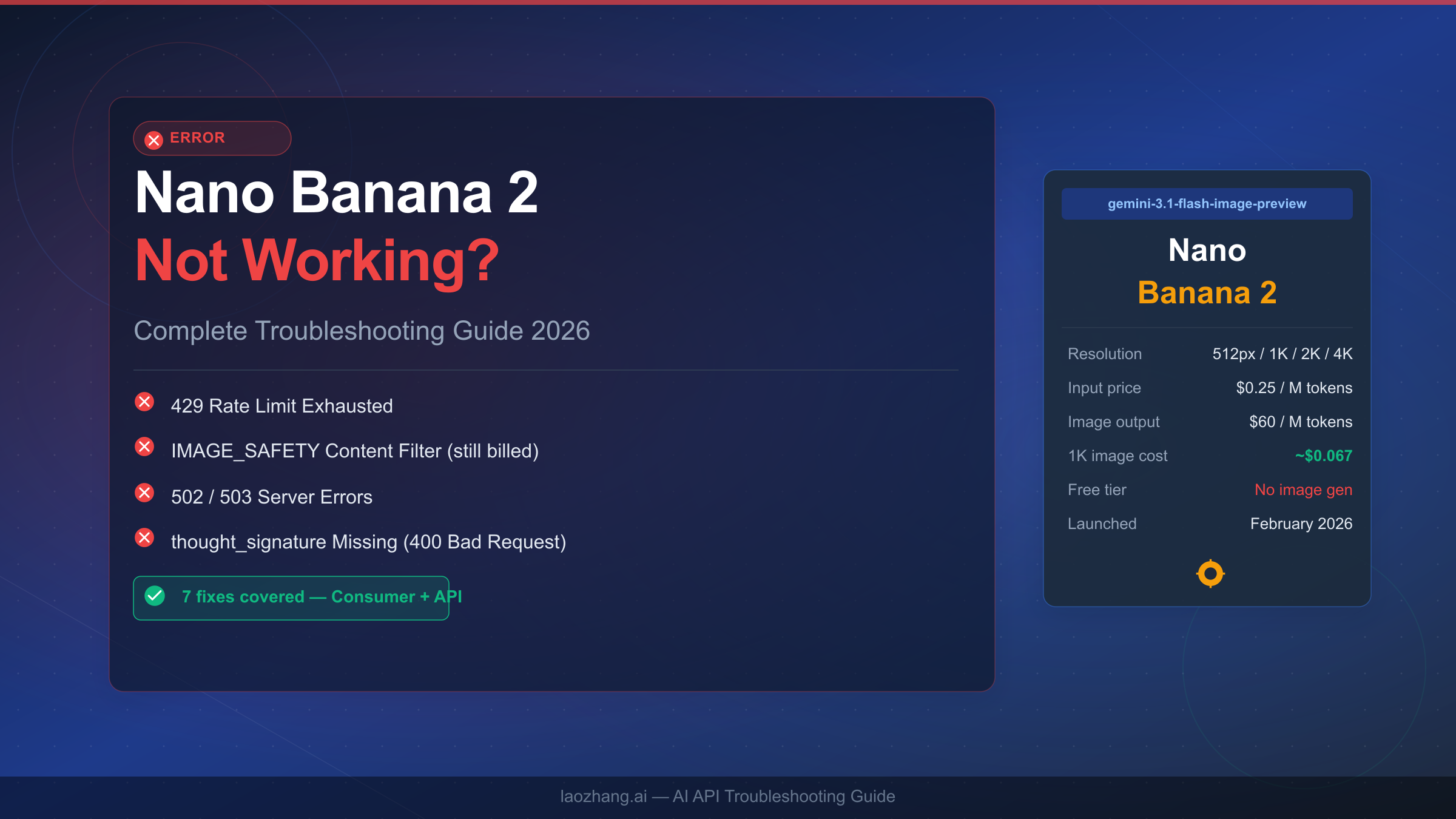
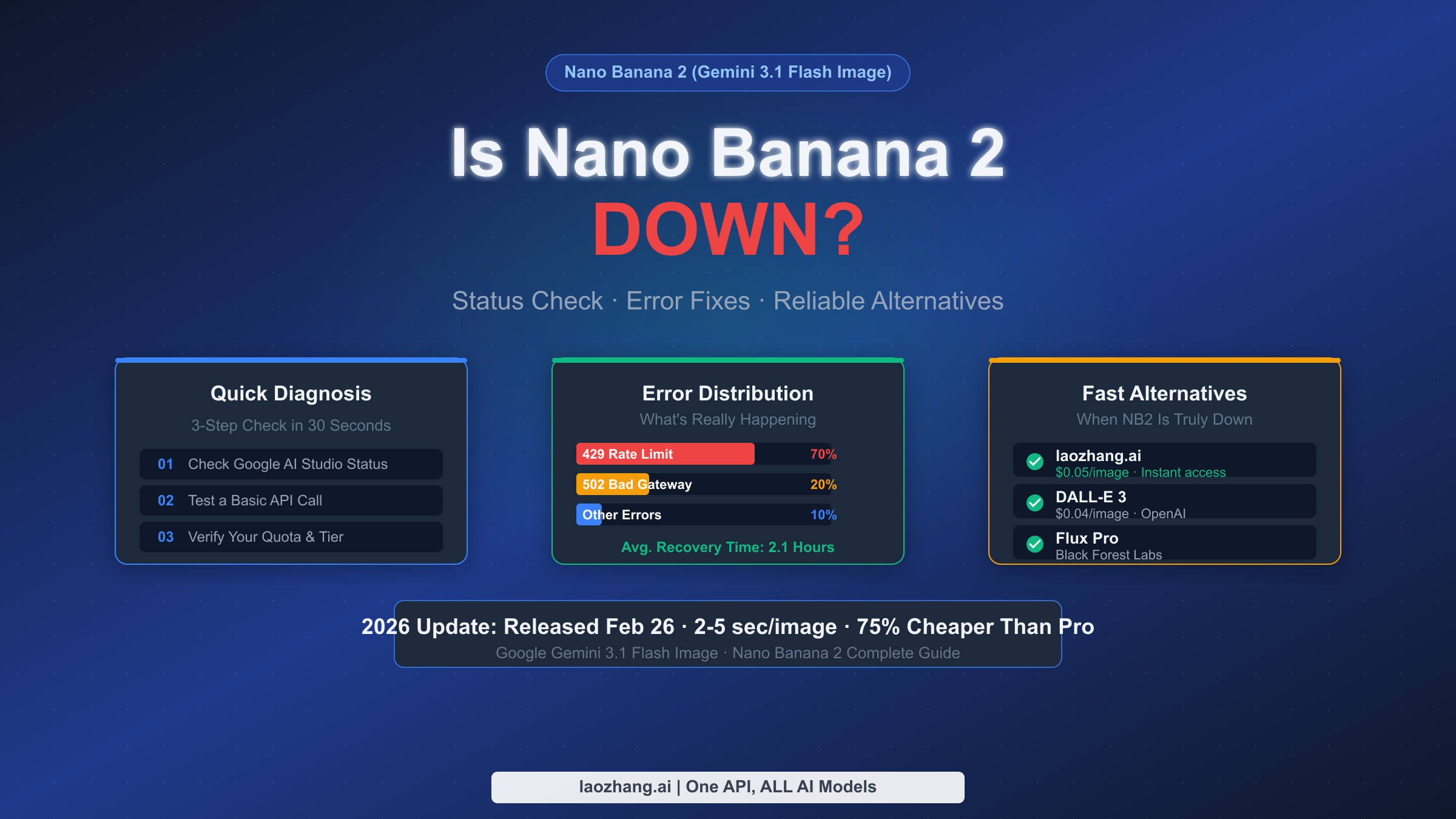
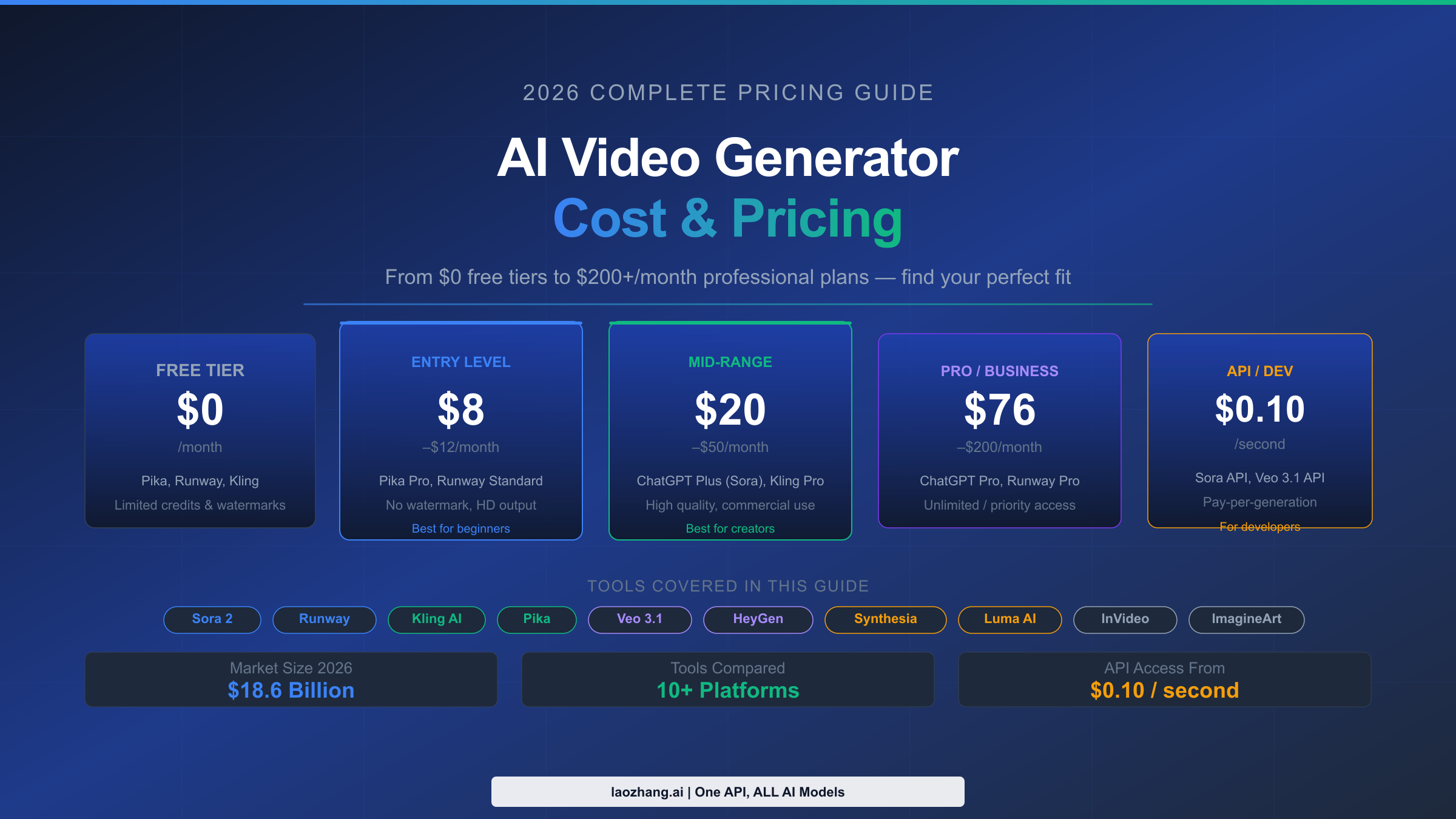



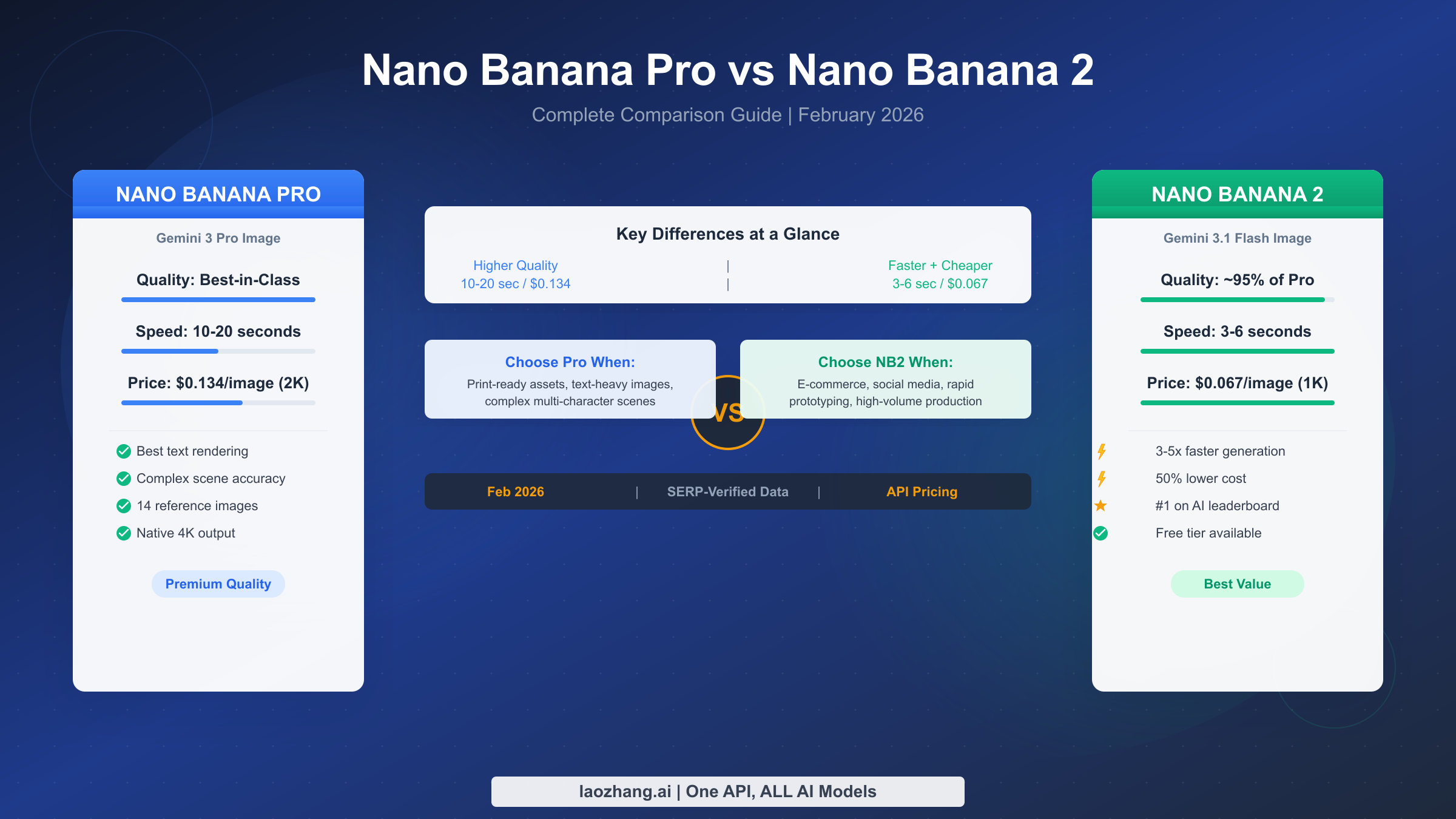
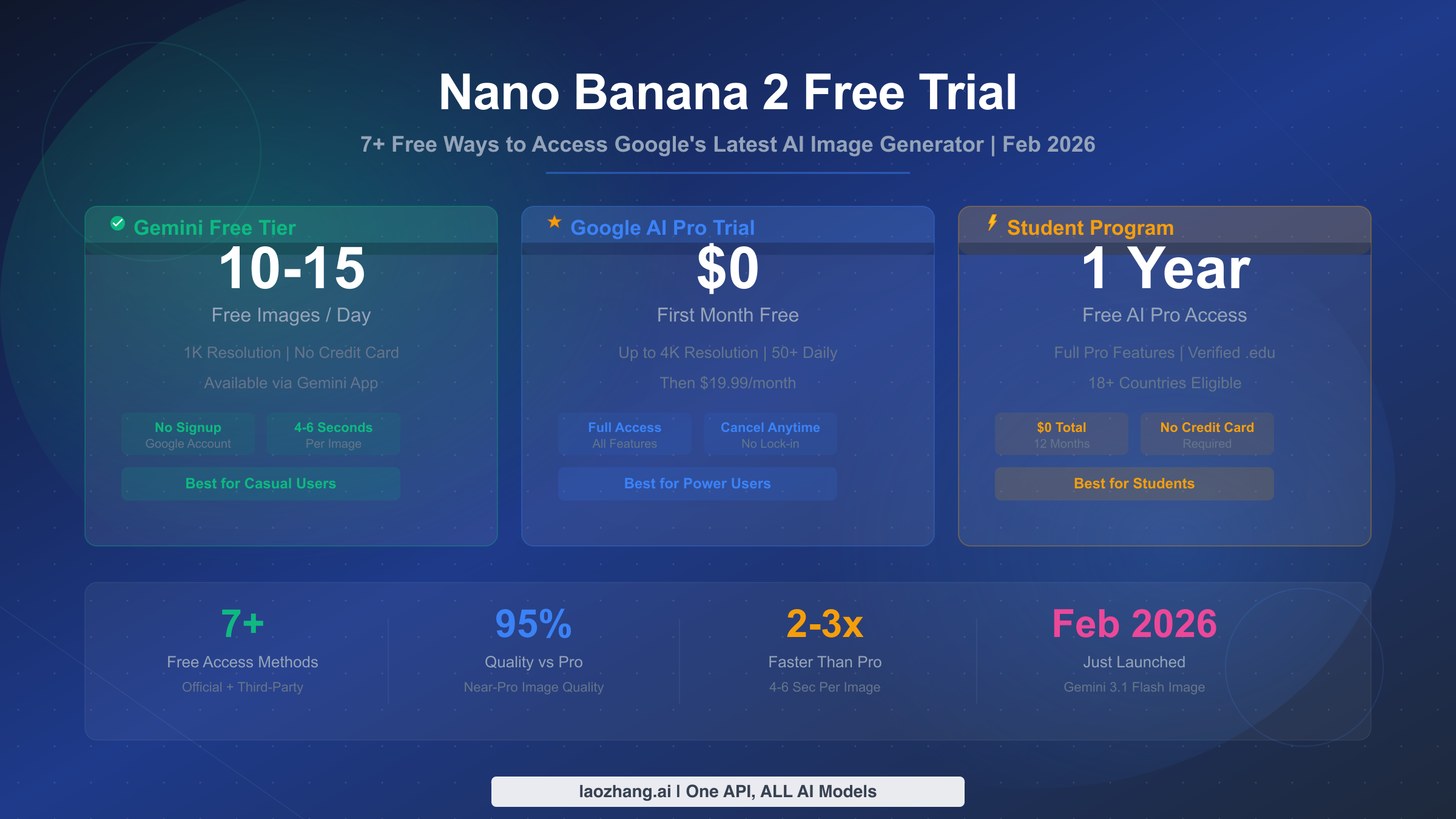
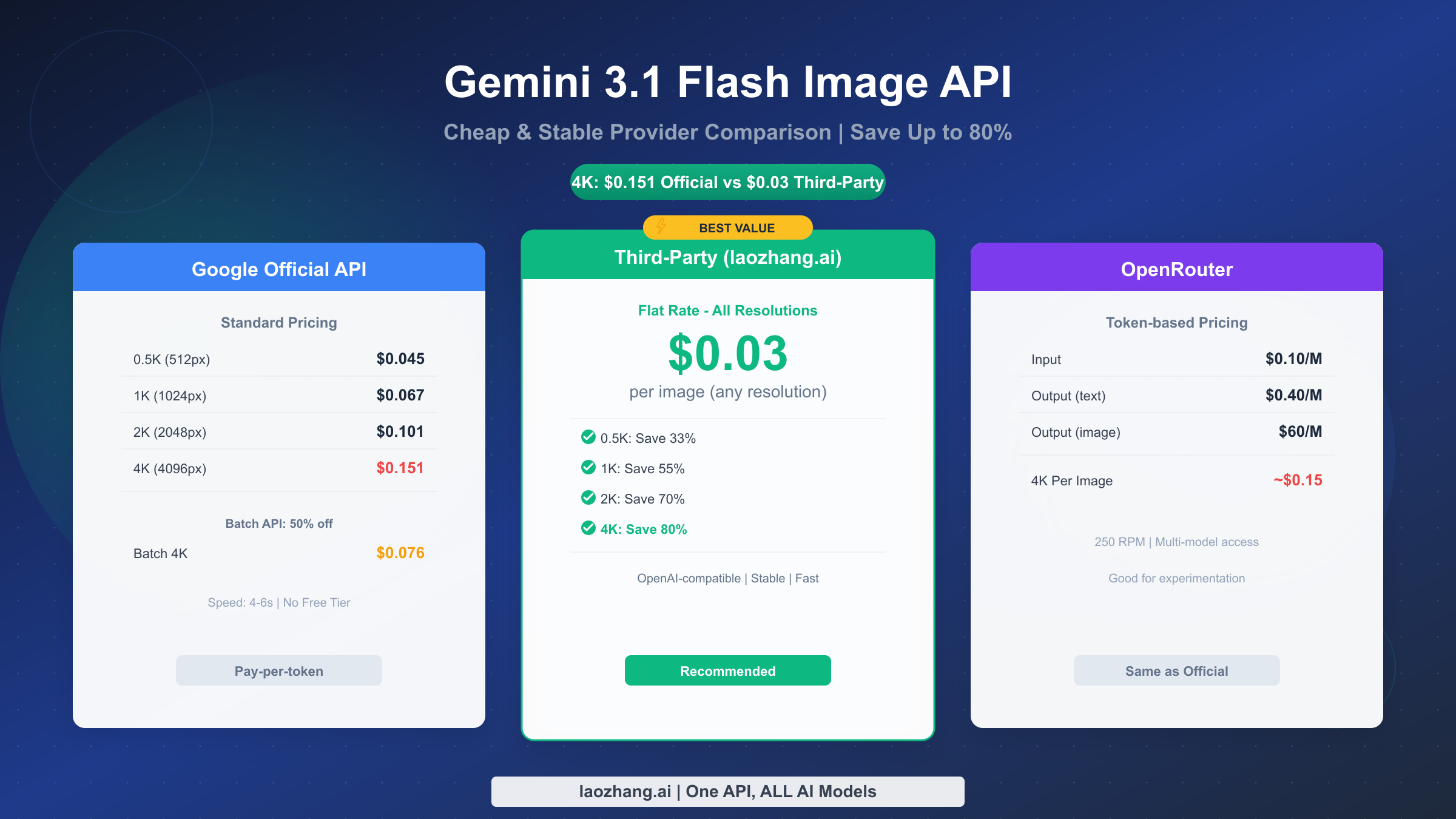
