AI Image Generation
Read Now
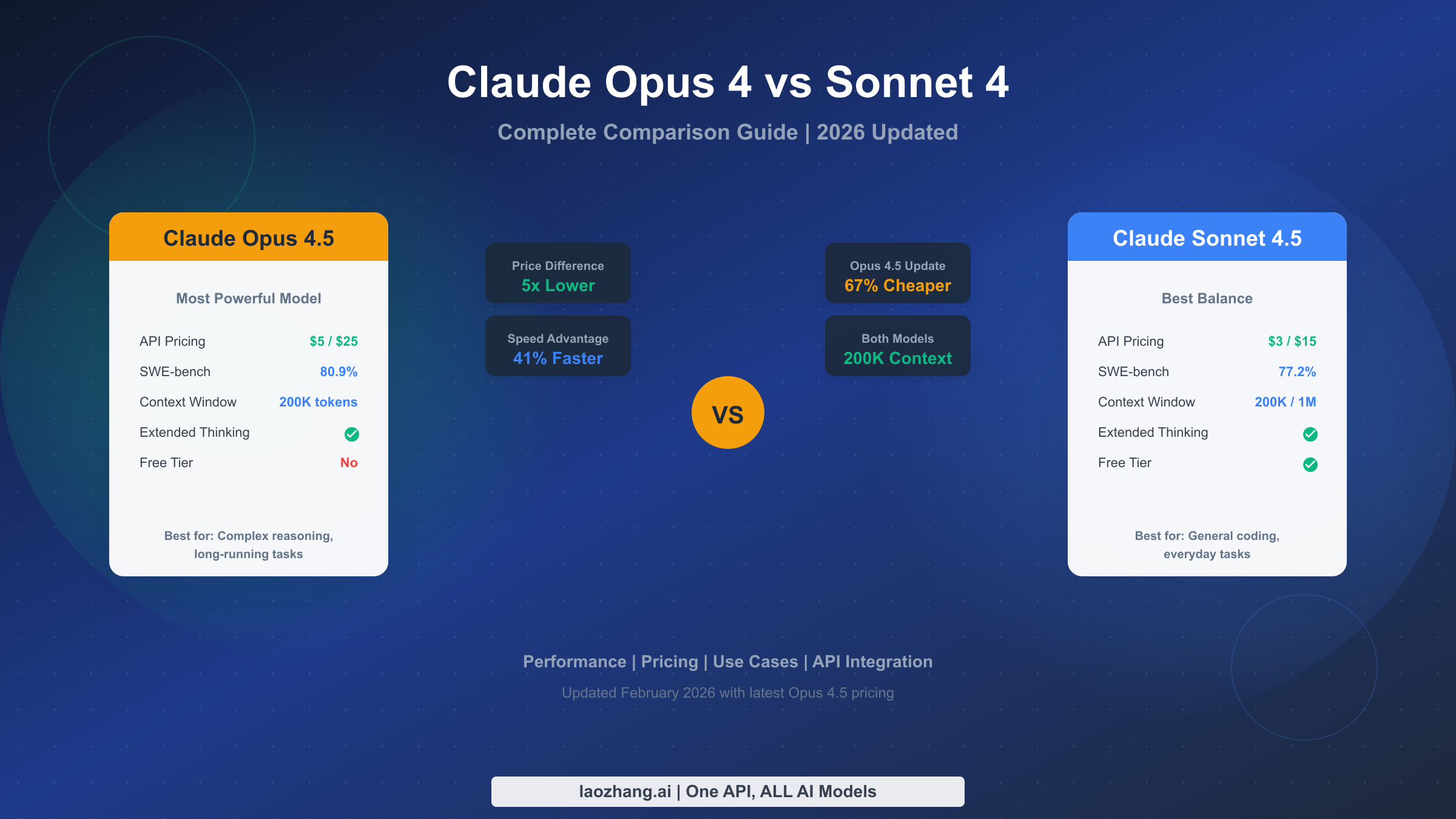
Nano Banana 2 vs Midjourney vs GPT Image 1.5 vs FLUX.2: Complete Comparison (2026)
Choosing between Nano Banana 2, Midjourney, GPT Image 1.5, and FLUX.2 in 2026? This comprehensive comparison covers real-world quality tests, generation speed benchmarks, per-image pricing across all tiers, and API integration options. We test each model head-to-head and provide a clear decision framework based on your specific use case — whether you prioritize speed, artistic quality, photorealism, or cost efficiency.

![Nano Banana 2 API Pricing Explained: Official vs Proxy Cost Comparison [2026]](/posts/en/nano-banana-2-api-pricing-guide/img/cover.png)

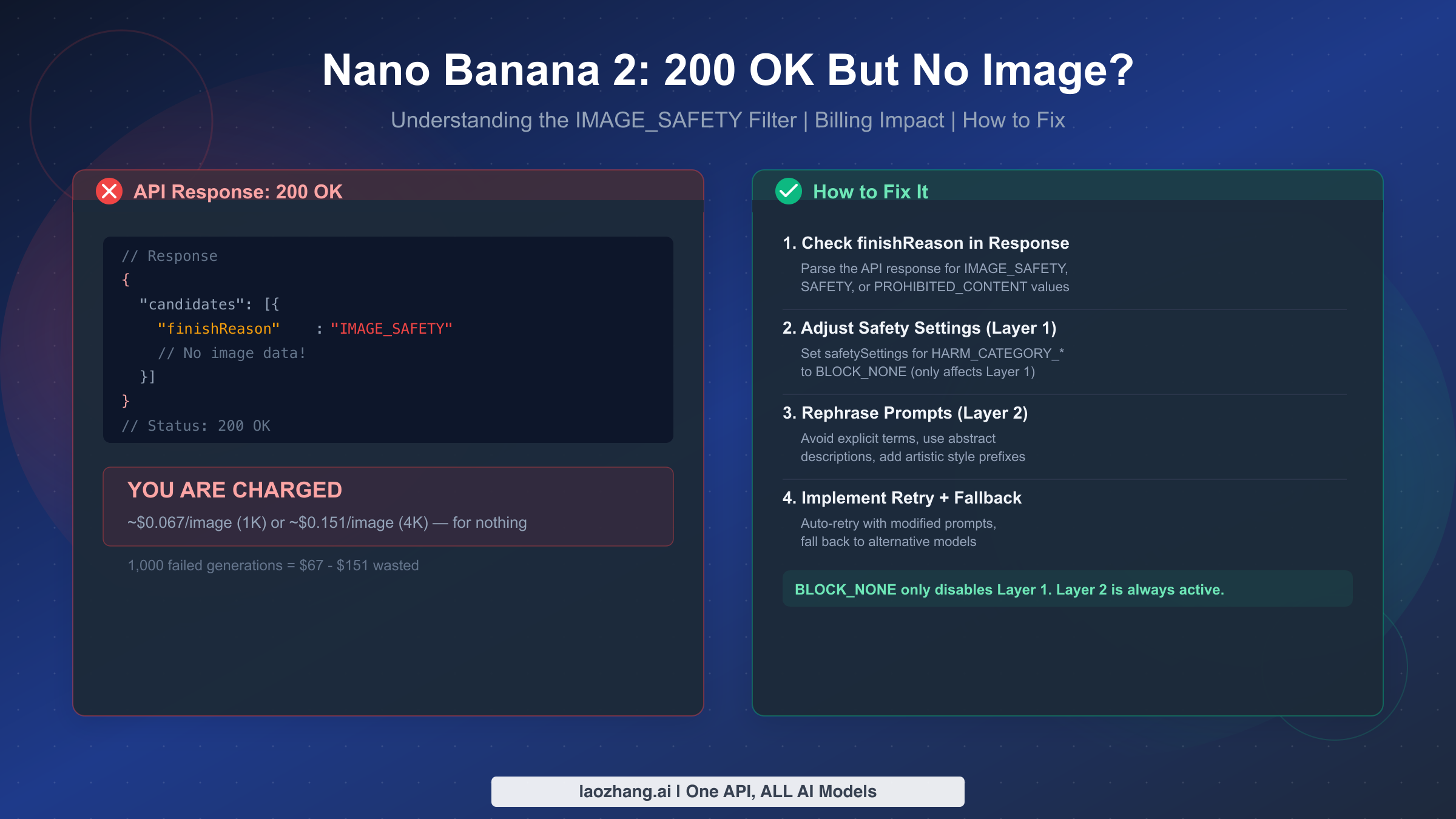
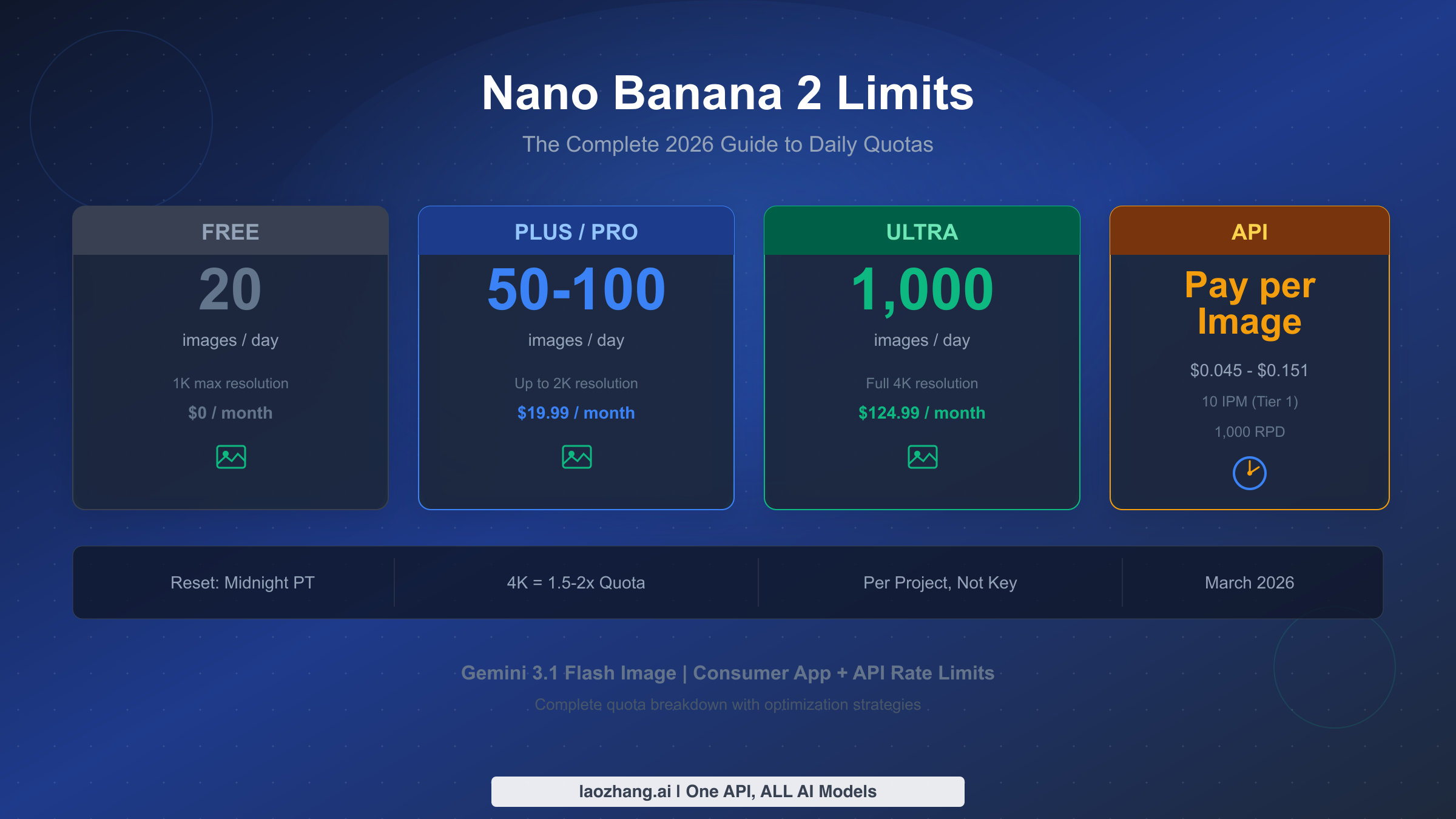


