
Si con “Gemini 3.1 Flash Live API” te refieres al nuevo modelo de voz en tiempo real de Google, el identificador oficial que necesitas es gemini-3.1-flash-live-preview y la superficie correcta es Gemini Live API. Esa aclaracion importa porque Google reparto la informacion util entre varias paginas: la ficha del modelo, el overview de Live API, la guia de capacidades, la pagina de precios, la guia de ephemeral tokens y el post oficial del 26 de marzo de 2026.
La conclusion corta es esta: si hoy vas a construir un agente de voz de baja latencia, empieza por Gemini 3.1 Flash Live. Pero no lo trates como una migracion limpia desde gemini-2.5-flash-native-audio-preview-12-2025. Google mejoro la calidad de voz, el techo operativo y el comportamiento en dialogo, pero tambien cambio la configuracion de thinking, la forma de los eventos del servidor, el modelo de entrada incremental y la semantica de tool use. Si tu stack en 2.5 dependia de async function calling, proactive audio o affective dialog, migrar sin revisar te puede romper la experiencia.
“Nota de evidencia: esta guia se apoya en documentacion oficial de Google y en el post de lanzamiento, todo revalidado el 28 de marzo de 2026. Cuando las paginas publicas de Google no coinciden entre si o dejan una zona gris, mantengo esa incertidumbre explicitamente.
TL;DR
| Lo primero que necesitas saber | Respuesta actual |
|---|---|
| Model ID exacto | gemini-3.1-flash-live-preview |
| Superficie exacta | Gemini Live API sobre una conexion WebSocket con estado |
| Fecha de lanzamiento | 26 de marzo de 2026 |
| Mejor caso de uso inicial | agentes de voz en tiempo real con baja latencia, conciencia multimodal y mejor calidad de audio |
| Recomendacion por defecto | para proyectos nuevos, empieza en 3.1 |
| Principal razon para seguir en 2.5 | aun necesitas async tool calling, proactive audio o affective dialog |
| Cambios grandes de migracion | thinkingBudget pasa a thinkingLevel, un evento puede traer varias partes, send_realtime_input sustituye el uso incremental de send_client_content, y las tools ahora son sincronas |
| Forma del precio | texto entrada $0.75 / 1M tokens, audio entrada $3 / 1M tokens o $0.005 / min, imagen/video entrada $1 / 1M tokens o $0.002 / min, texto salida $4.50 / 1M tokens, audio salida $12 / 1M tokens o $0.018 / min |
| Ruta segura en navegador | genera ephemeral tokens en tu backend y conecta el cliente con esos tokens |
| Trampa oculta | el turn coverage por defecto ahora incluye todos los frames de video |
Que lanzo Google exactamente el 26 de marzo de 2026
El post oficial presenta Gemini 3.1 Flash Live como el ultimo modelo de audio en tiempo real de Google y dice que esta disponible para desarrolladores en preview a traves de Gemini Live API dentro de Google AI Studio. La pagina del modelo baja eso a un contrato tecnico concreto: el codigo es gemini-3.1-flash-live-preview, acepta text, images, audio y video como entrada, y esta optimizado para dialogo de baja latencia con acoustic nuance detection, numeric precision y multimodal awareness.
Eso aclara una confusion muy comun. No existe un producto independiente llamado “Gemini 3.1 Flash Live API”. Existe Gemini Live API, y este es uno de los modelos que puedes ejecutar sobre esa superficie. La propia Live API es una sesion WebSocket con estado, pensada para streaming continuo, interrupciones, entrada multimodal y respuestas habladas, no para un simple ciclo request-response como generateContent.
La consecuencia practica es que no debes leerlo como “otro modelo de voz” sin mas. La documentacion oficial dice que soporta function calling y Search grounding, asi que el caso de uso real no es solo sintesis de voz. Es un agente conversacional que puede escuchar, razonar, usar herramientas y responder en el mismo hilo de interaccion. La misma pagina del modelo fija un knowledge cutoff en enero de 2025, por lo que si tu producto necesita informacion actual, debes planear grounding o tu propio retrieval.
