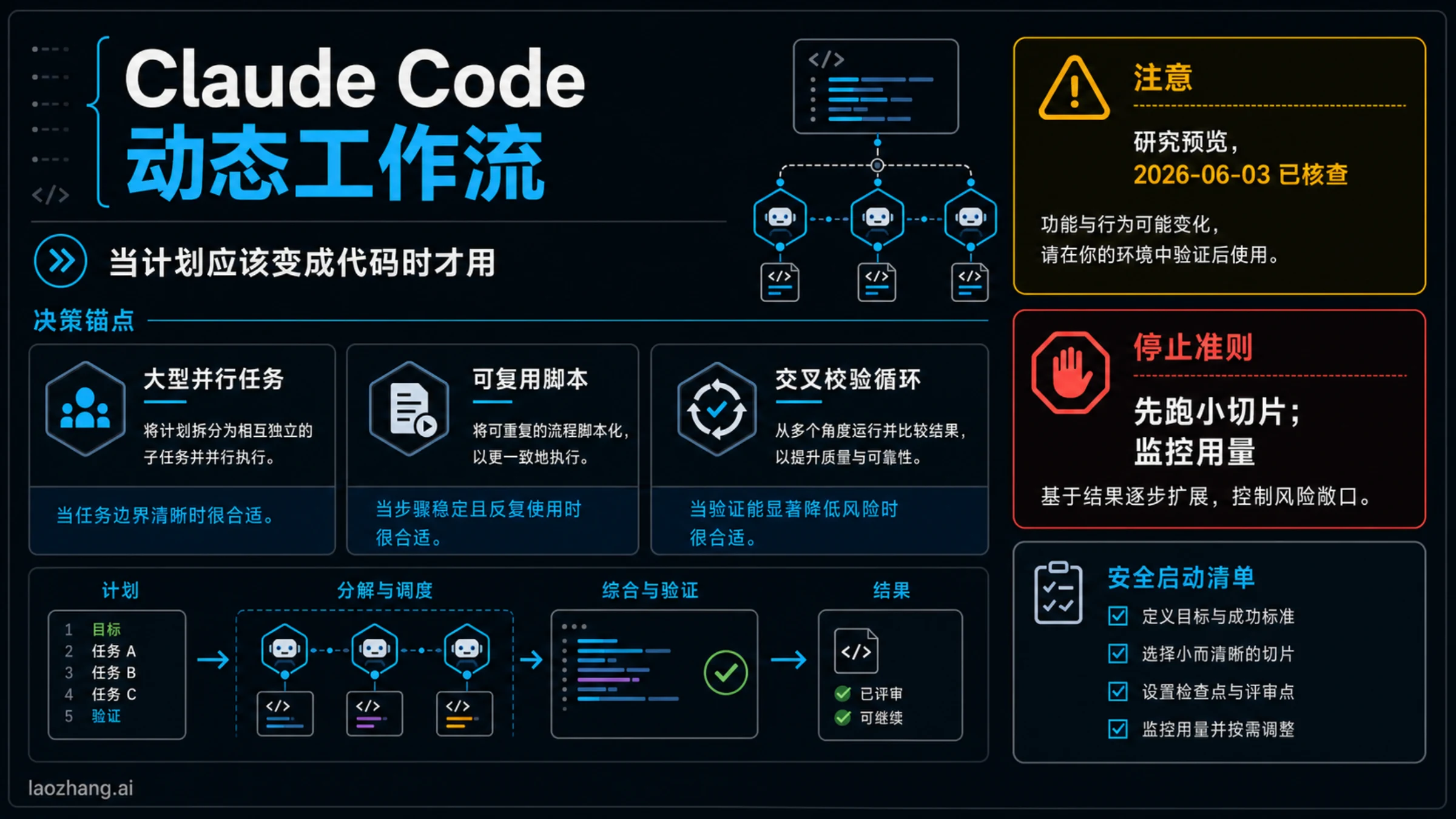
Claude Code 动态工作流不是“多开几个代理”的口号,而是把编排计划写成 JavaScript workflow 脚本,再让后台运行时协调多个子代理。只有当计划本身需要变成可检查、可复用的代码时,才值得使用它。如果一个普通 Claude Code 回合、一个子代理、一个 skill、一个 hook,或者一个 routine 已经能承担任务,就先从更小的表面开始。
截至 2026 年 6 月 3 日,Anthropic 官方文档把 Dynamic Workflows 标为 research preview,并要求 Claude Code v2.1.154 或更高版本。文档同时说明 workflow 会计入计划用量和速率限制,当前上限是最多 16 个并发代理、每次运行最多 1,000 个代理。也就是说,第一步不是“能不能更快”,而是“该不该把控制权交给一个脚本”。
| 你面前的任务 | 适合 Dynamic Workflows 的情况 | 更小表面更合适的情况 | 第一安全动作 |
|---|---|---|---|
| 大型仓库审计或迁移 | 任务能切成独立片段并相互校验 | 一个文件、一个包或一个 reviewer 能完成 | 先请求一个窄范围切片和明确验证标准 |
| 可复用研究或验证循环 | 分支计划需要保存成脚本 | 只是想让 Claude 以后记住做法 | 先做成 skill,等编排代码有价值再升级 |
| 工具密集实现 | 子代理需要不同读写和命令上下文 | 只需要确定性的事件规则 | lifecycle 类问题优先用 hooks |
| 定时或无人值守任务 | workflow 只是更大运行时的一部分 | 频率、重试和外部状态才是真正 owner | 留在 routine 或外部 job system |
| ultracode 探索 | 想让 Claude 判断是否需要 workflow | 已知简单会话能完成 | 保持小范围并打开 /workflows 观察 |
停止规则很简单:不要把第一次 workflow 用在全仓迁移、宽泛研究或高权限执行上。先让 Claude 只处理一个小切片,只批准这个切片需要的工具,在 /workflows 中观察运行状态和 token 消耗,再根据证据决定停止、保存、恢复或扩大范围。
计划变成脚本后到底改变了什么
关键变化是计划的位置。普通 Claude Code 会话里,计划保存在当前对话上下文中,工具调用、观察、修正也都挤在同一条对话里。动态工作流则让 Claude 先写一个 JavaScript orchestration script,后台 runtime 执行这个脚本,脚本再启动子代理、分配分支、收集中间结果,最后汇总成一个答案。
这种结构适合“分开做、互相看、最后合成”的任务。安全审计、跨包迁移、架构风险梳理、文档声明核验,都可能需要多个干净上下文分别检查。workflow 的价值不是代理数量本身,而是这些上下文能否提供更好的证据、更少的上下文污染和更清晰的复核路径。
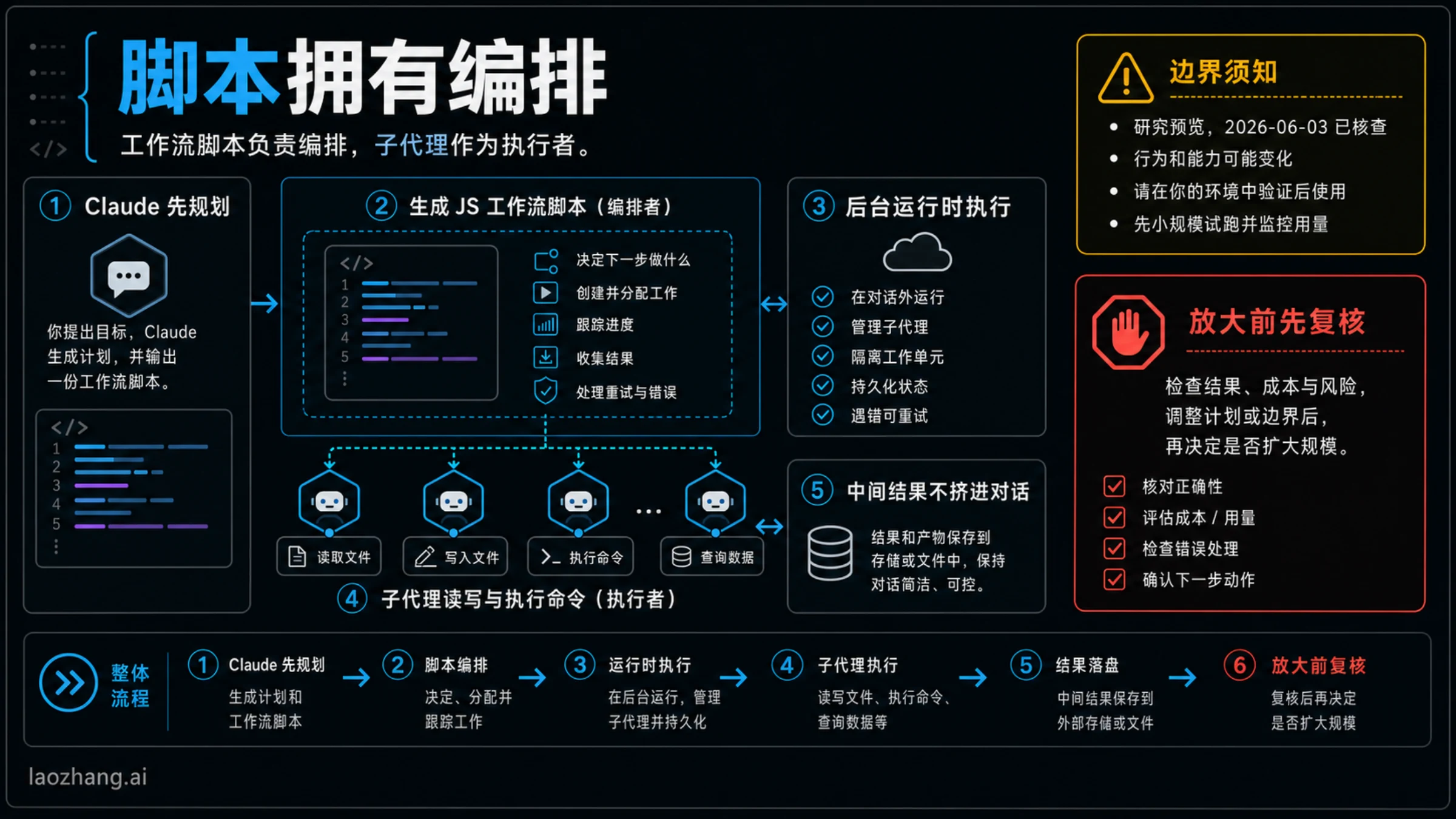