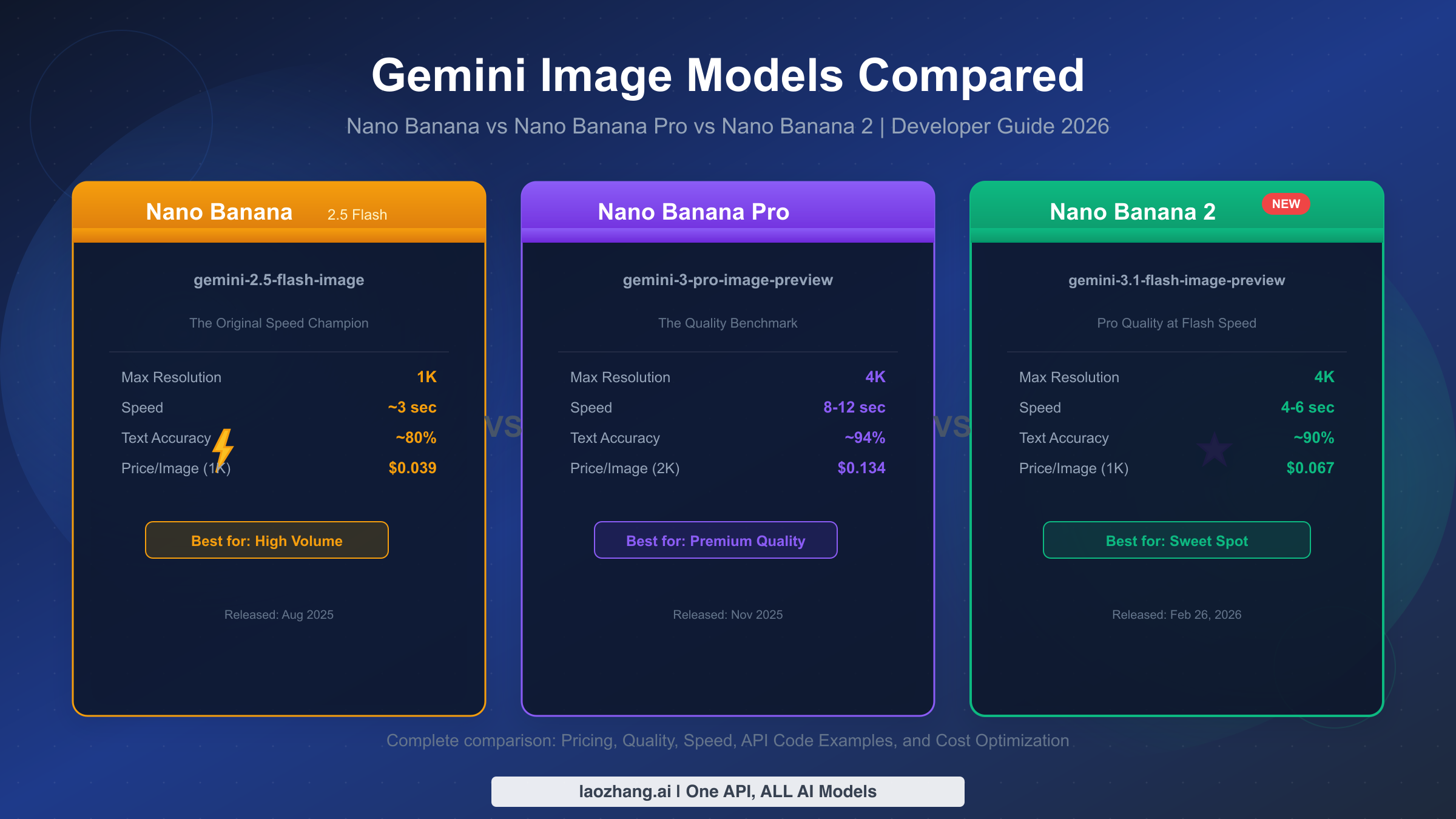
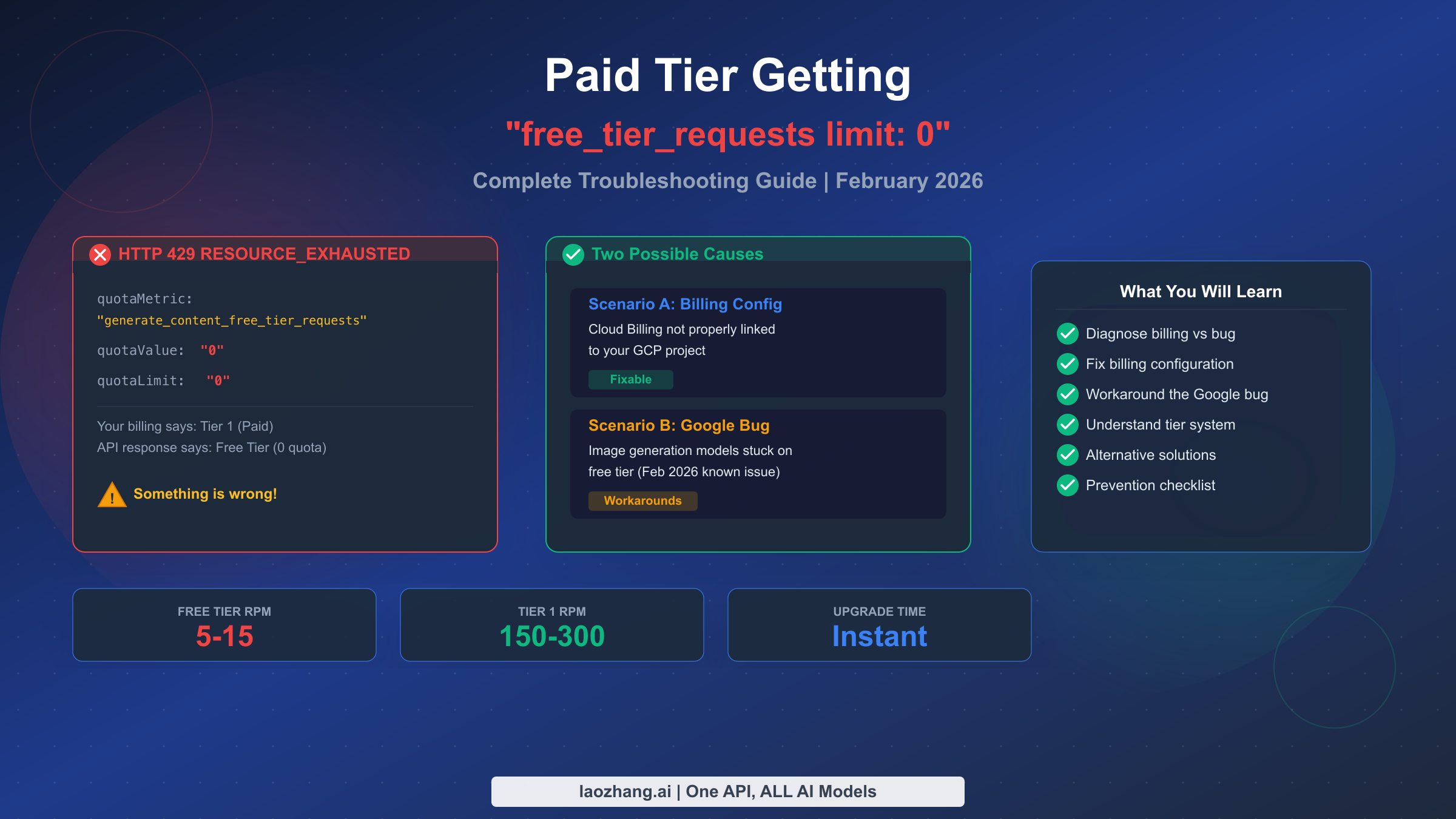

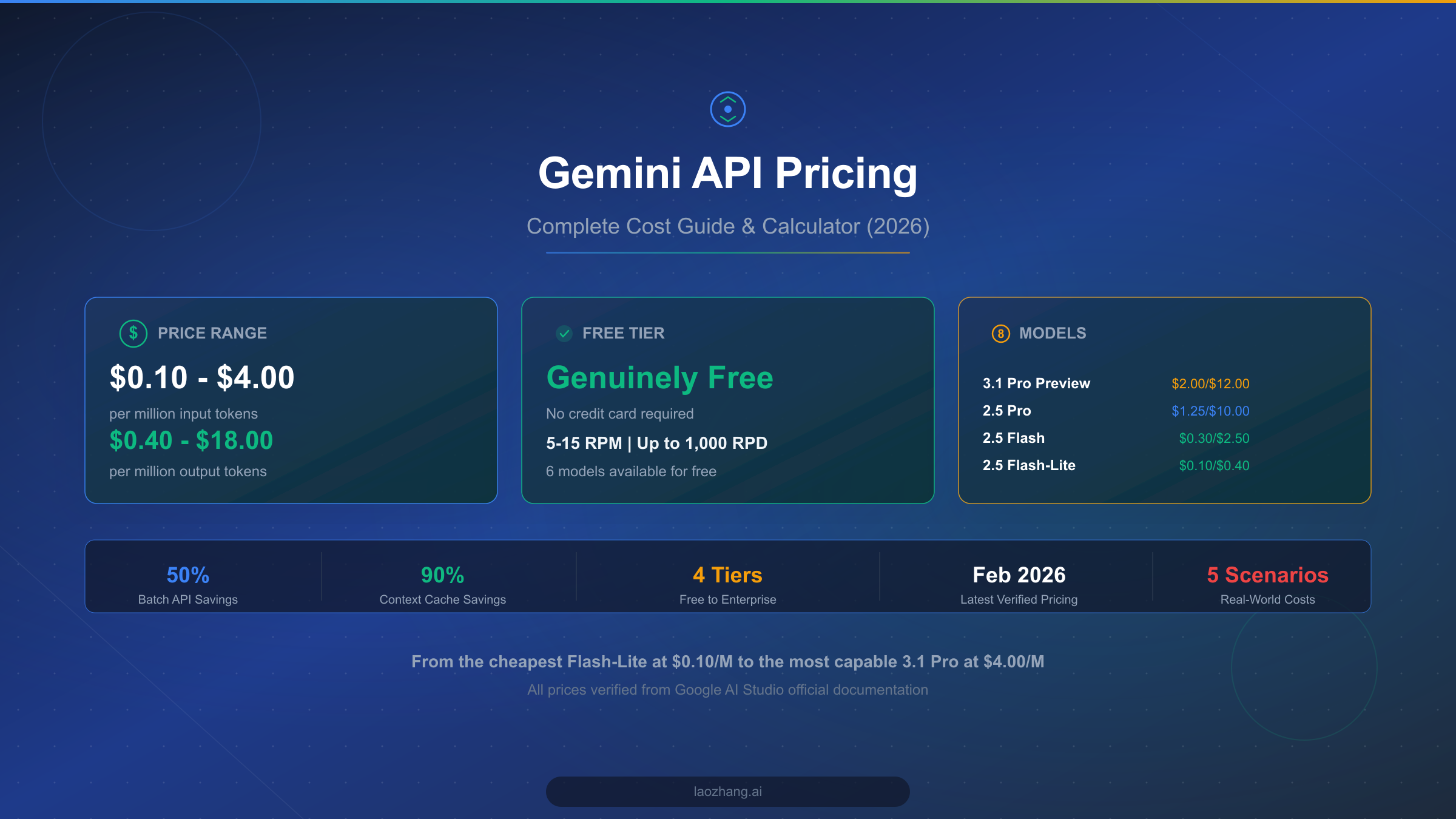

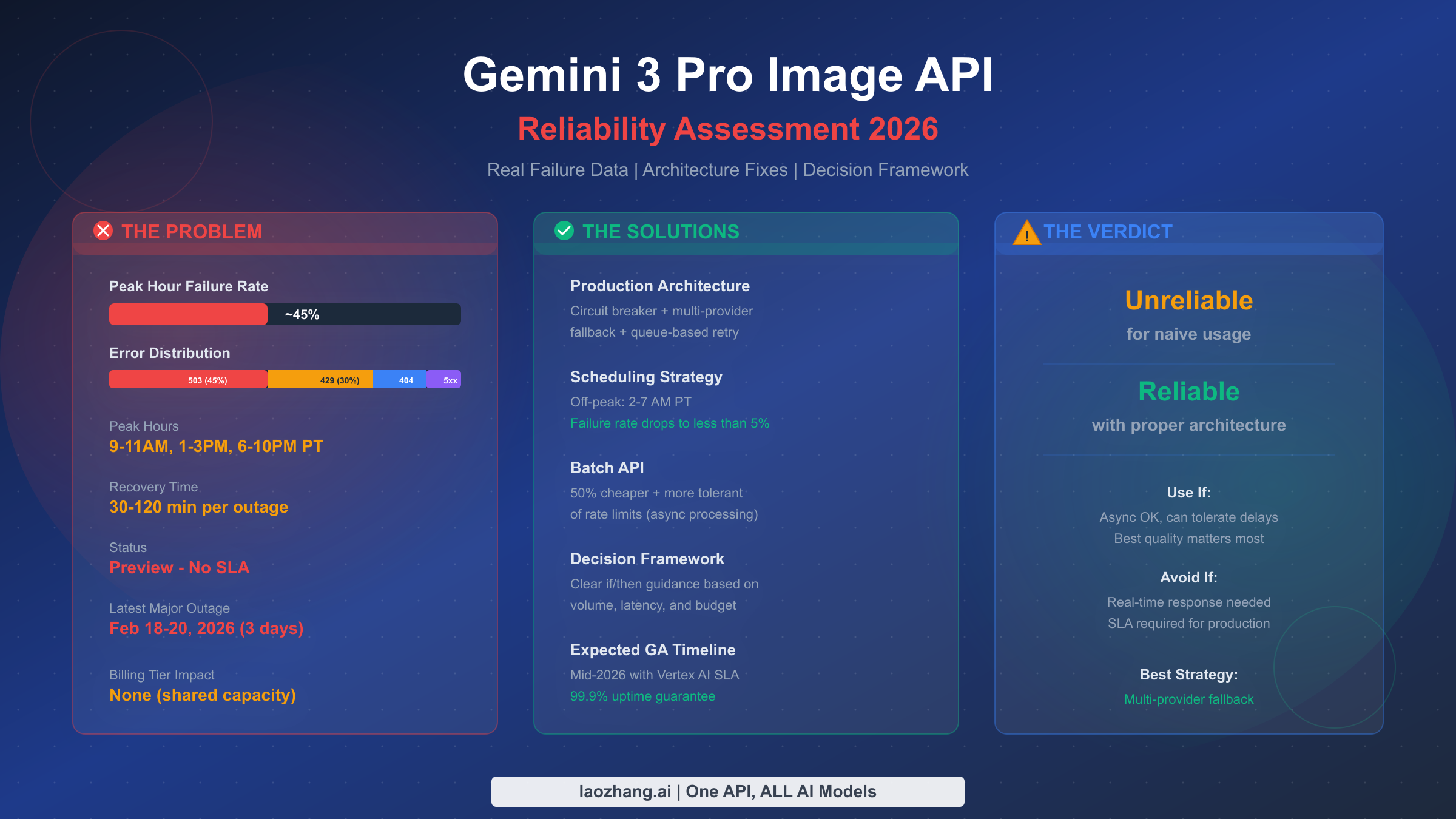
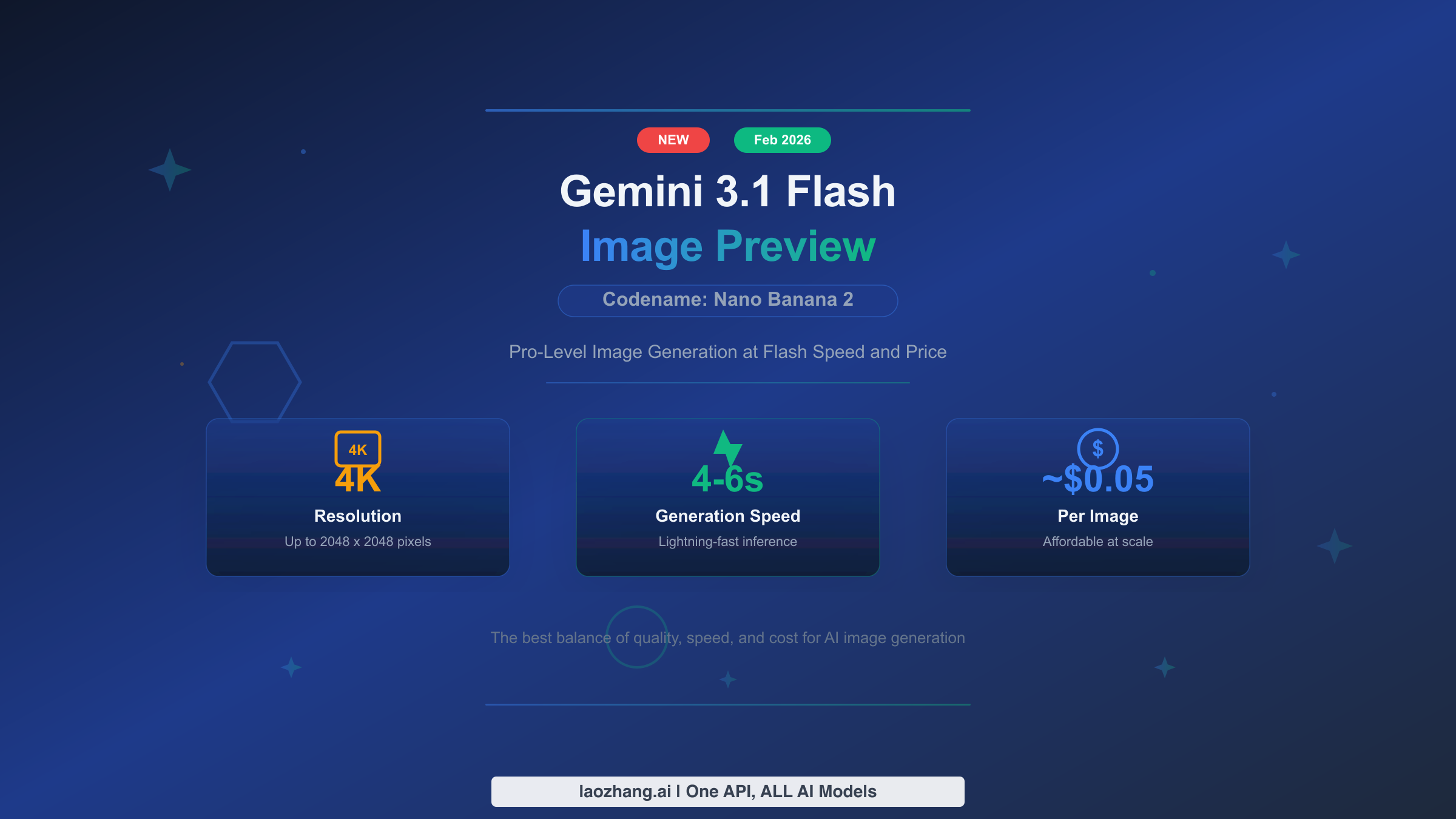
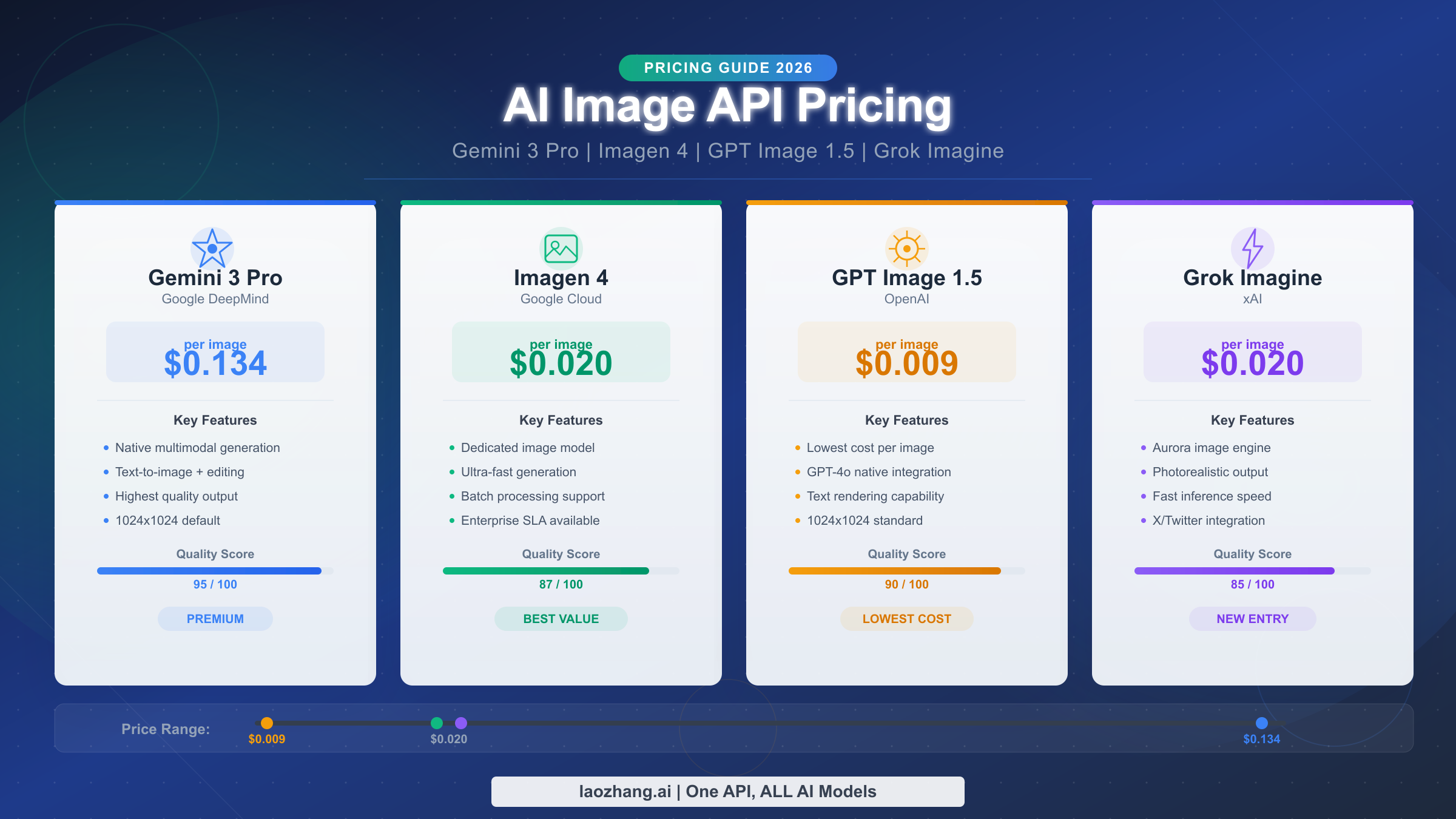


