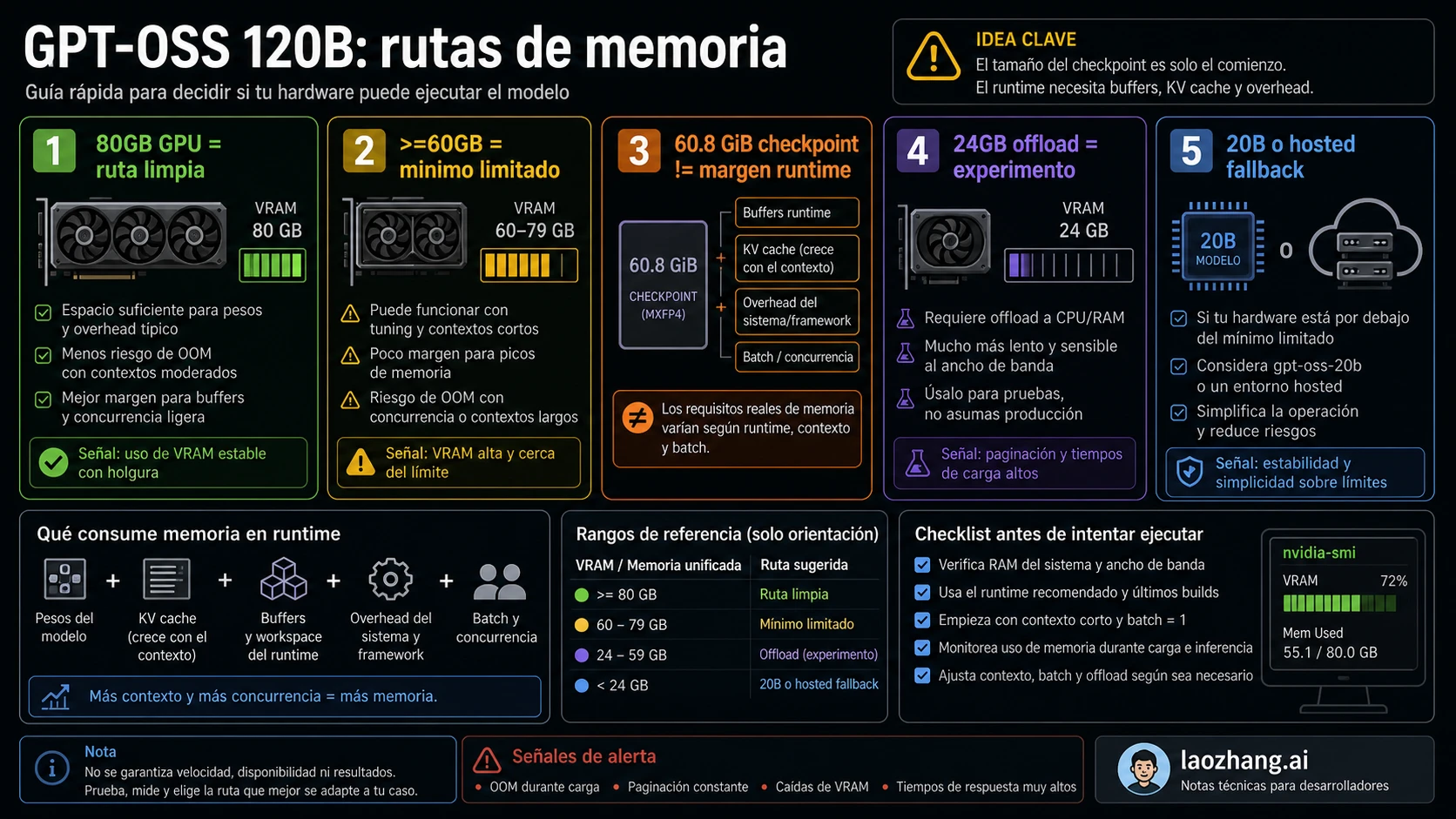
GPT-OSS 120B debe planificarse como un modelo local de clase 80GB de memoria GPU si se busca una ejecución limpia. Algunas rutas de runtime pueden acercarse a un piso de >=60GB VRAM o unified memory, y el checkpoint MXFP4 ronda 60.8 GiB, pero esos números no incluyen runtime buffers, KV cache, longitud de contexto, batch, concurrencia ni el coste de CPU offload.
