
Codex token 和上下文用量不是一个可以到处套用的总数。你要先问清楚自己在查哪一类用量:当前 CLI 会话、当前 context pressure、CLI 底部常驻计数、ChatGPT 或 Codex 计划额度、OpenAI API 账单、某一次 API 响应,还是这台机器上的本地历史记录。
如果你正在 Codex CLI 里工作,第一步是运行 /status。如果你想把 context stats、token counter、限制和模型信息放在底部持续看,用 /statusline。如果你问的是计划还剩多少额度或 credits,应该去 Codex 或 ChatGPT 的 usage 设置;如果你问的是 API key 花了多少,应该看 OpenAI Platform Usage;如果你问的是单次请求用了多少 token,要看完成后的响应 usage 字段。
不要一上来就跑别人发的本地 JSONL 统计脚本,也不要把私有接口脚本当成标准办法。本地日志可以帮你估算这台机器上的活动,但它不是官方账单,也可能包含提示词、文件路径、代码片段或客户上下文。
- 当前 CLI 会话:
/status - CLI 常驻 context 和 token 显示:
/statusline - ChatGPT/Codex 计划额度或 credits:Codex 或 ChatGPT usage 设置
- API key 账单:OpenAI Platform Usage
- 单次 API 请求:完成响应里的
usage - 本地历史:只把本地 Codex 日志当估算
快速答案:先选对用量表
最可靠的做法不是问“Codex 总共用了多少 token”,而是先确定这个数字要证明什么。CLI 当前会话、订阅计划额度、API 组织账单、一次请求的 token 统计和本地日志都属于不同记录。把它们放在同一张表里比较,通常只会制造误报。
| 你想查的问题 | 先看哪里 | 它能证明什么 | 它不能证明什么 |
|---|---|---|---|
| 当前 Codex CLI 会话用了多少 | CLI 里运行 /status | 当前会话配置和 token 状态 | 账号历史总量或 API 账单 |
| 当前任务的上下文压力有多高 | 先用 /status,再用 /statusline 持续显示 | 当前会话的 context 和 token-counter 状态 | Codex web/app 里按 conversation、task 或 run 汇总的完整历史 |
| 计划额度或 credits 还剩多少 | Codex 或 ChatGPT usage 设置 | 订阅侧额度、credits 或使用状态 | API key 花费 |
| API key 花了多少 | OpenAI Platform Usage | 组织或项目的 API usage | ChatGPT/Codex 订阅额度 |
| 某一次请求用了多少 token | 完成响应里的 usage | input、cached input、output、reasoning 和 total 等字段 | 月度账单全貌 |
