Claude Code se siente “caro” por una razón distinta a la del chat normal: no solo responde, sino que arrastra contexto, archivos, resultados de herramientas y salida del modelo dentro de un bucle agente. Desde tu punto de vista escribiste una petición corta en la terminal; desde la perspectiva del sistema, Claude Code ya leyó código, ejecutó comandos, revisó resultados y volvió a meter todo eso en el siguiente turno. Lo que más confunde hoy es que “usage” ya no significa un número simple. Si usas Pro o Max, Claude Code comparte el mismo cupo que Claude en web, escritorio y móvil, y ese consumo se entiende sobre todo en ventanas de 5 horas y límites semanales. Si tienes ANTHROPIC_API_KEY en el entorno, o cambias a pay-as-you-go, Claude Code deja de comportarse como una función de suscripción y pasa a comportarse como tráfico API, con RPM, TPM de entrada, TPM de salida y límites de gasto. Separar esas dos superficies aclara casi todo.
Esta guía se apoya en información pública verificable al 2 de abril de 2026. Explica cómo se mide hoy el uso en Claude Code, por qué se consume más rápido que en el chat, cómo leer Settings > Usage, /status y /cost, y qué optimizaciones siguen valiendo después de las actualizaciones recientes de Anthropic. La idea no es darte otra tabla estática de “cuántas horas por semana” que quede obsoleta el mes que viene. La idea es darte un modelo útil para decidir si hoy te conviene limpiar contexto, cambiar de modelo, activar extra usage o mover un sprint pesado a facturación API.
Resumen rápido
- Claude Code no tiene un único medidor universal. En Pro y Max importa el límite compartido de sesiones de 5 horas y el límite semanal; en modo API importan RPM, TPM de entrada, TPM de salida y topes de gasto.
- Lo que más mueve el consumo suele ser el tamaño del contexto, no solo la cantidad de prompts. Repos grandes, sesiones largas, tool loops intensos, sobrecarga MCP y modelos más caros se van acumulando.
- Para usuarios de Pro y Max, las dos vistas más importantes hoy son
Settings > Usagey/status. Para entender por qué una sesión concreta se volvió cara, la referencia es/cost. - Sonnet 4.6 y Opus 4.6 pueden usar 1M de contexto en Claude Code, pero en planes de pago de Claude esa ruta está ligada a las reglas actuales y al acceso vía extra usage. Una ventana mayor ayuda, pero también vuelve más caro un mal manejo del contexto.
- El ahorro más rápido no suele venir de “preguntar menos”, sino de cortar sesiones viejas, compactar antes, usar Sonnet o Haiku por defecto y reducir lo que Claude necesita leer antes de actuar.
- Si el consumo te parece ilógico, primero confirma qué ruta de cobro estás usando, qué modelo está activo, qué tamaño real de contexto llevas y si estás trabajando en una franja más restringida.
Qué significa realmente “usage” en Claude Code ahora mismo

El error más común es tratar el uso de Claude Code como si fuera una sola cuota. En la práctica, Anthropic hoy expone dos sistemas distintos de contabilidad, y Claude Code puede saltar entre ellos según cómo te autentiques.