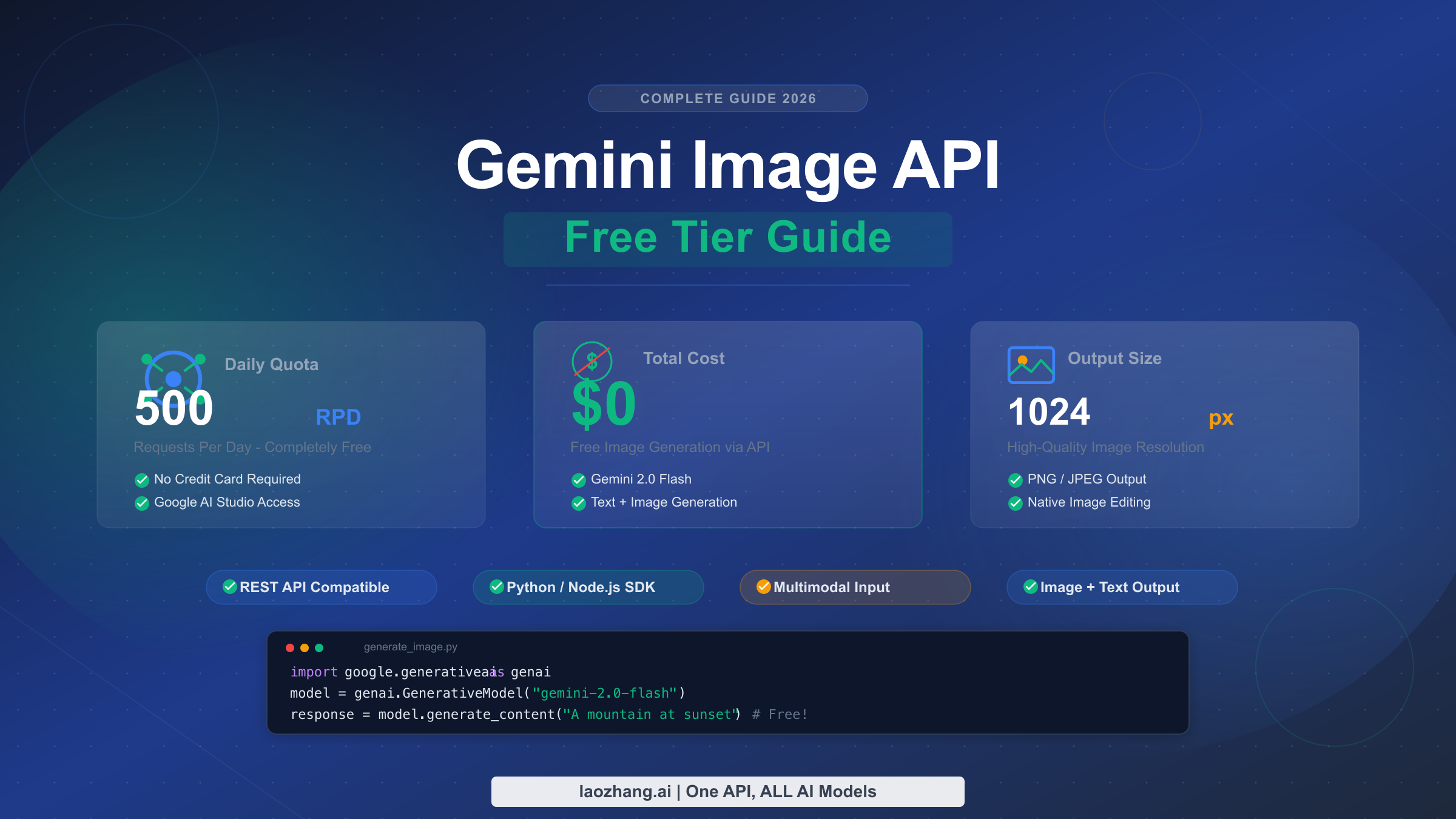
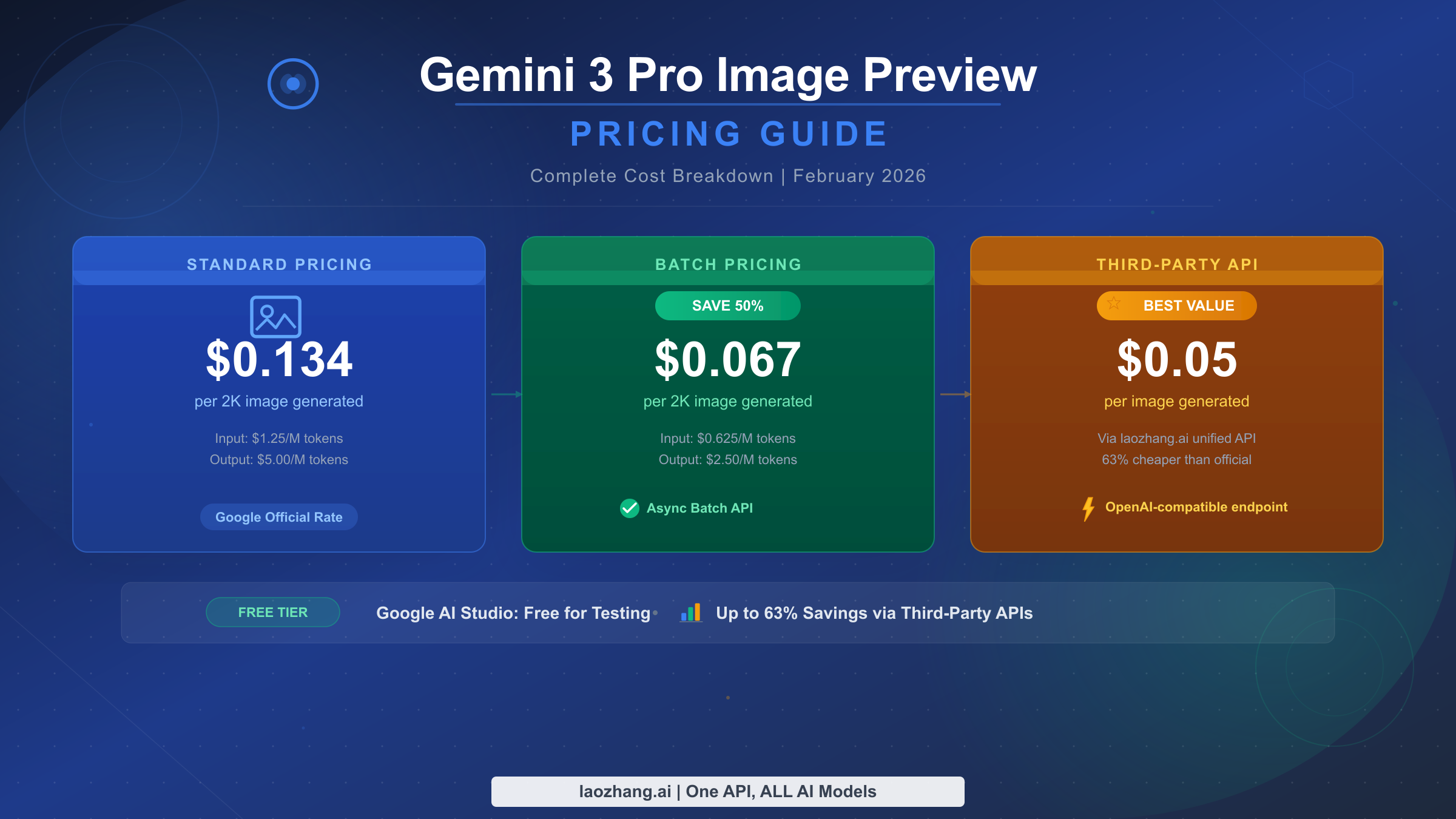
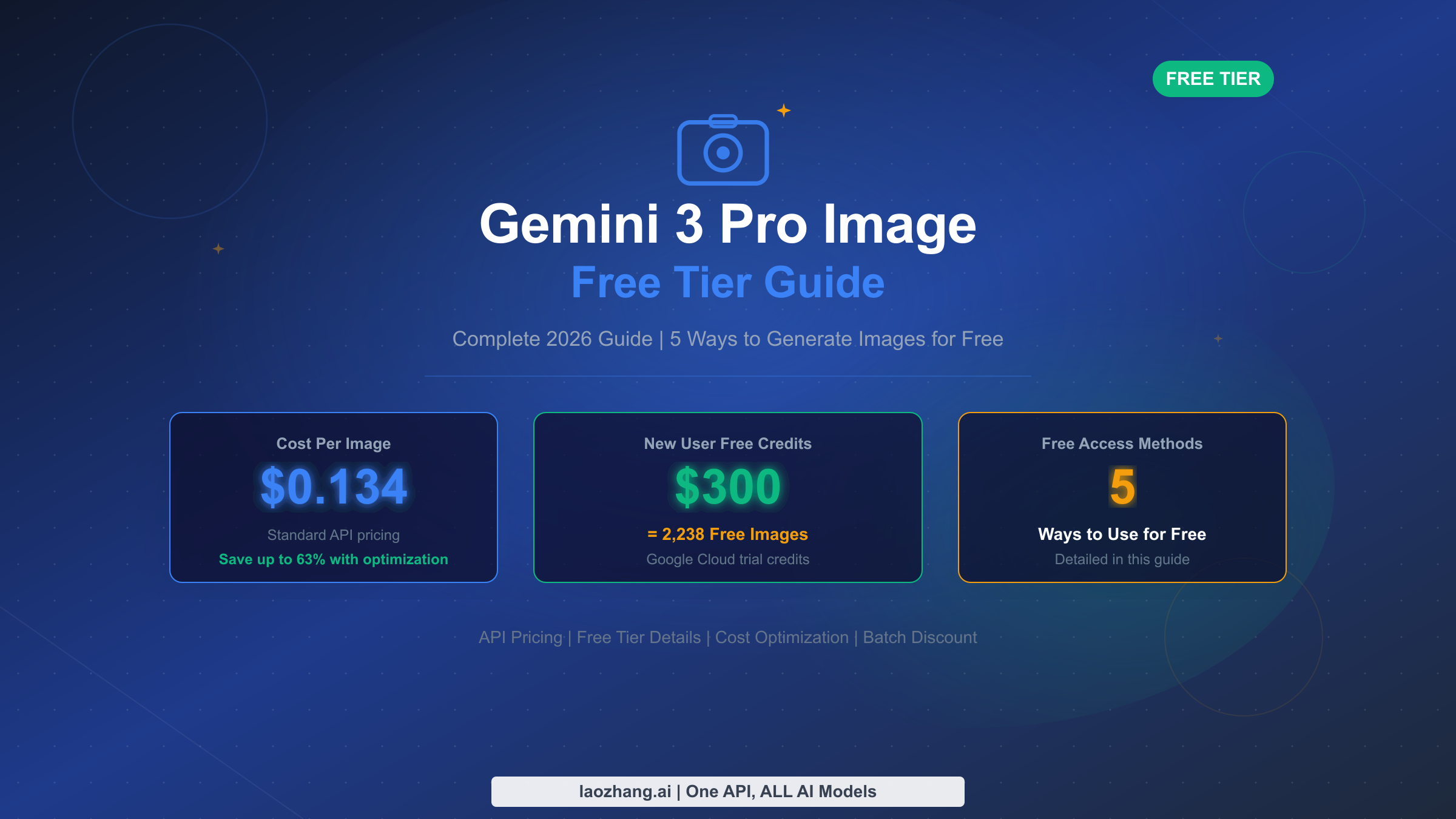

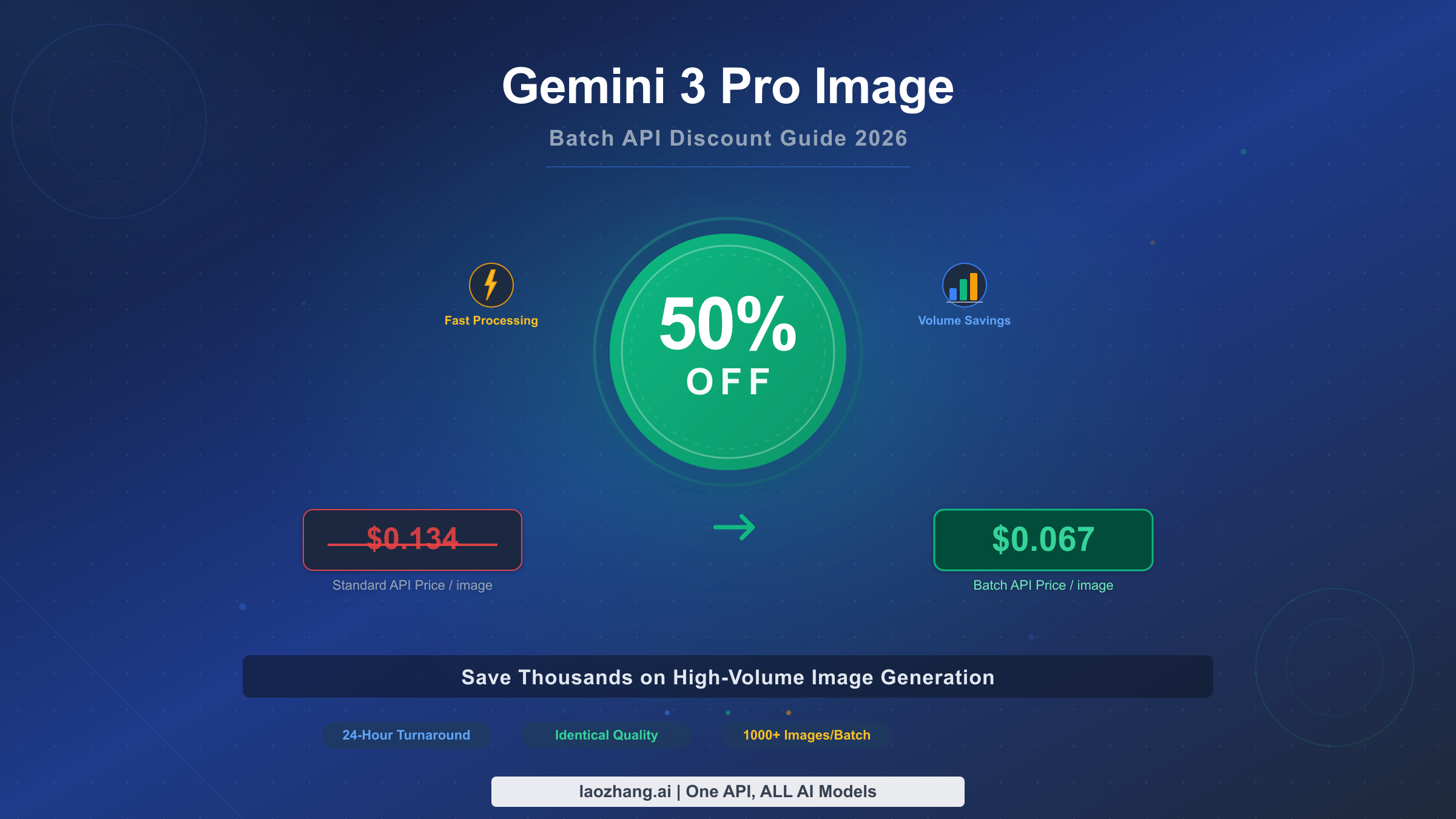
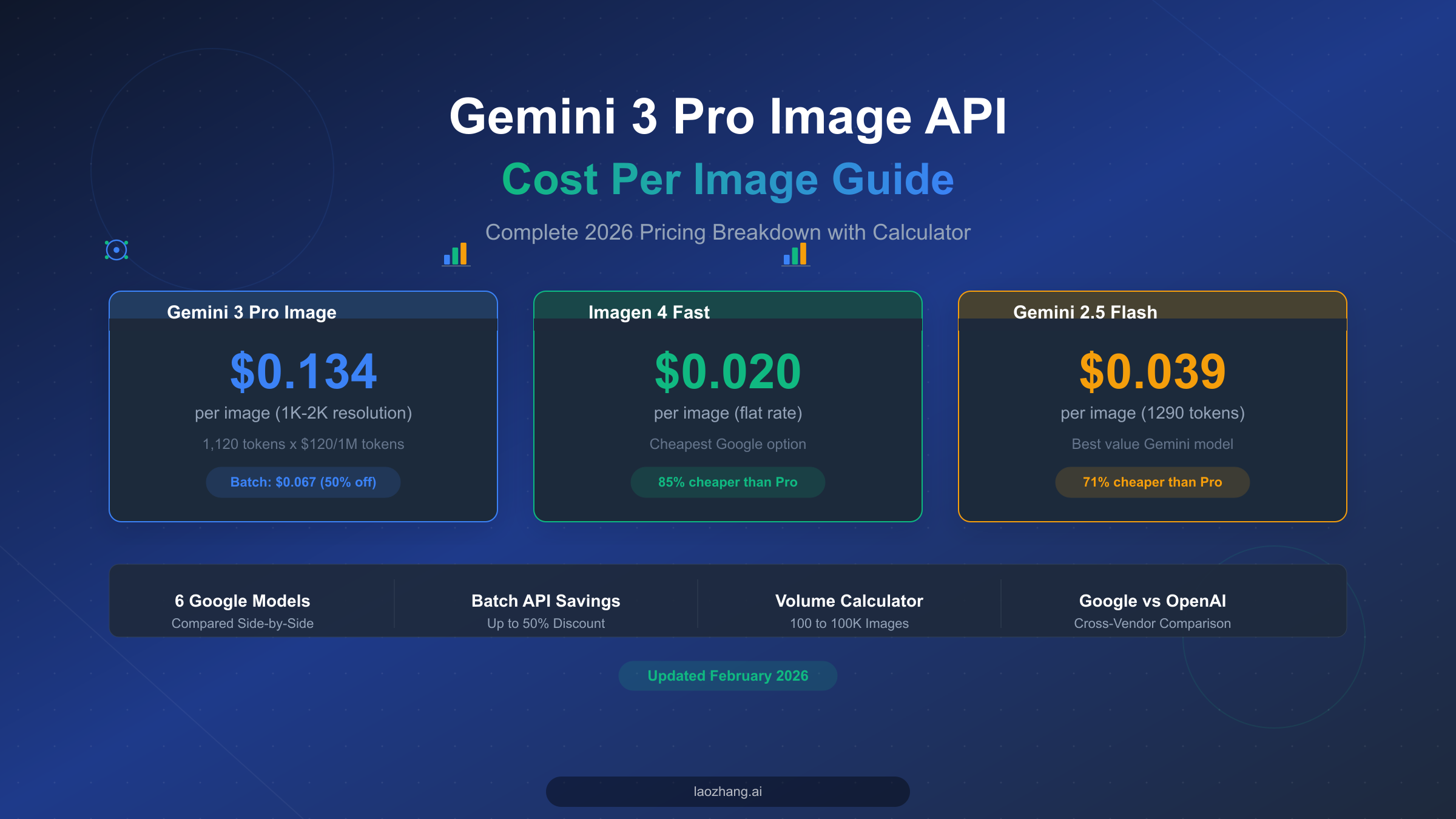
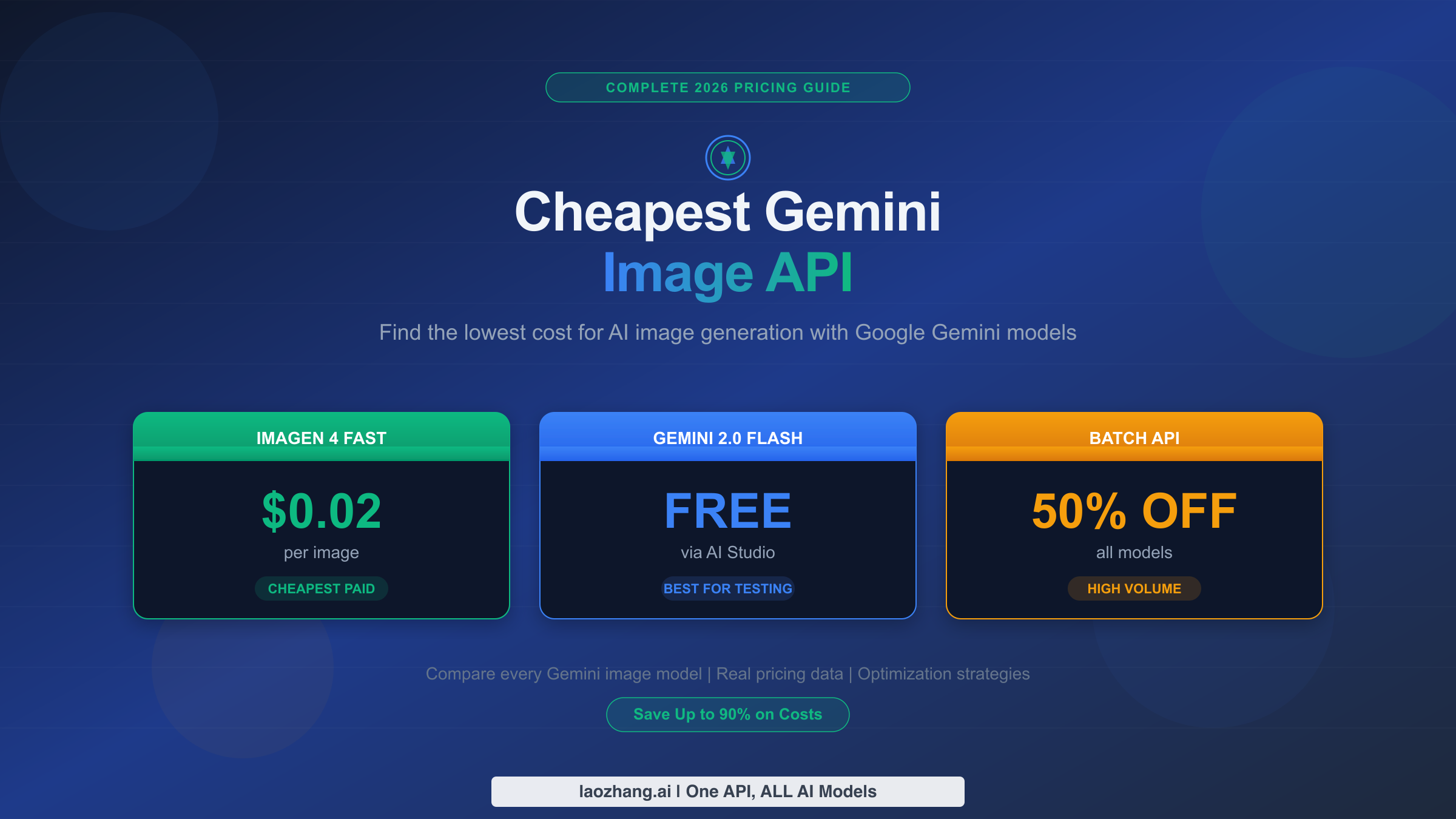
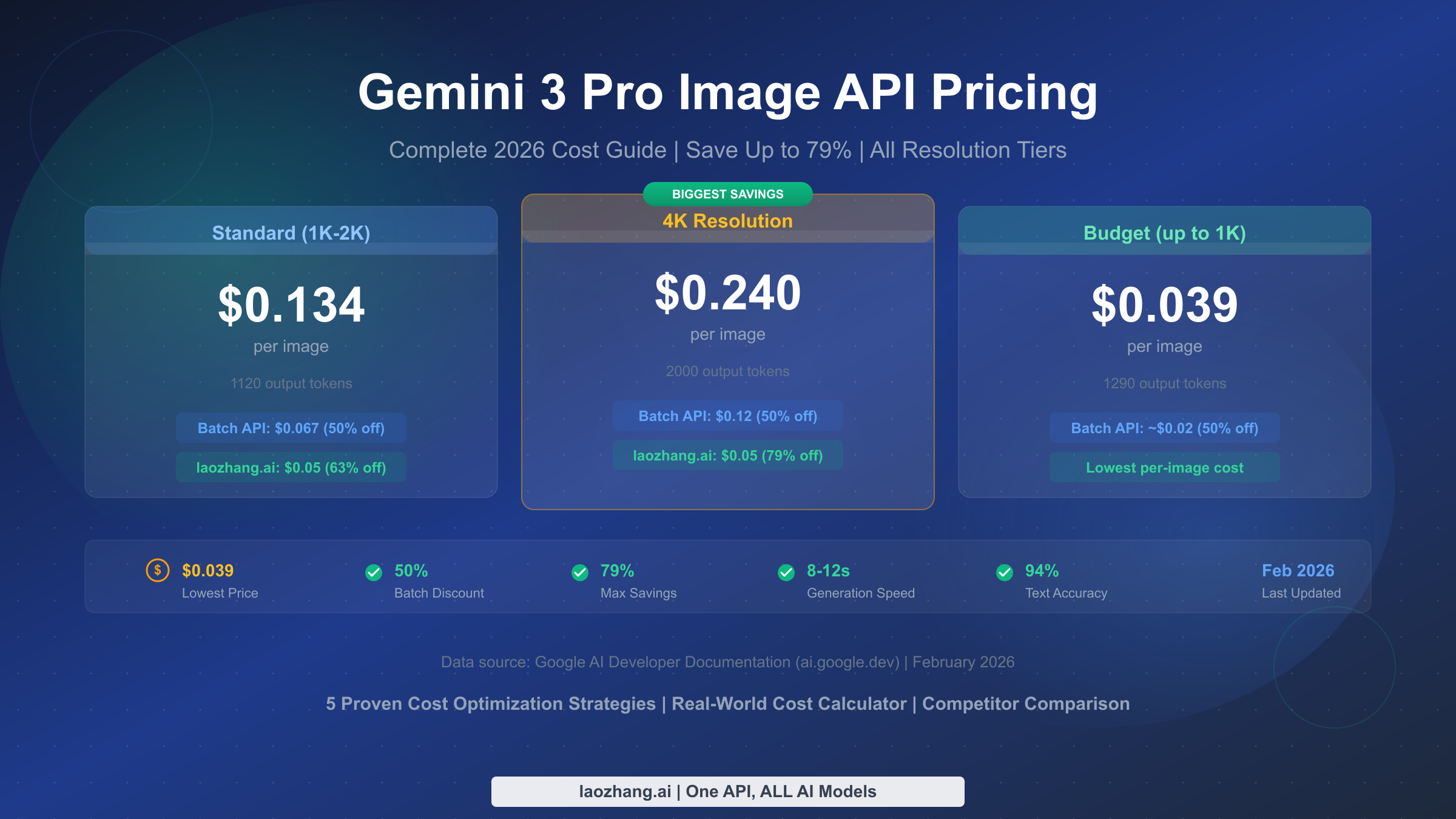