代价也很直接。workflow 不再像聊天那样每一步都等你补充说明;除权限提示之外,中途不会自然停下来问你下一句。子代理可以按照你允许的工具读文件、写文件、运行命令。第一次使用时,最重要的不是把功能跑满,而是证明脚本的分工和验证比普通会话更可靠。
| 部件 | 负责什么 | 你要观察什么 |
|---|---|---|
| Claude Code 会话 | 初始请求、批准路径、最终复核 | 任务是否真的需要编排 |
| workflow 脚本 | 分支、子代理调用、合成路径 | 计划是否可读、可保存、可复用 |
| 子代理 | 独立上下文里的检查或实现 | 是否越界写文件、重复探索或漏验证 |
| /workflows | 运行管理、用量可见性、保存决策 | 是否该停止、保存、恢复或缩小范围 |
如果脚本只是“让一个代理改一个文件”,它就不值得成为 workflow。如果脚本把迁移、审计、验证或多方案比较的规则保存下来,并且以后还会复用,它才开始有意义。
它和 subagents、skills、hooks、routines 的边界
Dynamic Workflows 不是其他 Claude Code 表面的替代品。更准确的判断方式是:谁应该拥有计划、运行时、方法和触发时机。
| 表面 | 最适合拥有的东西 | 该用它的情况 | 不该升级为 workflow 的原因 |
|---|---|---|---|
| 普通 Claude Code 会话 | 一个实时对话 | 一个上下文能完成并复核 | 任务听起来复杂不等于需要编排脚本 |
| Subagent | 一个专门 worker | 需要一个独立 reviewer 或 investigator | 只有一个视角就够时,workflow 只会增加成本 |
| Skill | 可复用方法 | 方法比运行时分支更重要 | 想记住步骤,不等于要后台 runtime |
| Hook | 确定性事件规则 | 某个命令应在事件前后自动触发 | deterministic rule 不需要子代理群 |
| Routine | 定时或无人值守运行时 | 时间、外部触发和重试拥有任务 | workflow 不是调度系统 |
| Dynamic Workflow | JavaScript 编排脚本 | 分支计划本身需要成为代码 | 代理多并不等于结果好 |
这些退出路线是安全设计的一部分。重复方法先写 skill。确定性检查先写 hook。每天自动跑的仓库巡检看 routines。跨产品选择再看 Claude Code vs Codex 或 hosted agent 页面。Dynamic Workflows 赢的只有一类场景:编排计划值得被看见、保存和改进。
ultracode、deep research 和 /workflows 分别负责什么
入口容易混淆。直接请求 workflow 是最清楚的方式:你告诉 Claude 这个任务需要动态工作流,并要求它先说明计划、分工和验证标准。/deep-research 更适合研究型任务,尤其是多路径资料收集和交叉验证。/workflows 是观察和管理运行的地方,不是泛泛的“更高智力按钮”。