| Ruta de hardware | Qué significa el número de memoria | Cuándo usarla | Regla de parada |
|---|---|---|---|
| GPU de 80GB | Objetivo limpio de una sola tarjeta | Evaluación, desarrollo, pruebas locales confiables | Aun así reserve margen para contexto y batch |
| >=60GB VRAM o unified memory | Piso estrecho de runtime | Pruebas con backend, contexto y batch controlados | No lo venda como margen de producción |
| 96GB+ o multi-GPU | Ruta con holgura | Contexto largo, mejor throughput, menos OOM | Verifique sharding y KV cache |
| GPU de consumo 24GB con offload | Ruta experimental | Aprender el stack o probar carga | Si la velocidad no sirve, cambie de ruta |
| GPT-OSS 20B o hosted/API | Fallback | El hardware local está bajo el piso de 120B | Evite seguir ajustando una configuración inviable |
60.8 GiB, >=60GB y 80GB no significan lo mismo
El error más común en los resultados en español es convertir tres capas distintas en una sola cifra. La primera capa es el artefacto del modelo. La model card de OpenAI lista el checkpoint MXFP4 de GPT-OSS 120B en unos 60.8 GiB, con 116.83B parámetros totales y 5.13B parámetros activos. Ese dato explica el tamaño del archivo y la eficiencia de MXFP4, pero no significa que una GPU de 64GB tenga margen cómodo para ejecutar el modelo.
La segunda capa es el piso de carga del runtime. Las guías de OpenAI Cookbook para Transformers, vLLM y Ollama describen rutas alrededor de >=60GB VRAM o >=60GB VRAM / unified memory. Ese piso depende del backend, del formato de pesos, de la cuantización, del contexto, del batch, de drivers y de cómo se maneja la memoria. Cargar una prueba corta no equivale a soportar una carga real.
La tercera capa es el objetivo operativo. El anuncio de OpenAI dice que GPT-OSS 120B can run within 80GB memory, y Hugging Face lo presenta como un modelo que cabe en una sola GPU de 80GB, como H100 o MI300X. Para elegir una máquina, alquilar GPU o escribir una recomendación interna, 80GB es la respuesta limpia. Por debajo de eso ya no se habla de comodidad, sino de compromisos.
Los números no se contradicen. 60.8 GiB es tamaño de checkpoint, >=60GB es una posibilidad restringida de runtime y 80GB es una planificación más segura. Mezclarlos lleva a comprar, alquilar o configurar hardware que solo funciona como demostración.
Use los hechos oficiales como ancla
Las experiencias de Reddit, Xataka, LobeHub o blogs locales ayudan a ver qué intenta la comunidad, pero los límites del modelo deben salir de fuentes primarias.
| Hecho | Dueño de la evidencia | Significado práctico |
|---|---|---|
| GPT-OSS 120B can run within 80GB memory | OpenAI launch post | 80GB es el objetivo limpio de una tarjeta |
| GPT-OSS 20B targets 16GB memory | OpenAI launch post | 20B es el fallback realista de baja memoria |
| Checkpoint de 60.8 GiB | OpenAI model card | El archivo no cubre todo el presupuesto runtime |
| Rutas >=60GB VRAM o unified memory | OpenAI Cookbook runtime guides | Existe un piso, pero es condicional |
| Enfoque single 80GB GPU | Hugging Face model page y MXFP4 docs | 80GB GPU es el plan local más sólido |
El launch post de OpenAI, la model card PDF, las guías de Transformers, Ollama y vLLM, y la documentación de Hugging Face sobre el modelo y MXFP4 son las fuentes que fijan el marco. Los reportes de comunidad son útiles para offload, varias RTX 3090, Apple unified memory, CPU y pruebas de instalación, pero no deben convertirse en requisitos generales.
