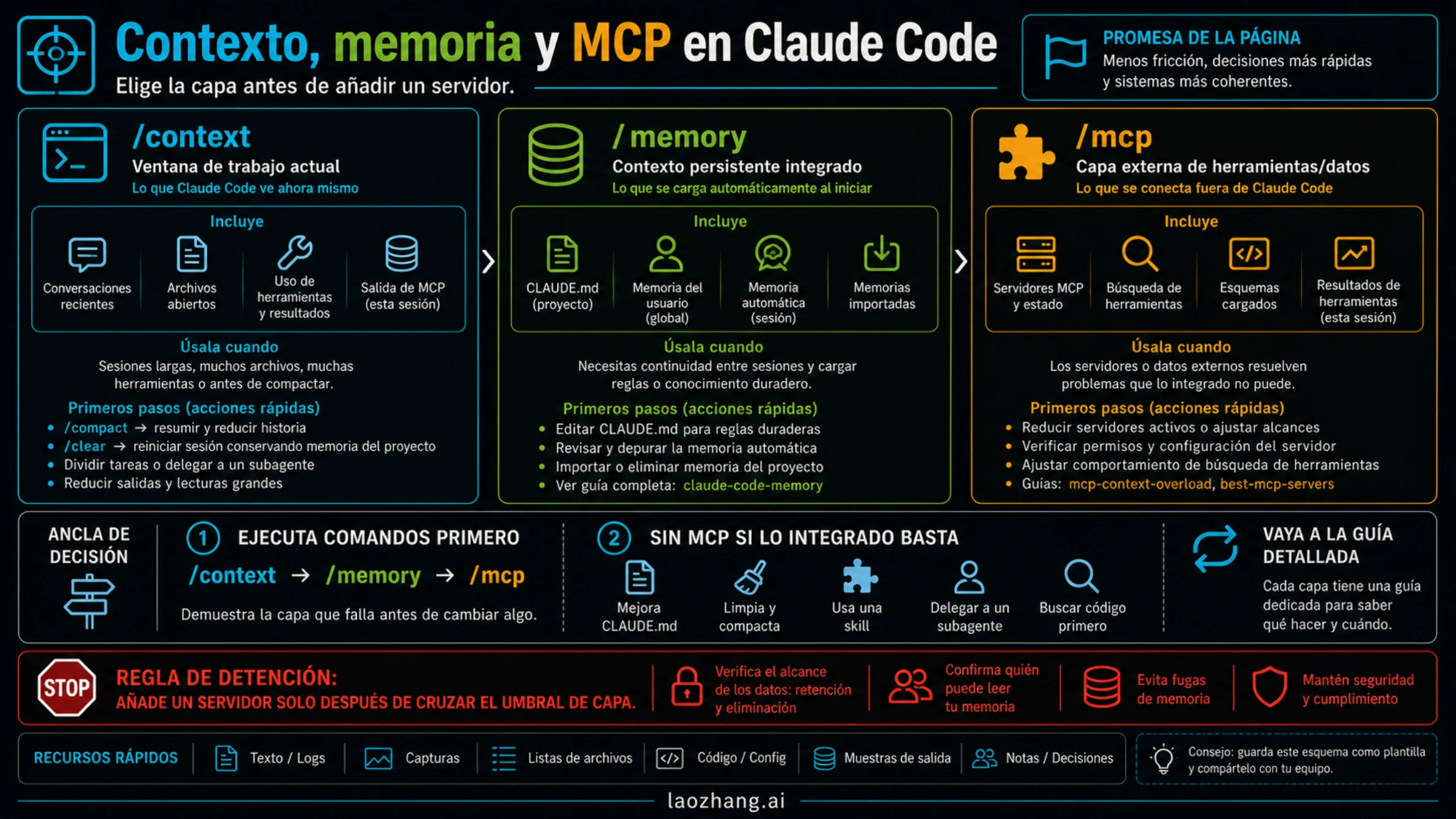
El contexto, la memoria y MCP en Claude Code no son la misma capa. Cuando Claude "olvida" una regla, arrastra una rama vieja de la conversación o se vuelve impreciso después de leer demasiado, la reacción tentadora es instalar un memory MCP. Ese salto suele ser prematuro. Primero hay que probar si falló la ventana de trabajo actual, la memoria integrada que se carga al inicio, o el acceso externo que llega por MCP.
