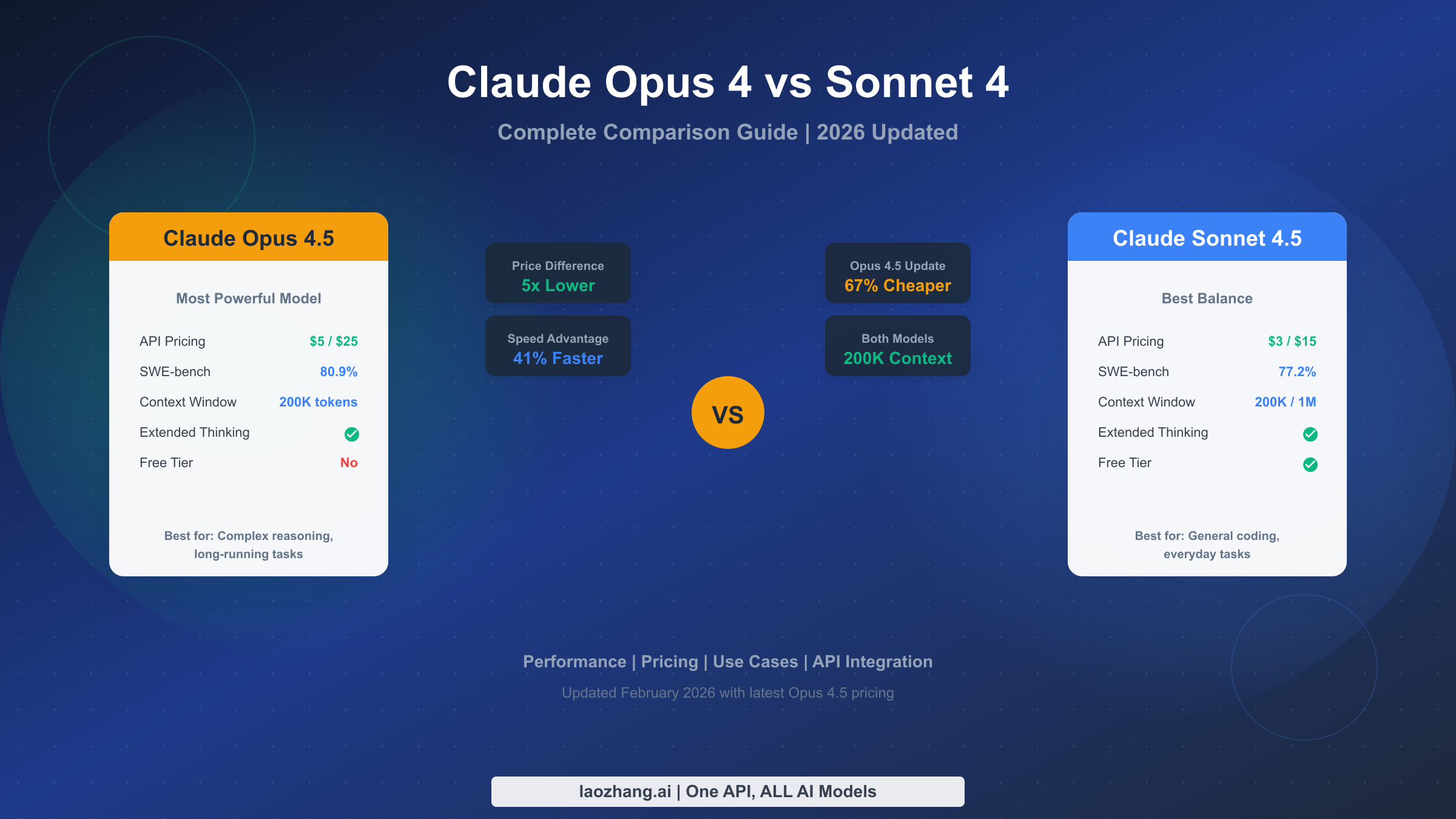
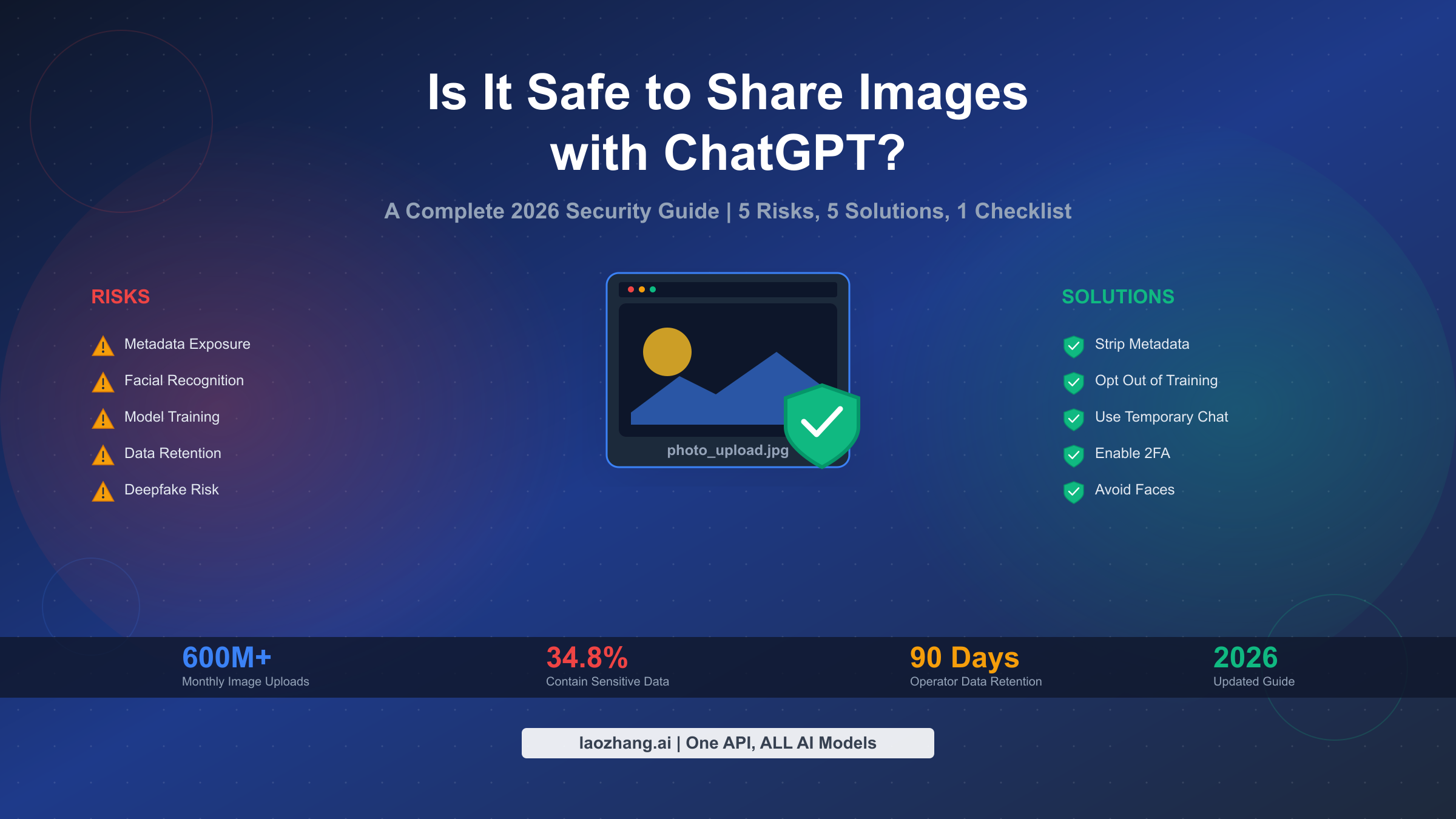
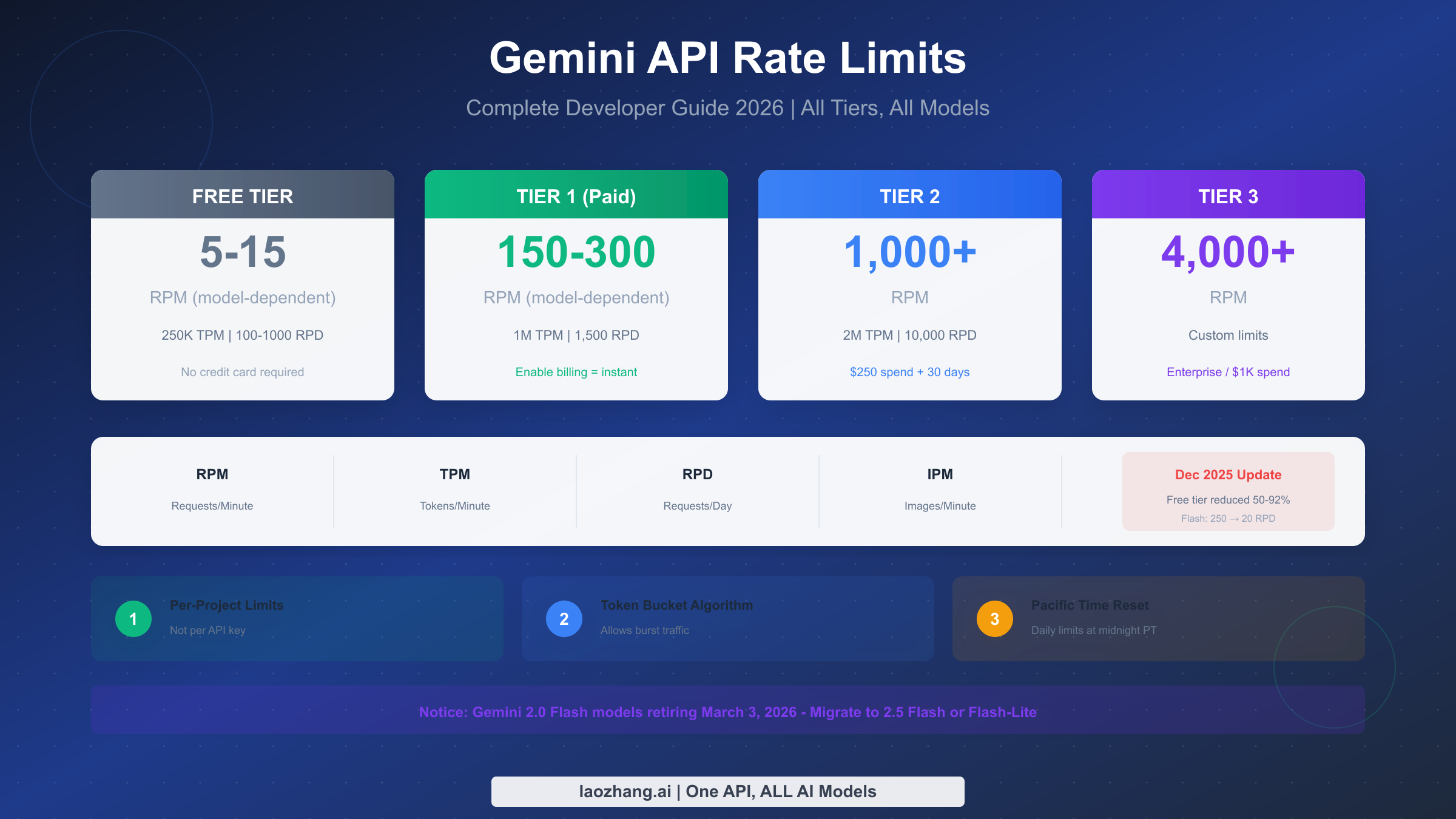
AI Video Generation
Read Now
Seedance 2.0 vs Grok Imagine Video: Pick Control or Access?
Start with Grok Imagine Video if you need the easier public API and simpler pricing today. Start with Seedance 2.0 if you need a richer multimodal video workflow with more image, video, and audio conditioning inside one official surface.














![Nano Banana 2 API Proxy Comparison: Price, Stability & True Cost Analysis [2026]](/posts/en/nano-banana-2-api-proxy-comparison/img/cover.png)


