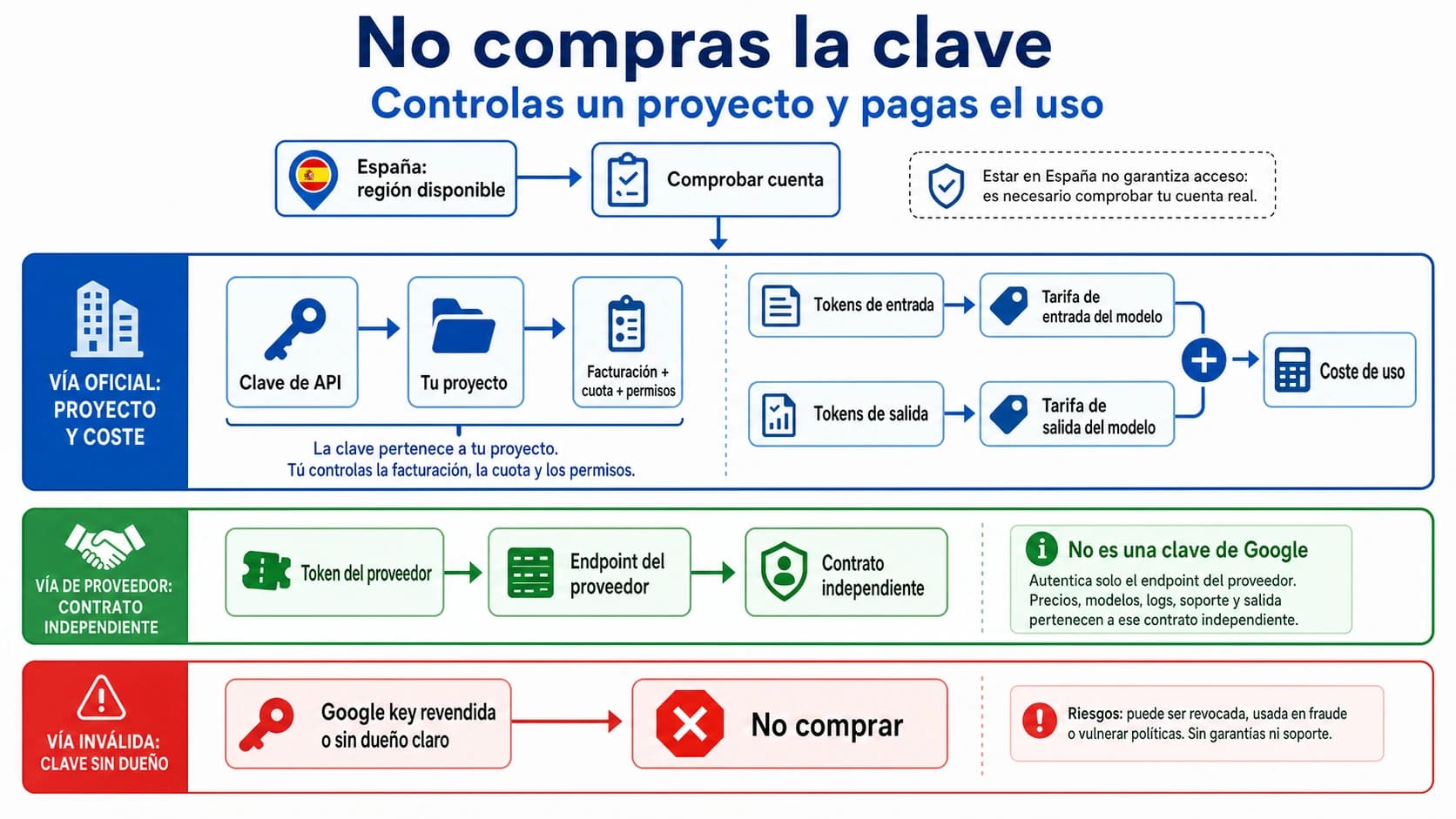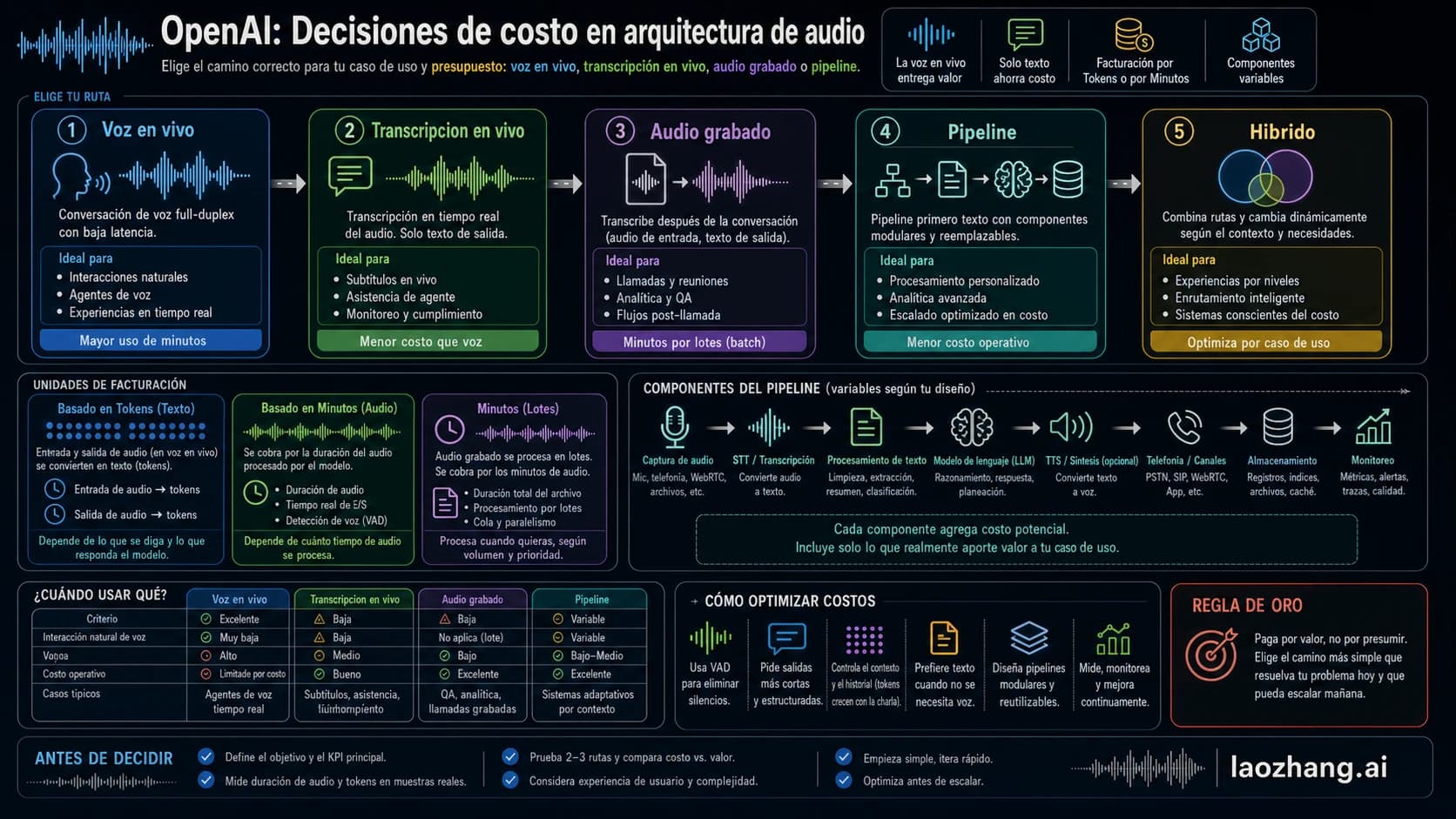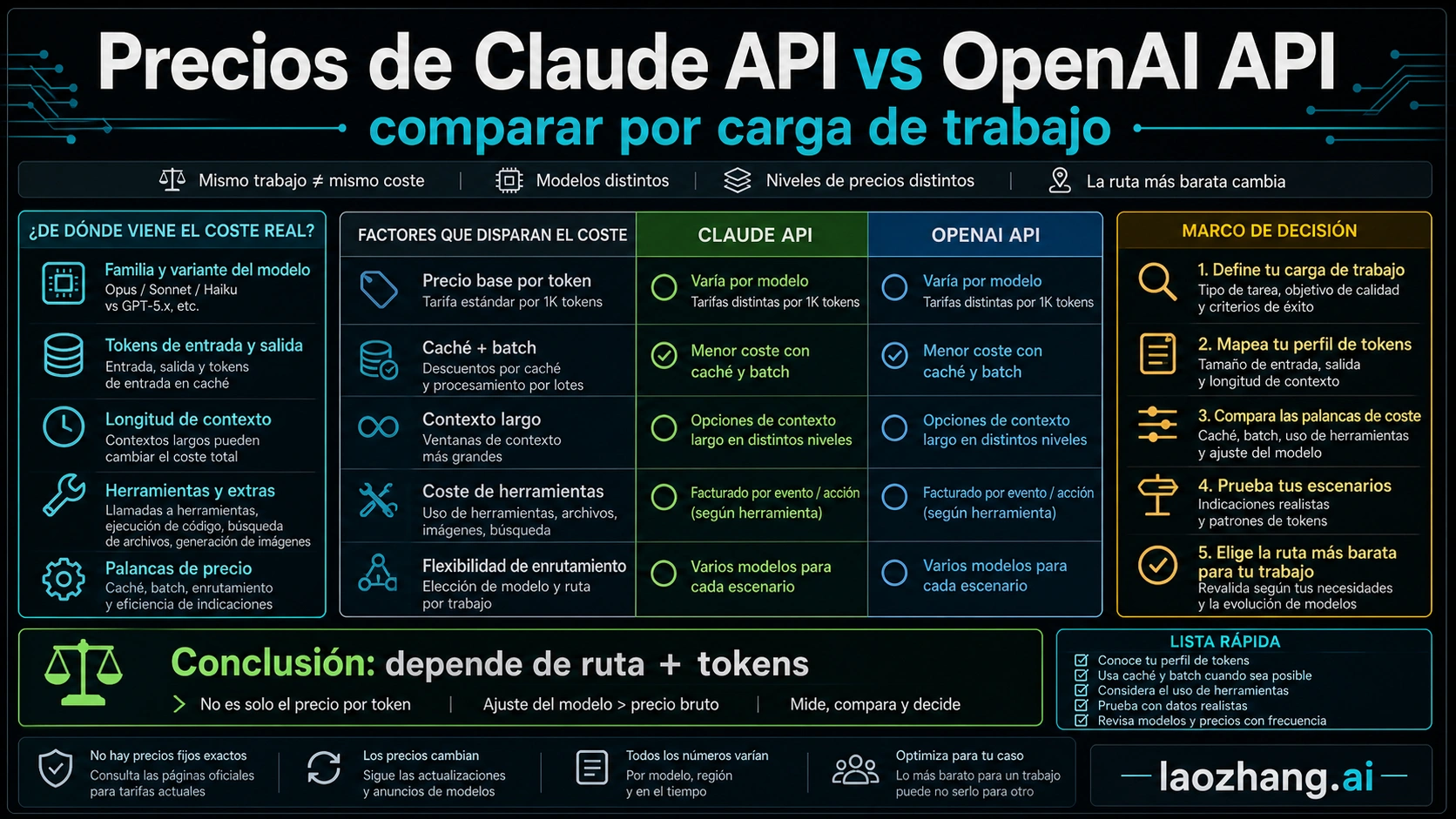
No existe una respuesta única para saber si Claude API u OpenAI API es más barato. Si la carga es masiva, breve y GPT-5.4 mini supera el umbral de calidad, OpenAI suele empezar con un coste menor. Si el trabajo necesita contexto largo, agentes de código, razonamiento complejo o mucha reutilización de caché, Claude puede ser más barato en coste total aunque una fila de precio parezca más alta.
Verificado el 2 de mayo de 2026: la página de OpenAI API Pricing lista GPT-5.5 a $5 por 1M tokens de entrada, $0.50 por cached input y $30 por output; GPT-5.4 a $2.50 / $0.25 / $15; GPT-5.4 mini a $0.75 / $0.075 / $4.50. La nota de lanzamiento de GPT-5.5 fue actualizada el 24 de abril de 2026 para decir que GPT-5.5 y GPT-5.5 Pro ya están disponibles en la API, pero antes de usarlo en producción hay que confirmar si está habilitado en la cuenta. La página de Anthropic Pricing lista Claude Opus 4.7 a $5 input y $25 output, Sonnet 4.6 a $3 / $15, Haiku 4.5 a $1 / $5 por 1M tokens, con reglas separadas para cache, batch, data residency, long context y tools.