Elija la ruta antes de afinar parámetros
La memoria requerida cambia según el camino de ejecución. Elegir la ruta primero evita perder horas ajustando un setup que no corresponde al objetivo.
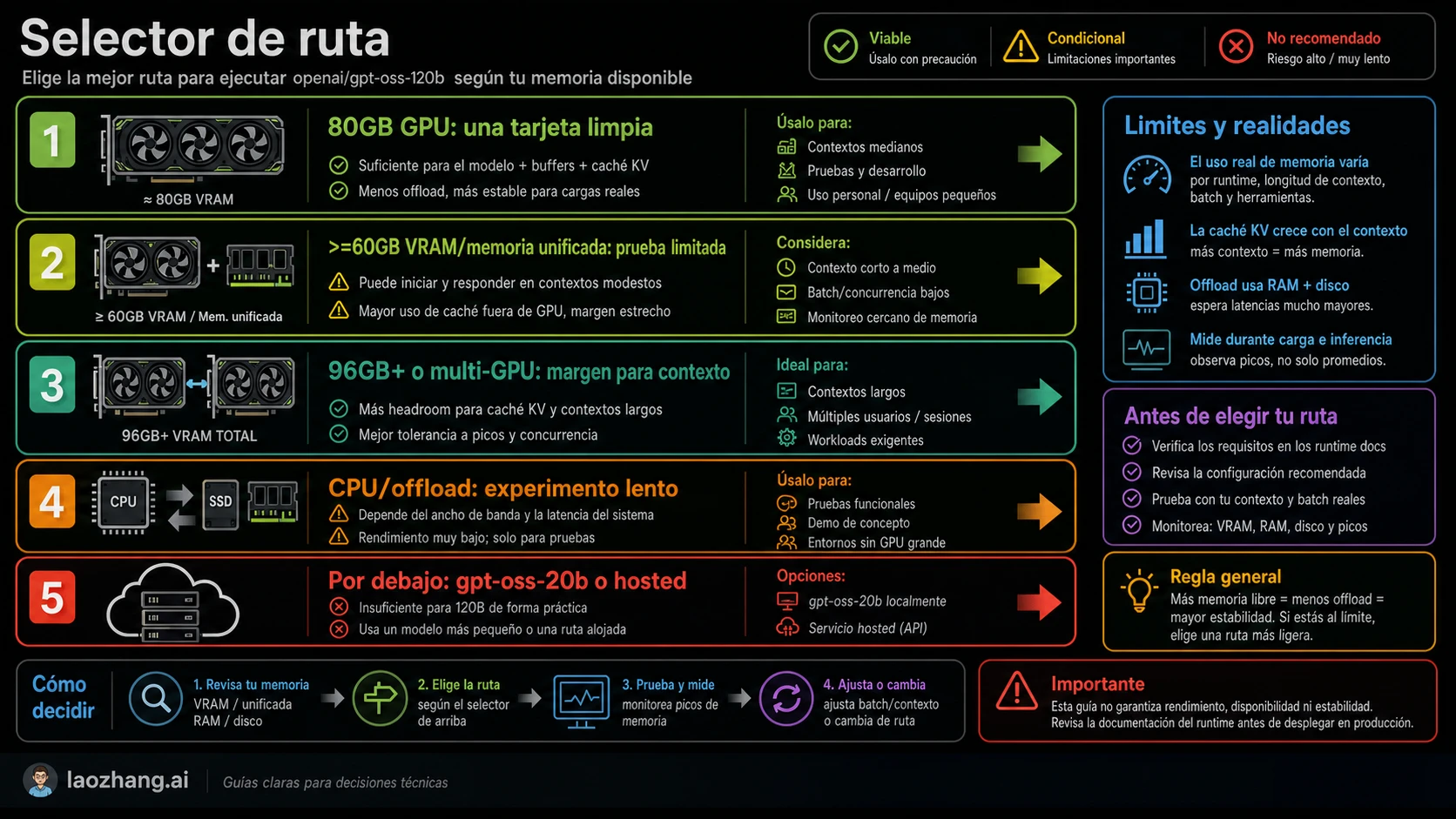
| Ruta | Postura de memoria | Mejor uso | Riesgo principal |
|---|---|---|---|
| Transformers en GPU de 80GB | Ruta local limpia | Desarrollo, evaluación, pruebas controladas | Contexto y batch aún consumen margen |
| vLLM en 80GB o multi-GPU | Ruta de serving | Throughput, API, concurrencia | KV cache y concurrencia suben el requisito |
| Ollama con >=60GB VRAM/unified memory | Ruta local simple | Workstations y pruebas de memoria unificada | CPU offload puede ser lento |
| Workstation 96GB+ o multi-GPU | Ruta con holgura | Contexto largo y menos sorpresas OOM | Complejidad de sharding y backend |
| GPU 24GB con offload | Ruta experimental | Aprender, cargar, explorar | Velocidad y contexto pueden no servir |
| GPT-OSS 20B | Fallback pequeño | Máquinas de 16GB a 24GB | Calidad y capacidad distintas |
| Hosted/API | Sin carga local de memoria | Integración de producto | Coste, límites y disponibilidad reemplazan el problema GPU |