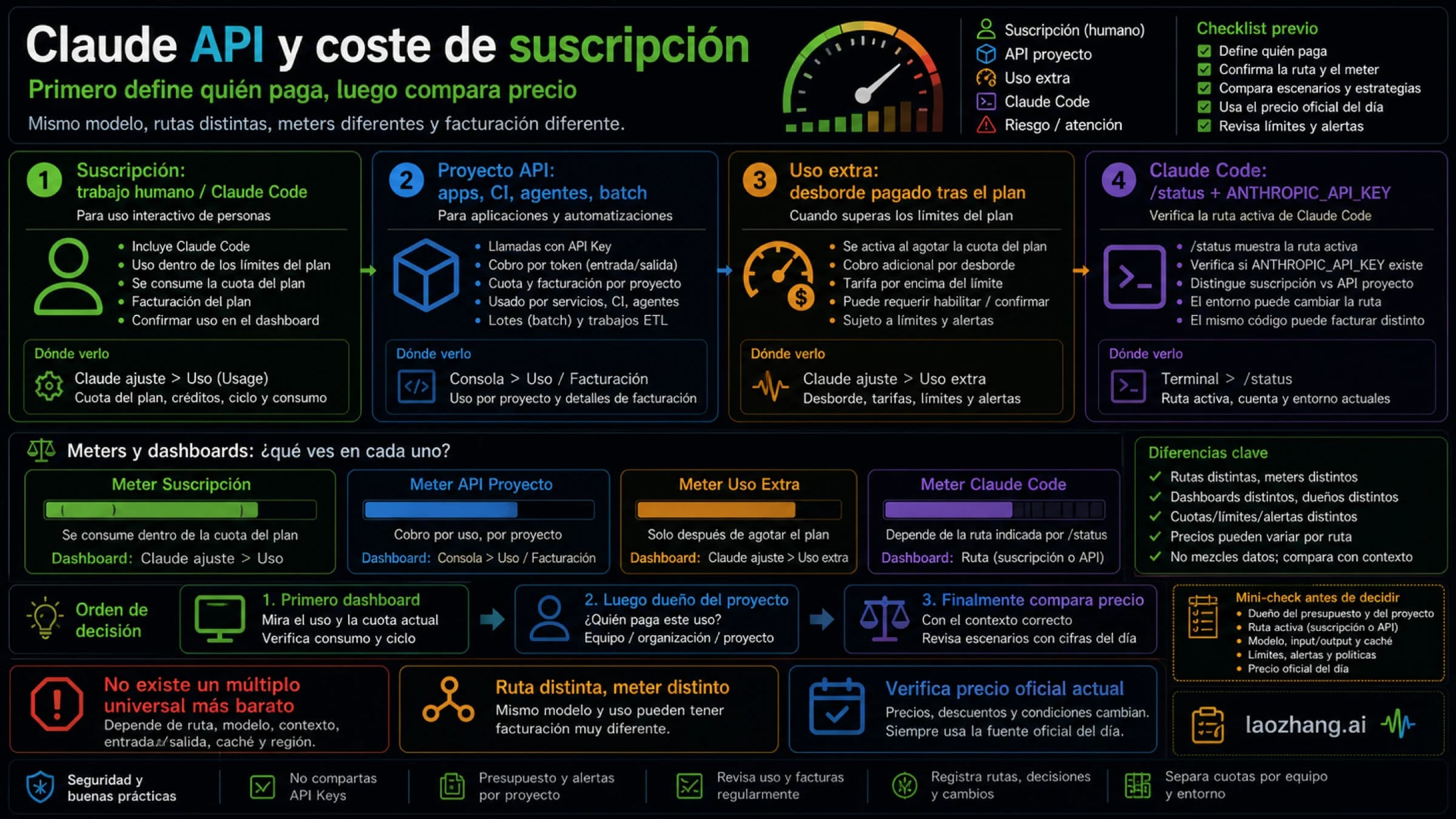
Si usas una suscripción Pro o Max, Claude Code tira del mismo pool compartido que Claude en web, escritorio y móvil. El help center actual de Anthropic te manda a Settings > Usage, donde aparecen tanto el uso de la sesión actual de 5 horas como los límites semanales. Ese es el marco oficial que hoy debería usar cualquier usuario individual. Por eso muchas páginas antiguas que hablaban de “cuota diaria”, “número fijo de prompts” o “tantas horas por semana” son bastante menos fiables de lo que parecen. La ayuda oficial también deja claras dos cosas que antes muchos deducían a ciegas: Claude y Claude Code comparten uso, y cuando se agota el uso incluido, tus salidas oficiales son esperar el reset, activar extra usage o pasar a pay-as-you-go con Console.
Si usas Claude Code con API key, el sistema cambia por completo. La documentación API de Anthropic mide el uso con requests per minute, input tokens per minute y output tokens per minute, además de topes de gasto por tier. Para un usuario API, la pregunta importante ya no es “¿cuánto me queda del plan?”, sino “¿qué bucket me está frenando?”. Puedes tener saldo en Console y aun así chocar con ITPM o RPM.