Tambien hay dos matices tecnicos faciles de pasar por alto. Primero, la ficha del modelo dice text and audio output, pero la guia de capacidades de Live API indica que los native audio models solo soportan AUDIO response modality. La lectura mas segura para produccion es: si necesitas texto legible, usa output audio transcription en lugar de asumir un comportamiento de modelo puramente textual. Segundo, el post de lanzamiento dice que todo el audio generado se marca con SynthID. Para una app orientada a usuarios, eso forma parte del contrato del producto.
Conviene empezar en Gemini 3.1 Flash Live o quedarse un tiempo en 2.5
Para proyectos nuevos, Gemini 3.1 Flash Live es el punto de partida correcto. Google lo posiciona como su mejor modelo actual de audio en tiempo real y la propia documentacion de migracion deja claro que espera movimiento desde gemini-2.5-flash-native-audio-preview-12-2025. Pero “migrar” no significa “todo lo de 2.5 existe igual o mejor en 3.1”.
La pregunta util es si tu sistema actual depende de capacidades que 2.5 todavia tiene y 3.1 no. Por eso la tabla de migracion vale mas que los titulares del lanzamiento.
| Diferencia practica | Gemini 3.1 Flash Live | Gemini 2.5 Flash Live |
|---|---|---|
| Model ID | gemini-3.1-flash-live-preview | gemini-2.5-flash-native-audio-preview-12-2025 |
| Lanzamiento / ultima actualizacion | lanzado el 26 de marzo de 2026 | ultima actualizacion en septiembre de 2025 |
| Limite de output tokens | 65,536 | 8,192 |
| Control de thinking | thinkingLevel con minimal, low, medium, high | thinkingBudget |
| Forma del evento | un evento puede traer varias partes a la vez | un evento trae una sola parte |
| Texto incremental | send_client_content solo para seed inicial; el vivo va con send_realtime_input | send_client_content puede seguir usandose durante la conversacion |
| Turn coverage por defecto | TURN_INCLUDES_AUDIO_ACTIVITY_AND_ALL_VIDEO | TURN_INCLUDES_ONLY_ACTIVITY |
| Async function calling | no soportado | soportado |
| Proactive audio | no soportado | soportado |
| Affective dialog | no soportado | soportado |
| Mejor encaje hoy | nuevos agentes de voz y equipos que priorizan el modelo mas nuevo | despliegues de 2.5 que aun dependen de capacidades que 3.1 no trae |
Hay dos lecturas claras.
La primera es que 3.1 mejora de verdad donde importa para una experiencia de voz viva.
Google habla de mejor comprension tonal, mejor rendimiento en tareas complejas y mejor comportamiento en benchmarks de audio. El salto de 8,192 a 65,536 output tokens tambien le da mucho mas aire para turnos largos y respuestas mas ricas.
La segunda es que 3.1 todavia no es la mejor opcion para todas las apps ya montadas sobre 2.5.
Si tu arquitectura usaba behavior: NON_BLOCKING para que la conversacion siguiera mientras las herramientas trabajaban, ese patron hoy no se mantiene. La guia de capacidades lo dice sin rodeos: Gemini 3.1 Flash Live usa tool calling secuencial. Y si tu UX se apoyaba en proactive audio o affective dialog, perder esas piezas puede pesar mas que ganar calidad de voz.
Asi que la decision puede resumirse asi:
- si empiezas desde cero, usa 3.1
- si ya tienes un flujo productivo en 2.5, migra solo cuando las nuevas restricciones te encajen de verdad

El precio por fin se puede leer como operador y no solo como cuota de tokens
La pagina oficial de precios es muy util porque no solo habla en tokens. Tambien da precios por minuto, y para una aplicacion de voz eso es mucho mas cercano a la realidad de producto.