Respuesta rápida: primero la carga, después el proveedor
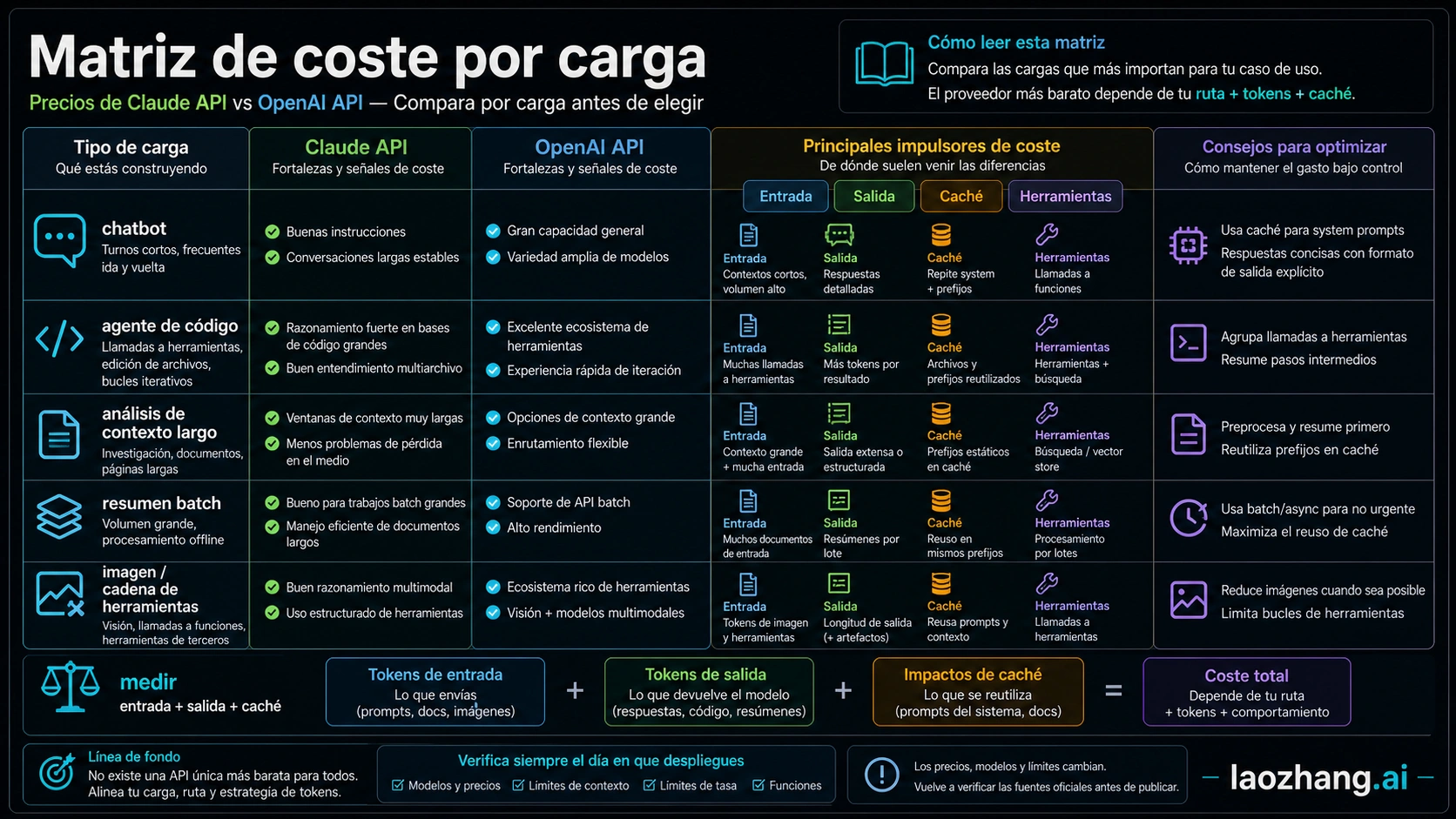
| Carga | Ruta que conviene probar primero | Motivo |
|---|---|---|
| Clasificación, extracción, resúmenes cortos | OpenAI GPT-5.4 mini | La fila base es menor que Claude Haiku 4.5. |
| Coding complejo o razonamiento profesional | GPT-5.5 y Claude Opus 4.7 con la misma muestra | El input es comparable y Opus tiene menor output, pero retries y calidad cambian el total. |
| Análisis de documentos largos | Claude Opus 4.7 o Sonnet 4.6 | Anthropic documenta 1M context a precio estándar para esas rutas. |
| Procesos offline grandes | Batch en ambos proveedores | Los dos publican descuentos de batch del 50%. |
| Prompts de sistema y RAG repetidos | Comparar cache hit rate | El cached input puede pesar más que el precio base. |
La fila de precio es solo el ancla
La tabla simple dice que GPT-5.4 mini es más barato que Haiku 4.5, y que GPT-5.4 tiene menor input que Sonnet 4.6 con el mismo output. En GPT-5.5 contra Opus 4.7, el input es igual y el output de Opus es menor. Pero GPT-5.5 debe verificarse en la cuenta antes de entrar en una hoja de costes de producción.