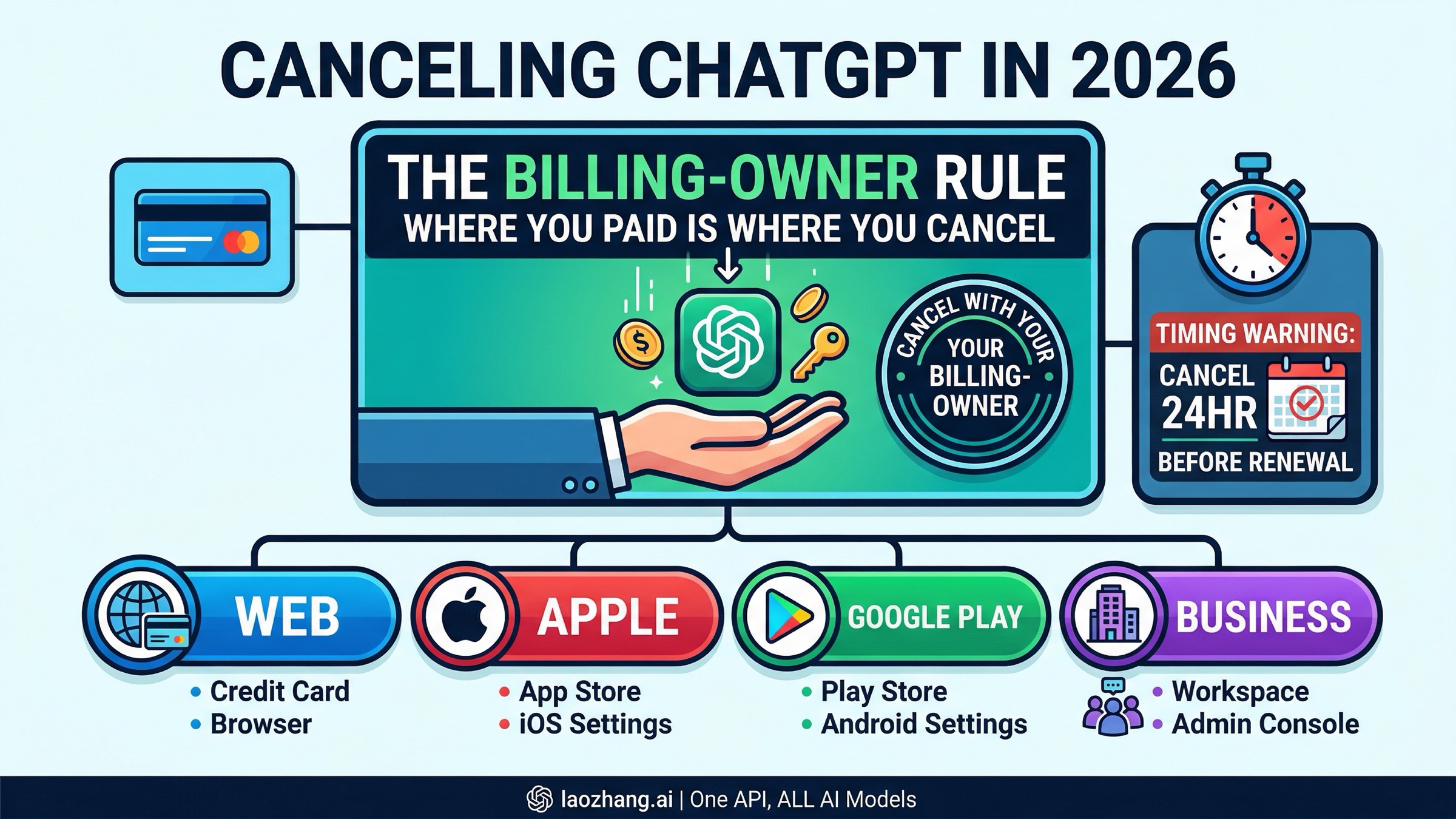

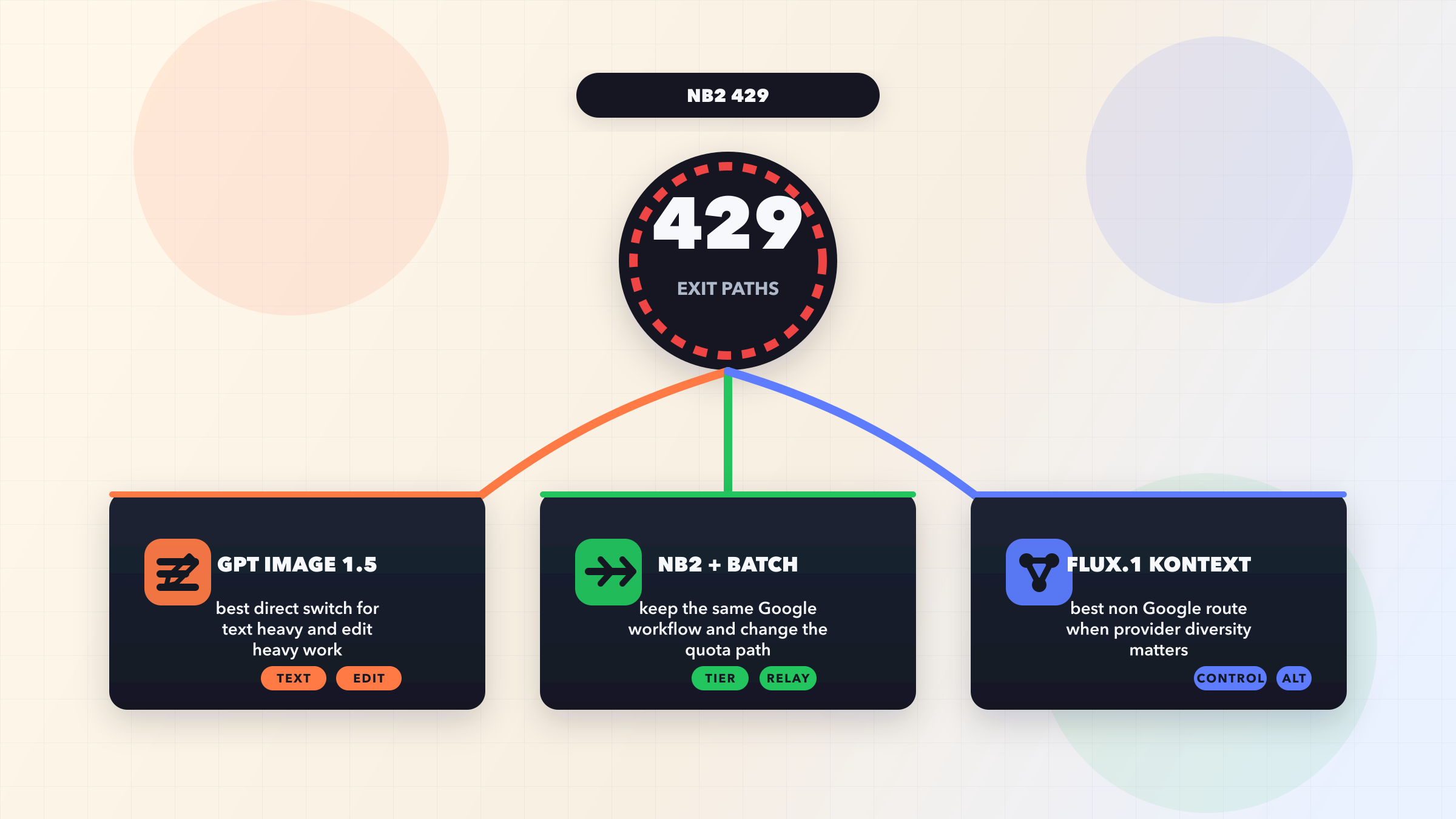













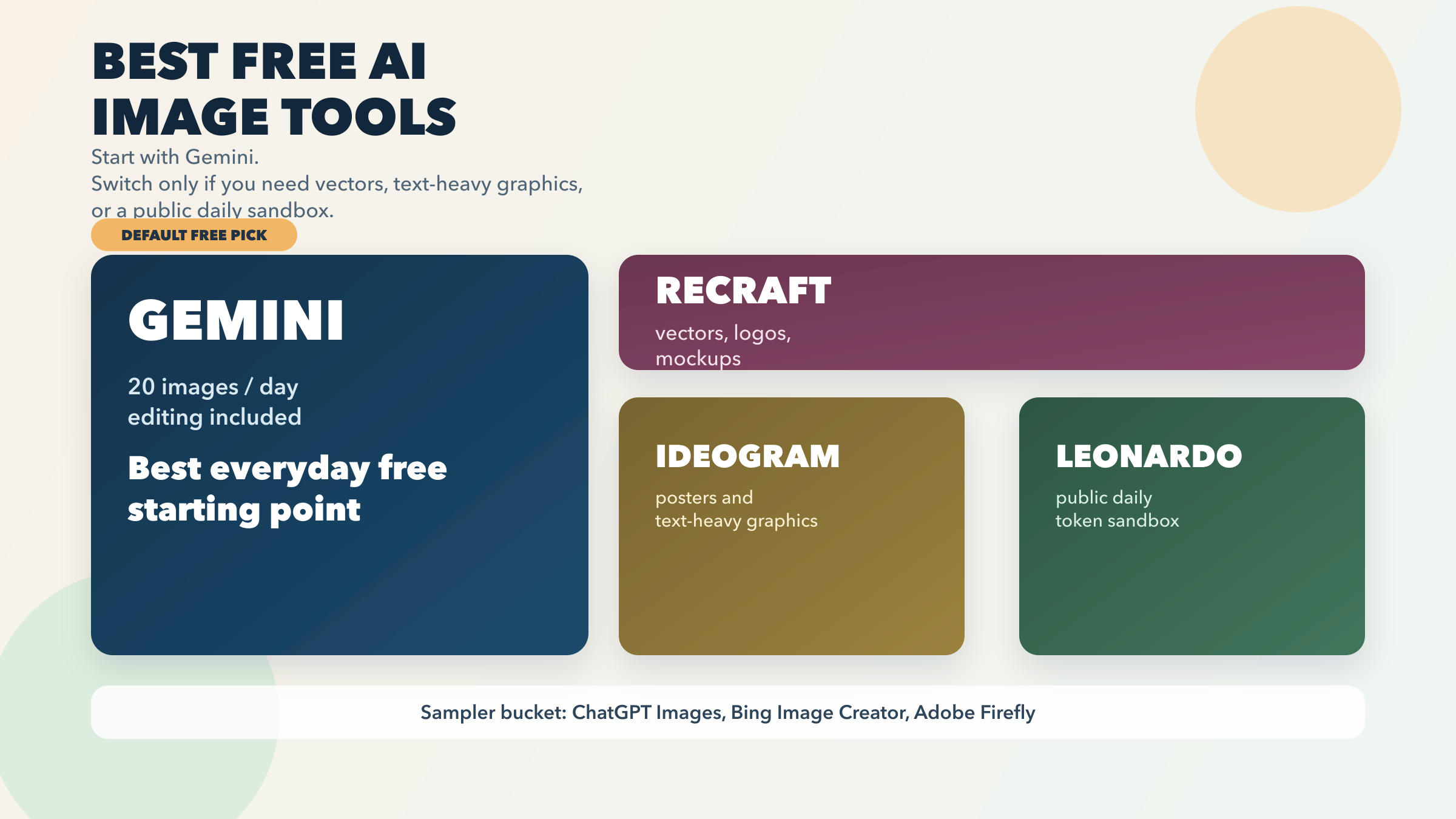

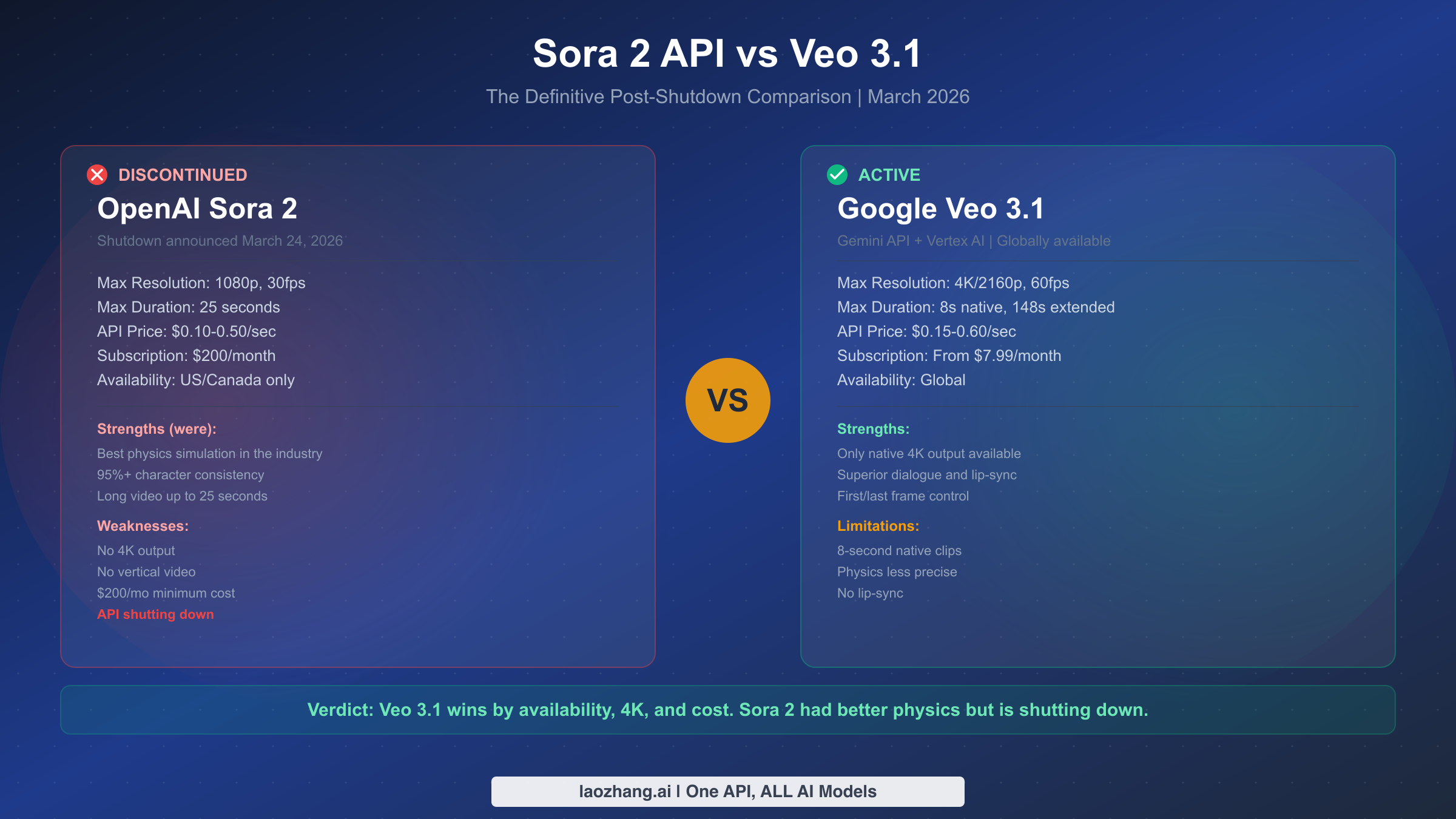

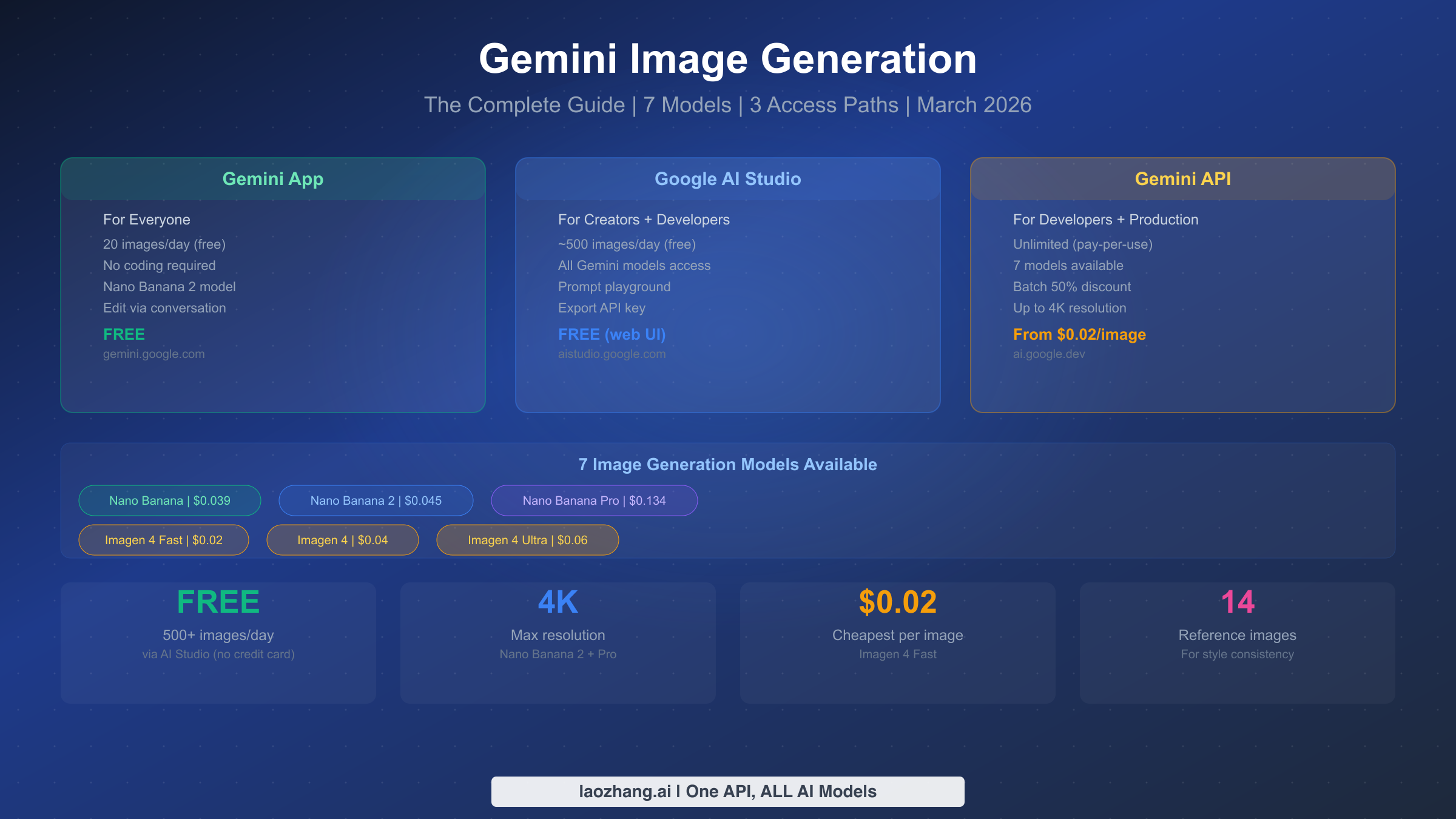

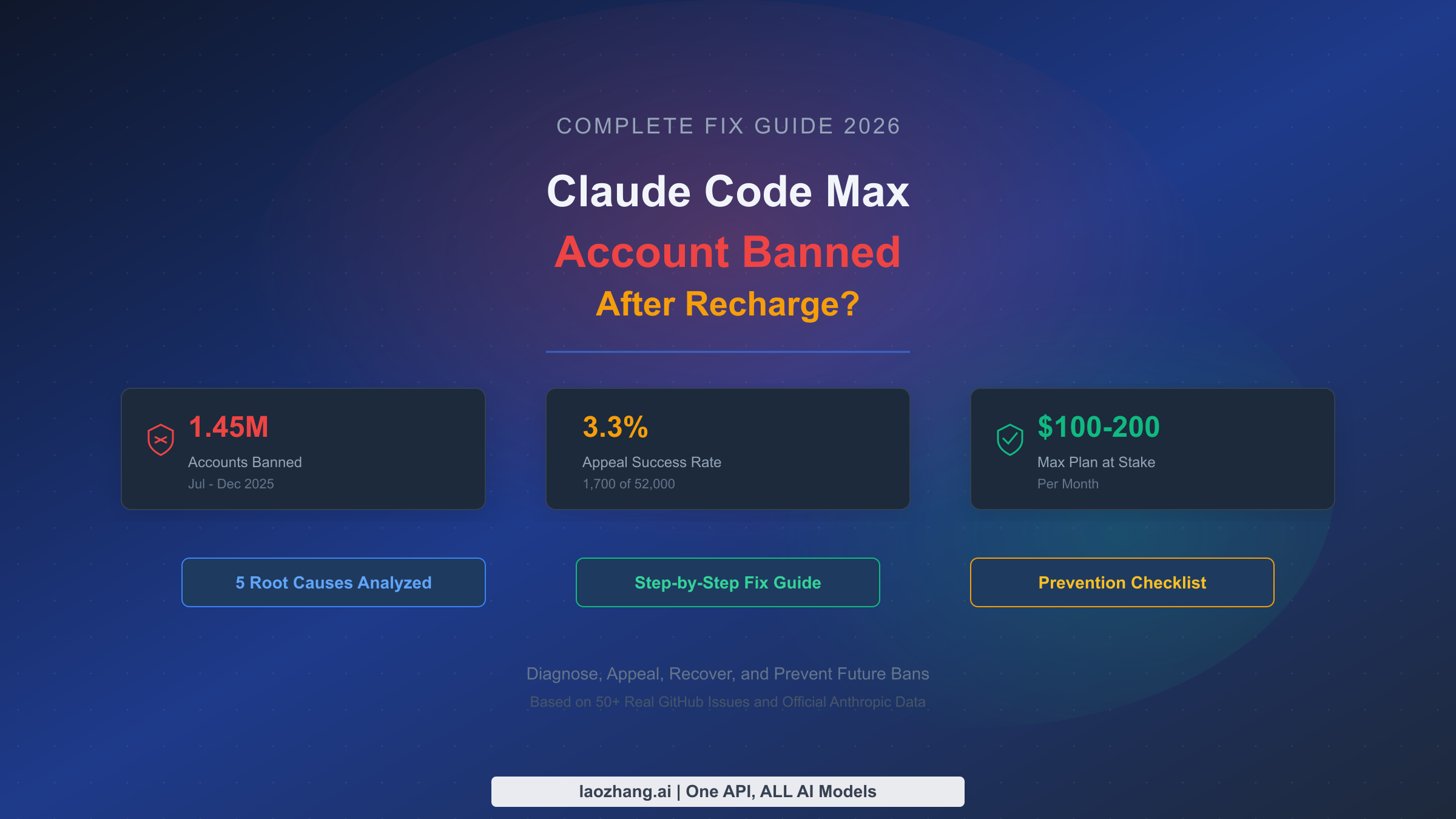





![OpenClaw Doctor and Gateway Restart: Complete Troubleshooting Guide [2026]](/posts/en/openclaw-doctor-gateway-restart/img/cover.png)