Si el objetivo es medir calidad, alquilar una GPU adecuada por poco tiempo puede ser más barato que forzar una tarjeta equivocada. Si el objetivo es aprender el backend, una ruta con offload puede valer. Si el objetivo es un servicio estable, empiece por la ruta con margen.
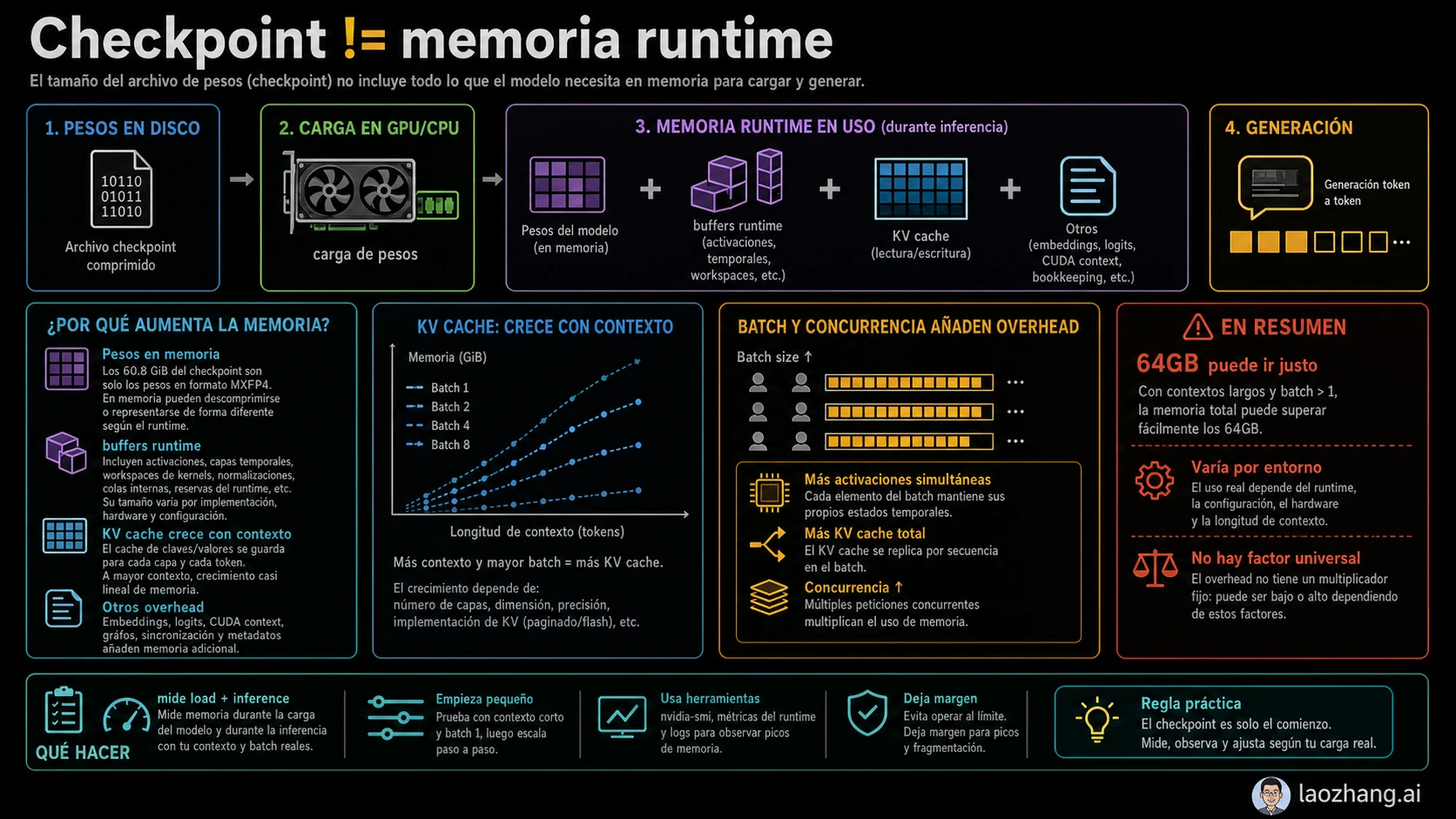
VRAM, unified memory, RAM y disco no son intercambiables
VRAM es memoria dedicada de la GPU. Cuando se habla de H100 80GB, A100 80GB o MI300X, normalmente se evalúa si los pesos, runtime buffers y KV cache pueden quedarse del lado del acelerador. Para velocidad y estabilidad, es la memoria crítica.
Unified memory es una reserva compartida entre CPU y GPU. Puede ayudar en Apple Silicon u otras plataformas, pero no equivale automáticamente a una GPU discreta de 80GB. El ancho de banda, el soporte del backend, la migración de capas, la temperatura y el contexto afectan el resultado.
System RAM importa en CPU offload e inferencia híbrida. Puede evitar que la carga falle, pero normalmente cambia memoria por latencia y tokens por segundo. Disk almacena checkpoint, tokenizer, formatos convertidos y cache. El checkpoint de 60.8 GiB es un dato de almacenamiento, no de memoria activa.
