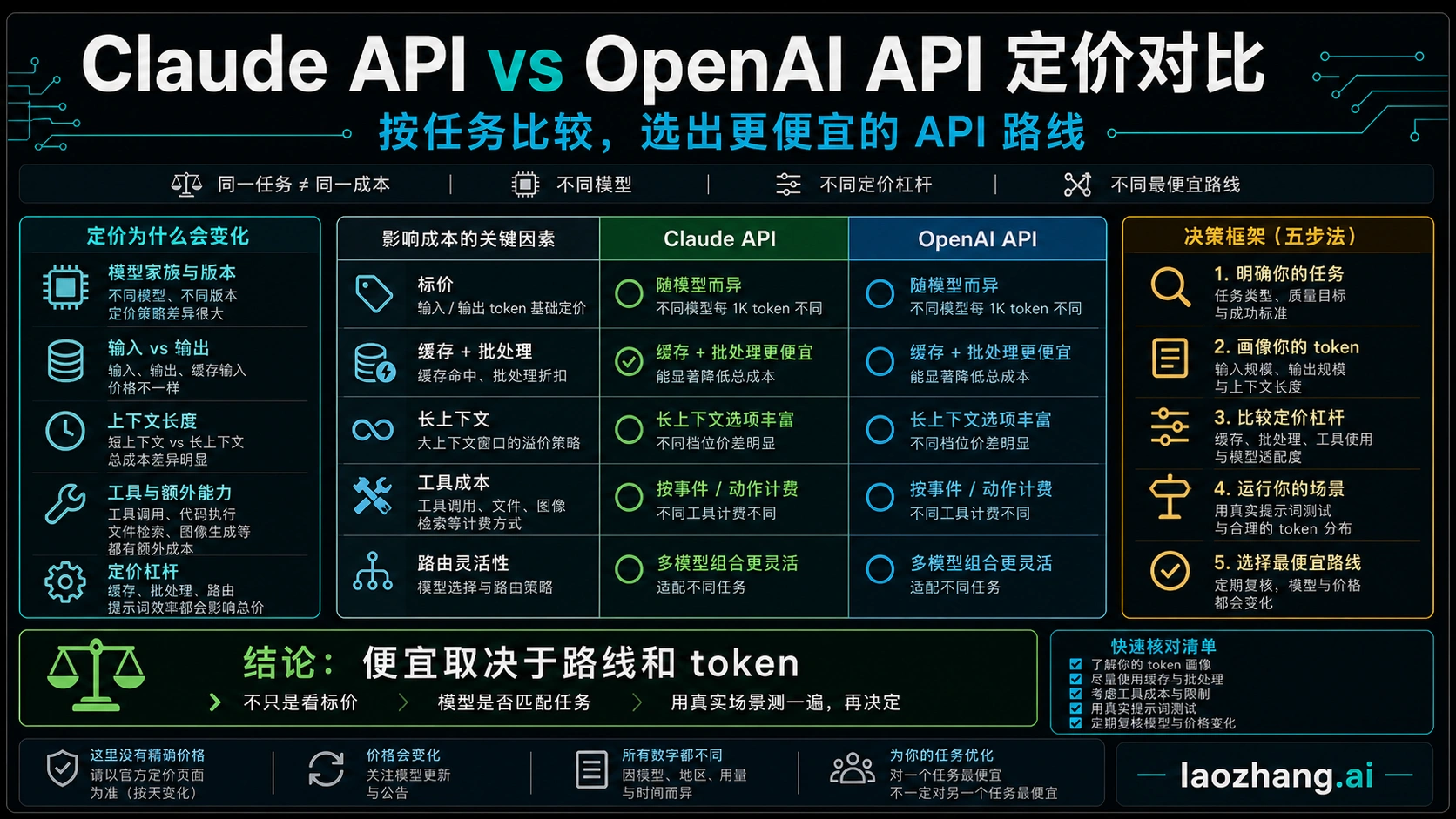
Claude API 和 OpenAI API 哪个更便宜,不能只看一行模型标价。如果你的任务是高频、短上下文、输出很短,并且 GPT-5.4 mini 就能稳定完成,OpenAI 通常是更便宜的起点。如果任务需要长上下文、复杂 Agent、代码推理、高缓存复用,或者 Claude 在一次通过率上明显更稳,Claude 的真实总成本也可能更低。
本文按 2026-05-02 的官方页面核验:OpenAI 价格页列出 GPT-5.5 为每 100 万 token 输入 5 美元、缓存输入 0.50 美元、输出 30 美元;GPT-5.4 为 2.50 / 0.25 / 15 美元;GPT-5.4 mini 为 0.75 / 0.075 / 4.50 美元。OpenAI 的 GPT-5.5 发布说明在 2026-04-24 更新为 GPT-5.5 和 GPT-5.5 Pro 已在 API 可用,但生产环境仍必须确认自己的账号里是否已经能用该模型。Anthropic 价格页列出 Claude Opus 4.7 为输入 5 美元、输出 25 美元,Sonnet 4.6 为 3 / 15 美元,Haiku 4.5 为 1 / 5 美元,并且单独说明缓存、批处理、数据驻留、长上下文和工具调用价格。
快速结论:先选任务,再选服务商
| 任务类型 | 先测试的便宜路线 | 原因 |
|---|---|---|
| 分类、抽取、短摘要、简单客服话术 | OpenAI GPT-5.4 mini | 基础输入和输出价格低于 Claude Haiku 4.5。 |