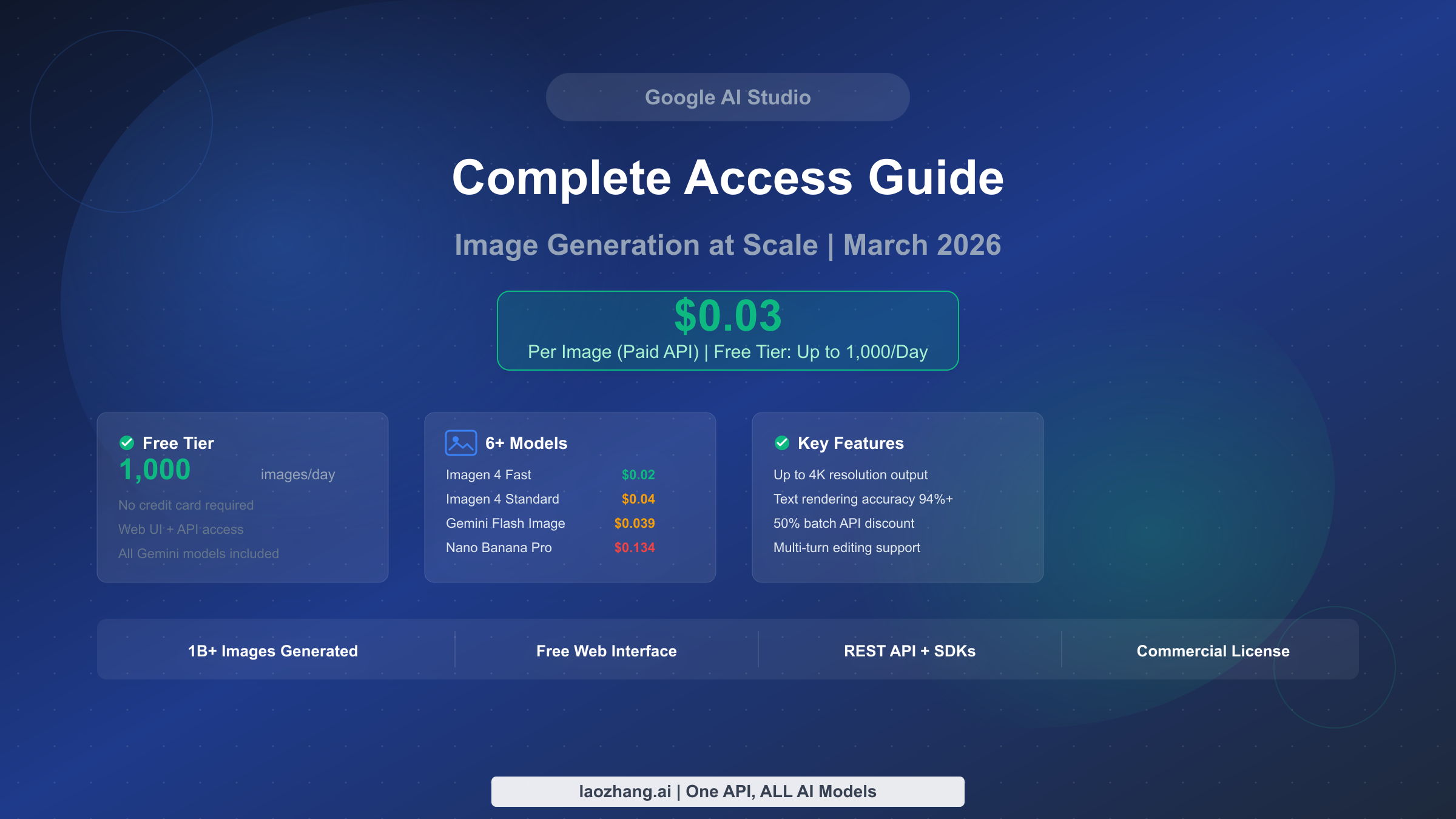
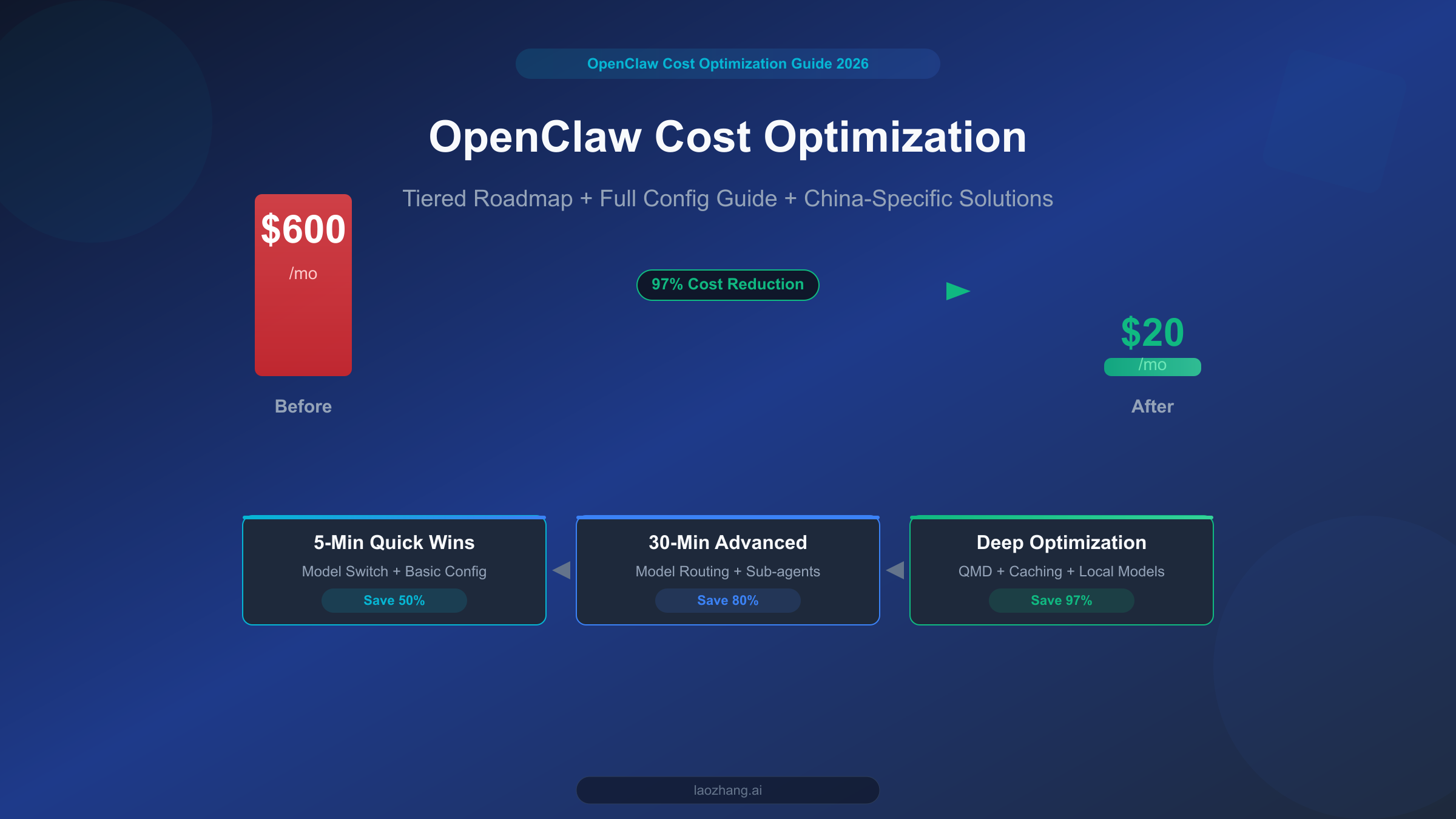
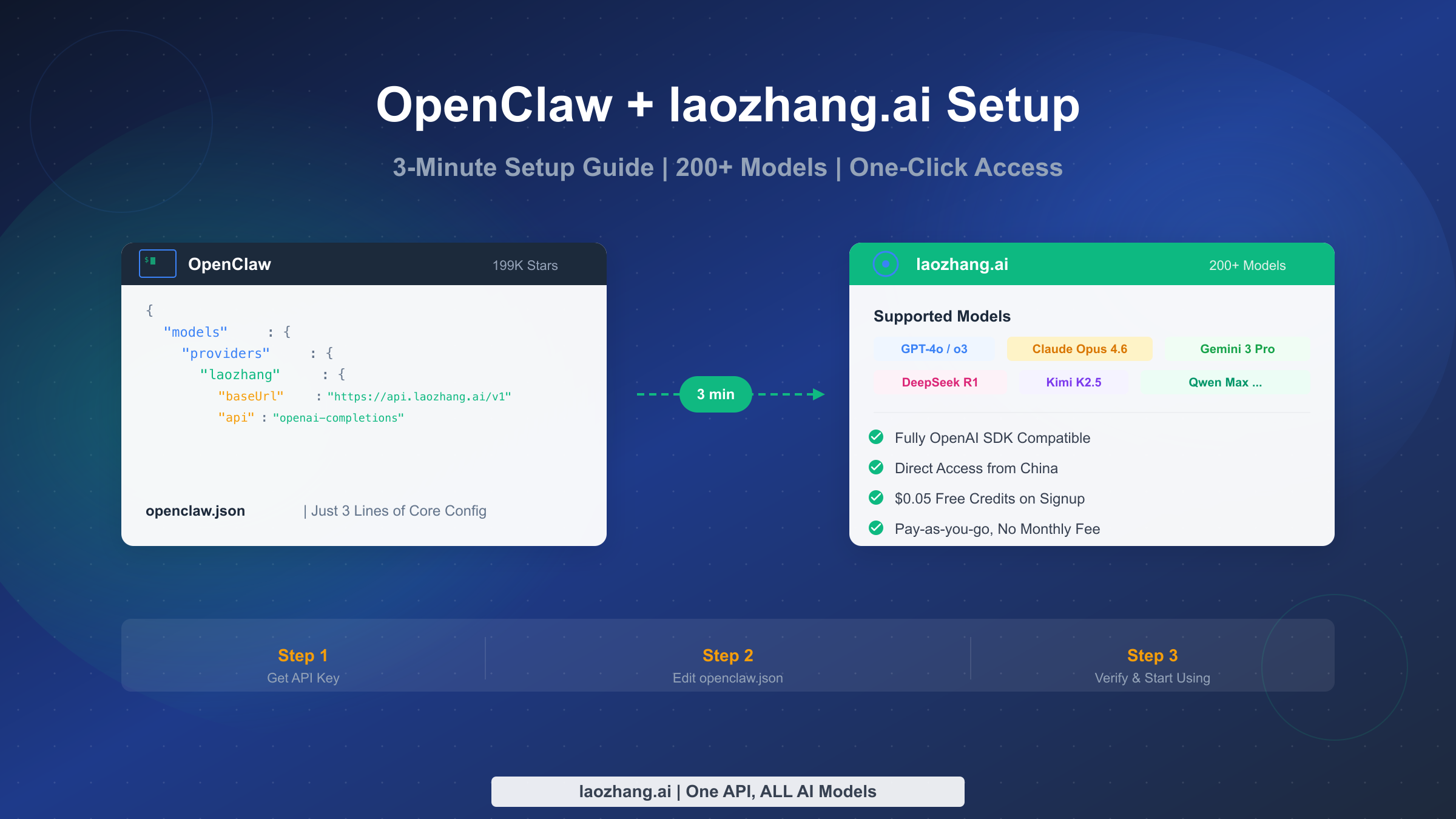

