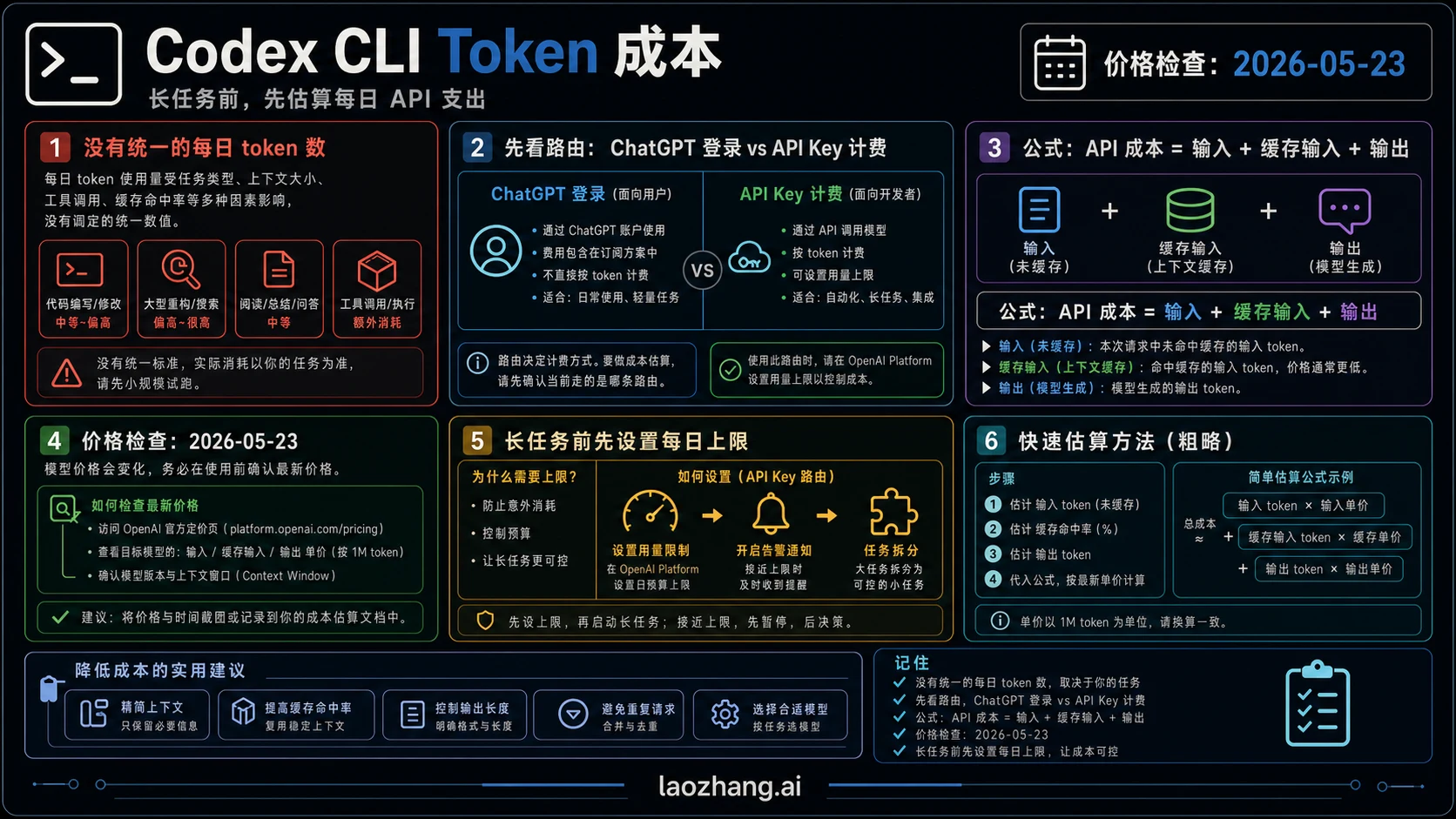
截至 2026 年 5 月 23 日,Codex CLI 没有一个对所有人都成立的每日 token 数。你要先确认当前会话走的是 ChatGPT 登录、API key、云端任务、代码审查还是 fast mode;只有确认是 API-key 计费后,才应该用 input tokens、cached input tokens 和 output tokens 去估算美元成本。更可靠的做法是先定路由,再套公式,再给长任务写一个当天必须暂停的预算上限。
先用两分钟估算器定边界
在让 Codex 改完整仓库、跑长时间调试、生成大量解释或连续修复测试之前,先做这个短检查。它不能替代账单,但能让你知道现在是不是该继续。
- 看清路由:ChatGPT 登录、API key、本地 CLI、云端任务、代码审查或 fast mode。
- 如果是 API-key 计费,选定实际模型,并打开当前 OpenAI Platform 价格表。
- 把 token 分成三类:input、cached input、output。
- 每类 token 乘以自己的百万 token 单价。
- 写下今天的软上限和硬上限,长任务超过软上限就暂停复算。
API-key 路由下的基础公式是:
text每日 API 成本 = input_tokens / 1,000,000 * input_price + cached_input_tokens / 1,000,000 * cached_input_price + output_tokens / 1,000,000 * output_price
用 2026 年 5 月 23 日核对到的 OpenAI 标准文字价格做演练:一个普通工作日如果有 3M input、2M cached input 和 0.4M output,约等于 gpt-5.4-mini 4.20 美元,或 gpt-5.4 14.00 美元。这只是预算演练,不是账单承诺;真正账单要看 OpenAI Platform Usage 和当前项目设置。
先判断当前是哪一个计费表
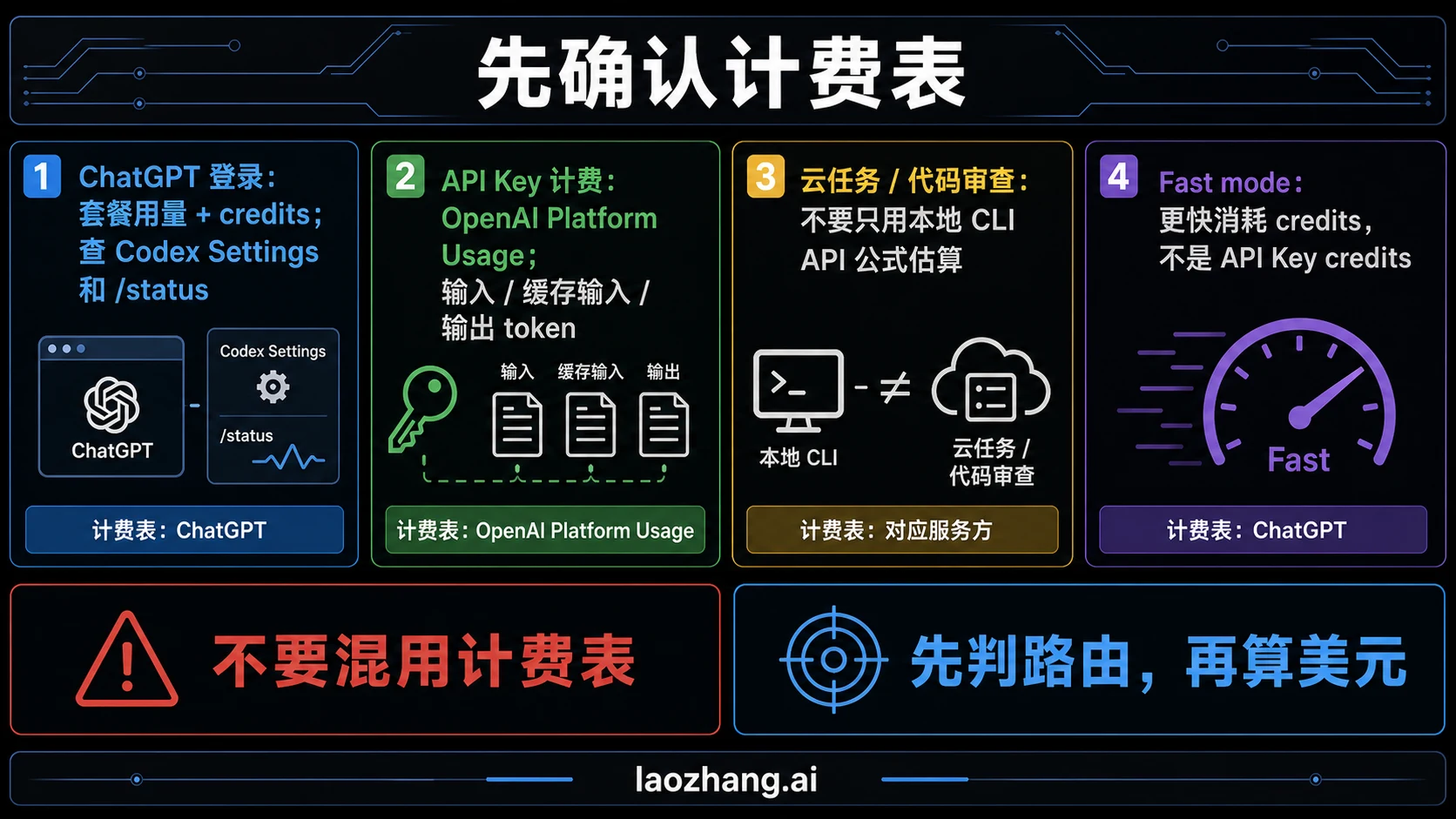
很多高账单误会不是公式错,而是路由错。终端里都叫 Codex,后台可能不是同一个计费表。