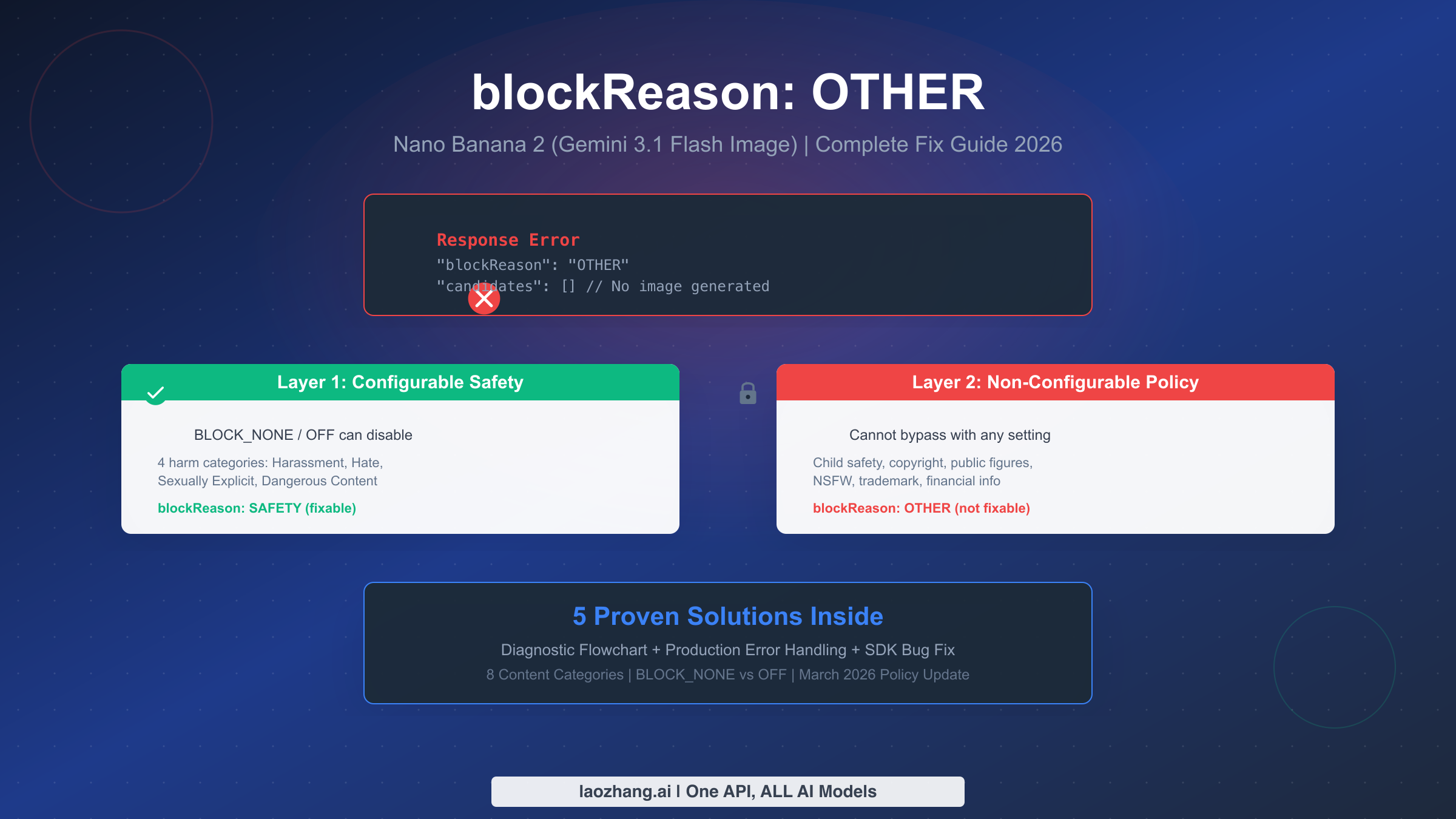
![Fix Gemini 3 Pro Image 503 Overloaded: Complete Troubleshooting Guide [2026]](/posts/en/fix-gemini-3-pro-image-503-overloaded/img/cover.png)












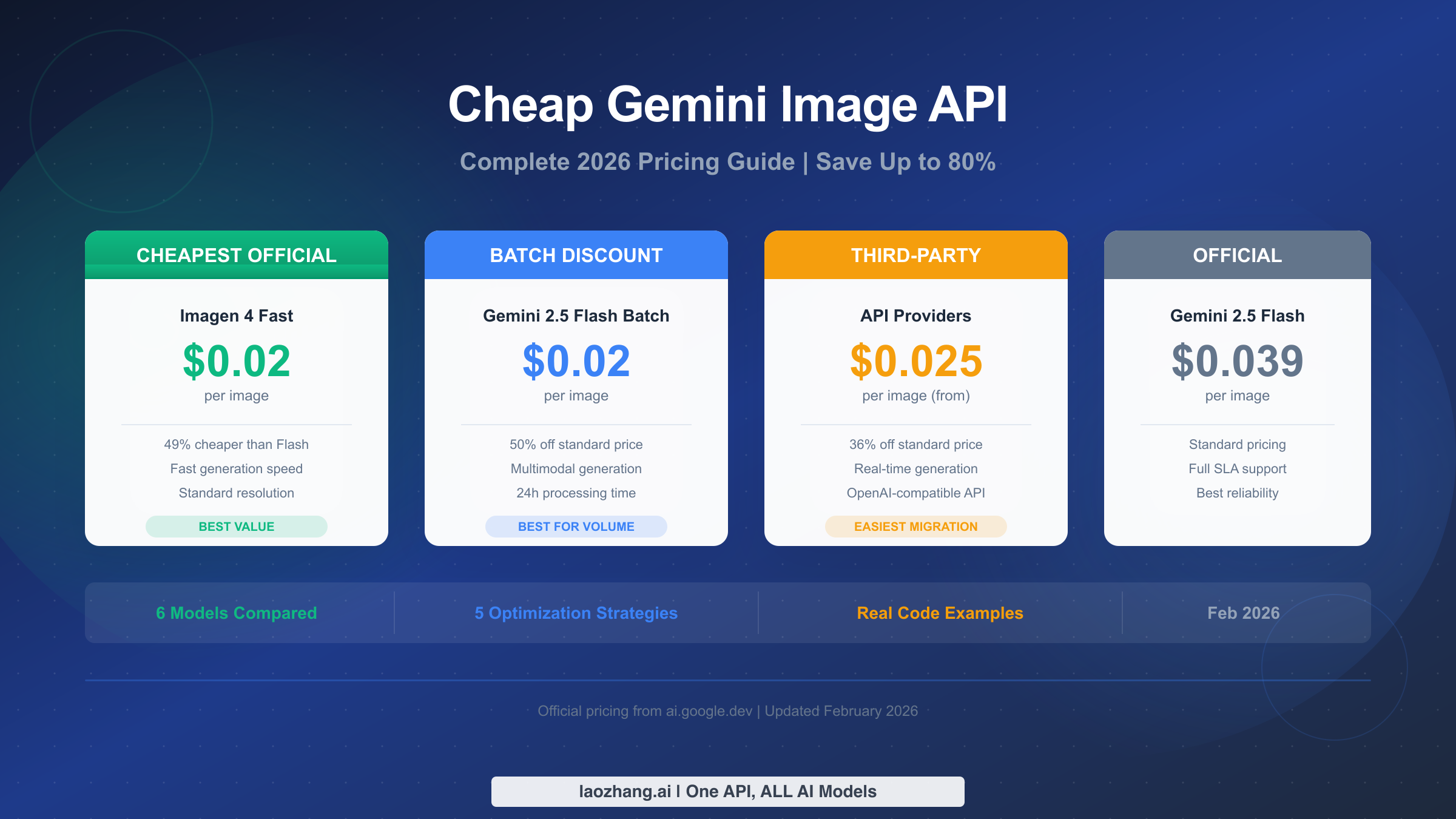