ultracode 则是一个会话设置。官方 model config 文档把它和普通 effort level 区分开:它会使用很高的努力设置,也会让 Claude 在实质性任务中考虑动态工作流。它不是保存好的 workflow,也不是固定价格档,更不是“所有任务都应该开 workflow”的授权。
| 需求 | 先用什么 | 理由 |
|---|---|---|
| 明确要一次编排运行 | 直接请求 workflow | 决策可见,便于复核 |
| 多路径研究综合 | /deep-research | 研究形态更匹配 |
| 想让 Claude 判断复杂任务是否值得编排 | ultracode | 保留探索空间,但必须观察用量 |
| 查看、停止、保存、恢复 | /workflows | 运行状态和 token 可见 |
| 复用已经证明有效的计划 | 保存的 workflow 文件 | 把计划变成可审计资产 |
如果你在旧版本上排查行为差异,版本也要写进判断。当前页面的建议是先升级,再在本机 /config 和 /workflows 中验证功能状态,而不是根据帖子里的旧触发词来推断。
第一条 workflow 应该怎么安全启动

开始前先做三项测试。第一,任务能否切成输入输出清晰的独立片段。第二,价值是否来自比较和验证,而不只是“同时做更多事”。第三,编排脚本是否可能在未来复用。如果这三项有一项不成立,先不要用 Dynamic Workflows。
一个好的首跑请求应该窄到当天就能复核。不要说“迁移整个 repo”。更好的写法是:只处理 auth package 和相关测试;目标是找出三个迁移风险、给出 patch 建议,并用现有测试命令验证;不要编辑包外文件;写入前请求权限;在扩大范围前报告用量和未解决风险。
这个请求同时限制了范围、工具、验证和扩展条件。你想要的结果不是“很多代理跑了很久”,而是一个判断:这套 workflow 形状是否比普通 Claude Code 会话提供了更好的证据。如果没有,就停止或缩小。
运行中保持 /workflows 可见。看它是否把 token 用在真正独立的工作,而不是重复探索;看权限提示是否超过切片需要;看合成结果是否说明每个子代理验证了什么。只有这些信号成立,才考虑保存或扩大。
成本、限制、权限和禁用层

动态工作流不是免费的并行能力。官方文档说 workflow 会计入计划用量和速率限制,而且同一个任务用 workflow 可能比单一对话消耗更多 token。/workflows 可以看 workflow 的 token 使用情况,/usage 则适合看更广的 Claude Code 用量。
截至 2026 年 6 月 3 日,当前实现限制是最多 16 个并发代理、每次运行最多 1,000 个代理。这个上限足够强,也足够危险。松散提示会很快把预算花在重复探索上。
权限控制从启动前就开始。子代理能不能写文件、能不能运行命令、能不能访问某些路径,取决于你允许的工具和批准模式。第一次运行应当限制路径、限制命令、设置复核点。团队环境里还要提前知道谁拥有禁用开关。当前文档提到的层级包括 /config、disableWorkflows、CLAUDE_CODE_DISABLE_WORKFLOWS=1、managed settings 和 admin settings。