| Concepto | Precio actual |
|---|---|
| Text input | $0.75 / 1M tokens |
| Audio input | $3.00 / 1M tokens o $0.005 / minuto |
| Image/video input | $1.00 / 1M tokens o $0.002 / minuto |
| Text output | $4.50 / 1M tokens |
| Audio output | $12.00 / 1M tokens o $0.018 / minuto |
| Search grounding | 5,000 prompts gratis al mes compartidos en Gemini 3; despues $14 / 1,000 queries |
Eso permite hacer cuentas practicas enseguida. Si asumes una conversacion con audio entrando y saliendo de forma continua, la tarifa publicada implica aproximadamente $0.023 por minuto solo en audio. Una llamada de 10 minutos sale alrededor de $0.23 antes de sumar grounding, imagen, video o infraestructura. No es una cita textual de Google; es una inferencia directa desde $0.005 / minuto de entrada y $0.018 / minuto de salida.
El grounding con Search es la otra linea que muchos subestiman. A $14 / 1,000 queries, cada query sale aproximadamente $0.014 una vez agotado el tramo gratuito. Si una llamada dispara cinco busquedas, el extra ronda $0.07. Sigue sin parecer enorme, pero en productos intensivos si termina moviendo el margen.
El verdadero riesgo escondido esta en el video. La guia de migracion indica que el turn coverage por defecto incluye todos los frames de video. Si en 2.5 tu app ya estaba acostumbrada a mandar una camara abierta mientras el trabajo real era solo de voz, 3.1 puede subir la factura sin que lo notes.
Y luego esta el tema de cuotas. Google no publica de forma limpia los RPM/RPD exactos para este modelo en la pagina publica, sino que te manda a AI Studio para ver tus rate limits activos. Eso obliga a una regla sana: usa la pagina publica para entender el precio, pero usa AI Studio para validar la capacidad real que tiene hoy tu proyecto.
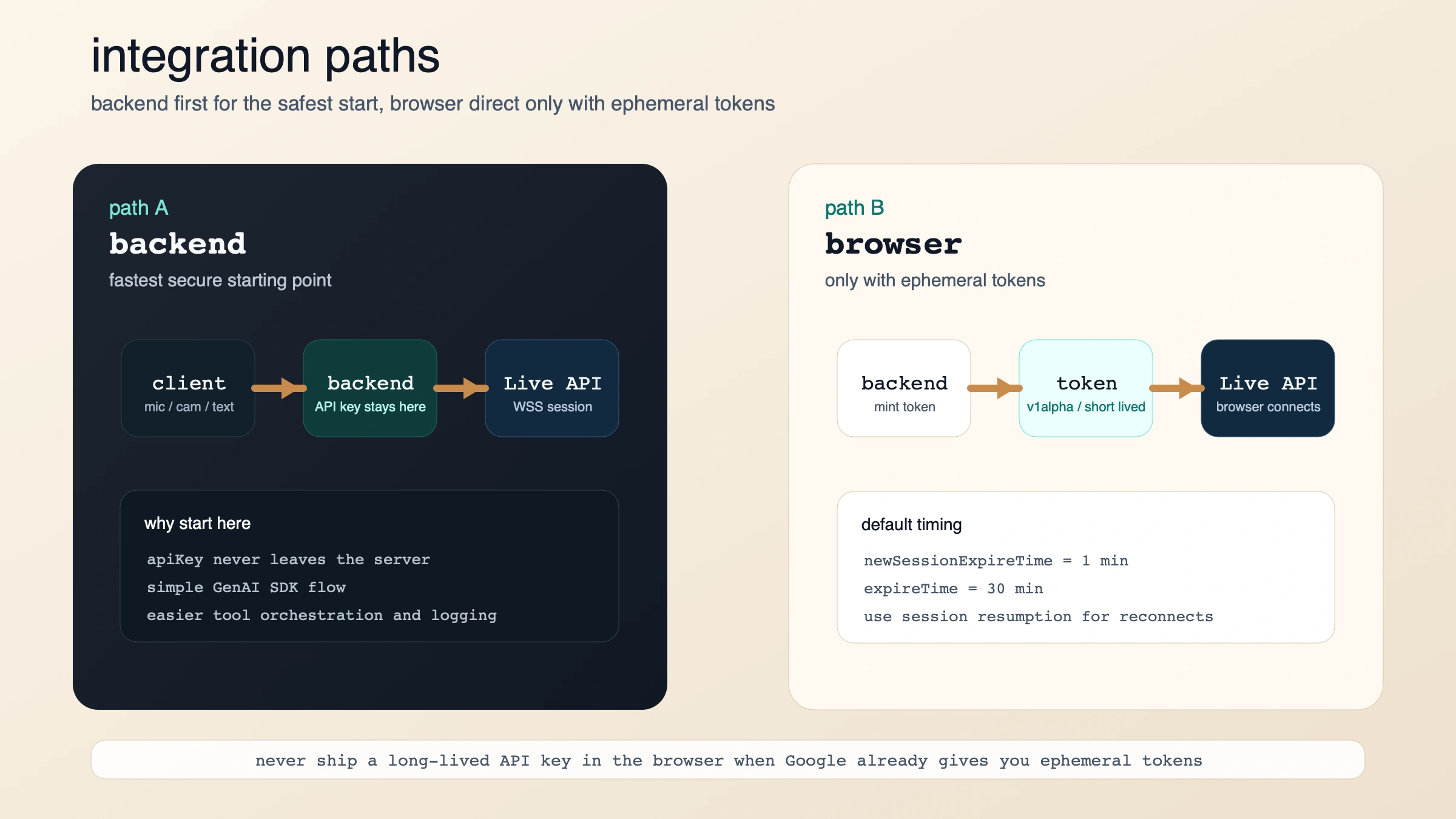
La ruta mas rapida que funciona: backend primero, navegador despues
Si lo que quieres es tener algo vivo cuanto antes, la mejor ruta sigue siendo server-to-server. El overview de Live API la trata como arquitectura por defecto y la guia de capacidades ensena el patron base: abrir una sesion Live, pedir AUDIO y enviar send_realtime_input segun lleguen audio, texto o video.