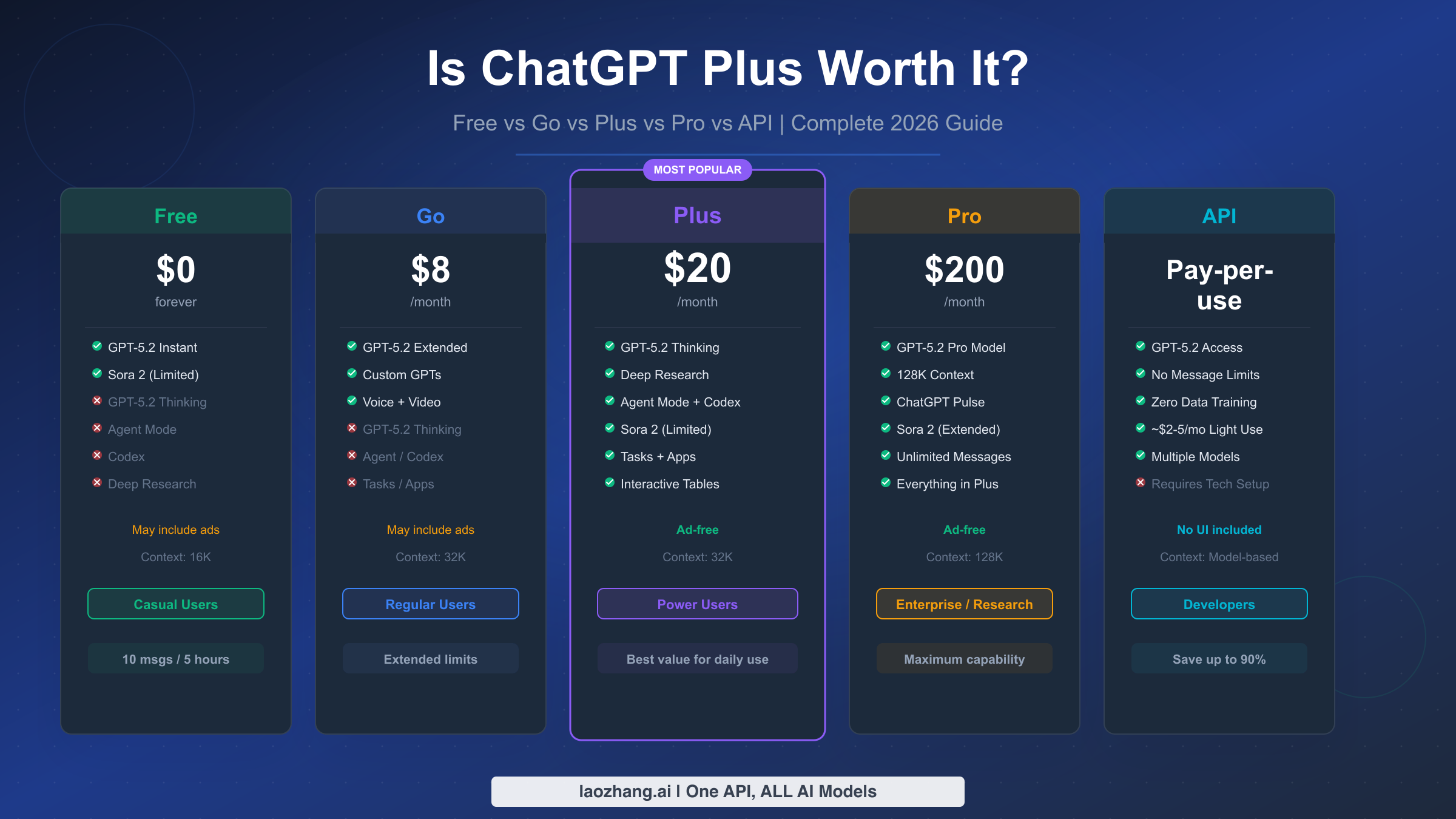


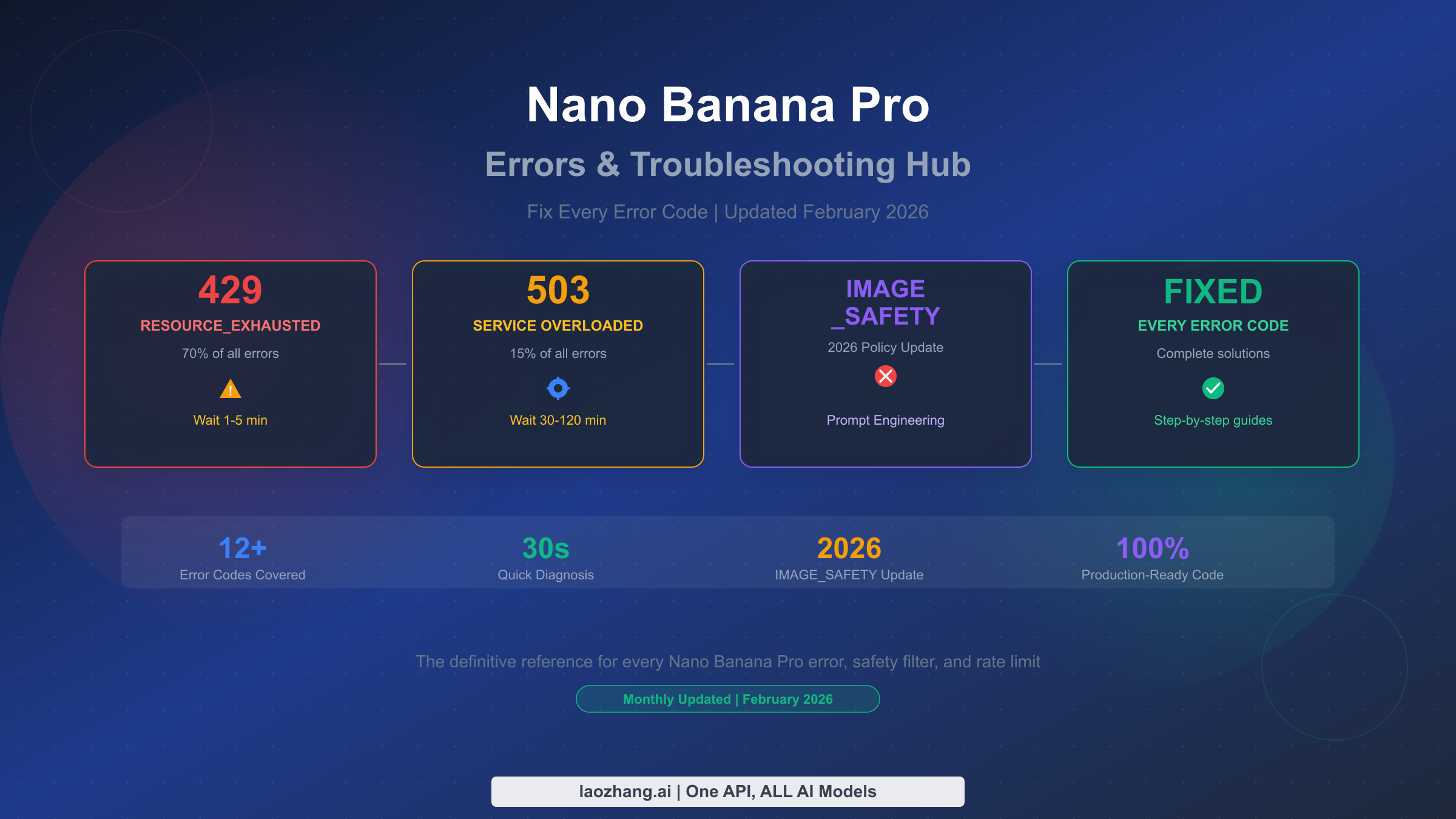

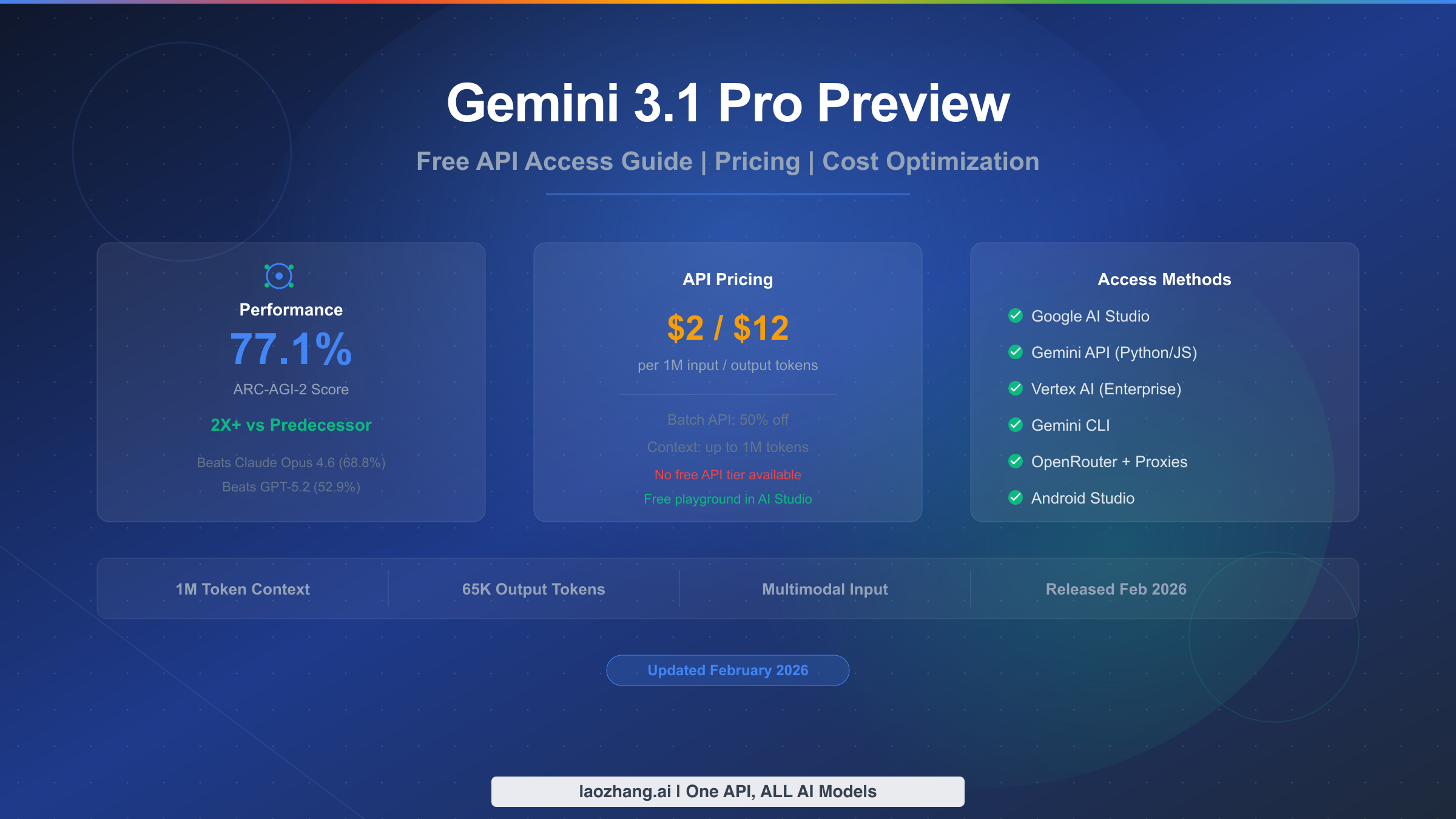
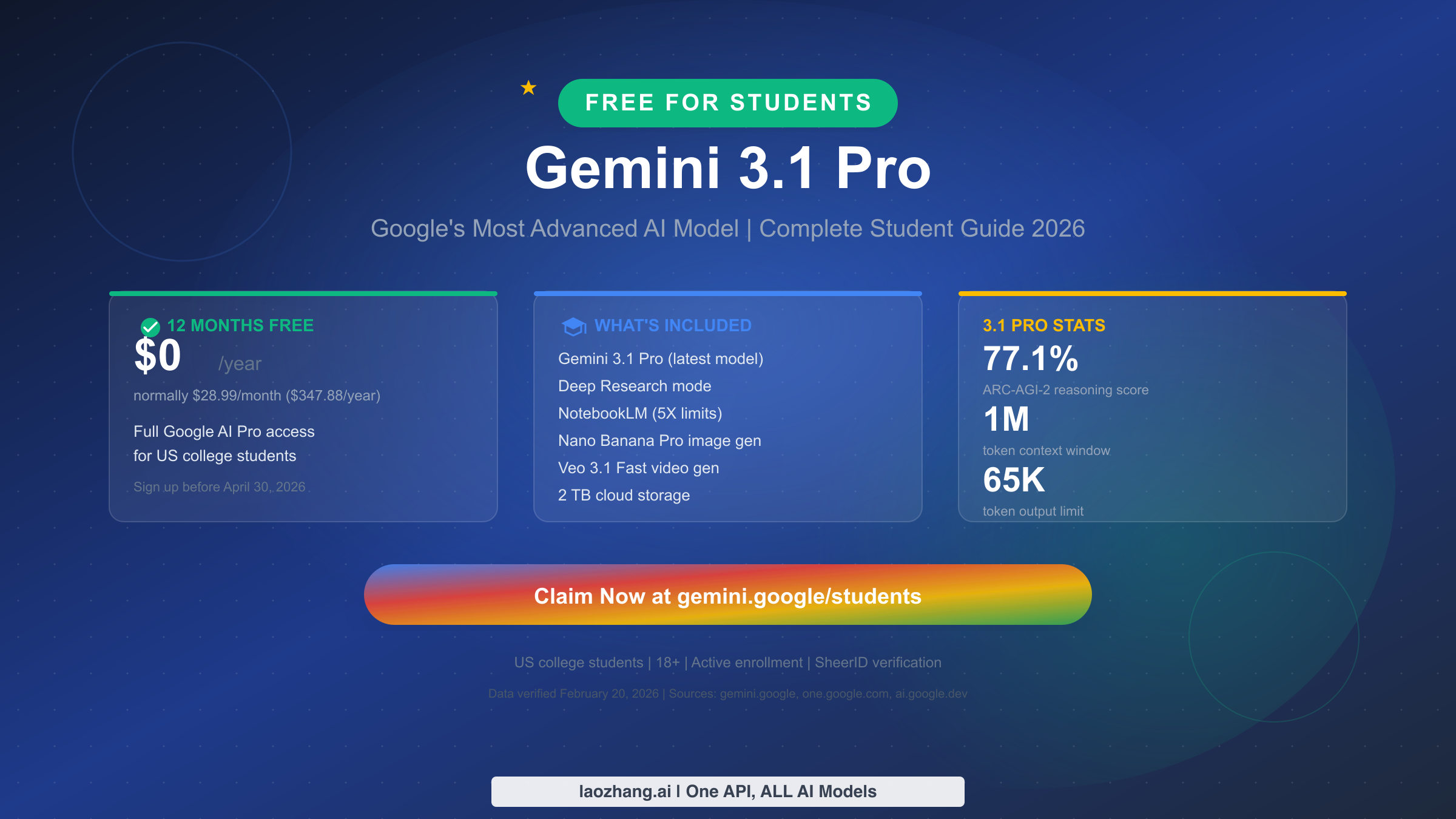
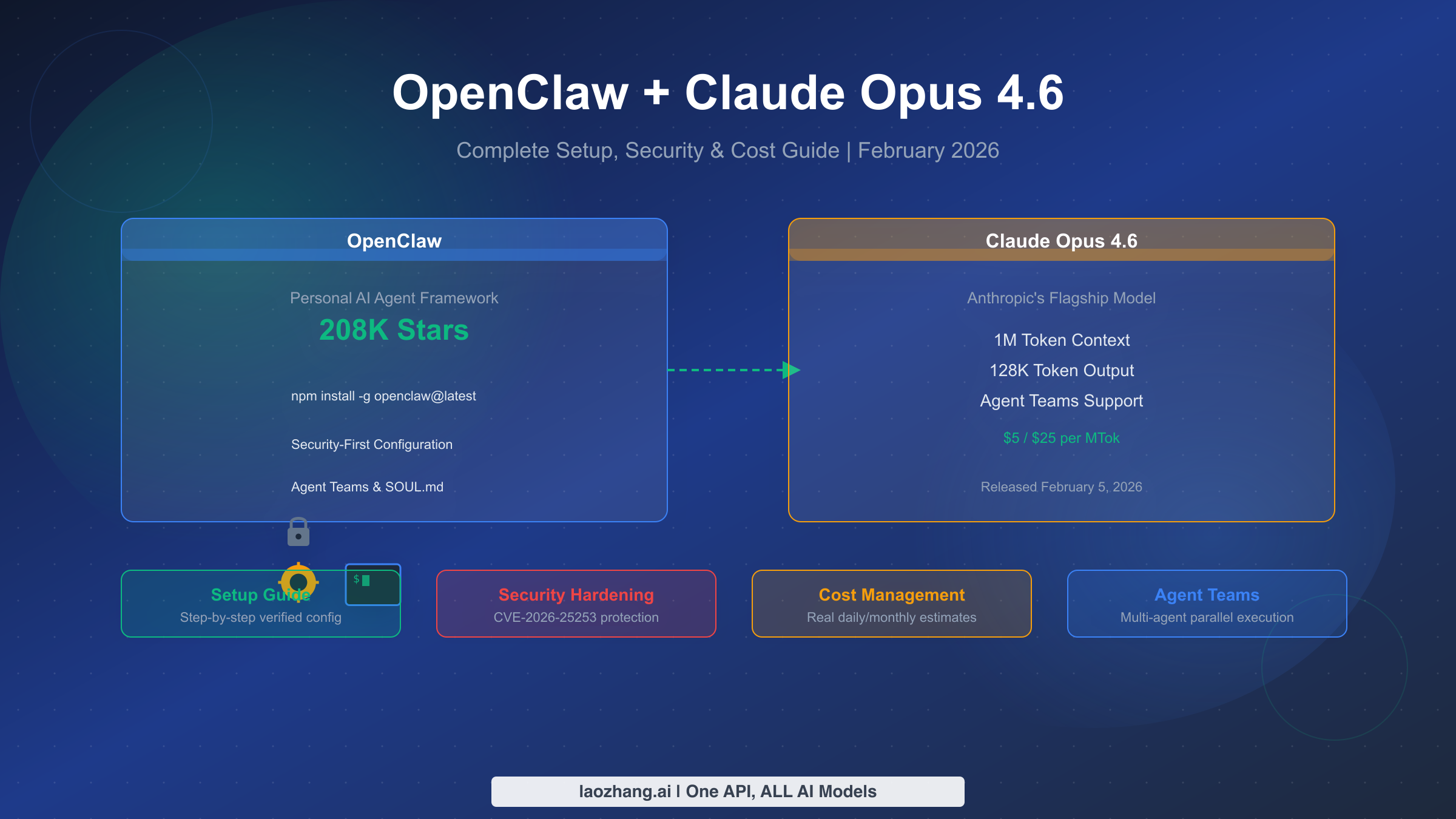

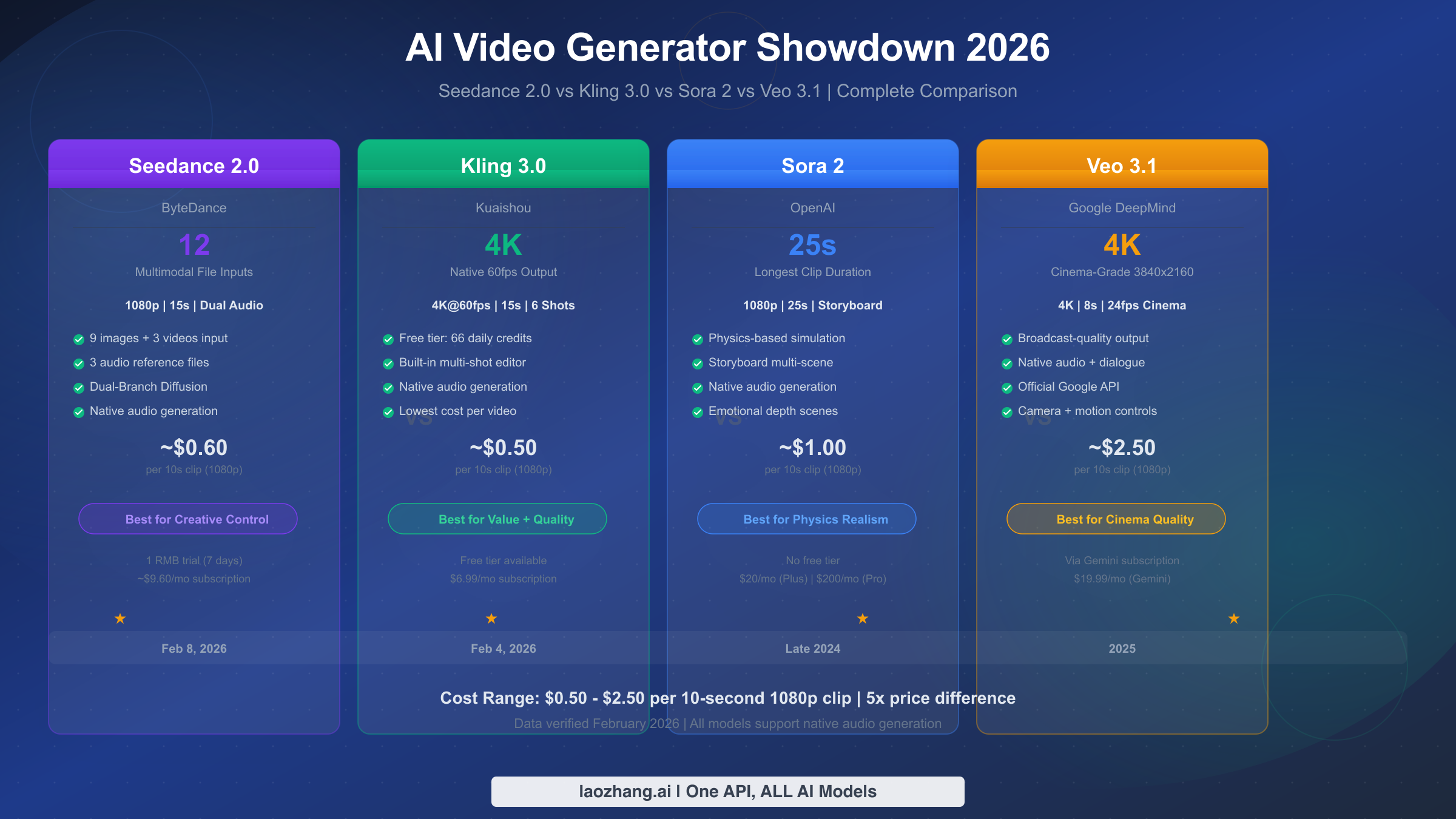