Hay además una trampa fácil de pasar por alto. Anthropic advierte de forma explícita que, si ANTHROPIC_API_KEY está presente, Claude Code usa esa autenticación en lugar de tu suscripción Pro o Max. Es decir: puedes creer que estás consumiendo el cupo del plan y en realidad estar generando cargos API. Cuando alguien dice “Claude Code me quemó los tokens”, lo primero que conviene revisar no es el número de tokens. Es la ruta de facturación.
La forma más útil de pensarlo es esta: en Pro/Max gestionas ventanas de sesión y límite semanal; en API gestionas throughput y gasto. La sensación final puede parecer parecida porque ambos caminos te detienen cuando llegas al borde, pero los controles son distintos. El lado de suscripción se piensa en sesiones de 5 horas, weekly limits, extra usage y tiempo del día. El lado API se piensa en RPM, ITPM, OTPM, caché y topes de gasto. Mezclar ambas cosas es lo que hace que Claude Code parezca más misterioso de lo que realmente es.
Por qué Claude Code consume tokens más rápido que el chat normal

Claude Code se siente más caro que el chat por una razón muy simple: no es un chat de un turno disfrazado de terminal, sino una herramienta agente que vuelve a cargar contexto, llama herramientas, lee archivos, propone cambios, verifica resultados y repite ese ciclo varias veces.
El factor más importante es la acumulación de contexto. La guía de costes actual de Anthropic lo dice de forma directa: el coste escala con el tamaño del contexto. En workflows de código, esa regla pega todavía más fuerte que en un chat normal. Cada archivo adicional, cada trozo de conversación previa y cada definición MCP que dejas dentro del hilo vuelve el siguiente turno más pesado. Una sesión que al principio parece “eficiente” porque todo vive en la misma conversación puede convertirse en la forma más cara de trabajar, porque cada turno posterior arrastra más historia.
El segundo factor es el trabajo cargado de herramientas. El valor de Claude Code está justamente en que no solo contesta. Busca, lee, edita, ejecuta y verifica. Por eso la misma frase “arregla este bug” cuesta muy distinto si la dejas en una charla web o si haces que Claude Code entre realmente al repo. Tú ves una sola petición; por debajo puede haber varias iteraciones model/tool y cada una vuelve a llevar contexto.
El tercer factor es la ruta de modelo y el tamaño de la ventana de contexto. Las páginas de ayuda actuales de Anthropic dicen que los planes de pago de Claude se mueven normalmente en torno a 200K de contexto, mientras que Sonnet 4.6 y Opus 4.6 pueden llegar a 1M en Claude Code. En API, Anthropic confirma también 1M para Sonnet 4.6 y Opus 4.6, mientras que otros modelos siguen en 200K+. Una ventana más grande es potentísima, pero no es magia gratis. Solo significa que puedes meter más. Si metes más sin criterio, el consumo también sube sin criterio.
El cuarto factor es el coste de fondo que casi no ves. La documentación de Claude Code menciona ahora de forma explícita que prompt caching ayuda a reutilizar contenido repetido, que auto-compaction resume historial a medida que crece el contexto y que algunas funciones de fondo también consumen una pequeña cantidad de tokens. Anthropic describe ese gasto como pequeño, normalmente por debajo de $0.04 por sesión, pero la idea importante no es el importe exacto sino el principio: el usage de Claude Code nunca refleja solo “lo que escribí”.
Por eso “yo solo envié unos pocos prompts” es una métrica muy mala para juzgar costes. Lo que importa es qué parte del repo quedó dentro del contexto, cuánto tiempo mantuviste viva la sesión, qué modelo estaba activo y cuánto obligaste a Claude a redescubrir algo que podrías haber acotado antes.
Cómo mirar el uso sin adivinar
Si una guía sobre uso termina diciendo que estimes todo por intuición, no sirve de mucho. Anthropic ya ofrece varias maneras concretas de ver lo que pasa, pero cada una vive en un sitio distinto.
Para los suscriptores Pro y Max, la vista externa principal es Settings > Usage. La ayuda actual explica que ahí aparecen el uso actual de la sesión de 5 horas, los límites semanales y el tiempo de reset. Dentro de Claude Code, Anthropic recomienda /status como la forma rápida de ver lo que te queda. Si tu objetivo es seguir dentro del plan y evitar derramar trabajo a la ruta API, /status debería ser la primera comprobación antes de arrancar otra tarea pesada.
