
如果你说的 “Gemini 3.1 Flash Live API” 指的是 Google 新推出的实时语音模型,那么你真正要用的官方模型是 gemini-3.1-flash-live-preview,接口面则是 Gemini Live API。这件事看似只是命名细节,但它决定了你会不会一开始就走错路。因为 Google 把有用的信息拆散在多个页面里:有 模型页、Live API 总览、能力说明页、价格页、ephemeral token 指南,还有 2026 年 3 月 26 日的官方发布文章。
先给结论:如果你今天要新做一个低延迟语音智能体,优先从 Gemini 3.1 Flash Live 开始。 但不要把它理解成 gemini-2.5-flash-native-audio-preview-12-2025 的无痛升级。Google 的确提升了语音质量、实时对话能力和输出上限,但它同时改掉了 thinking 配置、服务端事件结构、增量输入方式,以及工具调用行为。如果你当前的 2.5 架构依赖异步函数调用、proactive audio 或 affective dialog,盲迁只会先把你的产品体验搞坏。
“证据说明:本文基于 Google 官方开发者文档与官方发布文章,已在 2026 年 3 月 28 日 重新核对。凡是 Google 自己公开页面存在冲突或没有写死的地方,我都会保留不确定性,而不是用记忆补齐。
TL;DR
| 你最先需要知道什么 | 当前答案 |
|---|---|
| 准确模型 ID | gemini-3.1-flash-live-preview |
| 准确接口面 | Gemini Live API,底层是有状态 WebSocket 连接 |
| 上线日期 | 2026 年 3 月 26 日 |
| 最适合的新场景 | 需要低延迟、多模态感知、语音质量更自然的实时语音智能体 |
| 默认建议 | 新项目优先从 3.1 开始 |
| 还应该留在 2.5 的主要原因 | 你还需要异步工具调用、proactive audio 或 affective dialog |
| 最大迁移变化 | thinkingBudget 变成 thinkingLevel;单个服务端事件可能同时包含多个 part;实时更新应使用 send_realtime_input;工具调用目前只有同步模式 |
| 价格形态 | text 输入 $0.75 / 1M tokens,audio 输入 $3 / 1M tokens 或 $0.005 / 分钟,image/video 输入 $1 / 1M tokens 或 $0.002 / 分钟,text 输出 $4.50 / 1M tokens,audio 输出 $12 / 1M tokens 或 $0.018 / 分钟 |
| 浏览器安全接入 | 后端签发 ephemeral token,再让前端直连 |
| 隐蔽坑点 | 默认 turn coverage 会把所有视频帧都算进去,连续推流很容易额外烧钱 |
Google 在 2026 年 3 月 26 日到底发布了什么
Google 的发布文章把 Gemini 3.1 Flash Live 定位为最新的实时音频模型,并明确写了开发者可以通过 Gemini Live API 在 Google AI Studio 中以 preview 方式使用它。模型页则把这件事说得更具体:模型代码是 gemini-3.1-flash-live-preview,支持 text、images、audio、video 输入,核心目标是低延迟实时对话,强调 acoustic nuance detection、numeric precision、multimodal awareness。
这不是一个单独的 “Gemini 3.1 Flash Live API” 产品。准确的说法是:Gemini Live API 是实时交互接口面,而 Gemini 3.1 Flash Live 是运行在这个接口面上的一个模型。Live API 自己是一个有状态的 WebSocket 会话,适合连续媒体流、打断、实时 turn 处理,并不是普通 generateContent 那种一次请求一次响应的调用形态。
这也是为什么它不应该被理解成“只是一个语音模型”。官方文档写得很清楚:它支持 function calling 和 Google Search grounding。这意味着它的设计目标不是单纯把文字念出来,而是做一个能听、能看、能推理、能调工具、能实时回应的 voice-ready agent。模型页还写了 2025 年 1 月 的知识截止日期,所以如果你的语音智能体需要最新信息,就应该主动接入搜索或你自己的检索层,而不是默认相信模型本身知道一切。
这里有两个容易被忽略的技术细节。第一,模型页写的是 text 和 audio output,但 Live API capabilities 页又写 native audio models 只支持 AUDIO response modality。更稳妥的工程解读是:如果你需要可读文本,不要把它当成普通文本模型来用,而是应该按 Google 的建议启用 output audio transcription。第二,Google 发布文中写明 所有由 3.1 Flash Live 生成的音频都带 SynthID 水印。如果你做的是面向用户的语音产品,这不是边角信息,而是产品合同的一部分。
新项目该直接上 Gemini 3.1 Flash Live 吗,还是继续留在 2.5?