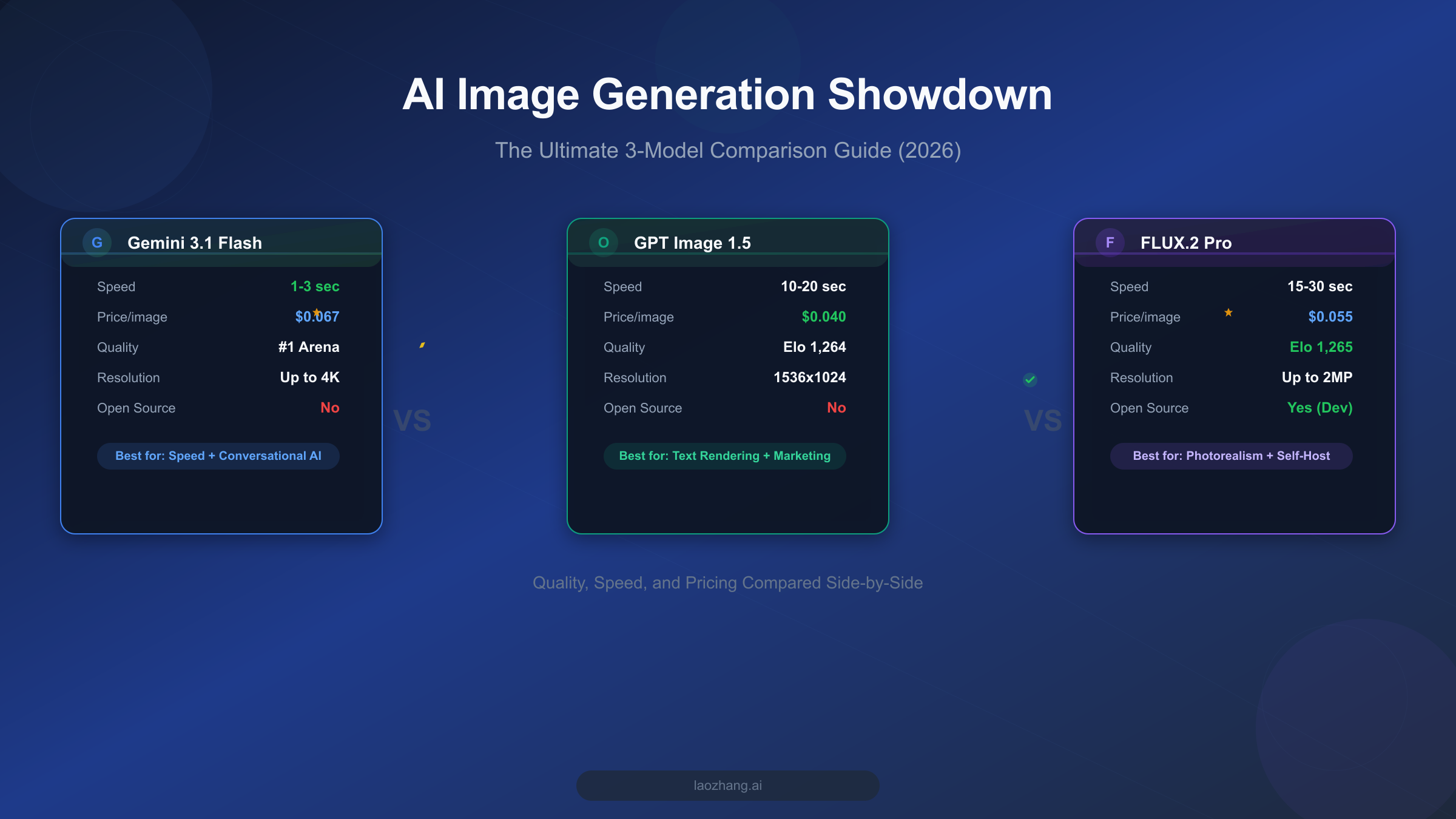

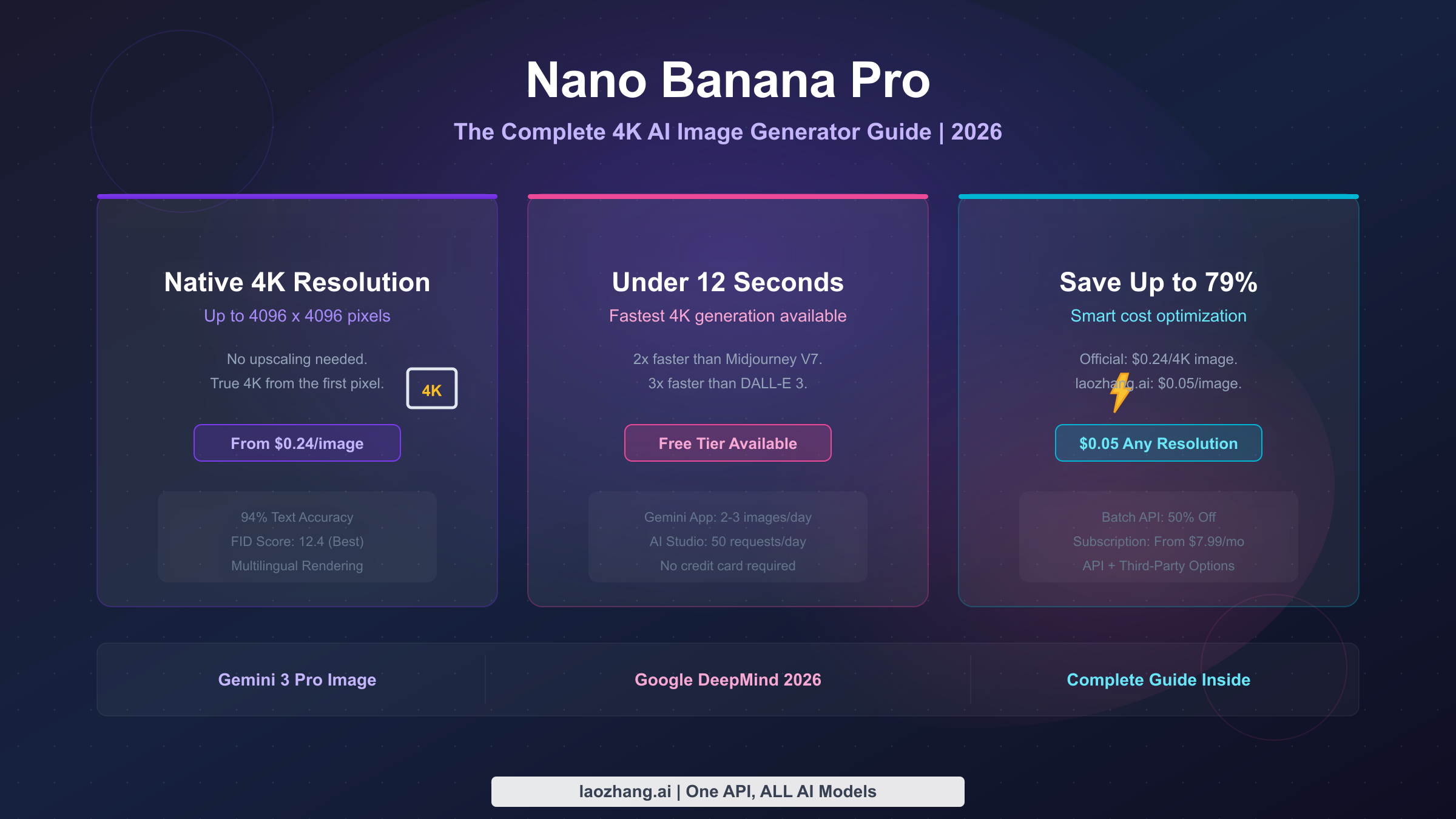
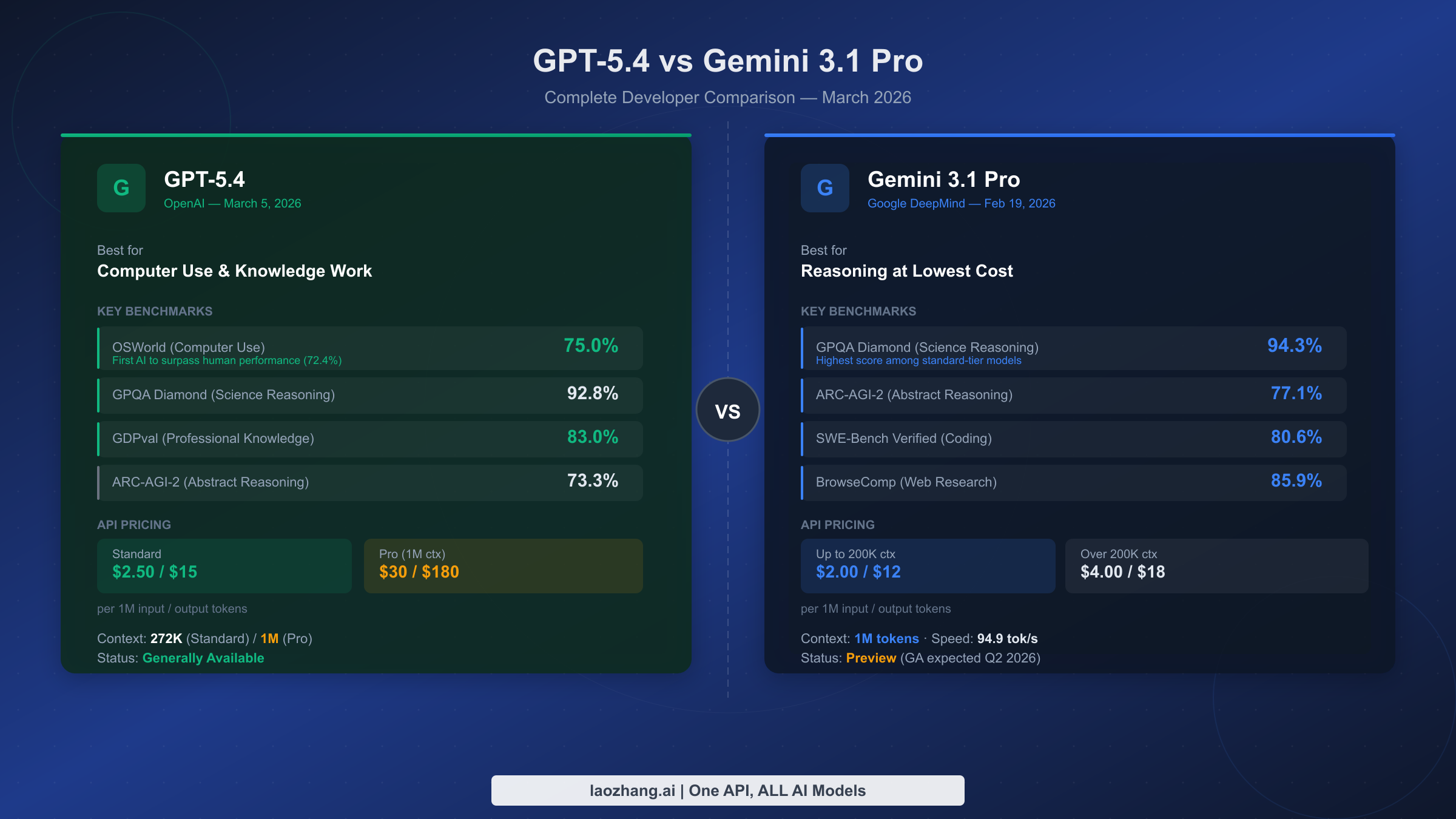
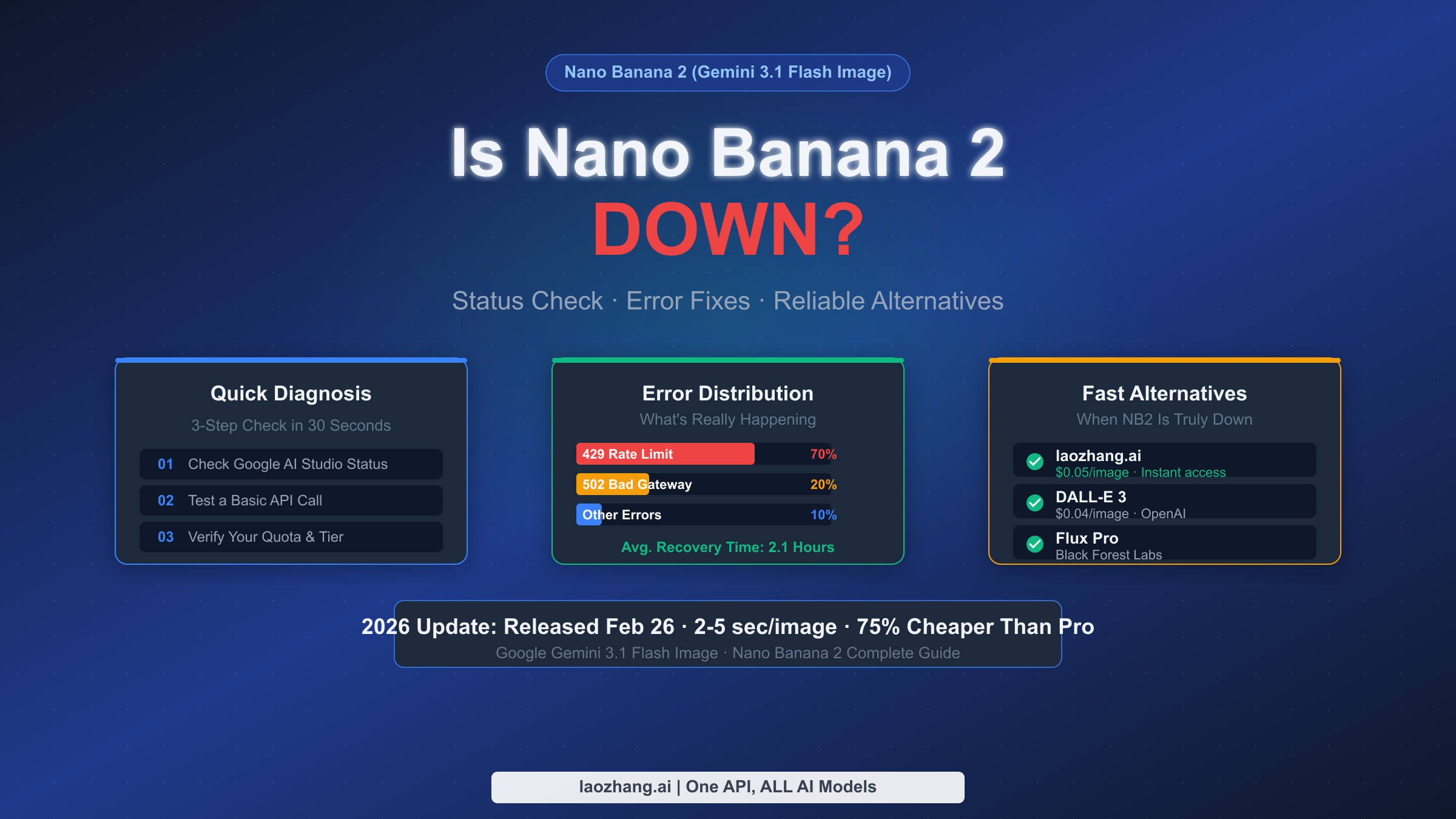
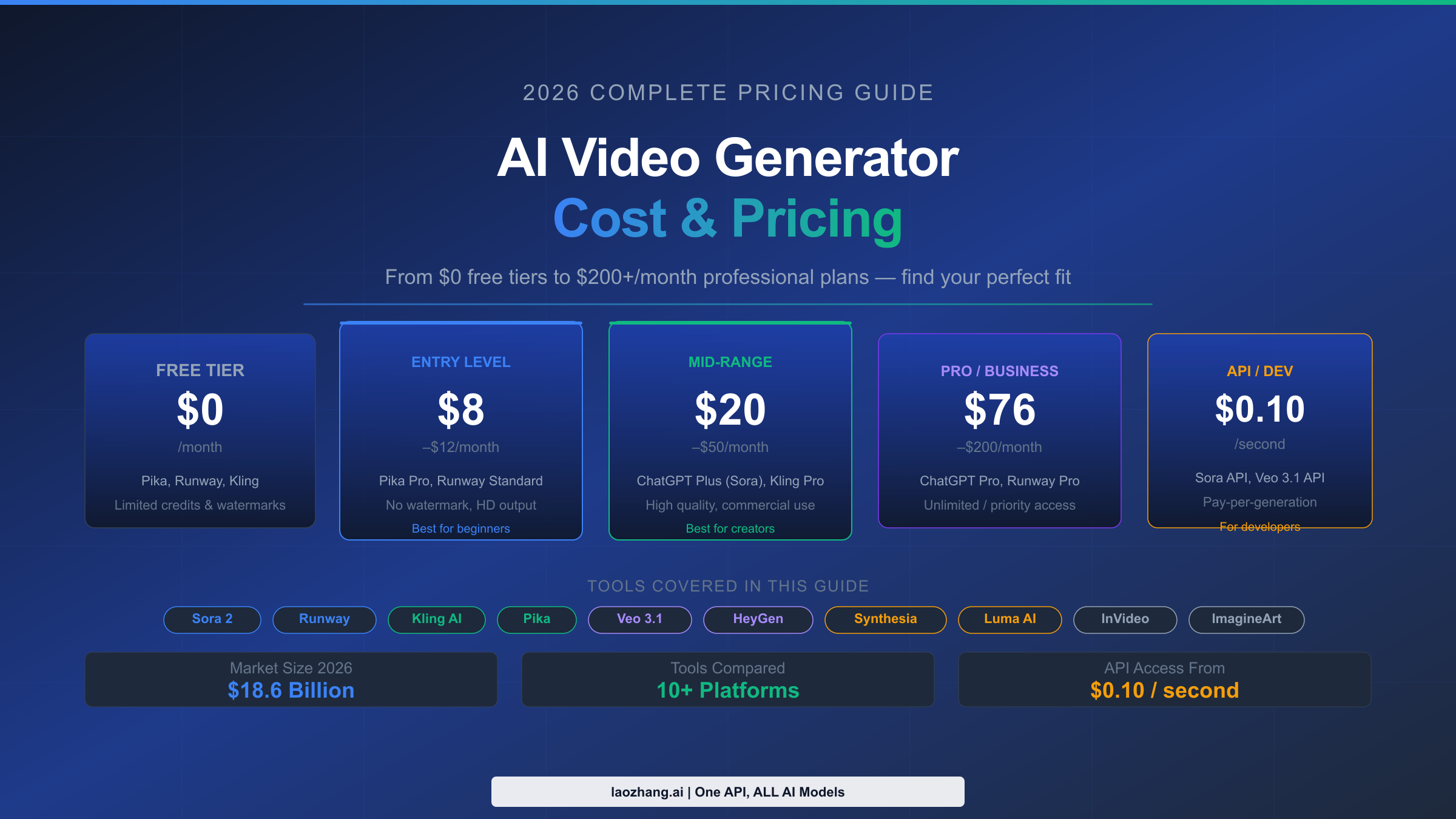



