
如果你的显卡只有 16GB 显存,本地编程 LLM 的第一问题不是“哪一个模型最强”,而是“哪一条路线能稳定完成真实代码任务”。更稳妥的起点是 gpt-oss-20b;更激进的尝试是 Qwen3.6 35B A3B 的低比特或 offload 组合;更轻的回退是 Gemma 4 E4B 或已经验证过的中小型代码模型。
16GB 显存可以跑出有用的本地代码助手,但它不会自动变成大型仓库代理。模型权重、KV cache、长上下文、工具包装层、编辑器插件和系统内存都会抢预算。一个模型在短 prompt 下能启动,不等于它能看懂多文件变更、保持测试上下文并稳定产出补丁。
截至 2026-07-03,本页把官方说明、运行时页面和社区经验分开处理:官方和运行时负责内存级别与包体边界,社区结果只说明有人在尝试什么。需要发布为日常路线的模型,必须先通过你自己代码仓库里的烟测。
直接答案:先装 gpt-oss-20b,跑一个真实函数和测试文件的改动;如果质量不够,再用短上下文测试 Qwen3.6 低比特路线;如果速度、稳定性或显存压力不合格,退回更小模型、升级显存,或把多文件代理任务交给托管编码工具。
快速结论:先选路线,不要先排冠军
16GB 显存的推荐表应该是路线表,而不是冠军榜。中文公开讨论里有 Reddit 问答、CSDN 和技术博客,也有直接给模型名的简短答案,但多数内容没有把“能装载”“能保持上下文”“能改代码”拆开。
下面这张表把读者真正要做的决定压到第一屏:先选起步路线,再按失败信号切换。
| 路线 | 先试模型 | 为什么适合 16GB 问题 | 主要风险 | 下一步 |
|---|---|---|---|---|
| 稳妥起步 | gpt-oss-20b | 官方与运行时材料更接近 16GB 级别 | 能力上限不是无限仓库代理 | 先安装并跑烟测 |
| 进阶实验 | Qwen3.6-35B-A3B 低比特或 offload | 社区和 AI 摘要常把它当能力候选 | 常规包体和内存要求不是干净的 16GB 保证 | 只用短上下文验证 |
| 轻量回退 | Gemma 4 E4B-it | 显存压力低,响应更稳 | 深仓库推理未必最强 | 用于窄任务和快速辅助 |
| 代码专用回退 | Qwen2.5-Coder、Qwen3-Coder、DeepSeek Coder 变体 | 代码家族适合函数解释、补丁和小范围重构 | 具体量化包决定可行性 | 先看模型文件和上下文设置 |
| 停止 | 更大显存或托管编码 | 长上下文和多轮工具调用会超过 16GB 舒适区 | 继续硬调会消耗开发时间 | 出现 OOM、慢 offload 或上下文丢失就停 |
证据边界:官方、运行时和社区不能混用
gpt-oss-20b 负责稳妥起点,是因为 OpenAI 与主流本地运行说明把它放在 16GB 显存或统一内存级别。这个结论不等于它在所有代码 benchmark 上第一,而是说它的内存证据更干净,第一次安装更少依赖猜测。
