ChatGPT Plus Image Generation Limit: Master DALL-E 3’s 50 Images per 3 Hours
ChatGPT Plus enforces a 50 images per 3-hour rolling window limit for DALL-E 3 and GPT-4o image generation. This quota refreshes continuously rather than resetting daily, with dynamic throttling to 40-45 images during peak hours from 2-6 PM EST.

Understanding ChatGPT Plus Image Generation Limits in 2025
ChatGPT Plus image generation limits represent a carefully balanced system between computational resources and user access. The current quota structure, established in July 2025, provides Plus subscribers with 50 image generations every three hours through a sophisticated rolling window mechanism. This limit applies to both DALL-E 3 requests and the newer GPT-4o native image generation capabilities, treating them as a unified quota pool despite their fundamentally different technical implementations.
The evolution from pure DALL-E 3 API integration to GPT-4o’s multimodal generation marks a significant shift in how these limits function. While DALL-E 3 operates as discrete API calls with predictable resource consumption, GPT-4o’s native generation integrates visual creation directly into the language model’s neural architecture. This integration enables contextual understanding across conversations but introduces variable resource demands that necessitate dynamic quota adjustments. To better understand the capabilities and limitations of DALL-E 3 specifically, our comprehensive DALL-E 3 guide covers technical specifications and best practices.
Understanding your tier’s specific limits becomes crucial for effective usage planning. ChatGPT Plus users receive 50 images per 3-hour window at $20 monthly, while Team subscribers enjoy doubled quotas with 100 images per window at $30 per user. Free tier users face severe restrictions with only 2 daily generations, primarily serving as a preview rather than a functional creative tool. Enterprise customers negotiate custom quotas based on their specific infrastructure agreements with OpenAI. For a comprehensive overview of all ChatGPT Plus features beyond image generation, understanding these tiers helps maximize your subscription value.
The quota system’s complexity extends beyond simple numerical limits. Each generation counts equally regardless of resolution (1024×1024, 1024×1792, or 1792×1024), quality settings, or generation method. Failed generations, including those blocked by content policies or technical errors, still consume quota slots. This “all or nothing” approach means users must carefully consider each generation request to maximize their available resources within the rolling three-hour windows.
How the 50 Image Generation Limit Actually Works
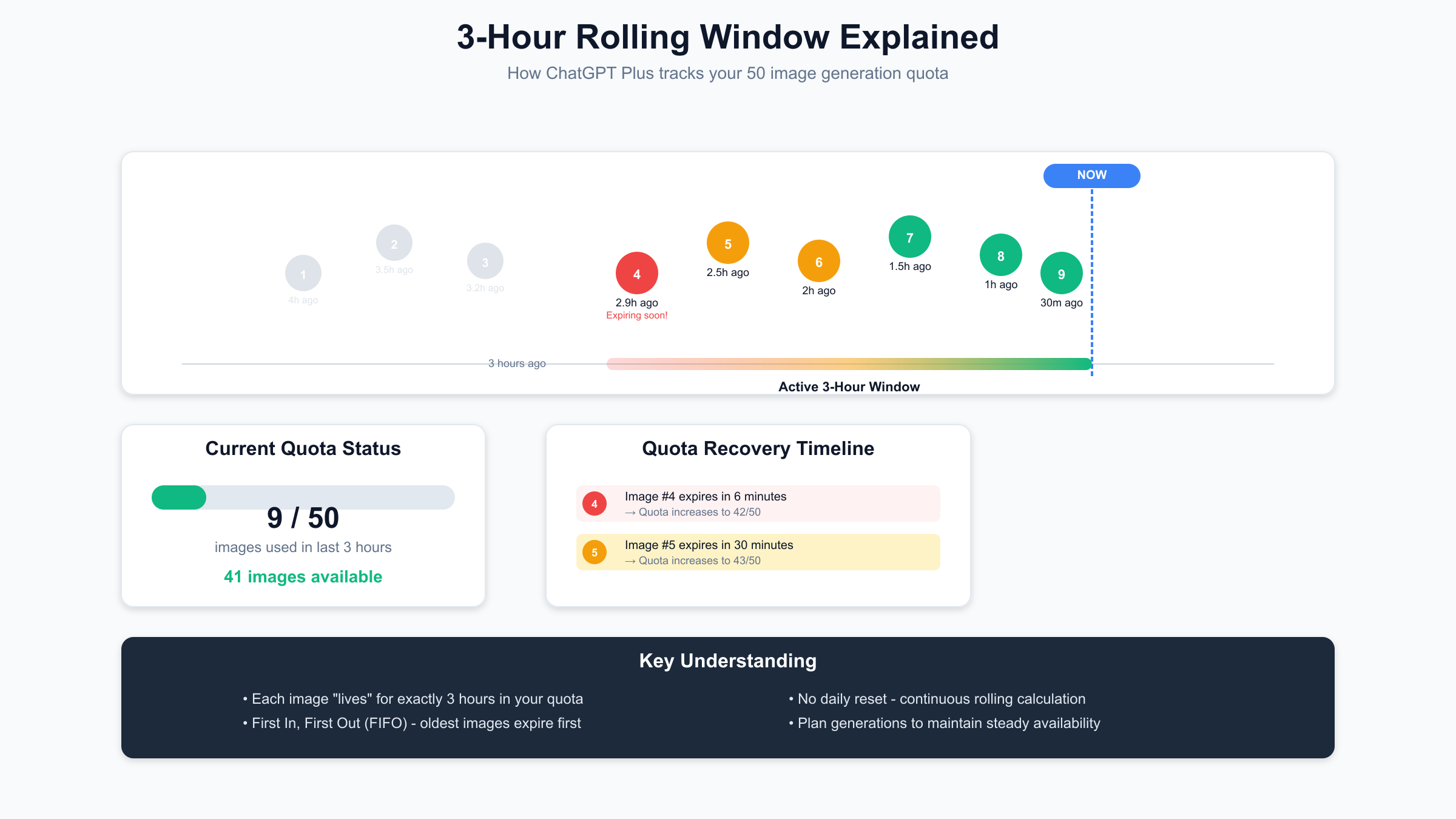