La ruta rápida es esta:
| Síntoma | Ejecuta primero | Qué demuestra | Arreglo menor antes de un servidor |
|---|---|---|---|
| La sesión larga empieza a desviarse | /context | La ventana actual está presionada por conversación, archivos, tools o resultados MCP | Compactar en un límite, limpiar residuos, dividir la tarea o reducir salida |
| Una sesión nueva no trae una regla del proyecto | /memory | Qué CLAUDE.md, imports o auto memory están cargados | Editar la memoria durable en el alcance correcto |
| Las herramientas externas son ruidosas o sospechosas | /mcp | Qué MCP servers están conectados y qué capa externa participa | Desactivar servers ruidosos, reducir scope o arreglar conexión |
| El mismo proceso se vuelve a explicar siempre | /skills o subagent | Si el problema es método reutilizable o exploración aislada | Crear un skill o mover la lectura grande a un subagent |
La regla de parada es sencilla: si un CLAUDE.md más limpio, /compact, /clear, un skill, un subagent o la búsqueda de código resuelven el problema, todavía no necesitas un memory MCP externo. Considera un servidor de memoria solo cuando necesitas continuidad entre máquinas, memoria compartida de equipo, recuperación entre herramientas o estado de trabajo dinámico que no cabe bien en la memoria integrada. Antes de conectarlo, revisa retención, borrado, permisos de lectura y riesgo de guardar secretos.
Respuesta rápida: qué capa falló
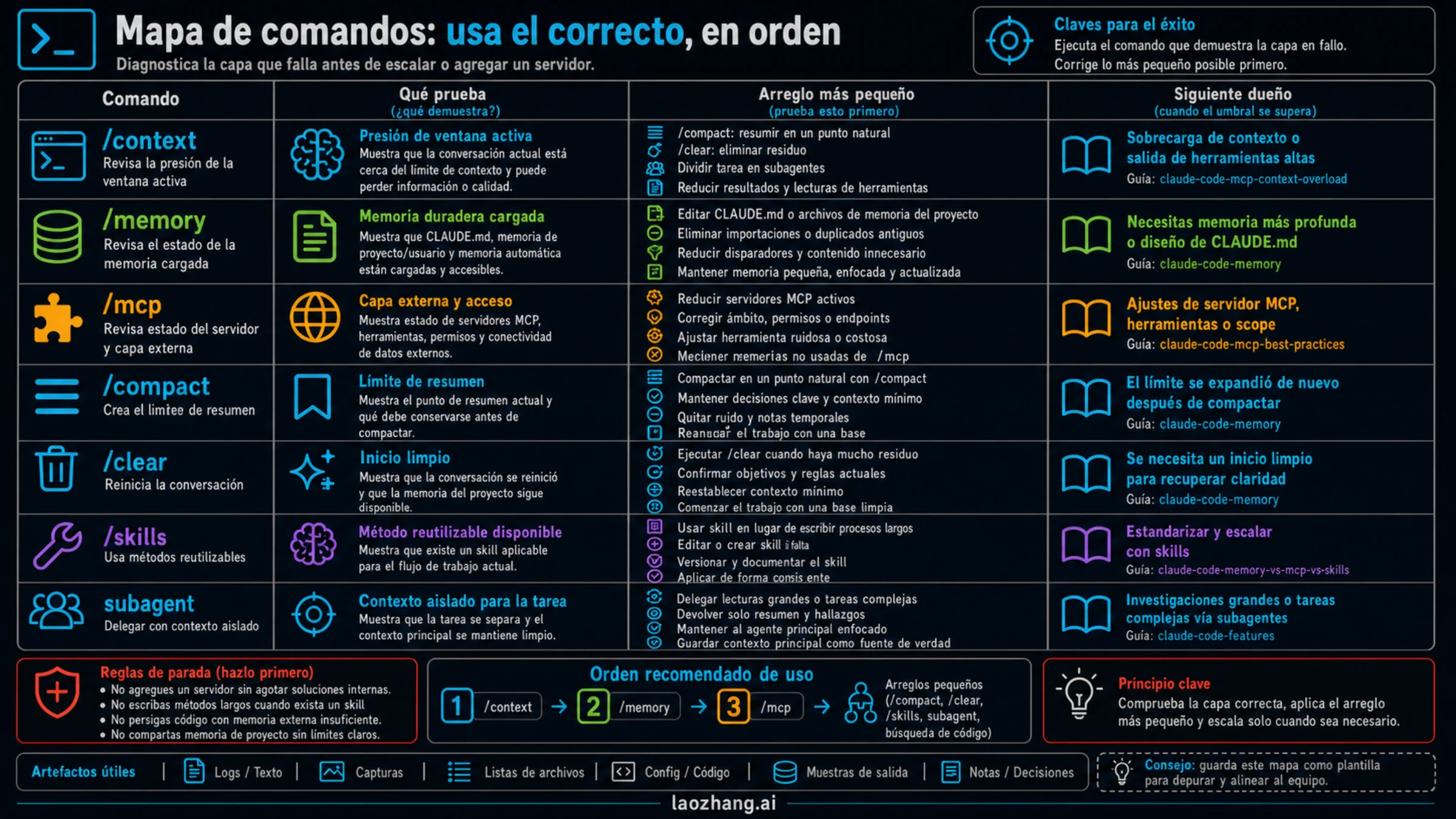
Piensa en la continuidad de Claude Code como capas, no como un único interruptor de memoria. La conversación activa es la ventana que Claude puede ver ahora. La memoria integrada es el contexto de proyecto o usuario que entra al inicio de una sesión. MCP es la capa de herramientas, datos y acciones externas. Los skills guardan método reutilizable. Los subagents aíslan trabajo grande para que no ensucie la conversación principal.
