
如果你现在要接 xAI 的实时语音能力,先别停在“它有没有 voice API”这种泛答案上。对开发者真正有用的公开入口,是 Grok Voice Agent API,端点是 wss://api.x.ai/v1/realtime。截至 2026 年 4 月 6 日,公开自助规格写的是 $0.05 / 分钟、每团队 100 个并发会话、以及单次 30 分钟。工程上最先要记住的不是宣传词,而是三件事:长期 API key 只放后端;浏览器或移动端要走 ephemeral token;如果你的任务只是把文本念出来,而不是做实时来回对话,就不要先上实时语音回路,直接走单独的 Text to Speech API。
“截至 2026 年 4 月 6 日,我对照了 xAI 当前的 Voice Agent 文档、价格与模型页、voice overview、TTS 文档、产品页和 release notes。2026 年 4 月 20 日 已补充 STT 边界:xAI 现在有独立 Grok STT 文档和端点。
先判断你到底要接哪条语音路
很多人一上来就把 “Voice Agent API / TTS / STT / 语音框架” 压成同一层,最后越看越乱。实际开发里,先分路比先背产品名更重要。
| 你的真实需求 | 现在更合适的路线 |
|---|---|
| 做实时、双向、低延迟语音对话 | Grok Voice Agent API |
| 只需要把文本生成语音播出来 | Text to Speech API |
| 真正卡住的是浏览器音频、电话接入、媒体转发、部署编排 | 现成语音框架或 telephony 路线 |
| 只需要普通语音转文字 | Grok STT API |
这样拆不是吹毛求疵,而是会直接影响你的架构。
如果产品要做 turn-taking、低延迟来回说话、会话内工具调用、电话智能体,Voice Agent API 才是正解。反过来,如果你的应用自己已经掌握完整状态机,最后只需要一个“把内容念出来”的步骤,TTS 更轻,也更容易估成本。
xAI 的产品页会提到 Speech to Text,而这条边界在本文首发后已经变化。到 2026 年 4 月 20 日,xAI 已经公开独立 Grok STT 路线:文件或音频 URL 用 POST https://api.x.ai/v1/stt,实时转写 用 wss://api.x.ai/v1/stt。它和 Voice Agent API 不是同一件事:STT 输出文本,Voice Agent API 运行实时双向语音会话。
所以先记一个最稳的分路:
- 需要实时语音会话,选 Voice Agent API
- 只需要一次性语音输出,选 TTS
- 只需要语音转文字,选 Grok STT;详细路线见 Grok STT API:端点、价格、实时转写和路线选择
一屏看懂今天能直接用的公开接入信息
| 你最先需要知道什么 | 当前公开答案 |
|---|---|
| 官方实时端点 | wss://api.x.ai/v1/realtime |
| 产品名 | Grok Voice Agent API |
| 公开自助价格 | $0.05 / 分钟(约 $3.00 / 小时) |
| 公开自助运行限制 | 每团队 100 并发会话,单次 30 分钟 |
| 浏览器安全鉴权 | 后端先签发 ephemeral token,再由客户端建连 |
| 第一次接入的默认做法 | 先把会话留在服务端跑通 |
| 最容易被忽略的费用 | 工具调用单独计费,不包含在分钟费里 |
| 只要语音输出时该走什么 | POST https://api.x.ai/v1/tts |
| 公开自助区域表述 | 当前价格/模型页写的是 us-east-1 |
| 从 OpenAI Realtime 迁移的结论 | 会话心智能借,但事件名和细节别默认完全一样 |
最快又安全的接入顺序