| 复杂代码、专业推理、GPT-5.5 已在账号中可用 | GPT-5.5 与 Claude Opus 4.7 同题测试 | GPT-5.5 输出价更高,Opus 4.7 输出价更低,但重试次数会改变总成本。 |
| 几十万到百万 token 的长文档分析 | Claude Opus 4.7 或 Sonnet 4.6 值得单独测试 | Anthropic 明确把 Opus 4.7、Opus 4.6、Sonnet 4.6 的 1M 上下文写入标准定价边界。 |
| 大批量离线总结、评测、清洗 | 两边都先看 batch | 两家都提供批处理折扣,前提是任务可以等待。 |
| 稳定系统提示、工具 schema、RAG 上下文反复复用 | 比缓存命中率,而不是只比标价 | 缓存命中能显著降低输入侧成本。 |
当前价格行只是锚点,不是最终答案

基础表格会给你一个方向:GPT-5.4 mini 比 Claude Haiku 4.5 更便宜;GPT-5.4 与 Claude Sonnet 4.6 的输出价格相同,OpenAI 输入更低;GPT-5.5 与 Claude Opus 4.7 的输入价格相同,但 Opus 4.7 输出价格更低。真正上线时,不能把这些行直接当作最终结论。
原因是总成本由成功完成任务的成本决定。模型如果需要更多重试、更长输出、更复杂工具调用,低单价也会被抵消。Claude 如果一次通过率更高,或者长上下文减少切块和中间总结,较高输入价格也可能变成更低总成本。OpenAI 如果用 mini 模型就能过质量线,则没有必要用 frontier 行去比较。
缓存和批处理会改写赢家
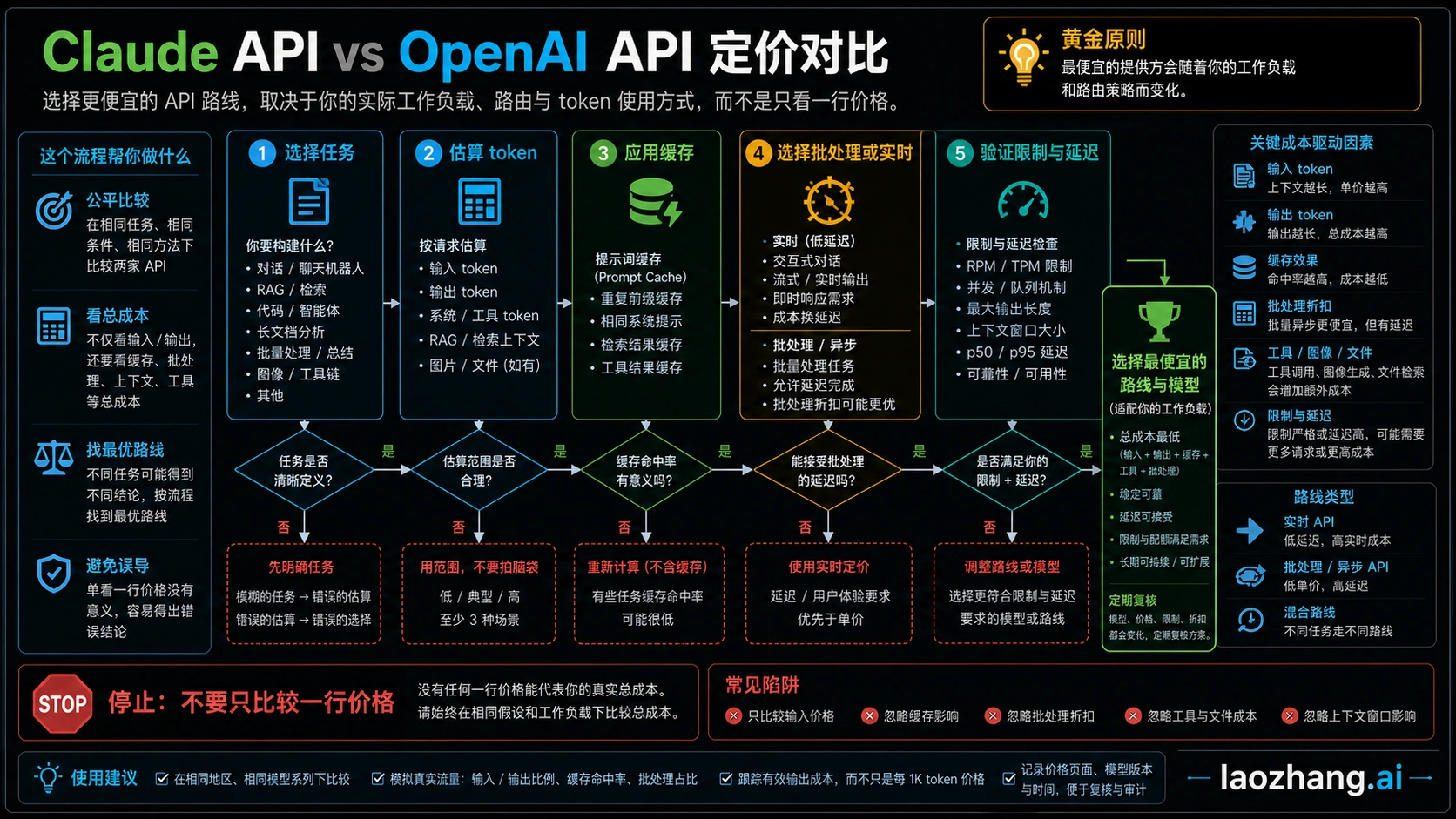
