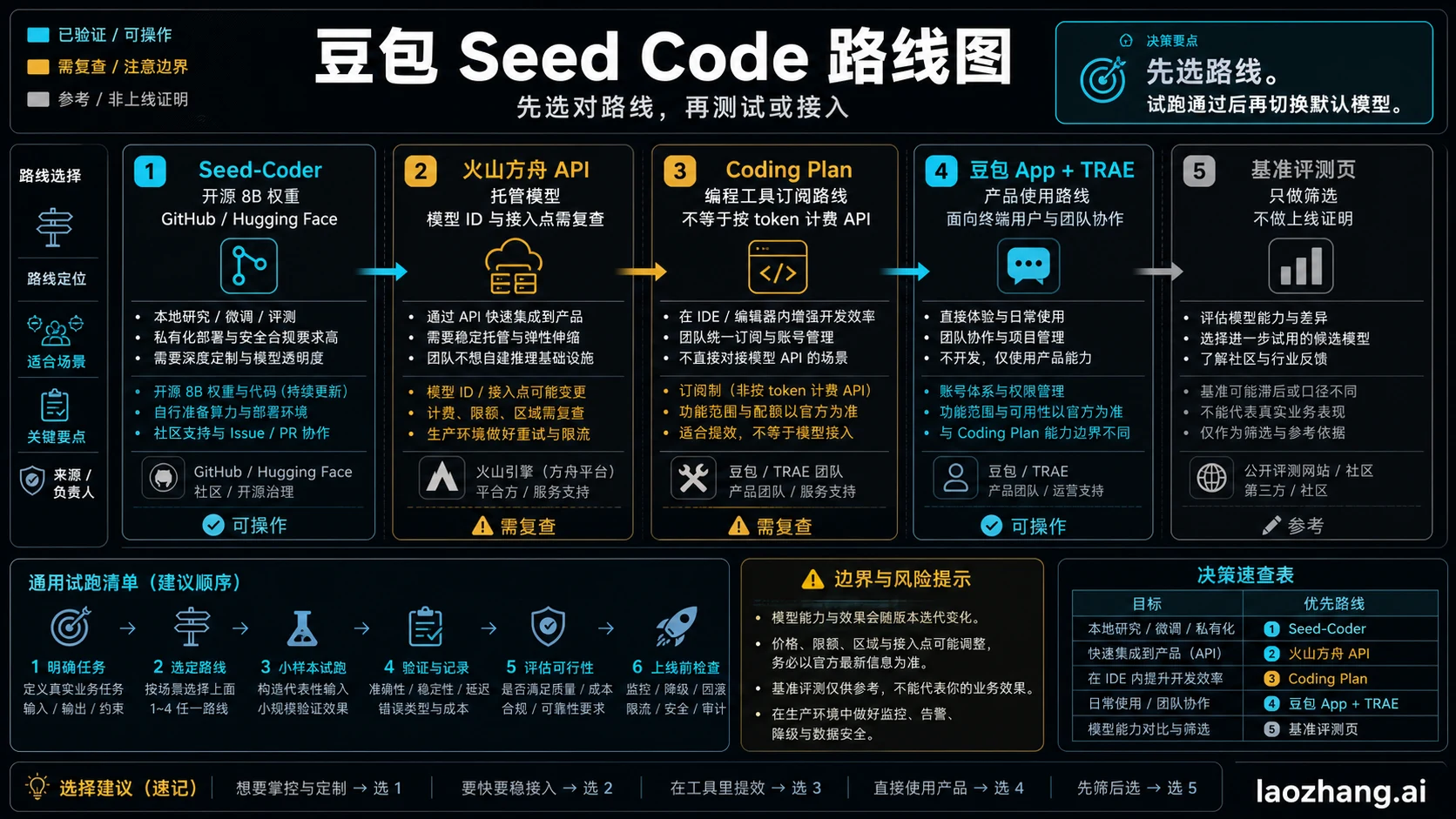
先不要把 Doubao Seed Code 当成一个模型按钮。要本地权重,就从 Seed-Coder 的 GitHub 或 Hugging Face 路线开始;要可接入代码工作流的托管模型,就先核对火山引擎 Ark 当前模型 ID、端点、上下文、价格、缓存和限额;要订阅式工具体验,就单独评估 Coding Plan;要产品体验,再看豆包 App 和 TRAE;要判断是否值得排进试点,榜单只能当筛选信号。
默认动作不是立刻换默认模型,而是做一个小而硬的同仓库试点。固定一个 commit、同一组提示词、同一条测试命令和同一套 review 标准,让候选路线完成 bugfix、重构、测试补齐或前端修改;只有测试通过、review 时间下降、重试成本可控、账单清楚、回滚简单时,才进入下一轮。
先看路线板
开发者真正要回答的是“我准备使用哪条路线”,而不是“这个名字强不强”。路线不同,事实来源、计费方式、工具兼容、失败成本和验收标准都不同。
| 路线 | 适合的任务 | 使用前复核 | 不要假设 |
|---|---|---|---|
| Seed-Coder 开源权重 | 需要本地控制、可复现实验、离线评估、自托管或安全审查。 | GitHub、Hugging Face、许可证、模型变体、上下文长度和硬件成本。 | 不要把 8B 开源族的能力和托管 API 的合同混为一谈。 |
| 火山引擎 Ark 托管 API | 需要在应用、agent 或网关中调用代码模型。 | 模型 ID、别名、base URL、上下文、输出、价格、缓存、RPM/TPM 和控制台开通状态。 | 不要把旧教程里的端点直接复制到生产。 |
| Coding Plan | 购买的是受支持的编程工具订阅体验,而不是自己管理 API 请求。 | 支持工具、地区、席位、包含量、超量规则和取消条件。 | 不要把 Coding Plan 写成 token 后付费 API。 |
| 豆包 App / TRAE | 想先体验字节自己的产品表面或 IDE 邻近工作流。 | 账号、地区、TRAE 暴露的功能和当前可用性。 | 不要从 App 表现反推 API 价格和限额。 |
| 榜单与评测 | 决定是否值得拿进试点池。 | 测试日期、任务集、价格假设、延迟和是否测了工具调用。 | 不要用一个排名直接替换默认模型。 |
如果只要一句话:集成测试先看火山引擎 API,本地控制先看 Seed-Coder,购买工具体验才看 Coding Plan。所有路线都要先通过同仓库试点。
一个名称背后的五个表面
Seed-Coder 是开源路线。ByteDance-Seed 仓库把它描述为此前名为 Doubao-Coder 的 8B 代码模型族,包含 base、instruct 和 reasoning 变体,并给出 Hugging Face 链接与 MIT 许可。它解决的是本地控制、可复现和自托管问题。
Doubao-Seed-Code 或 doubao-seed-code 是火山引擎材料里的托管 API 语境。只要你要写 adapter、接 agent、接网关、算 token 成本或做兼容端点,就应把火山引擎文档和控制台当作事实源。
