
GPT-OSS 120B 按本地干净运行来规划,应该先把它当成 80GB GPU 显存级模型。>=60GB 可以是某些运行时的受限加载门槛,60.8 GiB 是 checkpoint 文件层面的事实,但二者都不能替代上下文缓存、运行时缓冲、batch、并发和 offload 带来的额外内存。
| 硬件路径 | 这个内存数字真正表示什么 | 适合的场景 | 该停止的信号 |
|---|---|---|---|
| 80GB GPU | 干净的一卡运行目标 | 想少踩坑地评估或部署 120B | 仍然要给上下文和 batch 留余量 |
| >=60GB 显存或统一内存 | 受限运行时门槛 | 明确知道运行时、上下文和 batch 都很小 | 不要把它当生产余量 |
| 96GB+ 或多 GPU | 操作余量路线 | 需要长上下文、稳定吞吐或较少 OOM | 部署前验证切分和 KV cache |
| 24GB 消费级 GPU 加 offload | 实验路线 | 目标就是验证能否加载 | OOM 或速度不可用就换路线 |
| GPT-OSS 20B 或托管/API | 回退路线 | 本地硬件低于 120B 门槛 | 先换模型或路线,不要继续硬调 |
为什么 60.8 GiB、>=60GB 和 80GB 不是同一件事
中文硬件讨论里最容易误导人的地方,是把三个不同层级压成一个数字。第一个层级是模型文件。OpenAI 模型卡写明 GPT-OSS 120B 的 MXFP4 checkpoint 大约是 60.8 GiB,总参数约 116.83B,活跃参数约 5.13B。这个数字说明权重文件为什么比传统 dense 120B 小很多,也说明下载、缓存、格式转换和磁盘工作区都要预留足够容量。但它不是运行时显存预算,更不能替代 KV cache、上下文和服务框架的活动内存。
第二个层级是运行时加载门槛。OpenAI Cookbook 中 Transformers、vLLM、Ollama 的运行路线会提到 >=60GB VRAM,或者 >=60GB VRAM / unified memory。这个门槛依赖后端、量化格式、上下文长度和 batch 设置。它回答的是“某个栈能不能加载并开始跑”,不是“这台机器能不能稳定服务真实任务”。
第三个层级是更稳的操作目标。OpenAI 发布文写的是 GPT-OSS 120B 可以在 80GB 内存内运行,Hugging Face 也把它描述为可以放进单张 80GB GPU,例如 H100 或 MI300X。对于要买卡、租卡、安排服务器的人,80GB 才是更可靠的一句话答案。低于这个数字时,问题就不再是简单的“能不能运行”,而是“愿不愿意承受上下文、速度、offload 和 OOM 风险”。

这三个数字并不矛盾。60.8 GiB 是文件事实,>=60GB 是受限加载事实,80GB 是更干净的硬件规划事实。把它们混成一个要求,最常见的后果是用 64GB 或 24GB 机器去追一个本来应该换路线的问题。
先用官方事实定边界
GPT-OSS 120B 的硬件判断要以一手资料为主,社区帖和视频只能作为实验参考。
| 事实 | 证据归属 | 对硬件决策的意义 |
|---|---|---|
| GPT-OSS 120B 可以在 80GB 内存内运行 | OpenAI 发布文 | 80GB 是干净的一卡目标 |
| GPT-OSS 20B 面向 16GB 内存 | OpenAI 发布文 | 20B 是低内存机器的现实回退 |