La búsqueda en español ya mezcla estas ideas: documentación de ventana de contexto, búsqueda semántica por MCP, Mem0, videos de ahorro de tokens y servidores de memoria. Esa mezcla confirma que la necesidad existe, pero no dice qué instalar. El primer trabajo de una buena guía es separar propietarios. Si no lo haces, puedes añadir un servidor a un contexto que ya estaba saturado.
| Patrón de fallo | Propietario probable | Superficie de prueba | Próximo movimiento |
|---|---|---|---|
| La sesión mantiene decisiones descartadas | Current context window | /context | Compactar, limpiar, dividir o limitar outputs |
| Falta una regla estable al abrir sesión nueva | Built-in memory | /memory | Editar CLAUDE.md, import o user memory |
| Tools ausentes, duplicadas, grandes o desconectadas | MCP | /mcp | Corregir server, reducir tools o limitar salida |
| Un procedimiento repetido se explica cada vez | Skill | /skills | Convertir el método en skill |
| Una investigación lateral es demasiado grande | Subagent | Handoff summary | Aislar lectura y devolver solo conclusiones |
| Se necesita memoria entre máquinas, tools o equipo | External memory MCP | Política del server | Revisar privacidad, borrado y rollback |
Esta matriz no compite con los servidores de memoria. Los coloca en el momento correcto. Si la evidencia apunta a memoria integrada, el arreglo está en CLAUDE.md. Si apunta a MCP, limpia el server. Si apunta a procedimiento, crea un skill. Si de verdad apunta a recuperación externa y compartida, entonces sí vale comparar memory MCPs.
Qué prueba /context
/context prueba la ventana activa de trabajo. Dentro de esa ventana viven las instrucciones, archivos leídos, respuestas del modelo, resultados de tools, material cargado por MCP, memoria integrada y resúmenes de compaction. Por eso es la primera parada cuando la calidad cae dentro de una sesión larga. No prueba que falte memoria duradera; prueba qué material está compitiendo por atención ahora.