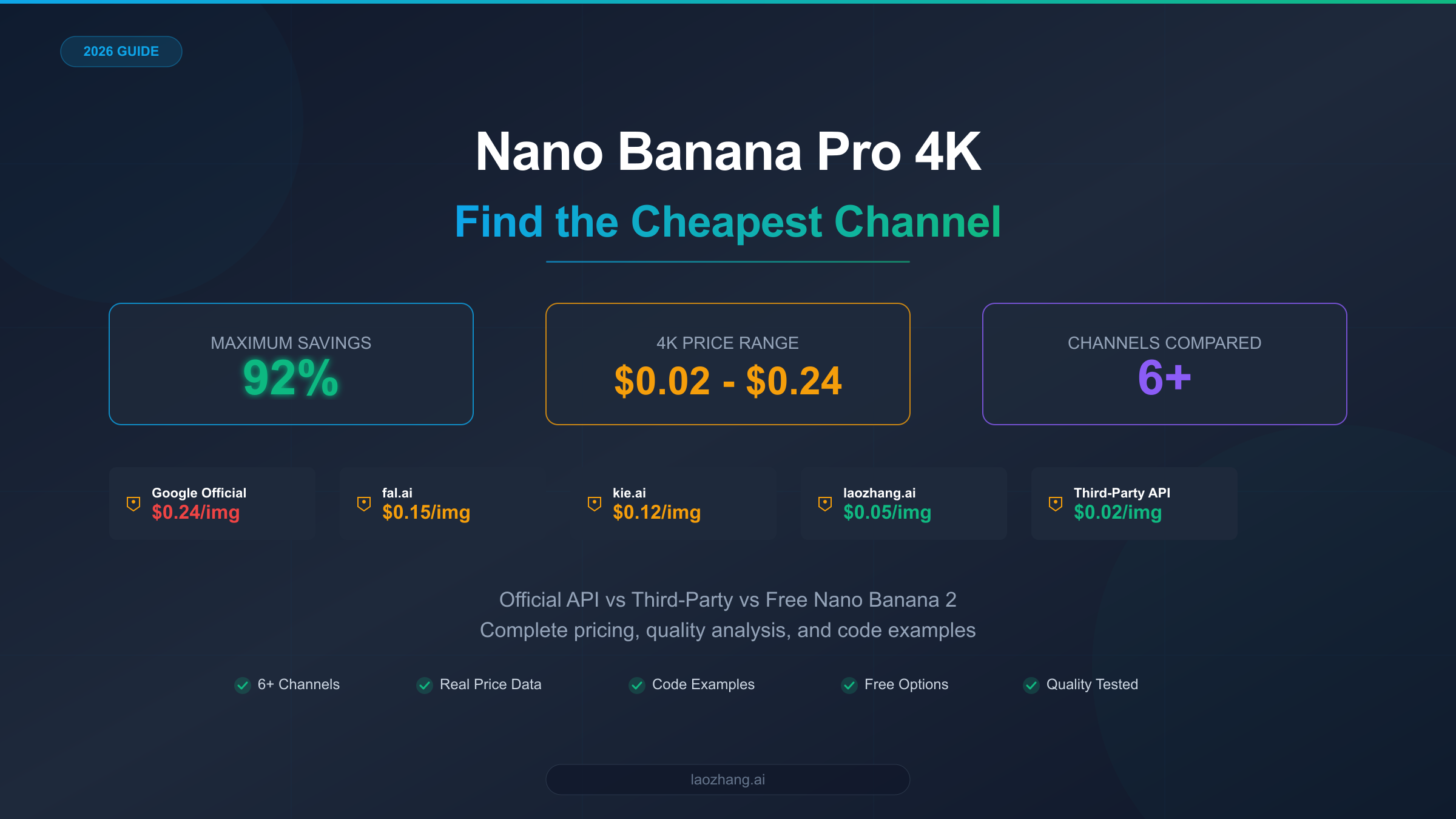
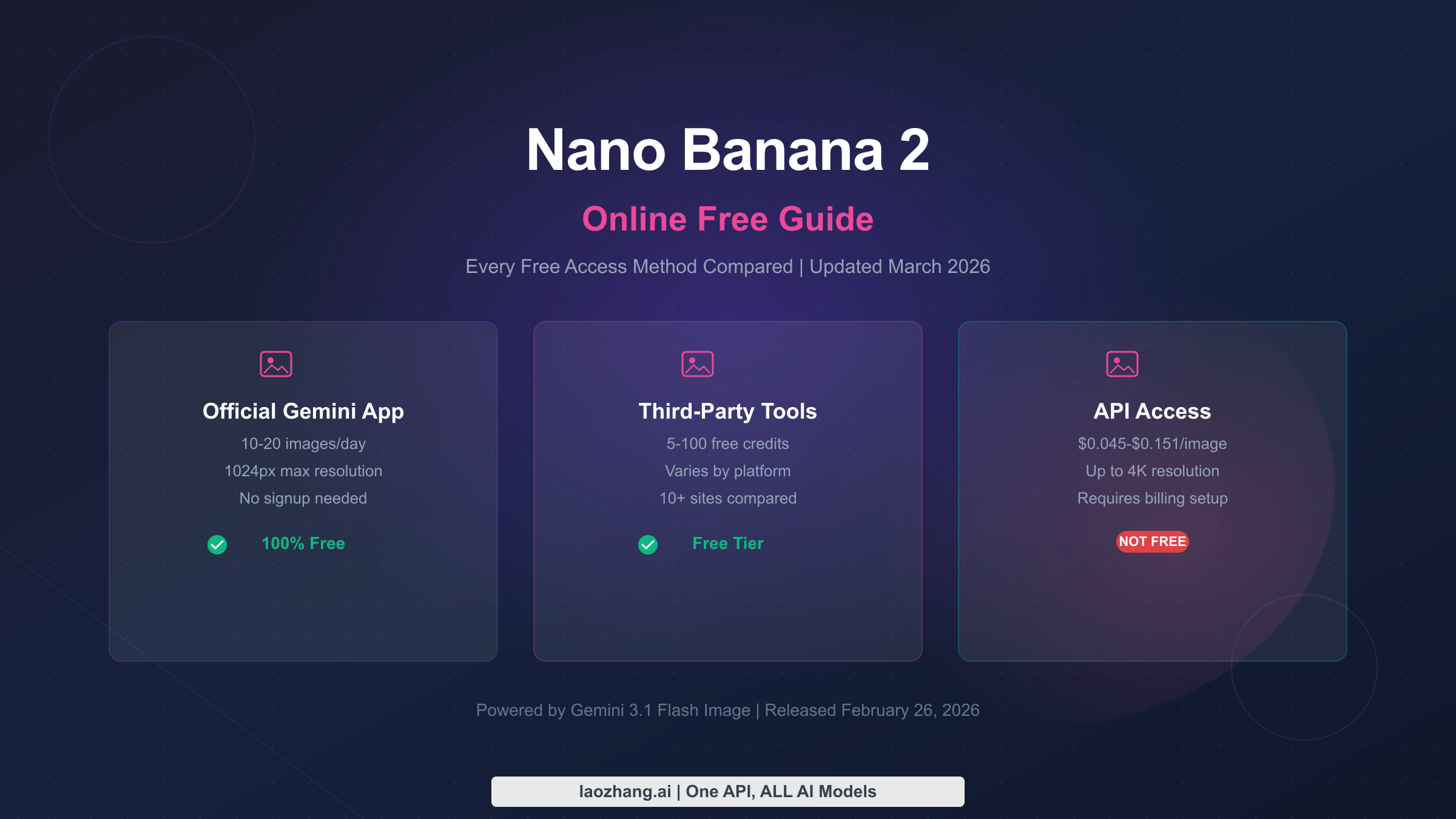
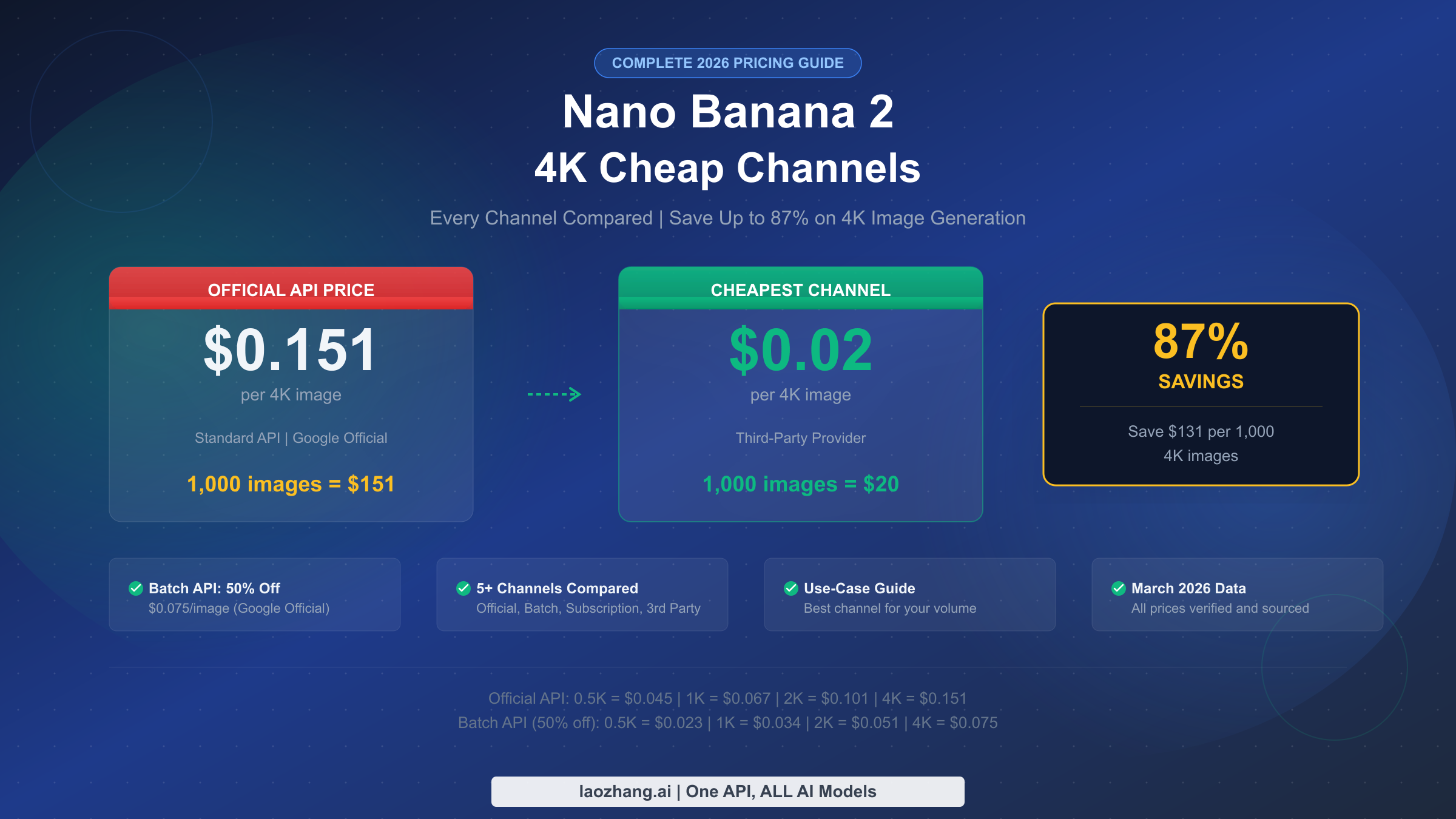
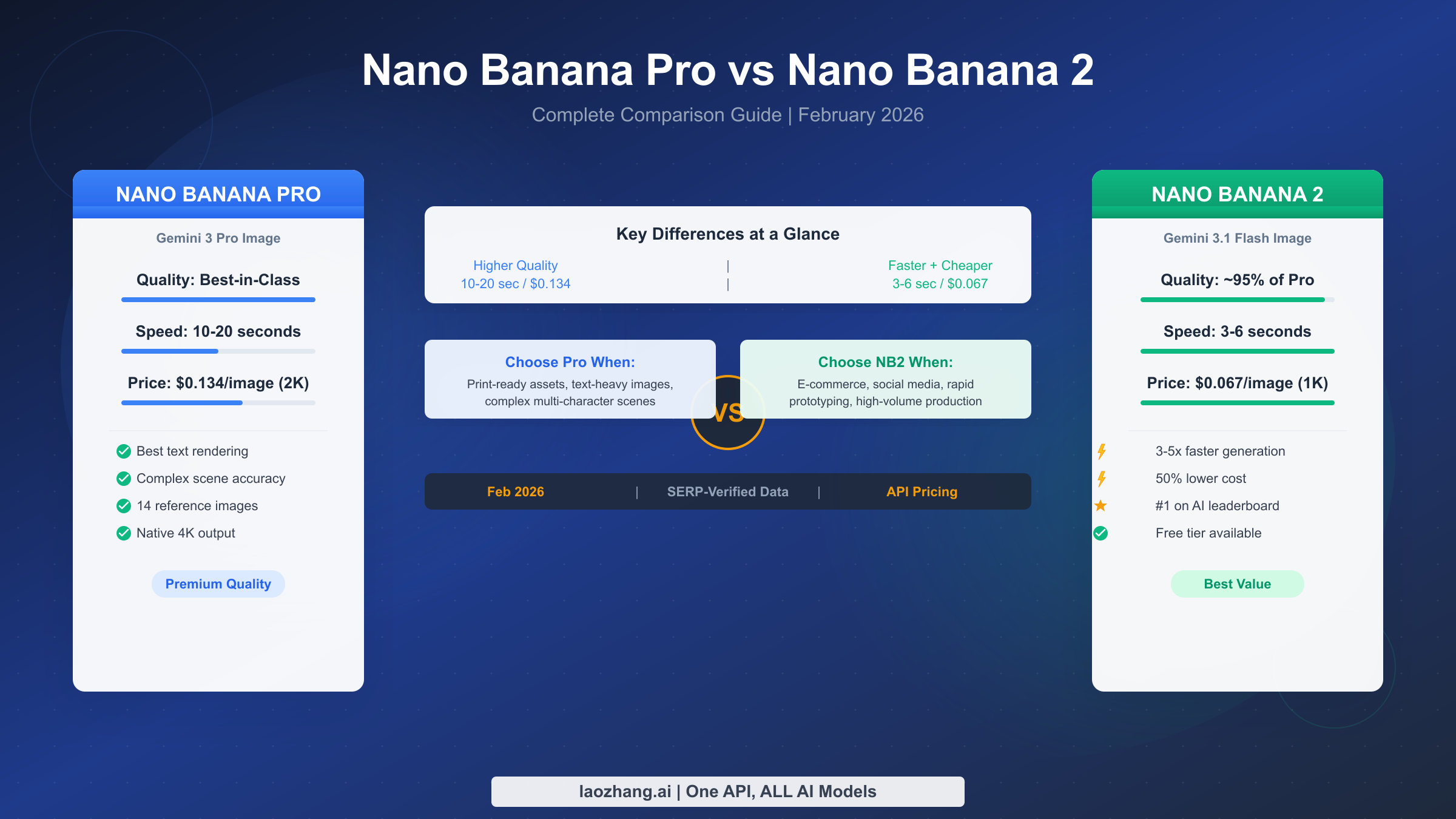
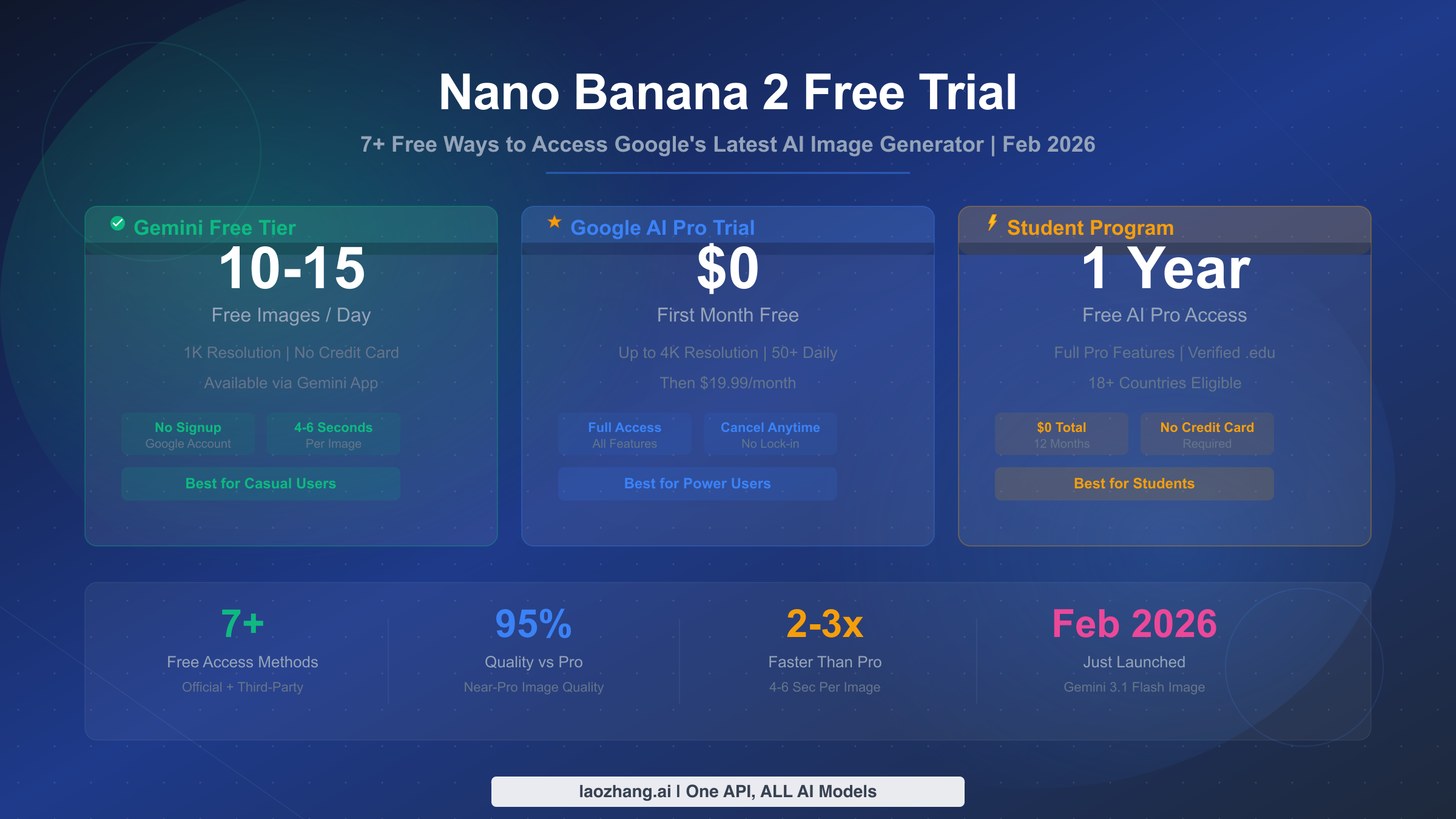


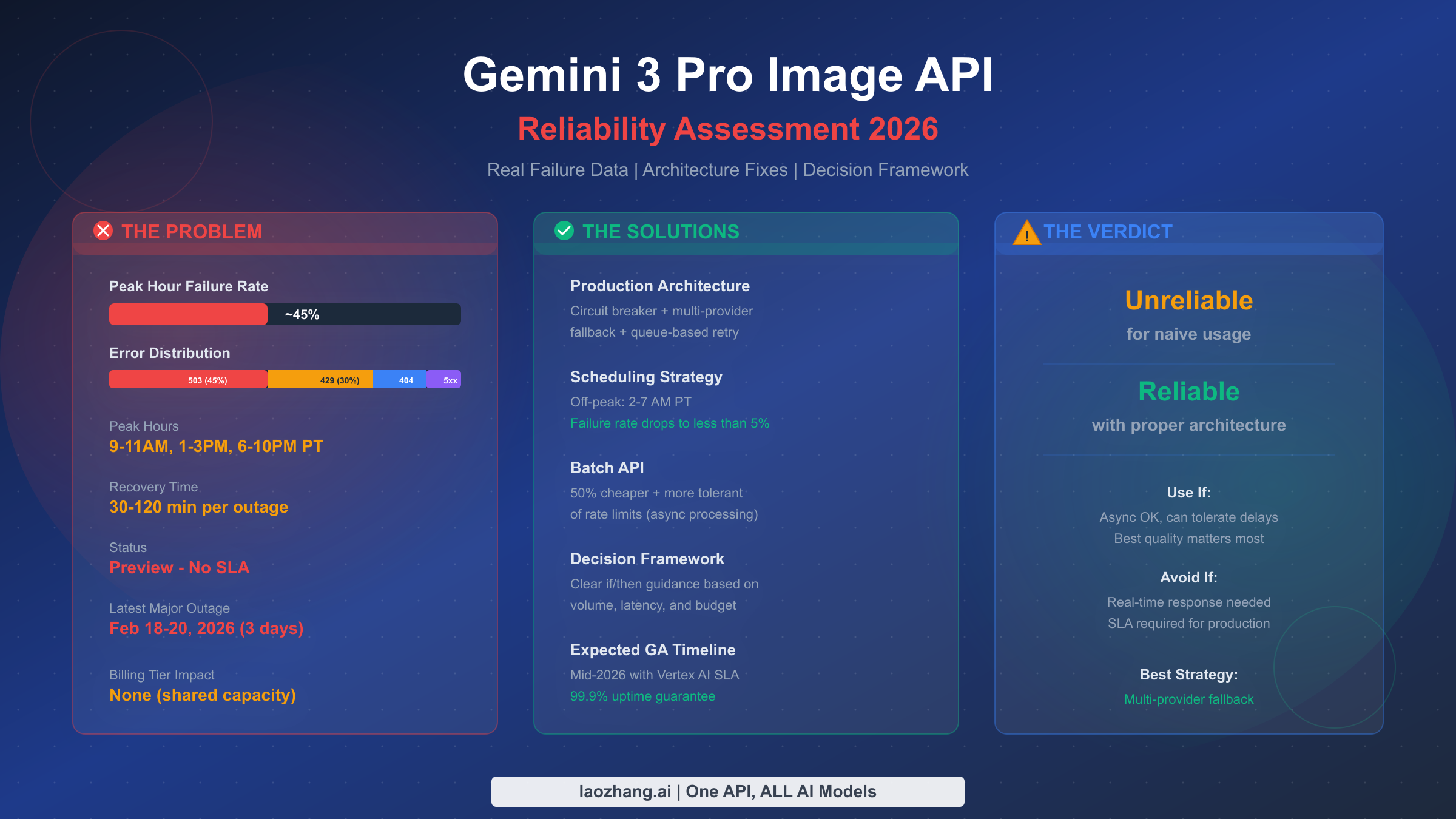
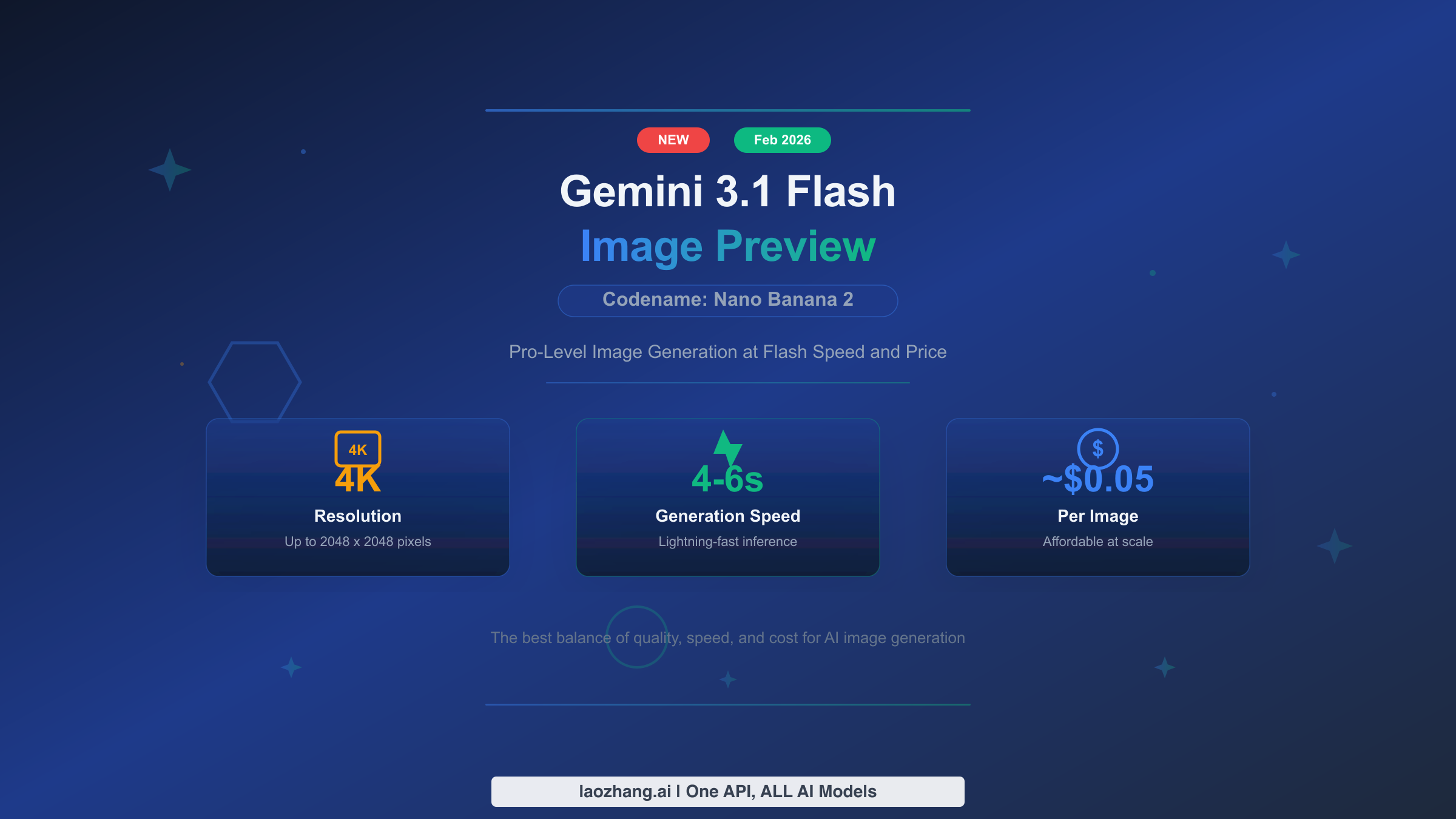
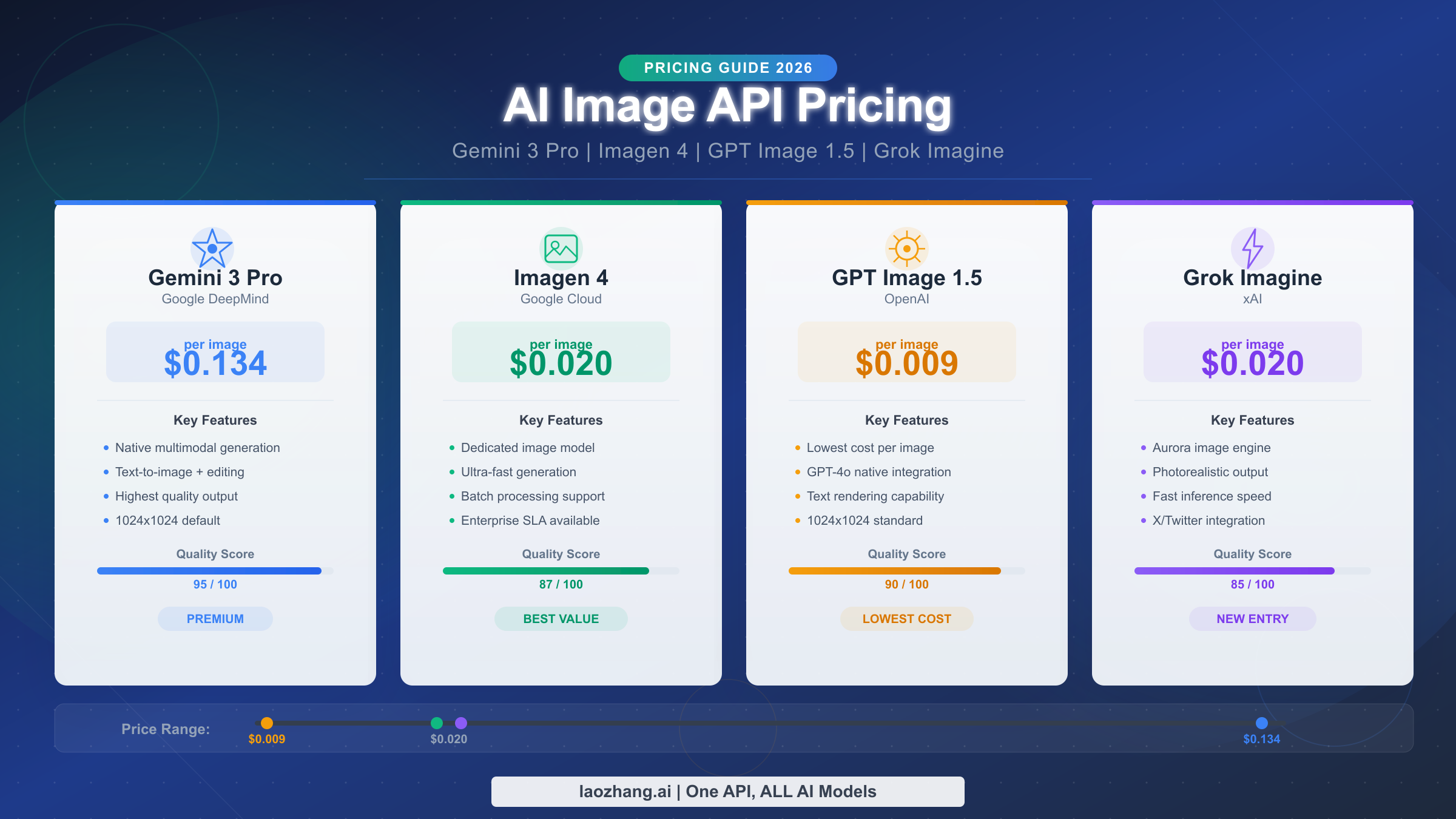