缓存适合系统提示、政策文本、工具 schema、固定 RAG 文档和长会话前缀。Anthropic 写入 5 分钟缓存按基础输入价 1.25 倍,1 小时缓存按 2 倍,命中读取按 0.1 倍。OpenAI 价格页也列出缓存输入行。你要分开算第一次写入和后续读取,不能把所有输入都按同一个价格算。
批处理适合非实时任务。OpenAI 写明 Batch API 对输入和输出节省 50%,Anthropic 也列出 50% 批处理折扣。只要任务能等 24 小时左右,批处理可能比换供应商更重要。反过来,如果你的场景是在线对话、低延迟 Agent 或交互式代码修复,批处理折扣就不能强行套用。
什么时候 OpenAI 是默认便宜路线
当任务短、稳定、量大、质量门槛不需要旗舰模型时,先测 OpenAI。典型例子是分类、抽取、JSON 转换、标题生成、短客服草稿、短摘要和格式化重写。只要 GPT-5.4 mini 能稳定过线,它通常比把任务直接送到 Claude Sonnet 或 Opus 更省。
如果 GPT-5.5 尚未出现在你的 API 账号里,也不要把它写进生产成本表。用当前可用的 GPT-5.4 或 GPT-5.4 mini 与 Claude 的官方行比较,并把 GPT-5.5 标成待账号确认的路线。
什么时候 Claude 更值得花钱
Claude 的优势常出现在长上下文、复杂 Agent、代码库理解、多文档分析、合同审阅和高缓存复用场景。这里的关键不是每百万 token 单价,而是能否减少切块、减少中间总结、减少失败重试、减少人工修正。
Anthropic 还提示 Opus 4.7 的新 tokenizer 可能让同一段固定文本多出最多 35% token。这个细节说明,不能拿字数直接估算两家的输入成本。上线前应该用真实 tokenizer、真实样本和真实输出长度跑一遍低、中、高三种场景。