The rolling 3-hour window mechanism differs fundamentally from traditional daily reset systems. Rather than providing a fresh quota at midnight, ChatGPT Plus maintains a continuous 180-minute lookback period that tracks every image generation timestamp. When you request a new image, the system counts all generations within the past three hours. If this count reaches 50, your request gets denied until older generations “age out” of the window.
This implementation uses a distributed timestamp queue synchronized across OpenAI’s server infrastructure. Each generation request gets logged with microsecond precision, creating a chronological record that determines quota availability. The system’s elegance lies in its fairness – users who space out their generations enjoy consistent availability, while those who burst-generate face temporary restrictions until their older timestamps expire.
# Simplified rolling window quota tracker
from datetime import datetime, timedelta
from collections import deque
class ImageQuotaTracker:
def __init__(self, limit=50, window_hours=3):
self.limit = limit
self.window = timedelta(hours=window_hours)
self.generations = deque()
def can_generate(self):
"""Check if generation is allowed"""
now = datetime.now()
cutoff = now - self.window
# Remove expired timestamps
while self.generations and self.generations[0] < cutoff:
self.generations.popleft()
return len(self.generations) < self.limit
def record_generation(self):
"""Record a new generation if allowed"""
if self.can_generate():
self.generations.append(datetime.now())
return True, self.limit - len(self.generations)
return False, 0
def time_until_next_available(self):
"""Calculate when next slot opens"""
if len(self.generations) == 0:
return timedelta(0)
oldest = self.generations[0]
expiry = oldest + self.window
wait = expiry - datetime.now()
return wait if wait > timedelta(0) else timedelta(0)
Edge cases in the quota system create occasional user confusion. Server synchronization delays can cause temporary discrepancies where different ChatGPT sessions report slightly different remaining quotas. These inconsistencies typically resolve within 30 seconds as the distributed system achieves consensus. Additionally, rapid successive generations might trigger anti-abuse mechanisms that temporarily block requests even with available quota, enforcing a 30-60 second cooldown period.
The continuous refresh nature of the rolling window creates unique usage patterns. A user who generates 50 images between 2:00-2:30 PM will see gradual quota recovery starting at 5:00 PM, with approximately one slot becoming available every 3.6 minutes (180 minutes ÷ 50 images). This granular recovery encourages sustained usage throughout the day rather than burst generation followed by long waiting periods.