| 当前路由 | 含义 | 估算方式 | 优先检查位置 |
|---|---|---|---|
| ChatGPT 登录 | 个人或团队计划里的 Codex 使用 | included usage、credits、账户限额 | Codex Settings、/status |
| API-key 计费 | 本地 CLI 或自动化明确走 OpenAI Platform | input、cached input、output 单价 | OpenAI Platform Usage |
| 云端任务或代码审查 | 托管 Codex 工作流,不等同于本地 CLI token 数学 | 任务详情和 Codex 价格文档 | 任务页、Codex Settings |
| fast mode | 更快的 ChatGPT 路由工作,消耗 credit 更快 | credits 和当前倍数规则 | Codex Settings、speed 文档 |
最重要的分界是:ChatGPT 的 included usage 和 credits 不是普通 API-key 账单的钱包。OpenAI 的 Codex API key 登录说明把 API-key 路由归到 OpenAI Platform billing;Codex pricing则单独描述 ChatGPT 计划、credits 和 API-key 可用性。
如果你还没决定该用订阅还是 API key,先看配套路由页:Codex API Key vs Subscription: Which Route Should You Use?。这篇只负责在 API-key 成本需要估算时,把数字算清楚。
使用当前价格锚点,不要套旧表
API-key 成本最容易被 output 放大。Codex 写长解释、完整文件、测试日志、总结和多轮复盘时,output tokens 往往比你想象的贵。
这些是 2026 年 5 月 23 日核对到的 OpenAI Platform 标准文字价格:
| 模型 | input | cached input | output | 估算用途 |
|---|---|---|---|---|
| gpt-5.4-mini | $0.75 / 1M | $0.075 / 1M | $4.50 / 1M | 日常改文档、常规修复、初步排障的低成本基线 |
