
如果你说的“OpenAI Sora API”是指 OpenAI 平台上官方、可编程的视频生成能力,答案是 有:OpenAI 当前的开发者接口是 Videos API,核心是 POST /v1/videos,配套模型是 sora-2 和 sora-2-pro。真正让人困惑的地方在于,OpenAI 同时还有 面向消费者的 Sora 应用/编辑器,以及 基于 ChatGPT 的 Sora 访问入口,这些表层并不会用同一套“API”语言来描述自己。这就是为什么到了 2026 年 3 月,搜索结果依然显得互相矛盾。
这篇文章回答的是开发者问题,不是应用使用问题。重点是当前真实存在的官方开发者契约、最快可用的 create -> wait -> download 工作流、在你开始构建前必须知道的价格与策略限制,以及 2026 年 3 月让旧版 Sora API 总结不再完整的那些变化。
时效说明:本文于 2026 年 3 月 28 日对 OpenAI Developers 文档、价格页、模型页和帮助中心材料完成核验。
TL;DR
- 现在已经有官方开发者接入。 你要用的是
/v1/videos,不是消费级 Sora 编辑器。 - 先用
sora-2,适合低成本迭代提示词、构图和运动。 - 需要更高成片质量时再切到
sora-2-pro,尤其是需要1920x1080或1080x1920时。 - 默认按异步工作流设计。 创建任务后,轮询
GET /videos/{video_id}或使用 webhook,最后通过GET /videos/{video_id}/content下载成品。 - OpenAI 的 Sora 文档目前部分不同步。 当前主指南和 2026 年 3 月 changelog 已经写明 16/20 秒、视频 edits、extensions、可复用角色、Batch 和 1080p
sora-2-pro,但一些较旧的 reference 片段仍只显示更短时长和更低分辨率上限。
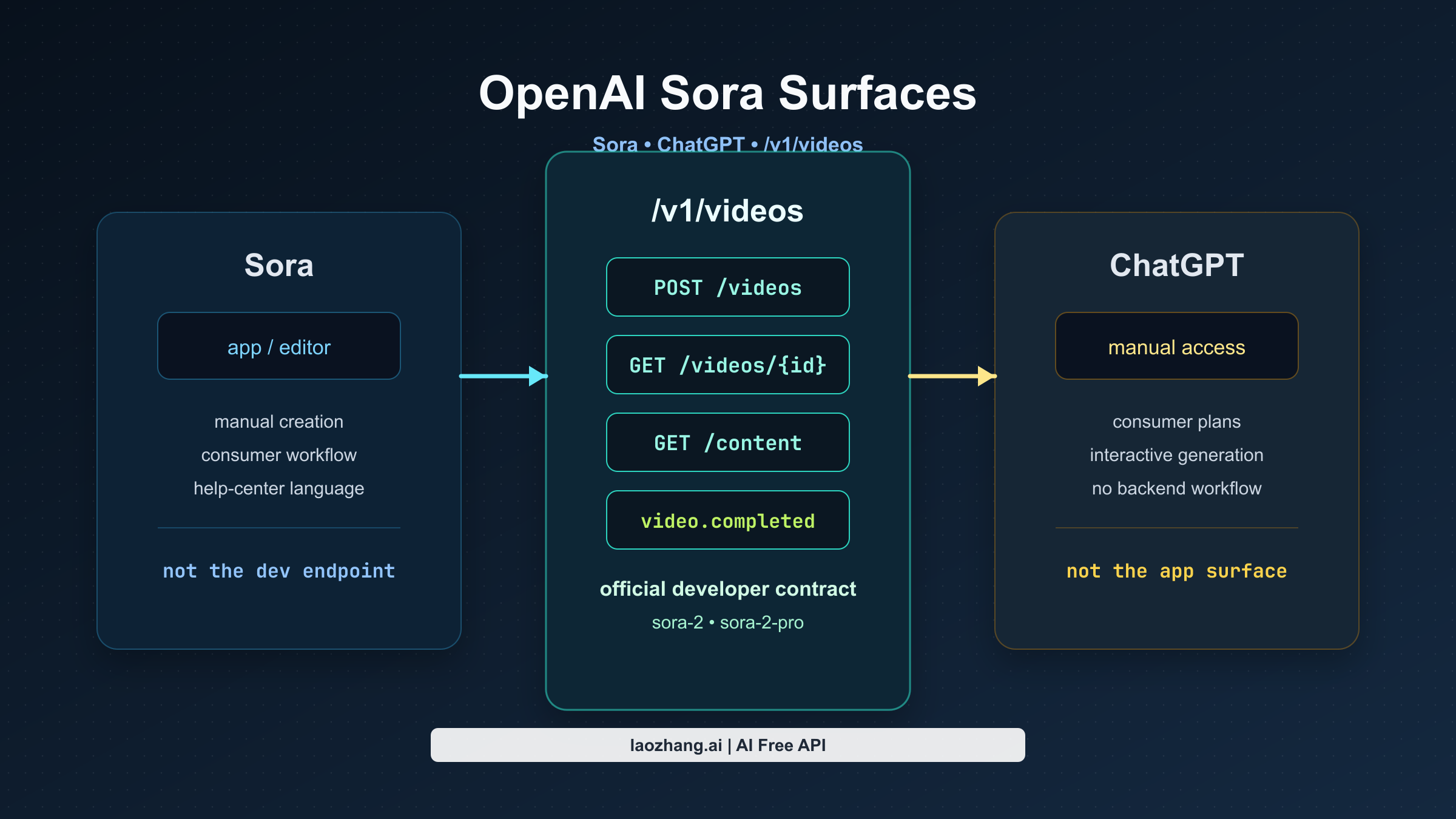