Para entender por qué una sesión concreta se disparó en coste, la referencia es /cost. La guía de costes de Anthropic lo presenta como el comando importante para mirar el consumo de tokens dentro de Claude Code. Si tu pregunta no es “¿cuánto queda del plan?” sino “¿por qué esta sesión se volvió tan cara?”, entonces /cost es la herramienta correcta. La documentación también habla de mostrar el coste en la línea de estado. Si usas Claude Code todos los días, vale la pena activarlo.
Para usuarios de Team, Enterprise o Console, Anthropic ya ofrece una capa más completa de Claude Code analytics: actividad, tasa de aceptación de sugerencias, líneas de código aceptadas y gasto, entre otras métricas. Pero el help center también lo deja claro: los planes individuales Pro y Max no tienen hoy ese dashboard completo. Así que el típico consejo de “busca el panel oculto” no aplica aquí.
La pila práctica se parece a esto:
| Pregunta | Mejor herramienta hoy |
|---|---|
| ¿Cuánto me queda de Pro / Max? | Settings > Usage y /status |
| ¿Por qué esta sesión se volvió cara? | /cost y coste en la línea de estado |
| ¿Cómo usa mi equipo Claude Code en conjunto? | Claude Code analytics para Team / Enterprise / Console |
| ¿En qué límite API choqué? | respuestas 429, retry-after y límites en Console |
Si te quedas con un solo hábito nuevo, que sea este: deja de medir el uso de Claude Code por intuición. Mira /status antes de tareas grandes y /cost durante la sesión. Es más fiable que casi cualquier tabla pública de “horas por semana”.
El modelo de precios y límites que sí importa hoy

En abril de 2026 Anthropic deja bastante claro el precio de los planes, pero mucho menos claro el volumen exacto que esos planes equivalen a soportar. Por eso aquí conviene separar precio publicado y capacidad efectiva no publicada.
Del lado de las suscripciones individuales, la página de precios dice que Pro cuesta $20/mes o $17/mes en el equivalente anual, y además especifica que incluye Claude Code y Claude Cowork. Max empieza en $100/mes y ofrece 5x o 20x más usage que Pro, además de más capacidad de salida y prioridad en horas de tráfico alto. Ese es el contrato público estable. Es una base mejor que cualquier artículo de terceros que intente traducirlo a “tantas horas por semana”. Si tu problema principal no es la sesión concreta sino la elección de plan, puedes complementar con nuestra comparativa Claude Code Pro vs Max y nuestra guía de precios de Claude Code.
Del lado de la facturación API, Anthropic sí publica precios exactos por token. A 2 de abril de 2026, la página de precios muestra Sonnet 4.6 a $3 por millón de tokens de entrada y $15 por millón de tokens de salida, Opus 4.6 a $5 / $25 y Haiku 4.5 a $1 / $5. Prompt caching se cobra aparte y el batch processing sigue anunciado con 50% de descuento. Para desarrolladores que trabajan por ráfagas con automatización pesada, esta unidad de coste suele ser más útil que el marketing de los planes.
La pieza realmente práctica es la tabla de tiers API, porque te ayuda a distinguir si el problema es de velocidad o de presupuesto:
| API tier | Umbral de crédito | RPM | Sonnet ITPM | Sonnet OTPM |
|---|---|---|---|---|
| Tier 1 | $5 | 50 | 30,000 | 8,000 |
| Tier 2 | $40 | 1,000 | 450,000 | 90,000 |
| Tier 3 | $200 | 2,000 | 800,000 | 160,000 |
| Tier 4 | $400 | 4,000 | 2,000,000 | 400,000 |
Esos números salen de la documentación actual de rate limits de Anthropic. La misma página también recalca algo que mucha gente pasa por alto: en la mayoría de modelos, las lecturas desde caché no cuentan contra ITPM. Por eso reutilizar bien el contexto puede sentirse como ganar un tier extra sin cambiar de tier.
