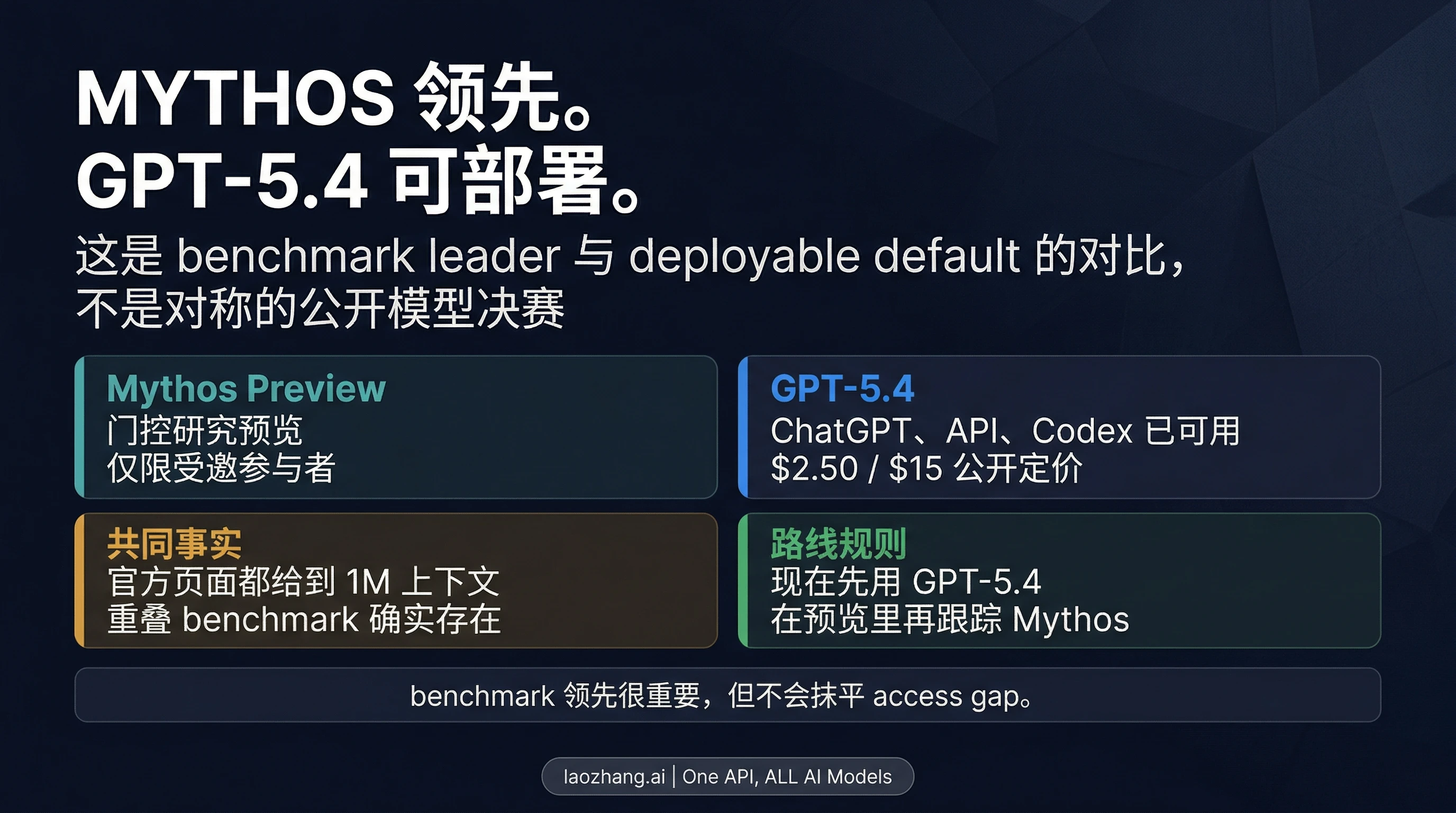
如果你今天就要用模型,先用 GPT-5.4。Claude Mythos Preview 虽然在 Anthropic 官方发布时给出的多项 benchmark 上领先,但它仍是只对受邀参与者开放的 research preview,不是你看完这篇就能直接切换过去的普通公开模型。
截至 2026 年 4 月 9 日,OpenAI 说 GPT-5.4 已经在 ChatGPT、API 和 Codex 中可用;Anthropic 则把 Mythos Preview 限定在 Project Glasswing 合作方和其他受邀组织内。这意味着这篇文章首先要回答的是路线问题,而不是单纯的 benchmark 胜负问题:对大多数读者来说,现在继续用 GPT-5.4 才是正确默认项;只有当你已经在 preview 受众里,或者你本来就负责 future-tier 评测时,Mythos 才会改变你的计划。
快速答案
如果标题让你以为这是一个普通的「谁更强」对比,真正有用的答案其实更窄。
| 你的真实问题 | 现在最合理的动作 | 为什么 |
|---|---|---|
| 「我今天到底能用哪个模型?」 | GPT-5.4 | 它已经公开出现在 ChatGPT、API 和 Codex 里。 |
| 「Mythos Preview 是不是公开可买的替代项?」 | 不是 | Anthropic 仍把它写成门控 research preview。 |
| 「Mythos 会不会改变我现在的 GPT-5.4 选择?」 | 通常不会 | benchmark 领先并不会抹平 access gap。 |
| 「什么时候 Mythos 值得跟踪?」 | 当你已在 preview 里,或你负责 future-tier evals 时 | 这时 benchmark 信号才会真正变成决策输入。 |
这里最容易被写错的地方,是把两边都是真的,误读成两边是同一层对象。Anthropic 的 Project Glasswing 页面确实给了 Mythos Preview 的参与者定价和强势 benchmark;OpenAI 的 GPT-5.4 发布页也确实给了公开可用性、公开价格和上下文能力。问题不在于哪边是假,而在于它们不是同一层合同:一边是门控 preview,一边是今天就能部署的公开路线。
Claude Mythos Preview 现在到底是什么

Claude Mythos Preview 是真的,但它不是一个普通的公开模型合同。Anthropic 现在的公开说法是,它面向 Project Glasswing 合作方,以及 40 多家受邀的关键基础设施相关组织开放。这个事实很重要,因为它说明 Mythos 不是 rumor residue,也不是媒体自己拼出来的名字;但它同样说明,多数普通读者并不能把 Mythos 当成看完文章之后就能立刻采购或部署的选项。