现在的“OpenAI Sora API”到底指什么
这个话题里最常见的错误,是把 Sora 当成一个单一产品表层。实际上它至少分成三层:
| 表层 | 它是什么 | 面向谁 | 适合做什么 |
|---|---|---|---|
| Sora 应用 / 编辑器 | OpenAI 的消费级 Sora 体验 | 手动制作视频的个人用户 | 在应用或网页编辑器中创作和探索 |
| ChatGPT 访问 | ChatGPT 套餐中的 Sora 生成能力 | 想在 ChatGPT 里手动生成视频的用户与专业用户 | 不写后端、直接交互式生成 |
| Videos API | OpenAI 的官方开发者表层 | 开发者、创业团队、产品团队 | 程序化视频生成、edits、extensions、Batch 和资产处理 |
这正是官方页面读起来会互相矛盾的原因。帮助中心里仍有大量以应用为中心的 Sora 说明,那些内容讨论的是 消费级产品。而开发者文档现在已经明确给出了可用的 Video generation with Sora 栈,包含当前端点、模型、价格和代码示例。
所以今天最可靠的理解方式其实很简单:
不要去“接入 Sora 应用”,而是接入 OpenAI 的 Videos API。
这句话一旦说清楚就很显然,但当前搜索结果里最缺的恰好就是这个澄清。
今天最快能跑通的 OpenAI 路径
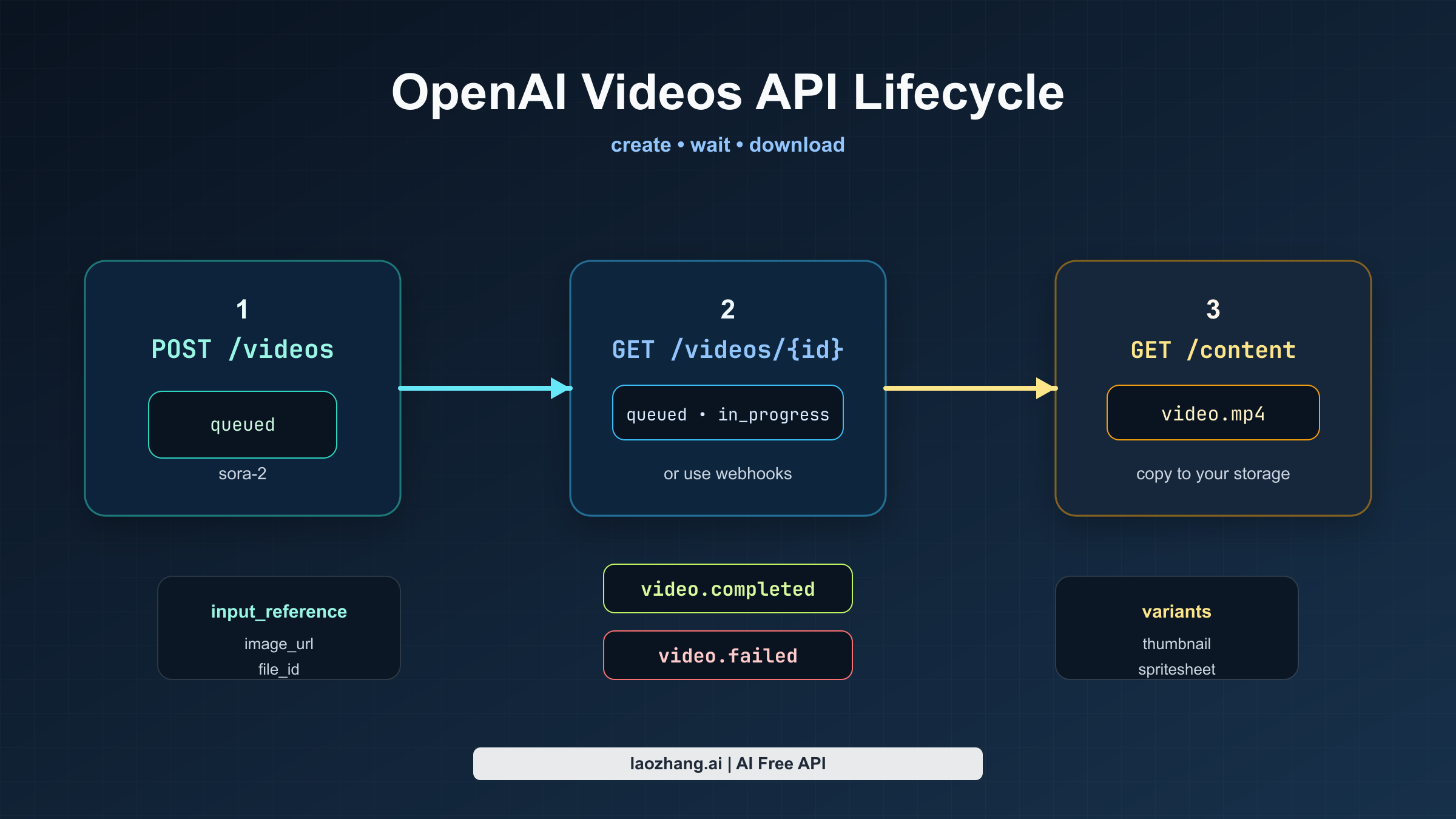
如果你只想从零到一尽快跑出一个官方可用结果,路径其实很直接。
先调用 POST /v1/videos 并传入 prompt、model、size 和 duration。OpenAI 把视频生成定义成异步任务,所以初始响应只会告诉你任务已经创建,并进入 queued 或 in_progress 之类的状态。接下来你可以轮询 GET /v1/videos/{video_id},直到状态变成 completed;或者注册 webhook,让 OpenAI 在 video.completed 或 video.failed 事件发生时通知你。任务完成后,再通过 GET /v1/videos/{video_id}/content 获取二进制视频文件。
做原型时,轮询已经够用。做生产系统时,webhook 才是更干净的契约,因为长视频渲染可能要几分钟,你不应该为了知道“还没好”而持续消耗请求。
下面是基于 OpenAI 当前 SDK 习惯用法的最小 JavaScript 路径:
javascriptimport OpenAI from "openai"; import { writeFile } from "node:fs/promises"; const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY }); const video = await openai.videos.createAndPoll({ model: "sora-2", prompt: "Wide tracking shot of a yellow taxi crossing a rain-soaked city street at blue hour, neon reflections, natural ambient audio.", size: "1280x720", seconds: "8", }); if (video.status !== "completed") { throw new Error(`Video failed with status ${video.status}`); } const content = await openai.videos.downloadContent(video.id); const buffer = Buffer.from(await content.arrayBuffer()); await writeFile("video.mp4", buffer); // In production, copy the file into your own object storage immediately.