Las señales típicas son muy concretas. Claude vuelve a una opción que ya descartaste. Un log grande cambia la calidad de las siguientes respuestas. Un MCP server devuelve demasiado JSON. Después de compactar, sobreviven frases generales pero se pierden límites críticos. La misma conversación contiene investigación, implementación, revisión y publicación. En esos casos, un memory MCP puede añadir más definiciones, más resultados y más decisiones de confianza a una ventana que ya estaba llena.
El arreglo empieza con higiene de contexto. Compacta cuando hay una decisión estable y deja solo decisiones, rutas, riesgos y próximos pasos. Mueve exploraciones grandes a un subagent. Pide a las herramientas resúmenes, handles, paginación y campos concretos. Si la conversación ya acumuló demasiadas ramas erróneas, usa /clear y vuelve a cargar la memoria de proyecto. Eso suele ser más barato que convertir el problema en arquitectura externa.
Qué posee la memoria integrada
La memoria integrada posee información estable que debe estar disponible al empezar una sesión: reglas de repositorio, nombres, comandos de test, límites de publicación, preferencias de usuario, rutas de documentación y principios de trabajo. Entra por CLAUDE.md, imports o auto memory, y por eso también consume espacio de contexto. Una memoria buena debe ser corta y accionable.
No es el lugar para transcripciones completas, logs largos, todo el historial de decisiones, tablas enormes o investigación sin filtrar. Esos materiales pertenecen a archivos, issues, docs o sistemas externos. En la memoria deja una regla breve y una referencia: qué importa, cuándo se aplica y dónde está el detalle. Si conviertes la memoria integrada en archivo histórico, cada sesión empieza con ruido.
Usa /memory cuando una sesión nueva no conoce una regla que debería conocer. La salida te ayuda a separar tres casos: la regla nunca se guardó; se guardó en el alcance equivocado; se cargó, pero el contexto actual está tan lleno que Claude no la está usando bien. Los dos primeros casos se arreglan editando memoria. El tercero vuelve a /context. Ninguno exige instalar automáticamente un servidor externo.
Qué posee MCP
MCP posee acceso externo. Conecta Claude Code con buscadores de código, bases de datos, navegadores, issue trackers, documentos, servicios internos y acciones. Un memory MCP también es un MCP server, por lo que debe evaluarse como infraestructura externa: transporte, permisos, descripción de tools, tamaño de resultados, retención, borrado y control de secretos.
/mcp es útil cuando sospechas de la capa externa. ¿Hay servers desconectados? ¿Demasiadas tools expuestas? ¿Tools duplicadas? ¿Descripciones largas? ¿Resultados crudos gigantes? ¿Un server de búsqueda semántica está devolviendo más contexto del que el modelo puede usar? Si el MCP layer ya está ruidoso, añadir memoria externa agrava el problema.
También conviene separar búsqueda de código, memoria de proyecto y estado duradero. La búsqueda de código responde dónde está un archivo o símbolo. La memoria integrada responde qué reglas debe recordar el proyecto. Un memory MCP externo responde cómo recuperar estado dinámico entre sesiones, máquinas o herramientas. Si guardas ubicaciones de código como memoria duradera, pronto mezclarás hechos caducados con reglas reales.
Arreglos menores antes de un memory MCP
Si repites el mismo procedimiento, usa un skill. Un skill puede contener pasos, referencias, checklist y ejemplos sin cargar todos los detalles en cada sesión. La memoria dice qué debe saber Claude al arrancar. El skill dice cómo ejecutar un trabajo repetible. Esta separación evita convertir métodos en una masa de memoria permanente.
Si necesitas leer muchas zonas del repo, usa un subagent o una conversación aislada. La conversación principal necesita conclusión, evidencia, riesgos y siguiente paso, no todo el historial de lectura. Para auditorías de código, análisis de logs, localización o investigación competitiva, esa separación protege más que un servidor de memoria, porque evita residuos en el hilo principal.
No subestimes /compact y /clear. /compact sirve cuando ya hay una decisión estable y necesitas conservarla en forma breve. /clear sirve cuando el hilo está contaminado y conviene empezar limpio, dejando que la memoria de proyecto vuelva a cargarse. Si estas dos operaciones recuperan calidad, el problema era gestión de contexto, no falta de memoria externa.