pythonimport asyncio from google import genai client = genai.Client() MODEL = "gemini-3.1-flash-live-preview" async def main(): config = {"response_modalities": ["AUDIO"]} async with client.aio.live.connect(model=MODEL, config=config) as session: await session.send_realtime_input( text="Say hello and introduce yourself in one sentence." ) async for response in session.receive(): if response.server_content and response.server_content.model_turn: for part in response.server_content.model_turn.parts: if part.inline_data: audio_bytes = part.inline_data.data # Reproduce o reenvia audio_bytes aqui. if response.text: print(response.text) if response.server_content and response.server_content.turn_complete: break asyncio.run(main())
Cuando salgas del ejemplo minimo y pases a audio real, Google pide PCM de 16 bits a 16kHz en little-endian como entrada, con un MIME type del estilo audio/pcm;rate=16000. El audio de salida llega a 24kHz PCM. La misma guia fija ademas los limites de sesion: 15 minutos para audio-only y 2 minutos para audio+video, salvo que añadas las tecnicas de session management y resumption.
Si necesitas browser direct, la solucion de Google no es exponer tu API key en el frontend, sino usar ephemeral tokens. La guia oficial explica que su valor esta justo ahi: mejor latencia del lado cliente sin desplegar una credencial de larga vida.
Los defaults importantes son:
- normalmente tienes 1 minuto para abrir una nueva sesion con el token
- despues sueles tener 30 minutos para seguir enviando mensajes sobre esa conexion
- el cliente usa el token como si fuera una API key
- si necesitas reconexiones limpias, debes pasar por session resumption
Eso deja una regla simple:
- solo backend: camino mas seguro y facil
- navegador directo: solo si tu backend ya emite ephemeral tokens
Los errores de migracion que mas tiempo te hacen perder
Lo peor de migrar de 2.5 a 3.1 no es que todo falle con ruido. Lo peor es que varias cosas siguen “medio funcionando” mientras la app ya se comporta distinto.