Qwen3.6 35B A3B 的定位更诱人:它面向 agentic coding 和仓库级推理,多语言公开讨论里也经常被推到 16GB 候选位。但 Ollama 标准包、LM Studio 页面和实际低比特构建不是同一个证据面。低比特能不能用,要看量化、上下文、GPU 架构、系统内存和 offload。
Gemma 4 E4B 的价值不是“最大”,而是“更少被显存卡住”。它适合解释函数、写小 helper、复查短 diff、生成测试思路。对 16GB 机器来说,速度和上下文稳定性常常比参数规模更能决定日常体验。
社区帖子仍然有价值,因为它们暴露了真实硬件组合:RTX 4060 Ti 16GB、5060 Ti 16GB、RX 7800 XT、笔记本统一内存、Ollama、LM Studio、GGUF。它们不能单独变成发布承诺,因为很多帖子没有固定模型文件、量化版本、上下文长度和驱动环境。
所以每一个模型名都要绑定证据来源:官方负责模型定位,运行时负责包体和内存提示,社区负责需求和失败样本。把三者混成一句“最佳模型”会误导读者。

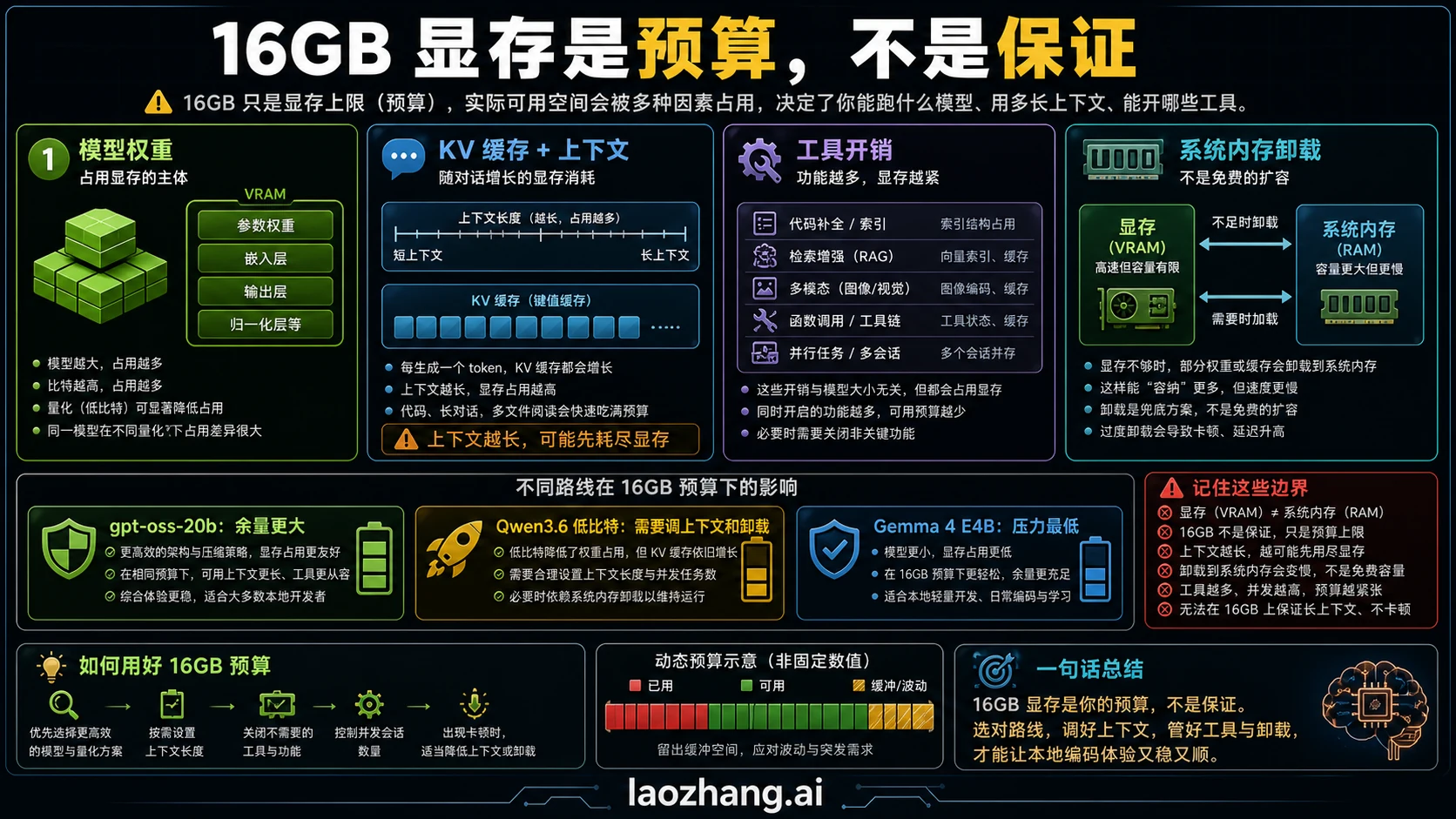
16GB 显存真正买到的是什么
显存是 GPU 上的专用内存,不是系统 RAM,也不是磁盘空间。模型权重、运行时 buffer、KV cache、上下文窗口和工具层都会在这里或系统内存里留下压力。你把上下文从 4k 提到 16k,可能模型没有变,显存表现却完全不同。
本地编程比普通聊天更吃内存,因为它要保留文件片段、函数定义、测试失败信息、补丁意图和多轮反馈。一个模型能回答“写一个排序函数”,并不代表它能在真实仓库里连续保持约束。
offload 可以让部分工作转到 CPU 或系统内存,但代价通常是延迟。对编程助手而言,延迟不是小问题:如果每次补丁都要等很久,开发者会停止使用它,即使模型偶尔能给出更聪明的答案。
16GB 的现实价值,是能让一个中等路线在本地完成隐私友好、低成本、短上下文的代码辅助。它不适合承诺大型 monorepo 的全自动代理工作。
| 压力来源 | 对代码任务的影响 | 16GB 下的处理方式 |
|---|---|---|
| 模型权重 | 决定模型能否启动并保留推理质量 | 优先选明确的 16GB 级别包 |
| KV cache | 长上下文会快速吃掉剩余显存 | 逐步增加 context,不一次性塞仓库 |
| 工具层 | IDE、server、tokenizer 和 wrapper 会增加额外开销 | 先用 CLI 建基线 |
| offload | 可避免 OOM,但通常增加延迟 | 只在速度仍可接受时保留 |
路线一:把 gpt-oss-20b 当作稳妥起点