Peak Hour Image Generation Limits and Throttling
Dynamic throttling during peak hours represents one of the most frustrating aspects of ChatGPT Plus image generation limits. Between 2:00 PM and 6:00 PM EST, OpenAI implements elastic quota reduction based on real-time GPU cluster utilization. This throttling doesn’t follow a fixed schedule but responds to aggregate system load, making it unpredictable for individual users who suddenly find their 50-image quota reduced to 40-45 images without warning.
The technical implementation of peak throttling operates through a sophisticated load balancing system. OpenAI’s infrastructure monitors GPU utilization across multiple data centers, implementing graduated restrictions as usage approaches capacity thresholds. When cluster utilization exceeds 75%, the system begins reducing individual quotas by 10%. At 85% utilization, reductions increase to 20%, explaining why users might see their effective limit drop to 40 images during extreme peak periods.
Geographical distribution of peak hours adds complexity to throttling patterns. While 2-6 PM EST represents the primary congestion window for North American users, European users experience secondary peaks during their evening hours (7-10 PM GMT), and Asian users face restrictions during their afternoon periods. This global usage pattern creates rolling waves of high demand that the throttling system must continuously adapt to.
Soft failures during peak periods manifest as a different user experience than hard quota limits. Instead of receiving an immediate “limit reached” error, requests enter a queuing system that might delay generation by 30-180 seconds. These delays don’t guarantee eventual processing – if system load remains high, queued requests timeout and return errors while still consuming quota slots. This behavior particularly impacts users attempting to generate time-sensitive content during peak hours.
Hidden Costs That Drain Your Image Generation Limit
Failed generations represent the most significant hidden drain on image generation quotas. Every request that triggers a content policy violation, encounters a technical error, or times out during processing counts against your 50-image limit despite producing no usable output. Common failure scenarios include false-positive content flags on benign requests, ambiguous prompts requiring clarification, and system errors during high-load periods. Users report failure rates between 5-15%, effectively reducing their 50-image quota to 42-47 usable generations.
The variation tax imposes another subtle quota penalty that catches users unprepared. Requesting minor modifications to existing images – adjusting colors, changing small details, or exploring alternatives – consumes full generation slots rather than fractional quotas. This design reflects technical reality: even minor visual changes require complete regeneration through the neural network. Users accustomed to traditional image editing software’s incremental modifications find this all-or-nothing approach particularly wasteful when perfecting specific visual elements.
Multi-panel and composite image requests multiply quota consumption in ways users rarely anticipate. A request for a “four-panel comic strip” doesn’t generate a single image divided into panels; instead, it triggers four separate generations that together consume 8% of your three-hour quota. Similarly, requests for “multiple views” or “variations showing different times of day” each count as individual generations. This multiplication effect severely impacts creators working on visual narratives or comprehensive design explorations. For broader context on AI image generation best practices across platforms, understanding these limitations helps set realistic expectations.
# Calculate real quota impact of different request types
class QuotaImpactCalculator:
def __init__(self, base_quota=50):
self.base_quota = base_quota
self.failure_rate = 0.10 # 10% average failure rate
def calculate_effective_quota(self, request_patterns):
"""Calculate how many usable images you actually get"""
total_consumed = 0
successful_outputs = 0
for pattern in request_patterns:
if pattern['type'] == 'single':
attempts = pattern['count']
successful = int(attempts * (1 - self.failure_rate))
total_consumed += attempts
successful_outputs += successful
elif pattern['type'] == 'variation':
# Each variation is a full generation
base_attempts = pattern['count']
variations = pattern['variations_per_image']
total_attempts = base_attempts * variations
successful = int(total_attempts * (1 - self.failure_rate))
total_consumed += total_attempts
successful_outputs += successful
elif pattern['type'] == 'multi_panel':
# Each panel is separate generation
sets = pattern['count']
panels = pattern['panels_per_set']
total_attempts = sets * panels
successful = int(total_attempts * (1 - self.failure_rate))
total_consumed += total_attempts
successful_outputs += successful
efficiency = (successful_outputs / total_consumed) * 100 if total_consumed > 0 else 0
return {
'quota_consumed': total_consumed,
'usable_images': successful_outputs,
'efficiency_percentage': round(efficiency, 1),
'wasted_generations': total_consumed - successful_outputs
}
# Example usage scenario
calculator = QuotaImpactCalculator()
typical_usage = [
{'type': 'single', 'count': 20},
{'type': 'variation', 'count': 5, 'variations_per_image': 3},
{'type': 'multi_panel', 'count': 3, 'panels_per_set': 4}
]
impact = calculator.calculate_effective_quota(typical_usage)
print(f"Quota consumed: {impact['quota_consumed']}/50")
print(f"Usable images: {impact['usable_images']}")
print(f"Efficiency: {impact['efficiency_percentage']}%")
Style consistency challenges create the most frustrating quota drain for professional users. When generating image series requiring visual coherence – such as storyboards, character designs in different poses, or branded content variations – the model’s inability to maintain consistent style across generations forces excessive regeneration. Users report needing 5-10 attempts to achieve acceptable consistency for a 5-image series, transforming their 50-image quota into merely 5-10 cohesive sets. This limitation particularly impacts commercial users who require style guides and brand consistency.