La historia de la ventana de contexto también es más matizada de lo que reflejan muchos artículos viejos. El help center de Anthropic dice que los planes de pago de Claude se mueven generalmente con 200K de contexto, pero que Sonnet 4.6 y Opus 4.6 en Claude Code pueden usar 1M. En API, Anthropic también confirma 1M para Sonnet 4.6 y Opus 4.6, mientras que el resto se mantiene más cerca de 200K+. La conclusión operativa es sencilla: una ventana mayor ayuda cuando realmente la necesitas, pero también encarece un manejo perezoso del contexto.
Entonces, ¿cómo pensar la elección? Si quieres un gasto mensual relativamente predecible y usas Claude Code de forma intensa, pero no continua todo el día, Pro o Max con extra usage suele ser la vía más limpia. Si haces burst automation, tareas agente repetidas, flujos de equipo o simplemente quieres separar coste y throughput con precisión, la facturación API suele ser más fácil de gobernar. El mal hábito es pensar que todo problema de usage se arregla subiendo de plan. A veces lo que hace falta es una sesión mejor diseñada.
Siete formas de reducir consumo en Claude Code sin trabajar más lento
La mejor optimización no es usar menos Claude Code. Es evitar que Claude haga trabajo evitable.
1. Limpia contexto viejo entre tareas no relacionadas. La guía de costes de Anthropic recomienda /clear cuando cambias a trabajo no relacionado, porque el contexto viejo encarece cada turno posterior. Para usuarios intensivos, probablemente es el hábito con más palanca. Si quieres conservar el hilo, puedes renombrarlo y volver luego con /resume. El error es arrastrar toda la jornada dentro de una sola sesión heroica.
2. Haz compact antes de que el hilo se vuelva obeso. Anthropic también recomienda /compact y permite añadir instrucciones de compaction en CLAUDE.md. Esto funciona cuando la tarea sigue siendo la misma, pero la conversación ya se volvió demasiado larga. Un buen compact debe ser concreto: conserva la hipótesis actual del bug, los archivos cambiados y los fallos de test que siguen abiertos.
3. Mira /cost, no solo tu sensación. Si solo miras el coste cuando ya estás molesto, llegaste tarde. Revisa /cost durante la sesión y, si usas Claude Code a diario, saca el coste a la línea de estado.
4. Quédate en Sonnet por defecto y manda más tareas simples a Haiku. La documentación de costes de Anthropic dice que Sonnet cubre bien la mayoría de tareas de código y cuesta menos que Opus. También sugiere Haiku para trabajo más simple. En la práctica significa que formateo, explicación, pequeños refactors y cambios acotados no deberían caer automáticamente en la ruta más cara. Deja Opus para arquitectura, depuración realmente compleja y razonamiento multietapa que de verdad lo justifique.
5. Reduce el overhead de MCP y de descubrimiento. La documentación de Claude Code explica que las definiciones MCP se diferencian por carga diferida y que /context te ayuda a ver qué está ocupando espacio. También recomienda preferir herramientas CLI cuando existan, porque muchas veces son más eficientes en contexto que arrastrar un gran inventario MCP. Si puedes resolver la tarea con git, gh, rg o el CLI de tu nube, normalmente es mejor.
6. Haz que Claude lea menos antes de actuar. Anthropic recomienda plugins de code intelligence para lenguajes tipados, porque una navegación simbólica precisa reduce lecturas innecesarias de archivos. La documentación también menciona hooks y skills para filtrar o preparar información antes de que Claude cargue contexto pesado. Si siempre le pasas logs gigantes, salidas brutas de tests o el mismo discovery una y otra vez, el problema ya no es el plan sino la falta de preprocesado.
7. Elige la superficie de pago correcta para la semana que estás viviendo. Las páginas de ayuda actuales de Pro/Max ya señalan dos salidas oficiales cuando se acaba el usage incluido: extra usage o pay-as-you-go. Para una migración puntual, una semana de agentes intensivos o un refactor especialmente pesado, muchas veces es más razonable usar la ruta diseñada para picos que exprimir a la fuerza el plan mensual habitual.
La lógica detrás de las siete es la misma: recorta contexto, elige modelos con intención y evita que Claude reaprenda lo que ya podrías haberle dado más limpio.