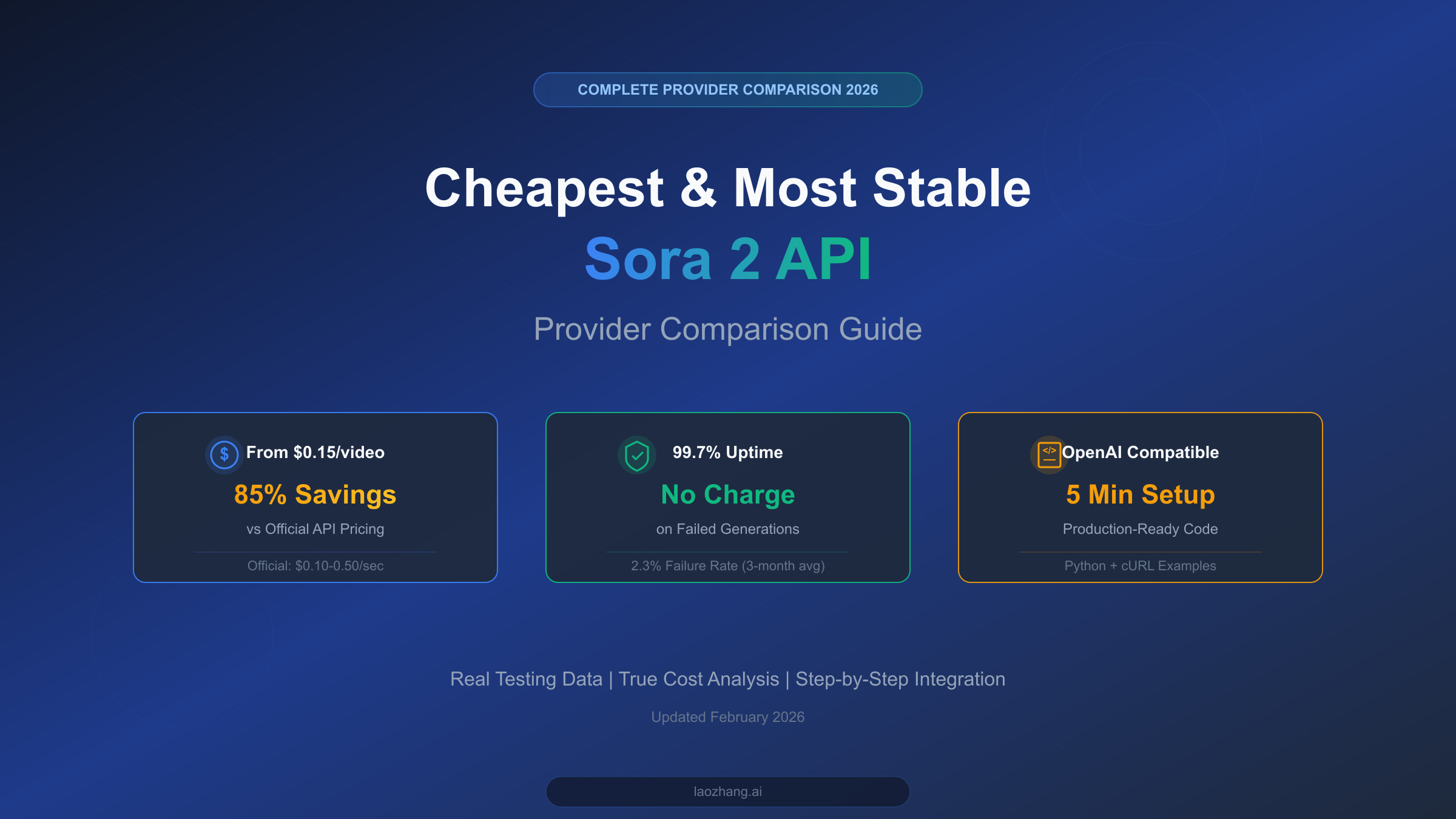





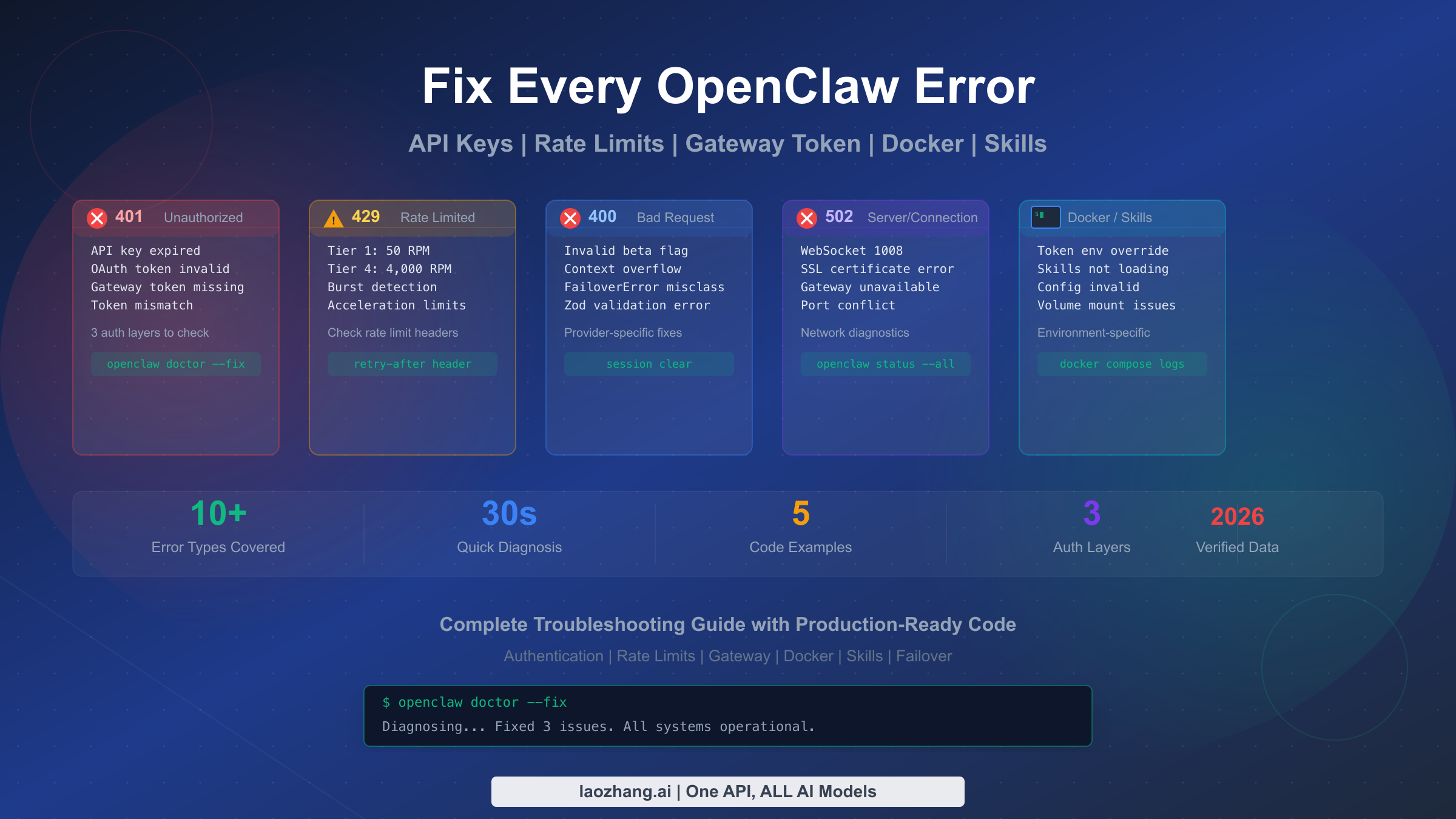


![Fix OpenClaw context_length_exceeded: Complete Troubleshooting Guide [2026]](/posts/en/openclaw-context-length-exceeded/img/cover.png)