价格层也强化了同样的边界。Anthropic 给出的数字是输入每百万 token 25 美元、输出每百万 token 125 美元,但这是参与者定价,不是与公开 API 同层的 self-serve 采购面。换句话说,这个价格只有在你已经拿到 access 时才有现实意义;如果 access 还没解决,它不能像 GPT-5.4 的公开 API 价格那样直接进入预算和上线决策。
更关键的一点是,Anthropic 截至 2026 年 4 月 9 日的公开说法,仍然是不打算让 Claude Mythos Preview 普遍可用。这不等于 Anthropic 永远不会在未来发布一个 Mythos 级别的公开模型,也不等于以后还会继续沿用这个名字。它只意味着,在当前这一轮决策里,你不应该把 Mythos Preview 当成一个默认公开路线。
所以最稳的理解方式是:Mythos Preview 是一个前沿能力信号,而不是一个普通默认项。它告诉你 Anthropic 的上限可能已经继续抬高,但它并没有自动把大多数人的当前选择从 GPT-5.4 改写掉。
GPT-5.4 今天能给你什么
GPT-5.4 则属于完全不同的一类对象。OpenAI 在 2026 年 3 月 5 日发布 GPT-5.4,并明确写出它已经出现在 ChatGPT、API 和 Codex 中。对于这篇文章来说,这不是一个边角事实,而是答案本身的一部分。因为大多数读者真正要解决的不是实验室想象力问题,而是今天能不能上、怎么上、用什么合同上。
OpenAI 公开给出的价格也更适合直接进入当前决策:输入每百万 token 2.50 美元、缓存输入每百万 token 0.25 美元、输出每百万 token 15 美元。对长上下文工作流,OpenAI 还明确说 GPT-5.4 在 API 和 Codex 工作流里支持最高 1M context。也就是说,GPT-5.4 给你的不是「未来也许更强」的信号,而是今天就能预算、测试、部署、交付的真实公开路线。
这也是为什么即便你接受 Anthropic 的 benchmark 叙事,GPT-5.4 仍然是大多数人的默认答案。默认路线不是那个最能制造未来感的模型,而是那个你这周就能把真实工作路由过去的模型。如果你下一步想看 GPT-5.4 的接入路径和成本选择,可以继续读 GPT-5.4 免费 API。如果你的工作流和 Codex 绑定更深,那么 OpenAI Codex 2026 年 3 月更新 会更实用。
官方重叠 benchmark 到底说明了什么,又没有说明什么
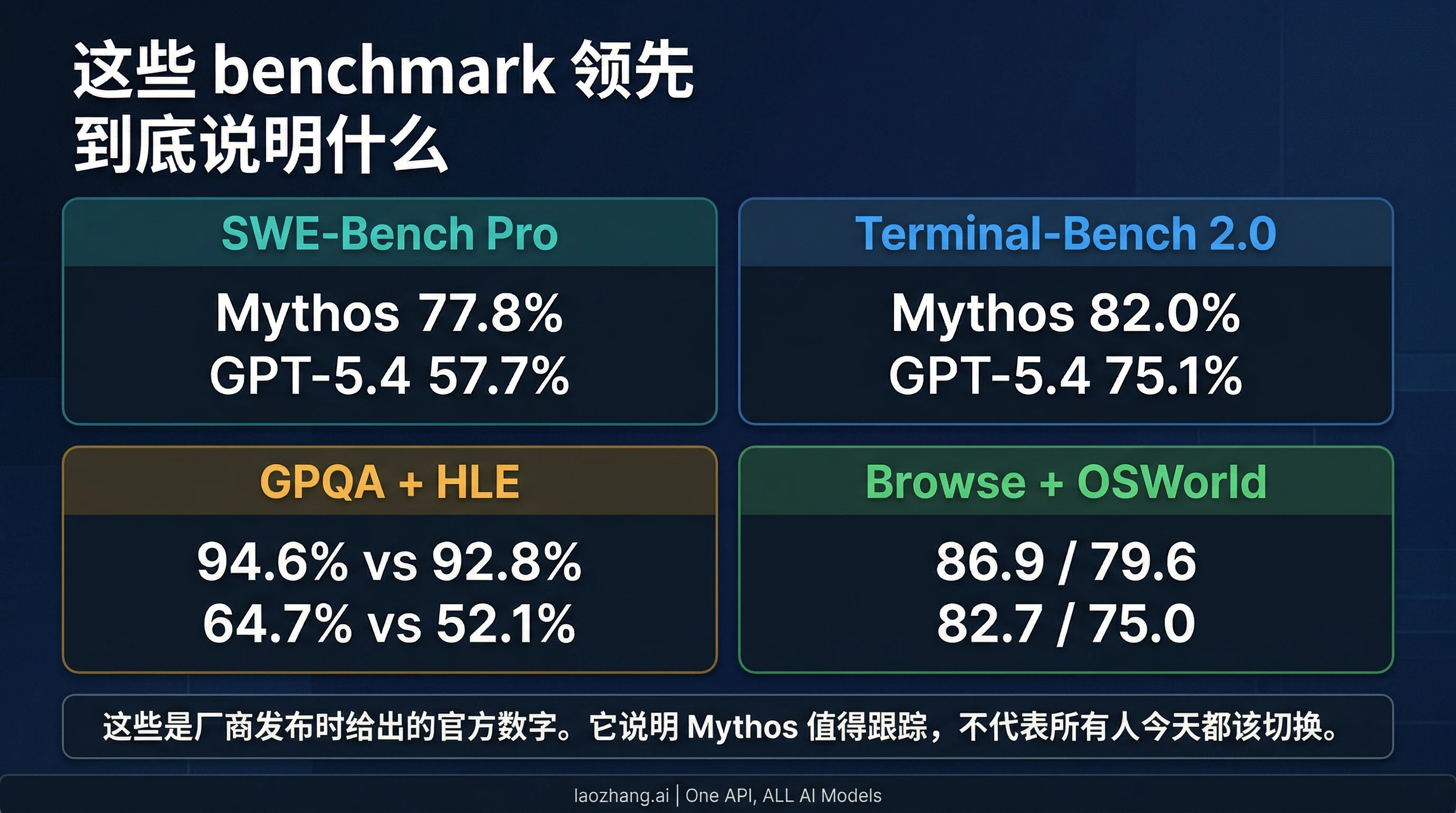