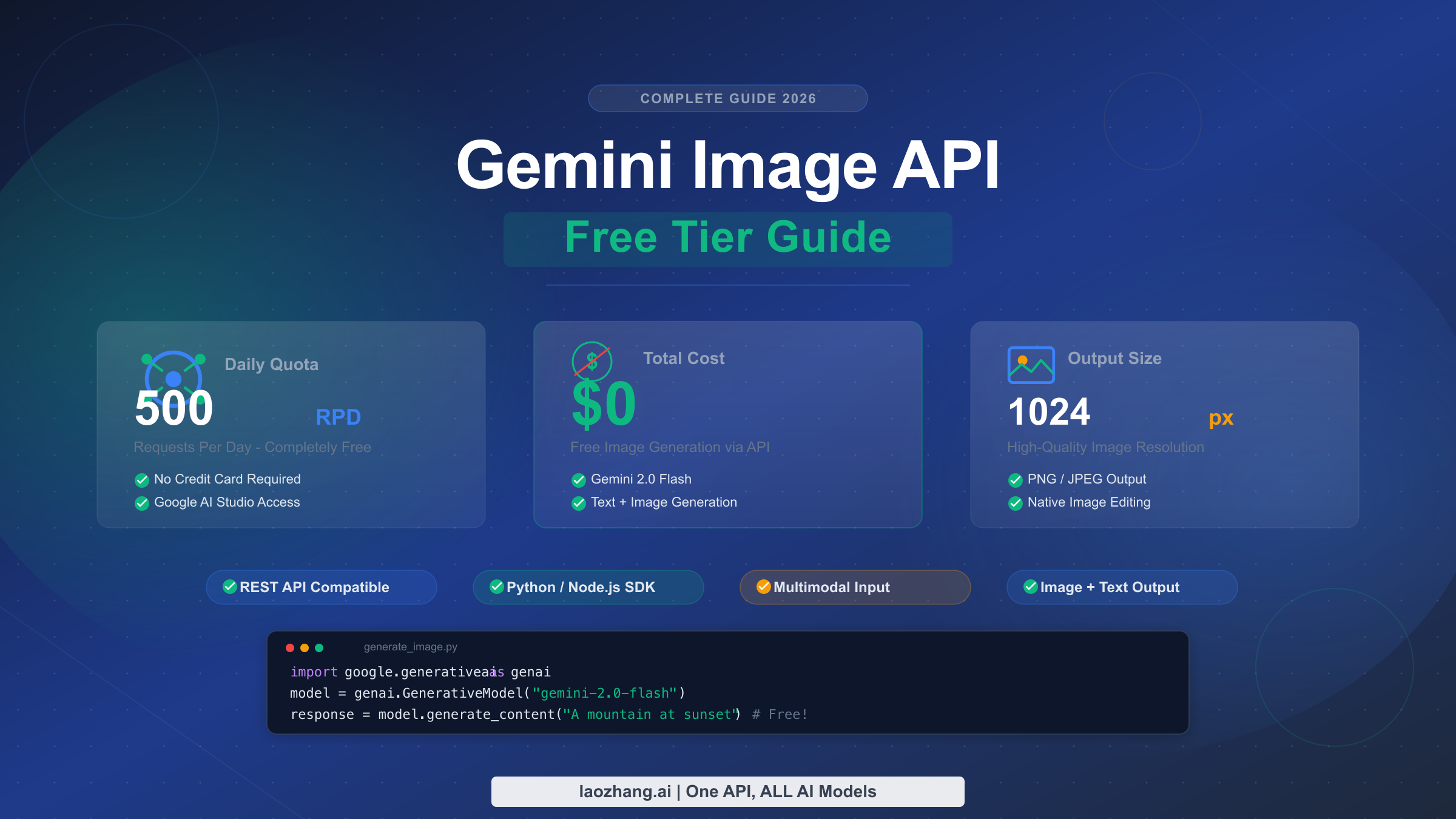
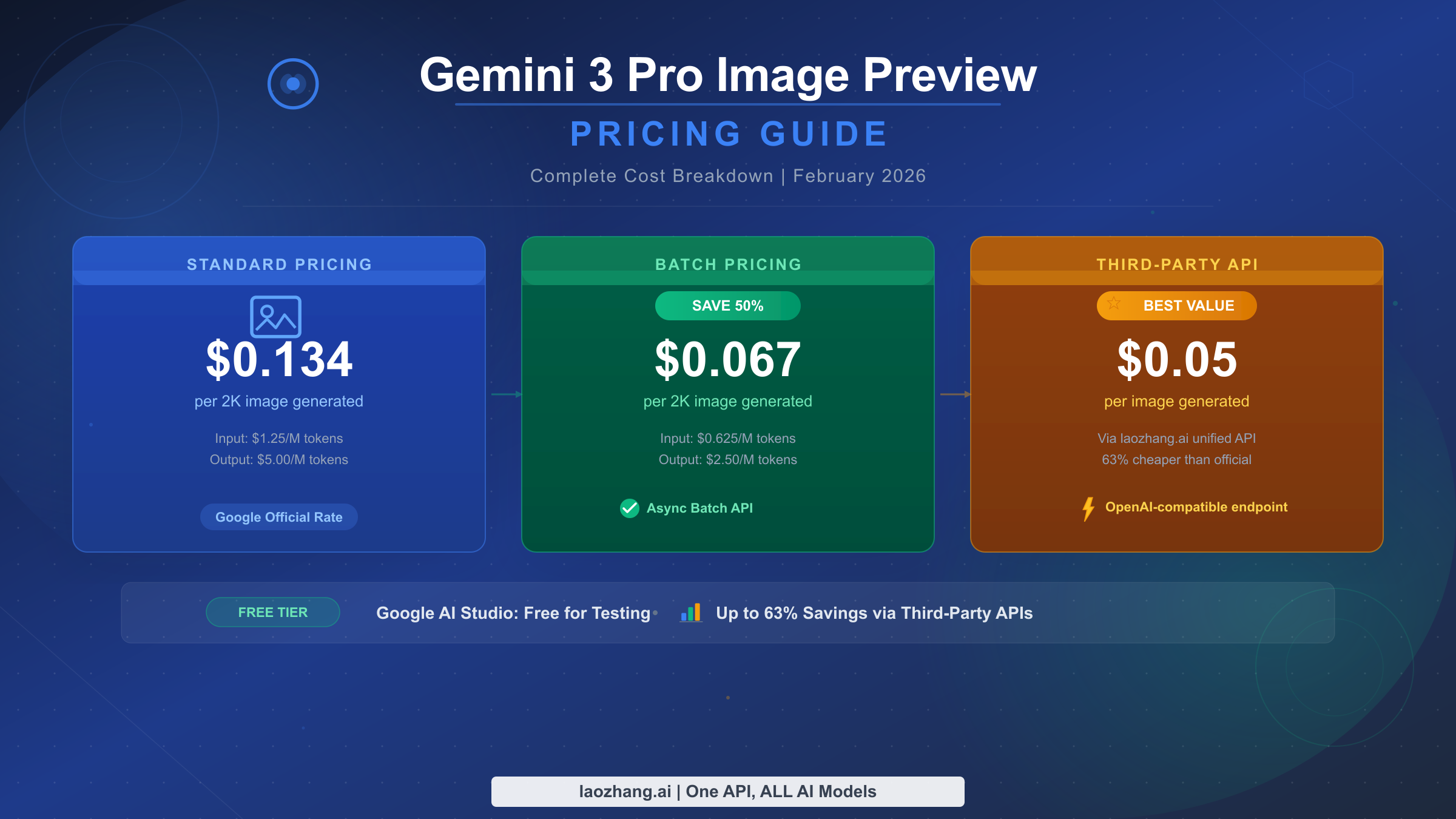
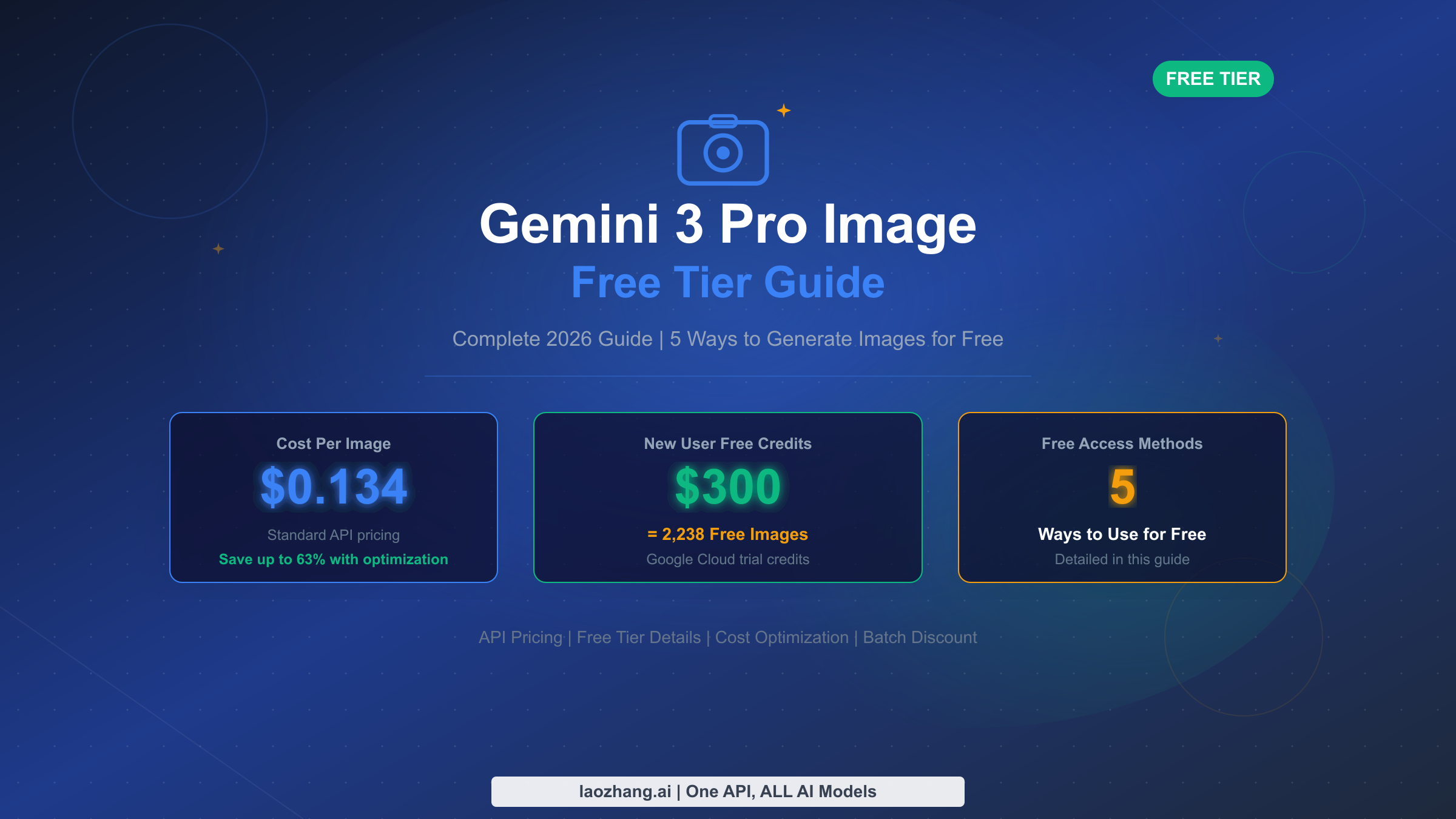