xAI 在这件事上写得比很多新 API 更直接。最小工作流就是:
- 连接
wss://api.x.ai/v1/realtime - 发送
session.update - 用
conversation.item.create创建用户消息 - 用
response.create触发响应
如果你准备先在可信后端跑第一版,最短的 JavaScript 路径大概是这样:
jsimport WebSocket from "ws"; const ws = new WebSocket("wss://api.x.ai/v1/realtime", { headers: { Authorization: `Bearer ${process.env.XAI_API_KEY}`, }, }); ws.on("open", () => { ws.send( JSON.stringify({ type: "session.update", session: { voice: "eve", instructions: "You are a helpful assistant.", turn_detection: { type: "server_vad" }, }, }), ); ws.send( JSON.stringify({ type: "conversation.item.create", item: { type: "message", role: "user", content: [{ type: "input_text", text: "Hello!" }], }, }), ); ws.send(JSON.stringify({ type: "response.create" })); });
这条做法最适合第一天,是因为鉴权边界最清楚:真实 key 在你后端,socket 会话也在你后端。你可以先验证 event 流、语音返回、工具调用和 session 生命周期,再决定要不要往浏览器录音、WebRTC、电话路由,或者更复杂的媒体编排扩。
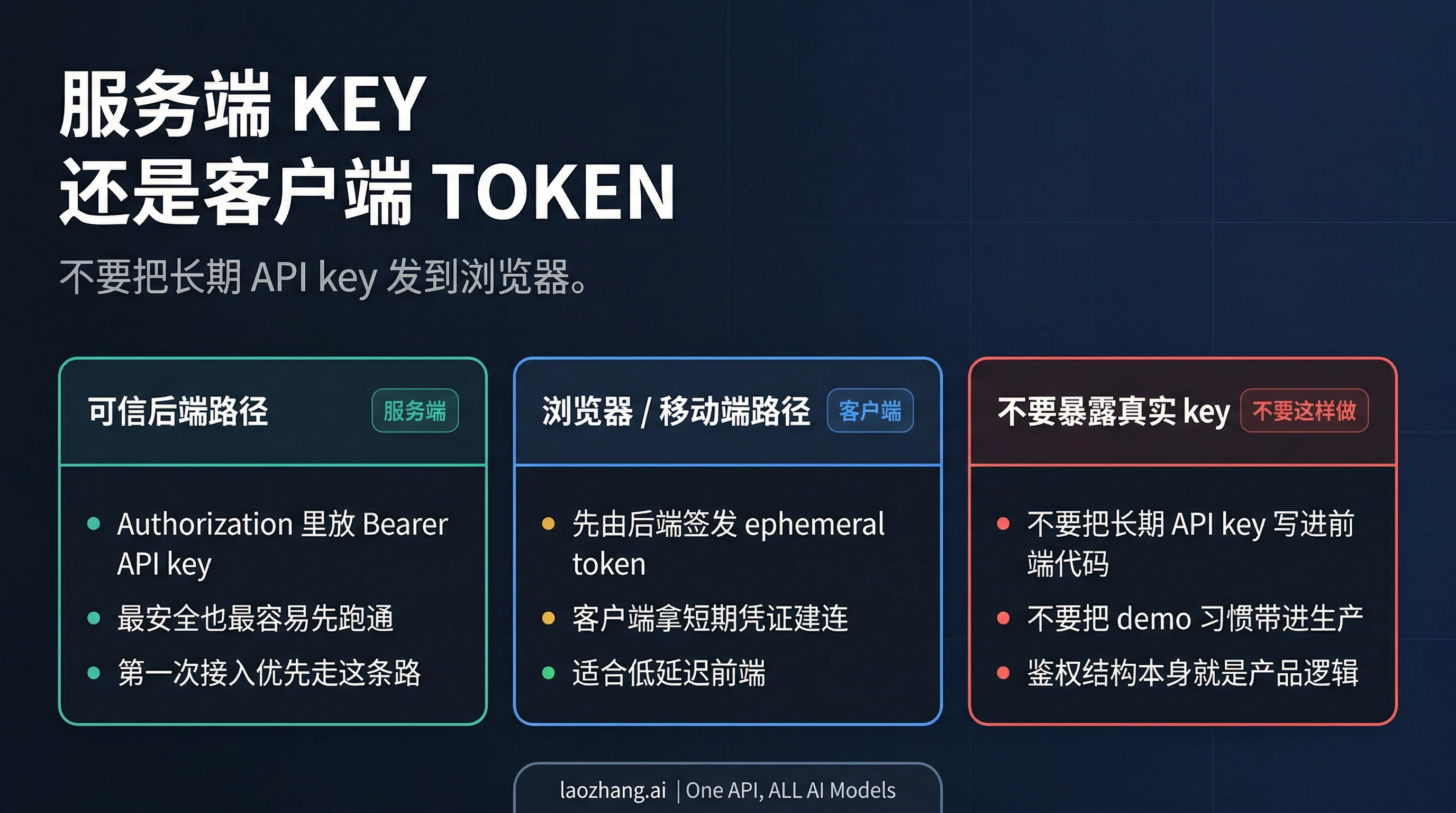
真正常见的坑,不是“连不上”,而是团队在“服务端能跑”之后,直接把同一把长期 key 发到浏览器。xAI 自己的文档已经把这件事写得很死:客户端应用应该用 ephemeral token。公开路由就是 POST https://api.x.ai/v1/realtime/client_secrets。后端负责签发短期凭证,前端再拿这 个 token 去建实时连接,而不是暴露长期 API key。xAI 还明确写了浏览器里会通过 sec-websocket-protocol 传 xai-client-secret. 前缀。
这可以压成一句部署规则:
- 第一次接入:后端优先,最安全也最容易排错
- 浏览器或移动端直连:前提是你已经有后端签发 ephemeral token
另外几条早期就值得知道的运行默认值,也别等踩坑才回来看:
- 自动 turn 检测的默认模式是
server_vad - 默认 PCM 音频是
24 kHz - 支持的音频格式包括
audio/pcm、audio/pcmu和audio/pcma - 当前公开 voices 包括
eve、ara、rex、sal和leo
这些不是“有空再调的参数”。它们说明这条 API 从一开始就更像给真实语音产品准备的接入面,而不是只能演示一句话的玩具接口。
费用怎么估:分钟费只是底价,工具另算
把公开资费压成最短答案,其实很简单:
| 项目 | 当前公开自助规格 |
|---|---|
| 会话分钟费 | $0.05 / 分钟 |
| 折算小时费 | $3.00 / 小时 |
| 并发会话 | 每团队 100 |
| 单次会话上限 | 30 分钟 |
| 公开自助区域 | us-east-1 |
问题在于,很多人看到这里就停了。真正会影响预算的,不只是分钟费,而是工具调用另算。