Track Your ChatGPT Plus Image Generation Limit
Manual tracking of image generation quotas becomes essential given ChatGPT’s lack of native quota visibility. The most basic approach involves maintaining a spreadsheet with timestamps for each generation, calculating rolling 3-hour windows to estimate remaining capacity. However, this method quickly becomes cumbersome during active creative sessions and prone to errors when tracking fails to account for failed generations or multi-panel requests that consume multiple slots.
Browser-based tracking solutions offer more sophisticated monitoring without requiring external tools. By injecting JavaScript into the ChatGPT interface, users can create real-time quota displays that automatically log generations and calculate remaining capacity. These client-side solutions intercept image generation requests, maintain local storage of timestamps, and display countdown timers showing when additional quota slots become available.
// Browser console quota tracker for ChatGPT Plus
class ChatGPTImageQuotaMonitor {
constructor() {
this.storageKey = 'chatgpt_image_quota';
this.quotaLimit = 50;
this.windowHours = 3;
this.initializeMonitoring();
}
initializeMonitoring() {
// Override fetch to intercept image generation requests
const originalFetch = window.fetch;
window.fetch = async (...args) => {
const response = await originalFetch(...args);
// Detect image generation endpoints
if (args[0].includes('/images/generations') ||
args[0].includes('dalle') ||
(args[1]?.body && args[1].body.includes('image'))) {
this.recordGeneration();
}
return response;
};
// Display quota status
this.createQuotaDisplay();
setInterval(() => this.updateDisplay(), 1000);
}
recordGeneration() {
const generations = this.getGenerations();
generations.push(new Date().toISOString());
localStorage.setItem(this.storageKey, JSON.stringify(generations));
this.updateDisplay();
}
getGenerations() {
const stored = localStorage.getItem(this.storageKey);
return stored ? JSON.parse(stored) : [];
}
calculateRemaining() {
const now = new Date();
const cutoff = new Date(now - this.windowHours * 60 * 60 * 1000);
const generations = this.getGenerations()
.map(ts => new Date(ts))
.filter(date => date > cutoff);
return {
used: generations.length,
remaining: Math.max(0, this.quotaLimit - generations.length),
oldest: generations[0] || null,
nextSlot: generations[0] ?
new Date(generations[0].getTime() + this.windowHours * 60 * 60 * 1000) :
null
};
}
createQuotaDisplay() {
const display = document.createElement('div');
display.id = 'quota-monitor';
display.style.cssText = `
position: fixed;
top: 20px;
right: 20px;
background: rgba(0, 0, 0, 0.8);
color: white;
padding: 15px;
border-radius: 10px;
font-family: monospace;
z-index: 10000;
min-width: 250px;
`;
document.body.appendChild(display);
}
updateDisplay() {
const status = this.calculateRemaining();
const display = document.getElementById('quota-monitor');
if (!display) return;
let html = `Image Quota Status
`;
html += `Used: ${status.used}/50`;
html += `Remaining: ${status.remaining}`;
if (status.nextSlot) {
const timeUntil = status.nextSlot - new Date();
const minutes = Math.ceil(timeUntil / 60000);
html += `Next slot in: ${minutes} min`;
}
display.innerHTML = html;
}
}
// Initialize tracker
const quotaMonitor = new ChatGPTImageQuotaMonitor();
Predictive quota modeling takes tracking beyond simple counting to forecast availability windows. By analyzing historical generation patterns, these advanced systems predict when you’ll hit limits and suggest optimal generation timing. Machine learning models can identify your personal usage patterns – burst generation during creative sessions versus steady usage throughout the day – and provide personalized recommendations for quota management. This predictive capability proves invaluable for professionals planning time-sensitive projects.