下面是同一个生命周期的原始 HTTP 版本:
bashcurl -X POST "https://api.openai.com/v1/videos" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F model="sora-2" \ -F prompt="Wide tracking shot of a yellow taxi crossing a rain-soaked city street at blue hour, neon reflections, natural ambient audio." \ -F size="1280x720" \ -F seconds="8" curl "https://api.openai.com/v1/videos/$VIDEO_ID" \ -H "Authorization: Bearer $OPENAI_API_KEY" curl -L "https://api.openai.com/v1/videos/$VIDEO_ID/content" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ --output video.mp4
这就是核心接入路径。当前 Sora 栈里的其他能力,都是围绕这个 job 模型向外扩展出来的。
开发者该注意的价格、模型与文档不同步
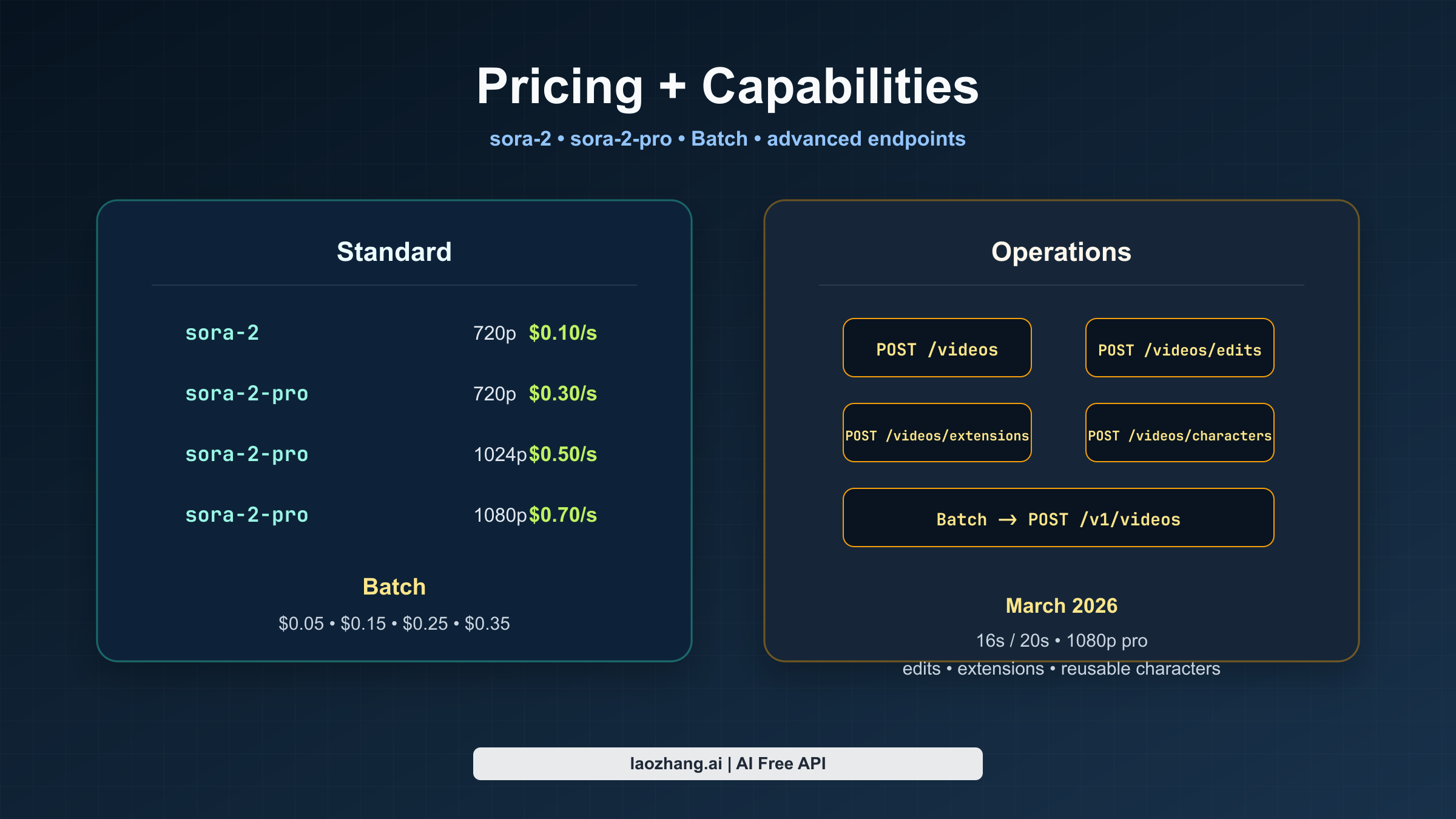
当前官方 pricing page 已经把模型分层说得很清楚。sora-2 更便宜、更快,适合迭代。sora-2-pro 输出更精致,也是你想拿到 1080p 成片时必须走的路线。
OpenAI 价格页当前给出的标准计费如下:
| 模式 | 模型 | 输出 | 官方价格 |
|---|---|---|---|
| Standard | sora-2 | 720x1280 或 1280x720 | $0.10/sec |
| Standard | sora-2-pro | 720x1280 或 1280x720 | $0.30/sec |
| Standard | sora-2-pro | 1024x1792 或 1792x1024 | $0.50/sec |
| Standard | sora-2-pro | 1080x1920 或 1920x1080 | $0.70/sec |
Batch 目前显示的是同一阶梯、价格减半:
| 模式 | 模型 | 输出 | 官方价格 |
|---|---|---|---|
| Batch | sora-2 | 720x1280 或 1280x720 | $0.05/sec |
| Batch | sora-2-pro | 720x1280 或 1280x720 | $0.15/sec |
| Batch | sora-2-pro | 1024x1792 或 1792x1024 | $0.25/sec |
| Batch | sora-2-pro | 1080x1920 或 1920x1080 | $0.35/sec |
这已经足够支撑大多数决策:
- 还在试 prompt,就先用
sora-2。 - 要做最终成片、画质更重要,就切到
sora-2-pro。 - 要离线批量渲染 shot list,Batch 的经济性已经足够值得认真评估。
更微妙、但对开发者更重要的一点是:OpenAI 当前的 Sora 文档存在局部不同步。这是基于当前官方资料做出的判断,不是猜测:
- 主视频指南写明