Seed2.0 Code 是产品族名称。ByteDance Seed 的发布材料把 Code 模型放在豆包 App、TRAE 和 Volcano Engine 可用性的叙述里。它能解释产品位置,但不能替代 API 限额、价格、端点和计费文档。
Coding Plan 是订阅式工具路线。它可能更适合团队采购和工具支持,但不能和 token 后付费 API 放进同一张价格表。榜单页面则更窄:它们可以筛出候选项,不能证明你的仓库会少返工。
官方事实应该归谁管

把事实挂到正确来源上,后续维护才不会乱。2026 年 5 月 22 日可确认的归属是:
| 需要的事实 | 优先来源 | 落地意义 |
|---|---|---|
| 开源身份、变体、许可、下载 | ByteDance-Seed/Seed-Coder 与 Hugging Face 模型卡 | 决定能否本地部署、再分发、复现实验,以及 8B 路线是否适合硬件。 |
| Seed2.0 Code 发布、豆包 App、TRAE | ByteDance Seed 发布页 | 说明产品族在哪里出现,不说明 API 账单。 |
| 模型 ID、上下文、输入输出、缓存、工具特性 | 火山引擎模型文档 | 决定 API 请求如何写、如何截断、如何记录成本。 |
| 价格、缓存命中价、缓存存储和计划/API 区分 | 火山引擎计费文档 | 所有成本估算都要按当前文档和控制台重算。 |
| RPM、TPM、端点家族、兼容 API | 火山引擎限额与接入文档 | 批量试点可能先卡在配额或 adapter,而不是模型能力。 |
| 榜单、评分、第三方评测 | 评测平台与评论站 | 只能决定是否进入试点,不能决定上线默认项。 |
这张表的价值在于防止两个常见错误:把 Seed-Coder 的开源事实当成 API 保证,或者把某次看到的价格、端点和别名当成长期合同。
火山引擎 API 路线:今天要复核什么

对集成开发来说,火山引擎 Ark 路线最需要新鲜度复核。2026 年 5 月 22 日,公开文档列出的 doubao-seed-code-preview-251028 包含 256k 最大上下文、224k 最大输入、32k 思考内容、文本输出、函数调用、深度思考、图像理解、透明缓存以及图像/视频输入等能力。正式试点前仍要按账号和地区重新确认。
| API 字段 | 复核动作 | 试点影响 |
|---|---|---|
| 模型 ID 与别名 | 确认当前是否仍是 doubao-seed-code-preview-251028、latest 别名或新的日期版本。 | 旧 ID 会导致请求失败,或者测到并非目标模型。 |
| base URL 家族 | Chat API / Responses API 走 /api/v3,Anthropic 兼容材料走 /api/compatible。 | Claude Code 风格工具需要兼容端点,不能只拿聊天端点。 |
| 上下文与输出 | 复核最大上下文、最大输入、思考预算、max_tokens 和 max_completion_tokens。 | 长仓库任务通常失败在输入截断、隐藏思考预算或输出不足。 |
| 价格与缓存 | 复核输入阶梯价、缓存命中价、输出价、缓存存储和 Coding Plan 是否参与。 | 便宜的 token 单价可能被重试、缓存未命中和大 diff 吃掉。 |
| 速率和配额 | 复核 RPM、TPM、账号 quota、服务开通和地区限制。 | 批量任务可能先撞限额,质量还没测出来。 |