把 gpt-oss-20b 作为第一步,是为了得到一个可解释的基线。基线的作用不是赢下所有模型,而是在你的机器、运行时和仓库里证明:本地模型可以稳定读取一个小范围任务,输出可 review 的补丁,并说清需要哪个测试。
先不要把仓库全塞进去。选择一个文件、一个临近测试、一个明确问题,让模型解释函数、提出最小改动、给出 patch,并说明如果信息不足还需要哪个符号。这个流程能同时暴露上下文预算、延迟、补丁质量和幻觉风险。
bashollama pull gpt-oss:20b ollama run gpt-oss:20b
如果这个路线已经慢、容易 OOM 或经常丢上下文,就没有必要马上跳到更大的 Qwen 低比特路线。先把上下文缩小、换更小模型或检查运行时设置。基线失败说明机器或任务边界有问题,不一定说明模型家族不行。
如果它能稳定完成小补丁,再逐步加上下文:先加测试,再加相邻模块,再加错误日志。每一步都记录显存、系统内存、响应时间和补丁是否能通过 review。
路线二:Qwen3.6 35B A3B 只能当进阶实验
Qwen3.6 35B A3B 是能力诱惑最大的路线之一,但它不能被写成“16GB 默认可用”。这里的正确说法是:在低比特、短上下文或 offload 条件下,它可能成为 16GB 用户的进阶实验。
测试前先写清楚这些条件:用哪个量化,哪个运行时,GPU 层数多少,是否 offload,系统内存多大,上下文设多长,任务是单轮解释还是多轮补丁。少任何一个条件,结果都不够可复现。
bashollama show qwen3.6:35b-a3b
如果包体、内存提示或下载页面已经超过你的舒适区,不要硬拉。勉强装进去的模型可能在真实代码任务里变慢、丢上下文、让编辑器插件超时。比起“大模型能启动”,更重要的是“小模型能持续改对”。
Qwen 路线适合愿意调参的开发者:你知道如何降上下文、换量化、看显存曲线、接受速度下降,并且愿意在失败时退回基线。它不适合只想找一个当天就可用的本地编程助手的人。
路线三:Gemma 4 E4B 和小型代码模型
Gemma 4 E4B 和中小型代码模型解决的是另一个问题:让 16GB 机器保持响应。它们适合解释代码、写小工具、补测试、生成 review checklist、把错误日志转成修复计划。
DeepSeek Coder、Qwen2.5-Coder、Qwen3-Coder 等代码家族可以进入候选,但不能只看家族名。你要看的是具体包:参数规模、量化格式、上下文长度、运行时支持和是否能贴合你的编辑器。
小模型的优势在交互节奏。开发者不需要每一次都拿到理论最强答案;很多时候需要 10 秒内得到一个可读 patch、一个测试建议或一个清楚的失败解释。
如果你只做短文件、脚本、配置、单元测试和局部重构,轻量路线可能比大模型更接近日常价值。它不会占满整台机器,也更容易和浏览器、IDE、终端同时运行。