对于新项目,Gemini 3.1 Flash Live 是更合理的默认起点。Google 自己的发布文章已经把它写成了最新、最高质量的实时语音模型,而模型页中的迁移说明也明显是在引导大家从 gemini-2.5-flash-native-audio-preview-12-2025 往 3.1 迁移。但“应该迁移”不等于“它是 2.5 的严格超集”。
真正决定你该不该迁的,不是发布会措辞,而是你当前系统有没有依赖 2.5 仍然具备、但 3.1 暂时还没有的能力。所以最重要的不是听官方说“质量更好了”,而是先看迁移表。
| 实际差异 | Gemini 3.1 Flash Live | Gemini 2.5 Flash Live |
|---|---|---|
| 模型 ID | gemini-3.1-flash-live-preview | gemini-2.5-flash-native-audio-preview-12-2025 |
| 发布时间 / 最近更新 | 2026-03-26 发布 | 2025-09 最近更新 |
| 输出 token 上限 | 65,536 | 8,192 |
| thinking 控制 | thinkingLevel,可选 minimal、low、medium、high | thinkingBudget |
| 服务端事件结构 | 一个事件里可能同时出现多个 part | 每个事件只有一个 part |
| 实时文本更新 | send_client_content 只适合初始历史;实时交互用 send_realtime_input | 对话过程中可继续用 send_client_content |
| 默认 turn coverage | TURN_INCLUDES_AUDIO_ACTIVITY_AND_ALL_VIDEO | TURN_INCLUDES_ONLY_ACTIVITY |
| 异步函数调用 | 不支持 | 支持 |
| proactive audio | 不支持 | 支持 |
| affective dialog | 不支持 | 支持 |
| 当前最适合谁 | 新做的语音智能体,或者优先追求最新语音质量的团队 | 现有 2.5 系统,而且真的依赖这些 2.5 特有能力 |
这个表真正有价值的地方,在于它一眼就能看出两件事。
第一,3.1 在“实时对话质量”这个核心问题上确实更强。
Google 在发布文里给出了更自然的语音表现、对音色和节奏的更好理解、以及更强的复杂任务处理能力。再加上输出 token 上限从 8,192 提高到 65,536,3.1 的确更像是下一代默认起点。
第二,3.1 还不是所有现有 2.5 生产流的理想替身。
如果你之前在 2.5 上依赖 behavior: NON_BLOCKING 之类的异步工具行为,让模型在工具还没返回时继续说话,那么这个模式目前在 3.1 上是没有的。Google 的 capabilities 文档写得很明确:Gemini 3.1 Flash Live 目前只有同步工具调用。同样,如果你的产品体验建立在 proactive audio 或 affective dialog 上,这些 2.5 有、3.1 暂时没有的功能,都会直接影响迁移收益。
所以结论很简单:
- 从零开始的新项目:直接用 3.1。
- 已经在线的 2.5 系统:先确认同步工具调用、事件结构变化、以及 2.5 独有功能缺失是否能接受,再决定是否迁移。

这次的价格终于足够“可运营化”
Google 这次的价格页有一个很重要的优点:它同时给了 按 token 计费 和 按分钟计费 两种视角。对于普通文本模型,大家往往只能拿 token 粗估。但对于实时语音产品,团队实际更关心的是一通电话、一次会话、一个语音工作流到底多少钱。按分钟价格因此更接近真实决策。
| 计费项 | 当前付费价格 |
|---|---|