La presión oculta aparece con KV cache y overhead del runtime. Un prompt corto puede funcionar donde falla un contexto largo, un lote mayor, varias solicitudes concurrentes o un servidor con cache reservado. Por eso la prueba mínima no basta.
Qué hacer con su hardware
Una GPU de 80GB es el nivel directo. Si tiene H100 80GB, A100 80GB, MI300X o una ruta equivalente soportada, GPT-OSS 120B es razonable para evaluación local y pruebas de servicio pequeñas. Aun así debe comprobar driver, runtime, formato del modelo, contexto y batch.
Entre 60GB y 79GB está el nivel de prueba. Puede cargar con la cuantización correcta y un contexto limitado, pero no debe prometerse para producción. Sirve para evaluación interna, aprendizaje del stack y pruebas cortas. Si cada aumento de contexto dispara OOM, no es una ruta estable.
96GB+, multi-GPU o cloud GPU es el nivel con margen. Cuesta más y puede ser más complejo, pero tiene sentido cuando el coste de fallo es alto. RAG largo, múltiples usuarios, evaluación por lotes y serving continuo suelen necesitar ese margen.
De 16GB a 24GB en GPU de consumo, el camino honesto es GPT-OSS 20B o un experimento etiquetado como tal. Una captura donde 120B carga con offload es interesante, pero no es recomendación de compra ni base de producción.