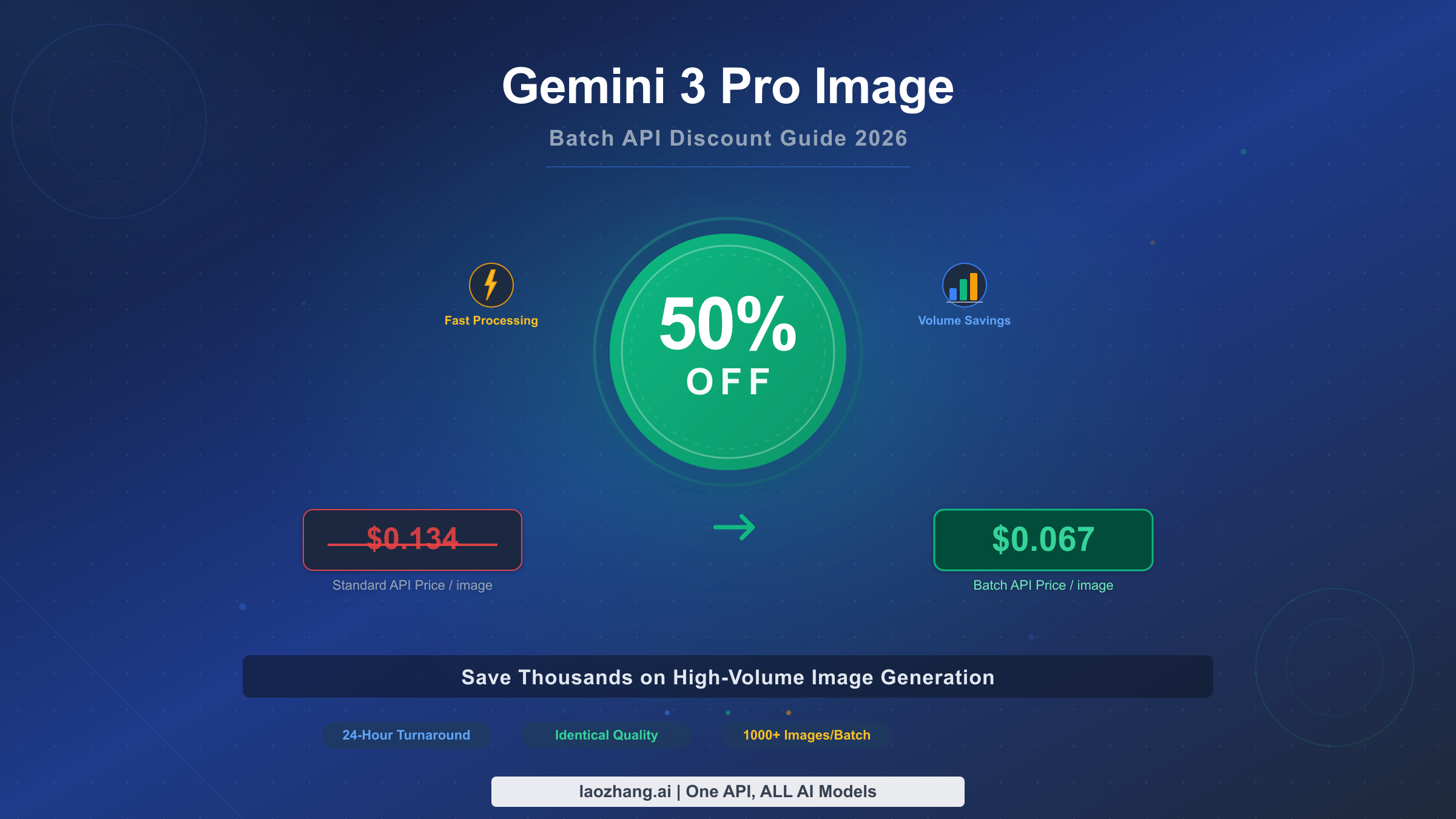
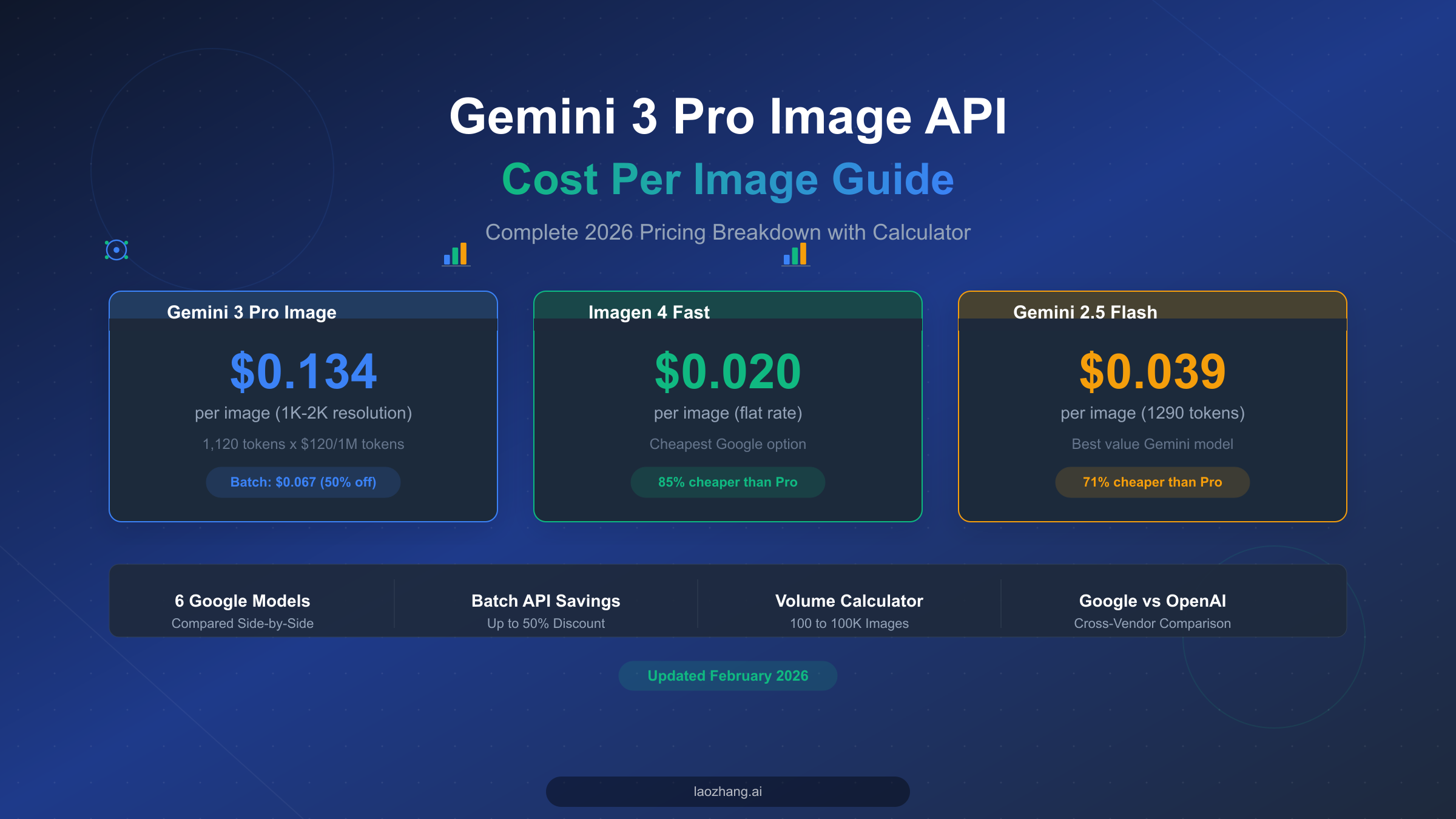
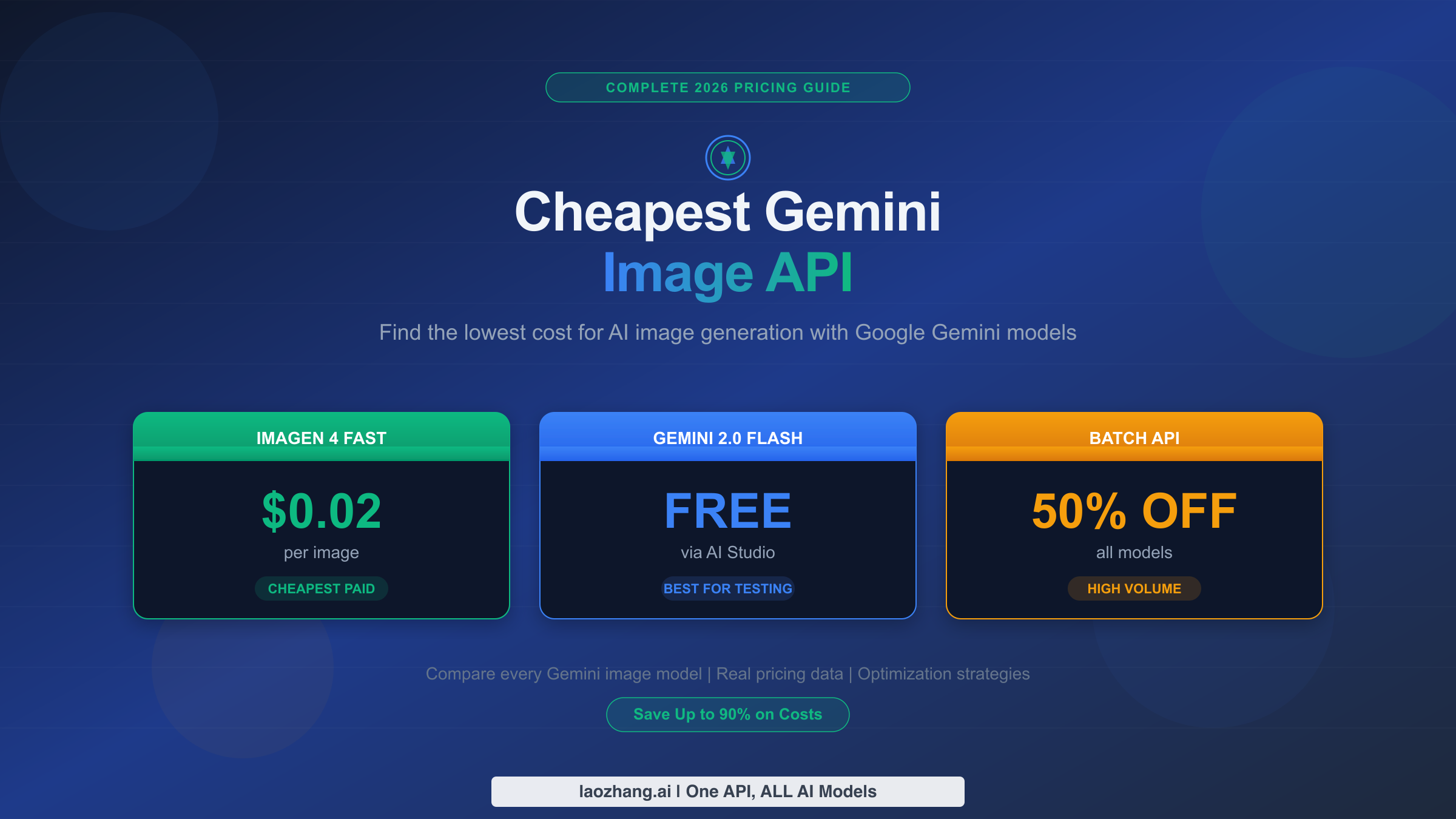
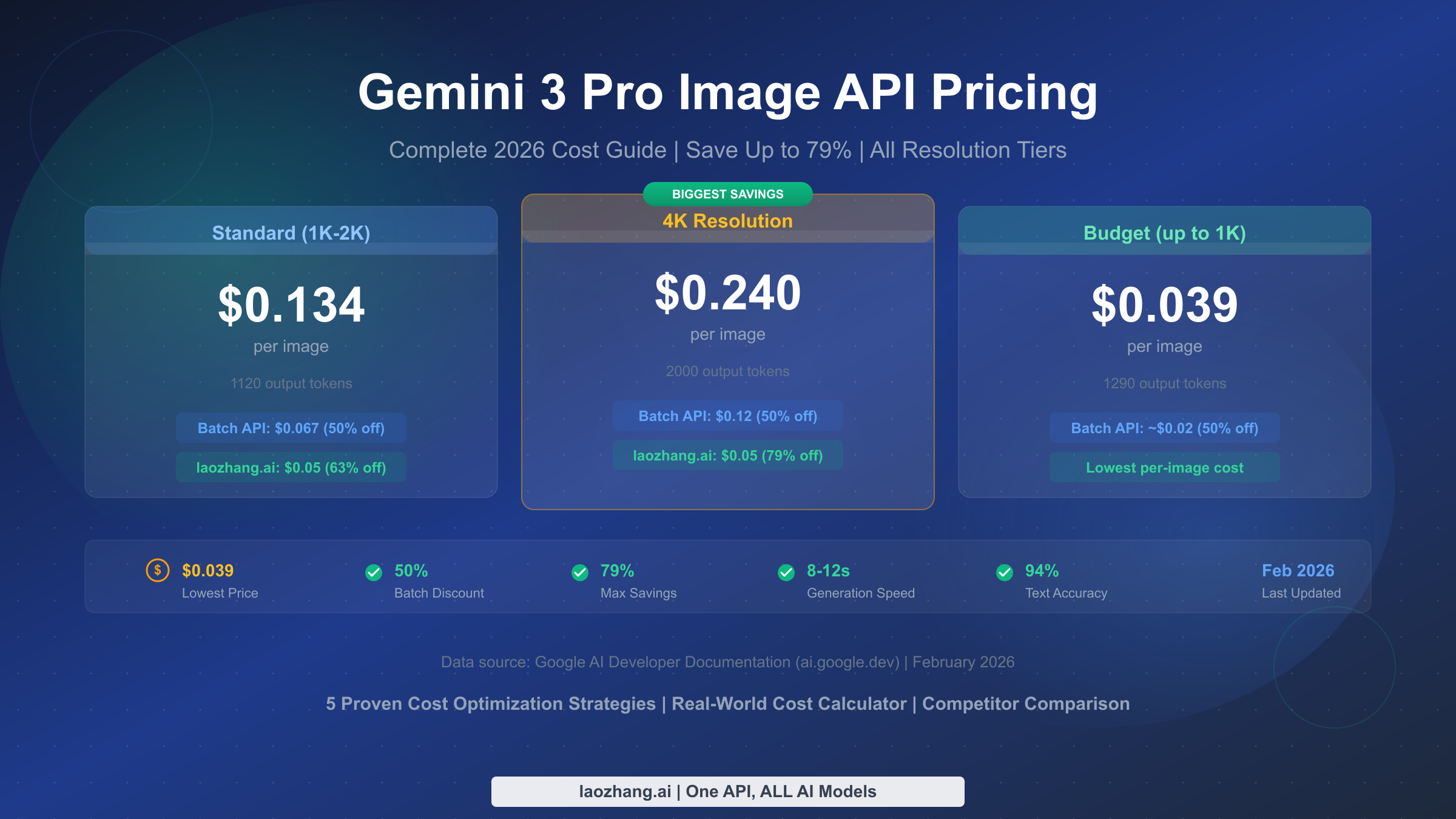
![Fix Gemini 3 Pro Image 503 Overloaded: Complete Troubleshooting Guide [2026]](/posts/en/fix-gemini-3-pro-image-503-overloaded/img/cover.png)
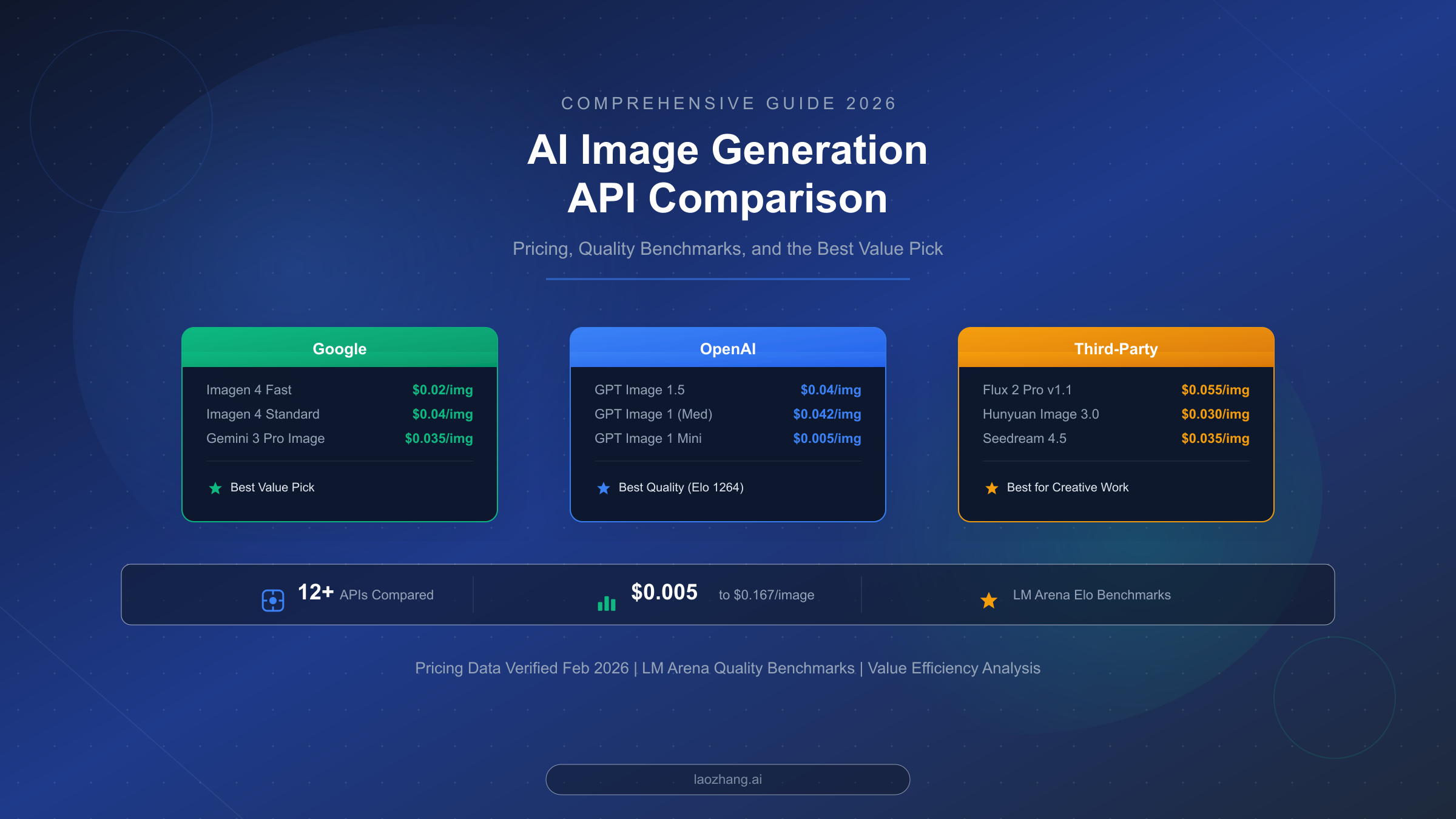