| Text input | $0.75 / 1M tokens |
| Audio input | $3.00 / 1M tokens 或 $0.005 / 分钟 |
| Image/video input | $1.00 / 1M tokens 或 $0.002 / 分钟 |
| Text output | $4.50 / 1M tokens |
| Audio output | $12.00 / 1M tokens 或 $0.018 / 分钟 |
| Google Search grounding | Gemini 3 共享每月 5,000 个免费 prompts,之后 $14 / 1,000 搜索查询 |
这让你可以很快做出比 “它看起来不贵” 更靠谱的判断。假设你的语音会话里,输入音频和输出音频都持续流动,那么按官方的分钟价格直接相加,每分钟大约是 $0.023。也就是说,一通 10 分钟的双向语音会话,大约是 $0.23 的纯音频成本。这不是 Google 原文里的现成句子,而是根据 $0.005 / 分钟 的输入音频价格和 $0.018 / 分钟 的输出音频价格直接算出来的。
Search grounding 是另一条经常被低估的成本线。免费共享额度之后,$14 / 1,000 查询意味着每次 grounded query 大约 $0.014。如果一次实时语音会话中触发 5 次搜索,就要多出大约 $0.07。绝对值不算夸张,但一旦你做的是高频客服、陪练或语音助手,这会成为真实的成本差异。
更危险的其实不是搜索,而是视频。Google 的 3.1 迁移说明里写得很清楚:默认 turn coverage 现在会包含 所有视频帧,不再只是“检测到活动的部分”。如果你过去在 2.5 上习惯了持续把摄像头画面推过去,但真正的核心交互其实是语音,那么 3.1 很可能会在你没注意时多计很多 image/video 输入。
另一个需要克制的点是限额。Google 在公开的 rate-limits 页面没有把 Gemini 3.1 Flash Live 的精确 RPM / RPD 静态写死,而是要求开发者去 AI Studio 查看当前项目的 active rate limits。同时它也明确提醒 preview 模型通常限制更紧。所以正确做法不是在文章里硬写一个看起来整齐的数字,而是:价格看公开文档,容量看你自己 AI Studio 里的当前配额。
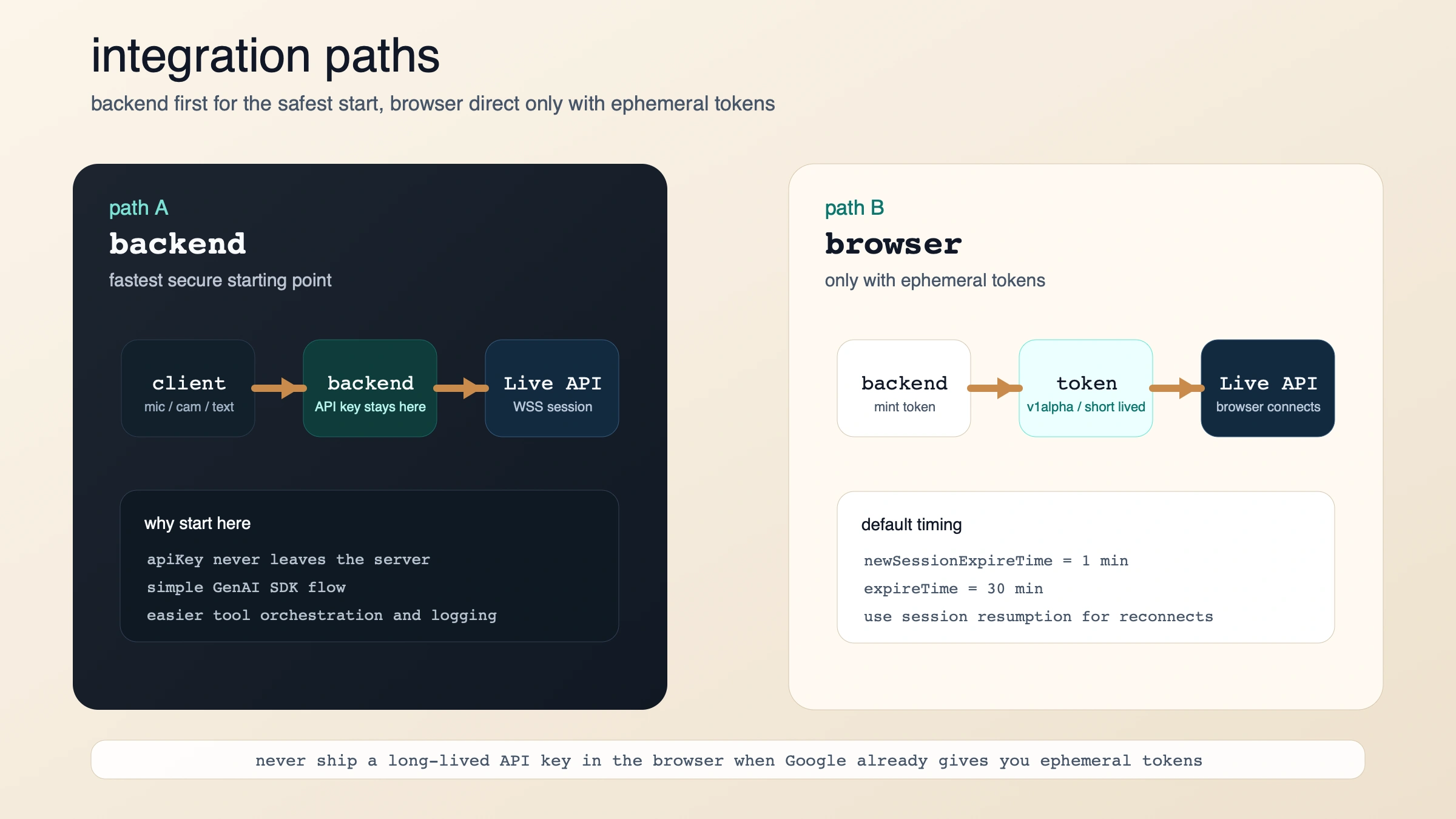
最快能跑起来的路径:先后端,再浏览器
如果你的目标是“先做成一个能工作的版本”,最稳的路径依然是 server-to-server。Live API overview 把这条路当成默认安全架构,capabilities 文档也给了基础接入模式:打开一个 Live 会话,声明 AUDIO,然后随着音频、文本或视频到来发送 send_realtime_input。
pythonimport asyncio from google import genai client = genai.Client() MODEL = "gemini-3.1-flash-live-preview" async def main(): config = {"response_modalities": ["AUDIO"]} async with client.aio.live.connect(model=MODEL, config=config) as session: await session.send_realtime_input( text="Say hello and introduce yourself in one sentence." ) async for response in session.receive(): if response.server_content and