只要你的语音智能体在会话里触发 function calling、web search、X search、collections,或者 MCP-backed tools,这些都不包含在 $0.05 / 分钟 里。分钟费只是会话底价,不是完整账单。
举一个足够直观的例子。10 分钟实时语音会话,按公开分钟费大约是 $0.50。如果同一次会话里再触发 20 次 web_search,而当前公开工具价格是 $5 / 1,000 调用,那么这部分会额外增加大约 $0.10。绝对值不算惊人,但它会直接改变你对这类产品的判断:你做的到底是“语音产品”,还是“带音频 I/O 的检索智能体”。
当前公开工具价格至少包括:
web_search:$5 / 1,000调用x_search:$5 / 1,000调用code_execution:$5 / 1,000调用collections_search/file_search:$2.50 / 1,000调用
另一个很容易被写平的点,是区域与基础设施表述。公开价格页把自助接入区域写成 us-east-1。与此同时,产品页又会提到多区域基础设施和定制速率限制。这两个说法不是同一层承诺。面向开发者的公开自助接入,你应该先以价格/模型页的表述为准;更宽的基础设施表述,更像企业销售层能力,而不是所有账号默认享有的条件。
因此,第一道预算问题不该是“用户平均会讲几分钟”,而应该是:“一次会话平均会触发多少工具,这些调用到底是不是每一轮都必须发生?”

这条接口已经够做真实语音产品,但别提前脑补不存在的能力
如果只在产品页和几篇介绍文之间来回看,Voice Agent API 很容易显得“什么都支持”或“只是会说话”两种极端。更有用的读法是:它已经足够覆盖一批真实 workload,而且这些能力不是边缘功能。
当前公开文档明确写到的能力至少包括:
- 通过 WebSocket 进行实时双向语音会话
- 多个内置 voice
server_vadturn handling- 多种音频格式,包括电话场景常见的
μ-law与A-law web_search、x_search、file_search、remote MCP tools 和 custom functions- OpenAI Realtime API 兼容入口
这已经足以支撑浏览器语音助手、电话智能体、支持工单流、检索增强语音界面,以及 operator copilot 这类产品。这里真正要抓住的不是“支持多少功能点”,而是两条更有用的判断。
第一,工具能力是主路径的一部分。
这条接口不是只会“把一句话用声音念出来”。如果你的产品在会话中需要检索、内部知识库、函数调用或远程工具,xAI 已经把它写成标准路径,而不是实验功能。
第二,公开开发者入口仍然要分层看。
Voice Agent API、TTS 和 STT 现在都需要分开读。Voice Agent API 是实时语音会话;TTS 是一次性语音输出;Grok STT 是语音转文字。写文章或做架构时,如果把三者都叫成“语音 API”,会把会话、输出和转写混成一层。
所以更稳的结论不是“xAI 语音全家桶都能直接接”,而是:
- 实时语音对话,今天可以按 Voice Agent API 开发
- 一次性语音输出,今天可以按 TTS 开发
- STT 走独立 Grok STT API,不要把它当成 Voice Agent API 的附属功能
从 OpenAI Realtime 迁过来,先改这些地方
xAI 的兼容说明,确实是它比很多人想象中更容易接近的原因。但它不该被压缩成一句“drop-in compatible”。更准确的结论是:
- 会话心智模型可以沿用。 你仍然在处理有状态的实时会话、流式事件、工具调用和实时音频。
- 端点需要换。 你的核心入口变成
wss://api.x.ai/v1/realtime。 - 事件名存在差异。 比如
