
Si quieres integrar la voz realtime de xAI como desarrollador, conviene salir rapido de la pregunta amplia de si “xAI ya tiene voice API”. La respuesta util hoy es mas concreta: el route publico mas claro es Grok Voice Agent API y su endpoint es wss://api.x.ai/v1/realtime. A 6 de abril de 2026, la oferta self-serve publica muestra $0.05 / min, 100 sesiones concurrentes por equipo y un maximo de 30 minutos por sesion. En la practica importa fijar tres cosas desde el inicio: la API key de larga vida solo debe vivir en el backend; navegador y movil deben conectarse con ephemeral token; y si no necesitas una conversacion viva de ida y vuelta, sino solo generar voz al final, es mejor empezar directamente por el Text to Speech API separado.
“Este articulo se apoya en las Voice Agent docs, pricing / model page, voice overview, Text to Speech docs, product page y release notes de xAI, revisadas de nuevo el 6 de abril de 2026. El 20 de abril de 2026 se actualizo la frontera de STT: xAI ya publica docs and endpoints separados para Grok STT.
Primero separa de que ruta de voz estamos hablando
El error mas comun en este tema es meter Voice Agent API, TTS, STT y frameworks de voz dentro del mismo saco. Para una decision de implementacion, conviene separarlos primero.
| Que necesitas de verdad | Ruta que tiene mas sentido hoy |
|---|---|
| Conversacion de voz bidireccional con baja latencia | Grok Voice Agent API |
| Generar voz una sola vez a partir de texto | Text to Speech API |
| Tu cuello de botella ya esta en WebRTC, telefonia o media routing | Framework de voz / ruta de telephony |
| Transcribir audio a texto | Grok STT API |
Esto no es una diferencia de terminologia, sino de arquitectura. Si tu producto necesita turn-taking, audio de ida y vuelta, tools durante la sesion o un escenario tipo phone agent, Voice Agent API es el camino correcto. Si tu aplicacion ya controla el estado y solo quiere convertir la salida final en voz, TTS suele ser mas simple y mas facil de presupuestar.
La product page de xAI tambien menciona Speech to Text, y esa frontera cambio despues de la primera publicacion. A 20 de abril de 2026, xAI ya ofrece una ruta Grok STT separada: POST https://api.x.ai/v1/stt para archivos o audio URL y wss://api.x.ai/v1/stt para transcripcion realtime. No es Voice Agent API: STT devuelve texto, mientras Voice Agent API ejecuta una live spoken session.