Reglas de parada para 4090, 3090, 5090 y GPU de consumo
La pregunta típica es si una RTX 4090 o RTX 3090 puede ejecutar GPT-OSS 120B. No como ruta limpia residente en GPU. Puede intentarse offload a CPU, unified memory, contexto reducido o trucos del runtime, pero eso convierte la prueba en experimento.
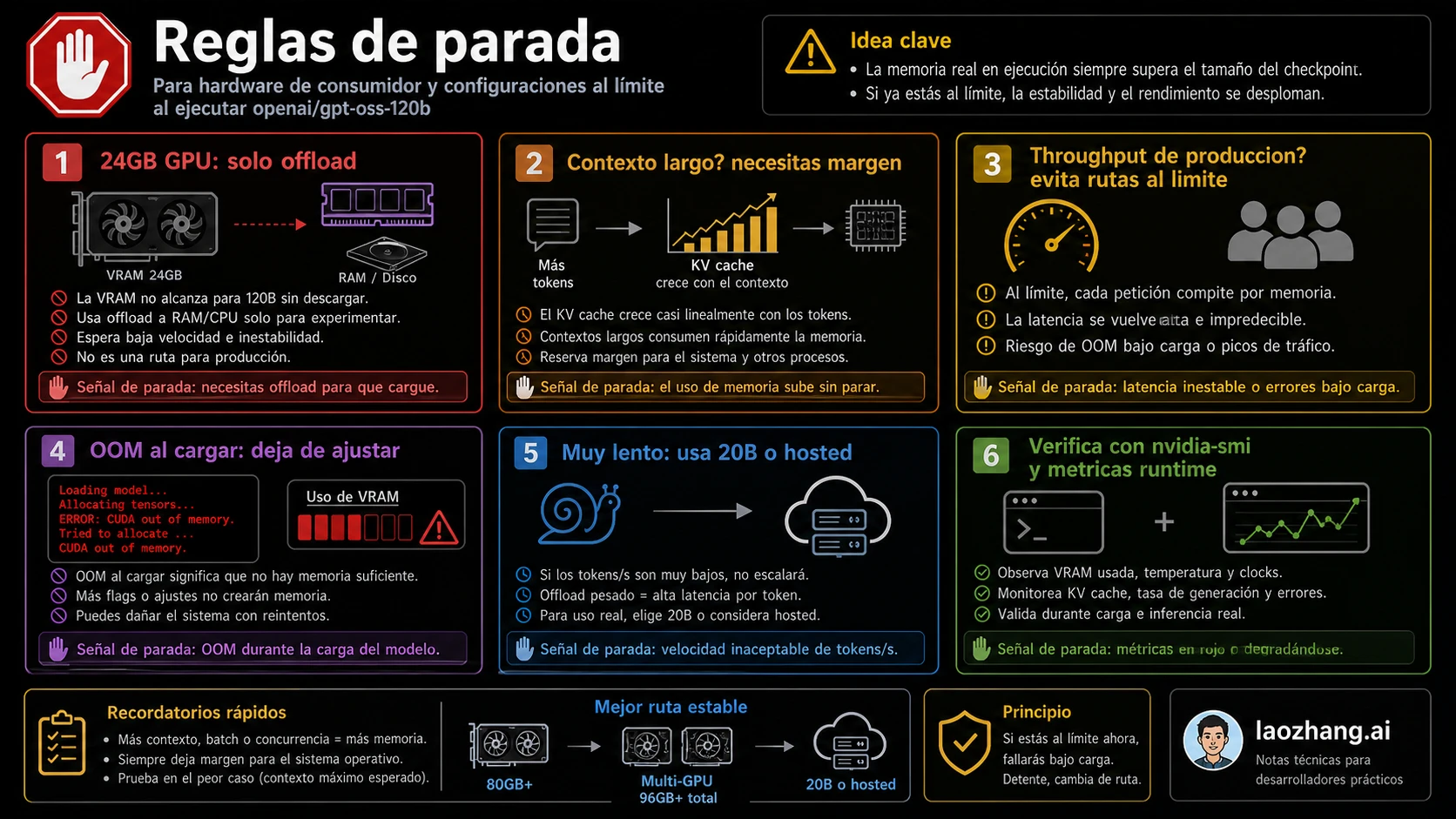
Detenga la prueba si la carga entra en OOM repetido. Deténgala si carga pero los tokens por segundo no sirven para el trabajo. Deténgala si solo funciona con contexto diminuto y su caso necesita contexto largo. Evite llamar producción a una configuración que encaja solo gracias a offload pesado. Si la motivación es curiosidad, escriba que el resultado es experimental.