response.output_text.delta与 xAI 的response.text.delta就不是同一套命名。 - 有些事件没有。 xAI 文档明确列出了诸如
conversation.item.retrieve、conversation.item.truncate等未支持或缺失的事件。
这段内容真正的价值,不是做品牌对比,而是减少第一天的迁移误判。如果你的代码库已经有 Realtime client 架构,那确实能借很多结构;但第一次生产验证时,你应该重点验证 event handling,而不是只看 socket 能不能连上。
什么时候该从原始接口切到现成语音框架
很多文章会把“用原始 API”与“上框架”写成孰优孰劣。现实里,这更像一个时机问题。
如果你的产品核心难点还在:
- 能不能先把实时会话跑通
- 鉴权边界怎么做对
- 工具调用和成本结构怎么估
那么直接用原始 Voice Agent API 往往更好。它已经足够让你验证价值,不需要一开始就往更重的媒体栈跳。
只有当团队真正卡住的是这些问题时,现成语音框架才开始更值钱:
- 浏览器音频采集和回放链太复杂
- 电话接入、号码路由和媒体转发成了主难点
- WebRTC、telephony 或部署拓扑开始比原始 socket 更耗团队时间
xAI 的 voice overview 里已经把 LiveKit、Twilio、WebRTC 和 telephony examples 放进生态路径里。这个信号本身就很明确:当真正的瓶颈从“接 xAI”变成“管媒体和编排”时,框架才是下一步。
所以更实用的分工是:
- Voice Agent API:实时语音对话本身就是产品
- TTS API:你只需要一次性语音输出
- 现成语音框架:媒体编排、电话接入或部署复杂度已经压过原始接口接入

FAQ
Grok Voice Agent API 的准确端点是什么?
使用 wss://api.x.ai/v1/realtime。
公开自助价格现在是多少?
当前公开自助价格写的是 $0.05 / 分钟,折算约 $3.00 / 小时。但工具调用另算。
浏览器里能直接接吗?
可以,但安全路线不是把长期 API key 放进前端,而是后端先签发 ephemeral token,再由客户端使用短期凭证建连。
Grok Voice Agent API 和 xAI 的 TTS API 是一回事吗?
不是。Voice Agent API 是实时双向语音会话的 WebSocket 接口;TTS API 是一次性语音生成的 REST 接口。
Voice Agent API 支持工具吗?
支持。当前公开文档列出了 web_search、x_search、file_search、remote MCP tools 和 custom function tools。
xAI 现在有公开自助的 Speech to Text API 吗?
有。按 2026 年 4 月 20 日核对,独立 Grok STT 已有公开 REST 和 WebSocket 路线:文件转写用 POST https://api.x.ai/v1/stt,实时转写 用 wss://api.x.ai/v1/stt。本文仍只负责 Voice Agent API 的实时语音会话路线。
当前公开运行限制是什么?
公开价格/模型页写的是每团队 100 并发会话,以及单次 30 分钟的会话上限。
结论
“Grok Voice Agent API” 这个问题真正有价值的答案,不只是“它现在有 API 了”。更重要的是:xAI 当前给开发者的实时语音入口已经足够明确,可以直接开始接入,但你必须一开始就把三件事分清楚:准确 WebSocket 端点、服务端 key 与客户端 token 的鉴权边界,以及分钟费之外的工具额外计费。如果你做的确实是实时语音产品,这条 Voice Agent API 就是正确起点;如果你只需要一次性语音输出,直接走 TTS 更省事;如果真正的难点已经转成媒体编排和电话接入,再考虑上现成语音框架。