| gpt-5.4 | $2.50 / 1M | $0.25 / 1M | $15.00 / 1M | 复杂架构判断、难复现错误、关键重构的强模型估算 |
| gpt-5.5 | $5.00 / 1M | $0.50 / 1M | $30.00 / 1M | Platform 有价格,但不要当成 Codex API-key 默认基线,除非当前 Codex 文档明确列出 |
GPT-5.5 的 caveat 必须保留。这个运行核对时,Codex 价格页在 ChatGPT 计划 Codex 使用中列到了 GPT-5.5,但 API-key 行没有把它列为该路由的默认可用模型。以后如果官方文档变化,先更新模型可用性,再更新例子。
价格以 OpenAI Platform pricing 为准;RPM、RPD、TPM、TPD、IPM 和 spend limit 等限制以 API rate limits 为准。限制会影响自动化能跑多久,但限制不是每日美元成本本身。
用日常场景给预算做上限
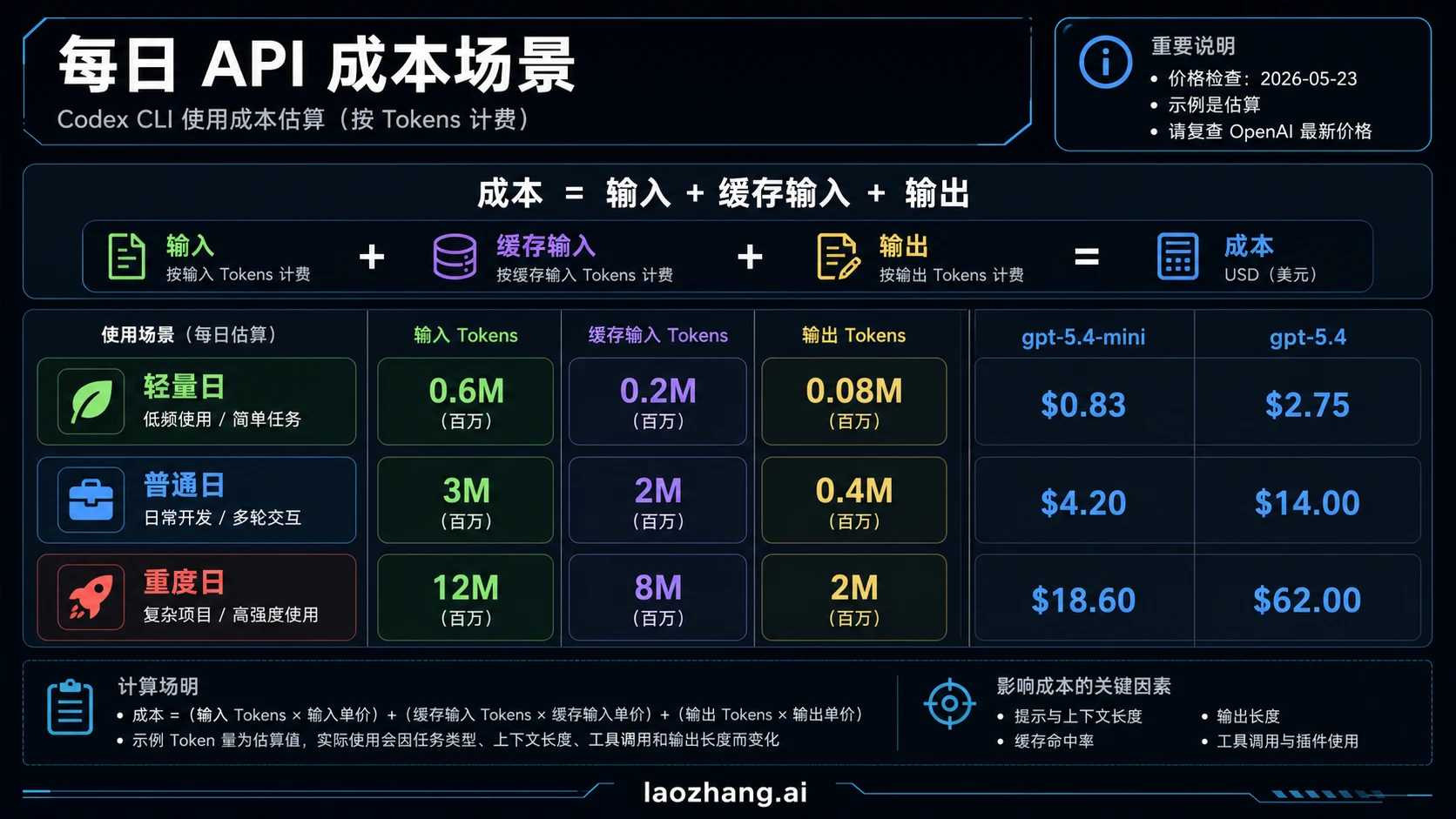
不要问“Codex 一天到底多少 token”这种没有上下文的问题。先把自己的工作日拆成 light、normal、heavy 三档,再看模型差异。
| 场景 | input tokens | cached input tokens | output tokens | gpt-5.4-mini 估算 | gpt-5.4 估算 |
|---|---|---|---|---|---|
| 轻量日 | 0.6M | 0.2M | 0.08M | $0.83 | $2.75 |
| 普通日 | 3M | 2M | 0.4M | $4.20 | $14.00 |
| 重度日 | 12M | 8M | 2M | $18.60 | $62.00 |
普通日的 gpt-5.4-mini 计算是:
text(3 * $0.75) + (2 * $0.075) + (0.4 * $4.50) = $4.20
同样 token 结构放到 gpt-5.4:
text(3 * $2.50) + (2 * $0.25) + (0.4 * $15.00) = $14.00