运行时选择:Ollama、LM Studio、llama.cpp 和编辑器包装层
运行时会改变结论。Ollama 适合快速建立命令行基线,LM Studio 适合看模型页面和本地 server,llama.cpp/GGUF 适合细调量化、GPU layers 与上下文,编辑器包装层则决定文件如何被打包进 prompt。
同一个模型名,在不同运行时里可能对应不同文件、不同量化和不同上下文默认值。发布推荐时不能只说模型名,至少要写清楚运行时路径和第一条检查命令。
Ollama 的第一检查是包体和参数;LM Studio 的第一检查是内存要求;GGUF 的第一检查是具体文件名;编辑器插件的第一检查是它到底把哪些文件送给本地 endpoint。
如果包装层隐藏了显存压力,宁可先回到命令行烟测。命令行不好看,但它能让你知道问题来自模型、上下文还是 IDE 集成。
烟测流程:先证明它能改你的代码
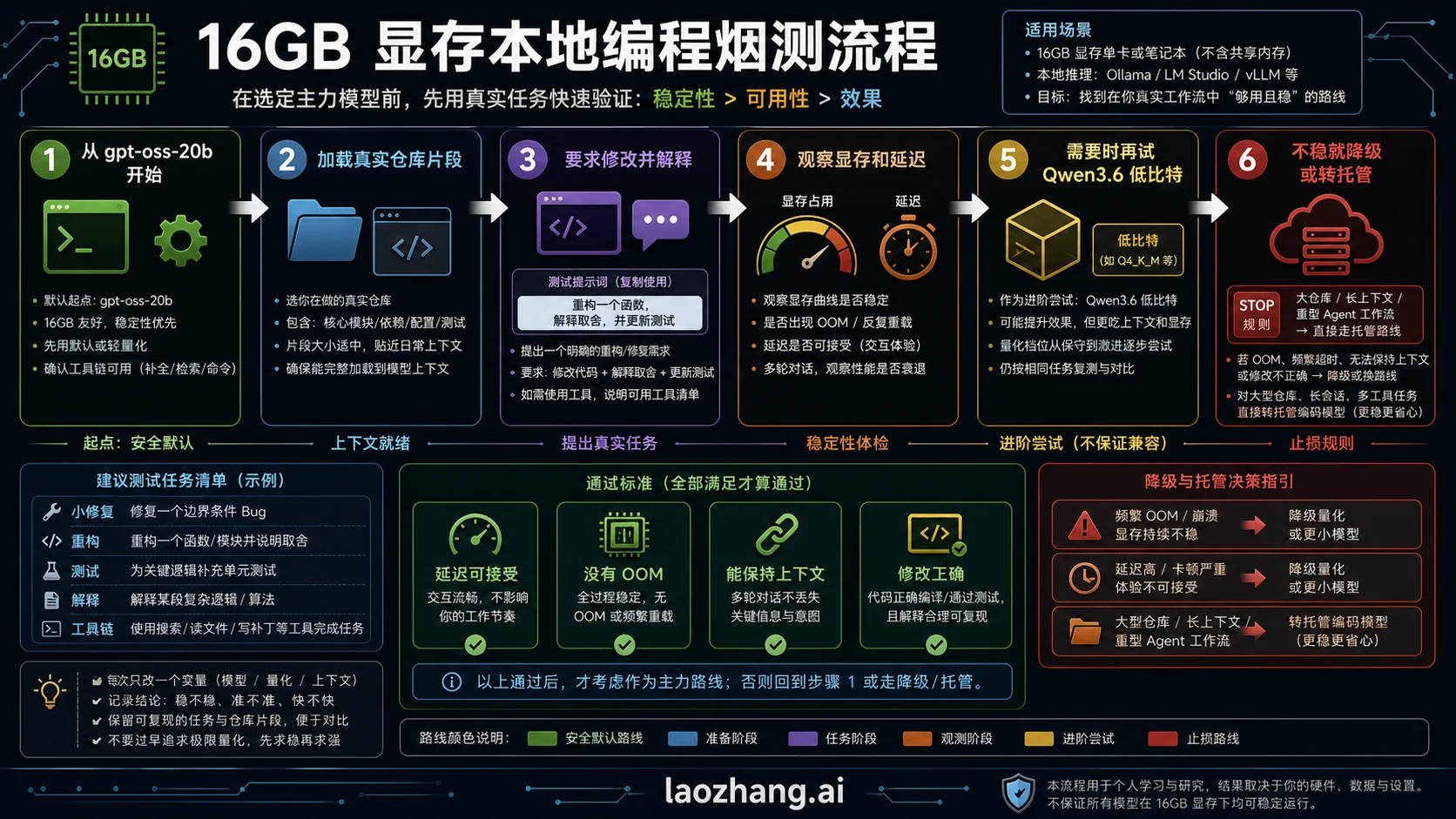
本地编程模型不是因为能启动才成为 daily driver,而是因为能在真实仓库里通过小工作流。烟测要用你的代码,不要用玩具题。
推荐任务:选一个函数、一个附近测试、一个明确目标,让模型解释当前逻辑、给出最小补丁、说明取舍,并指出应该更新哪个测试。如果它说上下文不足,答案必须具体到文件或符号。
textGiven the files below, refactor one function without changing behavior. Explain the tradeoff, show the patch, and name the test that should be updated. If the context is insufficient, say exactly what file or symbol you need next.
通过标准有四个:延迟能接受,没有 OOM 或不可控 offload,模型没有忘记函数和测试约束,补丁小且可 review。任何一项失败,都先调整上下文或模型,而不是直接宣布某个模型最好。
第二轮再增加上下文,第三轮再试 Qwen 低比特。这个顺序能防止你把显存调参误认为模型评估。
停止规则:什么时候别再硬调 16GB
停止规则要提前写好。16GB 用户最容易浪费时间的地方,是把一个边缘可加载的模型调到看起来能跑,却在真正改代码时慢到不可用。
如果模型加载后每轮都很慢,通常是 offload 或量化代价太高;如果短片段回答好、仓库任务差,通常是上下文打包问题;如果调大上下文就 OOM,通常是 KV cache 挤爆预算;如果补丁循环丢文件状态,说明本地代理路线超出机器舒适区。