response.server_content.model_turn: for part in response.server_content.model_turn.parts: if part.inline_data: audio_bytes = part.inline_data.data # 在这里播放或继续转发音频字节 if response.text: print(response.text) if response.server_content and response.server_content.turn_complete: break asyncio.run(main())
当你从 demo 往真实语音流迁移时,Google 的文档又给了几个很具体的工程约束:输入音频应该是 16-bit PCM、16kHz、小端序,MIME type 形如 audio/pcm;rate=16000;输出音频则是 24kHz PCM。同一份 capabilities 文档还写了会话时长限制:纯音频会话默认 15 分钟,音频加视频会话默认 2 分钟。如果你要更长的连续会话,就要继续接入 Google 提供的 session management / resumption 机制。
如果你确实需要 浏览器直连,Google 给出的答案不是“把 API key 发到前端”,而是 ephemeral tokens。它的设计目的就是让前端获得更低延迟,同时又不暴露长期有效的密钥。文档里给出的默认时间窗口是:
- 通常有 1 分钟 去用这个 token 建立新会话
- 建立后通常有 30 分钟 可以继续在该连接上发送消息
- 前端会把这个 token 当成 API key 一样使用
- 如果你需要更稳的重连,就继续接入 session resumption
因此接入规则非常明确:
- 只走后端:最快、最稳、最适合先上线
- 前端直连:只有在后端能签发 ephemeral token 时才值得做
第一批最容易踩的迁移坑
从 2.5 迁到 3.1,最容易浪费时间的地方不是“明显报错”,而是“看起来能跑、其实行为悄悄变了”。
1. 不要再发 thinkingBudget。
Gemini 3.1 用的是 thinkingLevel。而且 Google 明确写了默认值是 minimal,目的是优先保证低延迟。你如果还沿用 2.5 的 thinkingBudget 直觉,就相当于在调错旋钮。
2. 一个服务端事件里要把所有 parts 都读完。
3.1 的文档说,单个服务端事件可能同时包含多个内容 part,比如音频 chunk 加 transcript。如果你的旧代码默认“一条事件只有一个 part”,它不一定会崩,但很可能会悄悄漏掉重要内容。
3. 实时更新用 send_realtime_input,不是继续乱用 send_client_content。
在 2.5 上,send_client_content 可以在对话过程中持续增量发送内容。但在 3.1 上,它只适合初始化历史上下文。真正的实时文本、音频、视频更新,都应该走 send_realtime_input。
4. 工具调用现在要按同步来设计。
这大概是对 agent builder 影响最大的一点。Google 公开文档明确写了:Gemini 3.1 Flash Live 目前不支持非阻塞函数调用。模型会等你把工具结果送回来,才继续响应。如果你的 2.5 体验高度依赖“工具在后台跑、模型继续说”,那 3.1 迁移不是参数替换,而是交互层重构。
5. proactive audio 和 affective dialog 的配置都要先删掉。
它们现在在 3.1 上没有支持。与其让废配置继续躺在系统里制造幻觉,不如在迁移时就明确移除。
6. 视频不是“反正可以传就顺手传”。
由于默认 turn coverage 会把所有视频帧都算进去,连续摄像头流本身就是一项计费与架构决策。如果你的真实核心任务是语音,不要让视频无脑常开。