自己做成本表
| 成本项 | 需要记录什么 |
|---|---|
| 输入 token | 系统提示、用户提示、RAG 文档、工具 schema、文件和图像相关输入 |
| 输出 token | 最终答案、代码、JSON、解释、错误恢复内容 |
| 缓存输入 | 首次写入多少,后续读取多少,命中率是多少 |
| 批处理 | 任务能否等待,相关功能是否支持 batch |
| 工具费用 | Web search、code execution、image、server-side tools 是否另收费 |
| 重试率 | 失败、质量不够、截断、人工重跑各出现多少 |
| 路线溢价 | 数据驻留、区域端点、优先处理、fast mode 是否加价 |
上线前核验清单
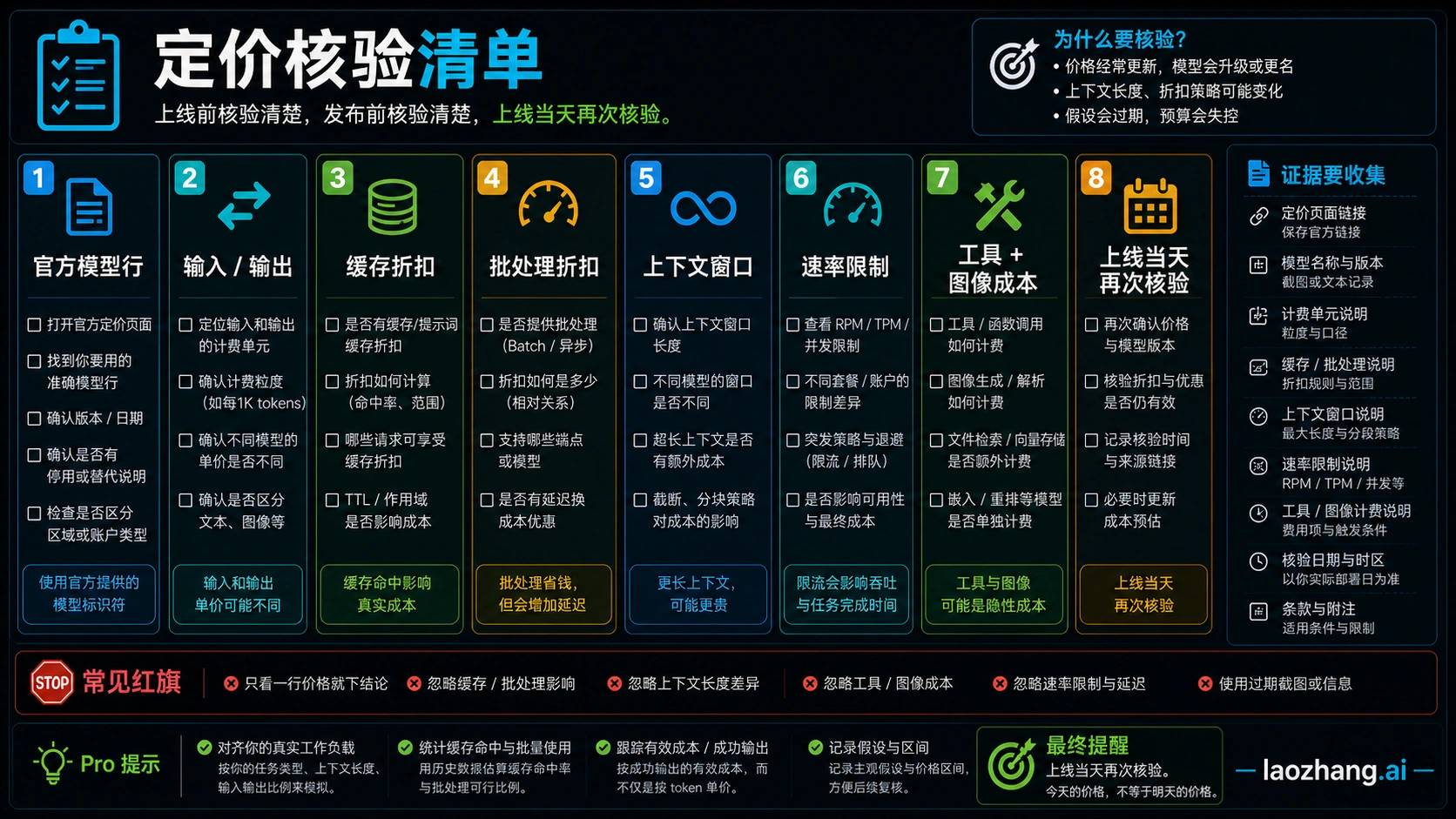
上线当天重新打开 OpenAI API Pricing、GPT-5.5 发布说明 和 Anthropic Pricing。确认模型是否在账号中可用、价格是否变化、缓存和批处理是否适用、上下文窗口和速率限制是否满足、工具调用是否另收费。第三方博客和计算器只能当场景灵感,不能当官方价格源。
还要补两组真实样本
如果团队已经有线上流量,不要只拿一个平均请求来算。至少抽三组样本:短输入短输出、长输入短输出、长输入长输出。每组分别记录输入 token、输出 token、缓存可复用部分、是否能改成批处理、以及失败后是否需要人工重跑。这样你会看到不同任务的赢家并不相同:短任务可能被 mini 模型拉低成本,长任务可能被上下文保持和低重试率拉低成本。