| 想估算本机历史 | 本地 Codex 日志 | 这台机器记录到的大致活动 | 官方账单、云任务、其他设备或被删日志 |
截至 2026 年 5 月 24 日,Codex 的计划、credits、模型可用性和界面入口仍属于容易变化的事实。命令名、status-line 概念和 API 响应对象的 usage 比具体按钮文字稳定;写支持工单时,也应该把数字和来源一起保存。
CLI 当前会话:先用 /status
在 Codex CLI 里,/status 是最先该用的检查命令。它适合回答“这个终端里的当前会话是什么状态”,例如模型、配置、上下文压力和当前会话的 token 使用情况。它不适合回答“我这个账号本周还剩多少 Codex 额度”。
text/status
把 /status 输出当成会话证据。它能帮助你判断这次任务是不是已经接近上下文压力点,是否用了预期模型,以及当前路由是否符合你的预期。它不能替代 ChatGPT usage 设置、Codex usage dashboard 或 OpenAI Platform Usage。
/status 里看到的内容 | 合理解释 | 不要这样解释 |
|---|---|---|
| 模型或会话配置 | 当前 CLI 表面正在使用的配置 | 永久账号政策 |
| 上下文或 token 使用 | 本次会话的工作状态 | 月度账单 |
| 限制或使用提示 | 当前 Codex 表面的信号 | 跨产品额度证明 |
实际流程很简单:先在当前会话运行 /status,把输出保存为截图或文本;然后再判断问题是否已经离开 CLI,进入订阅额度或 API 账单的范围。
用 /statusline 把计数留在底部
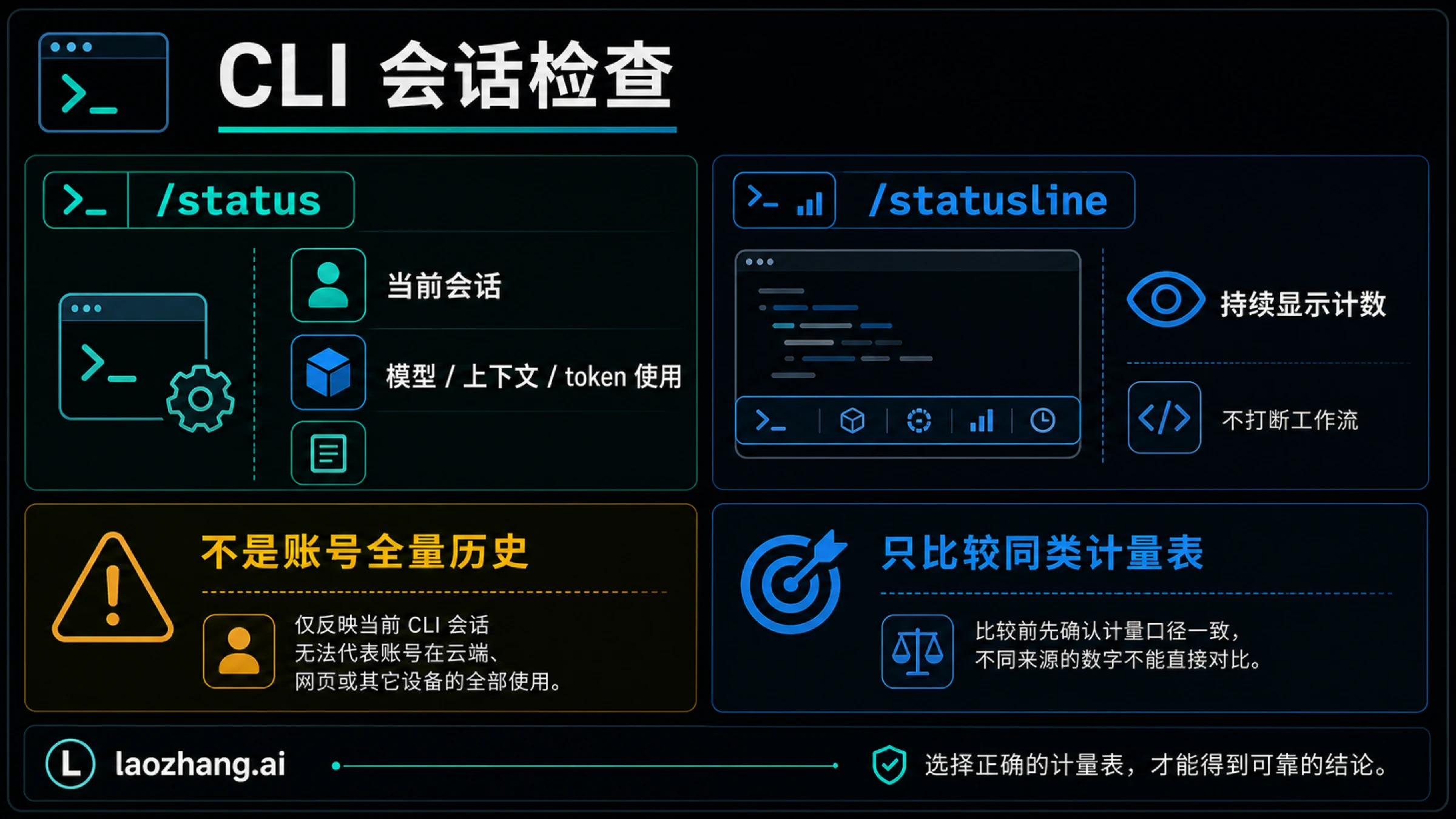
如果你不想每隔一会儿就打一次 /status,可以用 /statusline 配置底部状态栏。这个入口适合把模型、上下文、限制、token counter、git 状态、会话、当前目录和 Codex 版本等信息放在 TUI 底部。
区别要分清:/status 是你主动调用的一次检查;/statusline 是一个显示面板。它让你在长时间编辑时看见当前压力,但它仍然是当前工作表面,不是历史账单。
适合用 /statusline 的场景包括:
- 长任务里持续观察上下文压力
- 切换项目时确认模型和会话身份
- 在开始大改动前判断是否需要压缩上下文
- 减少反复输入
/status的打断
不适合用它来做这些事:
- 证明过去一个月花了多少钱
- 对账 ChatGPT 计划额度和 API 账单
- 估算另一台电脑上的 Codex 活动
- 替代 OpenAI Platform Usage
如果问题是“这个终端现在怎样”,留在 CLI。问题一旦变成“账号或 API key 花了多少”,就应该换到对应的官方 usage 表面。
Context meter:把上下文当作会话压力
很多人说的 “context meter” 实际上是在问两件事:这个 CLI 会话离上下文压力点还有多远,以及能不能按 conversation、task 或 run 查一份完整历史。前者可以在 CLI 里处理;后者不能直接由 /status 或 /statusline 证明。