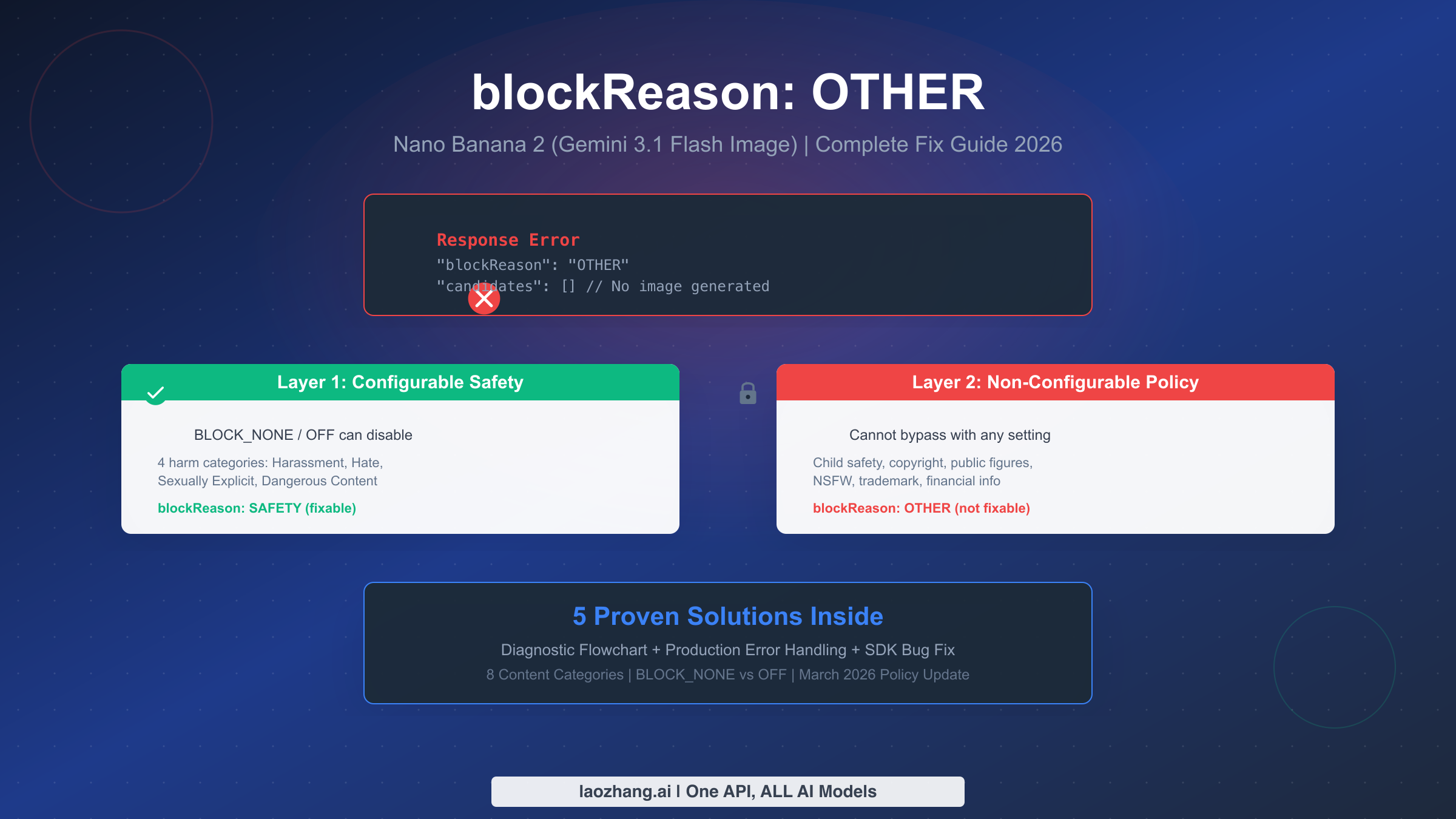
![Nano Banana 2 API Pricing Explained: Official vs Proxy Cost Comparison [2026]](/posts/en/nano-banana-2-api-pricing-guide/img/cover.png)

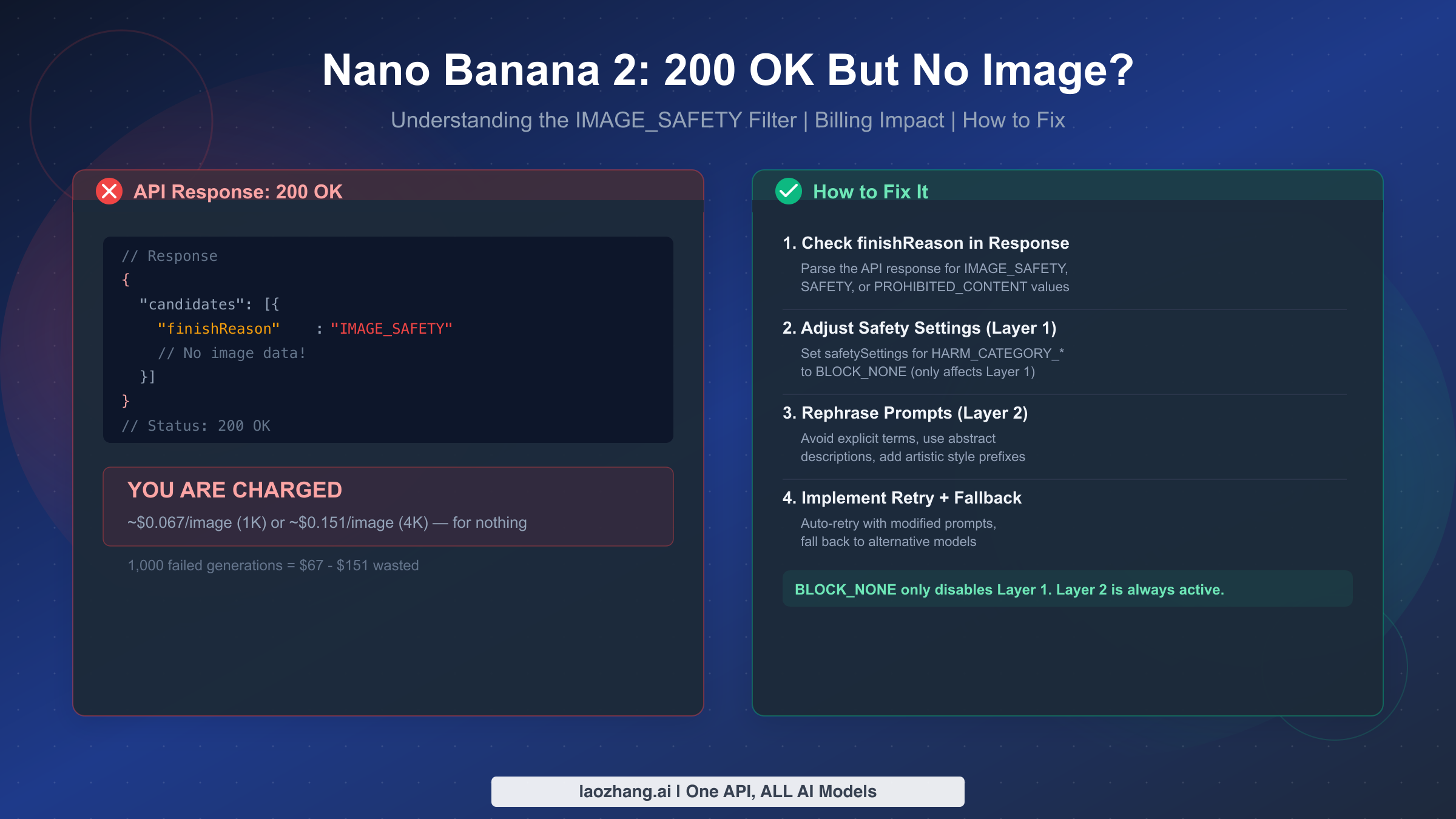



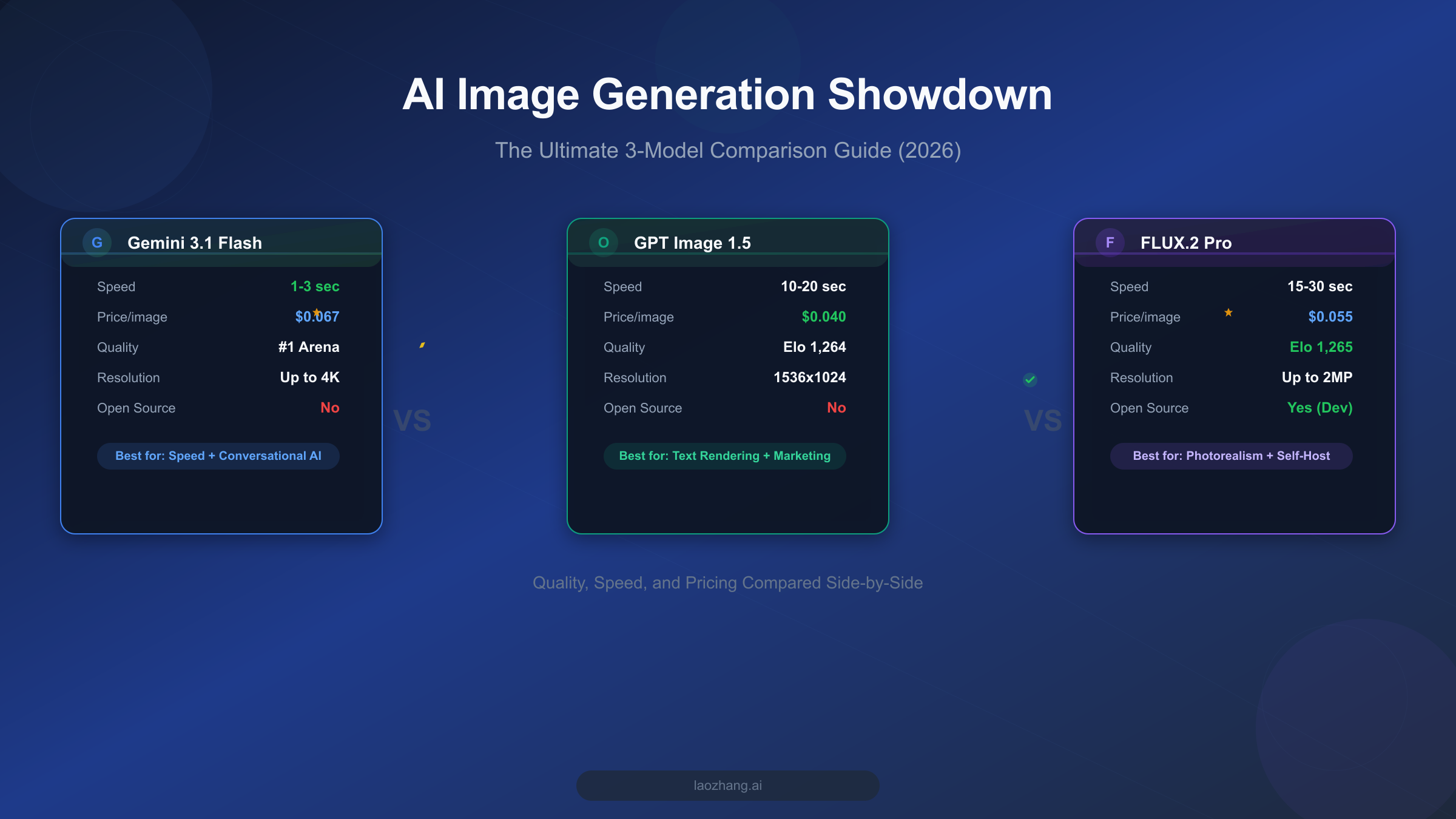

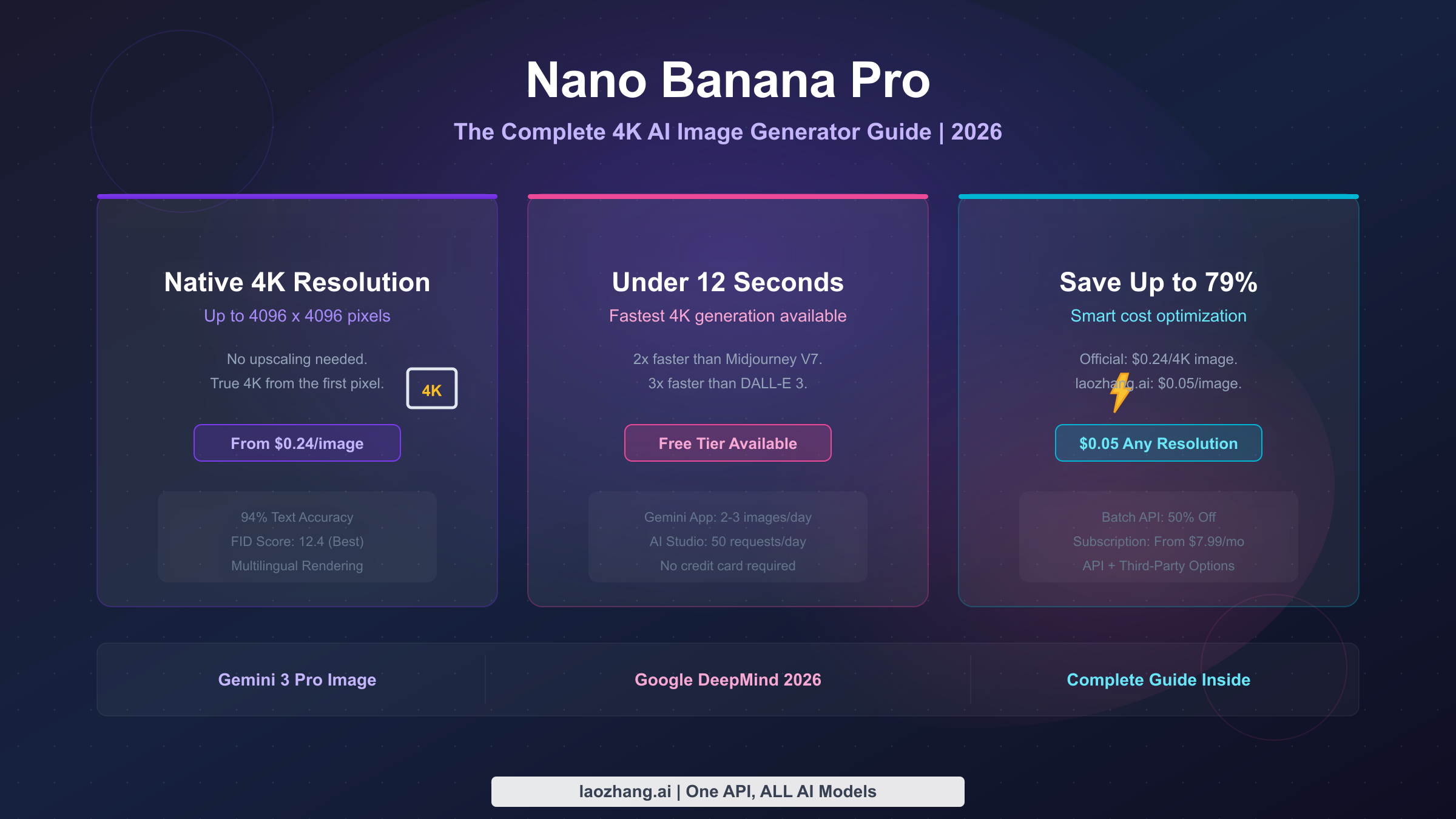
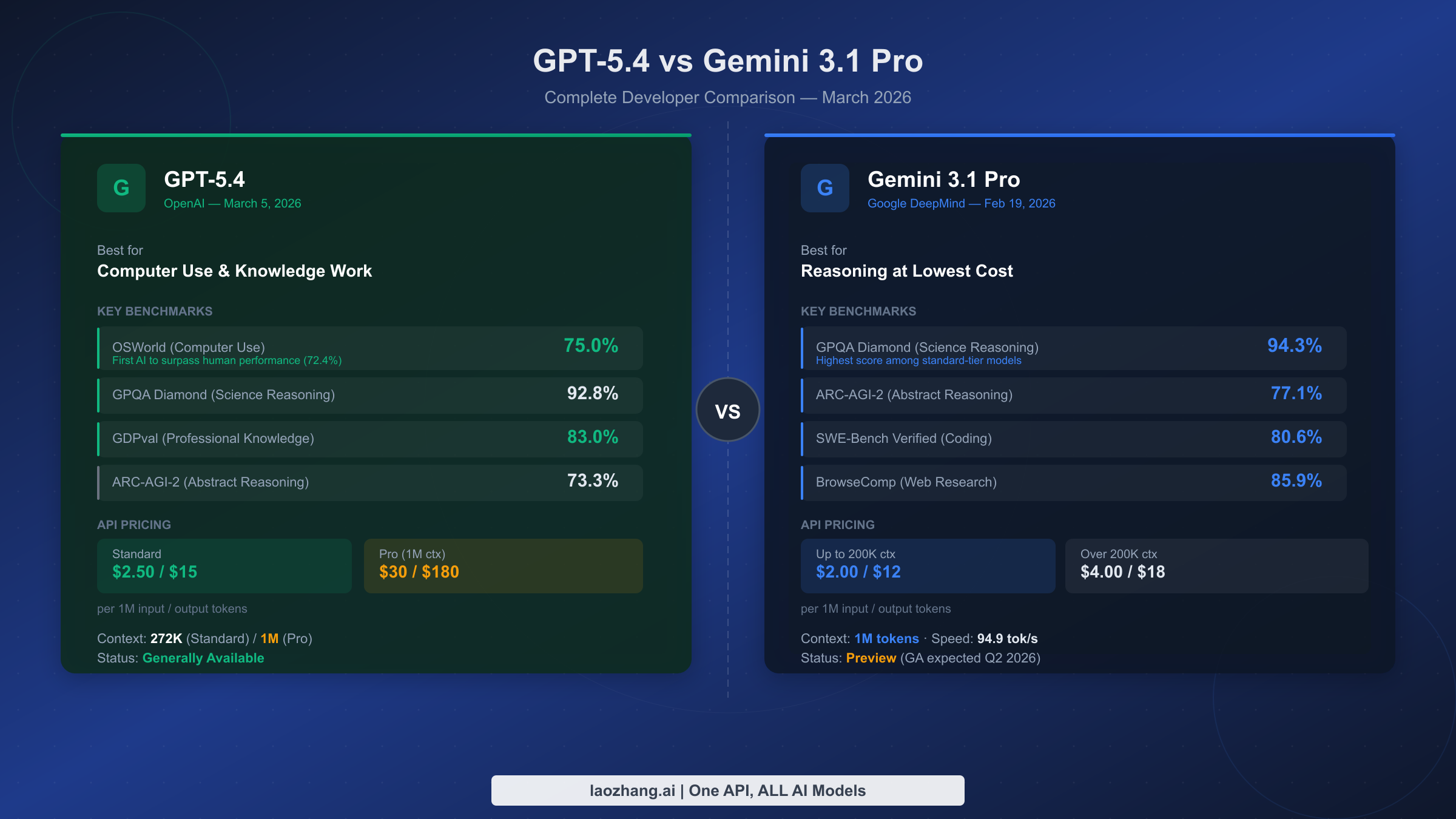
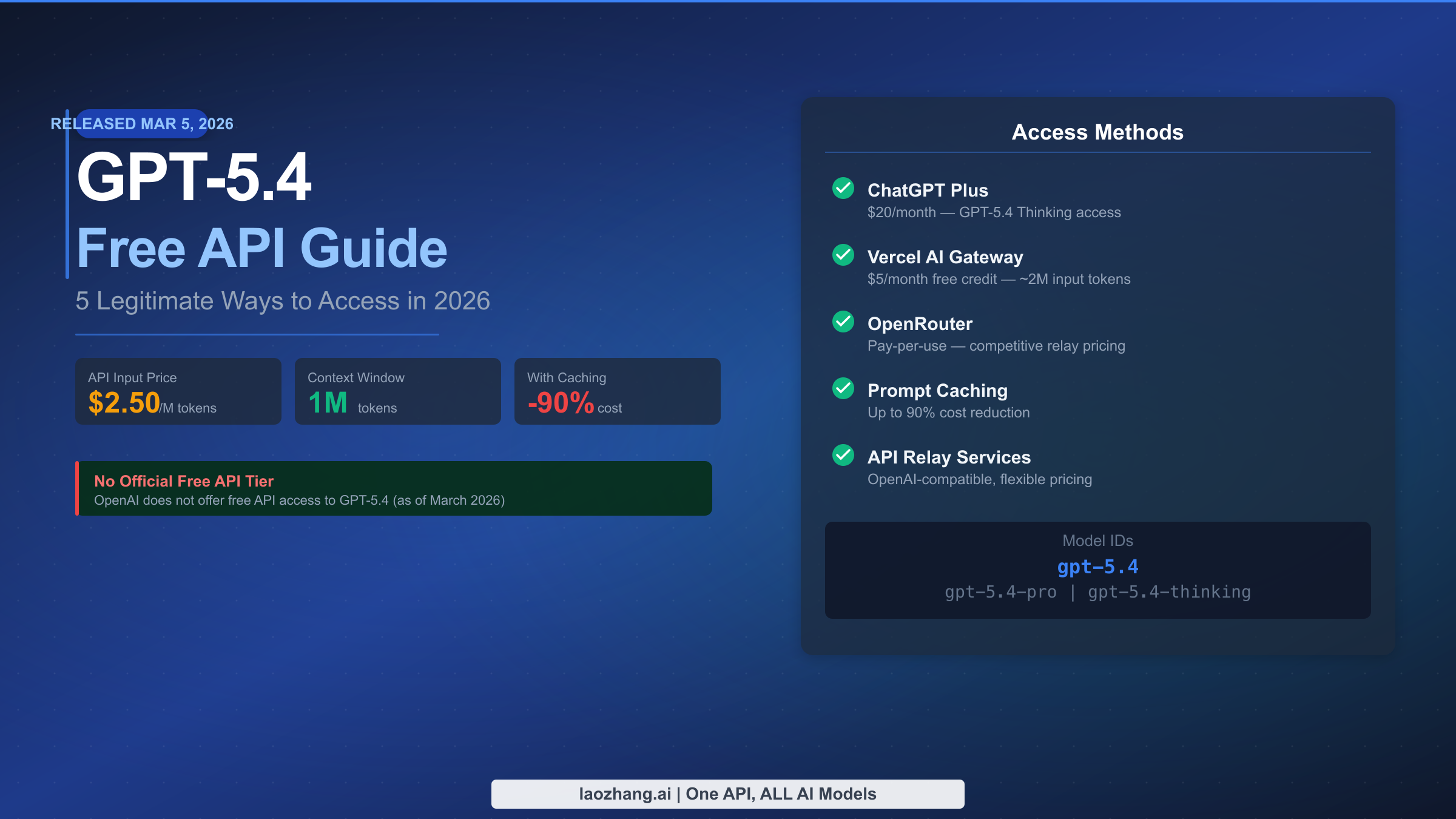