Optimize Prompts to Maximize Image Generation Limits
Prompt engineering represents the most effective strategy for maximizing your 50-image generation limit without additional costs. Well-crafted prompts that clearly specify style, composition, lighting, and mood reduce regeneration needs by 60-70%, effectively transforming your 50-image quota into 125-175 successful outputs. The key lies in understanding how DALL-E 3 and GPT-4o interpret visual descriptions and preemptively addressing common failure points.
Systematic prompt construction follows a hierarchical structure that prioritizes clarity and specificity. Begin with the core subject and action, followed by environmental context, then artistic style, technical parameters, and finally negative prompts to exclude unwanted elements. This structured approach reduces ambiguity that often leads to unexpected results requiring regeneration. Including reference styles, specific color palettes, and compositional guidelines in initial prompts eliminates iterative refinement cycles. For advanced techniques, our prompt engineering guide provides comprehensive strategies applicable to all AI image generation.
# Advanced prompt optimization framework
class PromptOptimizer:
def __init__(self):
self.style_library = {
'photorealistic': {
'base': 'photorealistic, high detail, professional photography',
'lighting': 'natural lighting, golden hour',
'camera': 'shot with 85mm lens, shallow depth of field'
},
'illustration': {
'base': 'digital illustration, clean vector art',
'lighting': 'flat lighting, vibrant colors',
'style': 'modern minimalist design'
},
'artistic': {
'base': 'artistic interpretation, painterly style',
'lighting': 'dramatic lighting, chiaroscuro',
'texture': 'visible brushstrokes, canvas texture'
}
}
def optimize_prompt(self, user_input, style='photorealistic',
include_negative=True, consistency_ref=None):
"""Generate optimized prompt with high first-attempt success rate"""
components = []
# Core subject (user input)
components.append(user_input)
# Style parameters
style_params = self.style_library.get(style, self.style_library['photorealistic'])
components.extend([
style_params['base'],
style_params['lighting'],
style_params.get('camera', style_params.get('style', ''))
])
# Consistency reference for series
if consistency_ref:
components.append(f"maintaining exact style of {consistency_ref}")
# Technical quality markers
components.extend([
"high quality",
"detailed",
"sharp focus",
"professional"
])
# Negative prompts to prevent common issues
if include_negative:
components.append(
"avoiding: blurry, distorted, disfigured, poor quality, "
"bad anatomy, wrong proportions, extra limbs, cloned face, "
"mutated, ugly, grain, low-res, deformed, text, watermark"
)
return ", ".join(filter(None, components))
def generate_series_prompts(self, base_concept, variations, style='photorealistic'):
"""Generate consistent prompts for image series"""
prompts = []
# First image establishes style
first_prompt = self.optimize_prompt(
f"{base_concept} - {variations[0]}",
style=style
)
prompts.append(first_prompt)
# Subsequent images reference the first
for i, variation in enumerate(variations[1:], 1):
prompt = self.optimize_prompt(
f"{base_concept} - {variation}",
style=style,
consistency_ref=f"image 1 in this series"
)
prompts.append(prompt)
return prompts
# Example usage
optimizer = PromptOptimizer()
# Single optimized image
prompt = optimizer.optimize_prompt(
"a coffee shop interior with plants",
style='photorealistic'
)
print("Optimized prompt:", prompt)
# Consistent series
series_variations = [
"morning sunlight",
"afternoon busy period",
"evening ambient lighting",
"night with neon signs"
]
series_prompts = optimizer.generate_series_prompts(
"modern coffee shop interior",
series_variations,
style='photorealistic'
)
Parameter standardization across image series dramatically improves consistency while reducing regeneration waste. By maintaining fixed technical parameters – resolution, artistic style, color palette, and compositional rules – throughout a series, you minimize the variable factors that lead to visual inconsistency. This approach requires upfront planning but pays dividends in reduced quota consumption. Professional users report achieving 85-90% first-attempt success rates with properly standardized parameters.
Negative prompting techniques prevent common failure modes that waste generation slots. By explicitly excluding problematic elements like text overlays, watermarks, distorted anatomy, and compression artifacts, you guide the model away from outputs that would require regeneration. Advanced users maintain libraries of negative prompt templates tailored to different image types, ensuring consistent quality standards across all generations while minimizing quota waste from preventable failures.