Mythos Preview 的官方 benchmark 领先是真实存在的。Anthropic 在 Project Glasswing 页面上给出的 Mythos Preview 数字包括:SWE-Bench Pro 77.8%、Terminal-Bench 2.0 为 82.0%、SWE-Bench Verified 为 93.9%、GPQA Diamond 为 94.6%、带工具的 Humanity's Last Exam 为 64.7%、BrowseComp 为 86.9%、OSWorld-Verified 为 79.6%。OpenAI 在 GPT-5.4 发布页里给出的对应数字则包括:SWE-Bench Pro 57.7%、Terminal-Bench 2.0 为 75.1%、GPQA Diamond 为 92.8%、带工具的 Humanity's Last Exam 为 52.1%、BrowseComp 为 82.7%、OSWorld-Verified 为 75.0%。
这些行数值足以让 Mythos 值得被认真跟踪。也正因为这个领先是存在的,这篇文章才值得写。如果 Anthropic 发布的是一个完全没有公共优势信号的门控 preview,那么对大多数读者来说,这个话题就不值得占据这么多注意力。
但这些数字依然不能被读成一个中立、统一、无条件适用的总排行榜。Anthropic 和 OpenAI 都是在自己的官方首发页面上给出自己的 launch benchmark。重叠名字有参考价值,但它仍然是厂商发布时给出的官方数字,而不是一张用完全相同设置、工具预算和执行条件跑出来的通用记分牌。
因此最合理的读法不是「Mythos 已经全面取代 GPT-5.4」,而是「Mythos 的领先足以让 future-tier 评测者认真关注,但还不足以改变大多数普通用户今天的公开路线选择」。这个 caveat 不是写作上的退路,而是这篇文章最重要的判断边界。
什么时候 Mythos 才真的该改变你的计划

对大多数读者来说,Mythos 不应该改变当前计划。只要你的问题仍然是「今天要用哪个模型」,答案就还是 GPT-5.4。因为它已经跨过了 access、pricing、deployment 这些当前决策真正需要的门槛,而 Mythos 还没有。
Mythos 更早变得重要的,是一小群更窄的读者。如果你已经在 preview 受众里,那么这就不再是一个抽象话题。你真的需要评估:Mythos 在你的任务上,是否值得你额外投入评测时间、流程适配成本,甚至未来迁移准备。再比如,如果你的职责本来就包括维护 frontier-model watchlist、security 评测流程、或者高端 coding 系统的升级阈值,那么 Mythos 的 benchmark 信号就不只是新闻,而是你应该提前记录的路线变化。
对其他人来说,最好的姿势是把 Mythos 当成值得继续跟踪的信号,而不是今天就要切换过去的目的地。继续推进你已经可以部署的 GPT-5.4 工作,保留清晰的评测基线,只有在 access 真的变化、或者你的组织拿到 preview 资格时,再投入额外决策成本。比起因为未来 tier 很诱人就暂停现实工作,这个姿势通常更稳。