这说明模型选择和输出长度比“少写几句 prompt”更影响预算。例行任务先用够用的低成本模型,遇到难诊断、跨模块设计或高风险改动再升级。
用自己的 30 到 60 分钟样本校准
最好的估算来自一段真实工作样本,而不是别人的论坛截图。样本不需要完美,只要能代表你接下来要跑的任务。
- 使用和正式任务相同的路由。
- 选一个真实任务,不要用玩具 prompt。
- 记录模型、仓库规模、读取路径、文件数量、工具调用和对话轮数。
- 如果是 API key,去 OpenAI Platform Usage 看这段时间的用量。
- 能看到 token 分类时,分别记录 input、cached input、output。
- 只能看到总花费时,用模型价格反推一个区间。
- 把样本乘以当天预计工作块数量,再加 25% 到 50% 的重试缓冲。
例如你打算让 Codex 做四个类似的 refactor,而一个样本块用了 45 分钟、花费约 2 美元,那么当天预算不要只写 8 美元。测试失败、上下文扩展、解释变长都会抬高 output,比较保守的预算应先看 10 到 12 美元区间,再决定是否继续。
哪些行为最容易烧 token
Codex 的 token 消耗来自读得多、记得多、试得多和写得多。省钱不是让模型少做事,而是让它少做无关事。
| 消耗来源 | 实际发生的事 | 控制方式 |
|---|---|---|
| 大仓库上下文 | 大量文件进入 input 侧 | 限定路径,排除生成文件、日志、无关文档和 fixture |
| 反复工具调用 | 每次 read、test、log、summary 都会把上下文拉长 | 先给接受标准,让 agent 批量读相关文件 |
| 长输出 | 完整文件、长解释、测试日志和反复总结提高 output 成本 | 要求补丁、命令和结论简洁,长解释只在需要时输出 |
| 缓存复用差 | 重启或频繁改上下文会降低 cached input 占比 | 保持稳定上下文,避免无必要重开会话 |
| 迭代次数高 | 失败测试和不清晰需求制造更多轮次 | 一开始给边界、命令、停止条件和验收方式 |
| 默认强模型 | 更高单价乘上全部 token 类别 | 例行任务先用低成本可胜任模型 |
最有效的省钱手段通常很朴素:缩小范围、控制输出、少重跑、先测样本、写暂停线。它们比追一个神奇的“每日 token 数”更可靠。