| 预检问题 | 为什么重要 | 要留下的证据 |
|---|---|---|
| 当前版本是什么 | 低版本行为可能不同 | claude --version 或本地版本检查 |
| 功能是否启用 | plan/provider 可变 | /config 和同日官方文档 |
| 最小有价值切片是什么 | 防止首跑过宽 | 路径、目标、验证标准 |
| 允许哪些工具 | 子代理可能写入和执行命令 | approval mode、allowlist、禁止面 |
| 如何看用量 | workflow 更耗 token | /workflows、/usage、rate-limit 信号 |
| 谁能禁用 | 团队需要 kill switch | settings、env、managed 或 admin 层 |
答不出这六个问题,就不要跑宽范围 workflow。先用普通会话、单个子代理或 skill。
适合的例子和不适合的例子
适合的任务通常有共同点:多个干净上下文能提供更好的证据,并且最后需要合成比较。大迁移适合,因为不同 package 可以独立处理再统一验证。安全审计适合,因为依赖风险、权限边界、数据暴露、测试覆盖可以分开检查。声明核验适合,因为文档、代码、运行结果可以由不同代理交叉确认。
不适合的场景也常见。单文件重构不该因为重要就变成 workflow。确定性 pre-commit 行为该是 hook。可复用提示方法该是 skill。每天早上自动巡检仓库更像 routine。基础错误解释仍然应该留在一个对话里,直到真正出现多分支验证需求。
还有一种团队风险:用 workflow 掩盖不确定性。如果团队说不清每个子代理要证明什么,workflow 只会让活动看起来更严谨,证据却更难审。先写验证标准,再决定代理数量。
成功后应该保存什么
成功运行不等于应该保存。值得保存的 workflow 应该像项目自动化资产,而不是一段聊天记录。它要说明 owner、输入、允许工具、停止规则、验证标准和复用规则。
| 保存项 | 应写清楚 |
|---|---|
| Owner | 归哪个 repo 区域、团队或发布任务所有 |
| 触发意图 | 手动研究、迁移切片、审计 harness 或其他路线 |
| 输入 | 目标路径、分支假设、测试命令、要查的文档 |
| 工具边界 | 预期读写和命令范围 |
| 停止规则 | 什么时候停止而不是继续扩大 |
| 验证 | 测试、对比、review 证据 |
| 复用规则 | 什么情况下值得再次运行 |
如果任务只是“记住这个方法”,skill 更干净。如果任务是“每天定时跑”,routine 或外部 scheduler 更像真正 owner。workflow 的保存理由应该是:脚本化编排比普通提示更容易检查、复用和改进。
团队落地前还要检查什么