| 工具兼容 | 确认 adapter 是否支持鉴权、流式、工具调用、思考参数和目标别名。 | adapter 丢功能时,模型会显得比真实能力弱。 |
最稳妥的做法是给试点加日志:记录模型 ID、端点、参数、token、缓存状态、延迟、错误码、重试和最终 diff。没有这些记录,就分不清失败来自模型、端点、工具、提示词还是仓库任务。
开源路线:什么时候 Seed-Coder 就够了
Seed-Coder 适合把控制权放在自己环境里:安全审查、离线实验、可复现 benchmark、内部微调评估、固定硬件成本下的批量尝试。它的优势不是“所有任务都更强”,而是可拥有、可复查、可隔离。
代价也明确。8B 本地模型不等于长时间 autonomous agent 的托管大模型。要用它做小 bugfix、测试补齐、受限重构、仓库检索和批量清理;如果任务要求长上下文规划、复杂工具调用和跨文件迁移,就要先看硬件、上下文裁剪和 orchestration 是否撑得住。
| 任务 | 合格的 Seed-Coder 试点 | 停止规则 |
|---|---|---|
| 小 bugfix | 找到正确文件,给出最小补丁,并通过现有测试。 | 如果编造 API、错过失败条件或 review 更久,就停。 |
| 测试补齐 | 写出能覆盖真实分支、能编译、能暴露问题的测试。 | 如果测试很浅、脆弱或脱离源码行为,就停。 |
| 本地隐私任务 | 代码不出本地环境,并在硬件限制内产出可用 diff。 | 如果上下文裁剪让证据缺失,就停。 |
| 批量清理 | 重复低风险修改输出稳定、容易 review。 | 如果出现隐藏行为变化,就停。 |
Coding Plan、TRAE 和工具入口
Coding Plan 是另一种购买决策。它可能适合不想维护 API adapter 的团队,也可能适合需要官方支持的工具工作流。但它是否划算,取决于支持工具、包含量、节流、超量、地区、账号和退出路径,而不是模型名字本身。
TRAE 和豆包 App 更像体验入口。它们能帮助你感受字节自己的编程产品表面,但不能证明 API 价格、端点兼容、上下文上限或账号配额。
| 要确认的点 | 为什么决定路线 |
|---|---|
| 支持工具 | Claude Code 风格 CLI、Cursor、TRAE、OpenClaw 或其他 shell 必须逐一确认。 |
| 包含量与节流 | 订阅价值取决于 heavy repo task 能否跑完,而不只是月费。 |
| 地区与账号 | 采购和支付主体不同,可能改变可用性和合规审查。 |
| 退出路径 | 必须能退回原模型或 API 路线,否则试点成本会被锁定成本放大。 |
榜单只能筛选,不能替你切默认模型
榜单的用法是缩短候选名单,而不是替你验收仓库任务。
| 问题 | 榜单能提供 | 仍缺什么 |
|---|---|---|
| 是否值得试点 | 代码、推理、延迟、价格和趋势信号。 | 你的仓库、测试、review 时间和回滚路径。 |
| 该和谁比较 | 分数形态能提示对比便宜模型、前沿模型还是本地模型。 | 具体合同:开源权重、托管 API、计划订阅还是产品表面。 |
| 应看什么风险 | 推理、延迟、成本或工具调用短板。 | 是否会在你的代码库制造隐藏缺陷。 |
对编程 agent 来说,核心指标是每单位 review 负担带来的已接受工作量。榜单赢了但返工更多,就不便宜。