sora-2和sora-2-pro都支持16秒和20秒生成; - 2026 年 3 月 changelog 明确写了 Sora API 扩展到最长 20 秒,并支持 1080p
sora-2-pro; - 但一些较旧的 create reference 片段仍然只显示老的
4、8、12秒时长和更小的尺寸矩阵。
如果你要判断今天真正的能力边界,当前更安全的做法是:
当指南、价格页和 2026 年 3 月 changelog 与旧 reference 片段不一致时,优先信前者。
这个提醒值得单独写出来,因为它会直接影响你的分辨率选择、容量预估和对外产品文案。
官方 API 不止能做纯文本生视频
现在这套指南早就不只是一个 text-to-video 入口。OpenAI 当前的 Sora 栈已经覆盖了更完整的生成与迭代生命周期。
图片参考
你可以通过 input_reference 来引导生成,既可以在 multipart 请求里上传素材,也可以用包含 file_id 或 image_url 的 JSON 对象。OpenAI 把参考图描述为相当于视频的第一帧。最重要的约束是:参考图需要匹配目标 size,当前文档支持的格式是 image/jpeg、image/png 和 image/webp。
这让图片参考非常适合品牌资产、视觉风格控制,或者你更在意开场构图而不是跨多个任务复用角色的场景。
可复用角色
OpenAI 现在已经公开了 characters workflow,可以从上传视频里创建可复用的非人类角色资产。当前指南把 characters 定位为动物、吉祥物或物体的一致性工具,而且单次生成最多支持两个角色。指南还明确说明,带有人类外观的角色上传默认会被阻止,这一点很关键,因为它意味着这并不是一个通用的“训练真人演员”表层。
实际结论很简单:把 characters 用在可复用的非人类主体上,而不是拿它去绕过真人限制。
视频续写
OpenAI 现在已经提供了 video extensions,用来延续一个已完成的视频片段。当你要保持运动、镜头方向和场景连续性时,这才是正确路线;如果你只是想控制新视频的开场帧,那还是该用 input_reference。当前指南写明,每次 extension 最多可增加 20 秒、单个视频最多可延长 6 次,而且 extensions 不支持 characters 或 image references。
最后这点很重要。很多团队会默认“高级功能都能自由组合”,但当前契约并不是这样。
视频编辑
OpenAI 在 2026 年 3 月 changelog 中加入了 video edits workflow,现在它已经是对已有生成视频或上传视频做定向修改的首选路径。指南明确写到,旧的 remix 路线正在被弃用,而 edits 在你提出的修改范围越小、越明确时效果越好。
这说明 OpenAI 对 Sora 的定位,已经不再只是一次性生成器,而是在朝更完整的媒体迭代工作流走。
Batch
当前指南已经支持把 Batch 用于 POST /v1/videos,但有几个重要限制:
- Batch 目前只支持
POST /v1/videos。 - Batch 请求必须使用 JSON,不能用 multipart。
- 你需要提前上传素材,再在 JSON 中引用它们。
- Batch 生成的视频在 batch 完成后最多可下载 24 小时。
如果你在做离线渲染队列、工作室流程或者 shot-list pipeline,Batch 已经不是边缘功能,而是官方主路径的一部分。
在真正开工前必须知道的限制与坑
Sora 现在的限制已经足够多,所以你应该把策略和保留周期视为产品契约的一部分,而不是合规附注。