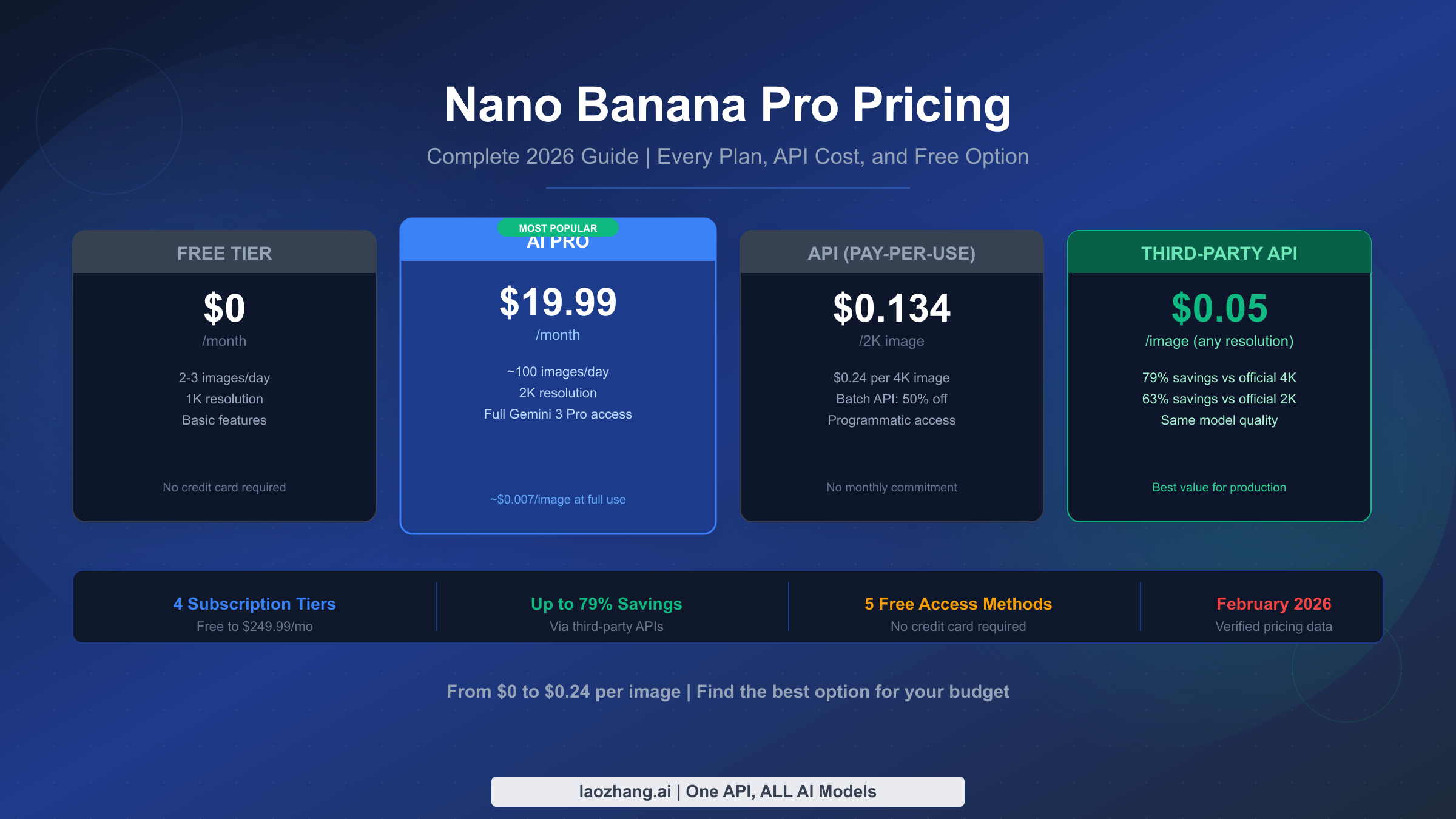




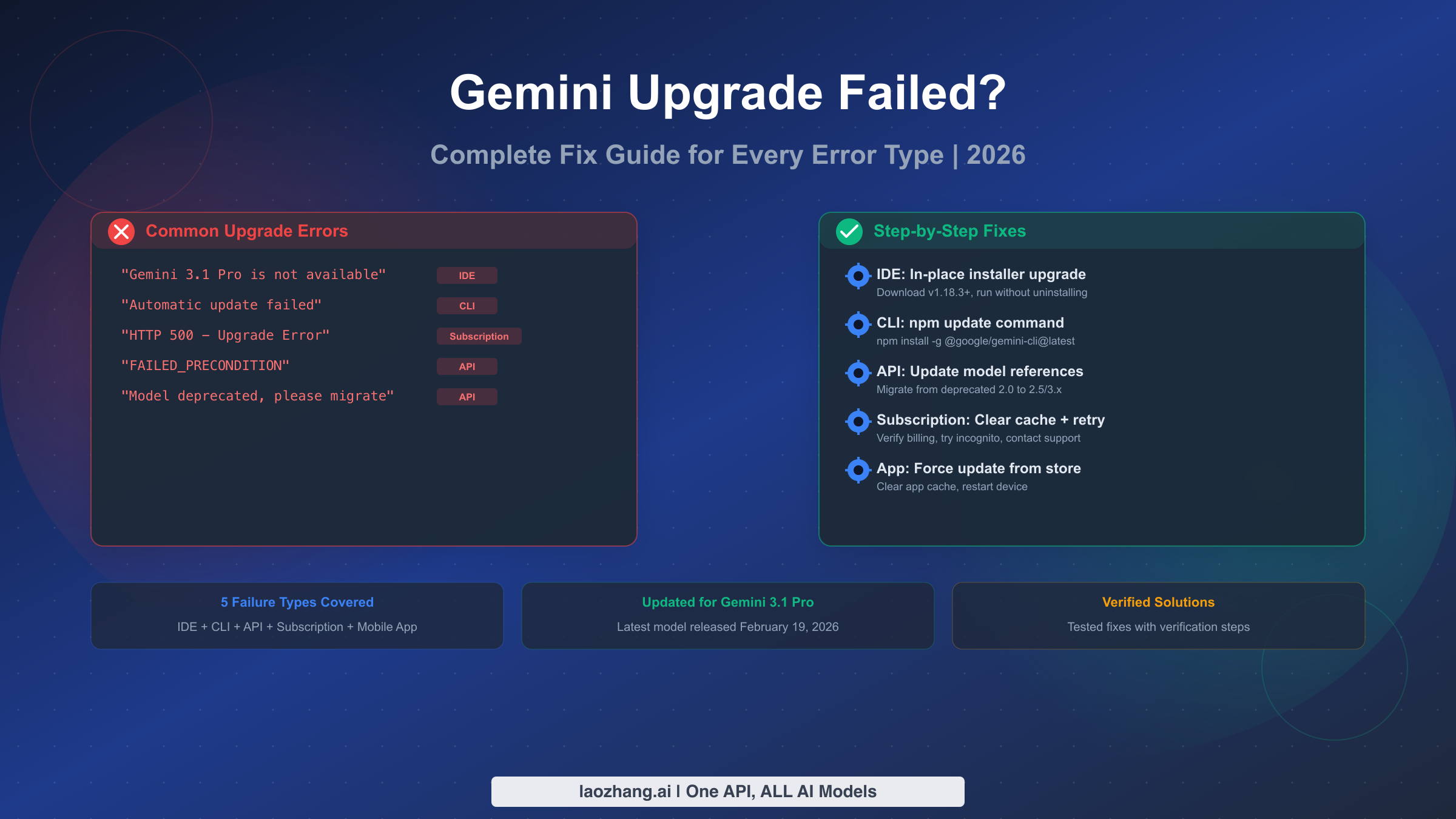
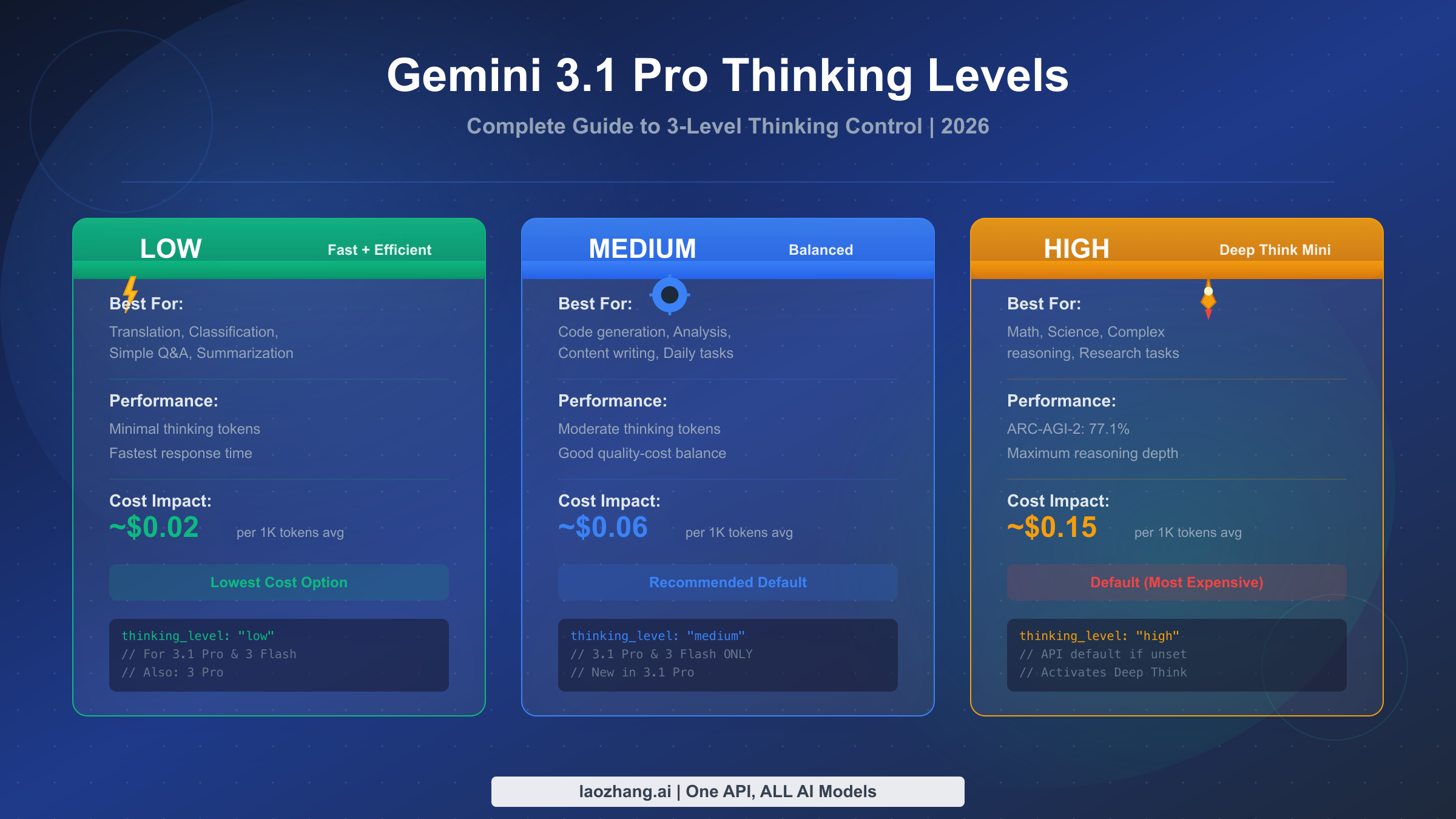

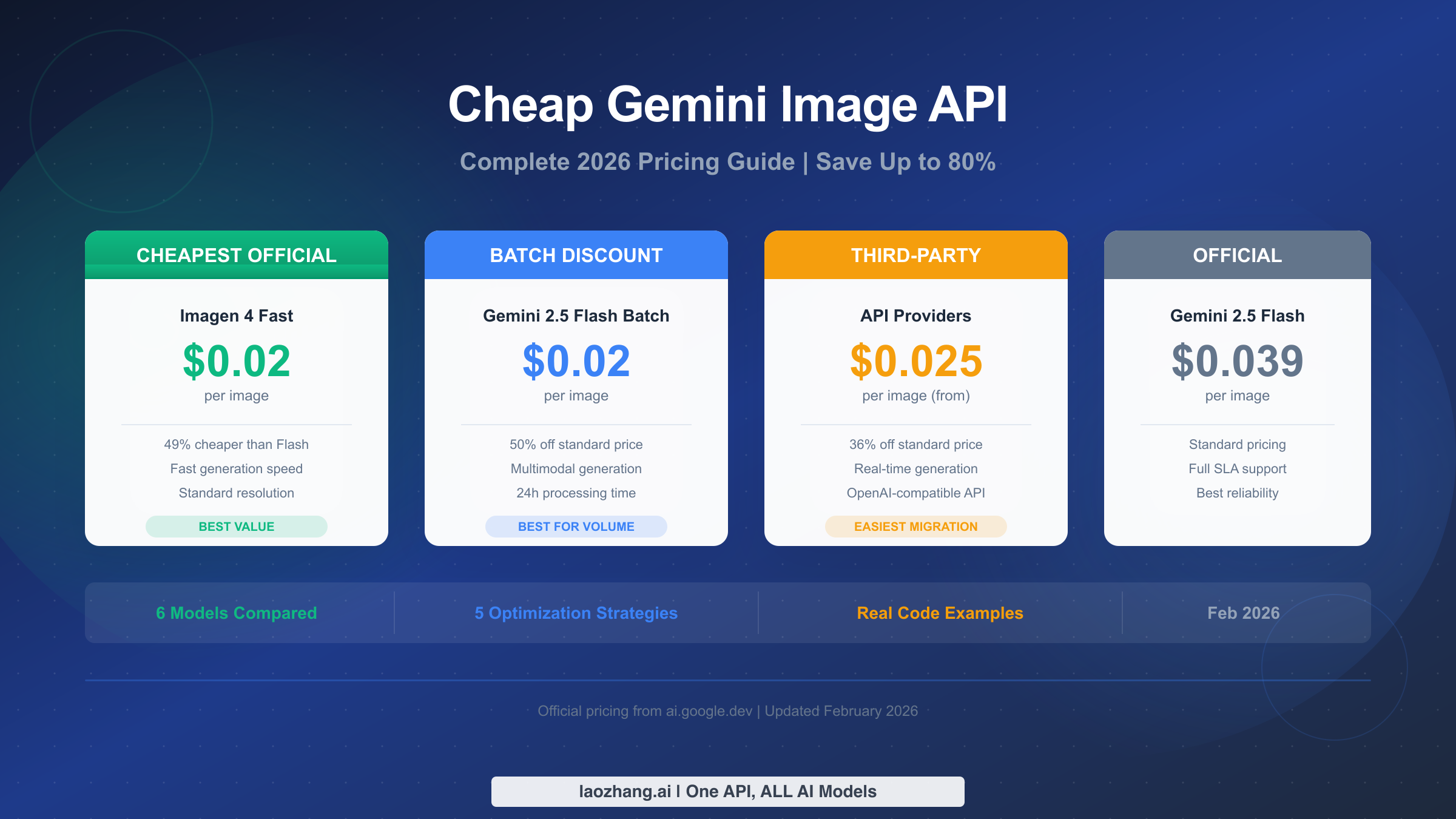
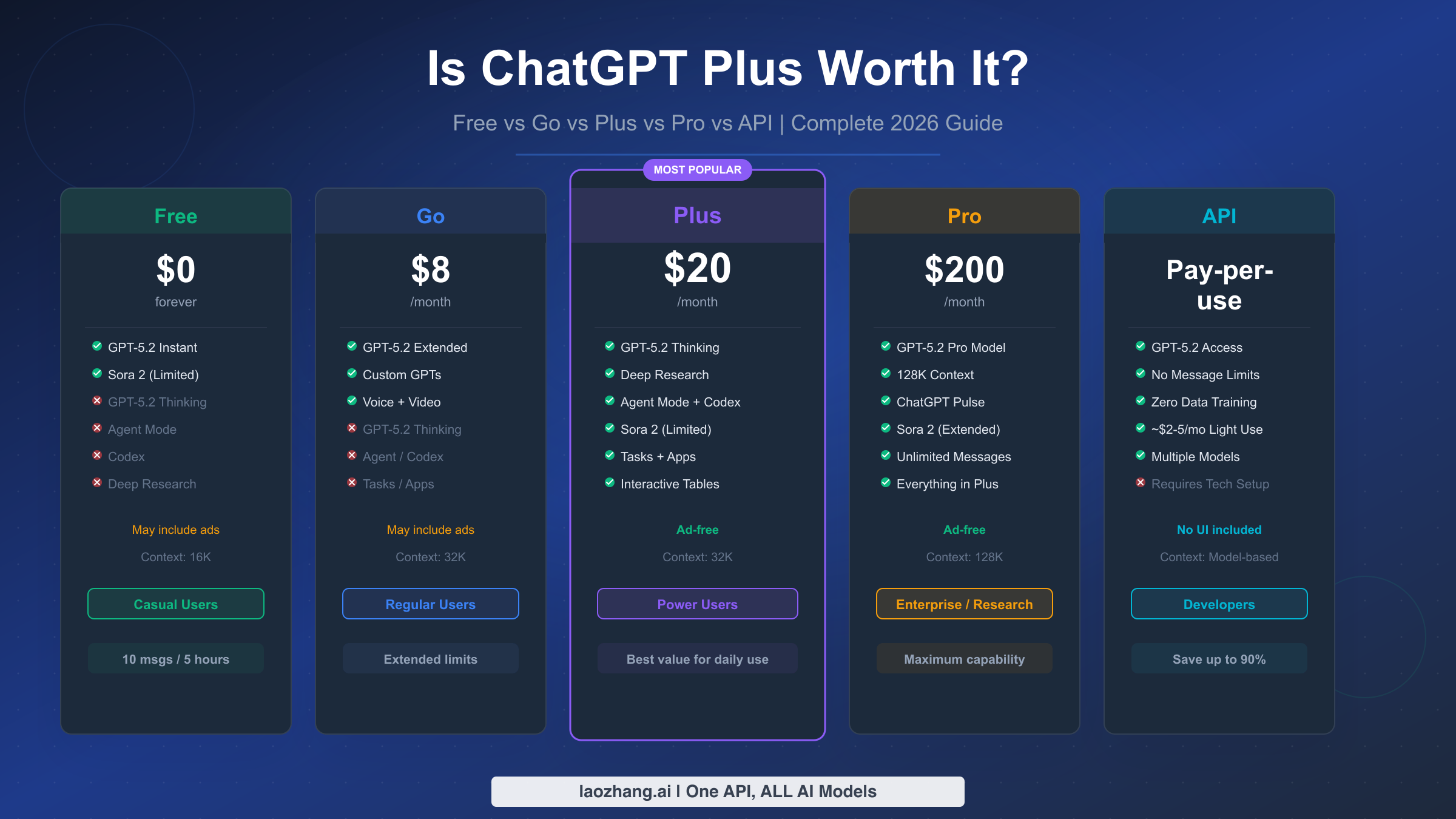