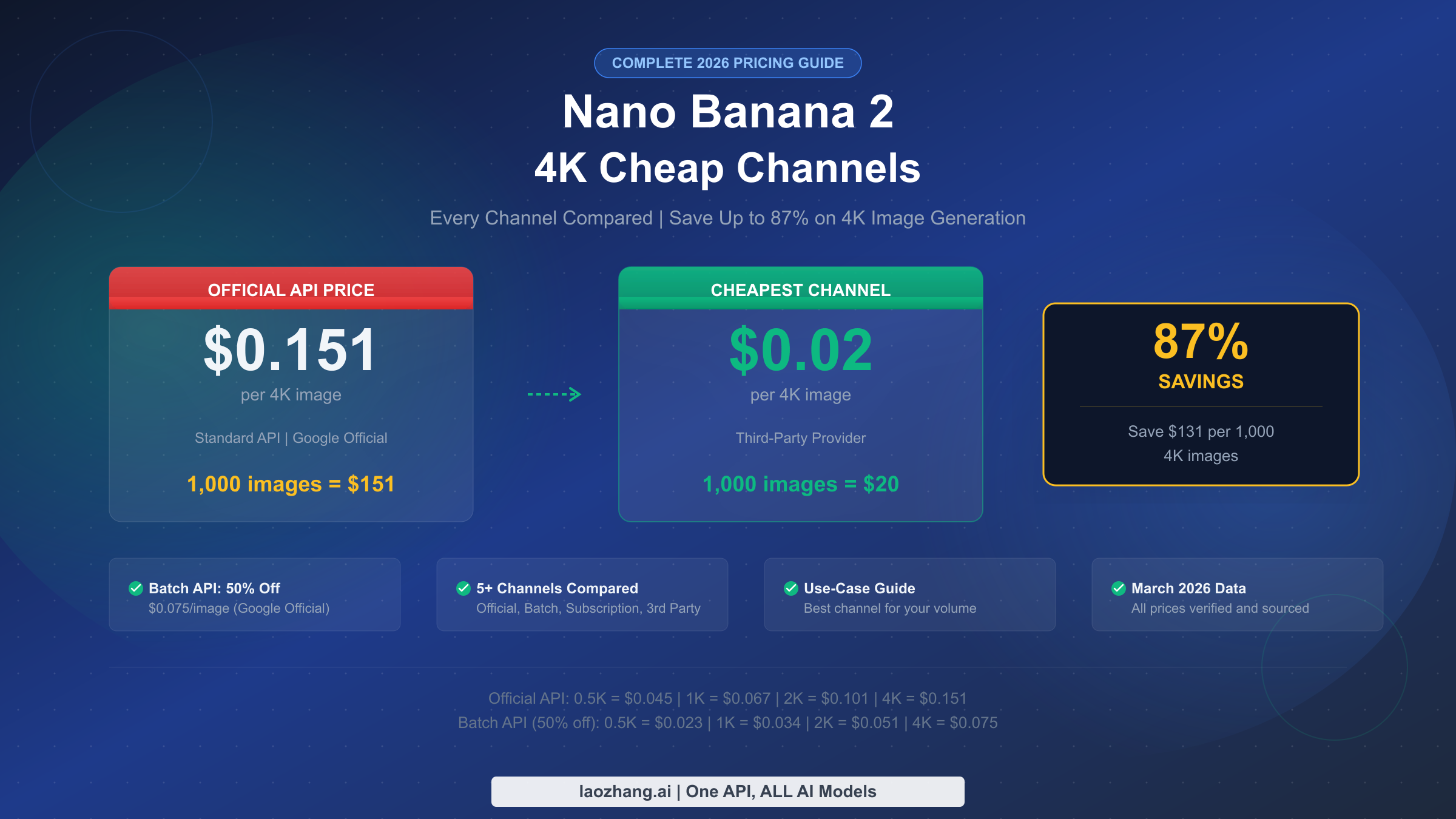
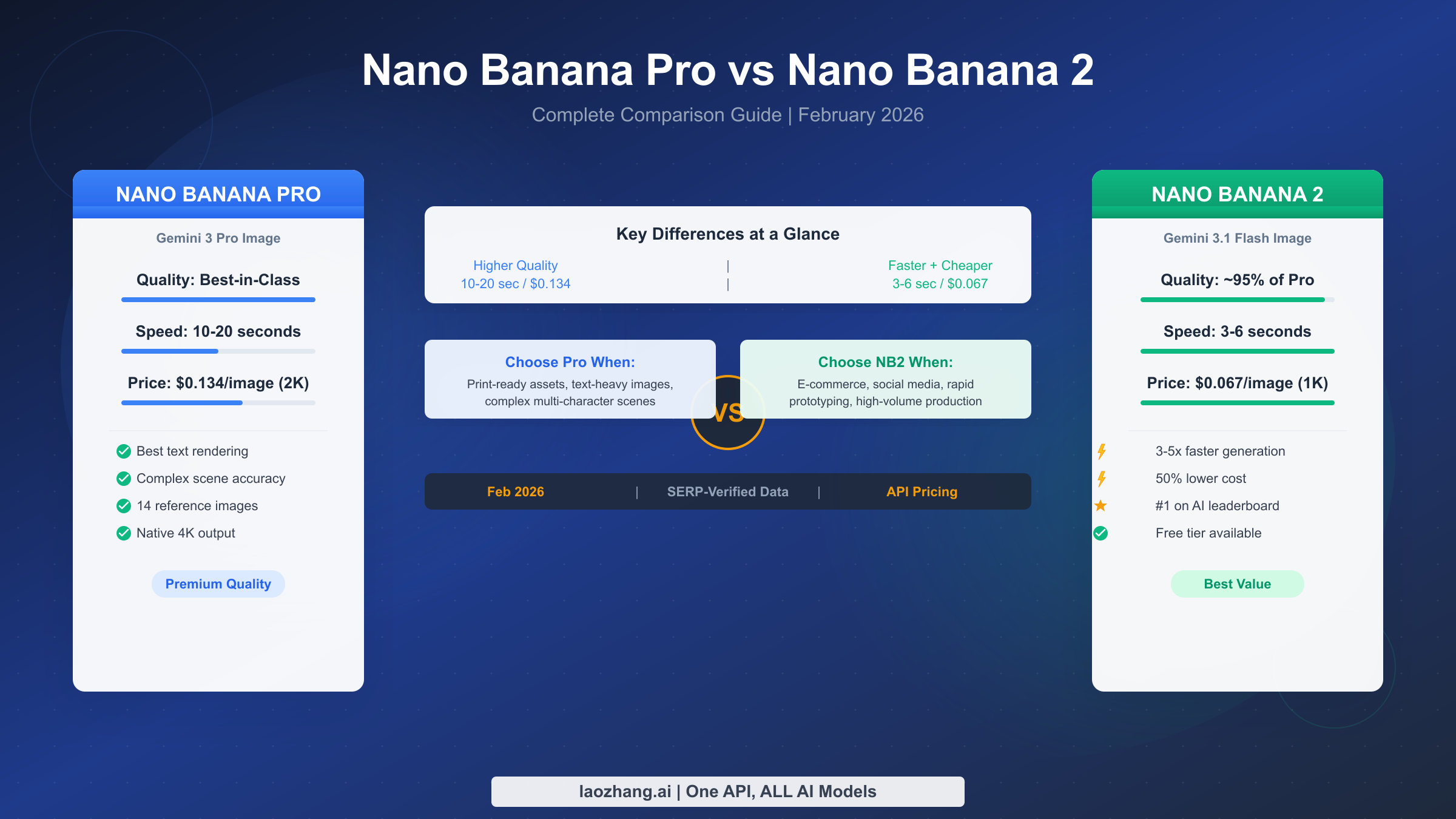
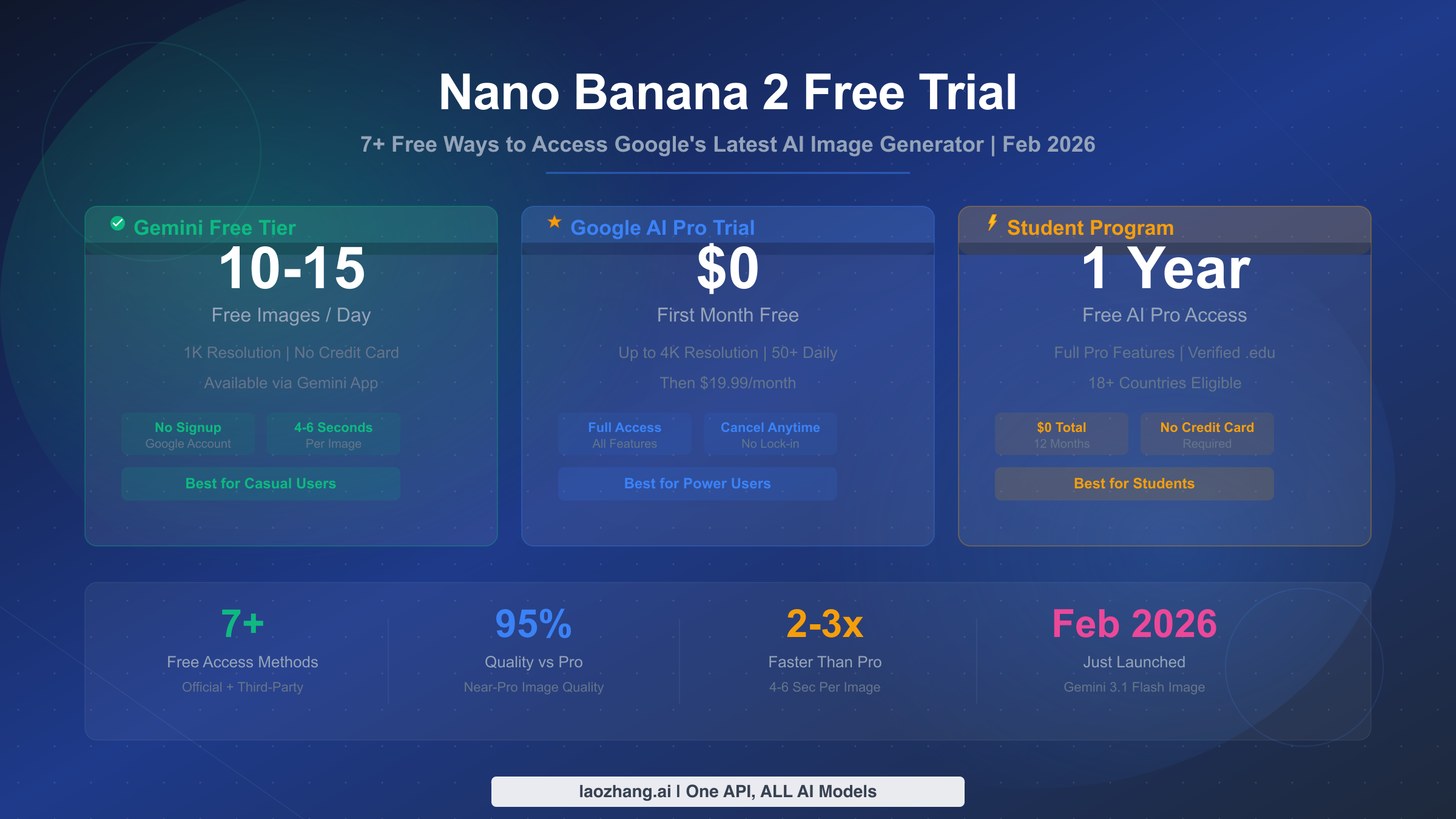
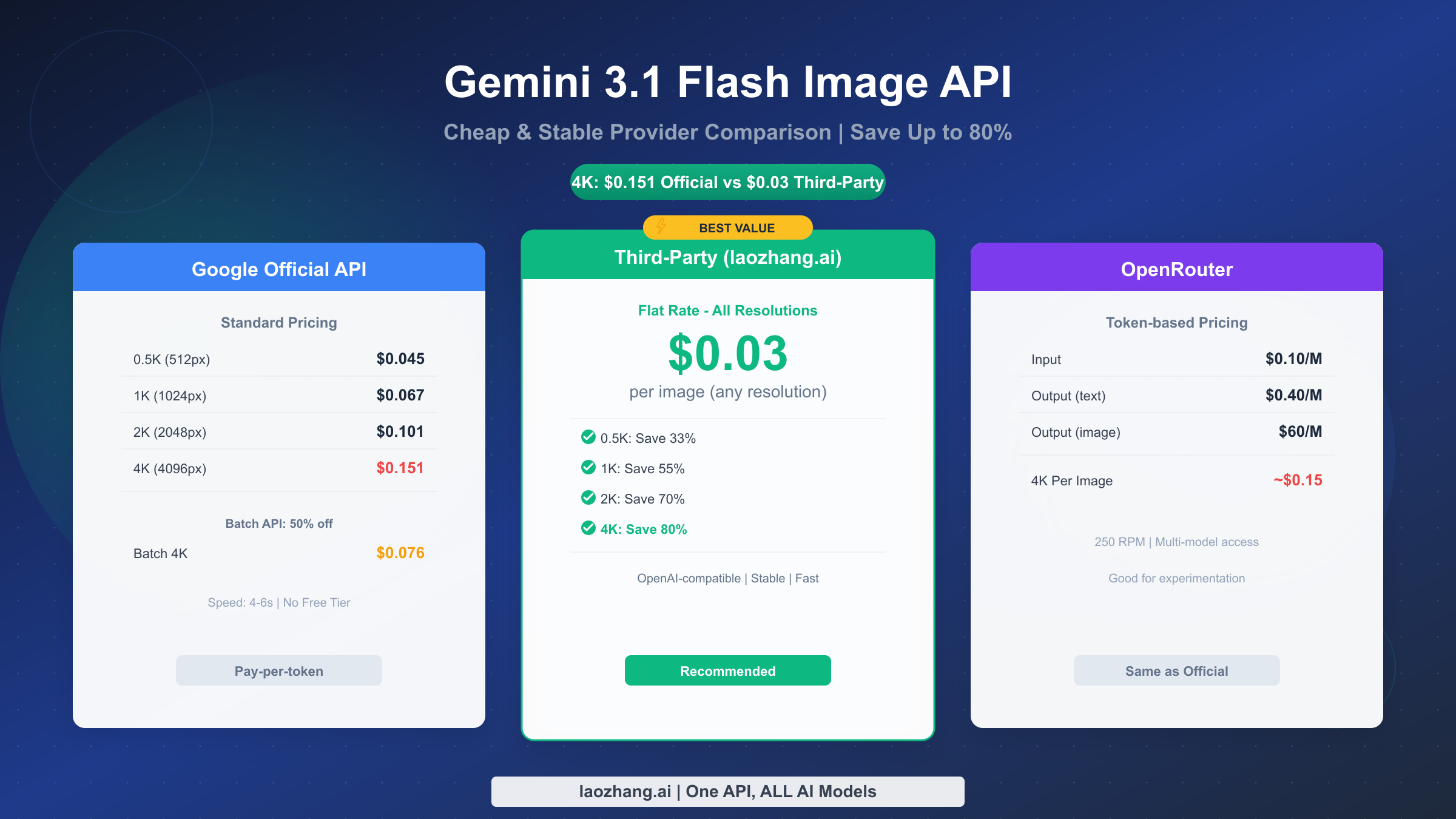
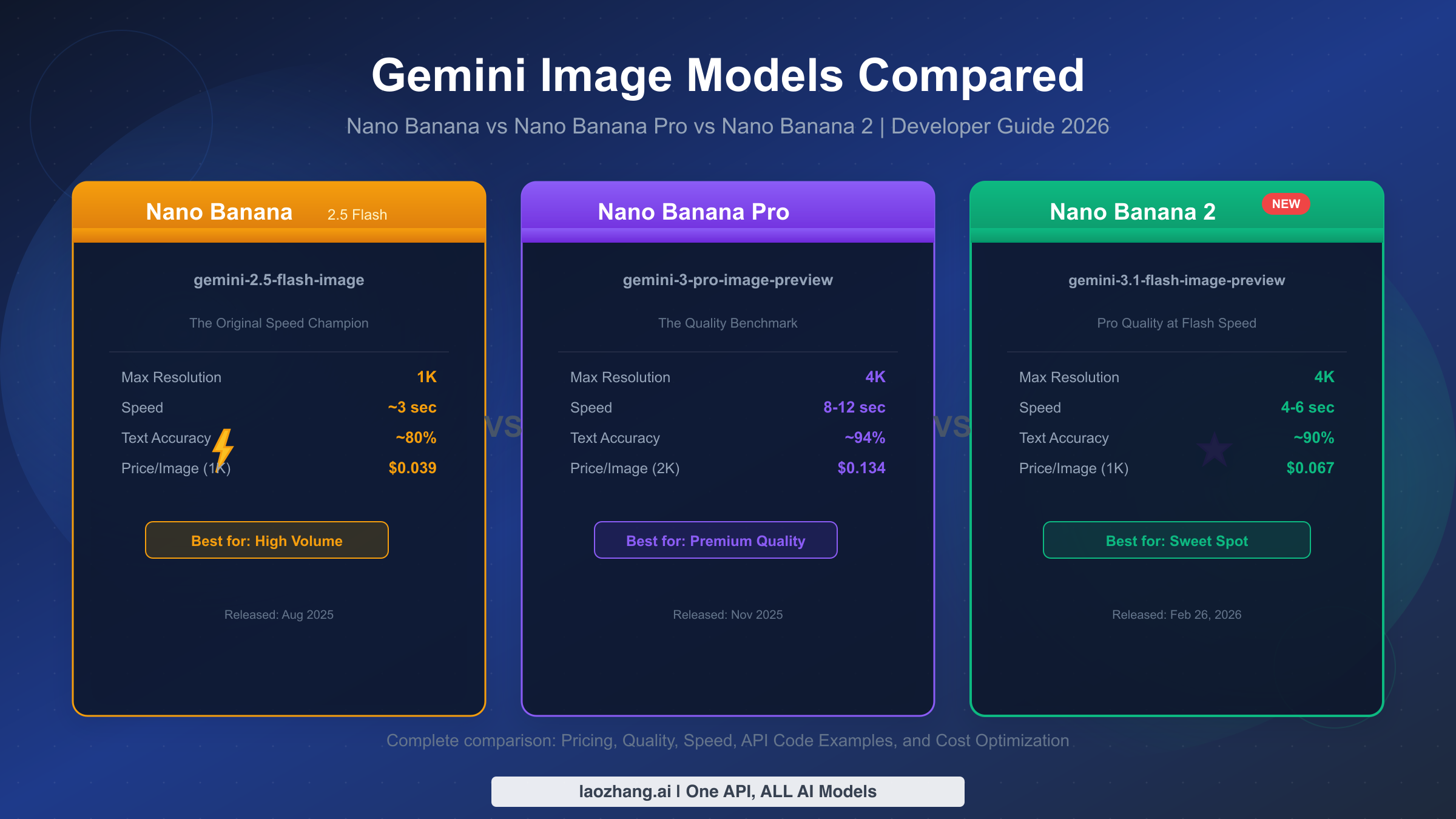
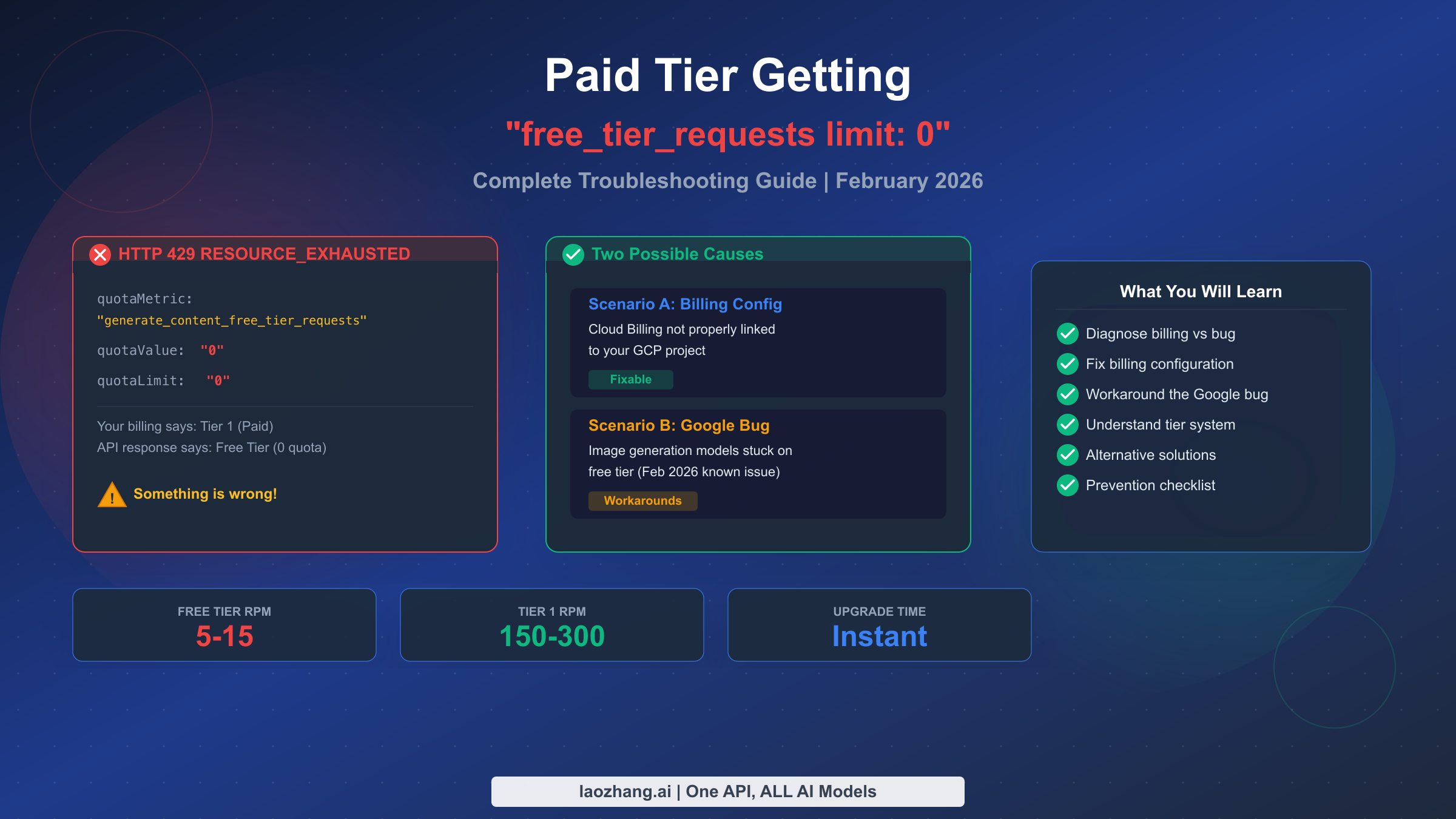