El coste real es coste por tarea terminada con éxito. Un modelo barato puede salir caro si produce más retries, respuestas demasiado largas, truncamientos o tool calls extra. Claude puede compensar su fila cuando reduce particiones, resúmenes intermedios o correcciones manuales en trabajos de contexto largo y agentes.
Caché y batch pueden cambiar el ganador
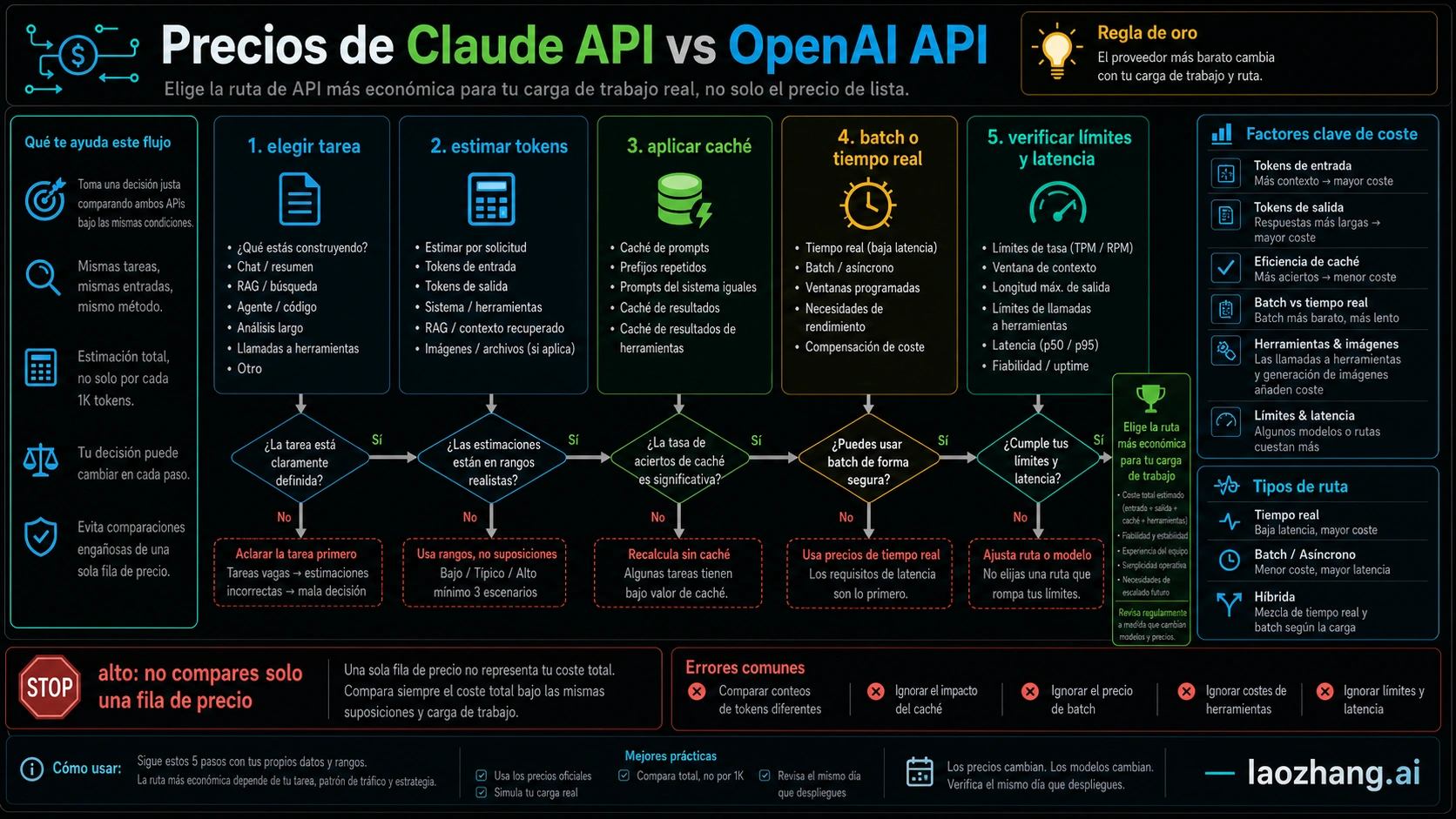
Anthropic cobra 1.25x del input base por cache write de 5 minutos, 2x por write de 1 hora y 0.1x por cache hit. OpenAI publica filas de cached input. Si repites system prompts, tool schemas, policy packs o documentos RAG, calcula por separado la primera escritura y las lecturas posteriores.