| 上下文问题 | 先做什么 | 边界 |
|---|---|---|
| 当前 CLI 会话的 context pressure 有多高 | 运行 /status | 只证明当前会话 |
| 工作时想一直看 context 和 token counter | 配置 /statusline | 只是在 TUI 打开时可见 |
| 想知道某个 task 历史上一共用了多少 | 先看官方 usage 表面;本地日志只能私下估算 | 不是账单证据 |
| 想把 context used 和 API cost 对账 | 不要直接对账;API cost 属于 Platform Usage 和 response usage | context pressure 不是发票 |
这个边界能避免一个常见误判:remaining context capacity 不是 remaining account quota。一个长会话可能上下文压力很高,但不等于 API 花费很高;一个 API project 可能已经产生费用,但不会改变 ChatGPT/Codex 订阅额度表面。只有证据明确进入 API 或订阅路线时,才离开 CLI meter。
ChatGPT/Codex 计划额度:看订阅侧
订阅侧最容易混词。Codex plan quota、credits、CLI 当前会话和 API organization bill 不是同一个数字。你如果用的是 ChatGPT 登录、Codex app、Cloud task 或 workspace 里的 Codex,用量入口应当从 Codex 或 ChatGPT 的 usage 设置开始。
这个入口适合回答:
- 我的 Codex 包含式用量还剩多少?
- 是否碰到了 plan limit 或 credit limit?
- credits 是否适用于当前 Codex 路线?
- 我现在是 ChatGPT 登录,还是 API key 路线?
不要在用量检查步骤里展开完整计划表。额度窗口、credits 和到达限制后的选择,应交给 OpenAI Codex usage limits 指南。当前任务更窄:先选对表面,再相信数字。
支持级别的记录要包含三件事:登录的是哪个账号,当前 Codex 路线是 ChatGPT 登录还是 API key,检查的是哪个 usage 表面和什么时间。只有数字没有来源,很难排查。
API 账单和单次 usage 是另一条线
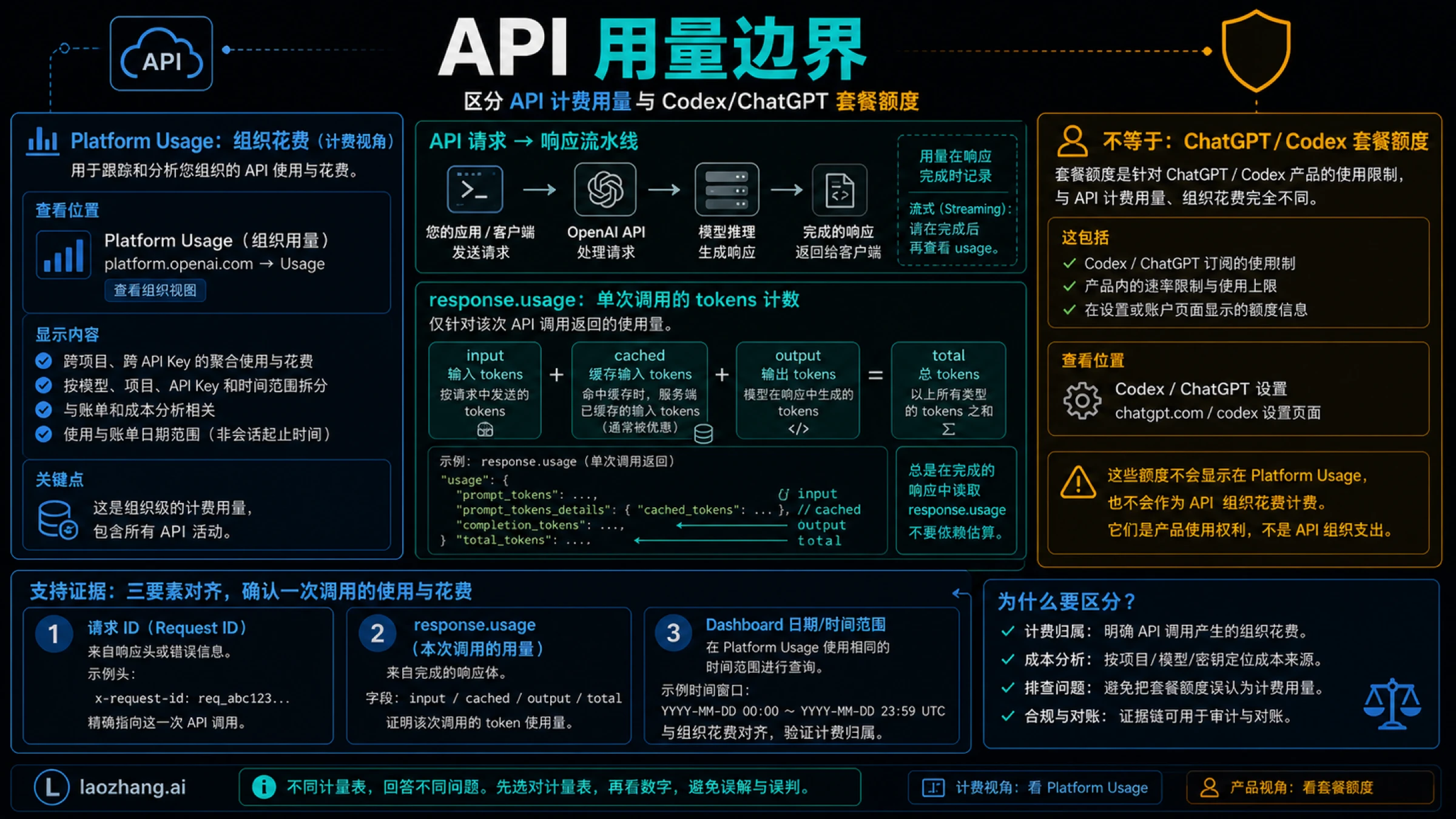
只要出现 API key、project、organization、service account、SDK 或后端集成,问题就进入 API 线。OpenAI Platform Usage 用来查组织或项目的 API 使用情况;完成响应中的 usage 用来查某一次请求的 token 统计。
| API 问题 | 应看表面 | 最好的证据 |
|---|---|---|
| 这个组织或项目用了多少 | OpenAI Platform Usage | 时间范围、组织/项目范围、账期 |