同一个仓库里的试点方案

试点要像工程实验,不要像演示。
| 步骤 | 固定什么 | 为什么 |
|---|---|---|
| 1. 选一条路线 | Seed-Coder、火山引擎 API、Coding Plan、TRAE 或当前默认模型。 | 混路线会让结果无效。 |
| 2. 固定仓库快照 | commit、lockfile、测试命令和 fixture。 | 相同任务必须面对相同代码。 |
| 3. 选 5 到 10 个任务 | bugfix、重构、测试、UI patch、文档和一个脏上下文任务。 | 单一 demo 容易被偶然结果误导。 |
| 4. 记录全链路 | 提示词、模型 ID、端点、adapter、token、缓存、延迟、错误、重试和 diff。 | 事后无法拆分质量和成本。 |
| 5. 按生产 review | 测试、代码审查、隐藏行为、安全和回滚。 | 输出看起来能跑,不代表可接受。 |
| 6. 对比当前默认 | 接受率、review 分钟数、重试数、缺陷率和每个接受任务成本。 | 新路线只和你已在用的路线比较才有意义。 |
试点通过后也不要一次性切全量。保留旧路线,让两三个真实任务继续通过;很多 coding-agent 问题会在第二波出现:边界漏测、过度修改、adapter 长上下文失败、或 review 负担反弹。
什么时候不要用 Doubao Seed Code
如果当前模型 ID、端点、价格、quota 和控制台开通状态说不清,不要用托管 API 路线跑生产仓库。
如果本地硬件无法保留必要上下文,不要用 Seed-Coder 承担长链路 autonomous 任务。
如果只是因为模型名字强就买 Coding Plan,不要买;只有工具支持、账单、地区、包含量和退出路径都匹配时才评估。
如果试点让 reviewer 花更多时间、产生更多重试或隐藏缺陷,不要切默认。可以继续观察,但它还不是默认路线。
还有一个常见误区是把“能跑通一次”当成“能成为默认”。编程模型的真实风险常在第二次、第三次任务里出现:前一次生成的测试太浅,下一次 refactor 就误改边界;一次大上下文没有截断,下一次 adapter 却丢了工具调用;一次缓存命中让成本很好看,下一次缓存未命中才暴露预算压力。因此团队要看稳定的 accepted diff,而不是一次漂亮输出。
如果团队里有不同角色,路线判断也要拆开。负责平台的人关心 API key、endpoint、quota、审计日志和账单;负责代码质量的人关心隐藏缺陷、review 时间和测试覆盖;负责采购的人关心 Coding Plan 的地区、席位、取消和超量;负责安全的人关心本地权重和代码出境。一个 Doubao Seed Code 决策同时影响这些角色,所以评审材料必须写清楚每条路线的责任边界。
对中文读者尤其要避免把“豆包”产品体验、TRAE 体验和火山引擎 API 体验合在一个结论里。App 里顺手、IDE 里好用、API 里可控、账单里便宜,是四个不同的判断。只有当同一仓库里的任务证明这些条件同时成立,才有理由扩大使用范围。
如果只是做一次个人尝鲜,可以用更轻的标准:确认账号能访问、任务不含敏感代码、输出不直接进入主分支、成本上限清楚。但团队试点不能这么松。团队试点必须能回答三类问题:这条路线是否减少真实工作量,失败时是否容易定位和回滚,后续维护是否会增加新的工具债。回答不了这三类问题,就先停在观察阶段。