把 Dynamic Workflows 引入团队时,真正需要治理的不是“能不能开 16 个并发代理”,而是谁拥有 workflow 的边界。一个经过验证的 workflow 应该有明确 owner、允许工具、停止条件、验证证据和回滚路径。否则它只是一次看起来自动化的个人探索,很难交给同事复用。
先把第一次运行的证据写下来:请求原文、目标路径、被批准的工具、Claude 写出的 workflow 分工、/workflows 中看到的用量、每个子代理带回的证据、失败分支、最终测试命令和未解决风险。只有这些内容能被另一个人复核,保存 workflow 才有意义。保存文件本身不等于治理,能解释它为什么存在才算。
| 团队复核项 | 通过标准 | 不通过时的动作 |
|---|---|---|
| Owner | 有 repo 区域、负责人或发布任务 | 先不要保存到共享 workflow 目录 |
| 权限边界 | 写入路径和命令范围可解释 | 缩小 scope 或改回普通会话 |
| 用量证据 | /workflows 和 /usage 中能看到成本压力 | 降低并发、减少分支或停止 |
| 验证证据 | synthesis 说明每个子代理验证了什么 | 重写验证标准,不扩大范围 |
| 禁用路径 | /config、settings、env 或 admin 层可执行 | 先补 kill switch 再推广 |
还要避免把 workflow 当作组织流程的捷径。动态工作流适合把复杂计划脚本化,但它不替代 code review、release checklist、incident response 或权限审批。更稳妥的方式是先让它服务一个具体场景,例如小范围迁移审计、文档声明核验、跨包测试分诊;等结果稳定后,再把脚本、说明和复跑条件一起进入项目文档。
如果 workflow 生成了 patch,最后 review 不应只看 diff。要看每条分支为什么存在、哪些证据互相印证、哪些分支失败、是否有代理重复探索、测试是否覆盖目标风险。Dynamic Workflows 的优势是把分支和交叉验证带回来;如果最终合成没有提供这些证据,就说明任务太宽,或者 verification bar 写得不够具体。
在中文团队语境里,还要把“谁批准”和“谁复核”分开。批准工具的人不一定是最终接受 patch 的人,最终接受 patch 的人也不一定拥有 workflow 的长期维护。建议把三件事写清楚:谁能允许 workflow 读写哪些目录,谁在运行后检查子代理证据,谁在保存后负责清理过期假设。尤其是 research preview 功能,版本、可用性、上限和禁用方式都可能变化,保存 workflow 时要同时保存检查日期,而不是把一次运行当成永久流程。
还有一个容易漏掉的点:不要把动态工作流的结果直接升级为团队标准。先让第二个人在相同输入上复跑或审读脚本,确认分支命名、工具边界和合成口径都能理解,再决定是否进入共享目录。这样能把一次成功运行和可维护自动化区分开。复跑记录也要包含同一组验证命令、失败差异、人工接受或拒绝理由,以及本次是否触发禁用开关。缺少这些记录时,workflow 只能算探索资产,不能算团队默认路径。共享前还要标明适用仓库、适用分支、允许失败范围,以及下一次官方文档复核日期,防止旧 workflow 在新版本里误用,也避免权限边界被默认放大。