| 60.8 GiB checkpoint | OpenAI 模型卡 | 文件大小不是完整运行余量 |
| >=60GB VRAM 或统一内存路线 | OpenAI Cookbook | 存在受限运行门槛,但需要实测 |
| 单张 80GB GPU 表述 | Hugging Face 模型页与 MXFP4 文档 | 80GB GPU 是更稳的本地计划 |
OpenAI 的 GPT-OSS 发布文、模型卡 PDF、Transformers 指南、Ollama 指南和 vLLM 指南,是内存数字和运行路径的主要证据。Hugging Face 的 openai/gpt-oss-120b 模型页与 MXFP4 文档,解释了为什么这个 120B 级模型能被压进 80GB 级别,而不是传统未压缩权重所需的数百 GB。社区经验有价值,但它通常回答“某人怎样让它在某台机器上动起来”,不应该变成给所有人的采购建议。
运行路线要先于调参
如果你先决定运行路线,显存要求会变得清楚得多。
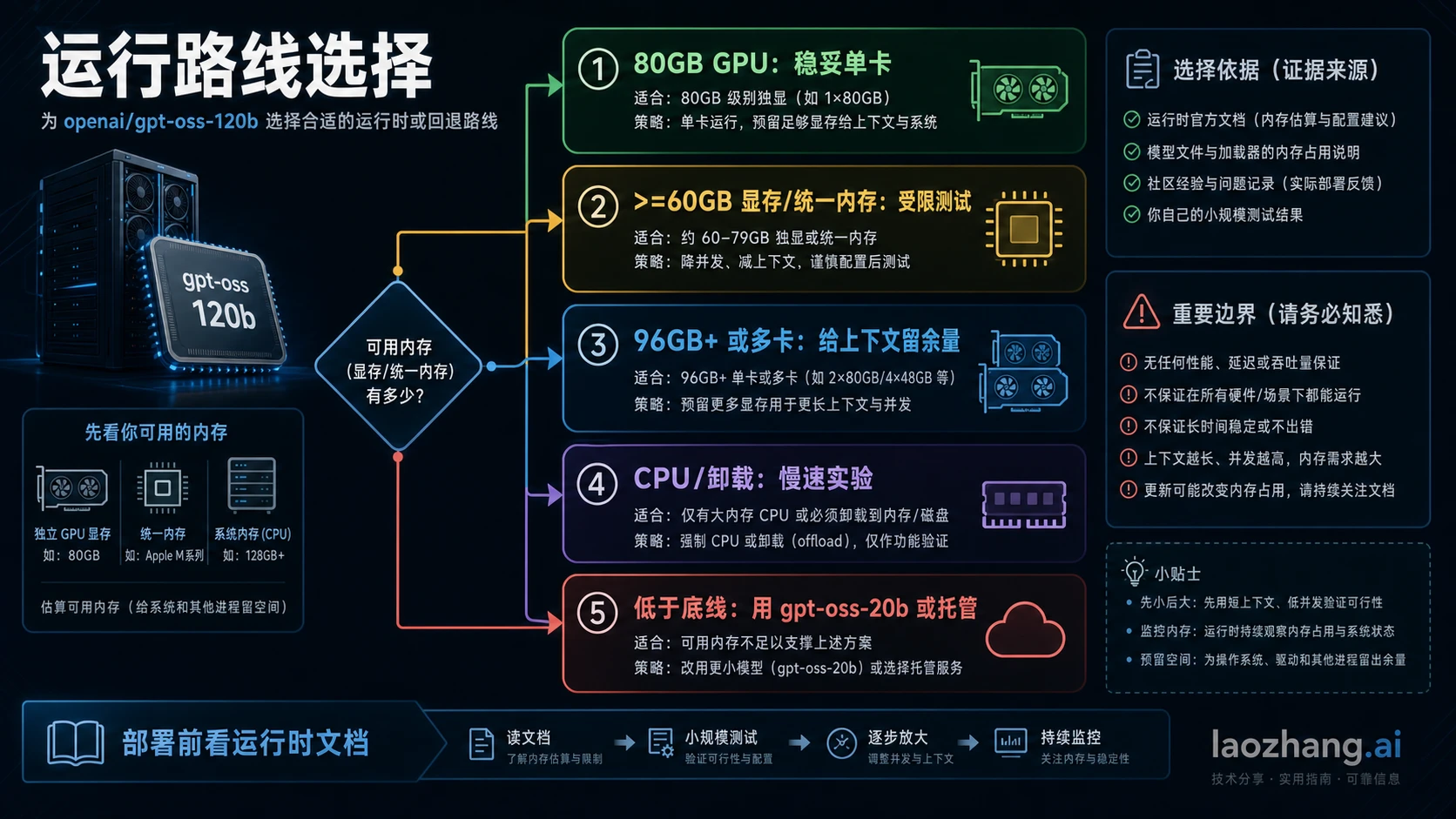
| 路线 | 内存姿态 | 最适合的用途 | 主要风险 |
|---|---|---|---|
| 80GB GPU 上的 Transformers | 干净本地路线 | 开发、评估、小规模服务测试 | 长上下文和 batch 仍会吃余量 |
| 80GB 或多 GPU 上的 vLLM | 服务化路线 | 更高吞吐、并发、API 实验 | KV cache 和并发会抬高真实需求 |
| Ollama 的 >=60GB 显存或统一内存 | 低门槛本地路线 | 工作站、Mac/统一内存或轻量体验 | offload 后速度可能很慢 |
| 96GB+ 工作站或多 GPU | 余量路线 | 长上下文、稳定吞吐、多用户评估 | 切分、驱动和后端复杂度更高 |
| 24GB GPU 加 CPU offload | 实验路线 | 学习运行栈、证明可以加载 | token 速度和上下文可能不可接受 |
| GPT-OSS 20B | 小模型回退 | 16GB 到 24GB 机器、本地快速试验 | 能力和 120B 不同 |
| 托管/API | 不承担本地内存 | 产品集成、快速验证功能 | 成本、限额、可用性替代显存问题 |
如果目标是学习模型行为,受限路线可以尝试;如果目标是给团队或产品提供稳定能力,应该从有余量的路线开始。中文读者尤其容易被“8GB 也能跑”“24GB 也能跑”的案例吸引,但这些案例多数是证明加载、量化或 offload 的技巧,不等于工作负载可用。
显存、统一内存、系统内存和磁盘要分开说
显存是 GPU 专用内存。H100 80GB、A100 80GB、MI300X 这类讨论,说的通常是模型权重、KV cache 和运行时缓冲能否主要留在加速器侧。对需要速度和稳定性的任务,这是最重要的内存。
统一内存是 CPU 和 GPU 共享的内存池。Apple Silicon 或某些加速平台可能用它让大模型加载起来,但统一内存不等于无限显存。带宽、后端支持、层迁移、上下文长度都会影响速度和稳定性。统一内存路线应该被看作“可以实验和特定工作流可用”,而不是把 80GB GPU 需求直接取消。