第二组样本要专门测边界情况。把最大文档、最大工具 schema、最容易超时的 Agent loop、最需要引用检查的回答拿出来,分别跑 Claude 和 OpenAI。记录截断、格式错误、事实补查、人工修复时间和最终可交付率。真正贵的不是某一行 token 价格,而是低价路线导致的返工、排队、重试和人工检查。
最后把结果写成一张内部路由表:哪些任务默认走 OpenAI,哪些任务进入 Claude 复测,哪些任务只能在官方价格页再次确认后上线。这个表比一次性的价格结论更有用,因为模型名称、缓存规则和账号权限都会变化。每次价格页、账号权限或上下文窗口变化后,只更新路由表的证据列和停止规则,不要重写成新的主观判断。这样团队下次换模型时还能沿用同一套核验口径,减少争议。
常见问题
Claude API 和 OpenAI API 哪个更便宜?
简单高频任务通常先测 OpenAI,尤其是 GPT-5.4 mini 足够时。长上下文、Agent、缓存复用或 Claude 一次通过率更高的任务,需要把 Claude 放进真实场景表里比较。
GPT-5.5 能直接和 Claude Opus 4.7 比吗?
可以,但必须注明日期和账号可用性。OpenAI 已列出 GPT-5.5 价格,并在 2026-04-24 更新说明 GPT-5.5 已在 API 可用;Anthropic 已把 Opus 4.7 列为当前 Claude API 价格行。如果账号里没有 GPT-5.5,就先用 GPT-5.4 系列比较。
缓存一定省钱吗?
不一定。只请求一次的内容可能只支付写入成本而没有读取收益。只有大段内容被多次复用,缓存才会明显改变总成本。
批处理是不是永远该用?
不是。批处理适合离线总结、评测、分类和数据清洗;实时对话和低延迟 Agent 不能为了折扣牺牲交互体验。