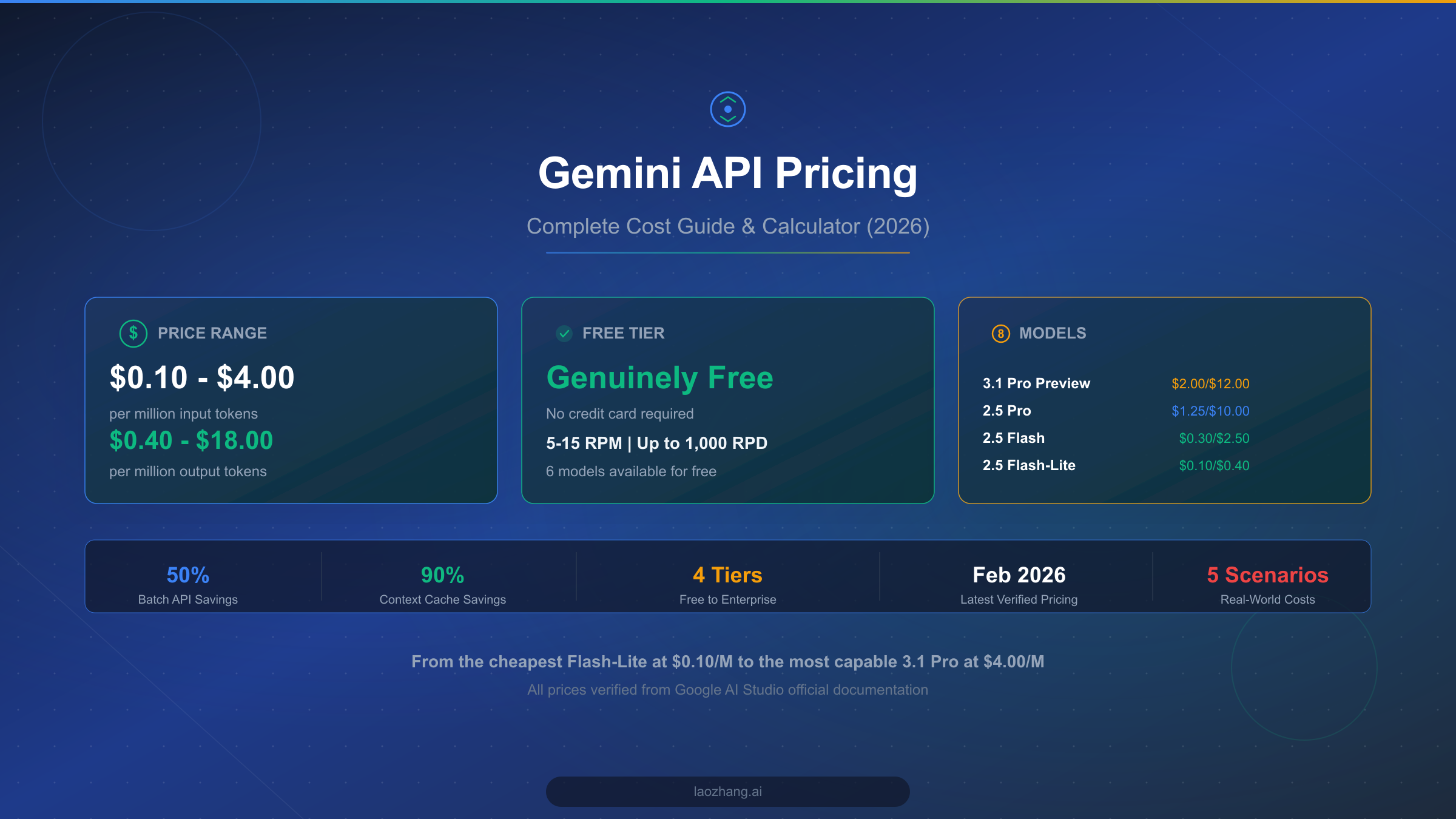

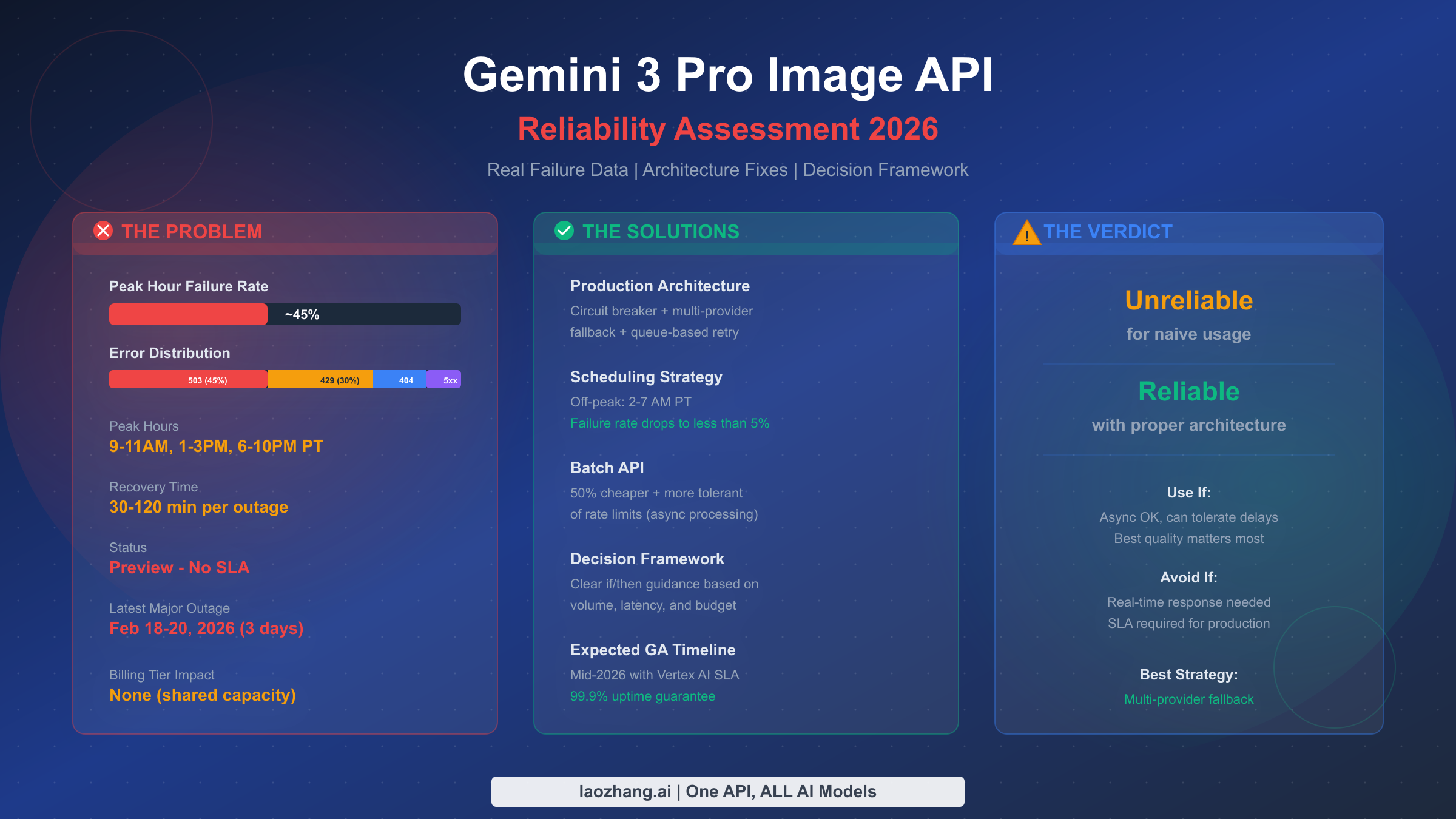
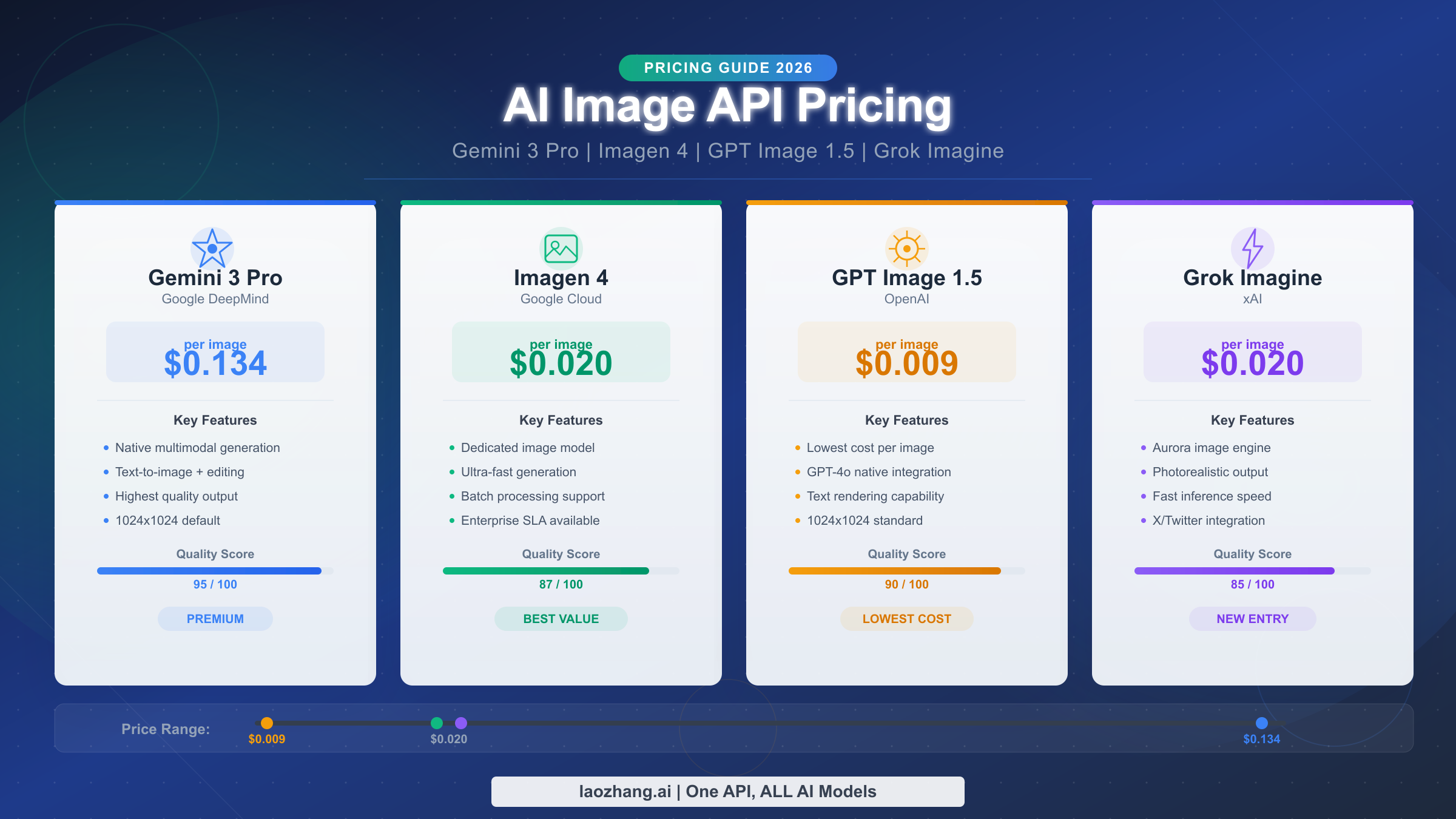