Por eso, ahora mismo la lectura mas segura es esta:
- Voice Agent API cuando la sesion de voz en vivo es el producto
- TTS API cuando la voz es solo la salida final
- Grok STT cuando el objetivo es transcribir audio; la referencia separada es Grok STT API: precio, endpoint, streaming y ruta correcta
Lo que ya esta publicado y sirve para empezar hoy
| Lo primero que conviene saber | Respuesta publica actual |
|---|---|
| Endpoint realtime oficial | wss://api.x.ai/v1/realtime |
| Nombre del producto | Grok Voice Agent API |
| Precio self-serve publico | $0.05 / min ($3.00 / hora) |
| Limites runtime publicados | 100 sesiones concurrentes por equipo, 30 minutos por sesion |
| Ruta segura de autenticacion para navegador | el backend emite un ephemeral token y el cliente se conecta con ese token |
| Punto de partida mas seguro | mantener primero la sesion realtime en backend |
| Coste que mas se olvida | las tools se cobran aparte del minute rate |
| Que usar si solo necesitas speech output | POST https://api.x.ai/v1/tts |
| Como aparece el region self-serve publico | pricing/model page muestra us-east-1 |
| Como leer la compatibilidad con OpenAI Realtime | el mental model se reaprovecha, pero eventos y detalles no coinciden uno a uno |
La forma mas rapida de conectar sin romper la seguridad
xAI describe un flujo minimo bastante directo:
- abrir una conexion a
wss://api.x.ai/v1/realtime - enviar
session.update - crear un user message con
conversation.item.create - pedir la respuesta con
response.create
Si arrancas desde un backend de confianza, el JavaScript minimo se ve asi:
jsimport WebSocket from "ws"; const ws = new WebSocket("wss://api.x.ai/v1/realtime", { headers: { Authorization: `Bearer ${process.env.XAI_API_KEY}`, }, }); ws.on("open", () => { ws.send( JSON.stringify({ type: "session.update", session: { voice: "eve", instructions: "You are a helpful assistant.", turn_detection: { type: "server_vad" }, }, }), ); ws.send( JSON.stringify({ type: "conversation.item.create", item: { type: "message", role: "user", content: [{ type: "input_text", text: "Hello!" }], }, }), ); ws.send(JSON.stringify({ type: "response.create" })); });
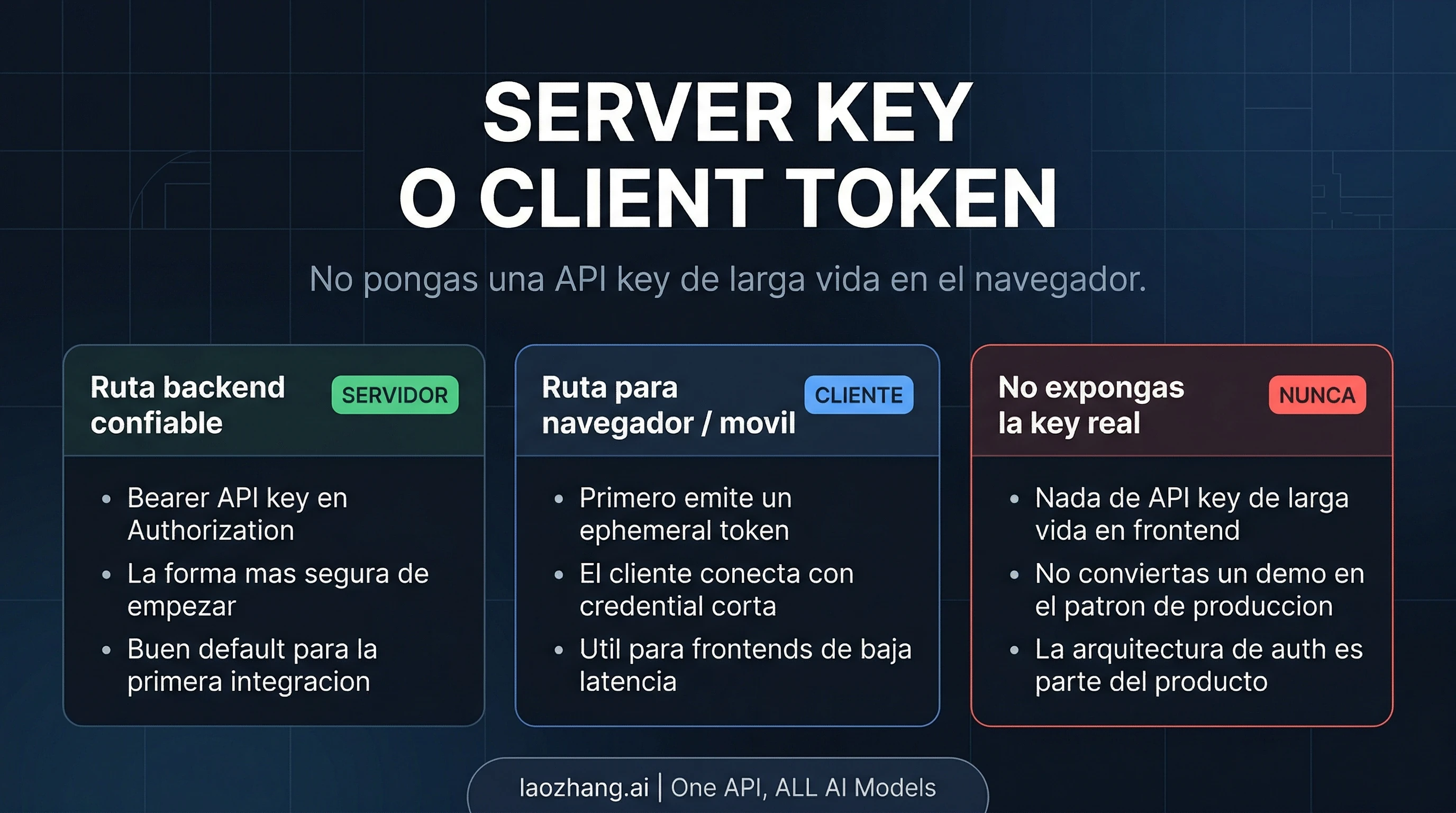
Es un buen primer paso porque deja clarisima la frontera de credenciales. La key real vive en tu backend y alli tambien controlas la sesion WebSocket. Browser audio capture, WebRTC, telefonia y orchestration mas pesada pueden venir despues.