如果 workflow 被用于客户项目、生产迁移或安全审计,还应该先定义“不可自动扩大”的边界。比如不得跨出目标 package,不得新增依赖,不得修改部署配置,不得在没有人工确认时执行破坏性命令。这些规则写进首跑请求,比事后解释为什么代理做多了更可靠。Dynamic Workflows 的价值是让复杂分工可见,而不是让不确定动作自动化。 最后,把保存和复用分开判断。一次运行成功,只能证明这个切片可行;复用需要证明输入形态稳定、工具边界稳定、验证命令稳定,并且下一次运行仍然比普通 Claude Code 会话更容易审计。达不到这个标准时,把经验整理成 skill、hook 或 routine,通常比保存一个宽泛 workflow 更清楚。
常见问题
Dynamic Workflows 和 subagents 一样吗?
不一样。subagent 是独立上下文里的 worker。Dynamic Workflow 是可以协调多个 worker 的脚本编排层。一个专门 reviewer 足够时用 subagent;计划、分支和合成需要脚本化时才用 workflow。
ultracode 到底做什么?
ultracode 是会话设置,不是保存的 workflow。当前文档把它描述为很高 effort 加上让 Claude 在实质任务中考虑 dynamic workflows。它会提高编排可能性,但不代表每个提示都该 fan out。
/deep-research 是 workflow 吗?
它是研究型 workflow 行为的入口之一。资料收集和多路径综合可以从 /deep-research 开始;代码迁移、审计和实现任务则应该明确写出 workflow 的范围、工具和验证标准。
保存的 workflow 放在哪里?
当前文档提到 .claude/workflows/ 和 ~/.claude/workflows/。保存后应像自动化资产一样管理,而不是当成聊天缓存。
能以后 resume 吗?
当前文档把 resume 和同一 Claude Code session 绑定。离开时仍在运行的 workflow,下一次 session 会重新开始。离开前应在 /workflows 中检查、保存或停止。
它会很贵吗?
没有安全的固定价格。官方边界是:会计入用量和速率限制,且可能比单一对话消耗更多 token。实务答案是先跑小切片,观察 /workflows 和 /usage,再决定是否扩大。
怎么禁用?
当前文档提到 /config、disableWorkflows、CLAUDE_CODE_DISABLE_WORKFLOWS=1、managed settings 和 admin settings。个人先看 /config;团队要明确 settings、env 或 admin 层谁负责。
它会替代 routines、hooks 或 skills 吗?
不会。workflows 负责脚本拥有的编排。routines 负责无人值守或定时运行。hooks 负责确定性事件规则。skills 负责可复用方法。谁更像真正 owner,就用谁。