当前指南明确写出 API 会执行以下限制:
- 内容必须适合 18 岁以下观众;
- 受版权保护的角色和受版权保护的音乐会被拒绝;
- 不能生成真实人物和公众人物;
- 具有人类外观的 character 上传默认会被阻止;
- 含有人脸的输入图片目前会被拒绝。
如果你的预期工作流依赖其中任何一点,这不是“小边角案例”,而是需要重做路由设计。
存储模型同样重要。OpenAI 当前说明直接下载链接的有效期最长只有 1 小时。Batch 下载则在 batch 完成后保留最多 24 小时。这意味着,供应商托管的 URL 只能被视为临时交付资产,不能当作长期存储。在生产环境里,你应该把复制到自有对象存储当作完成流程的一部分。
延迟也不能忽略。指南写得很明确:单次渲染可能需要几分钟,具体取决于模型、负载和分辨率。这让后台任务、进度状态、重试机制和基于 webhook 的完成处理变成默认方案,而不是只有大企业才会需要的额外工程。
最后,访问与速率上限取决于 usage tier。OpenAI 的 Rate limits 指南 说明,组织会随着消费提升而进入不同 tier,并明确建议开发者以账号里的 Limits 页面为准查看当前生效上限。Sora 模型页也展示了与 tier 相关的上限,但当前搜索索引里的渲染信息过于简略,所以这里更安全的做法,是把读者引导到实时 Limits 页面,而不是根据半截数字做过度解释。
你到底该用 OpenAI 的哪个表层
如果你的真实目标是 做产品,答案就是 Videos API。
如果你的真实目标只是 手动生成几段视频,那 ChatGPT 或 Sora 应用可能反而更适合,因为你根本不用处理异步任务、存储和 webhook。
这个区分看起来很小,但它正是整个话题的解法。关于“OpenAI Sora API”的大量困惑,本质上来自人们先看了偏应用侧的 Sora 帮助内容,再看偏开发者侧的 Videos API 文档,然后误以为其中必有一个是错的。实际上,它们只是各自在回答不同问题。
对开发者来说,最短也最好的答案是:
有,OpenAI 现在已经提供官方程序化视频生成。你要接的是 Videos API,而不是消费级 Sora 产品表层。
FAQ
OpenAI 现在是否官方支持通过 API 使用 Sora 生成视频?
支持。官方开发者入口是 OpenAI 当前的 Videos API,文档在视频生成指南和 POST /v1/videos reference 中都已经给出。
为什么有些 OpenAI 页面还是让人感觉 Sora 没有 API?
因为那些官方页面谈论的仍然是 消费级 Sora 应用 / 编辑器,而不是开发者用的 Videos API。这正是当前搜索混乱的根源。
我应该先用哪个模型?
先用 sora-2 做提示词和镜头迭代。需要更高质量输出,尤其是 1080p 时,再切到 sora-2-pro。
1080p 现在是官方正式能力吗?
是。OpenAI 当前指南、价格文档和 2026 年 3 月 changelog 都写到了 1080p sora-2-pro,而 changelog 还明确说明 1080p sora-2-pro 按 $0.70/sec 计费。
只靠轮询可以吗?
做原型可以。做生产系统时,webhook 更干净,因为渲染可能持续几分钟,你不应该让轮询循环成为自己的常态控制平面。
我能不能先用 reusable characters,再继续 extension 同一个视频?
今天还不能把它们当成完全可组合工作流。当前指南明确写到,extensions 不支持 characters 和 image references,所以产品设计时必须把这条限制单独考虑进去。