La manera mas rapida de arruinar la seguridad es pensar que, si esa misma key funciona en servidor, tambien se puede pegar en el navegador. La documentacion de xAI dice lo contrario: las client-side apps deben usar ephemeral tokens. La ruta publica es POST https://api.x.ai/v1/realtime/client_secrets. El backend emite la credencial corta y luego el cliente abre el socket con ese token, no con una API key de larga vida. La documentacion de navegador incluso muestra el prefijo xai-client-secret. en sec-websocket-protocol.
La regla de despliegue queda asi:
- backend primero para la forma mas segura y mas simple de empezar
- browser / mobile direct solo despues de que tu backend ya emita ephemeral tokens
Tambien conviene conocer varios defaults desde el principio:
- el modo normal de turn detection es
server_vad - el PCM por defecto es
24 kHz - los formatos soportados incluyen
audio/pcm,audio/pcmuyaudio/pcma - las voces publicas son
eve,ara,rex,salyleo
No son detalles decorativos. Son senales de que esta API ya esta pensada para voice products reales y no solo para demos.
Como leer el coste real: el minute rate solo es el suelo
La superficie self-serve publica se puede resumir asi:
| Concepto | Informacion publica actual |
|---|---|
| Precio por voice session | $0.05 / min |
| Equivalente por hora | $3.00 / hora |
| Sesiones concurrentes | 100 por equipo |
| Duracion maxima | 30 minutos |
| Region publica | us-east-1 |
Pero la lectura util para operaciones empieza justo despues. La frase mas importante de las voice pages de xAI no es el minute rate en si, sino la nota de que las llamadas a tools se cobran por separado. Si tu voice agent usa function calling, web search, X search, collections o MCP-backed tools durante la sesion, esos costes no estan incluidos en $0.05 / min. Esa tarifa es solo el suelo de la sesion.
Un ejemplo rapido lo hace tangible. Una sesion de 10 minutos cuesta unos $0.50 por la tarifa base. Si dentro de esa misma sesion haces 20 llamadas a web_search y el precio publico actual es $5 / 1,000 calls, eso anade unos $0.10. La cifra no parece enorme, pero ya cambia la economia del producto. No cuesta lo mismo una voice app ligera que un retrieval/search agent con audio de entrada y salida.
Los precios publicos de tools incluyen al menos:
web_search:$5 / 1,000callsx_search:$5 / 1,000callscode_execution:$5 / 1,000callscollections_search/file_search:$2.50 / 1,000calls
Tambien conviene no mezclar en una sola promesa la parte de regiones e infraestructura. La pricing/model page publica muestra us-east-1 para la oferta abierta al desarrollador. La product page, en cambio, habla de multi-region infrastructure y custom rate limits. No es el mismo contrato. Para el public developer route, la fuente de verdad es la pricing/model page; el lenguaje mas amplio de infraestructura debe leerse como framing enterprise salvo que tengas un acuerdo mas especifico.
Por eso la primera pregunta de presupuesto no deberia ser solo “cuantos minutos hablara el usuario”, sino “cuantas tools usa la conversacion media y si de verdad necesitamos llamarlas en cada turno”.

Lo publicado ya alcanza para varios workloads reales
Segun desde que pagina llegues, Voice Agent API puede parecer mas grande o mas pequena de lo que realmente es. La lectura util es mas simple: el API publico ya cubre varios workloads de agentes reales, y los elementos importantes no son marginales.
La documentacion actual deja ver, entre otras cosas:
- conversacion de voz bidireccional en tiempo real sobre WebSocket
- varias voces integradas
server_vadpara control de turnos- varios formatos de audio, incluidos
μ-lawyA-lawpara telefonia web_search,x_search,file_search, remote MCP tools y custom functions- una via de compatibilidad para clientes estilo OpenAI Realtime
Eso ya alcanza para browser assistants, phone agents, support flows, interfaces de voz con retrieval y operator copilots. Hay dos lecturas practicas que merece la pena conservar.
La primera es que las tools forman parte del route principal.
No es un API que solo “habla bonito”. Si tu producto necesita lookup en vivo, retrieval interno o function calls a mitad de la conversacion, xAI ya trata eso como ruta principal.