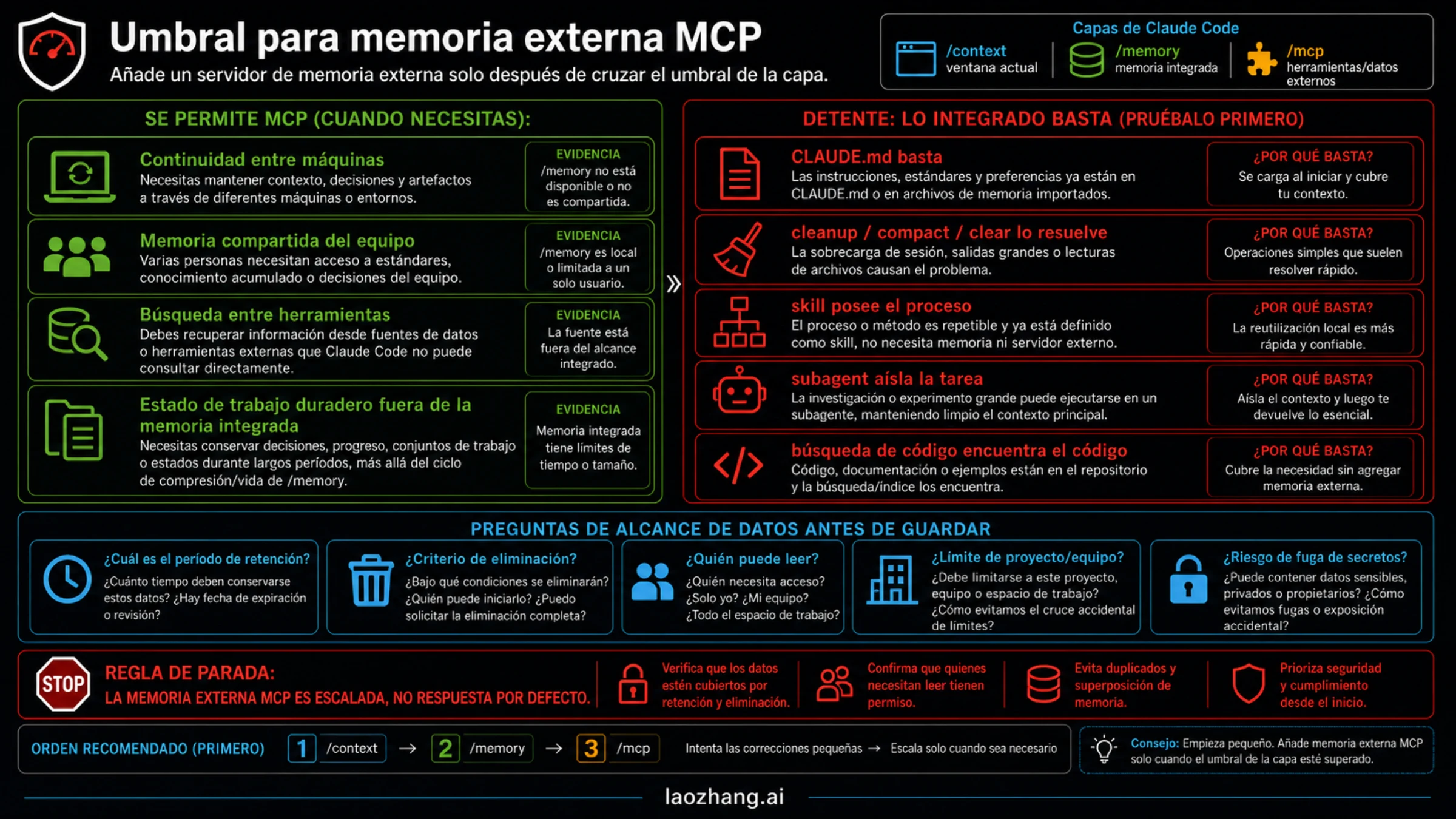
Cuándo sí se justifica un memory MCP externo
Un memory MCP externo se justifica cuando aparece un umbral real. El primero es continuidad entre máquinas o entornos: trabajas en varias máquinas, IDEs o agentes y la memoria local no basta. El segundo es memoria compartida de equipo: varias personas o agentes deben leer los mismos hechos de proyecto. El tercero es recuperación entre herramientas: issues, docs, chats y eventos de código están repartidos y necesitas buscarlos juntos. El cuarto es estado dinámico demasiado grande o cambiante para CLAUDE.md.