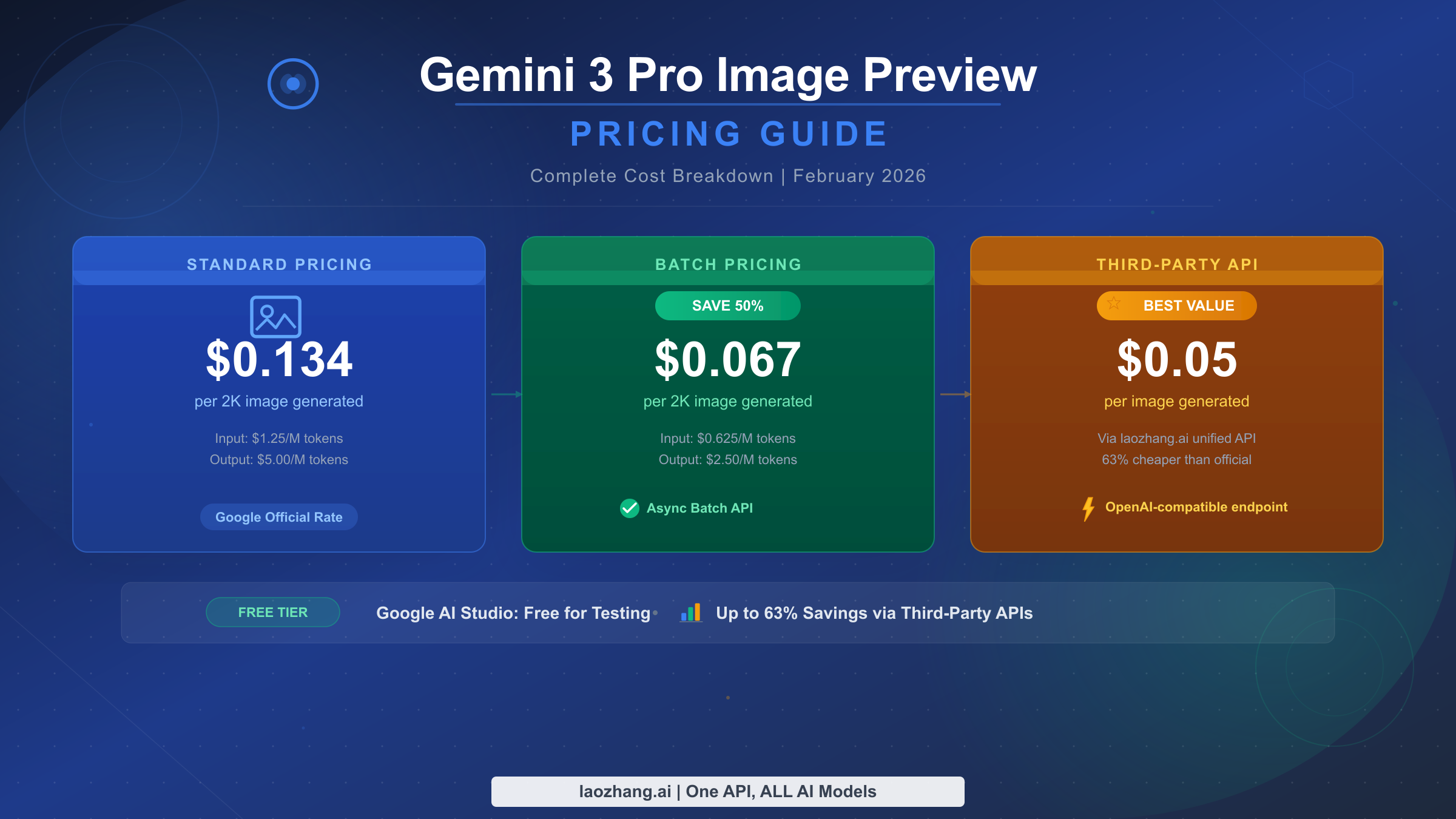

![Fix Gemini 3 Pro Image 503 Overloaded: Complete Troubleshooting Guide [2026]](/posts/en/fix-gemini-3-pro-image-503-overloaded/img/cover.png)







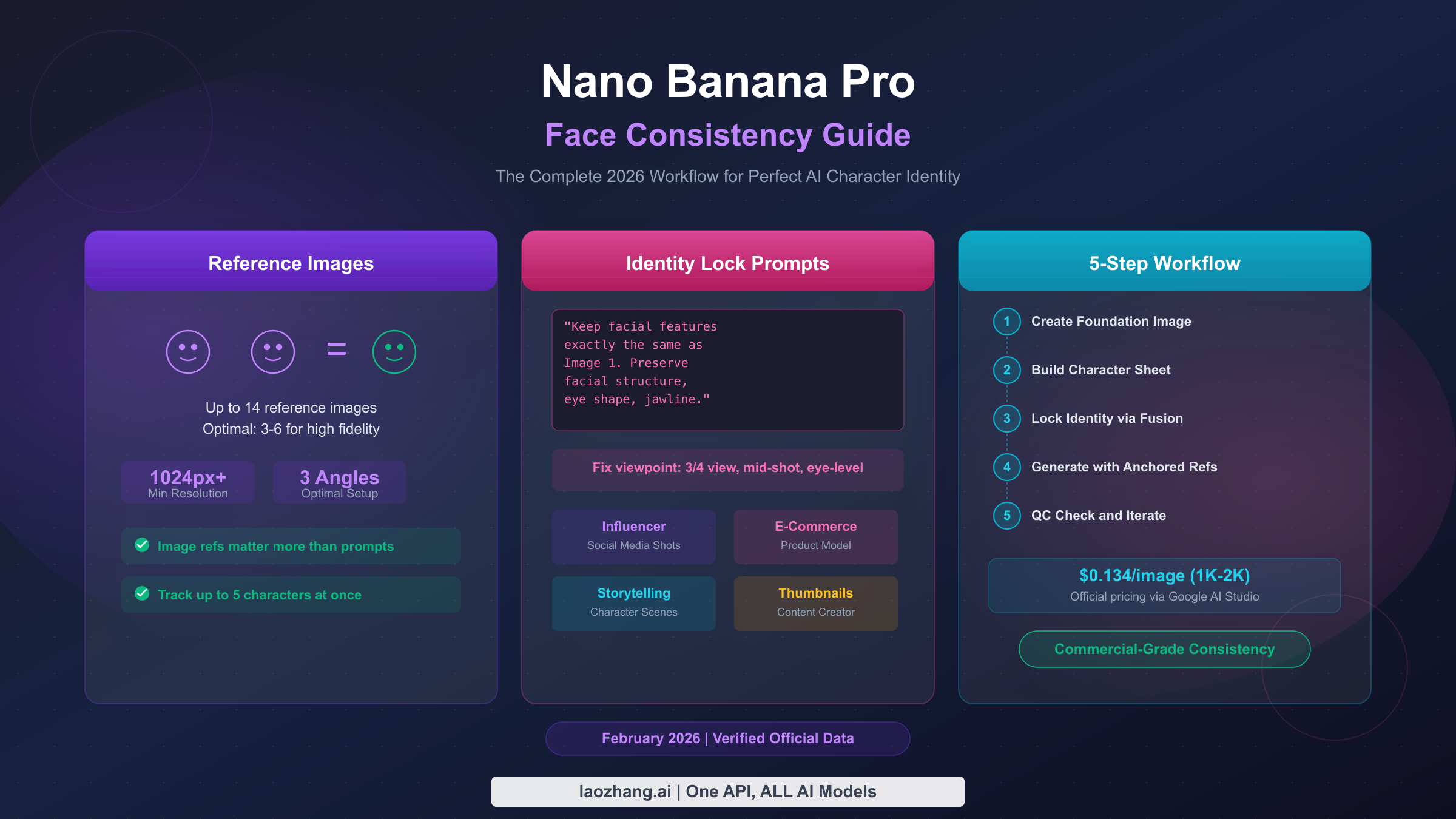


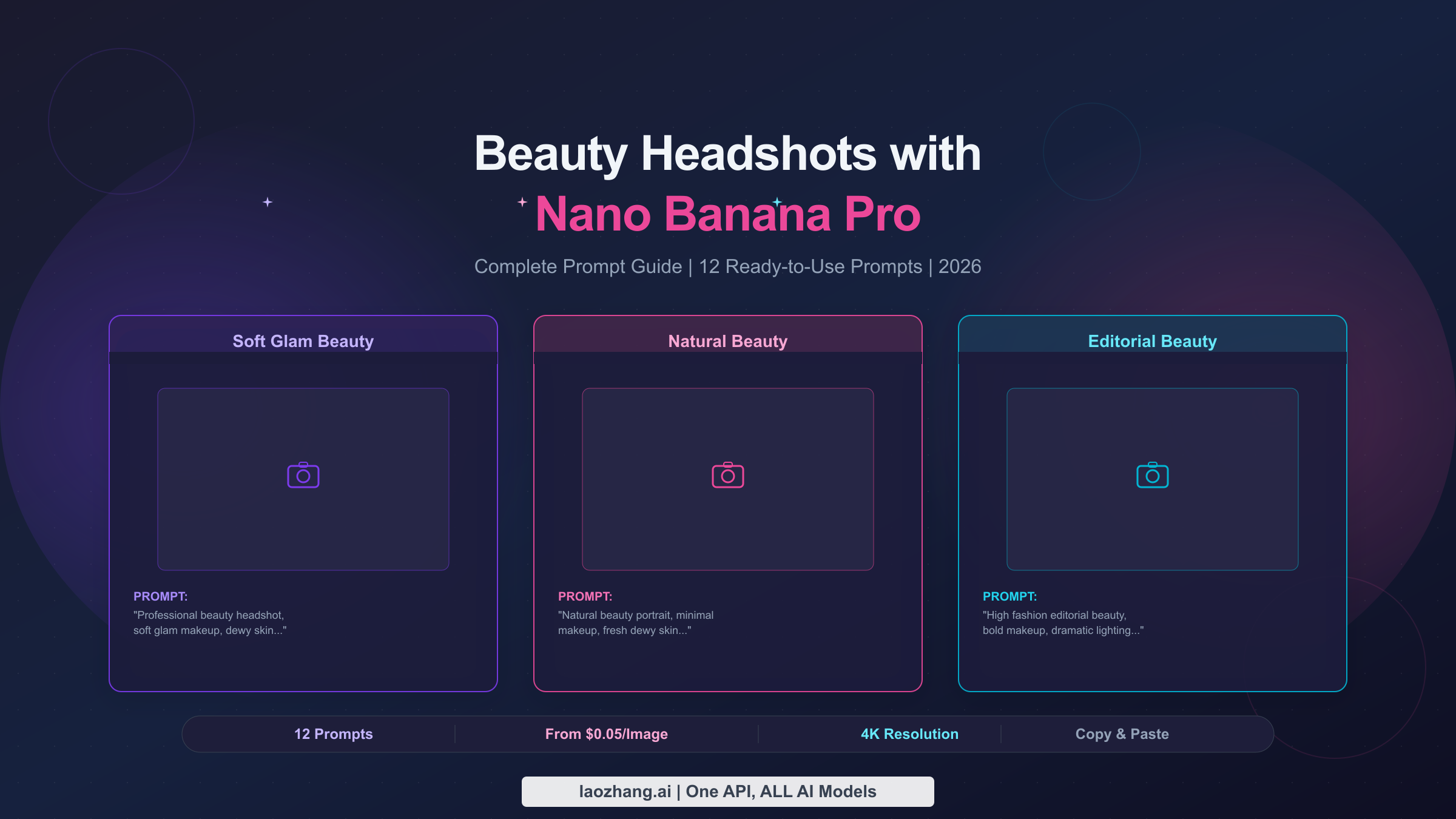
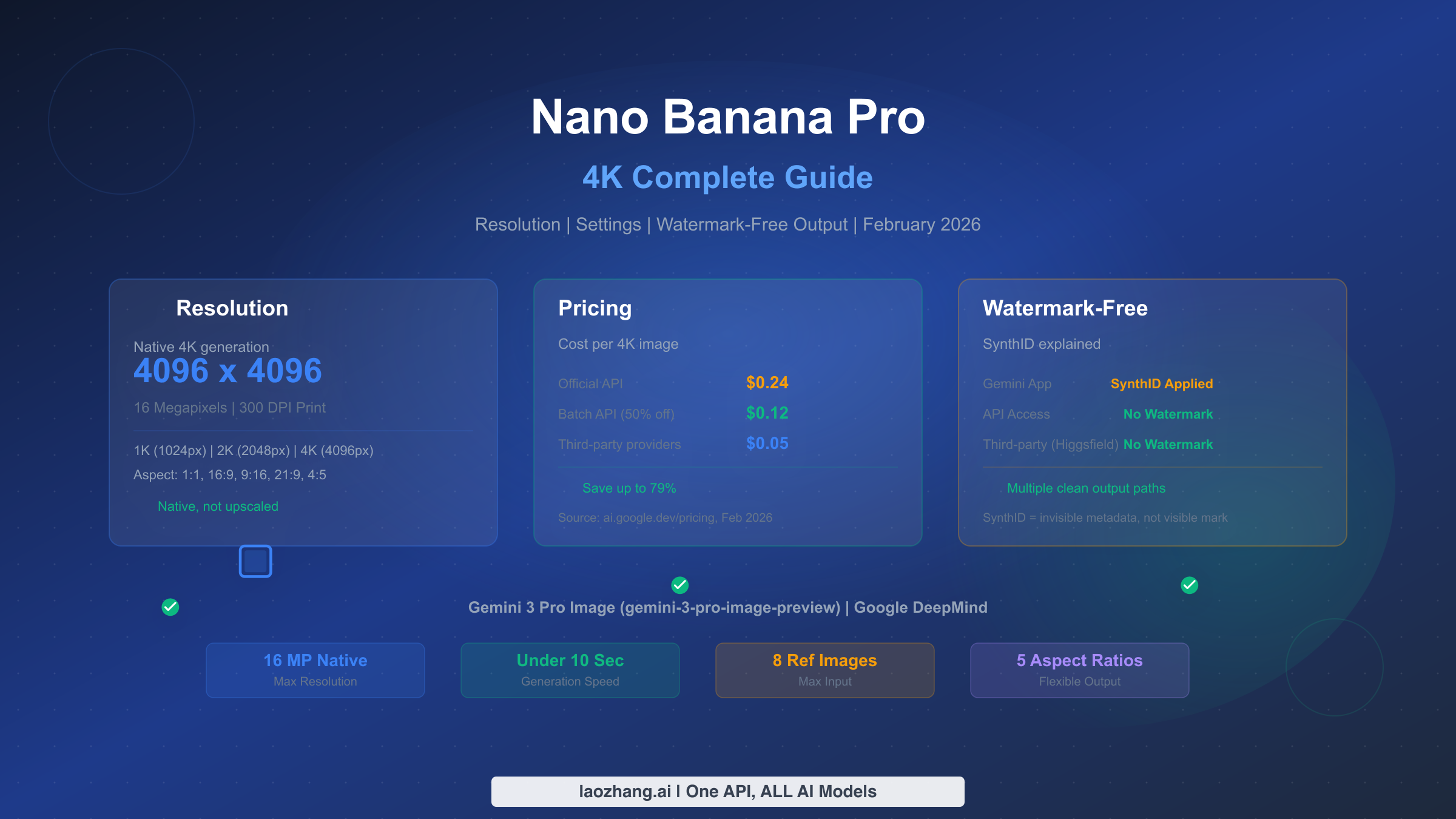