什么时候用订阅、credits 或 API key
不要把订阅、credits 和 API key 混为一个钱包。它们适合的工作不同。
| 工作类型 | 优先路由 | 原因 |
|---|---|---|
| 个人交互式写代码 | ChatGPT 登录 | included usage 和 credits 更适合这个界面 |
| 本地自动化并需要用量报表 | API key | Platform Usage、项目预算和 spend limit 更清楚 |
| CI、定时任务、SDK 或后端服务 | API key | 非交互凭证和项目级预算更合适 |
| Codex 云端任务或 code review | ChatGPT / workspace 路由 | 不能只用本地 CLI API 公式估算托管工作 |
| included usage 用完 | 看 credits 或等待重置 | credits 可能扩展受支持的使用,但不等于普通 API-key 账单余额 |
全局计划限制请看配套页:OpenAI Codex Usage Limits: Plus, Pro 5x/20x, Business Credits, and API Key Rules。这篇保持窄边界:只在本地 Codex 工作走 API-key 计费时,帮你估一个每日成本包络。
给长任务写预算停止规则

长会话先写停止规则,再给更多上下文。建议至少有五条:
- **软上限:**当天估算或观察用量达到预算 70% 就暂停。
- **硬上限:**API-key 项目使用 Platform budgets 或项目限制。
- **范围上限:**Codex 开始读约定范围外的文件时暂停。
- **输出上限:**输出开始变成长篇解释、完整文件或重复总结时暂停。
- **重试上限:**同一类测试或命令连续失败后暂停,重新诊断。
一个可执行的日预算可以这样写:
text预算:例行 Codex CLI API-key 工作 $15/day 暂停线:估算或观察到 $10.50 默认模型:gpt-5.4-mini 升级规则:只有难排障、架构判断或高风险重构才用 gpt-5.4 输出规则:默认给补丁和结论,不输出长篇背景
这个数字不是推荐给所有人,而是格式。你的团队要自己决定金额、模型和暂停条件。
账单突然变高时按这个顺序排查
先排路由,再排模型,再排输出。不要靠猜。