Batch sirve cuando la tarea no necesita tiempo real. OpenAI dice que Batch API ahorra 50% en input y output; Anthropic también lista 50% de descuento batch. Para evaluación, clasificación, QA de migración y resúmenes masivos, preguntar si puede ser async puede ahorrar más que cambiar de proveedor.
Cuándo OpenAI es la opción barata por defecto
OpenAI conviene primero en tareas cortas, estables y de alto volumen: classification, extraction, JSON transformation, borradores breves de soporte, títulos, resúmenes cortos y normalización de formatos. Si GPT-5.4 mini pasa la prueba de calidad, no empieces con una fila frontier.
Si GPT-5.5 no aparece en tu cuenta API, no lo fuerces en la matemática de producción. Compara la familia GPT-5.4 disponible con las filas actuales de Claude y deja GPT-5.5 como ruta pendiente de habilitación.
Cuándo Claude justifica el gasto
Claude merece prueba propia en investigación larga, comprensión de repositorios, revisión contractual, loops de agentes y knowledge bases grandes. En estos casos, el token más barato no siempre reduce el coste de la tarea.
Anthropic también advierte que el tokenizer nuevo de Opus 4.7 puede usar hasta 35% más tokens para el mismo texto fijo. Por eso no conviene estimar con recuento de palabras. Usa muestras reales, tokenizer real y tres escenarios: bajo, típico y alto output.
Calculadora mínima para el equipo
| Unidad de coste | Qué medir |
|---|---|
| input tokens | system prompt, user text, RAG, tools, files, image input |
| output tokens | answer, code, JSON, summary, explanation |
| cache | write size, read size, hit rate, TTL |
| batch | si puede esperar y si la ruta soporta la feature |
| tools | web search, code execution, image, server-side tools |
| retries | failed calls, truncation, manual reruns |
| route premium | data residency, regional endpoint, priority, fast mode |
Verificación antes del despliegue
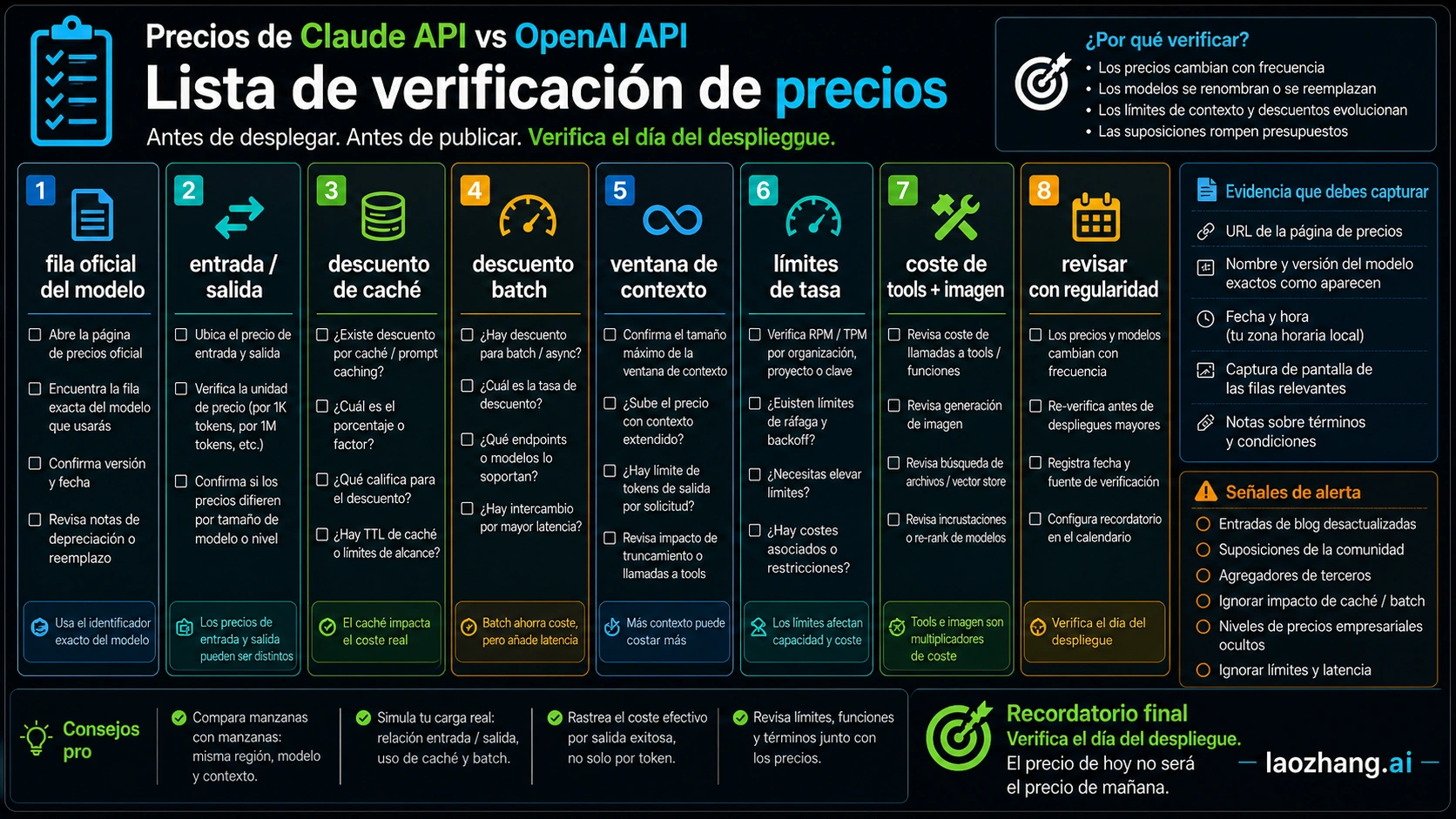