下一步不一定是买显卡。你可以缩小任务、换小模型、固定 prompt 模板、减少工具层,或者把长上下文代理工作放到托管编码环境。真正的目标是让代码更快交付,不是证明 16GB 什么都能扛。
如果你正在比较用量、成本和托管编码,而不是本地显存,应该转到编码代理用量控制类内容。这个页面只解决本地 16GB 路线选择,不把本地硬件问题包装成 API 产品推荐。
| 症状 | 可能原因 | 更好的路线 |
|---|---|---|
| 加载后很慢 | offload 或量化代价太高 | 换小模型或升级显存 |
| 片段好、仓库差 | context 打包不足 | 缩小任务或用托管编码 |
| context 一加就 OOM | KV cache 挤爆预算 | 降低 context 或上 24GB+ |
| 补丁循环丢状态 | 代理任务超过本地舒适区 | 换更大显存或 hosted coding |
本地验证记录怎么写
记录本地测试时,至少写下显卡型号、系统内存、驱动、运行时版本、模型文件、量化、上下文长度、是否 offload、任务类型、响应时间和失败信号。没有这些字段,下一次复现会变成猜谜。
对 gpt-oss-20b,记录重点是它在你的仓库里能稳定处理多大代码片段。对 Qwen3.6,记录重点是低比特和 offload 带来的速度损失是否可接受。对 Gemma 4 E4B,记录重点是它是否足够快、是否能保持测试约束。
不要只记录“能跑”。要记录“能不能改对”。编程助手的有效性来自补丁质量、上下文保持和可审查性,而不是模型启动截图。
一次有价值的 16GB 测试应该分成三轮。第一轮只给一个文件和一个测试,确认模型能读懂当前行为;第二轮加入错误日志或需求说明,观察它是否还能保持目标;第三轮才加入相邻模块,判断 context 增长后是否开始丢约束。三轮都通过,才值得把它放进日常工作流。
如果你在同一轮测试里同时更换模型、量化、运行时和插件,就无法知道是哪一个因素改变了结果。更好的做法是固定任务和 prompt,只改变一个变量。先比较 gpt-oss-20b 与一个小型代码模型,再比较 Qwen3.6 的两个量化版本,最后才比较 IDE wrapper。
中文读者常把“显存 16GB”理解成可以直接挑战所有 30B 以上模型,但代码场景要额外保留余量给编辑器、浏览器、终端、向量索引和测试进程。实际使用时,给模型留出 2GB 到 4GB 的安全空间,往往比把显存压到 99% 更稳定。
当你写团队推荐时,不要只说“我这里能跑”。应该写成“在某张 GPU、某个运行时、某个量化、某个 context、某类任务下通过”。这样的表述既能帮同事复现,也能避免把个人机器上的偶然成功变成通用承诺。
还要记录失败后的下一步。如果 gpt-oss-20b 质量不够,但机器仍然有余量,下一步是 Qwen 低比特短上下文;如果 Qwen 速度不可接受,下一步不是继续加 context,而是回到较小模型;如果小模型也无法保持测试约束,问题可能是任务切分,而不是模型名单。