La segunda es que la compatibilidad ayuda, pero no borra el trabajo de adaptacion.
xAI dice que muchos clientes y SDKs de OpenAI Realtime funcionan cambiando la base URL a wss://api.x.ai/v1/realtime. Eso es util. Pero la misma documentacion enumera diferencias de event names y eventos no soportados. El ejemplo mas concreto es response.text.delta frente a response.output_text.delta.
La regla mas util para migracion es:
- puedes reutilizar buena parte de la estructura general del cliente
- no debes asumir que el manejo de eventos es identico
- la compatibility note acelera el arranque, pero no sustituye una lectura puntual de las diferencias propias de xAI
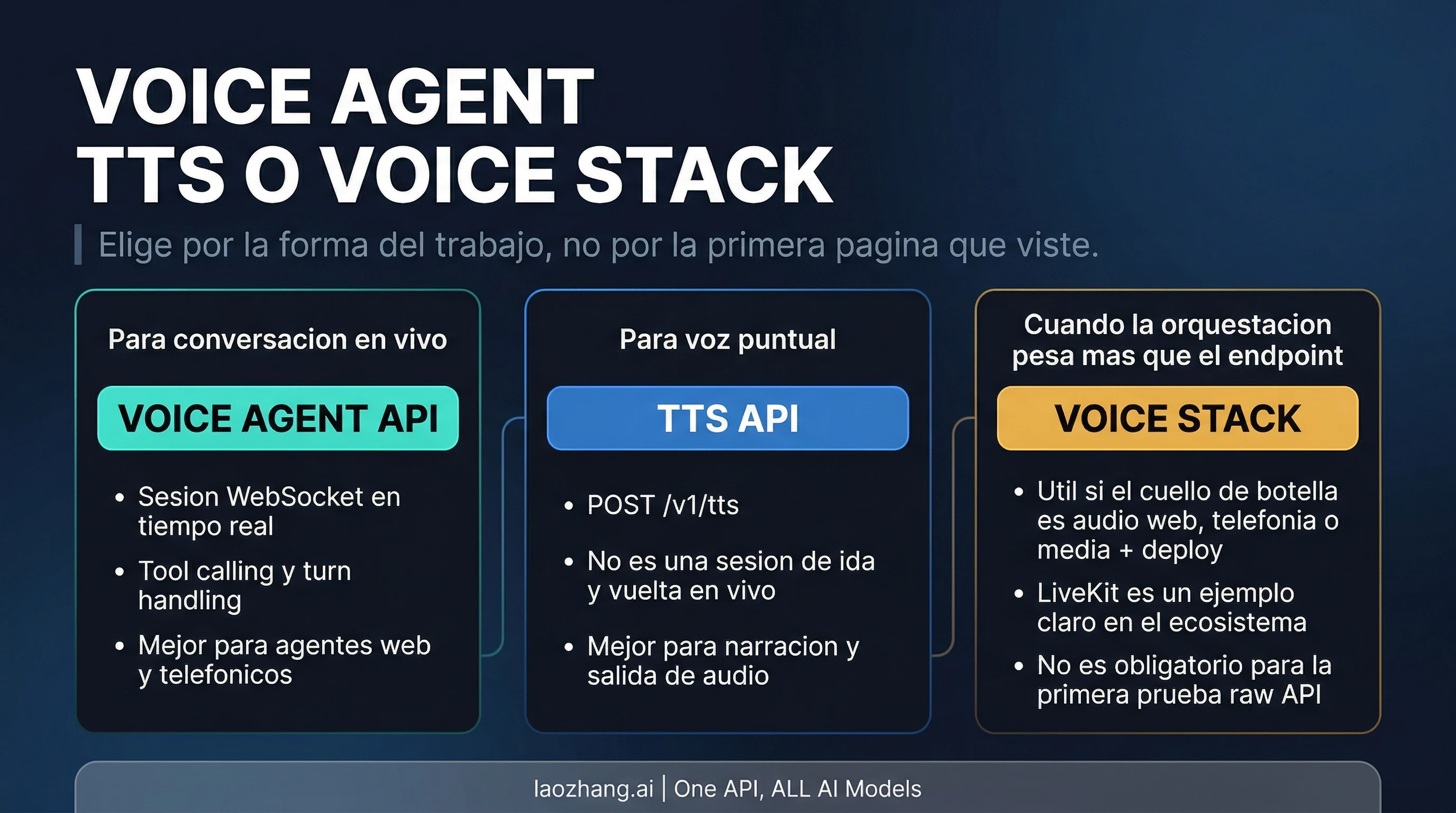
Cuando conviene mirar un framework de voz en lugar del raw API
No ayuda tratar raw API y framework como una pelea de “mejor” y “peor”. En realidad es una cuestion de donde esta el bottleneck.