7. 如果你要可读文本,就明确按 transcription 来设计。
这里 Google 自己的文档确实有点别扭:模型页写 text 和 audio output,capabilities 页又说 native audio models 只支持 AUDIO response modality。工程上最稳妥的做法,是把“文本结果”理解成 transcript 能力,而不是把它当成 обычный 文本模型。
什么情况下 Gemini 3.1 Flash Live 反而不是好选择
很多团队看完上面这些,最后还是会选 3.1,这很正常。但也确实存在它并不适合作为下一步的场景。
如果你根本不是在做实时语音产品,那 Live API 会引入不必要的复杂度。
WebSocket 会话管理、PCM 音频流、打断处理、ephemeral token,只有在 voice-first 产品里才配得上这些额外成本。普通多模态对话并不一定需要这一整套。
如果你当前 2.5 架构离不开异步工具调用,那么 3.1 现在可能会让体验变差。
这是最干净、也最值得尊重的“不迁移理由”。语音质量更好,不代表整体产品体验就更好。
如果你的后端还不能安全签发 ephemeral token,就不要先上浏览器直连。
Google 之所以专门给出这套 token 机制,就是为了避免开发者把长期有效的 API key 暴露给客户端。后端没准备好之前,继续让 Live 会话留在服务端更稳妥。
如果你只是想要语音播报,而不是实时对话智能体,那么纯 TTS 模型通常更简单。
Live 模型是为“连续对话、打断、多模态输入、工具调用”这种更厚的场景设计的。仅仅为了把文本念出来,就去接一整套 Live API,会显得过重。

FAQ
Gemini 3.1 Flash Live 的准确模型 ID 是什么?
就是 gemini-3.1-flash-live-preview。
Gemini 3.1 Flash Live 已经 GA 了吗?
还没有。模型页和 Live API 文档都把它标为 preview。
Gemini 3.1 Flash Live 支持 function calling 和 Google Search 吗?
支持。Google 文档写明它支持 function calling 和 Search grounding。但要注意,目前函数调用是同步的,不是异步。
浏览器可以直接接吗?
可以,但 Google 推荐的生产路径是:后端签发 ephemeral tokens,前端拿 token 去建立 Live 会话。不要把长期有效的 API key 直接暴露给浏览器。
会话能持续多久?
Google 的 capabilities 文档写的是:纯音频会话 15 分钟,音频加视频 2 分钟。如果你需要更长的连续交互,就用它的 session management / resumption 方案。
这个模型到底是输出文本还是只输出音频?
模型页写的是 text 和 audio output,但 capabilities 页又明确写 native audio models 使用 AUDIO response modality。如果你的应用真的需要可读文本,正确做法是显式处理 output audio transcription,不要把它当成普通文本接口。
生成出来的音频有水印吗?
有。Google 的发布文章写明,Gemini 3.1 Flash Live 输出的音频都带 SynthID 水印。
如果只用一句话总结迁移策略,应该怎么说?
新做的语音智能体直接用 Gemini 3.1 Flash Live;已经在线的 Gemini 2.5 Flash Live 系统,只有在你确认不再依赖异步工具调用、proactive audio 或 affective dialog 之后,再迁。