还要给价格判断留出缓存和失败空间。很多 API 价格比较只看 input/output 单价,却没有把 cache miss、long context 输入、生成过长 diff、失败重跑、人工 review 和回滚都算进去。Doubao Seed Code 如果要进入默认候选,必须按“已接受任务成本”而不是“百万 token 单价”来算。这样才能避免便宜单价在真实工程流程里变成昂贵返工。
最后,路线选择要能被复述给没有看过评测的人:我们为什么不用 App 表现证明 API,为什么不用开源权重证明托管模型,为什么不用榜单替代仓库测试,为什么不用 Coding Plan 价格替代 token 账单。只要这四个问题说不清,文章再多参数也没有形成可执行决策。
如果要把试点结果写进团队文档,建议按路线分栏记录:Seed-Coder 写硬件、上下文和本地合规;火山引擎 API 写模型 ID、端点、参数、价格和错误码;Coding Plan 写工具、席位和包含量;TRAE 或 App 写具体交互价值;榜单写测试日期和任务集。这样的记录能让后续复查者知道每个结论从哪里来,也能在模型别名、价格或计划条款变化时快速更新。
同样,不要把“支持 Claude Code 风格工具”写成泛化承诺。真正需要确认的是 compatible base URL、鉴权头、流式输出、工具调用参数、思考预算、错误码格式以及目标工具是否会截断上下文。只要其中一个环节不匹配,失败看起来像模型能力问题,实际可能只是 adapter 合同没有对齐。
如果目标是接入现有网关,还要确认日志和成本归因能不能按模型别名、项目、用户和任务类型拆开。没有这层归因,试点阶段看似通过,月底账单却无法解释哪类任务消耗了上下文、哪类任务重试最多、哪类任务应该退回旧模型。
这也是为什么路线板要放在正文前面:它让读者在看参数、价格和榜单之前,先知道自己要验证的是哪一种合同。
合同先清楚,后面的提示词、工具配置、预算表、上线节奏和回滚预案才有意义,也更容易被团队复核、长期维护和再次审计验证。
常见问题
Doubao Seed Code 是开源的吗?
部分是。开源路线叫 Seed-Coder,仓库显示它是此前名为 Doubao-Coder 的 8B 代码模型族。火山引擎托管 API 是另一条合同,不要把两者写成同一个东西。
应该用哪个 API?
做托管集成时从火山引擎 Ark 开始,复核模型 ID、base URL、上下文、输出、价格、缓存和限额。2026 年 5 月 22 日公开文档列出过 doubao-seed-code-preview-251028,但 ID 和别名会变。
Coding Plan 等于 API 计费吗?
不等于。Coding Plan 是工具订阅路线,token 后付费 API 是另一套合同。比较成本、限额、支持和退出路径时必须分开。
能接 Claude Code 风格工具吗?
可能可以,但要确认兼容端点、鉴权、流式、工具调用、思考参数和目标别名。一个 adapter 可用不代表另一个可用。
它会更便宜吗?
只看 token 单价不够。要算每个已接受任务成本,把重试、缓存未命中、失败运行、review 时间和回滚成本都算进去。
先测什么任务?
先测一个 bugfix、一个重构、一个测试补齐、一个 UI 或集成 patch、一个脏上下文任务。所有路线使用同一仓库快照和同一 review 标准。