1. Deja de enviar thinkingBudget.
En 3.1 debes usar thinkingLevel, y el valor por defecto es minimal para favorecer la latencia. Si sigues pensando como en 2.5, estas tocando la perilla equivocada.
2. Lee todas las parts de cada evento del servidor.
La documentacion de 3.1 dice que un solo evento puede incluir audio y transcripcion a la vez. Si tu parser seguia asumiendo una parte por evento, puedes perder datos sin darte cuenta.
3. Para actualizaciones en vivo usa send_realtime_input.
En 2.5, send_client_content podia seguir moviendo la conversacion. En 3.1 queda solo para seed inicial. Todo lo vivo debe pasar por send_realtime_input.
4. Diseña las tools como bloqueantes.
Este es el downgrade operativo mas importante para muchos agentes. En 3.1, las functions son sincronas. El modelo espera la respuesta de la herramienta antes de continuar. Si en 2.5 tu experiencia dependia de herramientas en segundo plano mientras la charla seguia, ahora necesitas rediseñar esa capa.
5. Quita de la configuracion proactive audio y affective dialog.
Hoy no estan soportados en 3.1. Dejar configuracion muerta solo complica el debug.
6. El video no es gratis solo porque la API lo acepte.
Como el coverage por defecto incluye todos los frames, una camara abierta de forma continua es una decision de coste, no solo una comodidad de UX.
7. Si quieres texto, piensalo como transcripcion.
La documentacion de Google es algo torpe aqui: una pagina habla de salida en texto y audio, otra insiste en AUDIO response modality. El enfoque seguro es tratar el texto como una capa de transcripcion y no como un contrato de salida textual puro.
Cuando Gemini 3.1 Flash Live no es la mejor opcion
Hay muchos casos en los que, aun reconociendo sus ventajas, no es la siguiente decision correcta.
Si no estas construyendo un producto de voz en tiempo real, Live API mete complejidad innecesaria.
Gestion de sesiones, audio PCM, interrupciones y tokens efimeros solo merecen la pena cuando la voz es el centro del producto.
Si tu producto actual depende de async tool use, 3.1 puede empeorar la experiencia.
Esa es la razon mas limpia para no migrar todavia. Mejor voz no compensa automaticamente peor orquestacion.
Si no puedes emitir ephemeral tokens con seguridad, no fuerces el navegador directo.
Mantener la sesion Live del lado del servidor sigue siendo la alternativa sensata.
Si solo quieres sintesis de voz, usa un modelo de TTS.
Gemini 3.1 Flash Live esta pensado para dialogo, herramientas, interrupciones y multimodalidad. Para un trabajo de “texto a audio” puro, es demasiado contrato para demasiado poco beneficio.

FAQ
Cual es el model ID exacto?
Usa gemini-3.1-flash-live-preview.
Ya esta en GA?
No. A fecha de marzo de 2026 sigue marcado como preview.
Soporta tools y Google Search?
Si. Google documenta function calling y Search grounding, pero la parte importante es que el function calling actual es sincrono.
Puedo conectarlo desde una web?
Si, pero la ruta recomendada para produccion es emitir ephemeral tokens desde tu backend y dejar que el cliente abra la sesion con esos tokens.
Cuanto puede durar una sesion?
La guia de capacidades dice 15 minutos para audio-only y 2 minutos para audio+video, salvo que añadas session management.
Devuelve texto o solo audio?
La pagina del modelo menciona texto y audio, pero la guia de capacidades insiste en AUDIO response modality para native audio models. Si necesitas texto legible, trata esa necesidad como transcripcion de salida.
El audio generado lleva marca?
Si. El post de lanzamiento dice que el audio generado con Gemini 3.1 Flash Live se marca con SynthID.
La regla de migracion en una frase?
Empieza los proyectos nuevos sobre Gemini 3.1 Flash Live, pero conserva Gemini 2.5 Flash Live solo si tu experiencia actual aun depende de async tools, proactive audio o affective dialog.