- 路由:是不是实际用了 API key,而你以为还在 ChatGPT included usage 里?
- 模型:是不是用了比估算更强、更贵的模型?
- 输出:是不是生成了长解释、完整文件、重复总结或大量日志?
- 上下文:是不是读了整仓,而不是目标路径?
- 重试:测试失败是否制造了很多额外轮次?
- 自动化:CI、脚本或定时任务是否重复启动同一流程?
- 限制:rate limit 或 spend limit 是否触发失败重试?
API-key 成本以 OpenAI Platform Usage 为账本;ChatGPT 路由用 Codex Settings 和 /status 核对。两个表如果和你的预期不一致,先停下修正路由,再继续任务。
常见问题
Codex CLI 一天会用多少 token?
没有通用答案。它取决于路由、模型、仓库上下文、读取文件、工具调用、输出长度、重试次数、缓存复用和任务时长。可发布的估算必须把这些变量摆出来。
Codex CLI API 成本怎么估算?
先确认 API-key 计费正在生效。然后估算 input tokens、cached input tokens、output tokens,分别乘以当前模型的价格,再相加。价格表必须写日期。
cached input 为什么要单独算?
因为 cached input 通常有不同单价。它能降低重复上下文的成本,但不能把所有 input 都自动变成缓存价。是否命中和具体会话、上下文稳定性、平台实现有关。
API key 一定比 ChatGPT Plus 或 Pro 便宜吗?
不一定。低量、可控、自动化的任务可能 API key 更便宜;长时间交互、输出很多、需要 included usage 的个人工作可能订阅更合适。先看路由和工作形态。
ChatGPT credits 能不能抵 API-key 账单?
不要这样假设。ChatGPT included usage 和 credits 属于 ChatGPT 路由的 Codex 体验;API-key 账单属于 OpenAI Platform。除非官方账户页和文档明确说明,否则把它们当作两个计费表。
长任务开始前最安全的做法是什么?
确认路由,选默认模型,限制上下文,要求简洁输出,做 30 到 60 分钟样本,写预算软上限,并在达到 70% 时暂停复算。