| 这一请求用了多少 token | 完成响应的 usage | response id、model、usage 字段 |
| 为什么 API 成本和 Codex CLI 不一致 | 路线对比 | API key 账单和 ChatGPT/Codex 计划分开 |
一个最小的记录可以长这样:
json{ "response_id": "resp_...", "model": "gpt-...", "usage": { "input_tokens": 1200, "cached_input_tokens": 800, "output_tokens": 350, "total_tokens": 1550 } }
这些字段适合做请求级归因、成本分析和异常排查。但它们仍然不能告诉你 ChatGPT 订阅里的 Codex quota 还剩多少。只要工作从 ChatGPT 登录切到 API key,你也同时换了用量表。
如果你还没分清自己该用 API key 还是订阅路线,先读 Codex API key vs subscription 指南。路线选择和用量检查要分开处理,避免把两套账合并。
本地历史估算:有用,但不是官方账
本地 Codex 日志可以帮你估算这台机器上发生过什么,例如哪个项目会话最长、昨天是否跑了大任务、某个工作目录是否产生了很多交互。它适合个人复盘,不适合拿来证明账单。

解析本地文件前先做安全判断:
| 本地问题 | 可以怎样用 | 风险 |
|---|---|---|
| 这台机器的会话 | 估算本地活动 | 其他设备和云表面缺失 |
| 会话文件里的 token-like 字段 | 粗略个人统计 | 字段含义可能随版本变化 |
| prompt 或 transcript 文本 | 调试上下文 | 可能暴露代码、路径、密钥或客户资料 |
| 私有 backend endpoint | 不作为正常路径 | 不稳定、无支持承诺、可能有账号风险 |
如果确实要跑本地解析脚本,保持只读、限制目录、不要把完整 transcript 粘到公开工具里。任何本地总和都只能写成“这台机器记录到的估算”,不能写成“官方 token ledger”。
更稳的顺序是:官方表面先告诉你要查哪类用量;本地日志只在你需要解释本机历史时补充背景。
为什么数字对不上
Codex 和 OpenAI 的不同 usage 数字经常对不上,因为它们本来就不是同一个问题。
| 看起来冲突 | 常见原因 | 下一步 |
|---|---|---|
/status 很高,但 Platform Usage 很低 | CLI 会话 token 不是 API organization spend | 分开记录 CLI 和 API |
| Platform Usage 增长,Codex plan quota 没变 | 工作通过 API key 运行 | 查 project key 和 billing owner |
| ChatGPT/Codex quota 变了,API logs 没变 | 工作走订阅 Codex,不走 API key | 查登录账号和 workspace |