Cuando el uso sigue sintiéndose mal
Una buena guía de uso también tiene que decirte cuándo el problema puede no ser del todo tuyo.
La primera situación es confusión de autenticación. Si hay una API key en el entorno, Claude Code puede estar funcionando por facturación API en lugar de por tu suscripción. Desde el punto de vista del usuario, eso se siente como “Claude Code está gastando demasiado”; desde el punto de vista del sistema, simplemente cambió la superficie de cobro.
La segunda es variabilidad en el comportamiento de los límites. A finales de marzo de 2026 aparecieron issues de GitHub, discusiones en Reddit y cobertura técnica sobre sesiones de 5 horas que se agotaban más rápido de lo esperado y franjas pico más agresivas. Las páginas de ayuda de Anthropic ya reconocen la existencia de límites de 5 horas y semanales, pero no publican una tabla estable y eterna de toda la regulación dinámica. La conclusión más segura no es “todas las quejas son ciertas”, sino otra: las estimaciones estáticas viejas valen menos que los indicadores vivos del producto. Si tu experiencia choca con un artículo antiguo, confía primero en Settings > Usage, /status y /cost.
La tercera es usar por defecto una ruta de contexto demasiado grande. El debate alrededor de 1M de contexto ha generado mucha confusión. Lo que Anthropic confirma oficialmente es que Sonnet 4.6 y Opus 4.6 pueden llegar a 1M en Claude Code. Eso no significa que debas trabajar siempre con la ventana máxima. Si el gasto te parece peor que antes, primero prueba las explicaciones simples: modelo más pequeño, contexto más pequeño, sesión nueva, revisar si hay API key activa y considerar el factor horario.
Si lo que necesitas no es el modelo mental sino una receta para recuperarte de un error concreto, te conviene más nuestra guía para arreglar el error Claude Code “Rate limit reached”. Este artículo explica el “por qué”; aquel explica el “qué hago ahora”.
Preguntas frecuentes
¿Claude Code tiene una cuota separada de Claude en la web?
No en planes individuales Pro y Max. El help center de Anthropic dice que el uso es compartido entre Claude y Claude Code. Si usas facturación API, entonces sí estás en otra superficie con otras reglas y otros límites.
¿El contexto de 1M está siempre disponible en Claude Code?
No. Las páginas actuales de ayuda dicen que los planes de pago de Claude operan normalmente con 200K, mientras que Sonnet 4.6 y Opus 4.6 pueden llegar a 1M dentro de Claude Code. En API, Anthropic también confirma 1M para Sonnet 4.6 y Opus 4.6. Que un modelo soporte 1M no significa que debas usarlo como modo por defecto.
¿Los usuarios individuales de Pro o Max tienen Claude Code analytics?
Hoy no. La ayuda de Anthropic sobre usage analytics dice explícitamente que esa capa está disponible para Team, Enterprise y usuarios de Console, no para planes individuales Pro o Max. En uso personal, lo correcto es mirar Settings > Usage, /status y /cost.
¿Prompt caching realmente ayuda a reducir consumo?
Sí, aunque el efecto depende de la superficie. La documentación API de Anthropic dice que, para la mayoría de modelos, las lecturas desde caché no cuentan en ITPM. En términos prácticos eso mejora throughput. Más ampliamente, reutilizar contexto estable siempre es más barato que obligar a Claude a releerlo todo desde cero.
¿Me quedo en Pro, subo a Max o me paso a API?
Si Claude Code te ayuda a diario pero todavía no es el motor principal de toda la jornada, empezar por Pro suele ser lo más razonable. Si los resets ya te interrumpen de forma recurrente durante el trabajo normal, Max empieza a tener sentido. Si necesitas ráfagas pesadas, automatización, flujos de equipo o control fino del gasto, la ruta API suele ser más clara.
¿Por qué al principio va bien y luego de repente se vuelve caro?
Porque la sesión pesa más con el tiempo. Se acumulan historial de conversación, archivos ya cargados, salidas de herramientas y coste de la ruta de modelo. El arreglo más común no es “hacer menos preguntas”, sino abrir sesión nueva, compactar antes y limitar el contexto a lo que esta tarea realmente necesita.