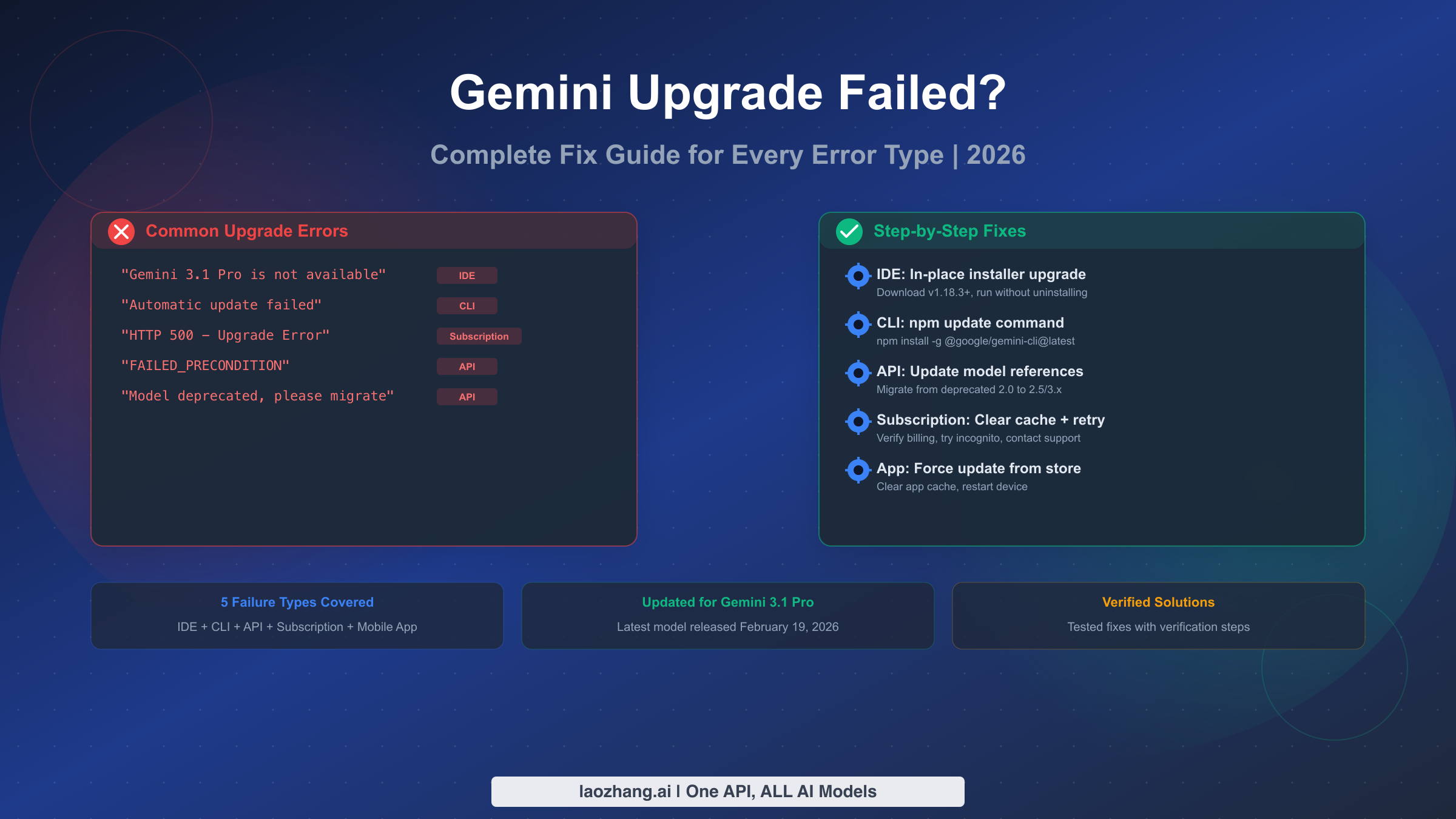




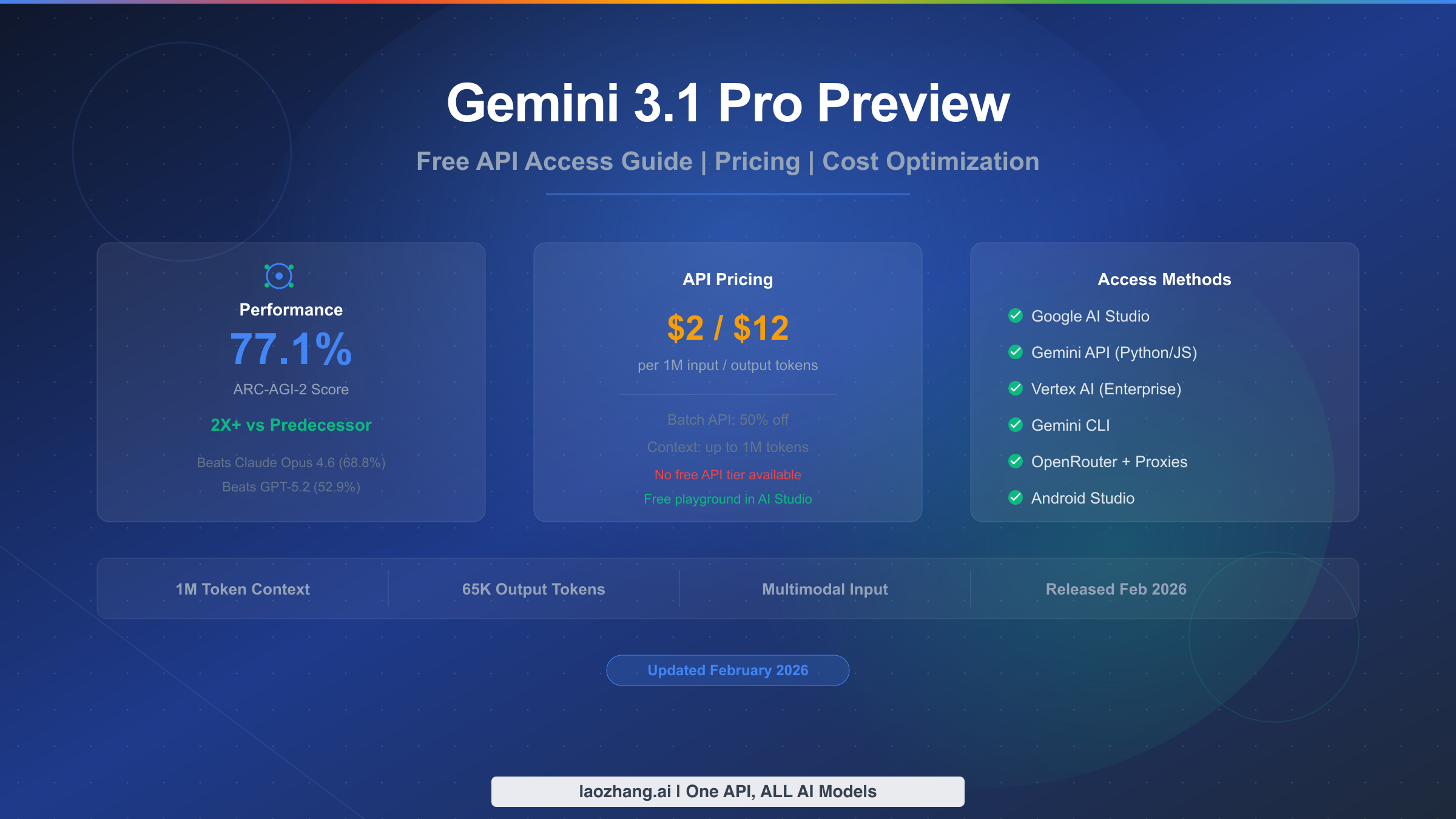
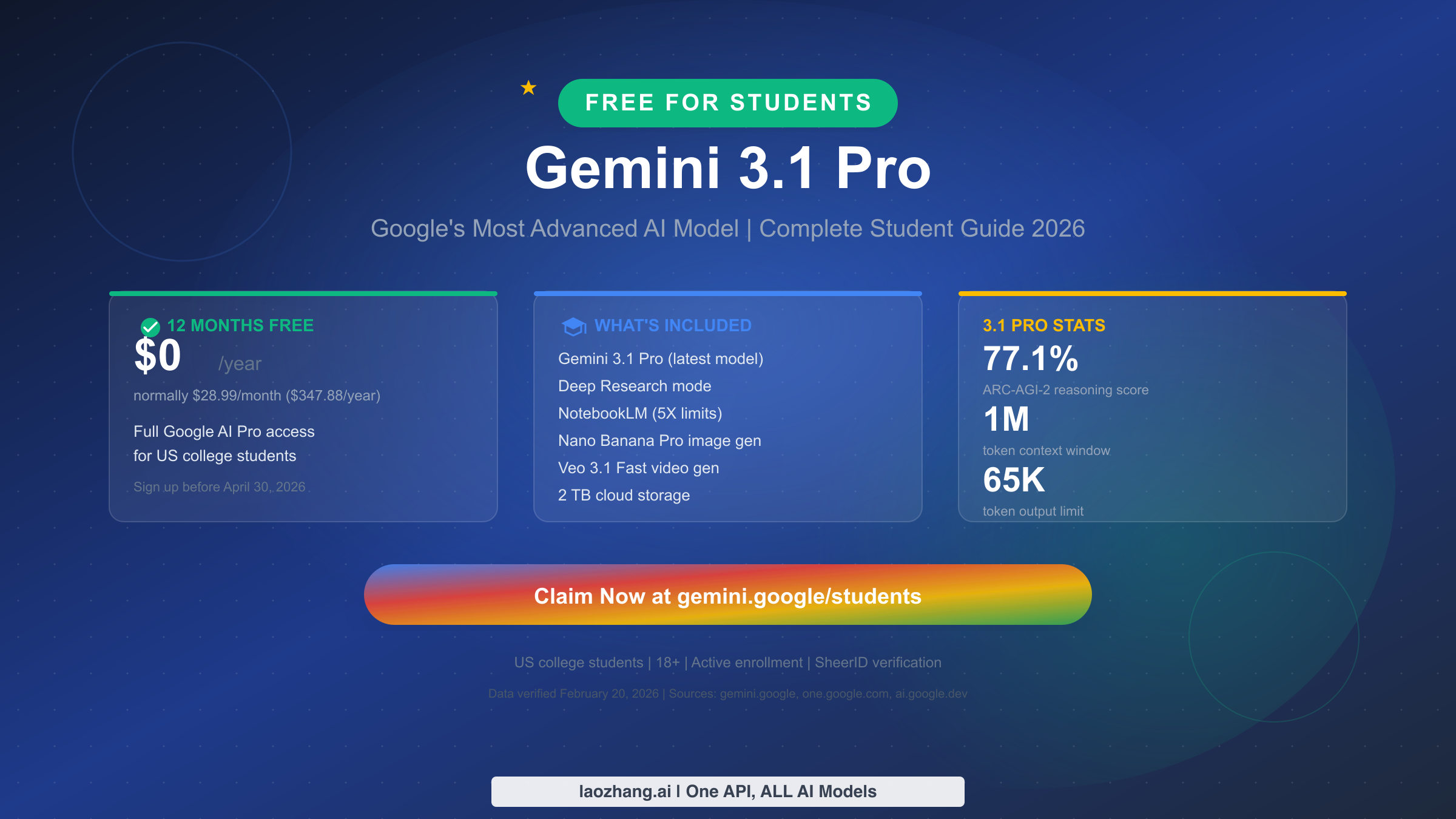
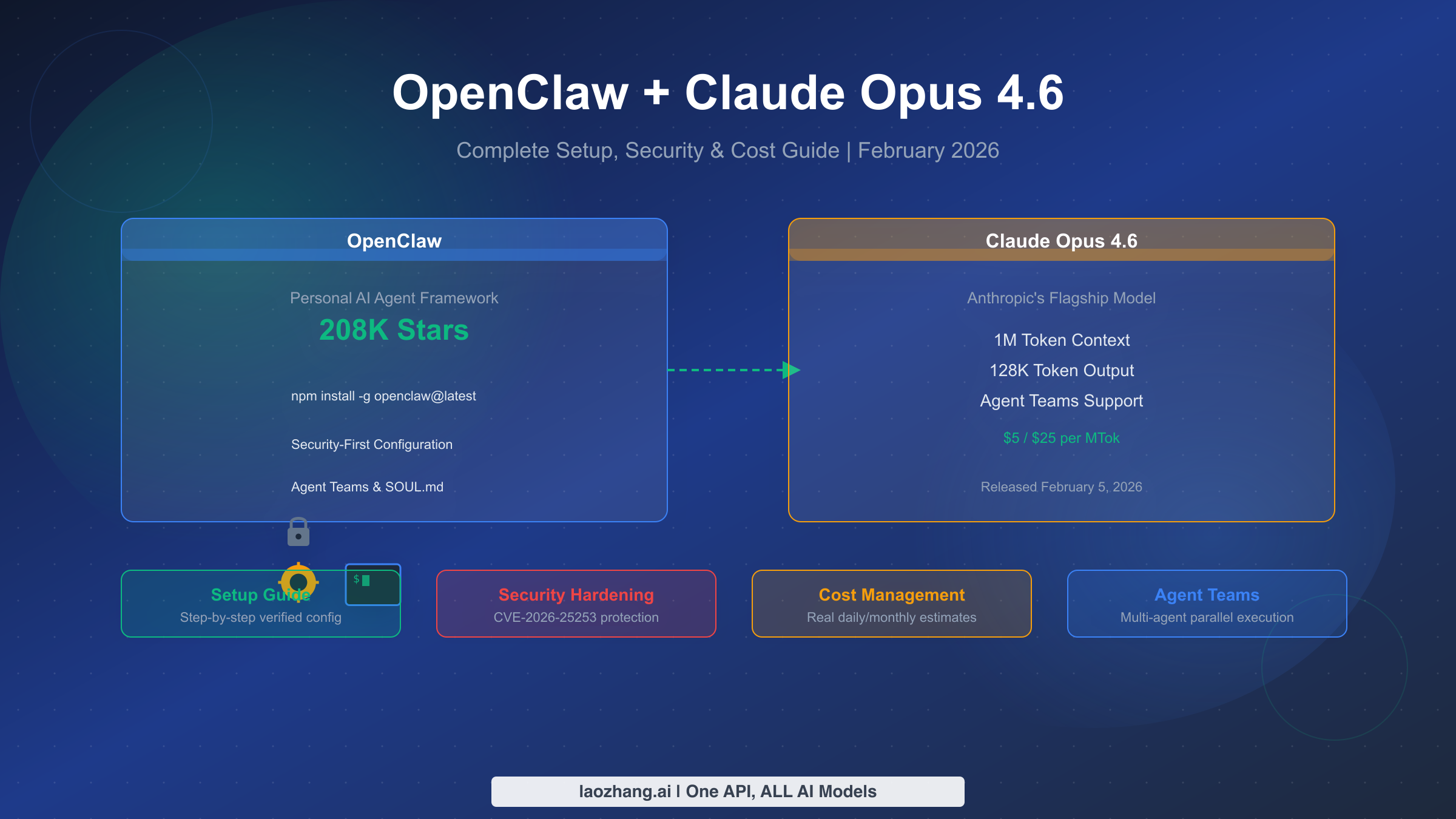