![Fix OpenClaw Rate Limit Exceeded (429): Complete Troubleshooting Guide [2026]](/posts/en/openclaw-rate-limit-exceeded-429/img/cover.png)
![Fix OpenClaw Invalid Beta Flag Error: Complete Guide [2026]](/posts/en/openclaw-invalid-beta-flag/img/cover.png)

![Fix OpenClaw Anthropic API Key Error: Complete Guide [2026]](/posts/en/openclaw-anthropic-api-key-error/img/cover.png)
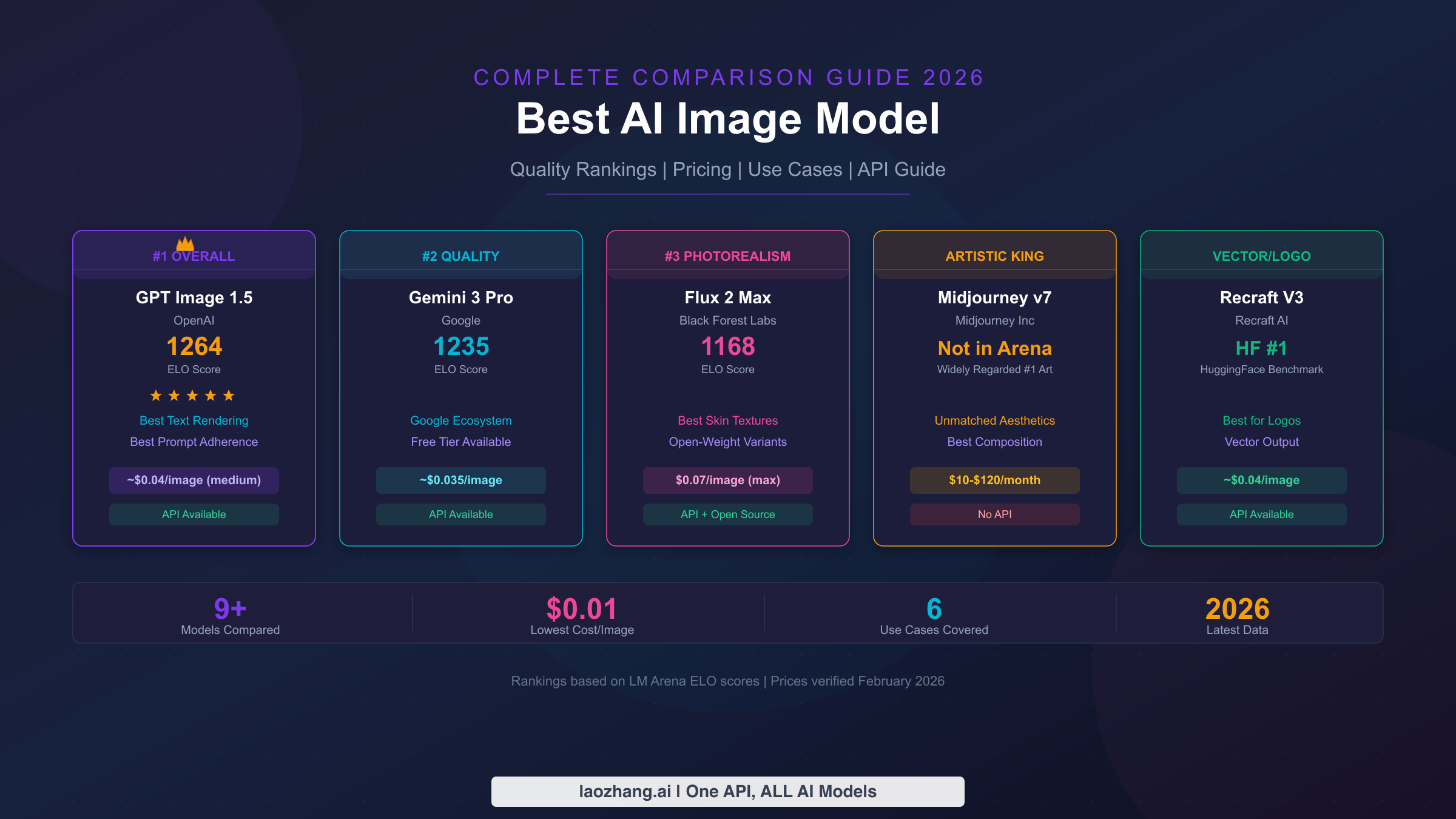
![Gemini 3 Complete Comparison: Pro, Flash, Nano Banana Pro Full Guide [2026 Update]](/posts/en/gemini-3-comparison/img/cover.png)