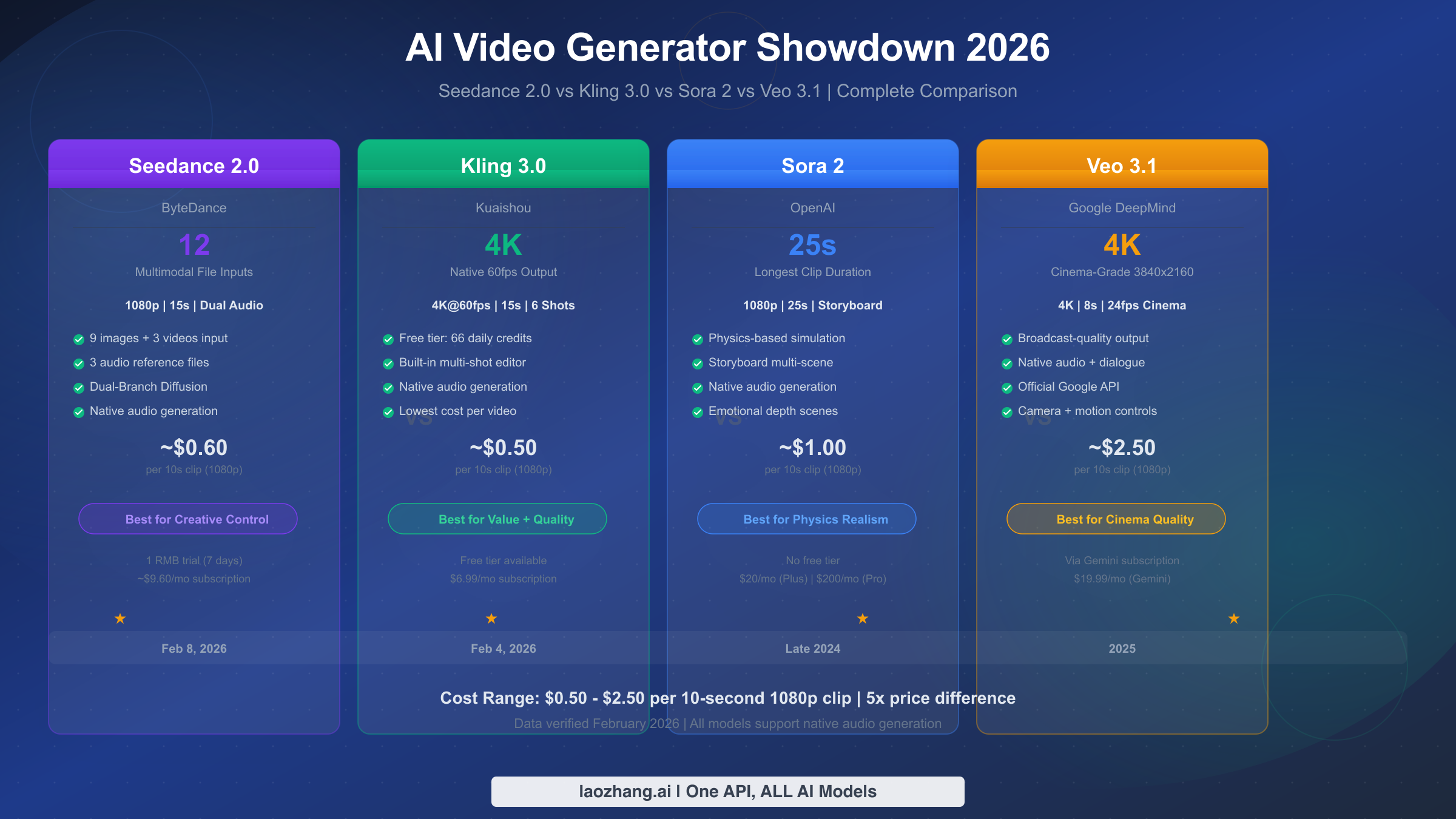
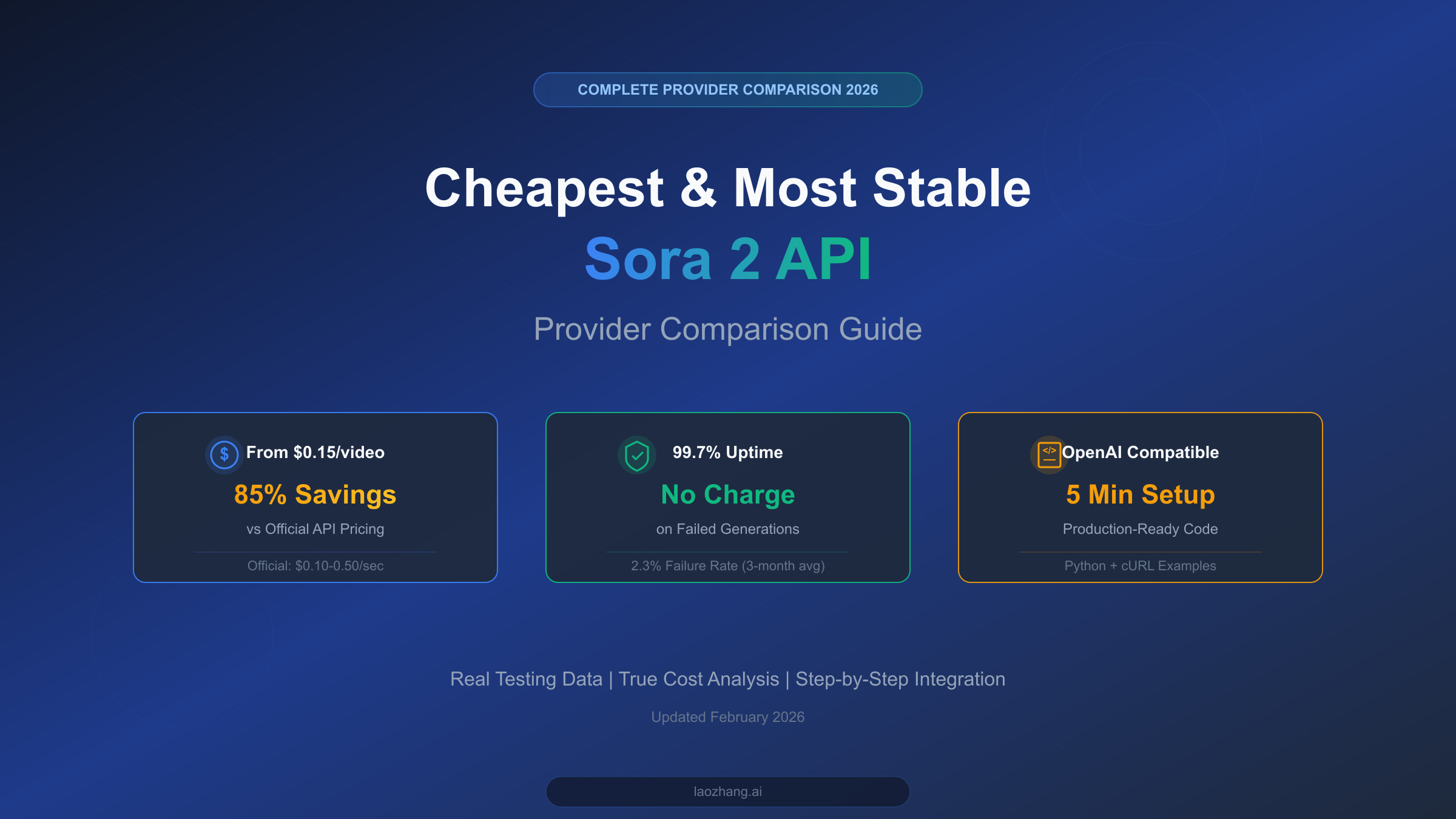
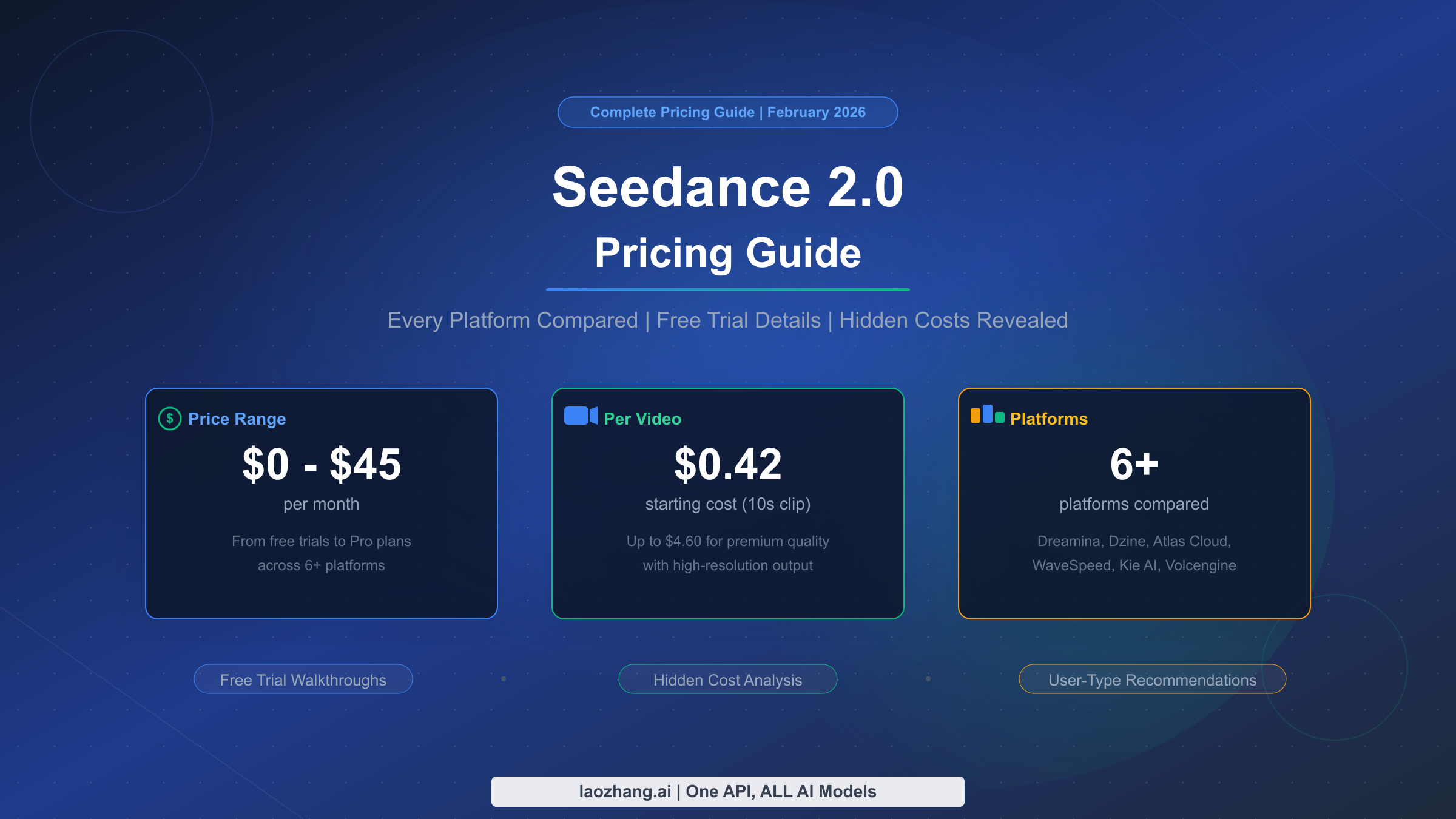

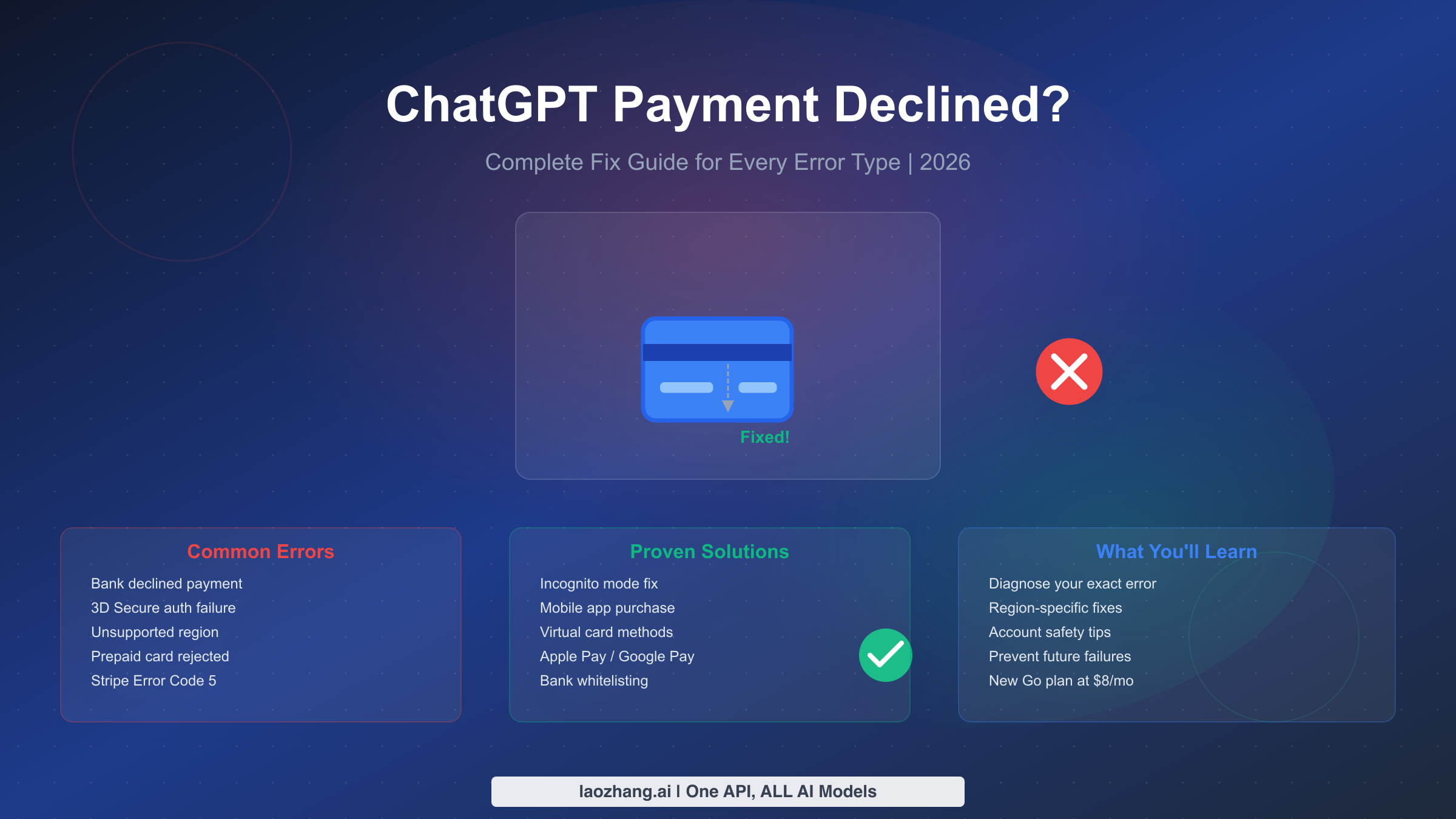






![Fix OpenClaw context_length_exceeded: Complete Troubleshooting Guide [2026]](/posts/en/openclaw-context-length-exceeded/img/cover.png)

![Fix OpenClaw Rate Limit Exceeded (429): Complete Troubleshooting Guide [2026]](/posts/en/openclaw-rate-limit-exceeded-429/img/cover.png)
![Fix OpenClaw Invalid Beta Flag Error: Complete Guide [2026]](/posts/en/openclaw-invalid-beta-flag/img/cover.png)

![Fix OpenClaw Anthropic API Key Error: Complete Guide [2026]](/posts/en/openclaw-anthropic-api-key-error/img/cover.png)
![Gemini 3 Complete Comparison: Pro, Flash, Nano Banana Pro Full Guide [2026 Update]](/posts/en/gemini-3-comparison/img/cover.png)