ChatGPT Plus vs Team Image Generation Limits
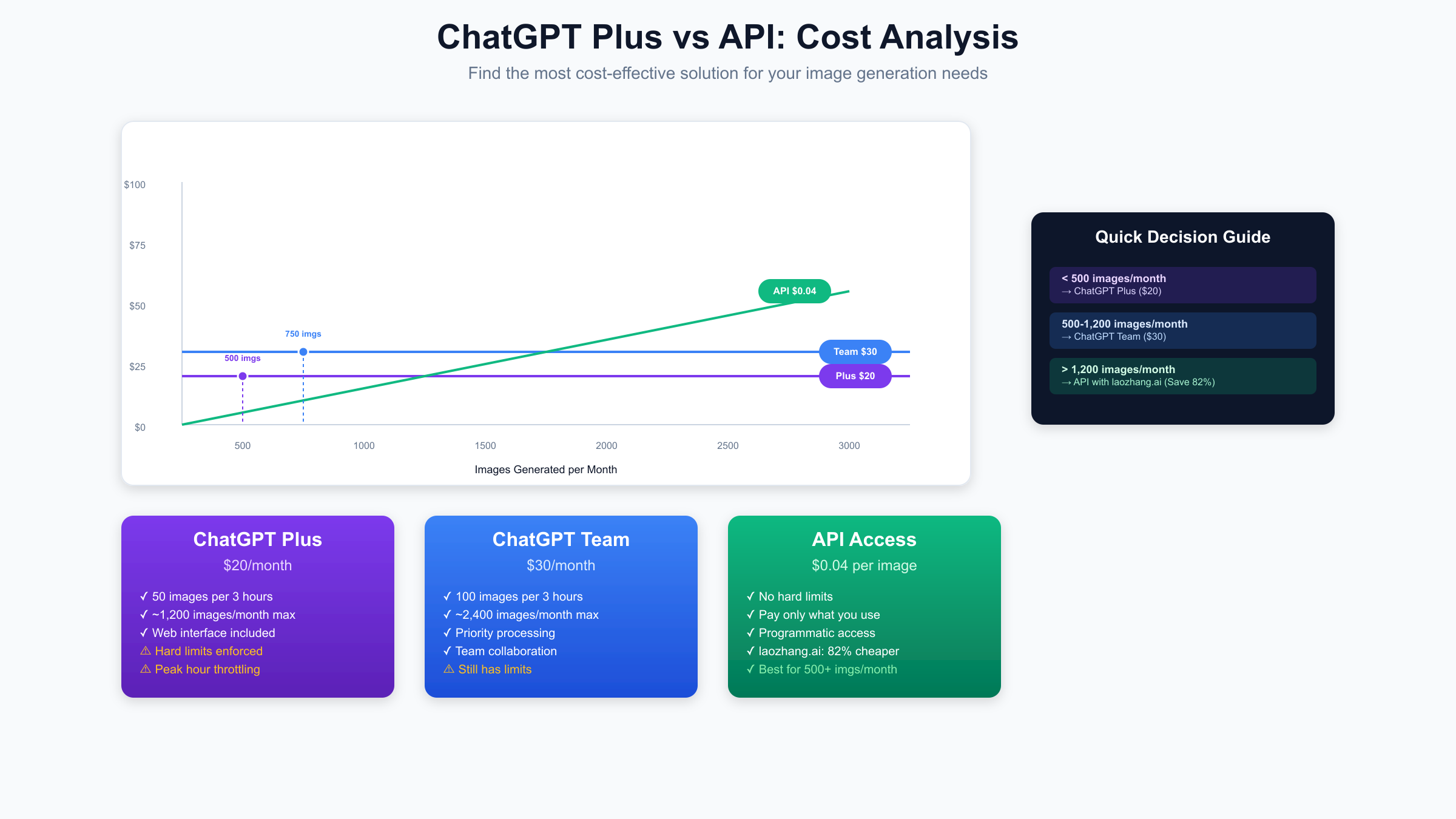
The comparison between ChatGPT Plus and Team image generation limits reveals a straightforward value proposition with hidden complexities. Plus subscribers receive 50 images per 3-hour window for $20 monthly, while Team subscribers enjoy exactly double that quota – 100 images per window – for $30 per user. This 50% price increase for 100% more capacity appears compelling, but the real value depends entirely on usage patterns and peak hour accessibility.