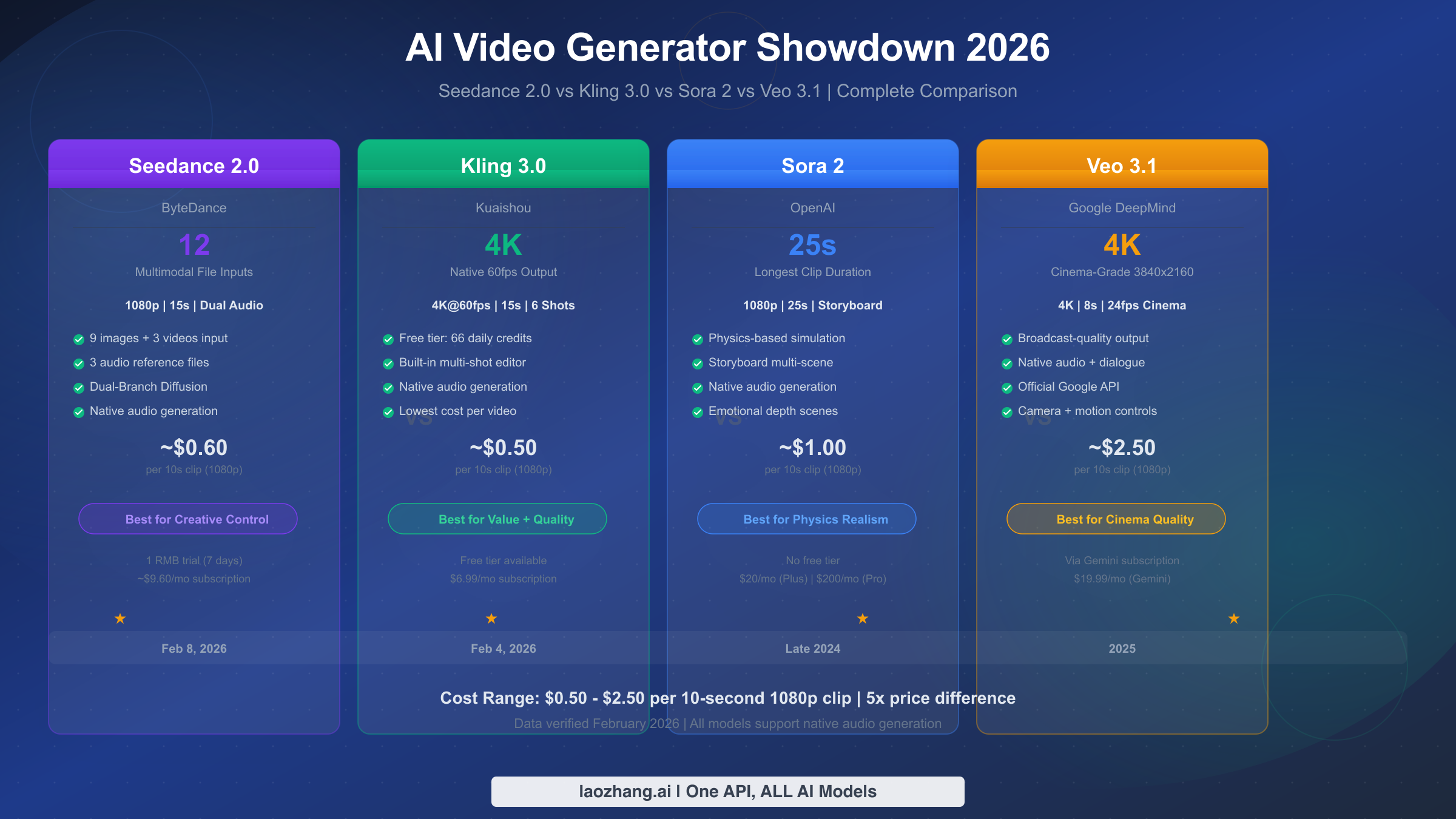





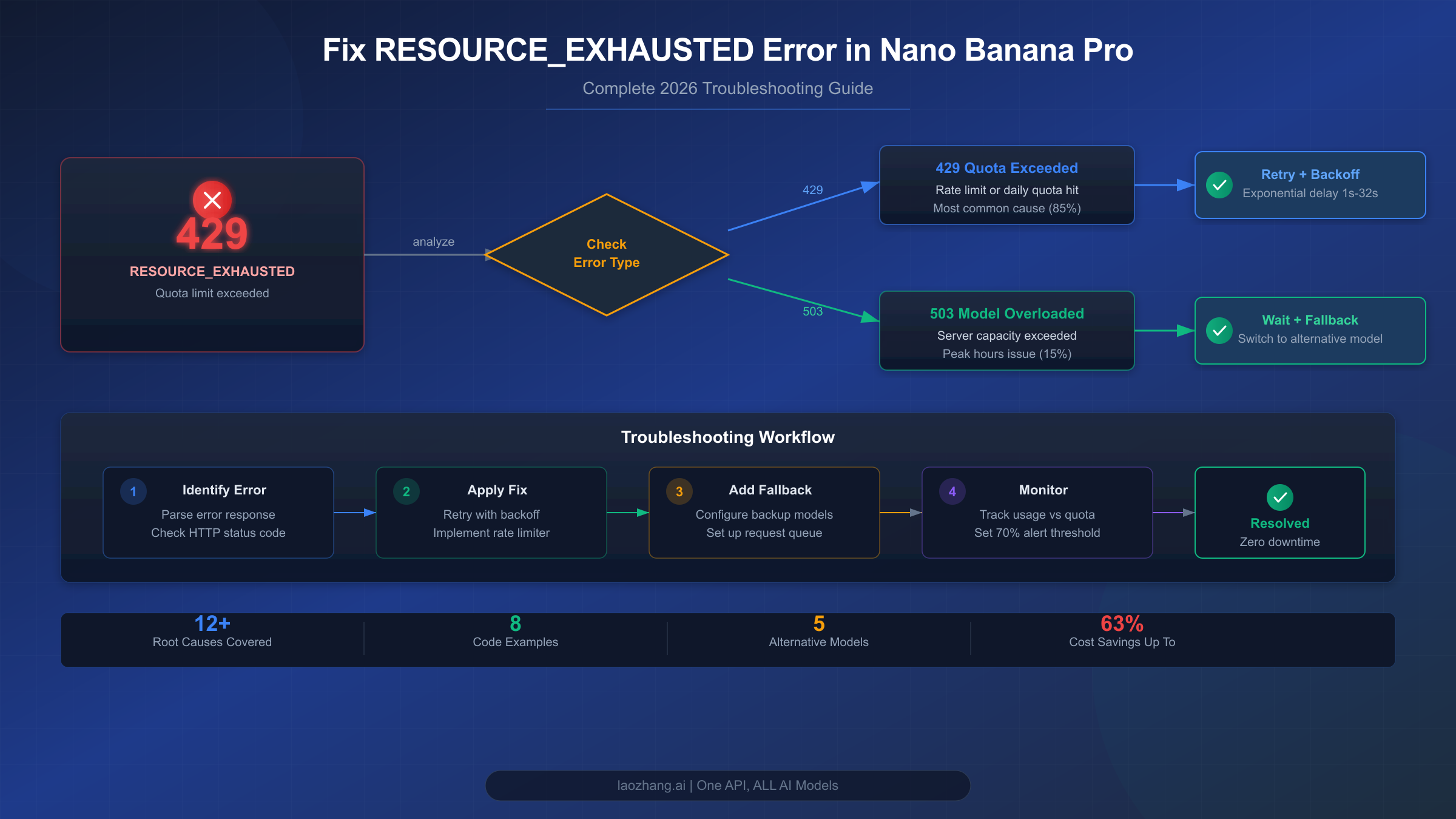
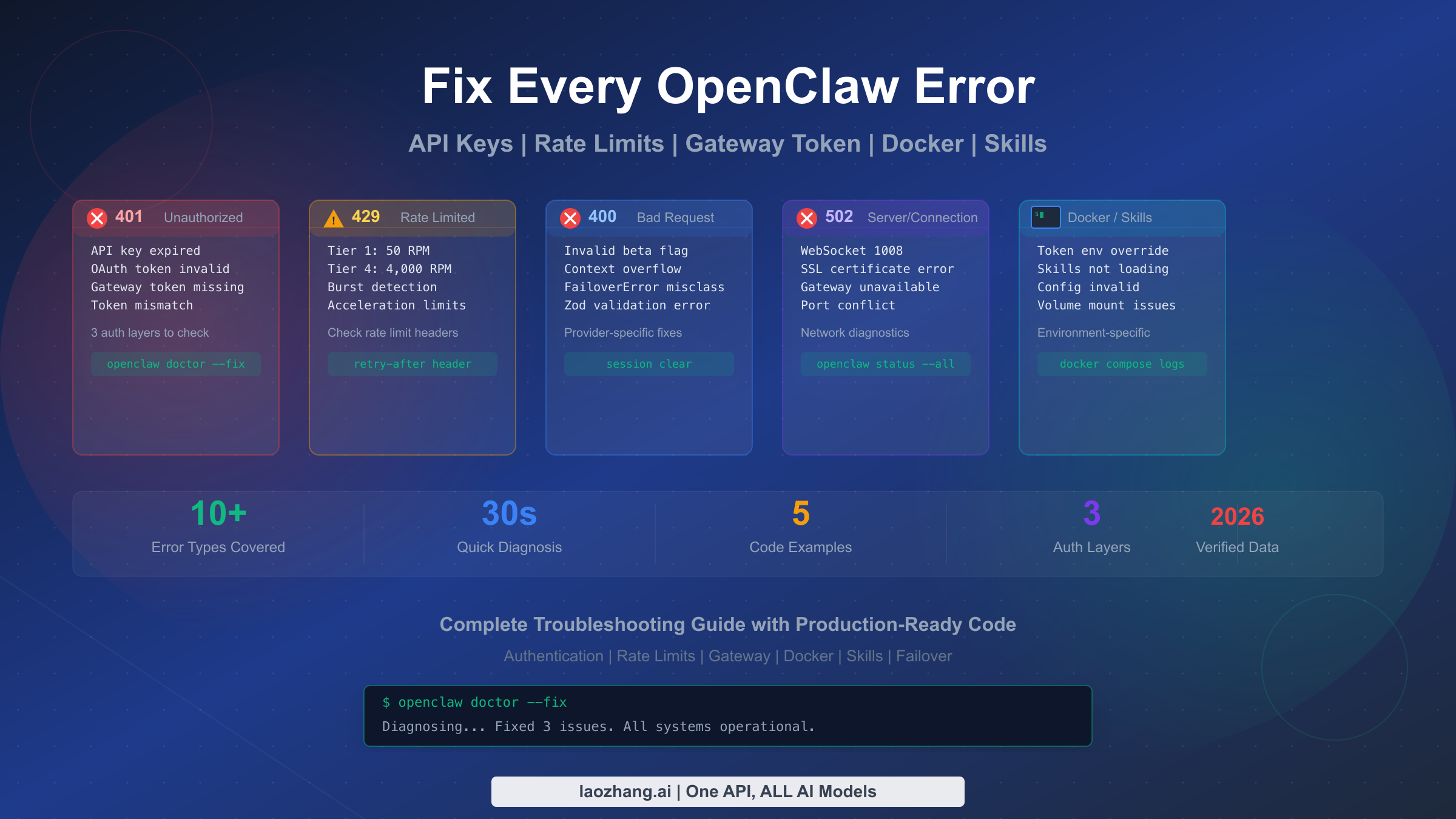
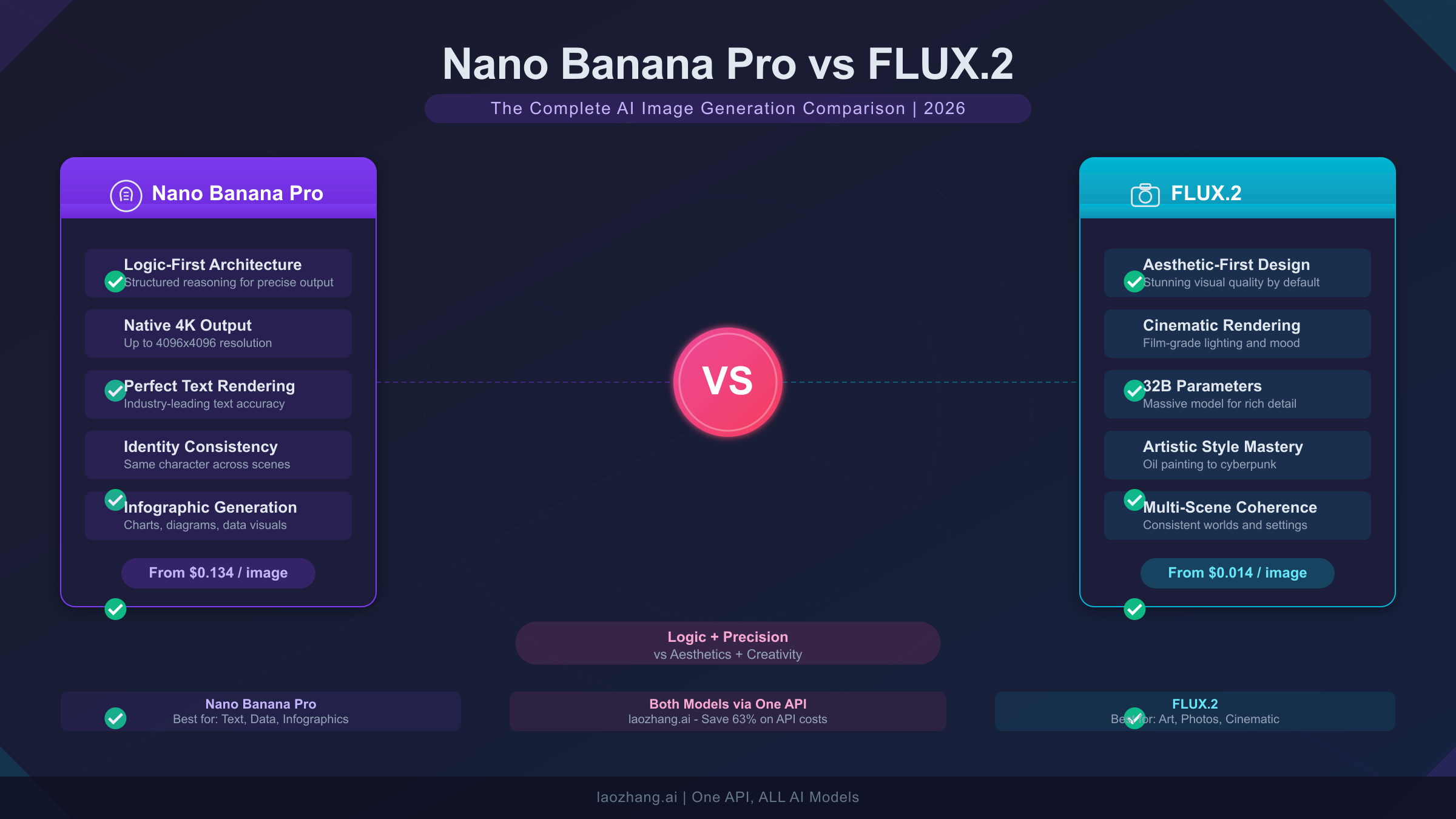


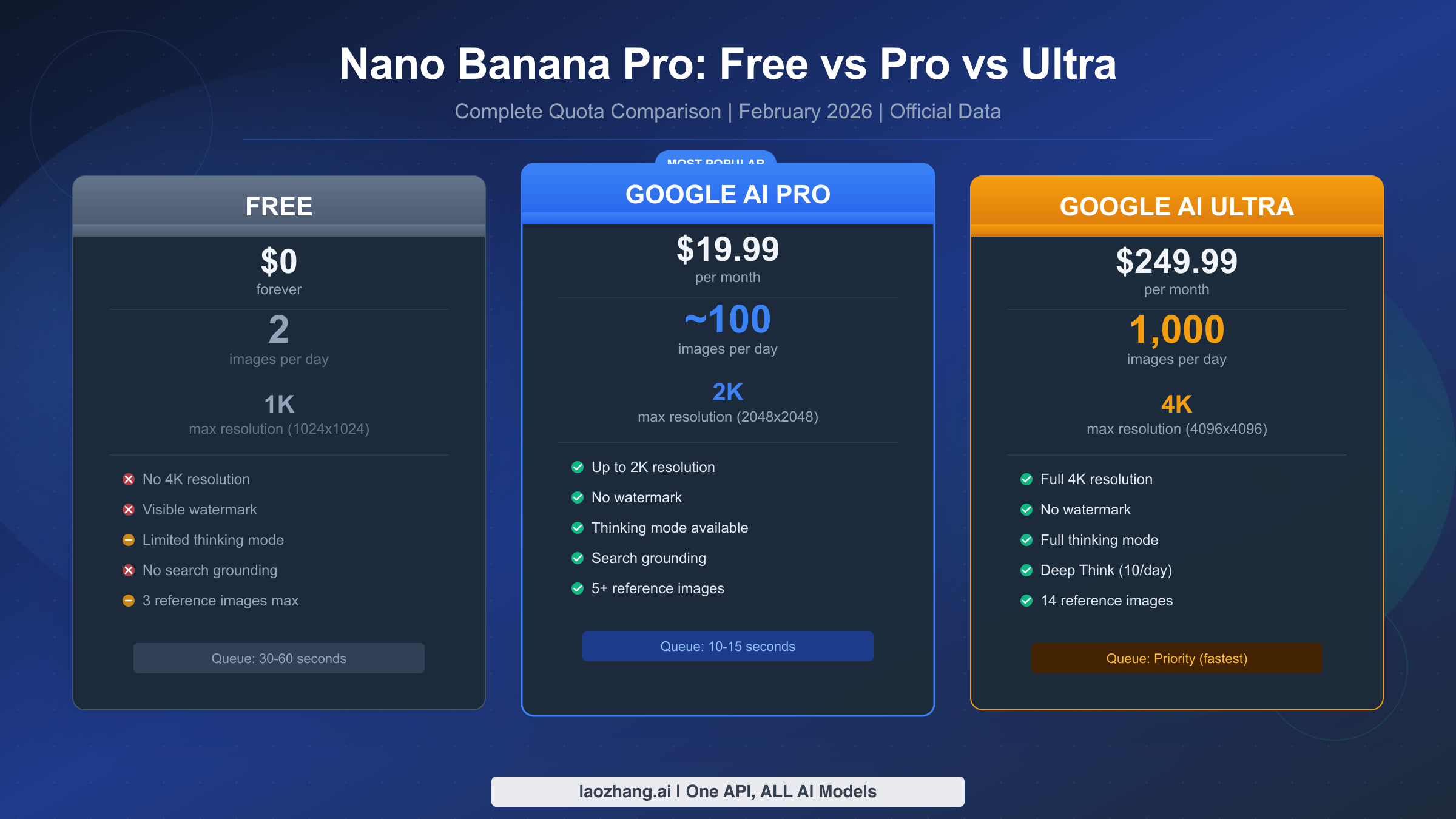
![Fix OpenClaw context_length_exceeded: Complete Troubleshooting Guide [2026]](/posts/en/openclaw-context-length-exceeded/img/cover.png)

![Fix OpenClaw Rate Limit Exceeded (429): Complete Troubleshooting Guide [2026]](/posts/en/openclaw-rate-limit-exceeded-429/img/cover.png)
![Fix OpenClaw Invalid Beta Flag Error: Complete Guide [2026]](/posts/en/openclaw-invalid-beta-flag/img/cover.png)

![Fix OpenClaw Anthropic API Key Error: Complete Guide [2026]](/posts/en/openclaw-anthropic-api-key-error/img/cover.png)
![Gemini 3 Complete Comparison: Pro, Flash, Nano Banana Pro Full Guide [2026 Update]](/posts/en/gemini-3-comparison/img/cover.png)