Una 5090 se juzga igual: por VRAM real y soporte del runtime. Más compute no elimina la necesidad de memoria para pesos, cache y contexto.
Context length y batch son la prueba real
Antes de decir que una máquina alcanza, ejecute la forma real de trabajo. Cargue el modelo en el runtime previsto. Use el contexto que piensa soportar. Pruebe batch o concurrencia esperada. Vigile memoria con nvidia-smi, logs del runtime o métricas de la plataforma. Registre GPU, VRAM, RAM, driver, runtime version, model file, quantization, context length, batch, offload, peak memory y tokens por segundo.
Si la configuración solo sobrevive cuando todo se reduce al mínimo, es una demo. Las demos sirven para aprender, pero no para compras, estándares de equipo ni compromisos con usuarios.
Cuándo conviene el fallback
GPT-OSS 20B existe porque las máquinas pequeñas necesitan una ruta usable. OpenAI lo posiciona para memoria de clase 16GB, así que en laptops, workstations de consumo, herramientas offline y pruebas rápidas suele ser más racional. Se pierde capacidad, pero se gana una ejecución que realmente funciona.
Hosted/API es el fallback cuando el objetivo es integración de producto y no propiedad del hardware. Quita la decisión de GPU, pero introduce coste, rate limits, estado de cuenta, disponibilidad y límites del proveedor. Son problemas distintos, no una solución gratuita.
| Objetivo real | Ruta mejor |
|---|---|
| Aprender cómo se comporta 120B en su máquina | Probar constrained/offload y etiquetar como experimento |
| Construir flujo local confiable | Usar 80GB+, 96GB+ o multi-GPU |
| Trabajar en 16GB a 24GB | Empezar con GPT-OSS 20B |
| Lanzar una función sin poseer GPU | Usar hosted/API y gestionar límites |
| Comparar calidad antes de comprar | Alquilar brevemente la GPU correcta |
Preguntas frecuentes
Cuánta VRAM necesita GPT-OSS 120B?
La respuesta local limpia es 80GB de memoria GPU. Algunas rutas pueden cargar cerca de >=60GB, pero deben probarse con su contexto, batch y runtime.
60.8 GiB basta para una GPU de 64GB?
No. 60.8 GiB es tamaño del checkpoint. Runtime buffers, KV cache, contexto y framework overhead necesitan memoria adicional.
Puede una RTX 4090 o RTX 3090 ejecutarlo?
No como ruta limpia residente en GPU. Puede hacer experimentos con offload, pero velocidad y contexto deciden si el resultado sirve.
Una 5090 sí puede?
Depende de la VRAM real y del soporte del runtime. Si sigue lejos de 60GB a 80GB, es una ruta experimental.
Cuánta RAM del sistema necesito?
La RAM del sistema ayuda con offload y unified memory, pero no reemplaza VRAM uno a uno. Pruebe el workload real.
Cuánto disco necesito?
Planifique el checkpoint de 60.8 GiB, tokenizer, cache, formatos convertidos y espacio de trabajo.
vLLM, Transformers u Ollama?
Transformers sirve para desarrollo controlado, vLLM para serving y Ollama para pruebas locales de baja fricción. Registre siempre backend y ruta de memoria.
Cuándo debo dejar de intentar 120B local?
Cuando solo funciona con contexto diminuto, OOM constante, tokens por segundo inútiles o offload pesado. Cambie a 20B, GPU mayor, multi-GPU/cloud o hosted/API.