| 本地日志和 dashboard 不一致 | 日志不完整、只在本机、可能被清理 | 官方 dashboard 做账号证据 |
单次 usage 与发票不完全相加 | 定价、cached token、时间范围、项目范围和四舍五入都会影响 | 只在同一 API billing 表面内对比 |
不要强行把这些数字凑成一条账。先给数字分类,再只和同类数字比。
联系支持前要保存什么
如果数字仍然异常,保存证据时也要保留用量表边界。
CLI 问题保存:
- 当前会话的
/status输出 - Codex 版本、模型和工作目录
- 是否用了 ChatGPT 登录或 API key
- 发生问题的大致时间窗口
订阅额度问题保存:
- Codex 或 ChatGPT usage 表面的截图
- plan 或 workspace 类型
- 是否涉及 credits
- 时区和时间窗口
- 是否有 cloud task、本地消息或 code review
API 账单问题保存:
- organization 和 project 范围
- API key 或 service account owner,不要暴露 key
- Platform Usage 的时间范围
- 代表性 completed response usage
- model 名称和 request id
这样支持或管理员才能判断是哪条线出了问题。“Codex token usage 不对”太宽泛;“我在比较 /status、ChatGPT usage 和 Platform Usage 三个不同表面”才可诊断。
常见问题
CLI 里怎么看 Codex token 用量?
在当前 Codex CLI 会话里运行 /status。它适合看当前会话配置和 token 状态,不适合当成账号历史总账。
/statusline 是什么?
/statusline 用来配置 Codex TUI 的底部状态栏。它可以持续显示模型、上下文、限制和计数,但仍然不是账单面板。
Codex plan quota 或 credits 在哪里看?
看当前登录账号的 Codex 或 ChatGPT usage 设置。计划、credits、模型可用性和 workspace 迁移状态都需要按当前日期核对。
OpenAI API token usage 在哪里看?
组织或项目层面的 API usage 看 OpenAI Platform Usage;单次请求的 token 统计看完成响应里的 usage 字段。
为什么 Codex CLI 用量和 OpenAI Platform Usage 不一致?
因为它们是不同表面。CLI 用量描述当前 Codex 会话;Platform Usage 描述 API organization 或 project 的用量。
本地 Codex 日志能看历史 token 吗?
可以估算这台机器记录到的本地活动,但不能证明官方账号总用量,也可能包含敏感 prompt、路径或文件内容。
要不要用私有接口脚本查用量?
不要把它当正常方法。先用受支持的 CLI 命令、账号 usage 设置、OpenAI Platform Usage 和完成响应 usage。