Incluso entonces, revisa los datos. ¿Dónde se aloja el server? ¿Quién puede leer? ¿Cómo se borra una entrada? ¿Guarda texto crudo, resúmenes, embeddings o facts escritos por el usuario? ¿Qué impide guardar claves, datos de cliente o información sensible? ¿Hay rollback? Si estas respuestas son vagas, el server no debe entrar en el flujo por defecto.
La implementación responsable empieza pequeña. Define un proyecto, hechos permitidos, hechos prohibidos, borrado y criterio de éxito. Tras varias tareas reales, comprueba si bajó la repetición, si el contexto se saturó menos, si la recuperación fue más precisa y si no aparecieron recuerdos falsos. Sin esa evidencia, el servidor sigue siendo experimento.
Matriz de arreglo y paquete de evidencia
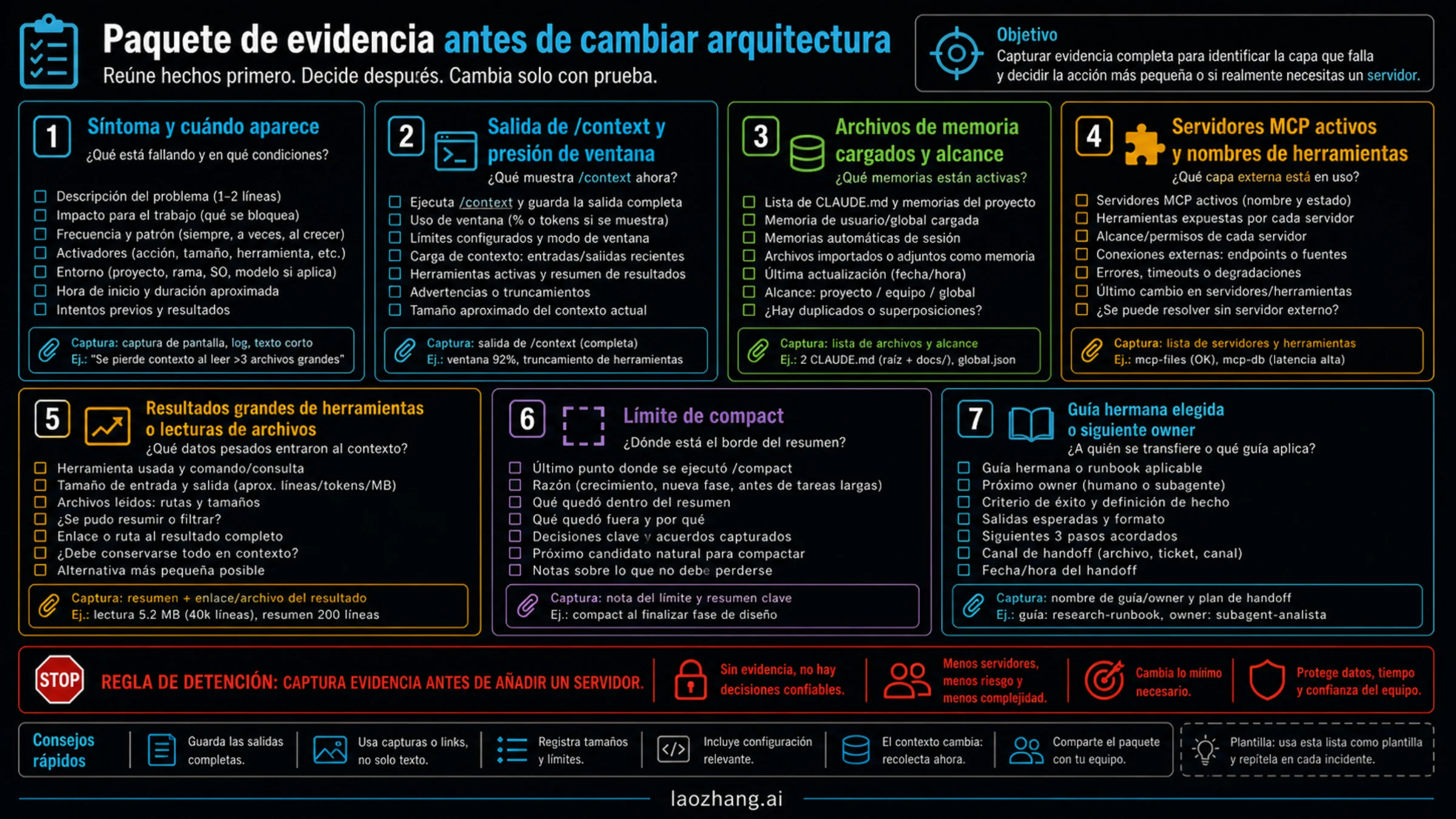
Antes de cambiar arquitectura, captura pruebas:
| Qué capturar | Por qué importa | Cómo decide |
|---|---|---|
| Síntoma y momento | Separa fallo de sesión nueva de deriva en sesión larga | Decide si empezar por /memory o /context |
| Salida de /context | Muestra presión y categorías cargadas | Decide compactar, dividir o limitar outputs |
| Salida de /memory | Muestra qué memoria está realmente cargada | Decide dónde editar reglas |
| Estado de /mcp | Muestra servers y capa externa | Decide apagar, reducir o arreglar servers |
| Resultados grandes de tools | Encuentra el origen del context bloat | Exige summary, pagination o handles |
| Límite de compaction | Aclara qué debía sobrevivir | Evita perder decisiones clave |
| Política de datos | Comprueba retención y permisos | Decide si memory MCP es aceptable |
El paquete debe demostrar por qué no basta un arreglo menor. Si apunta a memoria, edita CLAUDE.md. Si apunta a contexto, reduce material activo. Si apunta a MCP, acota el server. Si apunta a procedimiento, crea un skill. Si apunta a recuperación externa real, revisa política de datos y recién después evalúa memory MCP.