系统内存主要在 CPU offload 或混合推理中发挥作用。它能让模型权重的一部分不在显存里,但通常用速度换空间。磁盘则负责存放 checkpoint、tokenizer、转换格式和缓存。60.8 GiB 的 checkpoint 意味着下载和存储要留余量,但磁盘够不代表运行时内存够。
最后还有 KV cache、runtime buffer、batch、并发和上下文长度。模型能用短 prompt 加载成功,不代表能承受长上下文、多轮对话、并发请求或服务框架。很多 OOM 不是发生在下载阶段,也不是发生在最小 smoke test,而是发生在真实工作负载第一次拉长时。
按硬件档位做决定
80GB 加速卡是最直接的档位。如果你有 H100 80GB、A100 80GB、MI300X 或等价 80GB 级路线,并且运行时明确支持,就可以把 GPT-OSS 120B 当作本地评估和轻量服务的合理目标。仍然要检查驱动、CUDA/ROCm、模型格式、上下文长度和 batch,但你不再站在最窄的加载门槛上。
60GB 到 79GB 是测试档位。它可能在特定运行时、特定量化、特定上下文设置下跑起来,但不应该直接写进生产承诺。这个档位适合做模型评估、短上下文测试、离线分析和内部实验。只要出现“每次多一点上下文就 OOM”“只能单请求跑”“速度不稳定”,就说明它不是业务路线。
96GB+、多 GPU 或云 GPU 是余量档位。它更贵,也更需要处理分片、通信、驱动和服务框架,但当失败成本高于硬件成本时,余量就是必要条件。长上下文、多用户、批量评测、RAG 管线和持续服务,都应该优先看这个档位。
16GB 到 24GB 消费级显卡是回退或实验档位。它适合跑 GPT-OSS 20B,也适合学习 Ollama、Transformers、量化和 offload 的行为。它不适合被宣传成 GPT-OSS 120B 的干净路线。哪怕你找到了能加载 120B 的配置,也要把结果标成实验,而不是告诉别人“这张卡够了”。
4090、3090、5090 这类消费级卡怎么判断
RTX 4090 和 RTX 3090 的常见问题是:24GB 显存能不能跑 GPT-OSS 120B。答案应该分成两句。第一句:不能作为纯 GPU 驻留的干净 120B 路线。第二句:可以尝试 offload、低上下文、CPU/系统内存、量化和特定后端,但那是实验,不是推荐配置。
5090 或后续消费级卡也要看实际显存。只要显存仍明显低于 60GB 到 80GB 区间,就不能因为代际更新而自动进入干净路线。算力更强不等于显存足够;显存不足时,瓶颈会从矩阵计算变成权重搬运、缓存、上下文和带宽。
可以用下面的停止规则保护时间:
- 如果模型加载阶段反复 OOM,停止调参,换 20B、云 GPU 或多 GPU。
- 如果能加载但 token 速度低到无法完成工作,停止把它当可用路线。
- 如果只能短上下文运行,不要把它用于需要长上下文的任务。
- 如果需要服务并发,不要把 CPU offload 当主要可用性来源。
- 如果继续尝试只是为了好奇,就在记录中明确写成实验结果。
这不是否定社区探索。相反,实验值得保留,但实验和采购建议要分开。一个截图能说明“我让它动起来了”,不能说明“别人应该按这个硬件买机器”。
上下文长度和 batch 才是真正的余量测试
判断一台机器是否“够”,不能只看模型能否加载。真正的测试应该包含计划使用的上下文长度、batch、大概并发、实际 prompt 结构、工具调用或 RAG 输入长度。GPT-OSS 120B 的长上下文能力会让 KV cache 持续吃内存,服务框架还会为了吞吐预留缓存。一个短 prompt 的成功样本不能代表生产。