El día del despliegue vuelve a abrir OpenAI API pricing, GPT-5.5 availability note y Anthropic pricing. Verifica modelo exacto, acceso de cuenta, input/output, cache, batch, context, rate limits, tool charges y route premiums. Los calculadores y foros sirven para escenarios, no para autoridad de precios.
Dos pruebas adicionales con muestras reales
No decidas con una sola petición promedio. Prepara al menos tres muestras: entrada corta con salida corta, entrada larga con salida corta y entrada larga con salida larga. En cada una registra input tokens, output tokens, contexto reutilizable, posibilidad de batch, cache hit rate y número de retries. Así verás cuándo gana una ruta mini y cuándo una ruta de contexto largo o agentes reduce el coste total.
La segunda prueba debe usar casos límite: el documento más grande, el tool schema más pesado, el agent loop más largo y una respuesta que necesite verificación de citas. Compara truncation, errores de formato, tiempo de reparación manual, tasa de reintento y porcentaje que supera el quality bar en el primer intento. En producción, el coste caro aparece muchas veces en retries, colas y revisión humana, no solo en la fila de pricing.
Preguntas frecuentes
¿Claude API u OpenAI API es más barato?
OpenAI suele ser más barato para tareas simples y masivas. Claude debe probarse en contexto largo, agentes, cargas con mucha caché o tareas donde menos retries importan más que la fila base.
¿Puedo comparar GPT-5.5 con Claude Opus 4.7?
Sí, pero con fecha y disponibilidad. OpenAI publica precio y actualizó la nota el 24 de abril de 2026 para decir que GPT-5.5 ya está disponible en la API; Anthropic ya muestra Opus 4.7 como fila actual de API.
¿La caché siempre ahorra?
No. Si escribes en caché y nunca vuelves a leer, no ahorra. Funciona cuando reutilizas contexto grande muchas veces.
¿Batch siempre conviene?
No. Batch es para trabajos offline. En agentes interactivos y UX de baja latencia, la latencia puede importar más que el descuento.