如果你真正的问题比这篇更宽
这篇文章只适合回答一个很具体的问题:当 GPT-5.4 已经是你今天能用的模型时,Anthropic 的 Mythos benchmark 领先,会不会改变你现在的选择?
如果你真正的问题其实是「公开可用的 ChatGPT 和 Claude 到底怎么选」,那更合适的下一篇是 ChatGPT vs Claude。那篇文章解决的是公开路线对公开路线的问题,而不是门控 preview 对公开默认项的问题。
如果你真正的问题是「在 Anthropic 自己的体系里,我该继续用当前 shipping 模型,还是只跟踪 preview tier」,那应该去看 Claude Capybara vs Opus 4.6。那篇才是 Anthropic 内部路线问题的正面答案。
把问题往外路由,不是逃避,而是保证这篇文章仍然有用。它最强的时候,就是它始终保持窄焦点:Mythos 的 benchmark 领先是真实的,但对大多数人来说,GPT-5.4 仍是今天的 deployable default。
FAQ
“Claude Mythos” 和 Claude Mythos Preview 是一回事吗?
在当前公开语境里,“Claude Mythos” 往往就是对官方名字 Claude Mythos Preview 的简写。真正重要的不是简称和全名的差别,而是 Anthropic 当前把它定义成门控 preview,而不是公开 self-serve 产品。
Mythos 的参与者价格,能不能把它当成 GPT-5.4 的正常替代项?
不能。参与者价格是真实的,但它仍然绑定在门控 preview 上;GPT-5.4 的价格则绑定在公开可用路线里。这两者不是同一层采购条件。
Mythos 是不是已经“全面打赢” GPT-5.4?
更准确的说法是:Mythos 在多项重叠的厂商官方首发 benchmark 上领先。但这并不等于它在所有工作流、所有工具条件、所有 access 场景下都已经成为无条件总赢家。
如果我要比的是公开模型,是不是应该直接去看 Opus?
是。如果你的真实选择发生在公开模型之间,那么更合适的是看 ChatGPT vs Claude;如果你只想看 Anthropic 内部「preview vs shipping」的路线,则更适合看 Claude Capybara vs Opus 4.6。
最后的底线答案是什么?
Mythos 的 benchmark 领先足以让它值得继续跟踪,但还不足以把 GPT-5.4 从大多数人的当前默认项位置上拿掉。如果你今天就要用模型,先用 GPT-5.4;如果你已经在 preview 里,或者你负责 future-tier evals,再把 Mythos 纳入更窄、更真实的评测语境。