Team subscriptions offer advantages beyond raw quota increases. Priority processing during peak hours means Team users rarely experience the 40-45 image throttling that plagues Plus subscribers. The infrastructure allocation provides dedicated GPU resources that maintain consistent generation speeds even during high-demand periods. Additionally, Team accounts gain access to centralized administration, enabling quota pooling strategies where team members can effectively share generation capacity.
Cost-benefit analysis for the Team upgrade requires careful usage evaluation. Users consistently hitting Plus limits during peak creative sessions benefit most from the upgrade. The doubled quota translates to approximately 2,400 potential images monthly (100 images × 8 three-hour periods × 30 days), though real-world usage rarely approaches theoretical maximums. For comparison, achieving 2,400 images through API access would cost $96 at standard rates, making Team’s $30 price point attractive for high-volume users.

The decision matrix for Team upgrades considers multiple factors beyond simple quota math. Professional creators working on time-sensitive projects value the peak hour priority access more than the doubled quota. Small agencies benefit from administrative controls enabling flexible resource allocation across team members. However, solo users with predictable generation patterns often find Plus sufficient by implementing optimization strategies rather than paying for additional capacity they won’t fully utilize.
API Alternative to ChatGPT Plus Image Generation Limits
Direct API access eliminates hard quotas in favor of pay-per-use pricing, fundamentally changing the economics of image generation. At $0.04 per standard DALL-E 3 image, API users pay only for successful generations without worrying about rolling windows, peak hour throttling, or wasted quota from failures. This model particularly benefits users with variable demand – generating hundreds of images some days while remaining idle others.
Implementation requirements for API integration present a higher technical barrier than ChatGPT’s web interface. Developers must handle authentication, request formatting, error handling, and response processing. The absence of ChatGPT’s conversational refinement means prompts must be perfectly crafted upfront, as there’s no interactive adjustment process. Additionally, content filtering and safety systems operate differently, requiring developers to implement their own moderation layers. Understanding the full cost implications requires reviewing our detailed ChatGPT API pricing analysis.
# API integration for image generation
import requests
import time
from typing import Optional, Dict, List
class ImageGenerationAPI:
def __init__(self, api_key: str, use_laozhang: bool = False):
self.api_key = api_key
if use_laozhang:
self.base_url = "https://api.laozhang.ai/v1"
self.cost_per_image = 0.0072 # 82% discount
else:
self.base_url = "https://api.openai.com/v1"
self.cost_per_image = 0.04
self.total_cost = 0
self.generation_count = 0
def generate_image(self, prompt: str, size: str = "1024x1024",
quality: str = "standard", retries: int = 3) -> Optional[Dict]:
"""Generate image with automatic retry logic"""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
payload = {
"model": "dall-e-3",
"prompt": prompt,
"size": size,
"quality": quality,
"n": 1
}
for attempt in range(retries):
try:
response = requests.post(
f"{self.base_url}/images/generations",
headers=headers,
json=payload,
timeout=60
)
if response.status_code == 200:
self.generation_count += 1
self.total_cost += self.cost_per_image
return response.json()
elif response.status_code == 429: # Rate limit
wait_time = int(response.headers.get('Retry-After', 60))
print(f"Rate limited. Waiting {wait_time} seconds...")
time.sleep(wait_time)
else:
print(f"Error {response.status_code}: {response.text}")
except Exception as e:
print(f"Attempt {attempt + 1} failed: {str(e)}")
time.sleep(2 ** attempt) # Exponential backoff
return None
def batch_generate(self, prompts: List[str], **kwargs) -> List[Optional[Dict]]:
"""Generate multiple images with progress tracking"""
results = []
for i, prompt in enumerate(prompts):
print(f"Generating {i+1}/{len(prompts)}...")