实测时至少记录这些内容:运行时名称和版本、模型文件或量化格式、GPU 型号和显存、系统内存、驱动和后端、上下文长度、batch、并发、加载后显存、推理中峰值显存、tokens/sec、是否有 offload、是否出现 OOM 或速度塌陷。没有这些信息的“能跑”,只能当故事,不能当决策依据。
如果你的设置只有在最小上下文、单请求、无并发、强制 offload、关闭所有余量时才成功,它就是演示路线。演示路线可以用于学习和内部评估,但不应该进入服务承诺、客户交付或团队采购清单。
什么时候应该换 20B、云 GPU 或 API
GPT-OSS 20B 的存在很实际。OpenAI 把它放在 16GB 级内存目标上,说明低内存本地体验不必强行挤 120B。对个人笔记本、消费级台式机、离线工具、小规模内部测试,20B 往往能更快进入可用状态。能力不同,但稳定性和时间成本经常更重要。
云 GPU 或多 GPU 适合短期评估 120B 是否值得长期拥有硬件。与其在 24GB 卡上调一整天 offload,不如租一次合适的 80GB 或更高配置,把模型质量、上下文表现和速度先测清楚。托管/API 路线适合产品集成者,它去掉本地显存问题,但会引入账号、限额、成本、可用性和数据边界问题。
可以按目标选择:
| 真实目标 | 更合适的路线 |
|---|---|
| 学习 120B 在本机上怎么加载 | 受限或 offload 实验,但明确标注 |
| 建可靠本地流程 | 80GB+、96GB+ 或多 GPU |
| 只有 16GB 到 24GB 机器 | 先用 GPT-OSS 20B |
| 快速验证产品功能 | 托管/API,并管理成本和限额 |
| 比较回答质量再决定采购 | 短租合适 GPU,不要用错误硬件硬猜 |
常见问题
GPT-OSS 120B 到底需要多少显存?
干净本地答案是 80GB GPU 显存。>=60GB 可以是某些运行时的受限门槛,但需要用你的上下文长度、batch 和后端实测。
60.8 GiB checkpoint 能不能放进 64GB 显卡?
不能这样判断。60.8 GiB 是权重文件层面的数字,运行时还需要 KV cache、缓冲区、上下文和框架开销。
4090 或 3090 能不能运行?
不能作为干净 GPU 驻留路线。可以做 offload 实验,但速度、上下文和稳定性都要重新评估。
5090 能不能运行?
看实际显存和运行时支持。如果显存仍远低于 60GB 到 80GB,它仍属于实验档。
系统内存要多少?
系统内存对 CPU offload 和统一内存有帮助,但不能和显存一比一替代。关键是运行时是否能在真实上下文和速度要求下工作。
磁盘要准备多少?
至少要容纳 60.8 GiB checkpoint、tokenizer、缓存、转换格式和操作余量。磁盘比显存容易解决,但也不能只按一个文件大小卡死。
该用 vLLM、Transformers 还是 Ollama?
开发评估优先 Transformers,服务实验看 vLLM,低门槛本地体验可以看 Ollama。无论哪条路,都要记录后端、模型格式、上下文和峰值显存。
什么时候该停止折腾 120B?
当它只能短上下文、反复 OOM、速度不可用或必须依赖重度 offload 才能工作时,就该换 20B、云 GPU、多 GPU 或托管/API。