最值得保留的截图不是模型下载完成,而是一次完整 smoke test:输入文件范围、模型输出补丁、测试建议、显存曲线和最终是否接受补丁。这些证据能让下一次模型升级变成可比较的工程决策。
失败归因要具体:速度问题归到 offload、量化或上下文;质量问题归到模型能力或任务切分;稳定性问题归到显存余量、运行时版本或插件包装。只有这样,下一步才是工程调整,而不是继续换一个更大的名字。
如果日志要服务团队决策,还应记录是否能重复三次通过同一任务,因为一次成功只能说明可行,连续通过才说明它适合作为本地编程助手。
同一张 16GB 显卡在不同驱动、不同系统负载、不同编辑器插件下表现会变动。把这些条件写清楚,才能知道下次失败是模型退步、运行时变化,还是当天机器负载不同。
最后给每次测试打一个结论标签:保留、降级、继续观察、复测、复盘或停止。
常见问题
16GB 显存最先该试哪个本地编程 LLM?
先试 gpt-oss-20b。它的 16GB 级别证据更干净,适合作为基线。基线通过后再评估 Qwen3.6 低比特或更小代码模型。
Qwen3.6 35B A3B 能在 16GB 显存上跑吗?
可能能以低比特、短上下文或 offload 形式运行,但不能当成干净的 16GB 全 GPU 保证。要看量化、运行时、上下文、系统内存和具体任务。
gpt-oss-20b 够不够写代码?
它适合做 16GB 起点:函数解释、小补丁、测试建议和短仓库片段。它不是大型多文件代理的永久答案,必须用烟测判断。
Gemma 4 E4B 的位置是什么?
它是低压力回退路线。任务窄、要求响应快、Qwen 调参太重时,Gemma 4 E4B 或小型代码模型可能更实用。
Ollama 和 LM Studio 哪个更适合?
Ollama 适合命令行基线,LM Studio 适合 GUI 选择和本地 server。判断关键不是工具名,而是它展示的模型文件、量化和内存要求。
RTX 4060 Ti 16GB 或 5060 Ti 16GB 可以吗?
可以作为 16GB 路线测试机器,但不要假设所有 35B 或 30B 模型都舒服。先跑基线,再逐步增加上下文。
8GB 显存怎么办?
把目标降到更小模型、短上下文和轻任务。8GB 不适合照搬 16GB 的 Qwen 低比特实验。
24GB 显存是不是就够了?
24GB 会舒服很多,但仍然要看上下文、KV cache 和工具调用。它降低压力,不取消烟测。
什么时候该停止本地路线?
当 OOM、offload 延迟、上下文丢失或补丁循环失败成为主问题时停止。换小模型、升级显存或使用托管编码都比继续硬调更合理。
社区 benchmark 能直接决定最佳模型吗?
不能。社区结果只能提示候选和失败样本;发布决策要绑定具体模型文件、量化、运行时、上下文和你的烟测。