Si tu problema principal todavia es:
- levantar una realtime session minima que funcione
- fijar bien la auth boundary
- presupuestar el minute rate y la capa de tools
entonces empezar con raw Voice Agent API suele ser la decision correcta. Ya es suficiente para validar valor sin subir demasiado pronto a un media stack mas pesado.
El momento en que un framework de voz empieza a merecer mas la pena es otro:
- browser audio capture y playback pipeline ya son demasiado complejos
- phone routing, telephony y media forwarding se volvieron el problema principal
- WebRTC o deployment topology pesan mas que el propio socket de xAI
xAI remite en su voice overview a LiveKit, Twilio, WebRTC y ejemplos de telefonia. Esa senal es bastante clara: cuando el cuello de botella se mueve de “conectar xAI” a “gobernar media y orchestration”, un framework puede mejorar mas el time-to-shipping que otra vuelta de codigo crudo.
La division practica queda asi:
- Voice Agent API: el producto es la conversacion de voz en vivo
- TTS API: solo necesitas one-shot speech output
- Framework de voz: media plumbing, telephony y orchestration pesan mas que la conexion cruda
Si vienes desde OpenAI Realtime, revisa esto primero
La note de compatibilidad de xAI si hace que este API sea mas accesible de lo que muchos creen. Pero reducirlo a “drop-in compatible” sigue siendo demasiado agresivo. La version mas precisa es esta:
- La estructura general si se transfiere. Sigue habiendo una sesion realtime con estado, eventos en streaming, audio en vivo y tool use.
- El endpoint cambia. El contrato principal pasa a
wss://api.x.ai/v1/realtime. - Algunos event names cambian. El contraste entre
response.output_text.deltayresponse.text.deltaya basta para demostrarlo. - Hay eventos no soportados. xAI documenta huecos como
conversation.item.retrieveyconversation.item.truncate.
El valor de esta seccion no es comparativo de marca, sino de migrar con cuidado. Si ya tienes una client architecture orientada a Realtime, xAI sera mas accesible que un protocolo totalmente nuevo. Pero la primera validacion de produccion debe revisar el comportamiento de eventos, no solo el handshake del socket.
FAQ
Cual es el endpoint exacto de Grok Voice Agent API?
Usa wss://api.x.ai/v1/realtime.
Cuanto cuesta hoy la oferta self-serve publica?
La pagina publica muestra $0.05 / min o $3.00 / hora. Las llamadas a tools van aparte.
Se puede conectar directamente desde navegador?
Si, pero la ruta segura es emitir un ephemeral token en el backend y dejar que el cliente se conecte con esa credencial. No expongas una API key de larga vida en browser code.
Voice Agent API y TTS API son lo mismo?
No. Voice Agent API es el API WebSocket para dialogo en vivo. TTS API es el API REST para speech puntual.
Soporta tools?
Si. xAI documenta web_search, x_search, file_search, remote MCP tools y custom functions.
Existe ya un Speech to Text API publico?
Si. A 20 de abril de 2026, xAI publica Grok STT con POST https://api.x.ai/v1/stt para archivos y wss://api.x.ai/v1/stt para transcripcion realtime. Este articulo queda enfocado en Voice Agent API para live spoken agent sessions.
Cuales son los limites actuales?
La public pricing/model page muestra 100 sesiones concurrentes por equipo y un maximo de 30 minutos por sesion.
Conclusiones
La respuesta mas util a “Grok Voice Agent API” no es solo que el API exista. Lo importante es que xAI ya deja bastante claro cual es la via realtime para desarrolladores y bajo que fronteras conviene empezar a trabajar. Hay tres piezas que no deberian mezclarse desde el primer dia: el endpoint WebSocket exacto, la frontera de autenticacion entre server key y client token, y la capa de coste de tools por encima del minute rate. Si tu producto es de verdad una experiencia de voz en vivo, Voice Agent API es un punto de partida valido. Si solo necesitas speech output, TTS es la ruta mas natural. Si el bottleneck real ya se ha movido a media plumbing, telefonia u orchestration, entonces tiene mas sentido mirar un framework de voz.