result = self.generate_image(prompt, **kwargs)
results.append(result)
# Respect rate limits
if (i + 1) % 5 == 0:
time.sleep(1) # Brief pause every 5 images
return results
def get_usage_stats(self) -> Dict:
"""Return usage statistics and costs"""
return {
'total_generations': self.generation_count,
'total_cost': round(self.total_cost, 2),
'average_cost': round(self.total_cost / max(self.generation_count, 1), 4),
'vs_plus_monthly': round(self.total_cost / 20, 2) # Compared to $20 Plus
}
# Usage comparison
api = ImageGenerationAPI(api_key="your-key", use_laozhang=True)
# Generate images without quota worries
prompts = [
"futuristic city at sunset with flying cars",
"serene mountain lake with perfect reflection",
"abstract geometric pattern in vibrant colors"
]
results = api.batch_generate(prompts)
stats = api.get_usage_stats()
print(f"Generated {stats['total_generations']} images")
print(f"Total cost: ${stats['total_cost']}")
print(f"Equivalent to {stats['vs_plus_monthly']} months of ChatGPT Plus")
Hidden costs of API implementation extend beyond the per-image pricing. Development time, maintenance overhead, and infrastructure requirements add significant expense for smaller operations. Error handling becomes critical – failed generations due to content policy or technical issues still require robust retry logic. The lack of built-in conversation context means implementing your own prompt refinement system, adding complexity compared to ChatGPT’s intuitive interface.
The laozhang.ai API service presents a compelling middle ground for cost-conscious users. Offering the same DALL-E 3 access at an 82% discount ($0.0072 per image), it dramatically shifts the economics of high-volume generation. Users can generate 2,777 images for the same $20 monthly Plus subscription cost. The service includes enterprise features like bulk generation endpoints, automatic retry logic, and regional CDN distribution for faster response times. This pricing model particularly benefits international users facing payment restrictions with OpenAI’s limited payment options.
Common Image Generation Limit Problems and Solutions
The dreaded “You’ve reached your image generation limit” error typically appears at the worst possible moment – mid-project when creative momentum peaks. This generic message provides no information about when generation will resume or how many images triggered the limit. Users must manually calculate their rolling 3-hour window to estimate recovery time, a frustrating experience when deadlines loom. The solution requires understanding that limits don’t reset instantly but recover gradually as old generations age out of the 180-minute window.
Recovery strategies for limit-blocked users focus on maximizing the gradual quota restoration. Rather than waiting for full quota recovery, monitor when individual slots become available and use them strategically for highest-priority generations. Implement a queueing system that automatically attempts generation when quota allows, preventing wasted availability during off-hours. Some users schedule generation sessions around their typical quota recovery patterns, aligning creative work with maximum availability windows.
Multi-account strategies tempt users seeking to circumvent limits, but this approach carries significant risks. OpenAI’s detection systems identify shared payment methods, IP addresses, browser fingerprints, and usage patterns across accounts. Violations result in immediate suspension of all associated accounts, losing access to ChatGPT entirely. The terms of service explicitly prohibit creating multiple accounts to bypass limits, making this a dangerous strategy that risks permanent bans rather than temporary inconvenience.
Legitimate workarounds within terms of service focus on optimization rather than circumvention. Collaborative approaches where team members pool resources through official Team subscriptions provide legitimate quota expansion. Alternating between ChatGPT Plus for conversational refinement and API access for bulk generation maximizes both interfaces’ strengths. Some users maintain Plus subscriptions for development and testing, switching to API deployment for production use. These hybrid approaches respect service terms while meeting high-volume generation needs.
Future of ChatGPT Plus Image Generation Limits
The trajectory of image generation limits reflects broader competitive dynamics in the AI landscape. Anthropic’s Claude offers integrated image understanding without generation caps, while Google’s Gemini provides generous multimodal quotas within their subscription tiers. This competitive pressure, combined with infrastructure improvements and user demand, suggests OpenAI will likely announce significant quota increases by Q4 2025. Market analysis indicates a potential doubling of Plus limits to 100 images per 3 hours, matching current Team allocations.
Technical evolution toward fully integrated multimodal models will fundamentally alter quota structures. As GPT-4o’s native generation capabilities mature, the distinction between text and image tokens may dissolve into unified multimodal quotas. This shift would enable more flexible resource allocation where users balance text and image generation based on their specific needs rather than facing separate hard limits. Early experiments suggest this unified approach could effectively triple available image generation capacity through more efficient resource utilization. For the latest technical specifications and updates, consult OpenAI’s official DALL-E documentation.
Tiered subscription models represent the most likely near-term evolution. Rather than maintaining binary Plus/Pro distinctions, OpenAI may introduce bronze ($20), silver ($40), and gold ($80) tiers with proportionally scaled quotas. This structure would retain accessible entry pricing while capturing revenue from power users currently forced into expensive API access. Such tiering aligns with competitor strategies while providing clearer upgrade paths based on actual usage needs rather than forcing users to jump from $20 to $200 monthly subscriptions.