Preguntas frecuentes
¿Contexto y memoria en Claude Code son lo mismo?
No. El contexto es la ventana actual de trabajo. La memoria integrada es información persistente de proyecto o usuario que se carga en esa ventana al inicio. La memoria puede formar parte del contexto, pero el contexto no es almacenamiento duradero.
¿Debo instalar un Claude Code memory MCP?
No como primer paso. Ejecuta /context, /memory y /mcp. Usa el arreglo menor si encaja. Un memory MCP se justifica cuando necesitas continuidad entre máquinas, memoria compartida, recuperación entre herramientas o estado duradero que no encaja en la memoria integrada.
¿Tool Search elimina el coste de contexto de MCP?
No. Puede reducir la carga inicial de definiciones de tools, pero las tools usadas y sus resultados siguen entrando al material que Claude debe procesar. Siguen haciendo falta descripciones compactas, límites de salida, filtros, resúmenes y handles.
¿Las reglas del proyecto van en CLAUDE.md o en un MCP server?
La mayoría de reglas estables van en CLAUDE.md o en memoria integrada importada. MCP es para acceso externo, no para reglas cortas que deben estar visibles al arrancar.
¿Cuándo uso un skill en vez de memoria?
Cuando el problema es un método repetible: revisión, release, limpieza de datos, flujo editorial, diagnóstico de incidentes. Usa memoria para facts y preferencias que deben estar presentes al inicio.
¿La búsqueda de código es memoria?
No. La búsqueda de código encuentra archivos y símbolos. La memoria conserva reglas y decisiones. Un memory MCP externo solo entra cuando se necesita recall duradero fuera de esas dos tareas.